
Linux环境编程与内核之进程间通信

概述
在Linux系统中,有时候需要多个进程相互协作,共同完成某项任务。进程之间或线程之间有时候需要传递消息,有时候需要同步来协调彼此的工作。接下来讲述Linux中的进程间通信(interprocess communication,或者IPC)。
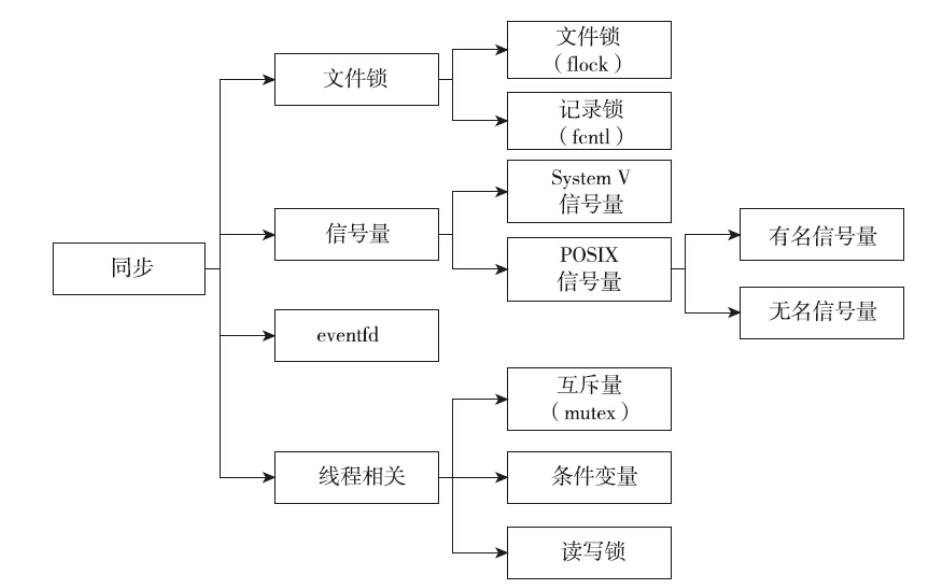
讲信号时曾提到,信号也是进程间通信的一种机制,尽管其主要作用不是这个。一个进程向另外一个进程发送信号,传递的信息是信号编号。当采用sigqueue函数发送信号时,还可以在信号上绑定数据(整型数字或指针),增强传递消息的能力。尽管如此,还是不建议将信号作为进程间通信的常规手段,原因在信号那一篇中已经详细介绍过了。
讲线程时曾提到,线程在Linux中被实现为轻量级的进程,线程之间的同步手段(互斥量和条件等待),本质上也是进程间通信。
进程间通信的手段,大体可以分成以下两类:
第一类是通信类。这类手段的作用是在进程之间传递消息,交换数据。若细分下来,通信类也可以分成两种,一种是用来传递消息的(比如消息队列),另外一种是通过共享一片内存区域来完成信息的交换的(比如共享内存)。
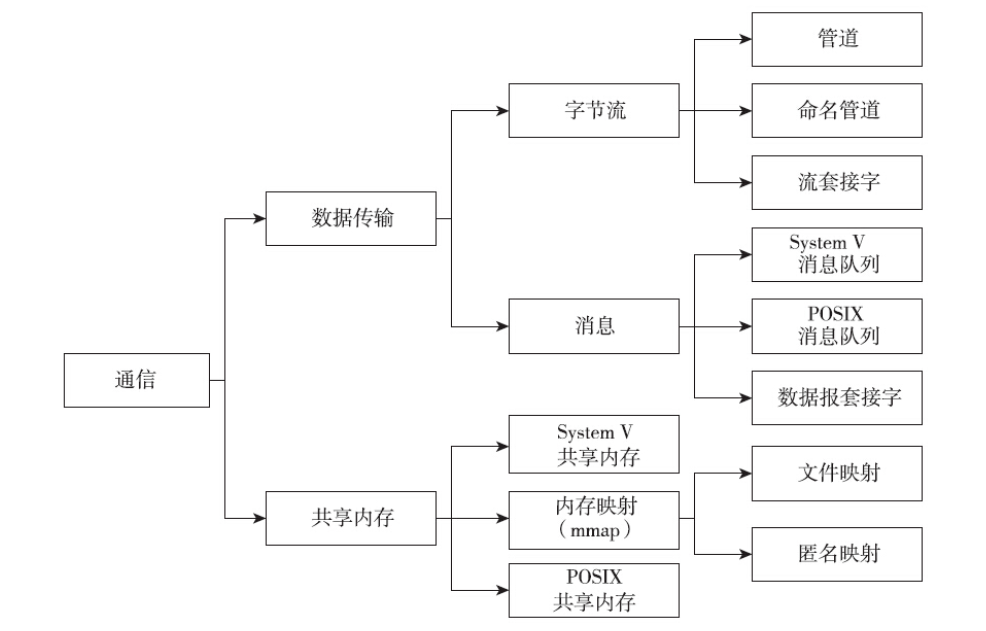
第二类是同步类。这类手段的目的是协调进程间的操作。某些操作,多个进程不能同时执行,否则可能会产生错误的结果,这就需要同步类的工具来协调。主要的同步类手段。
接下来AT&T的贝尔实验室和加州大学伯克利分校的伯克利软件发布中心(BSD)分别开发出了风格迥异的进程间通信手段。前者通过对早期的进程间通信手段的改进和扩充,开发出System V IPC,包括消息队列、信号量和共享内存。但是这些方法,将进程间的通信始终局限在单个计算机这个范围之内。BSD则走了一条完全不同的道路,开发出了套接字(socket),跳出了单机的限制,可以实现不同计算机之间的进程间通信。Linux将System V IPC和BSD socket都继承了下来,丰富了进程间通信的方法。
System V IPC方法出现地比较早,几乎所有的Unix平台都支持System V IPC,其可移植性较好,但是在使用过程中也暴露出一些弱点。POSIX IPC提供了和System V IPC相对应的工具(它也包括消息队列、信号量和共享内存),它的出现晚于System V IPC。System V IPC广泛应用了一段时间后,才开始设计POSIX IPC的,因此,设计者可以借鉴System V IPC的长处,避免其缺点。从设计的角度上讲,POSIX IPC是优于System V IPC的,接口简单,易于使用。但是POSIX IPC的可移植性并不如System V IPC。
下面将分别介绍进程间通信的工具。其中的套接字在后面会有专门的章节来介绍,就不在进程间通信部分提及了。
管道
管道是最早出现的进程间通信的手段。在shell中执行命令,经常会将上一个命令的输出作为下一个命令的输入,由多个命令配合完成一件事情。而这就是通过管道来实现的。
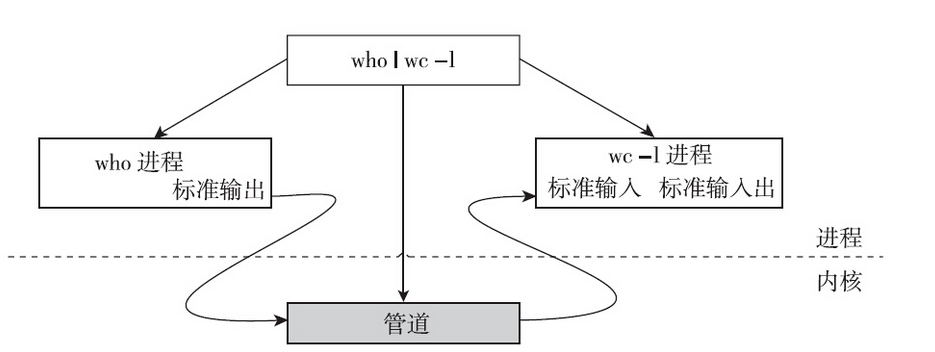
管道的作用是在有亲缘关系的进程之间传递消息。所谓有亲缘关系,是指有一个共同的祖先。所以管道并非只能用于父子进程之间,也可以用在兄弟进程之间,还可以用于祖孙进程之间甚至是叔侄进程之间。总而言之,只要共同的祖先曾经调用了pipe函数,打开的管道文件就会在fork之后,被各个后代进程所共享。打开的管道文件,就像是创建了一个家族私密场所,由远祖进程来创建,家族所有成员都知晓。家族成员可以将消息存放进该私密场所,等待另外一个接头的家族成员来取走消息,阅后即焚。
严格来说,家族里面的多个进程都可以往同一个秘密场所里面扔消息,也可以都从同一个秘密场所里面取消息,但是真的这么做的话又会存在风险。管道实质是一个字节流,并非前面提到的消息,没有消息的边界。如果多个进程发送的字节流混在一起,则无法辨认出各自的内容。所以一般是两个有亲缘关系的进程用管道来通信。从程序设计的角度来讲,当进程调用pipe函数时,哪两个有亲缘关系的进程使用该管道来通信应是事先约定好的,其他有亲缘关系的进程不应该进来搅局。其他进程想通信怎么办?那就创建它们之间需要用的另外的管道。
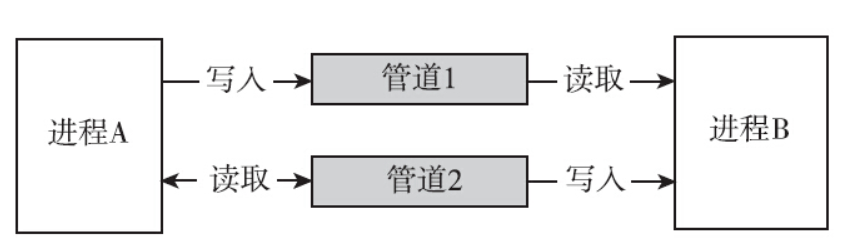
前面曾提到过,管道中的内容是阅后即焚的,这个特性指的是读取管道内容是消耗型的行为,即一个进程读取了管道内的一些内容之后,这些内容就不会继续在管道之中了。一般来讲管道是单向的。一个进程负责往管道里面写内容,另外一个进程读取管道里的内容。若两个有亲缘关系的进程都要往管道里面写,都要往管道里面读,自然也是可以的,但是管道中的内容可能会变得混乱,从而无法完成通信的任务。如果两个进程之间想双向通信怎么办?可以建立两个管道。
管道是一种文件,可以调用read、write和close等操作文件的接口来操作管道。另一方面管道又不是一种普通的文件,它属于一种独特的文件系统:pipefs。管道的本质是内核维护了一块缓冲区与管道文件相关联,对管道文件的操作,被内核转换成对这块缓冲区内存的操作。下面我们来看一下如何使用管道。
管道接口
在Linux下,可以使用如下接口创建管道:
1 |
|
如果成功,则返回值是0,如果失败,则返回值是-1,并且设置errno。需要处理的errno如表:

成功调用pipe函数之后,会返回两个打开的文件描述符,一个是管道的读取端描述符pipefd[0],另一个是管道的写入端描述符pipefd[1]。管道没有文件名与之关联,因此程序没有选择,只能通过文件描述符来访问管道,只有那些能看到这两个文件描述符的进程才能够使用管道。那么谁能看到进程打开的文件描述符呢?只有该进程及该进程的子孙进程才能看到。这就限制了管道的使用范围。成功调用pipe函数之后,可以对写入端描述符pipefd[1]调用write,向管道里面写入数据,代码如下所示:
1 | write(pipefd[1],wbuf,count); |
一旦向管道的写入端写入数据后,就可以对读取端描述符pipefd[0]调用read,读出管道里面的内容。如下所示,管道上的read调用返回的字节数等于请求字节数和管道中当前存在的字节数的最小值。如果当前管道为空,那么read调用会阻塞(如果没有设置O_NONBLOCK标志位的话)。
管道一端是写入端(pipefd[1]),另一端是读取端(pipefd[0])。不应该对读取端描述符调用写操作,也不应该对写入端描述符调用读操作。如果我非要向读取端描述符写入,或者读取写入端描述符,结果会怎么样?
调用pipe函数返回的两个文件描述符中,读取端pipefd[0]支持的文件操作定义在read_pipefifo_fops,写入端pipefd[1]支持的文件操作定义在write_pipefifo_fops,其定义如下:
1 | const struct file_operations read_pipefifo_fops = { |
我们可以看到,对读取端描述符执行write操作,内核就会执行bad_pipe_w函数;对写入端描述符执行read操作,内核就会执行bad_pipe_r函数。这两个函数比较简单,都是直接返回-EBADF。因此对应的read和write调用都会失败,返回-1,并置errno为EBADF。
1 | static ssize_t |
我们只介绍了pipe函数接口,至今尚看不出来该如何使用pipe函数进行进程间通信。调用pipe之后,进程发生了什么呢?
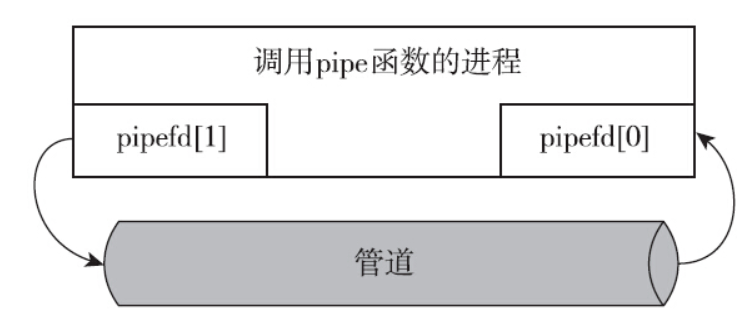
可以看到,调用pipe函数之后,系统给进程分配了两个文件描述符,即pipe函数返回的两个描述符。该进程既可以往写入端描述符写入信息,也可以从读取端描述符读出信息。可是一个进程管道,起不到任何通信的作用。这不是通信,而是自言自语。
如果调用pipe函数的进程随后调用fork函数,创建了子进程,情况就不一样了。fork以后,子进程复制了父进程打开的文件描述符。
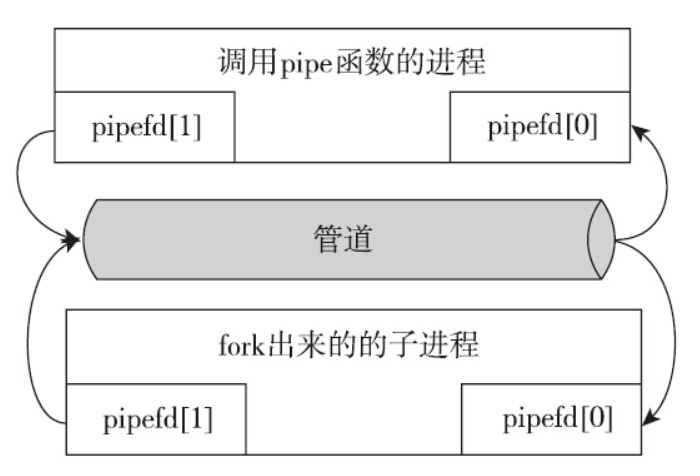
两条通信的通道就建立起来了。此时,可以是父进程往管道里写,子进程从管道里面读;也可以是子进程往管道里写,父进程从管道里面读。这两条通路都是可选的,但是不能都选。原因前面介绍过,管道里面是字节流,父子进程都写、都读,就会导致内容混在一起,对于读管道的一方,解析起来就比较困难。常规的使用方法是父子进程一方只能写入,另一方只能读出,管道变成一个单向的通道,以方便使用。父进程放弃读,子进程放弃写,变成父进程写入,子进程读出,成为一个通信的通道。

父进程如何放弃读,子进程又如何放弃写?其实很简单,父进程把读端口pipefd[0]这个文件描述符关闭掉,子进程把写端口pipefd[1]这个文件描述符关闭掉就可以了,示例代码如下:
1 | int pipefd[2]; |
从内核的角度看,调用pipe之后,系统给进程分配了两个文件描述符,调用fork之后,子进程也就有了与管道对应的两个文件描述符。和普通文件不同,这两个文件描述符对应的是一块内存缓冲区域。
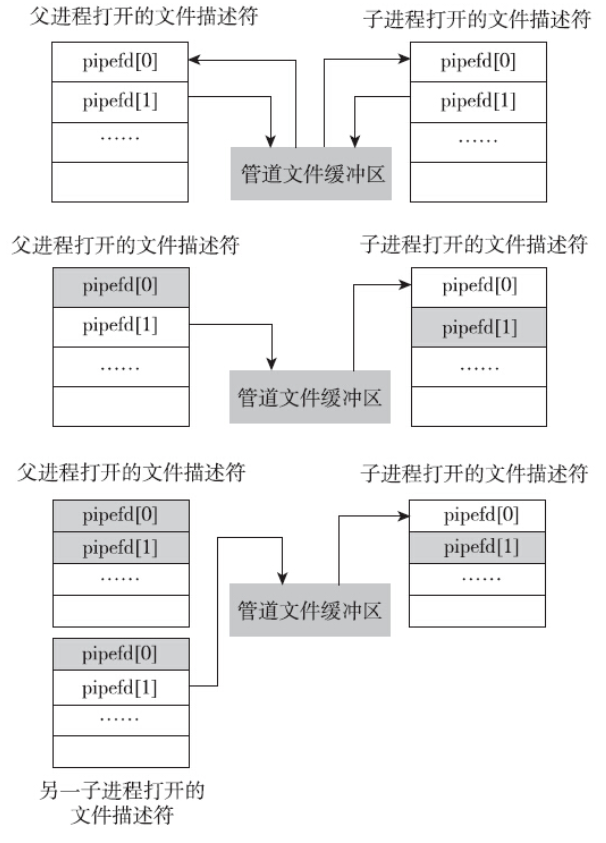
父进程再次创建一个子进程B,子进程B就持有管道写入端,这时候两个子进程之间就可以通过管道通信了。父进程为了不干扰两个子进程通信,很自觉地关闭了自己的写入端。从此管道成为了两个子进程之间的单向的通信通道。在shell中执行管道命令就是这种情景,只是略有特殊之处,其特殊的地方是管道描述符占用了标准输入和标准输出两个文件描述符。
任何两个有亲缘关系的进程,只要共同的祖先打开了一个管道,总能够通过关闭不相关进程的某些管道文件描述符,来建立起两者之间单向通信的管道。
*关闭未使用的管道文件描述符
前面提到过,用管道通信的两个进程,各持有一个管道文件描述符,不相干的进程应自觉关闭掉这些文件描述符。这么做不仅仅是为了让数据的流向更加清晰,也不仅仅是为了节省文件描述符,更重要的原因是:关闭未使用的管道文件描述符对管道的正确使用影响重大。
管道有如下三条性质:
- 只有当所有的写入端描述符都已关闭,且管道中的数据都被读出,对读取端描述符调用read函数才会返回0(即读到EOF标志)。
- 如果所有读取端描述符都已关闭,此时进程再次往管道里面写入数据,写操作会失败,errno被设置为EPIPE,同时内核会向写入进程发送一个SIGPIPE的信号。
- 当所有的读取端和写入端都关闭后,管道才能被销毁。
由于管道具有这些特性,因此我们要及时关闭没用的管道文件描述符,下面我们来细细分析这样做的原因。
关闭无用的管道写入端
从管道读取数据的进程,须要关闭其持有的管道写入端描述符。不参与通信的其他有亲缘关系的进程也应该关闭管道写入端描述符。管道也符合生产者-消费者模型。写入管道,对应于生产内容;读取管道,对应于消费内容。当所有的生产者都退场以后,消费者应有办法判断这种情况,而不是傻傻地等待已不复存在的生产者继续生产内容,以至于陷入永久的阻塞。
如何判断?答案是通过文件结束标志EOF。当对管道读取端调用read函数返回0时,就意味着所有的生产者都退场了,作为消费者的读取进程,就不需要再继续等待新的内容了。什么情况下对管道读取端描述符调用read会返回0呢?
- 所有相关的进程都已经关闭了管道的写入端描述符。
- 管道的中已有内容都被读取完毕。
同时满足上述条件,对管道读取端调用read会返回0。根据这个消费者就可以判断管道内容的生产者已经不存在了,它也不必傻傻等待,可以关闭读取端描述符了。
从上面的讨论可以看出,如果负责读取的进程,或者与通信无关的进程,不关闭管道的写入端描述符,就会有管道写入端描述符泄漏。当所有负责写入的进程都关闭了写入端描述符后,负责读的进程调用read时,仍会阻塞于此(如果没有设置O_NONBLOCK标志位的话),而且永不返回。这是因为内核维护的引用计数发现还有进程可以写入管道,因此read函数依旧会阻塞。
1 |
|
在上面的例子中,父子进程通过管道进行通信,父进程关闭了管道的读取端,子进程关闭了管道的写入端。父进程写入了1024字节,子进程则在循环体中调用read,每次尝试读取1000字节。子进程很快就读完了父进程生产的1024字节。但是父进程并没有立刻关闭管道的写入端,而是睡眠了15秒后,才关闭管道写入端。从子进程读完父进程生产的1024字节开始,到父进程关闭管道写入端这段接近15秒的时间内,子进程实际上是阻塞在read函数上的。当父进程关闭管道写入端,子进程调用的read函数才得以返回,返回值是0。子进程看到返回值0后,意识到硕果仅存的管道写入端也不复存在了,所以它没必要再继续read了,于是子进程就跳出了循环体。
1 | [PARENT] the bytes write to pipe is 1024 |
父子进程配合地珠联璧合,但是如果子进程忘记关闭管道的写入端,(删除上面示例代码中加粗的一行)结局就大相径庭了。纵然父进程关闭了管道的写入端,但是因为管道仍然存在一个写入端,所以子进程的read函数依旧会阻塞,无法返回。这显然不是我们期待的结果。
关闭无用的管道读取端
如果对管道的写入端描述符调用write函数,则会走到内核的pipe_write函数。在该函数中可以看到如下代码:
1 | if (!pipe->readers) { |
当管道的读取端不复存在时,内核会向write函数的调用进程发送SIGPIPE信号,并且当前的write系统调用失败,错误码为EPIPE。SIGPIPE信号默认情况下会杀死一个进程,当然我们也可以捕获或忽略该信号。事实上大多数情况下,服务器端的程序都会将SIGPIPE的信号处理函数设置成SIG_IGN,忽略掉该信号。这样的话,write系统调用就会返回失败,errno是EPIPE,通过返回值和errno,就可以及时获知所有的读取端都已关闭了。当所有的管道读取端都不复存在时,管道的写入操作就会失败。
为何要如此设计?因为管道的读取端是管道内容的消费者,管道的写入端是管道内容的生产者。当消费者已经不复存在了,生产者自然没有继续生产的必要了。
所以不参与通信的进程,以及负责向管道写入内容的进程应该及时地关闭管道的读取端描述符。只有这样,当通信双方中的消费者关闭管道读取端时,管道内容的生产者才能在第一时间获知所有消费者都已不存在了这个事实。如果写入管道的进程不关闭管道的读取文件描述符,哪怕其他进程都已经关闭了读取端,该进程仍可以向管道写入数据,但是只有生产者,没有消费者,管道最终会被写满,当管道被写满后,后续的写入请求就会被阻塞。
下面通过实例来证实:当最后一个读取端关闭时,向管道写入会触发SIGPIPE信号,同时write会返回失败,errno为EPIPE。
1 |
|
fork之后,父子进程都立刻关闭了读取端,这时候,管道已经不存在任何读取端了。1秒钟之后,父进程尝试向管道写入。此时按照前面的分析,父进程应该会收到SIGPIPE信号,write返回失败,并且errno为EPIPE。父进程为SIGPIPE安装了信号处理函数,如果收到SIGPIPE信号,会有打印提示。下面来看看程序的输出:
1 | [CHILD ] I will close the last read end of pipe |
通过上面的讨论可以看出,正常使用管道的场景,应该只有两个进程和管道关联,一个进程只拥有管道的写入端,另一个进程只拥有管道的读取端。
如何检验管道是否满足上面的情形?以如下情况为例:
1 | int pipefd[2] |
1 | manu@manu-rush:~$ ll /proc/2889/fd |
可以看出文件描述符3和4都是管道文件,其后面的相同数字13870表示它们属于同一个管道。文件描述符3对应的文件属性中有r,表示管道的读取端,文件描述符4对应的文件属性中有w表示4是管道的写入端。
还有哪些进程持有管道对应的文件描述符?
1 | manu@manu-rush:~$ lsof | grep FIFO | grep 13870 |
从上面的输出可以知晓,管道13870并不满足前面的讨论。在理想情况下,输出应该只有两行,一个进程只有管道的写入端,另一个进程只有管道的读取端。
管道对应的内存区大小
管道本质是一片内存区域,自然有大小。管道的默认大小是65536字节,可以调用fcntl来获取和修改这个值的大小,代码如下:
1 | pipe_capacity = fcntl(fd,?F_GETPIPE_SZ); // 获取管道的大小 |
管道内存区域的大小必须在页面大小(PAGE)和上限值之间,其上限记录在/proc/sys/fs/pipe-max-size里,对于特权用户,还可以修改该上限值。
1 | cat /proc/sys/fs/pipe-max-size |
管道的容量可以扩大,自然也可以缩小。缩小管道容量时会遇到一种比较有意思的场景,即当前管道中已存在的内容大于fcntl函数调用中指定的size,此时fcntl函数会返回失败,并置错误码为EBUSY。
管道容量有大小这个事实对于编程有什么影响呢?在使用管道的过程中要意识到:管道有大小,写入须谨慎,不能连续地写入大量的内容,一旦管道满了,写入就会被阻塞;对于读取端,要及时地读取,防止管道被写满,造成写入阻塞。
shell管道的实现
shell编程会大量使用管道,我们经常看到前一个命令的标准输出作为后一个命令的标准输入,来协作完成任务。管道是如何做到的呢?兄弟进程可以通过管道来传递消息,这并不稀奇,前面已经图示了做法。关键是如何使得一个程序的标准输出被重定向到管道中,而另一个程序的标准输入从管道中读取呢?

