
Linux-6-x内核分析

前言
本文主要参考姜老师的书《图解Linux内核》,还是,这本书图文结合,很适合简单适合内核/驱动/嵌入式初中级学者入门学习。
姜老师的另一本著作《精通Linux内核:智能设备开发核心技术》讲的较为深入,两本书结合相信能够帮很多小伙伴进一步熟悉Linux内核的原理。
本文将两本书结合起来,在原有基础上进行了一些扩展,后面也会加入linux系统加载相关部分。可惜老师并没有写网络相关的部分,笔者斗胆在结尾把网络管理部分也补充完整,尽可能和姜老师一样图文并茂的讲述Linux内核网络管理部分的原理。
本文着重讲解原理,关于项目实例放在了其他内核分析和Linux/Android驱动编程系列的文章里面。
基础篇
Linux内核概述
CPU与操作系统
处理器,也就是我们常说的中央处理器(Central Processing Unit, CPU),它是一台计算机的运算中心和控制中心,简单地说,它负责解释执行指令,并处理数据。但是仅仅一个处理器是无法运行的,必须有一套与处理器配合的硬件,它们与处理器一起构成一个平台。不同的处理器要求的硬件是不同的,比如x86处理器,一般配套的有南桥、北桥芯片和存储BIOS的芯片等。操作系统(Operating System, OS)是管理计算机硬件和软件资源的程序,是运行在平台上最基本的软件,其他软件以它为基础。
处理器运行操作系统用于管理应用程序的执行,应用程序通过操作系统使用平台的硬件,达到预期的运行效果,满足用户的需求。内核是操作系统最基本的部分,也是操作系统与硬件关系最密切的一部分,控制系统对硬件的访问。同样,Linux内核是它的操作系统的基础,包含了内存管理、文件系统、进程管理和设备驱动等核心模块。
一个基于Linux内核的操作系统一般包含以下几个部分:
bootloader, 比如GRUB和SYSLINUX,它负责将内核加载进内存,系统上电或者BIOS初始化完成后执行。- init程序,负责启动系统的服务和操作系统的核心程序。
- 必要的软件库(比如加载elf文件的ld-linux.so), 支持C程序的库(比如GNU C Library,简称glibc),Android的Bionic。
- 必要的命令和工具,比如shell命令和GNU coreutils等。coreutils是GNU下的一个软件包,提供常用的命令,比如ls等。
Linux内核代码结构
内核的代码比较复杂,一方面是代码量大,另一方面是模块间交叉,一个问题往往关联多个模块。好在内核维护的过程中,代码的结构一直比较清晰。
| 序号 | 第一级目录 | 第二级目录和文件 |
|---|---|---|
| 1 | arch |
包含与特定体系结构(架构)相关的代码。子目录对应支持的处理器架构,例如 x86/, arm/, mips/, riscv/。 每个架构目录内通常包含: boot/:启动相关代码,例如启动加载器。 kernel/:与架构相关的内核代码。 mm/:架构相关的内存管理代码。 include/:架构特定的头文件。 |
| 2 | block |
负责块设备子系统,管理磁盘和块设备的核心逻辑。提供块设备的 I/O 调度器。包含通用块设备管理代码。示例文件:blk-core.c(块设备核心实现) |
| 3 | certs |
处理与内核模块签名相关的证书。内核模块签名所需的公钥、私钥存储和管理等。 |
| 4 | crypto |
实现内核中的加密算法和加密框架。 |
| 5 | Documentation |
存放相关说明文档,很多实用文档,包括驱动编写等 。filesystems/:文件系统相关文档。 networking/:网络子系统相关文档。 admin-guide/:系统管理员指南。 dev-tools/:开发者工具指南。 |
| 6 | drivers |
存放 Linux 内核设备驱动程序源码。驱动源码在 Linux 内核源码中站了很大比例,常见外设几乎都有可参考源码,对驱动开发而言,该目录非常重要。该目录包含众多驱动,目录按照设备类别进行分类,如char、block、input、i2c、spi、pci、usb等 |
| 7 | firmware |
存储内核加载时需要的设备固件。固件文件用于初始化和操作特定硬件设备。 |
| 8 | fs |
**实现各种文件系统的代码。 子目录按文件系统类型分类,例如: **ext4/**:ext4 文件系统代码。 **nfs/**:NFS 文件系统代码。 **fat/:FAT 文件系统代码。 通用文件系统代码: namei.c:文件路径解析。 file.c:文件操作相关代码。 |
| 9 | include |
**存放内核所需、与平台无关的头文件,与平台相关的头文件已经被移动到 arch 平台的include 目录, **linux/**:与内核功能相关的头文件,例如 sched.h(调度器)、fs.h(文件系统)。 **asm/**:架构相关的头文件,通常是指向 arch/ 的链接。 **uapi/:用户态 API 头文件,与用户空间共享的数据结构。 |
| 10 | init |
包含内核初始化代码,init文件夹包含了内核启动的处理代码(INITiation)。main.c是内核的核心文件,这是用来衔接所有的其他文件的源代码主文件。do_mounts.c:根文件系统挂载代码。 |
| 11 | ipc |
存放进程间通信代码, 此文件夹中的代码是作为内核与进程之间的通信层。内核控制着硬件,因此程序只能请求内核来执行任务。假设用户有一个打开DVD托盘的程序。程序不直接打开托盘,该程序通知内核,然后,内核给硬件发送一个信号去打开托盘。 |
| 12 | kernel |
这个文件夹中的代码控制内核本身,包含调度器、内核线程、时间管理等核心功能代码。 sched/:CPU 调度器代码。 fork.c:进程创建和管理。 time/:时间管理。 |
| 13 | lib |
这个文件夹包含了内核需要引用的一系列内核库文件代码。 提供通用算法(如哈希、红黑树)。 提供内核中的字符串处理、位操作等工具函数。 |
| 14 | mm |
实现内存管理子系统。负责物理内存和虚拟内存的分配和回收。 slab.c:内核对象分配器(SLAB 分配器)。 vmalloc.c:虚拟内存分配。 |
| 15 | net |
**实现网络协议栈。 子目录按协议分类,例如: **ipv4/**:IPv4 协议栈。 **ipv6/:IPv6 协议栈。 netfilter/:防火墙相关代码。socket.c:套接字接口。net文件夹中包含了网络协议代码。这包括IPv6、AppleTalk、以太网、WiFi、蓝牙等的代码,此外处理网桥和DNS解析的代码也在net目录。 |
| 16 | samples |
存放提供的一些内核编程范例,如kfifo;后者相关用户态编程范例,如hidraw 此文件夹包含了程序示例和正在编写中的模块代码。假设一个新的模块引入了一个想要的有用功能,但没有程序员说它已经可以正常运行在内核上。那么,这些模块就会移到这里。这给了新内核程序员一个机会通过这个文件夹来获得帮助,或者选择一个他们想要协助开发的模块。 |
| 17 | srcipts |
用于内核配置、编译和分析。这个文件夹有内核编译所需的脚本。示例文件: kconfig/:内核配置工具。 checkpatch.pl:代码风格检查脚本。 |
| 18 | security |
这个文件夹是有关内核安全的代码。包括 SELinux、AppArmor 等安全模块。 |
| 19 | sound |
这个文件夹中包含了声卡驱动,存放声音系统架构相关代码和具体声卡的设备驱动程序。包含 ALSA(高级 Linux 声音架构)的实现代码。 |
| 20 | tools |
编译过程中一些主机必要工具,这个文件夹中包含了和内核交互的工具。提供内核调试和性能分析工具。包括 perf 工具、bpf 调试工具等。 |
| 21 | usr |
实现内核初始化 RAM 磁盘(initramfs)。用于打包并加载初始根文件系统。 |
| 22 | virt |
实现虚拟化功能。包括 KVM(内核虚拟机)的实现。 |
驱动目录结构:
| 序号 | 目录 | 说明 |
|---|---|---|
| 1 | drivers/gpio |
系统GPIO子系统和驱动目录,包括处理器内部GPIO以及外扩GPIO驱动。遵循GPIO子系统的驱动,可通过/sys/class/gpio进行访问 |
| 2 | drivers/hwmon |
硬件监测相关驱动,如温度传感器、风扇监测等 |
| 3 | drivers/i2c |
I2C子系统驱动。各I2C控制器的驱动在i2c/busses目录下 |
| 4 | drivers/input |
输入子系统驱动目录 |
| 5 | drivers/input/keyboard |
非HID键盘驱动,如GPIO键盘、矩阵键盘等 |
| 6 | drivers/input/touchscreen |
触摸屏驱动,如处理器的触摸屏控制器驱动、外扩串行触摸屏控制器驱动、串口触摸屏控制器驱动等 |
| 7 | drivers/leds |
LED子系统和驱动,如GPIO驱动的LED。遵循 LED子系统的驱动 ,可通过/sys/class/leds进行访问 |
| 8 | drivers/mfd |
多功能器件(Multi-Function Device)驱动。如果一个器件能做多种用途,通常需要借助MFD来完成。 |
| 9 | drivers/misc |
杂项(Miscellaneous)驱动。特别需要关注<drivers/misc/eeprom/>目录,提供了i2c和spi接口的EEPROM驱动范例,所驱动的设备可通过/sys系统访问 |
| 10 | drivers/mmc |
SD(Secure Digital)/MMC(Mutimedia Card)卡驱动目录 |
| 11 | drivers/mtd |
MTD(Memory Technology Device)子系统和驱动,包括NAND、oneNAND等。注意,UBI的实现也在MTD中 |
| 12 | drivers/mtd/nand |
NAND FALSH的MTD驱动目录,包括NAND的基础驱动和控制器接口驱动 |
| 13 | drivers/net |