答案就是复制文件描述符。对于第一个子进程,执行dup2之后,标准输出对应的文件描述符1,也成为了管道的写入端。这时候,管道就有了两个写入端,按照前面的建议,需要关闭不相干的写入端,使读取端可以顺利地读到EOF,所以应将刚开始分配的管道写入端的文件描述符pipefd[1]关闭掉。
1 | if(pipefd[1] != STDOUT_FILENO) |
同样的道理,对于第二个子进程,如法炮制:
1 | if(pipefd[0] != STDIN_FILENO) |
简单来说,就是第一个子进程的标准输出被绑定到了管道的写入端,于是第一个命令的输出,写入了管道,而第二个子进程管道将其标准输入绑定到管道的读取端,只要管道里面有了内容,这些内容就成了标准输入。两个示例代码,为什么要判断管道的文件描述符是否等于标准输入和标准输出呢?原因是,在调用pipe时,进程很可能已经关闭了标准输入和标准输出,调用pipe函数时,内核会分配最小的文件描述符,所以pipe的文件描述符可能等于0或1。在这种情况下,如果没有if判断加以保护,代码就变成了:
1 | dup2(1,1); |
这样的话,第一行代码什么也没做,第二行代码就把管道的写入端给关闭了,于是便无法传递信息了。
与shell命令进行通信(popen)
管道的一个重要作用是和外部命令进行通信。在日常编程中,经常会需要调用一个外部命令,并且要获取命令的输出。而有些时候,需要给外部命令提供一些内容,让外部命令处理这些输入。Linux提供了popen接口来帮助程序员做这些事情。
就像system函数,即使没有system函数,我们通过fork、exec及wait家族函数一样也可以实现system的功能。但终归是不方便,system函数为我们提供了一些便利。同样的道理,只用pipe函数及dup2等函数,也能完成popen要完成的工作,但popen接口给我们提供了便利。popen接口定义如下:
1 |
|
popen函数会创建一个管道,并且创建一个子进程来执行shell,shell会创建一个子进程来执行command。根据type值的不同,分成以下两种情况。
- 如果type是r:
command执行的标准输出,就会写入管道,从而被调用popen的进程读到。通过对popen返回的FILE类型指针执行read或fgets等操作,就可以读取到command的标准输出。
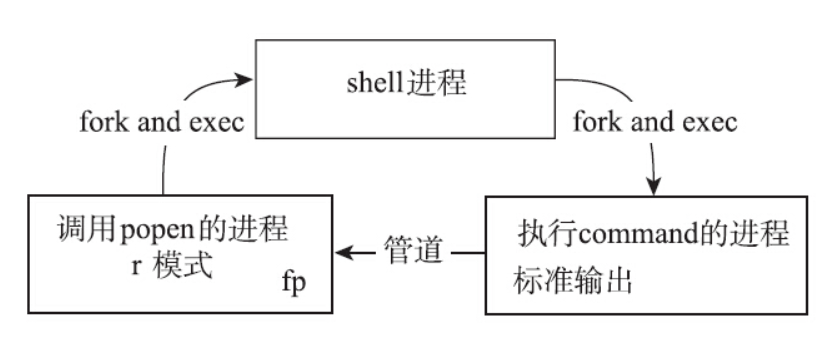
- 如果type是w:调用popen的进程,可以通过对FILE类型的指针
fp执行write、fputs等操作,负责往管道里面写入,写入的内容经过管道传给执行command的进程,作为命令的输入。
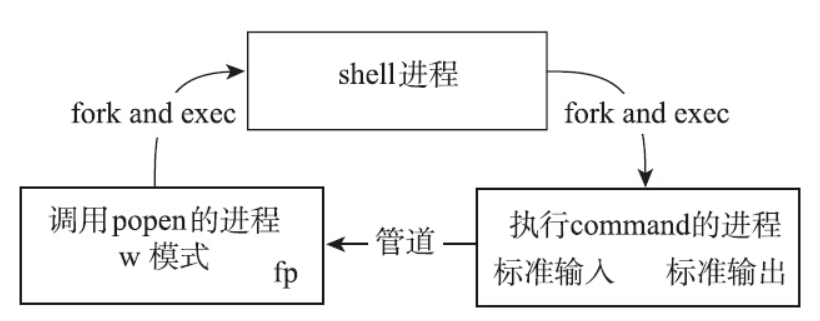
popen函数成功时,会返回stdio库封装的FILE类型的指针,失败时会返回NULL,并且设置errno。常见的失败有fork失败,pipe失败,或者分配内存失败。
I/O结束了以后,可以调用pclose函数来关闭管道,并且等待子进程的退出。尽管popen函数返回的是FILE类型的指针,也不应调用fclose函数来关闭popen函数打开的文件流指针,因为fclose不会等待子进程的退出。pclose函数成功时会返回子进程中shell的终止状态。popen函数和system函数类似,如果command对应的命令无法执行,就如同执行了exit(127)一样。如果发生其他错误,pclose函数则返回-1。可以从errno中获取到失败的原因。
1 |
|
将文件名作为参数传递给程序,执行cat filename的命令。popen创建子进程来负责执行cat filename的命令,子进程的标准输出通过管道传给父进程,父进程可以通过fgets来读取command的标准输出。popen函数和system有很多相似的地方,但是也有显著的不同。调用system函数时,shell命令的执行被封装在了函数内部,所以若system函数不返回,调用system的进程就不再继续执行。但是popen函数不同,一旦调用popen函数,调用进程和执行command的进程便处于并行状态。然后pclose函数才会关闭管道,等待执行command的进程退出。换句话说,在popen之后,pclose之前,调用popen的进程和执行command的进程是并行的,这种差异带来了两种显著的不同:
- 在并行期间,调用popen的进程可能会创建其他子进程,所以标准规定popen不能阻塞
SIGCHLD信号。这也意味着,popen创建的子进程可能被提前执行的等待操作所捕获。若发生这种情况,调用pclose函数时,已经无法等待command子进程的退出,这种情况下,将返回-1,并且errno为ECHILD。 - 调用进程和command子进程是并行的,所以标准要求popen不能忽略
SIGINT和SIGQUIT信号。如果是从键盘产生的上述信号,那么,调用进程和command子进程都会收到信号。
命名管道FIFO
前面介绍的管道也被称为无名管道,这种管道因为没有实体文件与之关联,靠的是世代相传的文件描述符,所以只能应用在有共同祖先的各个进程之间。对于没有亲缘关系的任意两个进程之间,无名管道就爱莫能助了。命名管道就是为了解决无名管道的这个问题而引入的。FIFO与管道类似,最大的差别就是有实体文件与之关联。由于存在实体文件,不相关的没有亲缘关系的进程也可以通过使用FIFO来实现进程之间的通信。与无名管道相比,命名管道仅仅是披了一件马甲,其核心与无名管道是一模一样的。内核的fs/fifo.c文件仅有153行,说白了,这简短的代码只干了两件事:
- 从外表看,我是一个FIFO文件,有文件名,任何进程通过文件名都可以打开我。
- 我的内心与无名管道是一样的,支持的文件操作与无名管道也是一样的。
创建FIFO文件
创建命名管道的接口定义如下:
1 |
|
其中,第二个参数的含义是FIFO文件的读写执行权利,和open函数类似。当然真实的读写执行权限,还需要按照当前进程的umask来取掩码,即:
1 | real_mode = (mode & ~umask) |
除了用C接口,还可以用命令来创建一个命名管道:
1 | mkfifo [-m mode] pathname |
pathname是创建命名管道文件的文件名,-m mode的使用方法和chmod的方法一样。
除此外,mknod命令也可以用来创建FIFO文件,使用方法如下:
1 | mknod [-m mode] pathname p |
命令末尾的p表示要创建命名管道(named pipe)。
创建出来的FIFO文件,用ls –l来查看,第一个字母是p,表示这是命名管道文件。
1 | prw-rw-r-- 1 manu manu 0 2月 19 23:03 myfifo2 |
在shell编程中可以使用-p file来判断是否为FIFO文件。在C语言中如何判断是否为FIFO文件呢?通过S_ISFIFO宏可以判断,不过要先通过stat或fstat函数来获取到文件的属性信息,如下面的代码所示:
1 |
|
打开FIFO文件
一旦FIFO文件创建好了,就可以把它用于进程间的通信了。一般的文件操作函数如open、read、write、close、unlink等都可以用在FIFO文件上。FIFO文件和普通文件相比,有一个明显的不同:程序不应该以O_RDWR模式打开FIFO文件。POSIX标准规定,以O_RDWR模式打开FIFO文件,结果是未定义的。当然了,Linux提供了对O_RDWR的支持,在某些场景下,O_RDWR模式的打开是有价值的。
对FIFO文件推荐的使用方法是,两个进程一个以只读模式(O_RDONLY)打开FIFO文件,另一个以只写模式(O_WRONLY)打开FIFO文件。这样负责写入的进程写入FIFO的内容就可以被负责读取的进程读到,从而达到通信的目的。
打开一个FIFO文件和打开普通文件相比,又有不同。在没有进程以写模式(O_RDWR或O_WRONLY)打开FIFO文件的情况下,以O_RDONLY模式打开一个FIFO文件时,调用进程会陷入阻塞,直到另一进程以O_WRONY(或者O_RDWR)的标志位打开该FIFO文件为止。同样的道理,在没有进程以读模式(O_RDONLY或O_RDWR)打开FIFO文件的情况下,如果一个进程以O_WRONLY的标志位打开一个FIFO文件,调用进程也会阻塞,直到另一个进程以O_RDONLY(或者O_RDWR)的标志位打开该FIFO文件为止。也就是说,打开FIFO文件会同步读取进程和写入进程。
乍看之下,O_RDONLY模式打开不能返回,在等写打开,同样O_WRONLY打开不能返回,在等读打开,造成死锁,谁都返回不了。事实上不是这样的。当O_RDONLY打开和O_WRONLY打开的请求都到达FIFO文件时,两者就都能返回了。内核之中,维护有引用计数r_counter和w_counter,分别记录FIFO文件两种打开模式的引用计数。对于FIFO文件,无论是读打开还是写打开,都会根据引用计数判断对方是否存在,进而决定后续的行为(是阻塞、返回成功,还是返回失败)。
FIFO文件提供了O_NONBLOCK标志位,该标志位会显著影响open的行为模式。将O_RDONLY、O_WRONLY及O_NONBLOCK三种标志位结合在一起考虑,共有以下四种组合方式,如表:
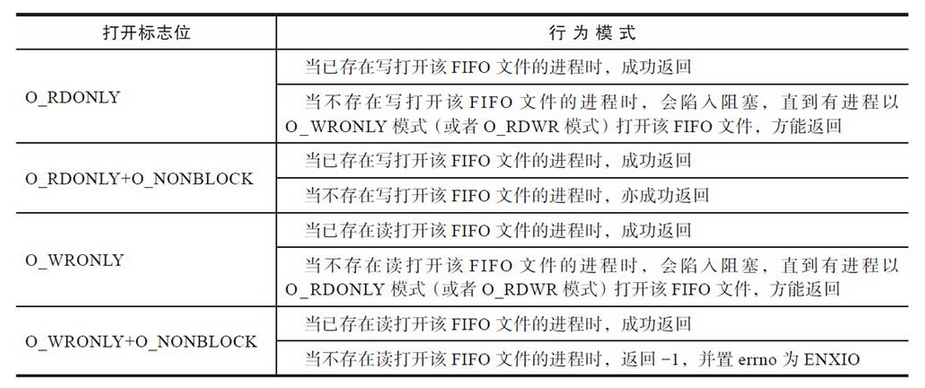
同样是带O_NONBLOCK标志位的打开,没有写打开进程时,读打开请求可以成功返回,但没有读打开进程时,写打开请求却失败,返回-1,并置errno为ENXIO,两相比较,是否太不公平了?这样设计是有原因的:FIFO只有读取端,没有写入端,并无显著的危害,所有尝试从FIFO中读取数据的操作都不会返回任何数据。反之则不然。如果允许只存在写入端,不存在读取端,那么open之后,所有向FIFO文件的写入操作,都会导致SIGPIPE信号的产生,以及write调用返回EPIPE的错误,所以在源头上堵住(即让open函数返回失败)反倒更加合理。打开FIFO文件的内核代码位于内核的fs/fifo.c文件中,代码简短,非常易懂。读者可以通过阅读源代码,加深对打开FIFO文件的理解。
读写管道文件
无名管道pipe和命名管道FIFO在内核实现部分有很大的重叠,都属于管道文件系统(pipefs)。无名管道,分裂成了读取文件描述符和写入文件描述符。而命名管道则将两个描述符合二为一,如果是读打开,就如同获取到了无名管道的读取文件描述符;如果是写打开,就如同获取到了无名管道的写入文件描述符。这种本质上的一致,造成FIFO的读写控制和无名管道的读写控制是一模一样的,因此在本节一并介绍。
影响管道或FIFO文件读写行为的因素有:
- 当前管道中存在的字节数p。
- 是否有O_NONBLOCK标志位。
- 管道的最大容量PIPE_BUF和要读写的字节数n的关系。
- 读写端是否都存在。管道文件的读写中一个很重要的标志位是O_NONBLOCK,该标志位会影响读写的行为模式。
对于无名管道,Linux提供了特有的pipe2函数,该函数的接口如下:
1 |
|
可选的flag就有O_NONBLOCK。对于命名管道FIFO,打开文件时,可以带上O_NONBLOCK标志位来控制读写的行为(当然了,对于FIFO文件,O_NONBLOCK也会影响打开的行为)。
如果打开时,忘记带上O_NONBLOCK标志位,那该如何补救呢?答案是用fcntl这把文件控制的瑞士军刀。
通过如下代码,可以给管道文件加上O_NONBLOCK标志位:
1 | int flags = fcntl(fd,F_GETFL); |
相反的,如果打开时,带有O_NONBLOCK标志位,而后面又想取消该标志位,又该怎么做?
1 | int flags = fcntl(fd,F_GETFL); |
花开两朵,各表一枝。先来说说从FIFO或管道读取端读。
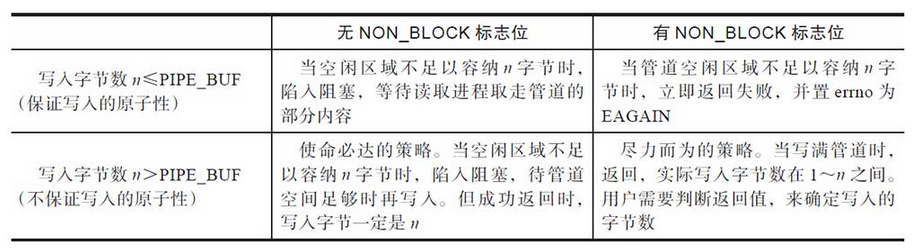
从一个包含p字节的管道或FIFO读取n字节的含义:

- O_NONBLOCK标志位影响的仅仅是当管道为空并且存在写入端时的行为,读取操作的行为是阻塞,还是当即返回失败。
- 当read返回0时,表示已经遇到了EOF,并且所有的写入端都已经关闭了。这一般出现在管道的使命结束时,此时读取端也可以关闭了。
对于管道的写入而言,POSIX标准规定,如果一次写入的数据量不超过PIPE_BUF个字节,必须确保写入是原子的(atomic)。所谓原子是指:写入的内容必须确保是连续的,纵然有多个进程同时往管道中写入,写入的内容也不会被其他进程写入的内容打断,本次写入的内容不会混杂其他进程write函数写入的内容。标准规定,PIPE_BUF最少为512字节,对于Linux而言,这个值是4096,一个页面的大小。
关于单次写入的长度超出PIPE_BUF,内核不能保证其原子性这个事实,我们可以通过一个简单的实验来验证,示例代码如下:
1 |
|
当写入内容长度不超过PIPE_BUF时,内核确保写入操作是原子的这条性质非常重要,尤其是在有多个进程向管道写入的情况下。在不采取其他同步手段的情况下,消息体小于PIPE_BUF时,写入管道是安全的,即使多个进程一起写入也没关系,内核会保证写入内容不会和其他进程的写入内容混在一起。但是如果消息体太大,长度超过了PIPE_BUF,就要警惕,需要采取必要的同步措施,来确保消息内容不会混杂其他进程的消息,否则会导致无法正确解析消息的内容。
System V IPC
下面三种类型的进程间通信方法统称为System V IPC:
- System V消息队列
- System V信号量
- System V共享内存
这三种IPC机制的差别很大,之所以将它们放在一起讨论,一个重要的原因是这三种机制是一同被开发出来的。它们最早出现在20世纪70年代末,1983年三者出现在主流的System V Unix系统上,因此这三种机制被统称为System V IPC。
System V IPC相关的接口如表:
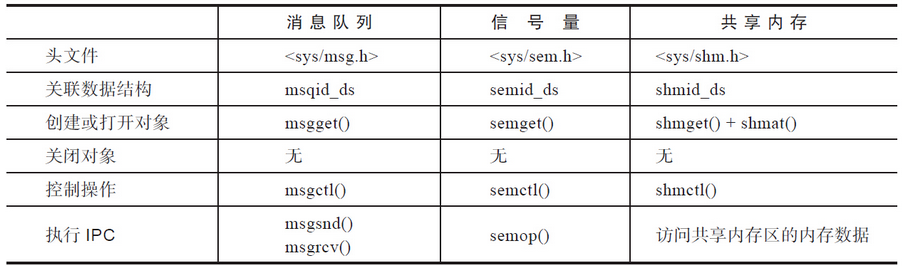
从作用上看,三种通信机制各不相同,但是从设计和实现的角度来看,还是有很多风格一致的地方。
System V IPC未遵循“一切都是文件”的Unix哲学,而是采用标识符ID和键值来标识一个System V IPC对象。每种System V IPC都有一个相关的get调用,该函数返回一个整型标识符ID,System V IPC后续的函数操作都要作用在该标识符ID上。
System V IPC对象的作用范围是整个操作系统,内核没有维护引用计数。调用各种get函数返回的ID是操作系统范围内的标识符,对于任何进程,无论是否存在亲缘关系,只要有相应的权限,都可以通过操作System V IPC对象来达到通信的目的。
System V IPC对象具有内核持久性。哪怕创建System V IPC对象的进程已经退出,哪怕有一段时间没有任何进程打开该IPC对象,只要不执行删除操作或系统重启,后面启动的进程依然可以使用之前创建的System V IPC对象来通信。
此外,我们也无法像操作文件一样来操作System V IPC对象。System V IPC对象在文件系统中没有实体文件与之关联。我们不能用文件相关的操作函数来访问它或修改它的属性。所以不得不提供专门的系统调用(如msgctl、semop等)来操作这些对象。在shell中无法用ls查看存在的IPC对象,无法用rm将其删除,也无法用chmod来修改它们的访问权限。幸好Linux提供了ipcs、ipcrm和ipcmk等命令来操作这些对象。
由于System V IPC对象不是文件描述符,所以无法使用基于文件描述符的多路转接I/O技术(select、poll和epoll等)。这个缺点会给编程带来一些不便之处。
System V IPC对象是靠标识符ID来识别和操作的。该标识符要具有系统唯一性。这和文件描述符不同,文件描述符是进程内有效的。一个进程的文件描述符4和另一个进程的文件描述符4可能毫不相干。但是IPC的标识符ID是操作系统的全局变量,只要知道该值(哪怕是猜测获得的)且有相应的权限,任何进程都可以通过标识符进行进程间通信。
三种IPC对象操作的起点都是调用相应的get函数来获取标识符ID,如消息队列的get函数为:
1 | int msgget(key_t key, int msgflg); |
其中第一个参数是key_t类型,它其实是一个整型的变量。IPC的get函数将key转换成相应的IPC标识符。根据IPC get函数中的第二个参数oflag的不同,会有不同的控制逻辑。

因为key可以产生IPC标识符,所以很容易产生一种误解,就是同一个key调用IPC的get函数总是返回同一个整型值。实际上并非如此。在IPC对象的生命周期中,key到标识符ID的映射是稳定不变的,即同一个key调用get函数,总是返回相同的标识符ID。但是一旦key对应的IPC对象被删除或系统重启后,则重新使用key创建的新的IPC对象被分配的标识符很可能是不同的。
不同进程可通过同一个key获取标识符ID,进而操作同一个System V IPC对象。那么现在问题就演变成了如何选择key。对于key的选择,存在以下三种方法。
- 第一种方法是随机选择一个整数值作为key值。作为key值的整数通常被放在一个头文件中,所有使用该IPC对象的程序都要包含该头文件。需要注意的是,要防止无意中选择了重复的key值,从而导致不需要通信的进程之间意外通信,以致引发程序混乱。一个技巧是将项目要用到的所有key放入同一个头文件中,这样就可以方便地检查是否有重复的key值。
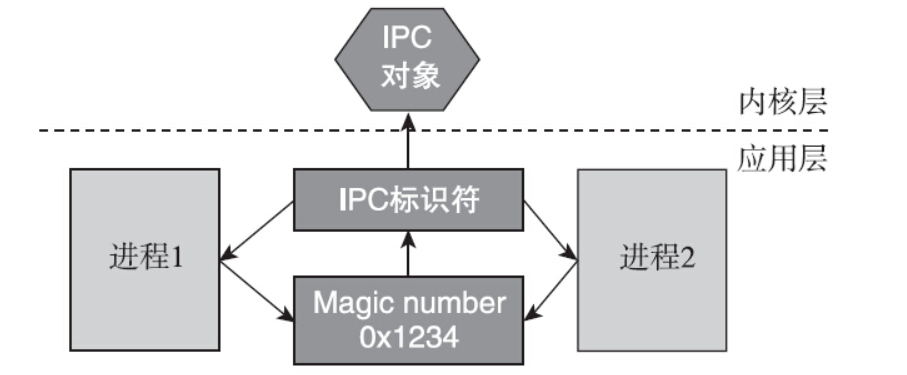
第二种方法是使用
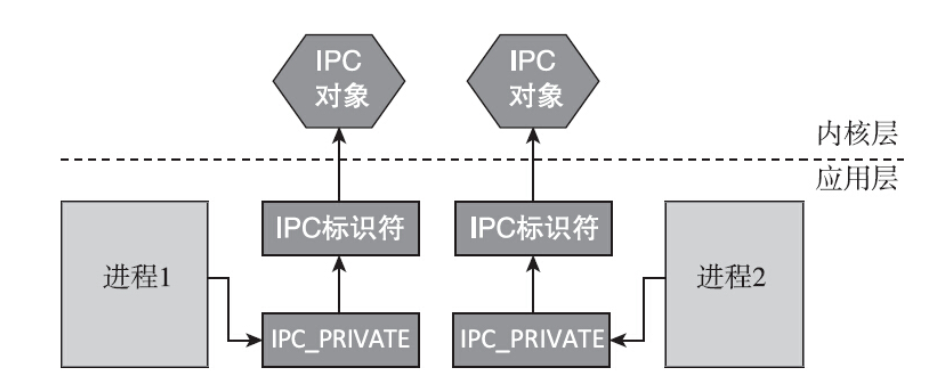
IPC_PRIVATE,使用方法如下:1
id = msgget(IPC_PRIVATE,S_IRUSR | S_IWUSR);
这种方法无须指定IPC_CREATE和IPC_EXCL标志位,就能创建一个新的IPC对象。使用IPC_PRIVATE时总是会创建新的IPC对象,从这个角度看将其称之为IPC_NEW或许更合理。不过,使用IPC_PRIVATE来得到IPC标识符会存在一个问题,即不相干的进程无法通过key值得到同一个IPC标识符。因为IPC_PRIVATE总是创建一个新的IPC对象。因此IPC_PRIVATE一般用于父子进程,父进程调用fork之前创建IPC对象,创建子进程后,子进程也就继承了IPC标识符,从而父子进程可以通信。当然无亲缘关系的进程也可以使用IPC_PRIVATE,只是稍微麻烦了一点,IPC对象的创建者必须想办法将IPC标识符共享出去,让其他进程有办法获取到,从而通过IPC标识符进行通信。
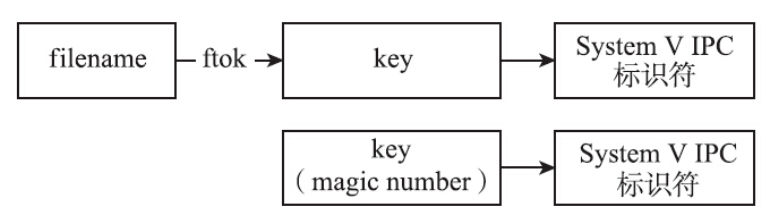
- 第三种方法是使用ftok函数,根据文件名生成一个key。ftok是file to key的意思,多个进程通过同一个路径名获得相同的key值,进而得到同一个IPC标识符。
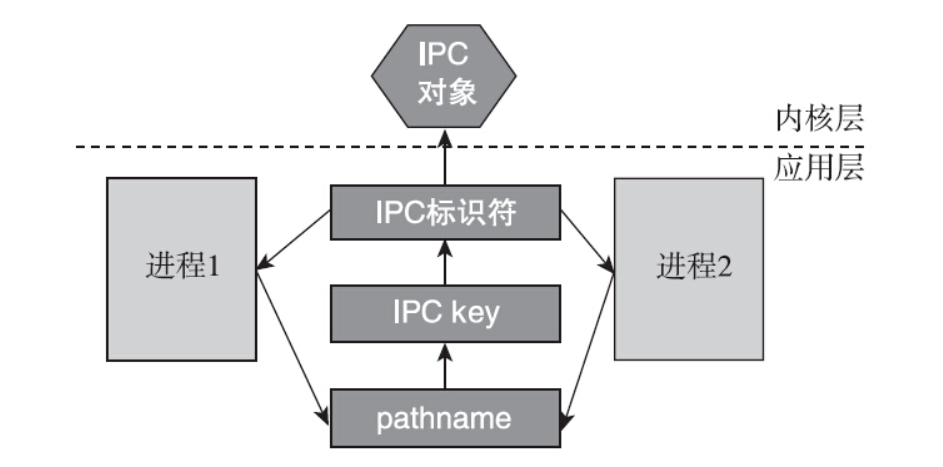
ftok函数接口的定义如下:
1 |
|
在Linux实现中,该接口把通过pathname获取的信息和传入的第二个参数的低8位糅合在一起,得到一个整型的IPC key值。需要注意的是,pathname对应的文件必须是存在的。这个函数在Linux上的实现是:按照给定的路径名,获取到文件的stat信息,从stat信息中取出st_dev和st_ino,然后结合给出的proj_id,按照下图所示的算法获取到32位的key值。