网络设备驱动,包括MAC、PHY、CAN、USB 网卡、无线、PPP协议等 |
| 14 | drivers/net/can |
CAN设备驱动。Linux已经将CAN归类到网络中,采用socket_CAN接口 |
| 15 | drivers/net/ethernet |
所支持的MAC驱动。常见厂家的MAC驱动都能找到,如broadcom、davicom、marvell、micrel、smsc等厂家的MAC,处理器自带MAC的驱动也在该目录下 |
| 16 | drivers/net/phy |
PHY驱动,像marvell、micrel和smsc的一些PHY驱动 |
| 17 | drivers/rtc |
RTC子系统和RTC芯片驱动 |
| 18 | drivers/spi |
SPI子系统和SPI控制器驱动,含GPIO 模拟SPI的驱动 |
| 19 | drivers/tty |
tty驱动用于管理物理终端连接。 |
| 20 | drivers/tty/serial |
串口驱动,包括8250串口以及各处理器内部串口驱动实现 |
| 21 | drivers/uio |
用户空间IO驱动 |
| 22 | drivers/usb |
USB驱动,包括USB HOST、Gadget、USB转串口以及OTG等支持 |
| 23 | drivers/video |
Video驱动,包括Framebuffer驱动、显示控制器驱动和背光驱动等。 |
| 24 | drivers/video/backlight |
背光控制驱动 |
| 25 | drivers/video/logo |
Linux内核启动LOGO图片目录 |
| 26 | drivers/watchdog |
看门狗驱动,包括软件看门狗和各种硬件看门狗驱动实现 |
内核中的模块较多,而且关系错综复杂,整体结构如图所示。
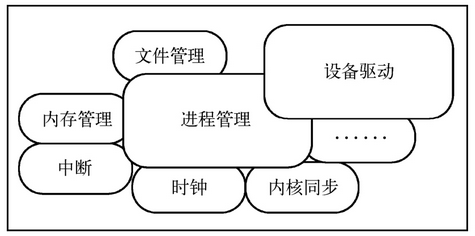
首先是几个相对独立的模块,比如中断(异常)、时钟和内核同步等,它们依赖于硬件和具体的体系结构,对其他模块依赖较小。它们也都属于基础模块,用于为其他模块提供支持。
- 中断模块不仅在设备驱动中频繁使用,内存管理和进程调度等也需要它的支持,内存管理需要缺页中断,进程调度则需要时钟中断和处理器间中断等。
- 时钟设备一方面是系统计算时间的基础,另一方面提供时钟中断,与大多数模块都有关联。
- 内核同步模块贯穿整个内核,如果没有同步机制,错综复杂的执行流访问临界区域就会失去保护,系统瞬间瘫痪。
内存管理、文件管理和进程管理算得上是内核中除了网络外最复杂的三个模块,也是本书讨论的重点。说它们最复杂与drivers目录体量庞大并不矛盾:drivers目录包含了成千上万个设备的驱动,单算一个驱动其实并不复杂。
- 内存管理模块涉及内存寻址、映射、虚拟内存和物理内存空间的管理、缓存和异常等。
- 文件系统的重要性从“一切皆文件”这句话就可以体现出来,硬件的控制、数据的传递和存储,几乎都与文件有关。
- 进程管理模块涉及进程的实现、创建、退出和进程通信等,进程本身是管理资源的载体,管理的资源包括内存、文件、I/O设备等,所以它与内存管理和文件系统等模块都有着紧密的关系。
- 设备驱动模块,从功能角度来看,每一个设备驱动都是一个小型的系统,电源管理、内存申请、释放、控制、数据,复杂一些的还会涉及进程调度等,它与前面几个模块都有着密切关系。所以对内核函数的熟悉程度,很大程度上决定了一个驱动工程师的效率;对其他模块的理解程度,很大程度上决定了他的高度。
Android操作系统
Android操作系统便是基于Linux内核,在此基础上搭建了从类库到app的整套架构。
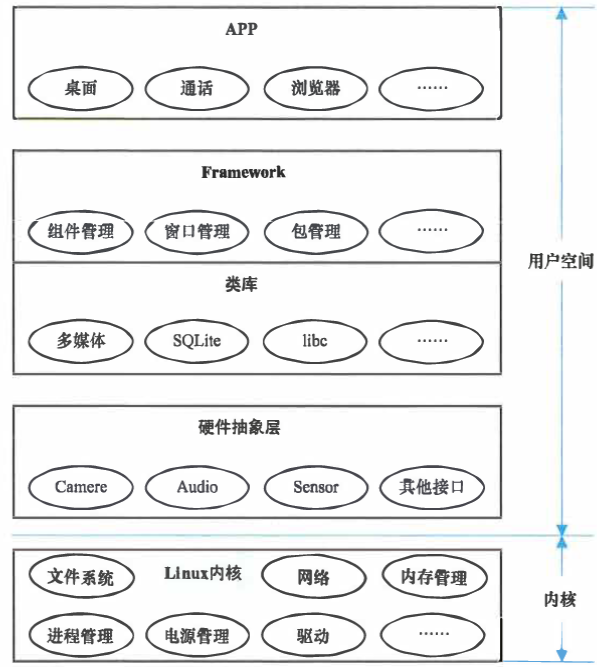
Linux内核作为整个架构的基础,负责内存管理,电源,文件系统和进程等核心模块,提供系统的设备驱动。
硬件抽象层可以保护芯片厂商的知识产权,避开Linux的GPL协议,芯片厂商的保密算法的代码可以以二进制文件的形式提供给手机等设备制造商,集成在硬件抽象层。另一个主要作用是屏蔽硬件差异,他与设备驱动紧密联系,可以根据系统的要求将数据和控制标准化。
Framerwork和类库是Android的核心,它规定并实现系统的标准,接口,构建Android的框架,比如数据存储,显示,服务和应用程序管理等。
应用层利用Framerwork的接口,接受设备驱动的数据,根据用户的指令,将控制传递至设备驱动。
需要说明的是,从应用层到硬件抽象层都属于用户空间,硬件抽象层并不属于内核,它与内核虽然逻辑上联系紧密,但也不能直接调用内核的函数,一般调用类库提供的接口实现,比如Bionic。上图所示的Android操作系统的架构图描述的只是逻辑关系,并不是函数调用关系,从函数调用关系角度看,libc(Bionic的一部分)与内核的关系更加紧密。
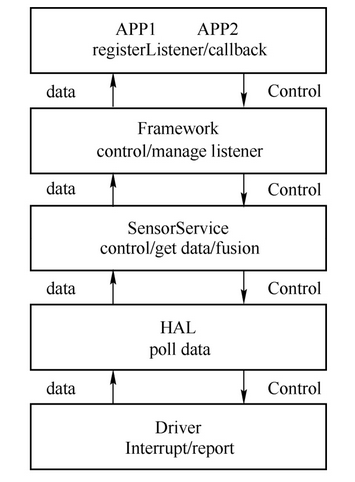
针对某一个模块,比如Sensor(传感器),系统运行时的架构如上图所示。图中箭头表示控制和数据传递关系,控制由APP向下传递,数据则由下向上。