即使是ftok函数的第二个参数相同,也很难出现两个文件映射出同一个key值的情况。这里说的是很难,而不是绝对不会,因为这种情况是有可能发生的。这种冲突的出现需要同时满足下面三个条件:·两个文件所属文件系统所在磁盘的次设备号的低8位相同。·两个文件在各自的文件系统上的inode的最低16位也相同。·两个进程分别选择同一个proj_id来调用ftok()来获取key值。虽然理论上是存在key值冲突的可能,但是实际上,不同的文件通过ftok函数产生出冲突的key值的可能性太低,除非刻意构造这种冲突,否则很难出现。因此使用ftok函数来获取key值是编程中常用的方法。
三种System V IPC对象有很多共性,从代码层面上看也有很多公共的部分。权限结构就是其中一个。IPC的权限结构至少包括如下成员:
1 | struct ipc_perm{ |
uid和gid字段用于指定IPC对象的所有权。cuid和cgid字段保存着创建该IPC对象的进程的有效用户ID和有效组ID。初始情况下,用户ID(uid)和创建者ID(cuid)的值是相同的。它们都是调用进程的有效ID。但是创建者ID(cuid)是不可以改变的,而所有者ID则可以通过IPC_SET来改写。下面的代码演示了如何修改共享内存的uid字段:
1 | struct shmid_ds shm_ds; |
mode 是用来控制读写权限的。所有的System V IPC对象都不具备执行权限,只有读写权限。其中对于信号量而言,写权限意味着修改权限。IPC对象的权限控制见表:
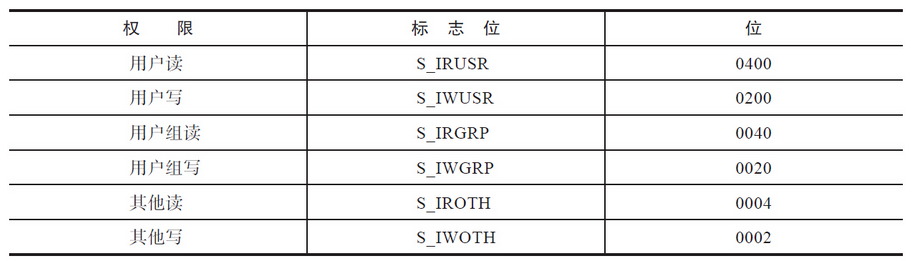
和文件的权限有点类似,IPC对象的权限被分成了三类:owner、group和other。创建对象时可以为各个类别设定不同的访问权限,代码如下所示:
1 | msg_id = msgget(key,IPC_CREAT | S_IRUSR | S_IWUSR |S_IRGRP); |
当一个进程尝试对IPC对象执行某种操作的时候,首先会检查权限。检查的逻辑如下:
- 如果进程是特权进程,那么进程拥有对IPC对象的所有权限。
- 如果进程的有效用户ID与IPC对象的所有者或创建者ID匹配,那么会将对象的owner的权限赋给进程。
- 如果进程的有效用户ID或任意一个辅助组ID与IPC对象的所有者组ID或创建者组ID匹配,那么会将IPC对象的group的权限赋予进程。
- 否则,将IPC对象的other权限赋予进程。
数据结构ipc_perm中的key和seq也很有意思。key比较简单,就是调用get函数创建IPC对象时传递进去的key值。如果key的值是IPC_PRIVATE,则实际的key值是0。和key相比,成员变量seq就不那么好理解了。进程分配文件描述符时采用的是最小可用算法。比如文件描述符5曾经被分配给文件A,但是很快进程关闭了文件A。如果进程尝试打开另外一个文件,此时如果5是最小可用的槽位,那么新打开文件的文件描述符就是5。但是IPC对象的标识符ID分配不能采用这个算法。因为多个进程要通过标识符ID来通信,而标识符ID是整个系统内有效的。如果采用最小可用的算法,一般来讲,IPC对象的个数不会太多,那么这个数字很容易就被猜到了。举例来说,如果存在一个恶意程序要攻击消息队列,它只需尝试很小范围内的数字,就可以猜到IPC对象的标识符ID,进而偷偷取走消息队列里面的信息。
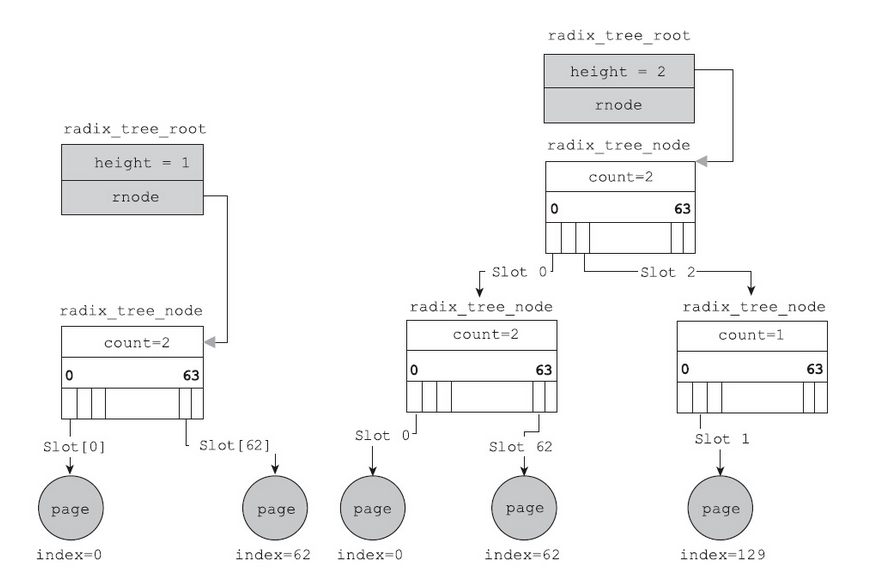
内核针为每一种System V IPC维护了一个ipc_ids类型的结构体。该结构体的组成如图:
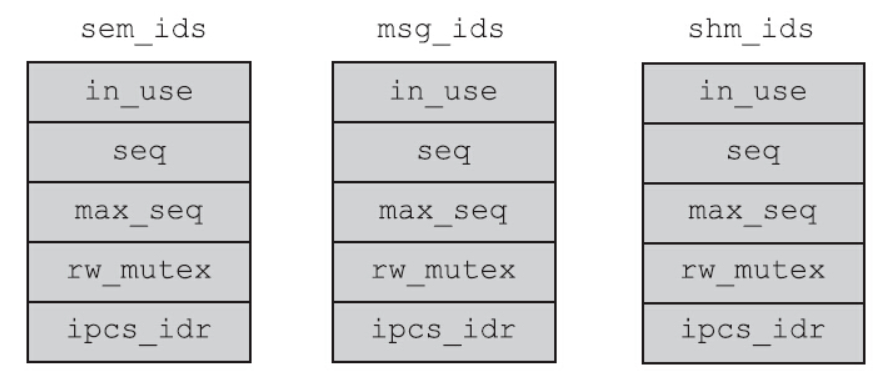
上述结构体中in_use字段记录的是系统当前在用的IPC个数。因此创建IPC对象时,该值会加1;销毁IPC对象时,该值会减去1。结构体中seq字段记录了开机以来创建该IPC对象的流水号。创建时seq的值自加,但是销毁的时候seq的值并不会自减。seq的值随着该种IPC对象的创建而单调地递增,直到递增到上限(max_seq),再溢出回绕,重新从0开始。当需要创建新的IPC对象时,三种IPC对象的创建都会走到ipc_addid函数处,如图:
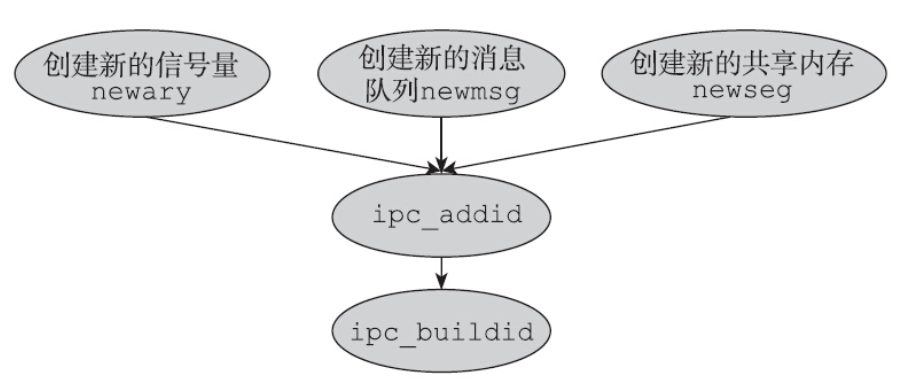
ipc_addid函数会初始化IPC对象的很多成员变量,比如权限相关的uid、gid、cuid和cgid,也会维护该IPC对象的seq值。
1 | int ipc_addid(struct ipc_ids* ids, struct kern_ipc_perm* new, int size) |
前面提到,内核分配IPC对象标识符的时候,使用的并不是最小可用算法,其使用的算法如下:
1 |
|
上面公式中的id就是最小可用的槽位,而seq是开机以来内核创建IPC对象的流水号。因此,返回的ID是一个比较大的值。仍然以消息队列为例,如果开机后,消息队列为空,创建的第一个消息队列的标识符必然为0,而创建的第二个消息队列和第三个消息队列的值则为:
1 | 32768 * 1 + 1 = 32769 |
根据上面的讨论可知,IPC对象的标识符ID虽然是通过get函数来获得的,但是和key值并不存在永久的对应关系,即不存在公式可以通过key值来计算出标识符ID。内核仅仅是关联了两者。重启系统之后,或者删除IPC对象之后,根据相同的key值再次创建,得到的标识符ID很可能并不相同。内核面临着如何根据IPC对象的标识符ID,快速地找到内核中的IPC对象的难题,根据前面的计算公式,不难做到:
1 | slot_index = 标识符ID % SEQ_MULTIPLIER |
这个公式透漏出了一个问题:整个系统内,每一种IPC对象的槽位有限,最多有IPCMIN个槽位。在ipc_addid函数中也证实了这一点,系统的硬上限为IPCMNI,即32768。这个限制就决定了不能无限制地创建IPC对象。
System V 消息队列
管道和FIFO都是字节流的模型,这种模型不存在记录边界。如果从管道里面读出100个字节,你无法确认这100个字节是单次写入的100字节,还是分10次每次10字节写入的,你也无法知晓这100个字节是几个消息。管道或FIFO里的数据如何解读,完全取决于写入进程和读取进程之间的约定。
从这个角度上讲,System V消息队列和POSIX消息队列都是优于管道和FIFO的。原因是消息队列机制中,双方是通过消息来通信的,无需花费精力从字节流中解析出完整的消息。
System V消息队列比管道或FIFO优越的第二个地方在于每条消息都有type字段,消息的读取进程可以通过type字段来选择自己感兴趣的消息,也可以根据type字段来实现按消息的优先级进行读取,而不一定要按照消息生成的顺序来依次读取。
内核为每一个System V消息队列分配了一个msg_queue类型的结构体,其成员变量和各自的含义如下所示:
1 | struct msg_queue { |
创建或打开一个消息队列
消息队列的创建或打开是由msgget函数来完成的,成功后,获得消息队列的标识符ID,函数接口定义如下:
1 |
|
msgget函数中两个参数的含义前面已经讲述过了,在此就不再赘述。当调用成功时,返回消息队列的标识符,后续的msgsnd、msgrcv和msgctl函数都通过该标识符来操作消息队列。当函数调用失败时,返回-1,并且设置相应的errno。常见的errno如表:
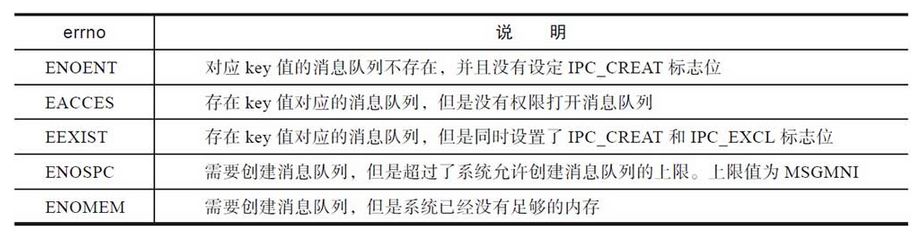
关于创建消息队列,一个很容易想到的问题是:操作系统到底允许创建多少个消息队列?
当errno等于ENOSPC时,表示创建的消息队列超过了上限值MSGMNI。有三种方法可以查看系统消息队列个数的上限,如下所示。
1 | // 通过procfs查看 |
操作系统会根据系统的硬件情况(主要是内存大小),计算出一个合理的上限值,因此不同的硬件环境下,该值是不同的。当然无论该值设置为多少,内核都存在硬上限IPCMNI(32768)。
可以通过如下的手段,修改msgmni的值,从而允许创建更多的消息队列。
1 | // 通过procfs来修改 |
上述两种方法都是立即生效,但是一旦系统重启,设置就失去了。要想确保重启后依然有效,需要将配置写入/etc/sysctl.conf。
1 | kernel.msgmni=20000 |
注意写入/etc/sysctl.conf并不会立即生效,需要执行sysctl -p重新加载,改变方能生效。
发送消息
获取到消息队列的标识符之后,可以通过调用msgsnd函数向队列中插入消息。内核会负责将消息维护在消息队列中,等待另外的进程来取走消息,从而完成通信的全过程。msgsnd函数的定义如下:
msgsnd函数的定义如下:
1 |
|
其中msqid是由msgget返回的标识符ID。参数msgp指向用户定义的缓冲区。它的第一个成员必须是一个指定消息类型的long型,后面跟着消息文本的内容。通常其定义如下:
1 | struct msgbuf { |
每条消息只能存放一个字符?并非如此。事实上可以是任意结构,mtext是由程序员定义的结构,其长度和内容都是由程序员控制的,只要发送方和接收方约定好即可。比如可以将结构体定义如下:
1 | struct private_buf { |
第三个参数msgsz指定了mtext字段中包含的字节数。消息队列单条消息的大小是有上限的,上限值为MSGMAX,记录在/proc/sys/kernel/msgmax中:
1 | cat /proc/sys/kernel/msgmax |
如果消息的长度超过了MSGMAX,那么msgsnd函数返回-1,并置errno为EINVAL。下面以发送字符串消息为例,介绍msgsnd函数所需的步骤:
1)因为glibc并未定义msgbuf结构体,因此首先要定义msgbuf结构体。
2)分配一个类型为msgbuf,长度足以容纳字符串的缓冲区mbuf。
3)将message的内容拷贝到mbuf->mtext中去。
4)在mbuf->mtype中设置消息类型。
5)调用msgsnd发送消息。
6)释放mbuf。
注意两点,即要对msgsnd进行错误检测和及时释放mbuf,以防止内存泄漏。
最后一个参数msgflg是一组标志位的位掩码,用于控制msgsnd的行为。目前只定义了IPC_NOWAIT一个标志位。IPC_NOWAIT表示执行一个无阻塞的发送操作。当没有设置IPC_NOWAIT标志位时,如果消息队列满了,那么msgsnd函数就会陷入阻塞,直到队列有足够的空间来存放这条消息为止。但是如果设置了IPC_NOWAIT标志位,那么msgsnd函数就不会陷入阻塞了,而是立刻返回失败,并置errno为EAGAIN。
等一下,这里好像提到了消息队列满。什么情况下,消息队列才能被称为是满的?任何一个消息队列,容纳的字节数是有上限的。这个上限值为MSGMNB,该值被记录在/proc/sys/kernel/msgmnb中:
1 | cat /proc/sys/kernel/msgmnb |
内核中消息队列对应的数据结构msg_queue中维护有当前字节数、当前消息数及允许的最大字节数等信息:
1 | struct msg_queue { |
检查消息队列是否满的逻辑非常简单,内核判断能否立刻发送消息的逻辑如下:
1 | if (msgsz + msq->q_cbytes <= msq->q_qbytes && |
如果同时满足以下两个条件,则可以立即发送消息,无须阻塞:
- 当前消息的字节数(msgsz)加上消息队列当前字节的总数(msq->q_cbytes)不大于消息队列允许的最大字节数(msq->q_qbytes)。
- 消息队列当前消息的个数加上1不大于消息队列容许的最大字节数(msq->q_qbytes)。
第二个条件看起来很奇怪的,其实这个条件是用来防范空消息的:发送的消息只有mtype字段,消息体正文mtext都是空的。不满足上述两个条件的话,msgsnd函数会根据是否设置了IPC_NOWAIT标志位来决定是陷入阻塞还是立刻返回失败。如果因消息队列满而陷入阻塞,msgsnd系统调用则可能会被信号中断,当这种情况发生时,msgsnd总是返回EINTR错误。注意,无论在建立信号处理函数的时候,是否设置了SA_RESTART标志位,msgsnd系统调用都不会自动重启。
无论是否经过阻塞,只要没有出错返回,调用msgsnd都需要执行下面的操作:
1 | /*将最后调用msgsnd的进程ID更新到消息队列的q_lspid成员变量中*/msq->q_lspid = task_tgid_vnr(current);/*将最后调用msgsnd的时间更新到消息队列的q_stime成员变量中*/ |
pipelined_send函数用于检测是否有进程正在等待该消息,如果有的话,消息无须进入消息队列,而是“就地消化”,皆大欢喜。如果没有等待该消息的进程,则消息就不得不进入消息队列,等待“有缘人”来提取。至此,msgsnd函数的使用和流程基本介绍完毕,如果执行成功,则msgsnd返回0,如果失败,msgsnd则返回-1,并置errno。
下面分析一下函数的返回值和常见错误。msgsnd函数不同于文件的write函数,write函数操作的是字节流,存在部分成功的概念,所以成功时,返回的是写入的字节个数;但是msgsnd函数操作的是封装好的消息,不成功则成仁,不存在部分成功的情况。所以其成功时,msgsnd函数返回0,失败时,msgsnd函数返回-1,并且设置errno。常见的出错情况如表
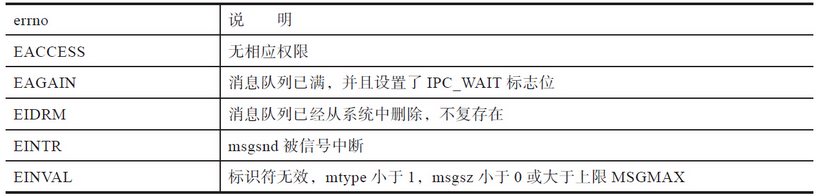
几乎所有的出错情况前面都已经介绍过了,除了EIDRM。这是消息队列和信号量的共同缺陷。当一个进程操作消息队列时,另外一个进程可能已经删除该消息队列了。对于IPC对象(共享内存除外),内核并没有维护引用计数,删除行为是说删就删,于是msgsnd调用就会收到EIDRM的错误。删除消息队列是一个编程难点,难就难在确定删除的时机。多个进程需要从逻辑上确定谁是最后一个访问消息队列的进程,然后由它来负责删除消息队列。
接收消息
有发送就要有接收,没有接收者的消息是没有意义的。System V消息队列用msgrcv函数来接收消息。
1 | ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp,int msgflg); |
其中前三个参数与msgsnd的含义是一致的。msgrcv调用进程也需要定义结构体,而结构体的定义要和发送端的定义一致,并且第一个字段必须是long类型,代码如下所示:
1 | struct private_buf { |
对于具有固定长度的消息体来讲,只要发送方和接收方的结构体达成一致,就不会存在风险。但是如果消息体是变长的,情况就复杂了点。因为不能预先得知收到消息体的长度,因此接收端的缓冲区要足够大,防止消息队列中的消息长度大于缓冲区的大小(这是其设计缺陷)。
Msgrcv函数的第4个参数msgtyp是消息队列的精华,提取消息时,可以选择进程感兴趣的消息类型。正是基于这个参数,读取消息的顺序才无须和发送顺序一致,进而可以演化出很多用法。msgtype与提取消息的行为关系如表
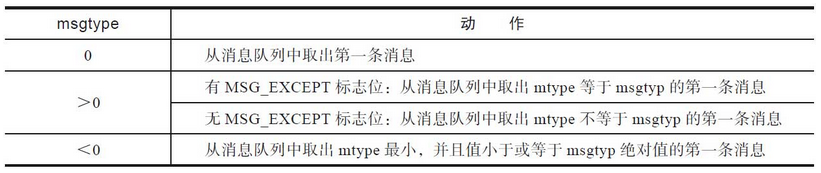
当msgtyp等于0时,行为模式是先入先出的模式。最先进入消息队列的消息被取出。当msgtyp小于0时,行为模式是优先级消息队列。mtype的值越低,其优先级越高,越早被取出。当msgtyp的值大于0时,会将消息队列中第一条mtype值等于msgtyp的消息取出。通过指定不同的msgtyp,多个进程可以在同一个消息队列中挑选各自感兴趣的消息。一种常见的场景是各个进程提取和自己进程ID匹配的消息。第5个参数是可选标志位。msgrcv函数有3个可选标志位。
IPC_NOWAIT:如果消息队列中不存在满足msgtyp要求的消息,默认情况是阻塞等待,但是一旦设置了IPC_NOWAIT标志位,则立即返回失败,并且设置errno为ENOMSG。MSG_EXCEPT:这个标志位是Linux特有的,只有当msgtyp大于0时才有意义,含义是选择mtype != msgtyp的第一条消息。MSG_NOERROR:前面也提到过,在消息体变长的情况下,可能事前并不知道消息体的大小,尽管要求maxmsgsz应尽可能地大,但是仍然存在maxmsgsz小于消息体大小的可能。如果发生这种情况,默认情况是返回错误E2BIG,但是如果设置了MSG_NOERROR标志位,情况就不同了,此时会将消息体截断并返回。
msgrcv函数调用成功时,返回消息体的大小;失败时返回-1,并且设置errno。大部分出错情况和msgsnd函数类似,比较特殊的错误码是E2BIG和ENOMSG,刚才都已经讨论过了,这里不再赘述。另外msgrcv函数和msgsnd函数一样,如果被信号中断,则不会重启系统调用,哪怕安装信号时设置了SA_RESTART标志位。System V消息队列存在一个问题,即当消息队列中有消息到来时,无法通知到某进程。消息队列的读取者进程,要么以阻塞的方式调用msgrcv函数,阻塞在消息队列上直到消息出现;要么以非阻塞(IPC_NOWAIT)的方式调用msgrcv函数,失败返回,过段时间再重试,除此以外并无好办法。阻塞或轮询,这就意味着一个进程或线程不得不无所事事,盯在该消息队列上,这给编程带来了不便。如果System V消息队列是文件,能支持select、poll和epoll等I/O多路转接函数,一个进程就能同时监控多个文件(或者多个消息队列),提供更灵活的编程模式。可惜的是,System V消息队列并非文件,不支持I/O多路转接函数。POSIX消息队列在这个方面做了很多的改进。
控制消息队列
msgctl函数可以控制消息队列的属性,其接口定义如下:
1 |
|
该函数提供的功能取决cmd字段,msgctl支持的操作如表

IPC_STAT
为了获取消息队列的属性信息或设置属性,必须要有一个用户态的数据结构来描述消息队列的属性信息,这个数据结构就是msqid_ds结构体,其大部分字段和内核的msg_queue结构体相对应。注意,msqid_ds结构体中包含下面的成员变量。在编程中,只要包含了对应的头文件,就可以直接使用该结构体。
1 |
|
几乎全部的字段都和内核的msg_queue相对应,而其对应的字段的含义在前面都已经介绍过了,此处不再赘述。在使用时,我们可以通过下面的简单代码来获取到消息队列的属性:
1 | strutct msqid_ds buf ; /*注意包含头文件*/ |
IPC_SET
消息队列开放出了4个可以设置的属性。
- msg_perm.uid
- msg_perm.gid
- msg_perm.mode
- msg_qbytes
设置方法一般首先调用IPC_STAT获取到当前的设置,然后修改4个属性中的某个或某几个属性,最后调用IPC_SET,代码如下所示:
1 | strutct msqid_ds buf ; /*注意包含头文件*/ |
IPC_RMID
IPC_RMID命令用于删除与标识符对应的消息队列。由于IPC对象并无引用计数的机制,因此只要有权限,可以说删就删,而且是立刻就删。消息队列中的所有消息都会被清除,相关的数据结构被释放,所有阻塞的msgsnd函数和msgrcv函数会被唤醒,并返回EIDRM错误。
System V 信号量
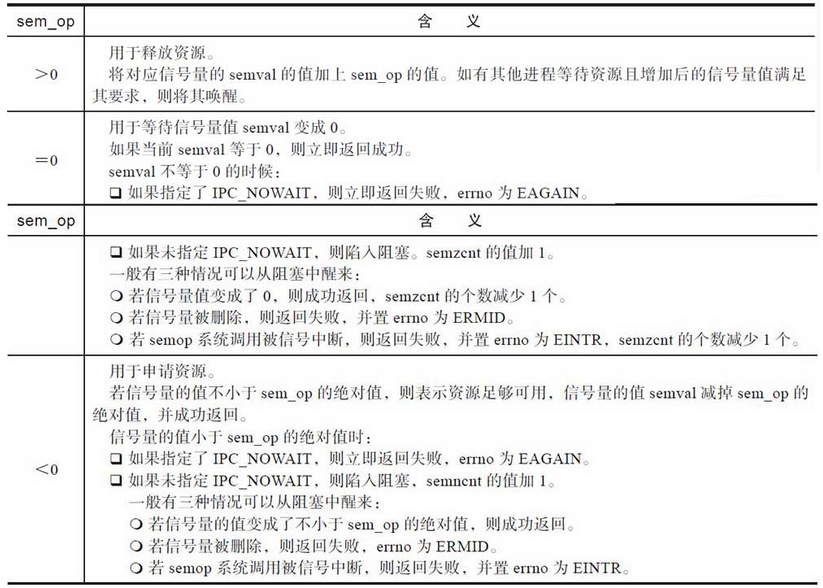
System V信号量又被称为System V信号量集,事实上信号量集的叫法更符合实际情况。信号量的作用和消息队列不太一样,消息队列的作用是进程之间传递消息。而信号量的作用是为了同步多个进程的操作。信号量是由E.W.Dijkstra为互斥和同步的高级管理提出的概念。它支持两种原子操作,wait和signal。wait还可以称为down、P或lock,signal还可以称为up、V、unlock或post。其作用分别是原子地增加和减少信号量的值。一般来说,信号量是和某种预先定义的资源相关联的。信号量元素的值,表示与之关联的资源的个数。内核会负责维护信号量的值,并确保其值不小于0。
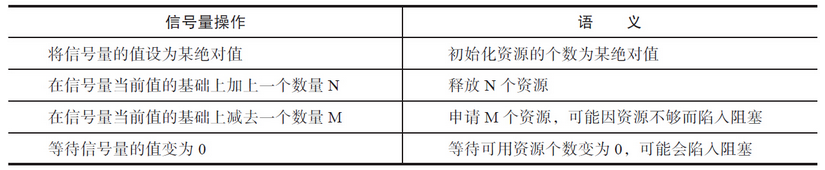
信号量上支持的操作有:
- 将信号量的值设置成一个绝对值。
- 在信号量当前值的基础上加上一个数量。
- 在信号量当前值的基础上减去一个数量。
- 等待信号量的值等于0。
在上述操作中,后两个可能会陷入阻塞。在第三种情况中,当信号量的当前值小于要减去的值时,操作会陷入阻塞。当信号量的值不小于要减去的值时,内核会唤醒阻塞进程。在第四种情况中,如果当前信号量的值不为0,该操作会陷入阻塞,直到信号量的值变为0为止。这些操作看似没有什么意义,但是一旦将信号量和某种资源关联起来,就起到了同步使用某种资源的功效,请看表
使用最广泛的信号量是二值信号量(binary semaphore)。对于这种信号量而言,它只有两种合法值:0和1,对应一个可用的资源。若当前有资源可用,则与之对应的二值信号量的值为1;若资源已被占用,则与之对应的二值信号量的值为0。当进程申请资源时,如果当前信号量的值为0,那么进程会陷入阻塞,直到有其他进程释放资源,将信号量的值加1才能被唤醒。
从这个角度看,二值信号量和互斥量所起的作用非常类似。那信号量和互斥量有何不同之处呢?互斥量(mutex)是用来保护临界区的,所谓临界区,是指同一时间只能容许一个进程进入。而信号量(semaphore)是用来管理资源的,资源的个数不一定是1,可能同时存在多个一模一样的资源,因此容许多个进程同时使用资源。
有个很有意思的卫生间理论可以用来阐述互斥量和信号量的区别。互斥量好比是一把卫生间的钥匙,卫生间只有一个,钥匙也只有一把。需要使用卫生间时,首先要去钥匙存放处取走钥匙,当使用完卫生间时,要将钥匙归还到钥匙存放处。如果某人需要使用卫生间,发现钥匙存放处没有钥匙,那么他就需要等待,直到卫生间的当前使用者将钥匙归还。假设后来买了一套豪宅,家里有8个一模一样的卫生间和8把通用的钥匙。这时信号量就横空出世了。信号量的值的含义是当前可用的钥匙数,最初有8把钥匙放在钥匙存放处。当同时使用卫生间的人数小于或等于8时,大家都可以拿到一把钥匙,各自使用各自的卫生间。但是到第9个人和第10个人要使用卫生间时,发现已经没有钥匙了,所以他们就不得不等待了。
从上面的讨论看,信号量是互斥量的一个扩展,由于资源数目增多,增强了并行度。但是这仅仅是一个方面。更重要的区别是,互斥量和信号量解决的问题是不同的。互斥量的关键在于互斥、排它,同一时间只允许一个线程访问临界区。这种严格的互斥,决定了解铃还须系铃人,即加锁进程必然也是解锁进程,代码如下所示:
1 | 进程1 进程2 |
而信号量的关键在于资源的多少和有无。申请资源的进程不一定要释放资源,信号量同样可以用于生产者-消费者的场景。在这种场景下,生产者进程只负责增加信号量的值,而消费者进程只负责减少信号量的值。彼此之间通过信号量的值来同步。
1 | 生产者进程消费者post wait |
和二值信号量相比,System V信号量在两个维度上都做了扩展。
第一,资源的数目可以是多个。资源个数超过1个的信号量称为计数信号量(counting semaphore)。
第二,允许同时管理多种资源,由多个计数信号量组成的一个集合称为计数信号量集,每个计数信号量管理一种资源。比如第一种资源的总数是5,第二种资源的总数是10。在使用过程中可选择申请哪种资源或哪几种资源。
坦率来讲,System V信号量有点设计过度,第二种扩展并无必要,同时操作集合中的多个信号量的能力是多余的,而这种扩展导致了编程接口过于复杂,使用不便。
创建或打开信号量
创建或打开信号量的函数为semget,其接口定义如下:
1 |
|
这个接口比较简单,第二个参数nsems表示信号量集中信号量的个数。换句话说,就是要控制几种资源。大部分情况下只控制一种。如果并非创建信号量,仅仅是访问已经存在的信号量集,可以将nsems指定为0。semflg支持多种标志位。目前支持IPC_CREAT和IPC_EXCL标志位,其含义不再赘述。
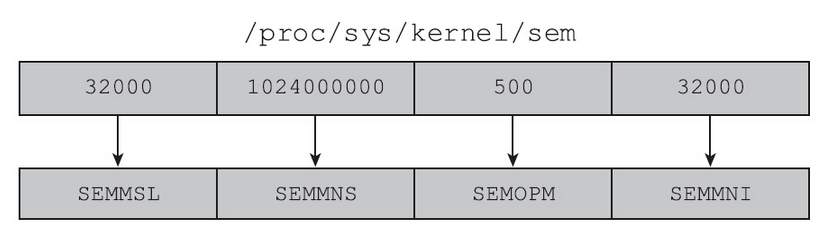
在创建信号量时,需要考虑的问题是系统限制。系统的限制可以分成三个层面。
- 系统容许的信号量集的上限:SEMMNI
- 单个信号量集中信号量的上限:SEMMSL
- 系统容许的信号量的上限:SEMMNS
首先介绍下对于每种限制,系统提供的硬上限,如表

其中SEMMSL的硬上限是65536,原因是semop函数中定义了sembuf结构体来操作信号量集中的信号量,代码如下所示:
1 | struct sembuf{ |
sembuf结构体中的成员变量sem_num用来指定修改集合中的哪个信号量。其数据类型是无符号短整型(unsigned short)。我们固然可以一意孤行地将SEMMSL的值设置为大于65536的数值,但是后续将无法通过semop来操作它,因此它也就失去了存在的意义。因此集合中信号量个数的硬上限值为65536。之所以SEMMNS的上限值为INT_MAX,原因是内核使用了int型来存储该值,代码如下所示:
1 | struct ipc_namespace{ |
在硬上限范围内,可以通过sysctl来设置软上限。
1 | cat /proc/sys/kernel/sem |
其中4个值的含义如图
第三个值(SEMOPM)的含义将放到后面再介绍。可以通过sysctl-w或修改/etc/sysctl.conf来设置控制参数。注意不要超过硬上限。如果超过系统限制时,返回的错误码见表.