图中涉及三个进程,APP1、APP2和Service,APP和Service之间传递控制和数据都需要通过进程通信实现,Service将控制传递至HAL,最终到设备驱动,HAL得到驱动产生的数据,报告至Service,由Service分发给APP1和APP2。从函数调用角度来看,Framework、Service和HAL都可能调用library,最终进入内核,Framework可能需要通过内核打开、关闭文件或与其他进程通信等,但它并不会直接访问设备驱动。仅保留Service和HAL的唯一访问设备驱动的通路,有助于设备的单一控制。如果APP进程直接控制驱动,会造成混乱。
需要说明的是,并不是每一个模块都需要HAL,比如Touch(触摸屏),Touch不需要APP控制,屏幕亮起即工作,关屏则关闭,Touch驱动的数据单位就是点坐标,也不需要转化,所以它不需要HAL。不仅仅是Sensor,任何一个模块,只要它与某个硬件有关,哪怕只是申请内存,都绕不开内核。下面从操作系统的几个核心功能看看Android与内核的关系。
- 进程管理:进程这个概念本身是由内核实现的,还包括进程调度、进程通信等。Android利用Pthread等实现了它的进程、线程,是对内核系统调用的封装。另外,Android还引入Binder通信,Binder也不是仅仅依靠用户空间就可以完成的,它也是需要驱动的,目前Linux内核的代码已经包含了Binder的驱动代码。
- 内存管理:内存、内存映射和内存分配、回收等内核都已实现。Android也实现了特有的ION内存管理机制,可以使用它在用户空间申请大段连续的物理内存。与Binder一样,ION的驱动代码也已经存在于内核中了。
- 文件系统:内核实现了文件系统的框架和常用的文件系统。文件系统不仅关乎数据存储,进程、内存和设备等都离不开它。对Linux而言,几乎是“一切皆文件”,Android延续了这种理念。
- 用户界面:Android开发了一套控件(View)供应用开发人员使用,背后有一套完整的显示架构支持它们,包括Framework中的Window Manager和Library中的Surface Manager等。除此之外,Android还开发了虚拟机(ART),运行Java开发的应用程序。
- 设备驱动:设备驱动由内核提供,需要随系统启动而运行的设备驱动,一般在内核启动过程中加载,某些在特定情况下才会使用的设备驱动(比如Wifi),在设备使用时被加载,前者一般被编译进内核,后者以ko文件的形式存在。
如果把整个Android比作一个房子,内核就是地基,加上Android架构,就成了一个毛坯房,再加上应用开发者开发的应用才是一个可以拎包入住的房子。如此看来,一部新手机算是精装交付了。
Linux 内核的作用
Linux内核与操作系统是底层基础和上层建筑的关系,内核提供了基本功能和概念,操作系统在此基础上根据自身的定位和特色实现自身的架构,提供接口和工具来支持应用开发,由应用体现其价值。
开机后,内核由bootloader加载进入内存执行,它是创建系统的第一个进程,初始化时钟、内存、中断等核心功能,然后执行init程序。init程序是基于Linux内核的操作系统,在用户空间的起点,它启动核心服务,挂载文件系统,更改文件权限,由后续的服务一步步初始化整个操作系统。
内核实现了内存管理、文件系统、进程管理和网络管理等核心模块,将用户空间封装内核提供的系统调用作为类库,供其他部分使用。内核并不是最底层的,下面还有硬件层,即内核驱动硬件、系统的数据来源于硬件、最终的结果也要靠硬件去体现,内核是系统与硬件的桥梁。
内核常见数据结构
内核中有很多数据结构本身并没有实际意义,它们扮演的是辅助角色,为实现某些特殊目的“穿针引线”,比如下面介绍的几种,可以辅助实现数据结构之间关系。也有某些数据结构,特别适用于某些特定场景,实现某些特定功能,比如位图。
关系型数据结构
程序=数据结构+算法,数据结构指的是数据与数据之间的逻辑关系,算法指的是解决特定问题的步骤和方法。逻辑关系本身就是现实的反映与抽象,理解逻辑关系是理解程序的关键,本节将讲述实现一对一、一对多和多对多关系的常用数据结构和方法。
一对一关系
一对一的关系随处可见,结构体与其成员、很多结构体与结构体之间都是这种关系。结构体与成员的一对一关系简单明了,两个结构体之间的一对一关系有指针和内嵌(包含)两种表达方式,代码如下。
1 | //指针 |
第二种方式的主要优点是对一对一关系体现得比较清晰,同时也方便管理,因为通过container_of宏(内核定义好的)可以由b计算出a的位置,而不再需要多一个指向a的指针。
然而第二种方式并不一定是最好的,要视逻辑而定。比如男人和妻子,通常是一对一,如果采用内嵌的方式首先造成的是逻辑混乱,男人结构体中多了一些不属于男人的成员(即妻子);其次,并不是每个男人都有妻子,有些是单身,用指针表示就是NULL,内嵌无疑浪费了空间。所以,要满足逻辑合理、有a就有b这两个条件,采用这种方式才是比较恰当的。
安全性是程序的首要要求,而合理的逻辑是安全性重要的前提,违背逻辑的程序即使当前“安全”,在程序不断维护和更新的过程中,随着开发人员的变动,隐患迟早会爆发。
一对多关系
一对多关系在内核中一般由链表或树实现,由于数组的大小是固定的,除非在特殊情况下,才会采用数组。用链表实现有多种常用方式,包括list_head、hlist_head/hlist_node、rb_root/rb_node(红黑树)等数据结构。下面以branch(树枝)和leaf(树叶)为例进行分析。
最简单的方式是单向链表,该方式直接明了,只需要leaf结构体内包含一个leaf类型的指针字段即可,代码如下。中断部分的irq_desc和irqaction结构体使用的就是这种方式。
branch包含指向链接头的指针,leaf对象通过next串联起来,如下图所示。
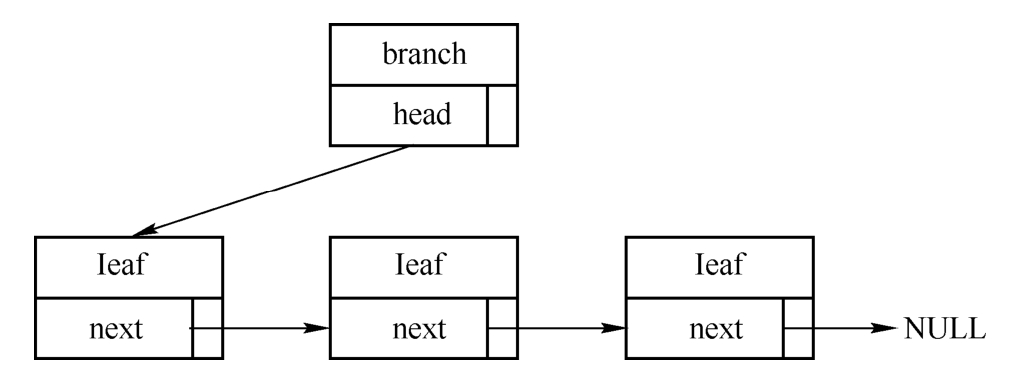
该方式的局限在于不能通过一个leaf访问前一个leaf对象,当然也不能方便地在某个元素前面插入新结点或删除当前结点,正因为缺乏灵活性,它一般用在只需要通过branch访问leaf的情况下。一般情况下,链表中所有的点都被称为结点,其中链表头被称为头结点。为了更好地区分头结点和其他结点,在本书中分别称之为链表头和链表的(普通)元素。
在需要方便地进行遍历、插入和删除等操作的情况下,上面的方式过于笨拙,可以使用双向链表。内核中已经提供了list_head、hlist_head等数据结构来满足该需求。branch的head字段是该链表的头,每一个相关的leaf都通过node字段链接起来,list_head的使用如下。
1 | struct branch{ |
利用这个双向链表和container_of等宏,就可以方便地满足遍历、插入和删除等操作,list_head定义如下。
1 | struct list_head{ |
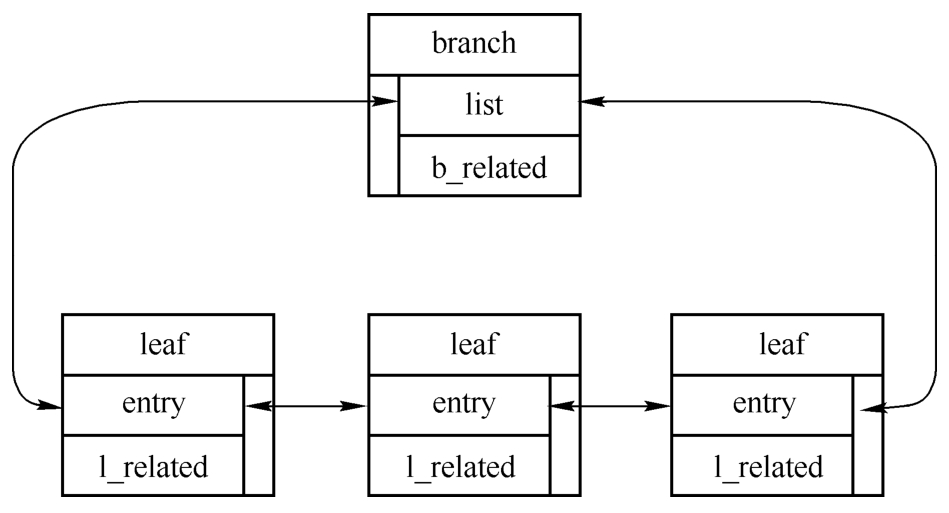
从上图可见,真正串联起来的是list_head,而不是branch或者leaf。不过有了list_head,通过container_of宏就可以得到branch和leaf了。内核提供了很多list_head相关的函数和宏,其中一部分如下表所示。
| 函数和宏 | 描 述 |
|---|---|
| LIST_HEAD(name) | 定义并初始化一个名字为 name 的链表 |
| INIT_LIST_HEAD(list) | 初始化 list |
| list_add(new,node) | 在 node 后面插入 new |
| list_add_tail(new,node) | 在 node 前面插入 new , node==head 时,插在尾部 |
| list_empty(node) | 链表是否为空,node 可以不等于 head |
| list_is_last(node,head) | node 是否为最后一个元素 |
| list_delete(node) | 删除 node |
| list_entry(ptr,type,member) | ptr 为 list_head 的地址,type为目标结构体名,member 是目标结构体内list_head对应的字段名,作用是获得包含该list_head的type对象。 例:struct leaf*leaf=list entry(ptr,struct leaf,node) |
| list_first_entry(ptr,type,member) | 参数同上,作用是获得包含下一个list_head结点的type对象 |
| list_for_each_entry(pos,head,member) | 遍历每一个type对象,pos是输出,表示当前循环中对象的地址,type 实际由typeof(*pos)实现 |
| list_for_each_entry_safe(pos,n,head,member) | n 起到临时存储的作用,其他同上。区别在于,如果循环中删除了当前元素,xxx_safe是安全的 |
list_head链表的头与链表的元素是相同的结构,所以无论传递给各操作的参数是链表头还是元素编译器都不会报错。但它们代表的意义不同,有些操作对参数是有要求的,比如list_delete不能以链表头为参数,否则branch的list相关字段被置为LIST_POISON1/LIST_POISON2,整个链表将不复存在。
另外,需要特别注意的是,也正是由于list_delete删除元素后会重置它的prev、next字段,所以不带safe后缀的操作(如list_for_each_entry),获得元素后不能进行删除当前元素的操作,否则无法完成遍历操作。有safe后缀的操作会使用n临时复制当前元素的链表关系,使用n继续遍历,所以不存在该问题。
list_head有一个兄弟,即hlist_head/hlist_node。顾名思义,hlist_head表示链表头,hlist_node表示链表元素,它们的定义如下。
1 | struct hlist_head { |