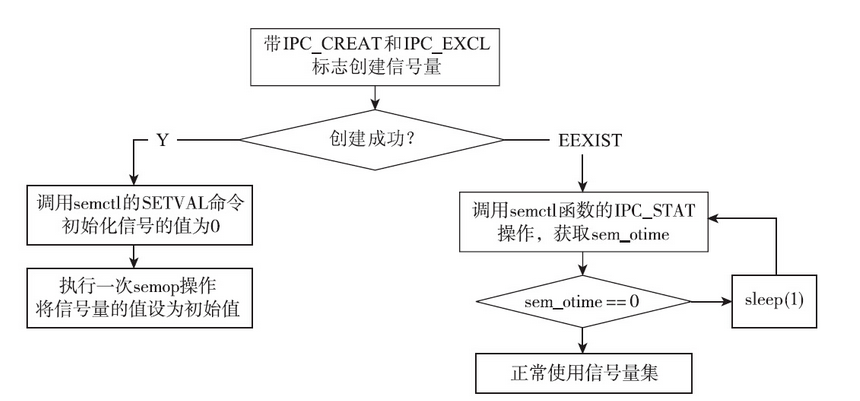
在System V信号量的接口设计中,存在一个致命的缺陷,即创建信号量集和初始化集合中的信号量是两个独立的操作,而非一个原子操作,标准并未要求创建信号量集时,将信号量的值初始化为0。当然,在Linux系统上,semget函数返回的信号量实际上会被初始化为0。但是很多情况下,信号量的初始值并不希望为0,因此需要额外调用一次semctl的SETVAL命令来设置初始值。由于创建和初始化之间存在一个时间窗口,因此可能会出现竞态条件(race condition),见表

在这种时序条件下,信号量的值尚未初始化就被进程2通过semop函数修改了。而后面进程1的初始化命令又会覆盖进程2所做的更改。W.Richard Stevens在名著《Unix网络编程卷2:进程间通信》中给出了如下思路来解决这个困境。内核与信号量集相关的数据结构sem_array中有一个成员变量sem_otime,如下所示:
1 | struct sem_array { |
信号量集被创建的时候,sem_otime被初始化成0,在后续执行semop操作的时候,才会对sem_otime的值进行修改。因此可以利用这个属性来消除竞争。即第二个进程要等到创建信号量的进程执行过一次修改信号量值的semop操作后(通过判断sem_otime的值是否为0),才开始正常的流程。《Linux/Unix系统编程手册(下册)》中也采用了这个思路解决了竞争问题,并给出了示例代码。但其示例代码适用范围比较狭窄,只适用于将信号量初始化为0这种场景。稍加改造,就可以适用于将信号量初始化为任意值的场景。
操作信号量
semop函数负责修改集合中一个或多个信号量的值,其定义如下:
1 |
|
第一个参数是通过semget获取到的信号量的标识符ID。
第二个参数是sembuf类型的指针。sembuf结构体定义在sys/sem.h头文件中。
一般来说,该结构体至少包含以下三个成员变量:
1 | struct sembuf { |
成员变量sem_num解决的是操作哪个信号量的问题。因为信号量集中可能存在多个信号量,需要用这个参数来告知semop函数要操作的是哪个信号量,0表示第一个信号量,1表示第二个信号量,依此类推,最大为nsems-1,即不得超过集合中信号量的个数。如果sem_num的值小于0,或者大于等于集合中信号量的个数,semop调用则会返回失败,并置errno为EFBIG。一般来讲,不建议采用如下方法来初始化sembuf:
1 | struct sembuf myopsbuf = {1,-1,0} |
因为考虑到可移植性,我们并没有十足的把握可以确定sembuf结构体中成员变量的顺序和上面定义中给出的顺序是严格一致的。(不过Linux的定义就是上面给出的定义,若不考虑可移植性,可以放心采用上面的方法。)
semop函数的典型用法如下所示:
1 | struct sembuf myopsbuf[3] ; |
semop函数每次会操作一组信号量,每个信号量由一个sembuf来表示,修改一个信号量最好也将其定义成struct sembuf ops[1]这样的数组,
semop函数的第三个参数表示要操作的信号量的个数。如果调用semop函数同时操作多个信号量,要被原子地执行,要么内核完成所有操作,要么内核什么也不做。尽管信号量集支持同时操作多个信号量,但事实上这种场景是非常罕见的。大多数情况下,只会操作集合中的一个信号量。更常见的是使用如下方式。
1 | struct sembuf myopsbuf[1] ; |
embuf中的sem_op可以是正值,也可以是负值,还可以是0。介绍其含义之前,首先来介绍几个相关的变量。
- semval:信号量的当前值,表示当前可用的资源个数,永远非负。
- semzcnt:正在等待信号量的值变成0的进程个数。
- semncnt:正在等待信号量的值大于当前值的进程个数。
根据sem_op的值和sem_flg值,semop函数的行为模式如表
对于semop操作,也存在如下系统限制:
- 单次semop调用能够操作的信号量的最大值:SEMOPM
- 信号量值的上限:SEMVMX
单次semop调用能够操作的信号量的最大个数记录在procfs中:
1 | sysctl kernel.sem |
如果nsops的值超过了SEMOPM,则semop函数返回-1,并置errno为E2BIG。除此之外,信号量的值也是有上限的,最大值为32767。若semop的增加操作导致信号量的值超过了其上限SEMVMX,那么semop函数返回-1,并置errno为ERANGE。通过上面的讨论,不难看出semop接口复杂难用。成熟的项目都会将semop函数封装起来,提供更好用、语义更简单的接口。对于编程者而言,不外乎申请资源(wait)和释放资源(post),可将接口进行如下封装:
1 | int semaphore_wait (int semid, int index) |
正常使用时,如果需要等待资源,就调用semaphore_wait函数:
1 | semaphore_wait(semid,0) |
释放资源的时候,就调用semaphore_post函数:
1 | semaphore_post(semid,0) |
注意,上面的封装仅仅是做一个简单的示意,很多问题并未考虑(比如未考虑系统调用被信号中断,收到EINTR错误码的场景),这些封装在项目中一般作为底层基础库,真正封装的时候要小心谨慎,考虑各种场景。
信号量撤销值
使用信号量存在这样一种风险,即进程申请了资源,修改了信号量的值,却没来得及释放资源就异常退出了。异常退出的进程把资源带进了坟墓,而其他进程却在苦苦等待其释放资源。这就意味着资源泄漏,即该进程申请的资源再也无法给其他进程使用了。对于二值信号量来说,资源泄漏的危害尤其大。为了避免因这个问题而陷入不可收拾的境地,内核提供了一种解决方案,即内核会负责记住进程对信号量施加的影响,当进程退出的时候,内核负责撤销该进程对信号量施加的影响。
调用semop函数时,可以通过如下方法设置SEM_UNDO标志位。
1 | struct sembuf myopsbuf[1]; |
内核并不会为所有带SEM_UNDO标志位的semop操作都保存一笔记录,内核维护了一个名为semadj的变量,该变量记录了一个进程在信号量上使用SEM_UNDO操作所做的调整总和。带SEM_UNDO标志位的semop对semadj的影响如表

申请资源和释放资源时,SEM_UNDO标志位要成对地出现。切不可只在申请资源的时候使用SEM_UNDO,或者只在释放资源的时候使用SEM_UNDO,这都会造成semadj失准,不能正确地反映进程对信号量施加的影响。
当使用semctl的SETVAL或SETALL命令重新设置信号量的值时,所有使用这个信号量的进程中的semadj值都会被重置为0。因为SETVAL或SETALL相当于开启了上帝模式,强行将信号量的值设定为某个值了。
SEM_UNDO也不是包治百病的良药。信号量是用来管理资源的,本身并无实际含义,如果进程异常退出,而资源并没有进入一个合理且稳定的状态,单单调整信号量的值并不一定能使应用恢复到一个稳定一致的状态。
除此以外,在某些情况下,进程终止时,也无法严格地按照进程的semadj来调整信号量的值,考虑如下情景:
1)信号量的初始值是0。
2)A进程将信号量增加2,并且设置了SEM_UNDO标志位。
3)B进程将信号量减去1,此时信号量的值变为1。
4)A进程退出。
按照逻辑,应该将当前信号量的值减去2。但是由于当前信号量的值是1,不可能减去2,那该怎么办呢。对于此困境,Linux采用的办法是尽可能地减小信号量的值。对于本例,就是将信号量的值减少为0。
上面的情况是向下溢出,与之对应的情况是向上溢出。即如果加上撤销量,信号量的值超过了上限SEMVMX,内核会将信号量的值调整为SEMVMX。这部分逻辑体现在ipc/sem.c中的exit_sem函数中:
1 | for (i = 0; i < sma->sem_nsems; i++) { |
一般来讲,SEM_UNDO 标志位多用于二值信号量。
控制信号量
控制信号量的函数为semctl函数,其定义如下:
1 |
|
某些特定的操作需要第四个参数,第四个参数是联合体,很不幸的是这个联合体需要程序员自己定义,代码如下所示:
1 | union semun { |
1.IPC_RMID
semctl函数的第二个参数被忽略。和消息队列的删除一样,内核不会维护信号量集的引用计数,说删就删,而且是立即删除信号量集。所有阻塞在semop函数上的进程将被唤醒,返回错误并置errno为ERMID。删除信号量的示例代码如下:
1 | int semaphore_destroy(int semid) |
2.IPC_STAT
用于获取信号量集的信息,并存放在union semun中buf指向的结构体。每个信号量集都有一个与之关联的semid_ds结构体(该结构体无须自己定义),它至少包含以下成员:
1 | struct ipc_perm sem_perm; |
可以使用如下的简单代码来获取上述信息(省略错误处理):
1 | struct semid_ds ds ; |
3.IPC_SET
union semun arg的成员变量buf,可用来设置sem_perm.uid、sem_perm.gid和sem_perm.mode。
4.GETVAL
返回集合中第semnum个信号量的值,无需第四个参数,示例代码如下:
1 | int semaphore_getval(int semid,int index) |
5.SETVAL
将信号量集中的第semnum个信号的值设置为arg.val,示例代码如下:
1 | int semaphore_setval(int semid, int index, int value) |
6.GETALL
将信号量集中所有信号的值存放在第四个参数arg的成员变量array中。确保有足够的空间可以存放array数组。这个操作将忽略第二个参数semnum。
7.SETALL
用第四个参数arg的成员变量array数组中的值初始化信号量集中的所有信号量。一般来说这个操作用于信号量的初始化,正常使用期间很少会调用SETALL。需要注意的是如果调用了SETVAL或SETALL,使用信号量的所有进程的semadj都会被清零。
8.GETPID
返回上一个对第semnum个信号量执行semop的进程的进程ID,如果不存在,则返回0。
9.GETNCNT
返回等待第semnum个信号量值增大的进程的个数。
10.GETZCNT
返回等待第semnum个信号量值变成0的进程的个数。
System V 共享内存
共享内存是所有IPC手段中最快的一种。它之所以快是因为共享内存一旦映射到进程的地址空间,进程之间数据的传递就不须要涉及内核了。回顾一下前面已经讨论过的管道、FIFO和消息队列,任意两个进程之间想要交换信息,都必须通过内核,内核在其中发挥了中转站的作用:
- 发送信息的一方,通过系统调用(write或msgsnd)将信息从用户层拷贝到内核层,由内核暂存这部分信息。
- 提取信息的一方,通过系统调用(read或msgrcv)将信息从内核层提取到应用层。
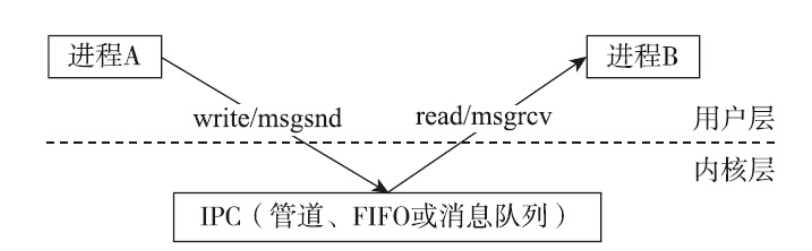
一个通信周期内,上述过程至少牵扯到两次内存拷贝(从用户拷贝到内核空间和从内核空间拷贝到用户空间)和两次系统调用,这其中的开销不容小觑。用户层的体验固然不佳,内核层想必也是不堪其扰,双方的内心都是崩溃的。
于是,不堪其扰的内核提出了一个新的思路:共享内存,这种思路可以通俗地概括为内核搭台,进程唱戏。简单地说,内核负责构建出一片内存区域,两个或多个进程可以将这块内存区域映射到自己的虚拟地址空间,从此之后内核不再参与双方通信。
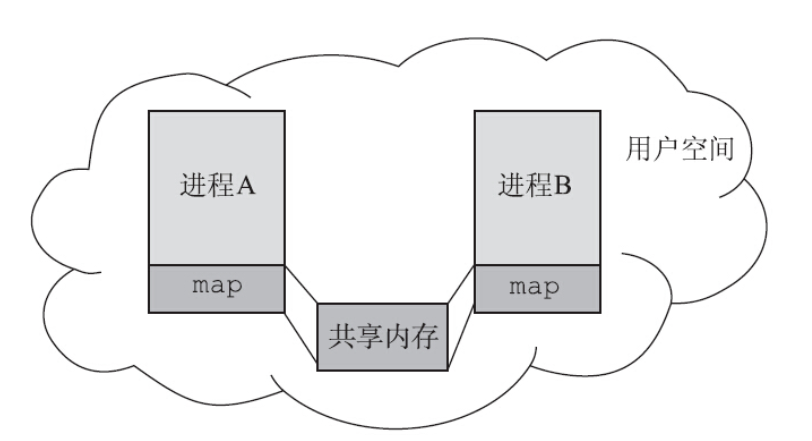
建立共享内存之后,内核完全不参与进程间的通信,这种说法严格来讲并不是正确的。因为当进程使用共享内存时,可能会发生缺页,引发缺页中断,这种情况下,内核还是会参与进来的。
进程从此就像操作普通进程的地址空间一样操作这块共享内存,一个进程可以将信息写入这片内存区域,而另一个进程也可以看到共享内存里面的信息,从而达到通信的目的。允许多个进程同时操作共享内存,就不得不防范竞争条件的出现,比如有两个进程同时执行更新操作,或者一个进程在执行读取操作时,另外一个进程正在执行更新操作。因此,共享内存这种进程间通信的手段通常不会单独出现,总是和信号量、文件锁等同步的手段配合使用。
创建或打开共享内存
shmget函数负责创建或打开共享内存段,其接口定义如下:
1 |
|
其中第二个参数size必须是正整数,表示要创建的共享内存的大小。内核以页面大小的整数倍来分配共享内存,因此,实际size会被向上取整为页面大小的整数倍。
第三个参数支持IPC_CREAT和IPC_EXCL标志位。如果没有设置IPC_CREAT标志位,那么第二个参数size对共享内存段并无实际意义,但是必须小于或等于共享内存的大小,否则会有EINVAL错误。和消息队列及信号量一样,对于创建共享内存,系统也存在一些限制。
和消息队列及信号量一样,对于创建共享内存,系统也存在一些限制。
- SHMMNI:系统所能够创建的共享内存的最大个数。
- SHMMIN:一个共享内存段的最小字节数。
- SHMMAX:一个共享内存段的最大字节数。
- SHMALL:系统中共享内存的分页总数。
- SHMSEG:一个进程允许attach的共享内存段的最大个数。
系统允许创建的共享内存的最大个数SHMMNI的硬上限为IPCMNI(32768),软上限记录在proc文件系统的如下位置。
1 | cat /proc/sys/kernel/shmmni |
单个共享内存段的最小字节数SHMMIN是1,内核并没有提供控制选项来修改这个值。实际上共享内存会向上取整到页面大小,即共享内存占用的内存总是页面大小的整数倍,因此,实际的限制为4096字节。单个共享内存段的最大字节数为SHMMAX。这个值默认是32MB,可以从procfs中读出该限制。但是内核并没有设置硬上限。
1 | cat /proc/sys/kernel/shmmax |
很明显,32MB对某些大型的应用来说是不够用的。最典型的就是PostgreSQL数据库。PostgreSQL数据库会征用大量的共享内存作为其内部使用的shared_buffer。因此须要修改该参数,方法为修改/etc/sysctl.conf,新增如下内容,并执行sysctl -p来重新加载。
1 | kernel.shmmax = 2147483648 |
SHMALL是一个系统级别的限制,单位是页面。内核也没有提供硬上限,一般默认值为2097152,2MB个页面即2MB×4096=8GB。该限制记录在procfs的如下位置。
1 | cat /proc/sys/kernel/shmall |
SHMSEG是一个进程级别的限制,限制一个进程最多可以attach多少个共享内存段。内核事实上并没有特别的限制,因此该限制实际上和SHMMNI的值一样。
使用共享内存
shmget函数,不过是在茫茫内存中创建了或找到了一块共享内存区域,但是这块内存和进程尚没有任何关系。要想使用该共享内存,必须先把共享内存引入进程的地址空间,这就是attach操作。attach操作的接口定义如下:
1 |
|
第二个参数是用来指定将共享内存放到虚拟地址空间的什么位置的。大部分的普通青年都会将第二个参数设置为NULL,表示用户并不在意,一切交由内核做主。
当shmaddr的地址不是NULL的时候,表示进程希望将共享内存attach到该地址。但是该地址必须是系统分页的整数倍,否则会返回EINVAL错误。内核提供了一个shmflg为SHM_RND,表示该地址不是系统分页的整数倍也没关系,系统会在用户给出的地址附近,就近找一个系统分页整数倍的地址。
如果指定的shmaddr落在已经在用的地址范围内,就会导致EINVAL错误。但是Linux提供了一个非标准的扩展SHM_REMAP。这个标志位表示替换位于shmaddr处且长度为共享内存段的长度的任何内存映射。很明显,设置了SHM_REMAP标志位,shmaddr参数就不能再为NULL了。
如果进程仅仅是读取共享内存段的内容,并不修改,则可以指定SHM_RDONLY标志位。
shmat如果调用成功,则返回进程虚拟地址空间内的一个地址。如果失败,就会返回(void*)-1,并且设置errno。
如何通过shmat返回的地址来使用共享内存?答案是像使用malloc分配的空间一样使用共享内存。我们都使用过malloc,调用malloc时,会指定分配空间的大小,malloc成功后,可以正常地使用返回的地址(只要不超过分配的空间)。shmat也是一样,程序员可以自如地使用shmat返回的地址。使用共享内存和使用malloc分配的空间还是有区别的。共享内存段用于多个进程间的通信,因此,写入共享内存的内容要事先约定好,读取进程才可以正常地解析写入进程写入的内容。malloc分配的内存区域完全归调用进程所有,其他进程不可见,但共享内存则不然,其他进程也可能会同时操作该共享内存,因此使用者要有进程间同步的觉悟。下面给出一个将共享内存attach到进程地址空间的例子:
1 |
|
当执行上述程序时,可以看到如下输出:
1 | ./shm |
可以看到返回的标识符ID为131075,该共享内存attach到进程的地址空间后,在进程内的地址为0x7f555dc5c000。通过查看进程的地址空间,也可以看出共享内存所在的位置,代码如下:
1 | cat /proc/9058/maps… |
上述输出中,字段的含义如图