hlist_head的first字段的值是链表第一个node的地址,hlist_node的next字段是指向下一个node的指针,pprev字段的值等于前一个node的next字段的地址。如果分别以curr、prev和next表示当前、前一个和下一个node的地址,那么curr->next==next,curr->pprev==&prev->next都成立。
与list_head相比,hlist的链表头与链表元素的数据结构是不同的,而且hlist_head占用内存与list_head相比小了一半。存在多个同质的双向链表的情况下,链表头占的空间就值得考虑节省了。内核中很多地方使用了它,这些链表头存于数组、哈希表、树结构中,节省的空间是比较可观的。
另外,hlist_head不能直接访问链表的最后一个元素,必须遍历每一个元素才能达到目的,而list_head链表头的prev字段就指向链表最后一个元素。因此,hlist_head并不适用于FIFO(First In First Out)的需求中。
内核也提供了hlist_head的相关操作,大多与list_head的操作相似,如下表所示。
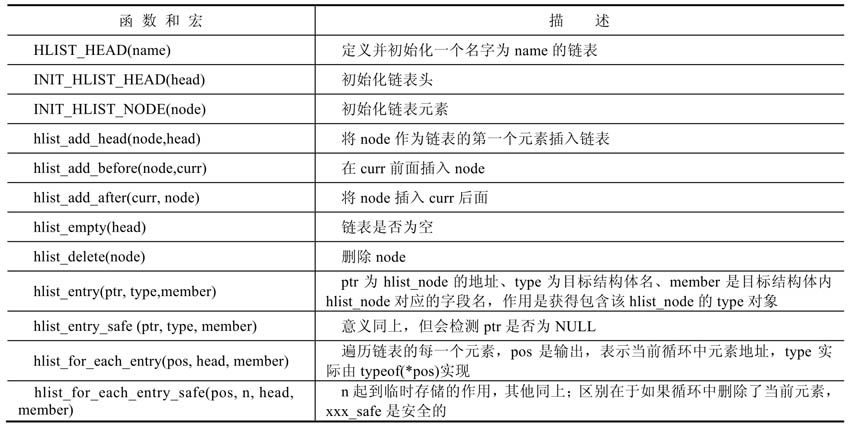
与list_head相同,不带safe后缀的操作(如hlist_for_each_entry)获得元素后,不能进行删除当前元素的操作,否则无法完成遍历操作。
红黑树、基数(radix)树等结构也会用在一对多的关系中,它们涉及比较有趣的算法,在对查询与增删改等性能要求较高的地方使用较多,相关知识可参考算法方面的书籍,内核中提供的函数可参考rbtree.h和radix-tree.h等文件。我在数据结构与算法中也有所介绍,后面也会用C语言来实现。
多对多关系
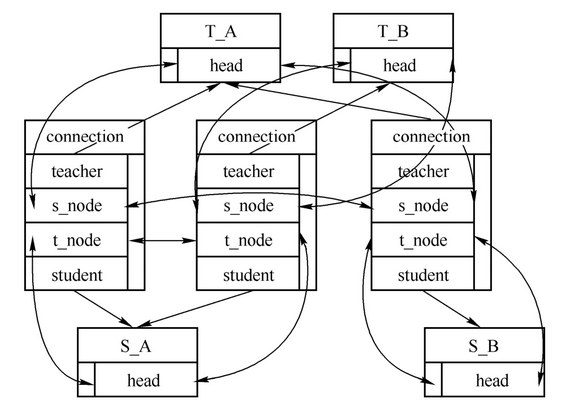
多对多关系相对复杂,它并不能像一对多关系那样可以简单地通过将list_head等的结点包含到结构体中来实现。在教与学范畴内,教师和学生关系属于多对多关系,下面就以teacher和student结构体为例分析(链表以list_head为例)。
一个教师可以有多个学生,从数据结构的角度看,teacher包含list_head链表头,每个student对象都可以通过list_head结点访问到,list_head结点链接到teacher包含的头上。
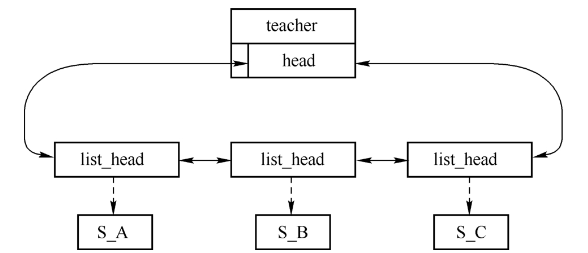
本质上,一对关系就需要一个结点,比如学生A(S_A)是教师A(T_A)的学生,需要一个结点链接到T_A包含的链表头;同时,学生A也是教师B的学生,也需要一个结点链接到T_B包含的链表头。针对该情况,一个学生可以属于多个链表,所以简单地将list_head的结点包含到student结构体中是无法实现多对多关系的(因为指针指向的唯一性,list_head属于且仅属于一个链表)。
可行的做法是将list_head独立于student结构体,并配合一个指向student对象的指针来定位结点所关联的student对象,如下。
1 | struct s_connection { |
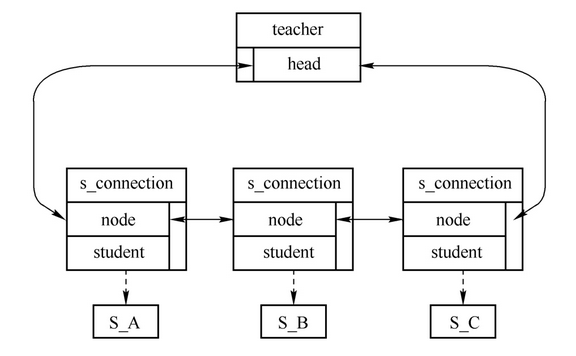
这样从student对象的角度,会有多个指针指向它,也有多个结点与它关联,如此它就可以与多个链表产生关系了。同样,一个学生可以有多个教师,也会遇到一个teacher对象会出现在多个student的链表中的问题,那就需要定义一个t_connection结构体,如下。
1 | struct t_connection { |
由于这种关系是相互的,如果S_A是T_A的学生,那么T_A必然是S_A的老师;如果S_A不是T_A的学生,那么T_A必然也不是S_A的老师。反之亦然。所以可以将s_connection和t_connection合并起来,具体代码如下。
1 | struct connection { |
到此,教师和学生的多对多关系就可以完整地用程序实现了,具体代码如下。
1 | struct teacher { |
connection结构体的s_node字段链接到teacher结构体head_for_student_list字段表示的链表头,t_node字段链接到student结构体head_for_teacher_list字段表示的链表头,这个错落有致的关系网就完毕了。
老师T_A有S_A和S_B两个学生的关系,老师T_B有S_A一个学生的关系,如下图所示。
input 子系统
input子系统有两大类使用场景。
- 第一类是协助我们完成设备驱动(device), 适用于鼠标、键盘、电源按键和传感器等设备。这类设备的共同点是数据量都不大,比如多数传感器不会超过X,Y,Z三个维度的数据。 它最基本的作用是报告数据给系统,如果我们在驱动中定义一些与它相关的文件,也可以作为控制设备的接口使用。
- 第二类协助我们定义操作(handler)来处理input事件,设备报告给系统 数据信息、报告一系列数据的结尾标志等都属于input事件。 一个input事件由