共享内存和System V消息队列及System V信号量有不同之处,共享内存维护了attach该共享内存的进程的个数,见下面输出的nattach列:
1 | ipcs -m |
存在引用计数,就不难猜出共享内存的删除和消息队列及信号量的删除是不同的。它并不遵循说删就删的准则,删除时会判断attach该共享内存的进程个数。如果尚有进程在使用该共享内存,就不会真正地删除,而是让内核负责标记一下就返回了。
正是因为attach操作会影响删除的行为,因此,使用共享内存的进程如果确认不再使用了,应该及时地将共享内存分离,使其离开进程的地址空间,这就是分离操作。分离会使共享内存的引用计数减1。通过fork函数创建的子进程,会继承父进程attach的共享内存。因此在fork之前创建共享内存,后面父子进程就可以使用这块共享内存进行通信了。
分离共享内存
分离操作的接口定义如下:
1 |
|
shmdt函数仅仅是使进程和共享内存脱离关系,并未删除共享内存。shmdt函数的作用是将共享内存的引用计数减1。如前所述,只有共享内存的引用计数为0时,调用shmctl函数的IPC_RMID命令才会真正地删除共享内存。进程执行exec之后,所有attach的共享内存都会被分离。当进程终止之后,共享内存也会自动被分离。
控制共享内存
shmctl 函数用来控制共享内存,函数接口定义如下:
1 |
|
当cmd为IPC_STAT和IPC_SET时,需要用到第三个参数。其中shmid_ds结构体的定义如下:
1 | struct shmid_ds { |
1.IPC_STAT
用于获取shmid对应的共享内存的信息。所谓信息,就是上面结构体的内容。shm_perm中的mode字段有两个比较特殊的标志位,即SHM_DEST和SHM_LOCKED。删除共享内存时,可能由于attach它的进程个数不为0,因此只能打上一个标记,表示标记删除,待到所有attach该共享内存的进程都执行过分离(detach)操作,共享内存的引用计数变成0之后,才执行真正的删除操作。所谓的标记指的就是SHM_DEST标志位。对于已经标记删除的共享内存,可以通过ipcs -m命令的status栏来查看,其dest含义是已经标记删除的意思。
1 | key shmid owner perms bytes nattch status |
可以通过shmctl的SHM_LOCK操作将一个共享内存段锁入内存,这样它就不会被置换出去。这样做的好处是访问共享内存的时候,不会产生缺页中断(page fault)。通过ipcs-m的输出可以查看共享内存是否被锁入内存,注意下面状态中的locked字段,该字段表明对应的共享内存已被锁入内存。
1 | ipcs -m |
除此以外,其他字段就顾名思义了。
shm_segsz:共享内存的字节数。shm_atime:创建共享内存时设置成0,当进程通过shmat函数attach共享内存时,将时间更新为当前时间。shm_dtime:创建共享内存时设置成0,当进程调用shmdt分离共享内存时,将时间更新成当前时间。shm_ctime:当创建共享内存时,设置该值为当前时间;当调用IPC_SET操作时,更新该值为当前时间。shm_nattch:attach该共享内存到其地址空间的进程的个数。
2.IPC_SETIPC_SET
也只能修改shm_perm中的uid、gid及mode。
3.IPC_RMID
可以通过如下方式删除共享内存段:
1 | ret = shmctl(shmid, IPC_RMID, (struct shmid_ds *) NULL); |
如果共享内存的引用计数shm_nattch等于0,则可以立即删除共享内存。但是如果仍然存在进程attach该共享内存,则并不执行真正的删除操作,而仅仅是设置SHM_DEST标记。待所有进程都执行过分离操作之后,再执行真正的删除操作。值得一提的是,共享内存处于SHM_DEST状态的情况下,依然允许新的进程调用shmat函数来attach该共享内存。
4.SHM_LOCK
可以通过如下方式将共享内存锁定在内存之中:
1 | ret = shmctl(shmid, SHM_LOCK, (struct shmid_ds *) NULL); |
上面的代码会将共享内存锁定在RAM中,而不被置换出去。这种做法可以提升共享内存的访问性能。因为进程在访问共享内存所在的分页时,不会因缺页中断而导致性能下降。注意调用SHM_LOCK并不能保证在shmctl函数结束时,所有的共享内存页已经位于RAM中了,当没有驻留在RAM中的页面因为访问需要,由缺页中断而被引入RAM后,该页面就会被锁定,而不会被交换出去。除非调用了下面提到的SHM_UNLOCK,否则页面会一直驻留在内存中。SHM_LOCK设置的是共享内存的属性,而不是进程的属性,所以哪怕所有attach共享内存的进程都已终止,共享内存的页面仍被锁定在RAM中。故而为了防止发生资源泄漏,要及时解锁已锁定的共享内存。解锁操作可通过shmctl函数的SHM_UNLOCK来完成。
5.SHM_UNLOCK
SHM_UNLOCK操作和SHM_LOCK操作相反,是解锁操作,即允许共享内存的页面被交换出去。可以通过如下方式解锁共享内存:
1 | ret = shmctl(shmid, SHM_UNLOCK, (struct shmid_ds *) NULL); |
POSIX IPC
与System V IPC一样,POSIX IPC也包含三种类型:
- POSIX消息队列
- POSIX信号量(又分为命名信号量和无名信号量)
- POSIX共享内存
POSIX IPC的出现要比System V IPC晚,因此POSIX IPC的设计者可以从容地参照System V IPC,吸收其设计上的长处,规避其设计上的缺点。正是由于POSIX IPC拥有后发优势,所以总体来讲,POSIX IPC要优于System V IPC。
下表汇总了POSIX IPC的所有函数。
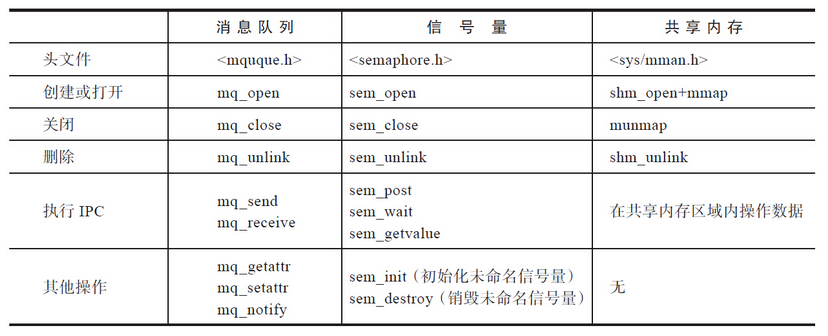
在POSIX IPC的模型中,对open、close和unlink等类似函数的使用与传统的Unix文件模型一致,相信理解和操作起来应该很容易。与打开文件一样,POSIX IPC对象也有引用计数,内核会负责维护IPC对象上的打开引用计数。它所带来的影响是删除POSIX IPC对象的操作比较简单。删除操作仅仅是删除IPC对象的名字,等所有的进程都使用完毕,IPC对象的引用计数变成0之后才真正销毁IPC对象。
IPC对象的名字
多个进程之间操作同一个IPC对象,总要有个入口点或线索,以便根据线索找到共同的IPC对象。对于System V IPC而言,键值就是其线索,只要拿着相同的键值就能找到同一个System V IPC对象。
对于POSIX IPC来说,可以像操作文件一样操作IPC对象。文件有路径名,同样,IPC对象也有IPC对象的名字。SUSv3标准规定,唯一一种用来标识POSIX IPC对象的可移植方法是使用以斜线打头后面跟着一个或多个非斜线字符的名字,如/myobject。下面三段代码分别负责创建POSIX消息队列、信号量和共享内存。
1 | /*创建POSIX消息队列*/ |
Linux为IPC对象提供了文件系统的访问接口,即可以像操作普通文件一样操作IPC对象。对于创建出来的共享内存和信号量,Linux将这些对象放到了挂载在/dev/shm目录处的tmpfs文件系统中,代码如下所示:
1 | $ ll /dev/shm/ |
可以看到,创建一个名为name的共享内存后,在/dev/shm目录下就会有一个名为name的文件。如果创建一个名为name的信号量,那么在/dev/shm目录下就会有一个名为sem.name的文件。消息队列也可以展现在文件系统中,不过要比共享内存和信号量稍微复杂一些。需要首先将消息队列挂载到文件系统中,方法如下:
1 | mkdir /dev/mqueue |
现在可以创建消息队列了。当然如果不将消息队列挂载到文件系统中,并不会影响消息队列的创建,仅仅是无法从文件系统查看消息队列的情况而已。
1 | $ ll /dev/mqueue/ |
IPC对象的名字有哪些限制?通过测试不难得出以下结论:
- POSIX消息队列的名字必须以/打头,而且后续字符不允许出现/,否则就返回EINVAL错误。
- POSIX消息队列的名字中打头的/字符不计入长度。
- POSIX消息队列名字的最大长度为NAME_MAX(255个字符),若超过则返回ENAMETOOLONG错误。
- POSIX信号量和共享内存的名字可以以1个或多个/打头,也可以不以/打头。
- POSIX信号量和共享内存的名字中,打头的一个或多个/字符不计入长度。
- POSIX共享内存名字的最大长度为NAME_MAX,POSIX信号量名字的最大长度为NAME_MAX-4(因为实现会在信号量的名字前面添加sem.这4个字符)。若超过则返回ENAMETOOLONG错误。
注意,这些结论是从glibc相关函数(mq_open、sem_open和shm_open)的角度来分析的,并不是从系统调用的角度来分析的。glibc调用系统调用之前会做一些动作,比如mq_open函数调用同名系统调用前会去除打头的/等。
解决了IPC对象的名字问题,接下来就是创建POSIX IPC对象了。创建或打开,都是由open系列函数来完成的。后续的操作要作用在open函数返回的句柄上。对于POSIX IPC的open系列函数而言,一般至少包含三个参数name、oflag和mode。
name前面已经说过,就是POSIX IPC的名字。下面来分析第二个参数打开标志位,见下图。
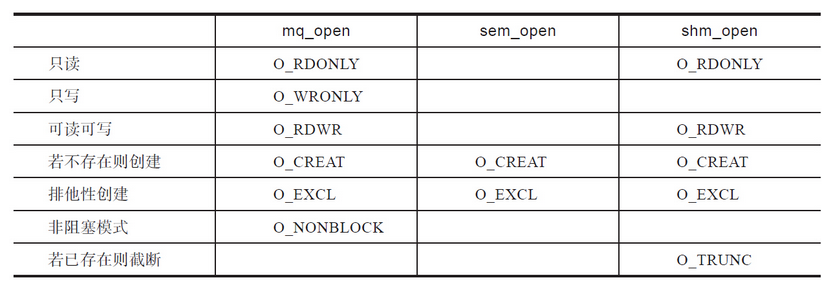
如果oflag中指定了O_CREAT标志位,则需要第三个参数mode来指定权限,这个权限和文件的权限一样,不外乎S_IRUSR、S_IWUSR、S_IRGRP、S_IWGRP、S_IROTH、S_IWOTH这6种权限。并且和open函数一样,mode中的权限会根据进程的umask取掩码。打开还是创建,取决于oflag是否设置了O_CREAT及O_EXCL标志位。内在的控制逻辑和System V IPC一致,如表

POSIX IPC对象维护有引用计数,在用完IPC对象后,可以调用相关的close函数来释放与该对象关联的资源并使引用计数减1。对于消息队列,该函数是mq_close;对于信号量该函数是sem_close。共享内存和前两者略有不同,它通过munmap解除映射来解除和共享内存的关系。
当进程退出或执行exec系列函数时,IPC对象会自动关闭。
正是因为POSIX IPC对象有引用计数,所以删除的时候比较方便。对应的unlink操作会删除对象的名字,直到所有进程使用完毕,关闭了对象或解除了映射关系之后,才会真正销毁。
因为Linux提供了文件系统访问方式,因此完全可以在文件系统中执行ls或rm操作来查看或删除IPC对象。细心的读者可以看出存放IPC对象的目录都设置了粘滞位,这是用来保护目录下的文件的,即对于非特权进程只能删除它自己拥有的POSIX IPC对象。
1 | # ll /dev/shm/ |
与System V IPC相比,POSIX有很多优势。后面介绍POSIX IPC的每一种通信手段的时候,都会与System V IPC对应的手段进行比较。但POSIX IPC也有明显的劣势——可移植性。因为System V出现得早,几乎所有的Unix平台都支持System V IPC。但是如果专注于Linux平台的话,这个问题就不存在了。2.6.6之后的内核版本,三种POSIX IPC手段就已经齐备。而主流在用的Linux版本很少有低于2.6.6的。
编译使用POSIX IPC的程序时需要注意以下两点。
- 当使用消息队列和共享内存的时候,需要和实时库librt链接起来。cc命令中需指定-lrt。
- 当使用信号量的时候,需要和线程库libpthread链接起来。cc命令中需指定-lpthread。示例代码如下所示:
1 | gcc -o mq_open mq_open.c –lrt |
POSIX 消息队列
POSIX消息队列与System V消息队列有一定的相似之处,信息交换的基本单位是消息,但也有显著的区别。最大的区别当属在Linux实现里POSIX消息队列的句柄本质是文件描述符。这个性质给POSIX消息队列带来了巨大的优势。因为是文件描述符,所以可以使用I/O多路复用系统调用(select、poll或epoll等)来监控这个文件描述符。
其次,POSIX消息队列提供了通知功能,当消息队列中有消息可用时,就会通知到进程。而System V消息队列没有通知功能,所以消息队列上何时有消息进程无从得知,只能阻塞(msgrcv)或轮询(带IPC_NOWAIT标志位的msgrcv)。最后,System V消息队列的消息提取要比POSIX消息队列灵活。POSIX消息队列本质是个优先级队列。而System V消息中存在类型字段,可以提取类型等于某值的消息,这点POSIX消息队列是做不到的。这个优势让System V消息队列在与POSIX消息队列的对决中,稍稍挽回一点颜面。
消息队列的创建,打开,关闭及删除
之所以在本节介绍三个接口,是因为POSIX消息队列的接口和操作文件的接口非常类似。消息队列的mq_open函数如同操作文件的open函数,用于创建或打开一个消息队列,其接口定义如下:
1 |
|
oflag允许的标志位包括O_RDONLY,O_WRONLY,O_RDWR,O_CREAT,O_EXCL,O_NONBLOCK。除了O_NONBLOCK标志位,其他都是老朋友了,不必赘述,这里单提一下O_NONBLOCK。如果打开消息队列时,没有设置O_NONBLOCK标志位,那么后续的mq_send调用和mq_receive调用就可能会陷入阻塞。反之,如果打开消息队列时设置了该标志位,发送消息或接受消息若不能立刻返回,则立刻返回失败,并置errno为EAGAIN,而不会陷入阻塞。
第三个参数mode和第四个参数attr只有在创建消息队列的时候才有意义。如果仅仅是打开消息队列,则无需这两个参数。mode设置的是访问权限,attr设置的是消息队列的属性。在介绍mq_getattr函数和mq_setattr函数时会展开说明。默认情况下,第四个参数可以传递NULL,表示创建默认属性的消息队列。
当mq_open调用成功时则返回一个mqd_t类型的消息队列描述符。对于Linux平台而言,这就是一个int型数字,其实这个数字和open函数返回的文件描述符本质上是一样的,从内核的ipc/mqueue.c中mq_open系统调用的实现就可以看出:
1 | SYSCALL_DEFINE4(mq_open, const char __user * u_name, int oflag, |
在/proc/PID/fd目录下,也可以看到消息队列对应的文件描述符:
1 | ./mq_open /abc |
一个进程允许打开多少个消息队列?标准并没有严格限定,这点是由具体的实现来决定的。SUSv3标准要求这个限制最小为_POSIX_MQ_OPEN_MAX(8)。Linux没有定义这个限制。相反因为消息描述符被实现成了文件描述符,因此其必须遵循文件描述符的限制。
进程允许打开的消息队列个数是否仅仅受限于进程打开的最大文件个数?事实上并非如此。资源限制中有一项RLIMIT_MSGQUEUE,用于限制用户在POSIX消息队列中可以分配的最大字节数。在下一节介绍POSIX消息队列的属性时,会重点介绍该限制对允许打开的消息队列个数的影响。
调用fork之后,子进程也获得了消息队列描述符的副本,这个副本会引用同样的打开的消息队列。调用exec之后,由于内核实现中消息队列的描述符自动带有O_CLOEXEC标志位,所以其打开的消息队列会被自动关闭。当进程退出时,所有打开的消息队列都会被关闭。
mq_close函数用于关闭消息队列描述符,这个函数和关闭文件的close函数十分类似:
1 |
|
如果进程已经注册了消息通知,那么消息通知也会被删除。因为任一时刻,只能有一个进程向特定消息队列注册并接收消息通知,因此删除消息通知后,其他进程就能注册消息通知了。
POSIX消息队列也具有内核持久性,纵然打开该消息队列的所有进程都执行了mq_close,消息队列的引用计数已变为0,但只要不显式地调用mq_unlink,该队列及队列上的消息依然存在。要销毁消息队列,需要调用mq_unlink函数,代码如下:
1 |
|
第一个小程序是用来创建消息队列的,如果传入了-e选项,则表示创建时要加上O_EXCL标志位:
1 |
|
第二个小程序是用来删除POSIX消息队列的:
1 |
|
Linux下POSIX提供了mqueue类型的虚拟文件系统,可以通过挂载,很方便地使用ls和rm来列出或删除POSIX消息队列。可以通过如下命令将消息队列挂载到文件系统:
1 | mount -t mqueue source target |
其中source可以为none,target是挂载点。比如可以通过如下命令挂载消息队列:
1 | mkdir /dev/mqueue |
使用第一个程序编译出mqcreate二进制程序,使用第二个程序编译出mqunlink二进制程序,可以做如下试验:
1 | ./mqcreate /abcd |
可以看出,通过mqcreate创建出来的消息队列,可以通过ls /dev/mqueue来查看,甚至可以通过cat /dev/mqueue/queue_name来获取消息队列的信息。
消息队列的属性
介绍mq_open函数时曾提到,第四个参数是mq_attr类型的,表示消息队列的属性。创建时可以指定消息队列的属性,POSIX消息队列也提供了mq_setattr函数来改变消息队列的属性。在继续讨论之前,首先需要了解消息队列有哪些属性,mq_attr结构体中定义了以下成员。
1 | struct mq_attr { |
这个结构体定义在<mqueue.h>文件中:
- mq_flags:0或设置了O_NONBLOCK。
- mq_maxmsg:消息队列中的最大消息个数。
- mq_msgsize:单条消息允许的最大字节数。
- mq_curmsgs:消息队列当前的消息个数。
如果调用mq_open函数创建POSIX消息队列时,第四个参数为NULL,那么将使用默认属性。可以使用如下代码来获取默认属性:
1 | int ret = mq_getattr(mqd,&attr); |
其中消息队列的最大消息数的默认值10记录在如下位置:
1 | cat /proc/sys/fs/mqueue/msg_default |
单条消息的最大字节数的默认值8192记录在如下位置:
1 | cat /proc/sys/fs/mqueue/msgsize_default |
消息队列中只能存放10条消息,这明显太少了,此外单条消息的最大字节数8192可能也无法满足我们的需要。因此创建消息队列的时候需要定制属性,定制方法如下所示:
1 | attr.mq_maxmsg = atoi(argv[2]); |
但是消息队列的最大消息数和单条消息的最大字节数并不能被随意指定。它受限于多个控制选项。对于普通用户(非特权用户)而言,内核提供了两个控制选项:
1 | cat /proc/sys/fs/mqueue/msg_max |
这两个值分别是最大消息数的上限和单条消息最大字节数的上限。普通用户在定制消息队列属性的时候不能超越这个上限。这两条限制是针对普通用户而言的,对于特权用户而言可以忽视这两条限制。很明显,这个上限值并不大,特权用户可以调整这两项的值:
1 | sysctl -w fs.mqueue.msg_max=4096 |
但是不能随意设置上限值,对于/proc/sys/fs/mqueue/msg_max,系统提供了硬上限HARD_MSGMAX,见表