input_value结构体表示,它的type、code和value 三个字段分别表示事件的类型、 事件码和值。比如手指按在支持多指操作的触摸屏上,报告一个手指的坐标,至少应该包含{EV _ABS, ABS_MT_POSlTlON_X, x}和{EV _ABS, ABS_MT_POSlTlON_Y, y},两组数据表示x/y坐标,报告完毕所们手指的坐标信息后, 还需要一个{EV_SYN,SYN_REPORT,O}表示结束。
input子系统的三个关键结构体input_dev、input_handler、input_handle就是如此实现的,input_dev和input_handler是多对多的关系,input_handle就相当于这里的connection。并不是每个多对多的关系中两个connection结构体都可以合并的,有些关系并不是相互的,比如男生和女生的暗恋关系。A男暗恋B女,B女却不一定暗恋A男;A男的链表关联B女,B女的链表不一定关联A男。两个connection结构体合并在一起明显浪费空间,如果强行利用多余的空间,岂不逻辑混乱。
位操作数据结构
位图(bitmap),以每一位(bit)来存放或表示某种状态,这样一个字节(byte)就可以表示8个元素的状态,可以极大地节省内存。一个bit只有0和1两个值,所以它也只适用于每个元素都是“非黑即白”的场景,比如打开和关闭、被占用和空闲等。
位图的本质是一段物理连续的存储空间,其中每一位表示一个元素的状态。比如申请新的文件描述符fd时,某一个bit为1,表示该bit对应的fd已被占用;为0,则表示fd可用。该bit相对于起始位置的偏移量就是fd的值。我们不妨假设表示fd的这段连续内存内容从低位到高位是 (11111111,11111111,10…),第17位可用,那么得到的fd可能就是17。
实际上多数程序员对位图并不陌生,人们可能经常使用一个整数来表示某些状态,比如很多函数的flags等类似的参数,会在自己的函数中操作这个整数的位来更改它的状态,或者根据它的状态来决定函数的行为。这其实也可以算作位图的一种,只不过一个整数一般最多表示32或者64个元素,位图可以表示的元素可以更多。除此之外,它们在逻辑上可能也有些许差别,位图表示的元素一般都是同质化的,而操作整数的情况可能逻辑上要复杂些。
内核提供了几个宏和函数,可以用来进行位操作,如下表。
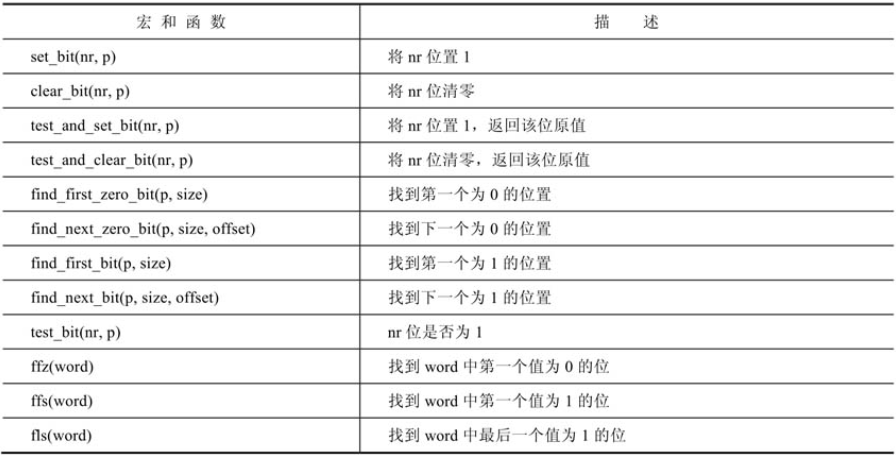
find_first_zero_bit和find_first_bit的第二个参数size是以位(bit)为单位的,find_next_zero_bit和find_next_bit从第offset位(包含offset)开始查找为0和为1的位置,找不到则返回size。有了以上的宏和函数,可以很方便地找到位图中的某位,比如要获取文件描述符的函数alloc_fd,它最终调用find_next_zero_bit来查找位图中下一个值为0的位,该位的偏移量就是可用的文件描述符。
模块和内核参数传递
内核的数据结构因为需要供多个模块使用,所以要考虑通用性,而很多模块往往要考虑自身的特性,需要满足自身需求的独特数据结构。模块传递给内核通用参数,从内核获取的也是通用参数,那么它如何通过通用参数来获得属于它的特殊数据呢?在模块内定义全局变量是一个方法,它也不依赖内核的通用参数,除非逻辑需要,全局变量一般并不是首选,下面我们将介绍两种优选方案。
内嵌通用数据结构
inode是一个典型的例子,内核使用inode对象,很多文件系统内部除了inode还需要其他特有信息,定义一个内嵌inode的特殊结构体就可以解决该问题,代码如下。
1 | struct my_inode{ |
传递参数给内核的时候,传递my_inode的inode的地址ptr;从内核获得的inode地址,通过container_of(ptr, my_inode, inode)宏就可以获得my_inode对象。
通用结构的私有变量
内核中很多数据结构都定义了类型为void*的私有数据字段,模块可以将它特有的数据赋值给该字段,通过引用该字段就可以获取它的数据。file结构体的private_data、device结构体的driver_data都是这种用法。
内嵌和私有变量方式该如何选择呢?内嵌和对象由模块负责创建;私有变量,为私有数据的字段赋值的时候,对象已经存在了。前者,对象归模块所有;后者,对象一般归内核所有。当然,有些情况下,模块也可以将两种方法一起使用,比如inode除了可以被内嵌外,它本身就有一个i_private字段。
模块的封装
内核中经常提起模块,在实现某一特定功能的时候,最好的做法是将它与其他部分独立开,形成一个单独的模块,有利于在未来以最小的改动扩展功能。这并不是说模块是封闭的,它一方面需要调用其他模块的函数,另一方面也需要提供函数供其他模块访问。在面向对象的编程中,这叫作封装,C语言并没有该概念,但封装的思想是一样的,我们在模块中要尽可能少地透漏实现细节,仅提供必要的函数供外部使用。这样在内部实现变化的时候,对其他模块影响更小,或者说在改变内部实现的时候,需要考虑的因素更少。同样,在使用其他模块的时候,不要违背其他模块的访问控制意图,虽然在我们试图这么做的时候编译器不会报错。
以inode结构体为例,它主要适用VFS和具体文件系统的实现两种场景。其他模块,比如一个设备驱动一般是不会直接访问它的,而是访问file结构体。从代码角度,通过file->f_inode就可以得到inode,是可行的,甚至在知道具体的文件系统时,可以通过inode获得内嵌它的那个文件系统内定义的xxx_inode。虽然这么做是错误的,但是方法起码是值得斟酌的。xxx_inode从文件系统的角度不需要为我们的模块负责,但强行“绑定”可能会导致更改xxx_inode变得困难。所以开发一个新模块,不仅要理清它自身的逻辑,还要理解已有模块数据结构的意图,不要逾越对它们的访问控制。
看破数据结构
要掌握一个模块,首先要理清模块内的数据结构,数据结构是灵魂,函数是表现。而复杂的模块往往数据结构也是复杂的,主要表现在定义的结构体数量多,而且它们之间的关系错综复杂。结构体间的关系中,类似指针这类单向引用关系容易理解,较难迅速理清的是间接关系,比如本章讨论的关系型数据结构。这些关系虽然表面上不明显,但还是有些技巧可以快速理清脉络的。
对一个结构体的某个字段,我们要关心字段类型和名字两方面,这句话看似多余却隐藏玄机。首先,链表或树类型结构,如果区分链表头和元素(树的根和叶),从类型即可区分结构体在链表或树中的地位。其次,字段类型在很大程度上体现了它的意图,这由类型本身的特性决定。链表一般用来遍历或者查找,红黑树一般用来查找。
最后,如果从类型上看不出门道,可以尝试从字段名入手,链表头的名字多为复数或者带有l(list)等字样。如果依然没有思路,可以借助于代码注释,虽然多数情况下会无功而返。
内核常用设计模式
看到“设计模式”四个字,熟悉面向对象编程语言的读者可能会有疑问,内核是用C语言编写的,为什么会提到涉及设计模式。实际上,内核是按照面向对象的思维设计的,设计模式与编程语言也并没有必然关系,C语言也完全可以按照面向对象的思路来编程。所谓设计模式,通俗理解就是解决特定类别问题时常用的套路。
模板方法设计模式
模板方法(Template Method)设计模式, 又被称为模板模式,顾名思义,就是有一个可以套用的 流程(模板),具体的实现只需要关心自身对流程中涉及的节点的细节即可。 以做菜为例,总共分为三个步骤:备菜、加工、 盛出,模板就是这三个固定的步骤,不同的工具会有不同的做法,如下图所示。
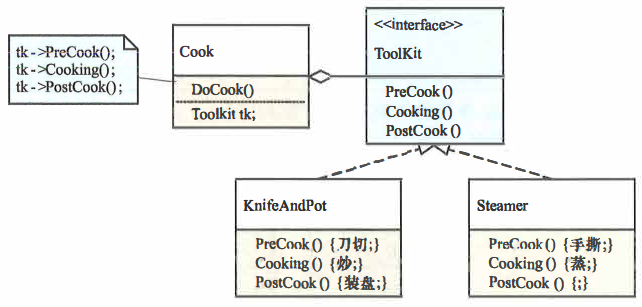
整个过程如下。
(1) 我们要做菜,也就是Cook类的DoCook,这个方法将做菜细化为三个步骤。
(2) Tool Kit表示不同的工具需要实现的操作(步骤)。
(3) 具体的方案只关心这几个操作如何实现。
这就像我们写一本做菜指南,第一部分阐述做菜的三步骤,第二部分针对不同的工具介绍在三个步骤中如何使用即可。做菜的人选择了工具之后,做菜的细节就定了。也许做菜这个例子显得不够灵活,那我们就看看内核中实际的例子。当我们在用户空间调用mmap()的时候,会调用文件的mmap(),如果文件的mmap()并没有分配物理内存,下次内存访问时触发缺页异常,可能会调用fault(),文件系统的开发人员不需要关心mmap() 和 fault() 的调用过程,只需要根据要求实现它们即可,类似的例子比比皆是。
观察者设计模式
订阅行为在我们的生活中随处可见,比如订阅报纸、杂志,以及订阅某些网站的文档等,以订阅报纸为例,过程如下。
- 个人读者或者中间代理(比如报刊亭)向报社申请订阅服务。
- 报社维护订阅列表。
- 新报印刷完毕,报社按照订阅列表派送报纸。
- 读者拿到报纸开始阅读,报刊亭拿到报纸开始售卖。
从程序设计角度来看,各个主体的关系如下图所示。
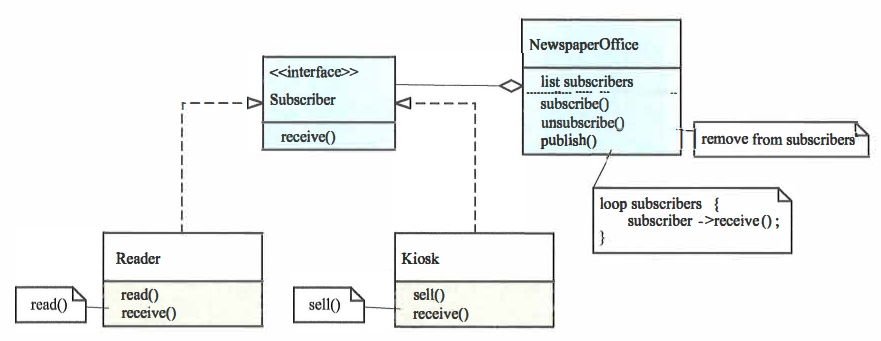
显而易见,观察者模式解耦了观察者和被观察者,被观察者不关心具体是谁在观察自己,它只知道一个列表,统一对待列表上每一个观察者,观察者也不需要一直询问被观察者的状态,如果没有订阅,你可能得经常或者定期去报刊亭了。观察者模式在内核中使用频率很高,我们在内核中看到类似xxx_listener 名字的函数多半都是观察者,类似xxx_notify名字的函数多半都是被观察者。
Linux的时间
们的作息、行为和活动都与时间息息相关,从人类的角度来看,时间是以时分秒来计算和衡量的。例如,某一时刻做某件事情或某个任务持续了多久等情况,我们基本都以时分秒来计算。但内核中却不是这样,从内核的角度,它的时间以滴答(jiffy)来计算。滴答,通俗地讲,是时间系统周期性地提醒内核某时间间隔已经过去的行为。另一方面,内核服务于用户,所以它还需要拥有将滴答转为时分秒的能力。因此,内核的任务就分为维护并响应滴答和告知用户时间两部分。
- Title: Linux-6-x内核分析
- Author: 韩乔落
- Created at : 2025-02-12 13:48:36
- Updated at : 2025-02-19 10:31:42
- Link: https://jelasin.github.io/2025/02/12/Linux-6-x内核分析/
- License: This work is licensed under CC BY-NC-SA 4.0.