对于/proc/sys/fs/mqueue/msgsize_max,系统也提供了硬上限,见表

事实上,除了上述控制选项外,还存在其他限制。如果调整msg_max控制选项到4096,调整msgsize_max控制选项到65536字节,那么可以创建出能容纳4096条消息,每条消息的最大长度为64字节的消息队列;也可以创建出只容纳两条消息,每条消息最大长度为65536字节的消息队列。但是无法创建出既可以容纳4096条消息,每条消息的最大长度又为65536字节的消息队列。这表明除了上述两条控制外,还存在其他限制。该限制就是介绍mq_open时提到的RLIMIT_MSGQUEUE。RLIMIT_MSGQUEUE属于资源限制的范畴。它限制了用户可以在POSIX消息队列中分配的最大字节数。注意不是单个消息队列的最大字节数,也不是一个进程能分配的最大字节数,而是该用户创建的所有的消息队列的最大字节数。如果新建消息队列会导致所有消息队列的字节数超出此限制,那么调用mq_open函数时会返回EMFILE错误。
Robert Love大师在《Linux系统编程》中提到的返回ENOMEM是错误的。
RLIMIT_MSGQUEUE默认为819200字节,可以通过如下指令来查看:
1 | ulimit -q |
消息队列消耗的空间,不能仅仅计算消息体(payload),还要考虑额外的开销。可以从内核的mqueue_get_inode函数中找到。
1 | /*mq_msg_tblsz是额外的开销*/ |
一个消息队列消耗的总空间为:
1 | bytes = (attr.mq_msgsize + sizeof(struct msg_msg*))*attr.mq_maxmsg |
消息队列创建以后可以通过调用mq_setattr来修改属性,相关接口定义如下:
1 |
|
对于mq_maxmsg和mq_msgsize这两个属性,在消息队列创建的时候,就已经确定下来了,虽然提供有mq_setattr函数,但是该函数并不能修改这两个属性。该函数可以改变的属性只有第一个mq_flags,即可以通过改变O_NONBLOCK标志位来确定是否置位。其他的属性均不可以修改。改变O_NONBLOCK属性的方法如下:
1 | mq_getattr(mqd,&attr); |
消息的发送和接收
发送消息
POSIX消息队列发送消息和接收消息的接口都很容易理解,从易用性的角度来讲,它们要优于System V消息队列的对应接口。发送消息的接口定义如下:
1 |
|
第三个参数msg_len表示消息体的长度,长度为0也是合法的,最大不得超过mq_msgsize。如果消息体太大,则会返回失败,并置errno为EMSGSIZE。
第四个参数为消息的优先级,是一个非负的整数。那么问题就来了,容许优先级最大为多少?在Linux中,这个上限为32768。
1 |
如果消息队列已满,mq_send函数可能会阻塞。如果设置了O_NONBLOCK标志位,这种情况下mq_send函数会返回失败,errno被置为EAGAIN。
接收消息
接收消息的接口定义如下:
1 | ssize_t mq_receive(mqd_t mqdes, char *msg_ptr,size_t msg_len, unsigned *msg_prio); |
对于POSIX消息队列而言,总是取走优先级最高的消息中最先到达的那个。
第二个参数msg_ptr指针用于存放消息体的内存缓冲区的地址,第三个参数msg_len是该内存缓冲区的大小。因为消息体的长度是不确定的,所以该缓冲区的大小不得小于最大消息体的长度(mq_msgsize),否则一旦消息体长度超过缓冲区的大小,就会失败,并返回EMSGSIZE错误。如何获得消息队列的最大消息长度?通过mq_getattr函数!
如果第四个参数msg_prio不是NULL,那么系统就将取到的消息体的优先级复制到msg_prio指向的整型变量。第四个参数如果为NULL,则表示压根不在乎消息体的优先级。
如果调用mq_receive函数时,消息队列中并没有消息,则函数陷入阻塞。如果设置了O_NONBLOCK标志位,则立即返回失败,并设置errno为EAGIAN。POSIX消息队列的本质就是个优先级队列。优先级高的消息总是被优先取出。从这个角度上看,System V消息队列更灵活,它可以让各个进程选取自己感兴趣的消息。
消息的通知
对于System V消息队列,当消息队列里面有消息到来时,消息队列却无法通知其他进程来取。对于消息队列中消息的消费者而言,只有两条路径:
- 调用msgrev函数,阻塞于此,直到消息队列里面有消息。
- 调用msgrev函数时设置IPC_NOWAIT标志位,周期性轮询。
从编程的角度看,期待有这样一种机制来解决上述困境:空的消息队列一收到消息,就给相应进程发出通知,被通知的进程收到通知后就可以及时地处理消息。这种机制称为异步通知机制。
POSIX消息队列就引入了这种机制。POSIX消息队列提供了两种异步通知的方法可供选择:
- 产生一个信号。
- 创建一个线程来执行一个事先指定的函数。
如果一个进程非常关心POSIX消息队列上出现的消息,那么该进程可以通过调用mq_notify函数来表示密切关注。
1 |
|
mq_notify函数的含义是调用进程通过该接口注册到消息队列,当空消息队列中出现一条消息时,消息队列就会通知到注册进程,也可以通过该接口注销调用进程曾经的注册。
关于消息通知,有以下几个注意事项:
- 只能有一个进程注册到特定的消息队列。如果一个消息队列上已经有注册进程了,那么后续调用mq_notify来注册的进程会返回EBUSY错误。
- 只有在消息进入空消息队列的情况下,才会向注册进程发送通知。如果注册时,消息队列非空,那么只有当消息队列被清空后,又有一条消息到达时,才会发出通知。
- 消息队列向注册进程发出通知后,会删除注册信息。之后任何进程都可以通过调用mq_notify函数来注册到消息队列,并接收通知了。
- 只有在当前不存在其他进程因在该队列上调用mq_receive()而陷入阻塞时,注册进程才会收到消息通知。否则阻塞在mq_receive()上的进程会“截胡”,读取该信息,而注册进程依然保持注册状态。
- 进程可以通过在调用mq_notify函数时传入一个值为NULL的sevp参数来撤销自己在消息队列上的注册信息。
前面讨论了消息通知的基本流程,但是当消息队列满足通知的条件时,又是如何通知到注册进程的?mq_notifiy函数的关键在第二个入参上,其结构体包含如下参数,若记不清成员变量,则可以通过man sigevent来查看手册。
1 | union sigval{ |
结构体sigevent的第一个成员sigev_notify用于选择采用哪种方式来通知注册进程,其有效值有以下三个:
- SIGEV_NONE:当消息到达空的消息队列时,不采取任何通知行动。
- SIGEV_SIGNAL:采用发送信号的方式通知进程。
- SIGEV_THREAD:通过调用
segev_notify_function中指定的函数来通知进程,就如同在一个新的线程中启动该函数一样。
信号通知
如果采用信号方式(SIGEV_SIGNAL),那么调用mq_notify的进程需要约定好希望收到哪种信号,其实现一般如下所示:
1 | struct sigevent sev; |
调用mq_notify函数的进程需要考虑该如何处理随时可能到来的信号。最容易想到的方法就是,在信号处理函数中,调用mq_receive函数,并进一步处理消息。很不幸的是,这种方法行不通。大多数函数都不是异步信号安全的,mq_receive函数也不是异步信号安全函数。更何况,还要在信号处理函数中执行复杂的逻辑,这就如同行驶在暗礁丛生的水域,很容易触礁沉船,这种做法是不明智的。等待信号来临不外乎有以下三种方法:
- sigsuspend
- sigwait
- signalfd
我们使用sigwait函数来等待信号的来临并处理消息。sigwait函数的引入,解决了信号的异步带来的很多问题。可以说这个函数提供了一种同步的方式来等待信号的降临。
1 |
|
将要等待的信号放置到set中,sigwait函数调用就会被阻塞,直到set集合中的某个信号处于未决状态,sigwait函数才会返回,信号的值记录在sig指针指向的整型变量中。需要注意的一点是,调用sigwait函数之前,set中的所有信号都要被阻塞,否则结果是不可预知的。以SIGUSR1为例,我们调用mq_notify函数,使消息降临空队列时,发送信号SIGUSR1,主流程等待SIGUSR1,收到信号时,去消息队列中取出该消息,整个流程如下:
1 | mqd_t mqd; |
需要注意的是,mq_notify函数注册之后,一旦发出信号完成使命,要想继续使用这种通知机制,需要再次调用mq_notify函数重新注册。使用sigsuspend函数和sigwait函数虽然都可以等到信号的来临,但是也阻塞了当前进程,这并不是明智的做法。更合理的做法是使用signalfd机制,配合select、pool或epoll等多路复用的接口,实现真正的事件驱动编程。
通过线程处理消息
POSIX消息队列提供的另外一种方法就是创建线程,执行预先约定的函数。在使用中,需要将sigev.sigev_notify设置成SIGEV_THREAD,同时设置好线程应该执行的函数,即将sigev.sigev_notify_function设置成约定好的函数。如果线程函数需要入参,则可以将任何变量的地址填入sigev.sigev_value.sival_ptr中,到达传递参数的目的。创建的线程具有默认的属性。如果对于线程有特殊的要求,则可以通过如下方法来设置:
1 | pthread_attr_t thread_attr; |
整体代码流程如下(示意代码,不完整):
1 | static void notify_function(union sigval sv) |
和信号通知机制一样,一旦创建线程执行完毕,通知机制就结束了,需要重新调用mq_notify函数来注册。
I/O多路复用监控消息队列
POSIX消息队列的通知功能或许在其他Unix平台上非常有用,但是在Linux平台下用处并不大,因为在Linux平台下有更友好、更强大的方法。在Linux系统中,消息队列描述符被实现成了文件描述符,因此完全可以使用I/O多路复用系统调用来监控消息队列。这种方法非常自然。
《Unix网络编程卷2:进程间通信》的5.6.6节给出了一个例子,如何使用select来监控POSIX消息队列。由于在某些平台下,消息队列描述符并不是文件描述符,所以不能直接使用select。Stevens大师给出的方法就相当地绕,具体方法如下。首先使用mq_notify函数来注册,确保当空的消息队列中出现消息时,进程会收到信号SIGUSR1;其次进程打开了一个管道,进程调用select监听管道的读取端;在SIGUSR1的信号处理函数中负责往管道的写入端写入一个字符。这样当消息降临空消息队列时,整个的逻辑流程就如图

该方案如此拧巴绝非大师之过,在操作系统不支持的情况下,只能如此处理。因为Linux支持在消息队列上执行select/poll/epoll,所以可以让这条路变得一马平川:

1 | mqd = mq_open(argv[1],O_RDONLY | O_NONBLOCK); |
注意上面的例子比较简易,仅仅是监听了一个消息队列,根据实际情况,可以同时监听多个消息队列和多个文件。只需要在上面代码的基础上打开其他文件或消息队列,将这些文件描述符置于select的监控之下,如果有来自文件描述符的输入(FD_ISSET来判断),添加相应的处理函数即可。这条特性并不是标准规定的,标准并未规定将消息队列描述符实现为文件描述符,因此使用I/O多路复用系统调用监控消息队列并不具备可移植性。
POSIX 信号量
POSIX信号量和System V信号量的作用是相同的,都是用于同步进程之间及线程之间的操作,以达到无冲突地访问共享资源的目的。在前面介绍System V信号量的时候也曾介绍过,Edsger Dijkstra提出了PV操作。所谓P操作,代表荷兰语中的Proberen(意思是尝试),也被称为递减操作或上锁操作。在POSIX术语中为等待(wait)。所谓V操作代表荷兰语单次Verhogen(意思是增加),也被称为递增操作、解锁操作和发信号(signal)操作。在POSIX术语中为挂出(post)。POSIX信号量的作用和System V信号量是一样的。但是两者在接口上有很大的区别:
- POSIX信号量将创建和初始化合二为一,这就解决了System V中可能出现竞争条件的问题。
- POSIX信号量的修改信号量值的接口(sem_post和sem_wait),一次只能修改一个信号量。与之对应的System V信号量其本质是信号量集,其下的semop函数一次可以修改多个信号量。
- POSIX信号量的修改信号量值的接口(sem_post和sem_wait),一次只能将信号量的值加1或减1。与之对应的System V信号量的semop函数,能够加上或减去一个大于1的值。
- POSIX信号量并没有提供一个等待信号量变为0的接口,而System V信号量中,semop函数则提供了这样的接口。
- POSIX信号量并没有提供UNDO操作,而System V信号量则提供了这样的操作。
从表面看,System V信号量的能力完胜POSIX信号量,事实上并非如此。System V信号量有过度设计之嫌,在大部分场景下,System V提供的第2、3和4条特性都没有什么用处,反而徒增接口的复杂程度。而POSIX信号量提供的接口异常清晰,易于理解和使用。POSIX信号量真正比System V信号量优越的地方在于,POSIX信号量性能更好。对于System V信号量而言,每次操作信号量,必然会从用户态陷入内核态,可以想象当加锁和解锁操作比较频繁的时候,时间上的开销也是很可观的。POSIX信号量则不然。只要不存在真正的两个线程争夺一把锁的情况,那么修改信号量就只是用户态的操作,并不会牵扯到内核。在竞争并不激烈的情况下,POSIX的性能要远远高于System V信号量。有得必有失。因为POSIX信号量不会每次操作都去求助内核,所以获得了性能上的提升,但却因此而失去了内核的强大后援。System V信号量支持UNDO操作,当用户进程异常消亡之后,内核会肩负起为进程还债的责任。但是POSIX信号量却没有这个特性。
POSIX提供了两类信号量:有名信号量和无名信号量。这两种信号量的本质都是一样的,最重要的sem_wait接口和sem_post接口也都是一样的。如此说来,两种信号量有何不同呢,各自应用在哪些场景呢?
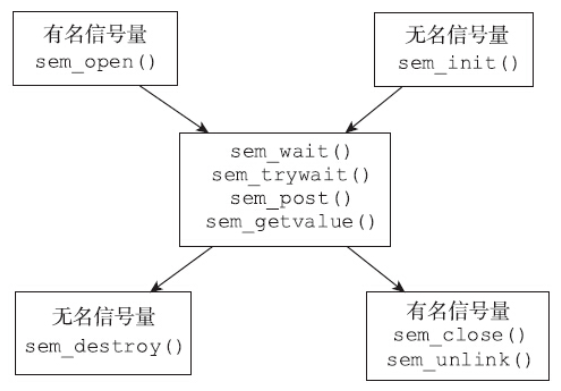
无名信号量,又称为基于内存的信号量,由于其没有名字,没法通过open操作直接找到对应的信号量,所以很难直接用于没有关联的两个进程之间。无名信号量多用于线程之间的同步。
有名信号量由于其有名字,多个不相干的进程可以通过名字来打开同一个信号量,从而完成同步操作,所以有名信号量的操作要方便一些,适用范围也比无名信号量更广。
创建、打开、关闭和删除有名信号量
创建或打开有名信号量,需要调用sem_open函数,其接口定义如下:
1 |
|
第二个参数oflag标志位支持的标志包括O_CREAT和O_EXCL标志位。如果带了O_CREAT标志位,则表示要创建信号量。
第三个参数mode表示创建的新信号量的访问权限,标志位和open函数一样,mode参数的值也会根据进程的umask来取掩码。
第四个参数value是新建信号量的初始值。创建和赋初值都是由一个接口来完成的,这样就不会出现System V信号量可能出现的初始化竞争的问题了。value的值在最小值0和最大值SEM_VALUE_MAX之间。SUSv3要求最大值至少等于32767,对于Linux而言,这个限制为INT_MAX。
当sem_open函数失败时,返回SEM_FAILED,并且设置errno。
注意,不要尝试创建sem_t结构体的副本,下面这段代码的做法是错误的:
1 | sem_t *sem_p,sem_dup; |
上面定义了sem_p的副本sem_dup,但在副本上执行sem的相关操作,行为是不可预知的,不要这样使用。切记,后面所有的调用都要用通过sem_open返回的sem_t类型的指针来进行操作,而不能使用结构体的副本。当一个进程打开有名信号量时,系统会记录进程与信号的关联关系。调用sem_close时,会终止这种关联关系,同时信号量的进程数的引用计数减1。关闭信号量的接口定义如下:
1 |
|
进程终止时,进程打开的有名信号量会自动关闭。当进程执行exec系列函数时,进程打开的有名信号量会自动关闭。但是关闭不等同于删除,如果要删除信号量则需要调用sem_unlink函数,其接口定义如下:
1 |
|
将有名信号量的名字作为参数,传递给sem_unlink,该函数会负责将该有名信号量删除。由于系统为信号量维护了引用计数,所以只有当打开信号量的所有进程都关闭了之后,才会真正地删除。
信号量的使用
信号量的使用,总是和某种可用资源联系在一起的。创建信号量时的value值,其实指定了对应资源的初始个数。当申请该资源时,需要先调用sem_wait函数;当发布该资源或使用完毕释放该资源时,则调用sem_post函数。
等待信号量
1 |
|
如果调用sem_wait函数时,信号量的当前值大于0,那么sem_wait函数立刻返回。否则sem_wait函数陷入阻塞,待信号量的值大于0之后,再执行减1操作,然后成功返回。如果陷入阻塞的sem_wait函数被信号中断,则返回-1,并且置errno为EINTR。
使用sigaction注册信号处理函数时,无论是否使用了SA_RESTART标志位,都不会自动重启系统调用。如果仅仅是尝试等待信号量,而不想陷入阻塞,则可以调用sem_trywait函数,其接口定义如下:
1 | int sem_trywait(sem_t *sem); |
sem_trywait会尝试将信号量的值减1,如果信号量的值大于0,那么该函数将信号量的值减1之后会立刻返回。如果信号量的当前值为0,那么sem_trywait也不会陷入阻塞,而是立刻返回失败,并置errno为EAGAIN。
若资源当前不可得,那么sem_wait调用就可能会陷入无限期阻塞,而sem_trywait调用则选择立刻返回失败,绝不阻塞。
除了这两种选择,系统还提供了第三种选择:有限期等待,即sem_timedwait函数。sem_timedwait函数的接口定义如下:
1 | int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout); |
第二个参数为一个绝对时间。可以使用gettimeofday函数获取到struct timeval类型的当前时间,然后将timeval转换成timespec类型的结构体,最后在该值上加上想等待的时间。或者调用clock_gettime函数,直接获得timespec结构体类型的变量表示当前时刻,然后在结构体上加上想等待的时间,作为第二个参数传给sem_timedwait函数。如果超过了等待时间,信号量的值仍然为0,那么返回-1,并置errno为ETIMEOUT。
发布信号量
sem_post函数用于发布信号量,表示资源已经使用完毕,可以归还资源了。该函数会使信号量的值加1。sem_post接口定义如下:
1 |
|
如果发布信号量之前,信号量的值是0,并且已经有进程或线程正等待在信号量上,此时会有一个进程被唤醒,被唤醒的进程会继续sem_wait函数的减1操作。
如果有多个进程正等待在信号量上,那么将无法确认哪个进程会被唤醒。当函数调用成功时,返回0;失败时,返回-1,并置errno。
当参数sem并不指向合法的信号量时,置errno为EINVAL;
当信号量的值超过上限(即超过INT_MAX)时,置errno为EOVERFLOW。
获取信号量的值
sem_getvalue函数会返回当前信号量的值,并将值写入sval指向的变量,代码如下:
1 |
|
如果信号量的值大于0,含义自不必说;但是如果信号量的值等于0,同时又有很多进程或线程阻塞在信号上,那么应该返回0还是返回一个负值——其绝对值等于等待进程的个数?看起来后者更有意义,因为从该值可以获知到竞争的激烈程度,但是Linux还是选择返回0。当sem_getvalue返回时,其返回的值可能已经过时了。从这个意义上讲,该接口的意义并不大。
无名信号量的创建和销毁
无名信号量,由于其没有名字,所以适用范围要小于有名信号量。只有将无名信号量放在多个进程或线程都共同可见的内存区域时才有意义,否则协作的进程无法操作信号量,达不到同步或互斥的目的。所以一般而言,无名信号量多用于线程之间。因为线程会共享地址空间,所以访问共同的无名信号量是很容易办到的事情。或者将信号量创建在共享内存内,多个进程通过操作共享内存的信号量达到同步或互斥的目的。
初始化无名信号量
无名信号量的初始化是通过sem_init函数来完成的。
1 |
|
第二个pshared参数用于声明信号量是在线程间共享还是在进程间共享。0表示在线程间共享,非零值则表示信号量将在进程间共享。要想在进程间共享,信号量必须位于共享内存区域内。
无名信号量的生命周期是有限的,对于线程间共享的信号量,线程组退出了,无名信号量也就不复存在了。对于进程间共享的信号量,信号量的持久性与所在的共享内存的持久性一样。无名信号量初始化以后,就可以像操作有名信号量一样操作无名信号量了。
销毁无名信号量
销毁无名信号量的接口定义如下所示:
1 |
|
sem_destroy用于销毁sem_init函数初始化的无名信号量。只有在所有进程都不会再等待一个信号量时,它才能被安全销毁。对Linux实现而言,省略sem_destroy函数,也不会带来异常。但是为了安全性和可移植性,还是应该在合适的时机正常销毁信号量。
信号量与futex
使用POSIX信号量,链接的时候需要加上-lpthread,而不是-lrt。由此可以看出POSIX信号量与NPTL线程库渊源甚深。
讲线程时曾提到过,互斥量是建立在快速用户空间互斥体(英文全名为fast userspace mutex,简称futex)基础上的。POSIX信号量也是架构在futex基础之上的。
快速用户空间互斥体,是一种用户态和内核态协同工作的同步机制。同步的进程需要一段共享内存,futex变量就位于这段内存之中。当进程尝试进入或退出互斥区时,首先会检查共享内存中的futex变量,如果没有竞争发生,则原子地修改futex变量,无须执行系统调用。如果通过访问futex变量的值发现有竞争发生,则执行相应的系统调用去完成相应的处理。
对于线程间同步,因为同一个进程下的多个线程共享该进程的地址空间,所以同时操作某个futex变量并不是特别难以做到的事情。如果是用于进程间的同步,则首先需要一块内存空间,而且要让多个进程都可以操作该内存空间,这就牵扯到共享内存了。事实上调用sem_open函数来创建POSIX信号量时,使用了后面会介绍到的mmap,并在多个进程之间共享文件的内容。
下面的代码摘自glibc的sem_open函数:
1 | /* Create the initial file content. */ |
每创建一个名为name的信号量,在/dev/shm下就会多出一个名为sem.name的文件。该文件的内容是sem_t结构体:
1 |
|
在x86架构下,32位系统里,该结构体的大小是16字节,在x86_64架构下,该结构体的大小是32字节。事实上,真实存放的内容是new_sem结构体:
1 | union |
下面创建一个名为res_88的信号量,创建该信号量时,将信号量的值初始化为88。代码如下所示:
1 | sem_t* sem = sem_open(argv[1],O_RDWR|O_CREAT|O_EXCL,S_IRUSR|S_IWUSR,88); |
我们可以通过查看/dev/shm/sem.res_88来查看该信号量的情况:
1 | manu@manu-rush:~$ od -x /dev/shm/sem.res_88 |
其文件内容的含义如图:

从输出中的00580000(0x58=88)可知,当前信号量的值是88。当将信号量的值减少到零,并且有两个进程在等待信号量时
输出中的0002 0000 0000 0000(0x02)表示当前有两个进程等待在该信号量上。对于POSIX信号量而言,需要同步的进程通过mmap将文件内容映射进了进程的地址空间。对这段内存的修改,其他进程也可见。内核提供了futex系统调用,其接口定义如下:
1 |
|
第一个参数uaddr是用户空间的一个地址,里面存放的是整型变量。
第二个参数op用于存放操作命令,最基本的两个操作命令FUTEX_WAIT和FUTEX_WAKE。当op是FUTEX_WAIT时,会原子地检查uaddr地址存放的int值是否等于val,如果是,那么内核会使进程陷入休眠,同时把进程挂到uaddr对应的等待队列上。当op是FUTEX_WAKE时,最多唤醒val个等待在uaddr上的进程。
内存映射mmap
内存映射mmap是POSIX共享内存的基础,内存映射完成了大量的基础性工作,临门一脚交给了共享内存。事实上POSIX共享内存也要和mmap配合使用。不理解mmap就不能很好地理解POSIX共享内存。
更重要的是,纵然不提共享内存,mmap这个系统调用也是非常重要的,其重要程度远远超过POSIX共享内存。只要你在Linux平台上工作,每天就一定会执行无数次的mmap系统调用,不管是直接地还是间接地。
当你执行哪怕是最简单的ls命令时,mmap系统调用在背后都会默默地帮你加载动态链接库,当你调用malloc函数分配大于MMAP_THRESHOLD大小(默认是128KB)的内存时,mmap系统调用会躲在malloc背后支撑;当你调用pthread_create创建线程时,mmap系统调用会帮你分配好线程栈;当你创建POSIX信号量时,mmap会默默帮你开辟一段空间存放futex变量……
mmap系统调用的作用是在调用进程的虚拟地址空间中创建一个新的内存映射。根据内存背后有无实体文件与之关联,映射可以分成以下两种:
- 文件映射:内存映射区域有实体文件与之关联。mmap系统调用将普通文件的一部分内容直接映射到调用进程的虚拟地址空间。一旦完成映射,就可以通过在相应的内存区域中操作字节来访问文件内容。这种映射也被称为基于文件的映射。
- 匿名映射:匿名映射没有对应的文件。这种映射的内存区域会被初始化成0。
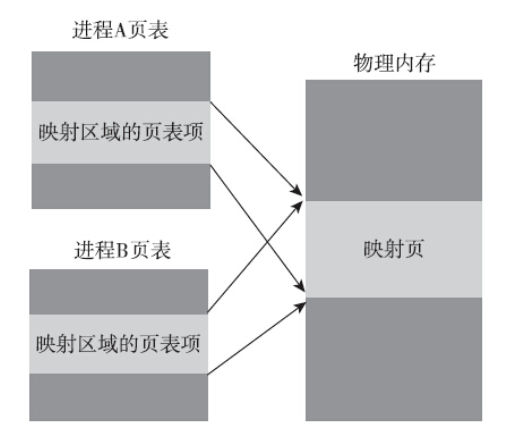
一个进程映射的内存可以与其他进程中的映射共享物理内存。所谓共享是指各个进程的页表条目指向RAM中的相同分页。
这种内存映射的共享,会在以下两种情况下发生:
- 通过fork,子进程继承了父进程通过mmap映射的副本。
- 多个进程通过mmap映射了同一个文件的同一个区域。
无论映射背后有无实体文件与之关联,这个进程之间共享映射的特性都是非常有用的。我们知道,进程的虚拟地址空间是彼此隔离的,一个进程不能直接操作另一个进程虚拟地址空间中的内存。但是mmap系统调用给出了两个办法,让多个进程可以共享一片内存区域。
看到第一种方式,即通过fork子进程继承父进程通过mmap映射的副本,大家的心中可能会隐隐有种不安。虽然子进程拷贝了父进程的内存,但是父子进程的页表并不是始终都指向同一物理内存的,一旦父子进程中有一个尝试修改内存的内容时,内核就不得不发起写时复制,分配新的物理内存。从此父子进程分道扬镳,彼此再也看不到对方对内存的改动。
对于进程malloc出来的内存,栈上的变量的确如此,fork之后父子进程并不是共享同一块映射。但是通过mmap系统调用创建的内存映射却可以做到进程之间共享同一个内存映射。当然进程之间要不要共享映射也是可以选择的,这取决于该映射是私有映射还是共享映射。
- 私有映射(MAP_PRIVATE):在映射内容上发生的变更对其他进程不可见。对于文件映射而言,变更不会同步到底层文件中。对映射内容所做的变更是进程私有的。事实上,内核使用了写时复制技术来完成这个任务。未对映射内容进行修改操作时,页面仍然是共享的。一旦有进程试图修改其中一个分页的内容时,内核首先会为该进程创建一个新的分页,并将需要修改的分页中的内容拷贝到新分页中。
- 共享映射(MAP_SHARED):在映射内容上发生的所有变更,对所有共享同一个映射的其他进程都可见。对于文件映射而言,变更会同步到底层的文件中。很明显,共享映射是用于进程间通信的。
内存映射根据有无文件关联,分成文件与匿名;根据映射是否在进程间共享,分成私有和共享。这两个维度两两组合,内存映射共分成4种类型,其各自的用途如表

内存映射的相关接口
mmap函数的接口定义如下
1 |
|
这个函数的参数比较多。其中fd、offset和length这三个参数指定了内存映射的源,即将fd对应的文件,从offset位置起,将长度为length的内容映射到进程的地址空间。
对于文件映射,调用mmap之前需要调用open取到对应文件的文件描述符。
第一个参数addr用于指定将文件对应的内容映射到进程地址空间的起始地址。一般来讲为了可移植性,该参数总是指定为NULL,表示交给内核去选择合适的位置。
第三个参数prot用于设置对内存映射区域的保护,它的合法值及其含义如表

flags参数用于指定内存映射是共享映射还是私有映射,也用于指定内存映射是文件映射还是匿名映射。flags可选的标志位及含义如表:

其中调用mmap函数时,MAP_SHARED和MAP_PRIVATE标志位,两者必须指定一个。flags中另一个可选的标志位是MAP_FIXED。如果指定了该标志位,那么表示函数调用者铁了心地要把内容映射到对应的地址上。这种情况下,addr一般要求按页对齐。如果内核无法映射文件到该指定位置,则调用失败。如果地址和长度指定的内存区域和已有映射有重叠部分,那么重叠区的原始内容将被丢弃,然后填入新的内容。使用该选项需要非常了解进程的地址空间,否则不建议使用。
需要注意的是mmap系统调用的操作单元是页。参数addr和offset都必须按页对齐(一般传NULL和0即可),即必须是页面大小的整数倍。在Linux下,页面大小是4096字节,该值可以通过getconf命令来获取到:
1 | getconf PAGESIZE |
对于编程接口,Linux提供了sysconf函数来获取到相关配置项的值:
1 |
|
对于获取页面大小而言,可以通过如下代码获取到页面的大小:
1 | long pagesize = sysconf(_SC_PAGESIZE); |
在进程的地址空间里,映射区域总是页面的整数倍。但是有些时候,mmap传递的length值并非页面的整数倍,比如文件映射时,文件的大小或要映射进内存的区域并非页面的整数倍,这时候,mmap会按照页面的大小向上取整,多出来的内存区域(最后一个有效字节到映射区域边界)会填充0。
当mmap调用成功时,则返回映射区域的起始地址,如果失败,则返回MAP_FAILED,并置errno。如果不再需要对应的内存映射了,可以调用munmap函数,解除该内存映射:
1 |
|
其中addr是mmap返回的内存映射的起始地址,length是内存映射区域的大小。执行过munmap后,如果继续访问内存映射范围内的地址,那么进程会收到SIGSEGV信号,引发段错误。需要注意的是,关闭对应文件的文件描述符并不会引发munmap。
如果创建内存映射时flags中带上了MAP_PRIVATE标志位,那么解除该内存映射时,调用进程对内存映射的所有改动都会被丢弃。
1 | int msync(void *addr, size_t len, int flags ); |
一般说来,进程在映射空间的对共享内容的改变并不直接写回到磁盘文件中,往往在调用munmap()后才执行该操作。
可以通过调用msync()实现磁盘上文件内容与共享内存区的内容一致。
共享文件映射
共享文件映射的建立和使用
创建共享文件映射的步骤如下所示。
(1)打开文件,获取文件描述符fd,这一步是通过open来完成的。
(2)将文件描述符作为fd参数,传给mmap函数。
整个步骤如下面的伪代码所示:
1 | fd = open(...); |
第(1)步打开文件时设置的权限必须要和mmap系统调用需要的权限相匹配。具体来讲就是:
- 打开时,必须允许读取,即
O_RDONLY和O_RDWR至少要指定一个。 - mmap调用时,如果prot参数中指定了
PROT_WRITE,并且flags中指定了MAP_SHARED,那么打开时,必须带有O_RDWR标志位。
open时需要注意,并非所有的文件都支持mmap操作,比如管道文件就不支持mmap操作。
mmap完成之后关闭文件描述符并不会导致内存映射被解除,因此,在没有其他需要的情况下,可以调用close关闭文件。
mmap这个接口容易产生的一个误解是,调用mmap时,真的已经把文件对应区域的内容读取到了内存的对应位置。事实上并非如此,mmap仅仅是建立了两者之间的关联。当第一次读取映射区的内容或修改映射区的内容时,会引发缺页中断(page fault),这时候才会真正地将文件的内容加载到内存的对应位置。
当mmap调用成功之后,共享映射在进程地址空间中的位置,以及和对应文件的关系如图:
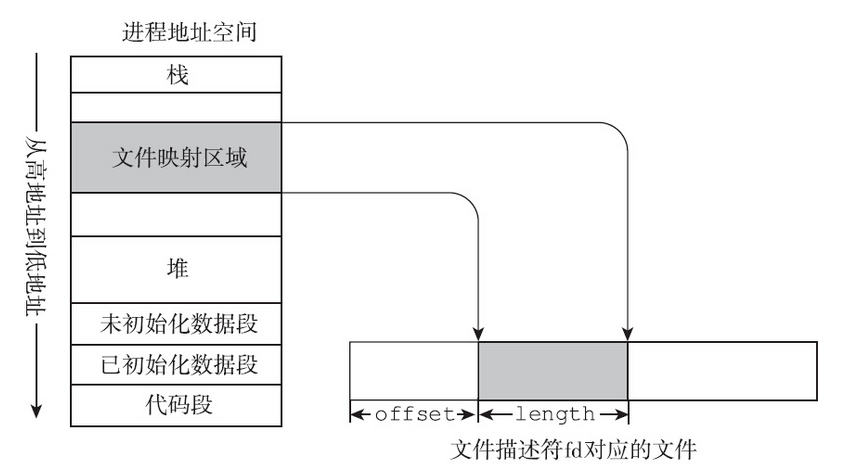
文件是有长度的,所以正常情况下offset和length参数应该遵循一定的限制:offset应小于文件的长度,并且offset+length也应小于文件的长度。很有意思的是,mmap函数并不检查offset和size定义的区域是否在文件的范围之内。示例代码如下:
1 |
|
上面的代码中,将文件结尾之后的1M字节映射到进程的地址空间,映射的区域和文件完全没有交集。在这种情况下,mmap也不会因offset和length参数而返回MAP_FAILED,而是正常地返回。
此处说的是不检查offset和length定义的范围是否在文件长度范围之内,并不是说不检查offset和size的值。mmap调用要求offset必须为系统分页的整数倍,这个限制始终存在。如若offset的值不是系统分页的整数倍,mmap会返回MAP_FAILED,并置errno为EINVAL。
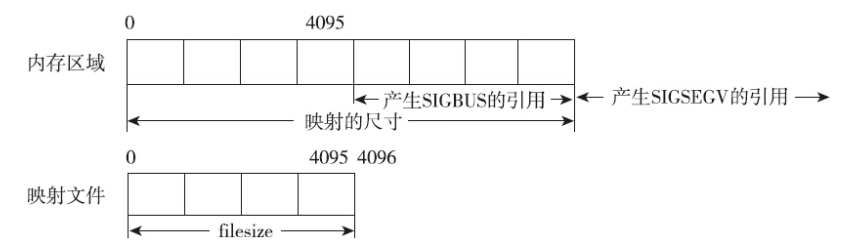
尽管mmap不检查对应区域是否落在文件的长度范围之内,但是这并不意味着随意建立的映射也能正常使用。使用共享文件映射需要谨慎,否则很容易触发错误。最容易想到的一种错误就是没有映射某区域却强行访问,而且无论该区域是否落在文件的长度范围以内。这种访问会引发段错误,产生SIGSEGV信号。该信号的默认动作是进程终止并产生核心转储文件。
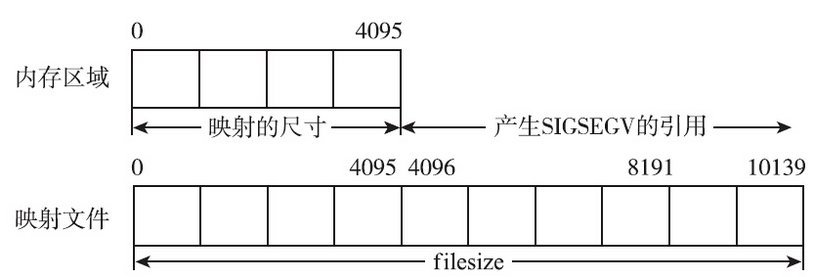
这种错误是一目了然的。但是如果调用mmap时length不是系统分页大小(4KB)的整数倍时,情况就会稍稍有些复杂。文件的长度为10KB,但是调用mmap时,将文件的前5KB映射到了进程的地址空间。这种情况下,真正映射的大小会被向上舍入成系统分页的整数倍,对于这个例子而言,虽然mmap调用指定了5KB,但是真实映射了8KB的大小。用户访问mmap返回基地址偏移8KB之内的内存地址,都不会触发SIGSEGV信号。访问基地址偏移8KB之后的地址,才会触发SIGSEGV信号。
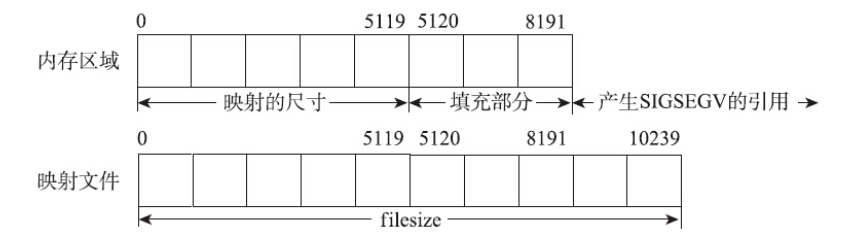
另外一种错误是访问的映射地址虽然在mmap映射的内存区域之内,但并不在文件长度的范围以内,这种情况会导致SIGBUS信号的产生,该信号的默认动作也是进程终止并产生核心转储文件。这种错误之所以会出现时因为mmap并不会检查offset和size定义的区域是否落在文件长度范围以内。既然建立映射的时候不检查,那么真正访问对应内存地址的时候,就可能触发错误。
这种错误也是很明显的。但是当文件的大小不是系统分页整数倍时,也会带来一定的特殊情况。
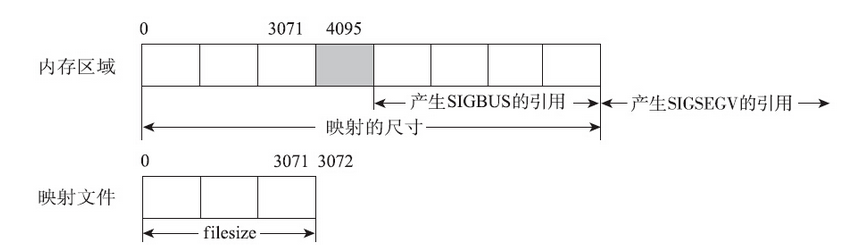
尽管文件的长度是3KB,但是mmap映射了一个长度为8KB的内存区域。4KB~8KB这个范围自不必说,超出了文件的范围,访问时一定会触发SIGBUS信号。但是比较挠头的是3KB~4KB这个范围的内存。因为这个范围已经不在文件的长度范围之内了,却又和文件的有效映射同处一个页面。这种情况下允许访问,而且不会触发SIGBUS信号。至于要访问8KB之后的内存,那已经是尝试访问映射范围之外的内存了,会触发上一种错误,即产生SIGSEGV信号。
共享文件映射的用途
共享文件映射主要用于两个方面:操作文件和进程间通信。
共享文件映射的第一个用途是操作文件。
Linux提供了read、write、lseek等操作文件的系统调用,通过这些接口可以操作文件。共享文件映射给出了另外一种操作文件的方法。
共享文件映射将文件的内容映射到了进程的地址空间。对应区域中的内容来源于文件,对映射内容所做的修改,都会自动反应到文件上,内核会负责将修改最终同步到底层的块设备。因此共享文件映射区域的内存,就等同于对文件的读写。访问过的文件页面,很可能还会继续访问。不同进程很可能会访问同一文件页面。如果每次访问文件的内容,都要操作底层块设备,那性能就会很差。因此现代的操作系统都提供了文件缓存,Linux也不例外。
Linux提供了页高速缓存(Page Cache,也称页缓存)用以减少对磁盘的访问。在大部分情况下,应用程序都会通过页高速缓存来读写文件。当读取文件的某一部分内容时,内核首先会从页高速缓存中查找所读取的数据是否存在对应的页面,如果请求的页面不在页高速缓存之中,那么内核就会负责分配页面并添加到页高速缓存中,然后从磁盘上读取对应的数据来填充它。如果物理内存足够大,空闲页面足够多,那么该页将长期保留在页高速缓存中,使得其他进程访问该页数据时不需要再访问磁盘。当应用程序向文件写入时,会直接修改页高速缓存中的数据,但是并不会立刻写入磁盘,而是将该页标记成脏页,由内核负责在合适的时机将脏页回写到磁盘中。
调用read也好,调用write也罢,事先都要准备用户空间缓冲区buffer。读取时,将读到的内容复制到该buffer中;写入时,再将buffer中的内容写入文件中。
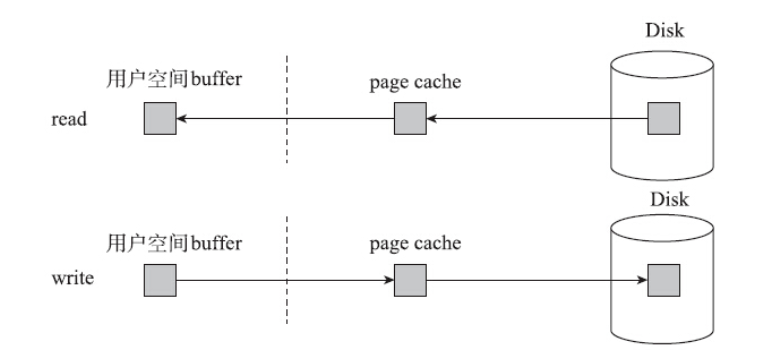
对于read和write接口而言,姑且不论磁盘与页高速缓存之间如何交互,页高速缓存和用户空间缓冲区之间的数据传输是不可避免的。但是如果使用mmap来操作文件,则不需要这次复制。mmap对共享文件映射的操作,直接作用在页高速缓存上,节省了一次数据传输。这是不是意味使用mmap来操作文件要比使用read/write的性能更好呢?大家很容易产生这种想法,但这种想法有些想当然。随着硬件的发展,内存拷贝消耗的时间已经极大地降低了,可是mmap访问文件内容,会引起缺页中断(page fault)。相对于内存拷贝而言,缺页中断的开销更大,加上创建内存映射、解除内存映射及更新硬件内存管理单元的翻译后备缓冲器(TLB)的开销,大部分情况下(不考虑刻意构造的场景),mmap的性能反而要低于read和write。
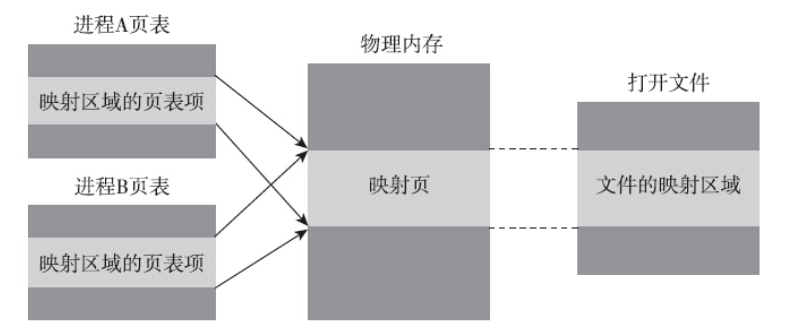
共享文件映射的第二个用途是进程间通信。
进程的地址空间是彼此隔离的,一个进程一般不能直接访问另一个进程的地址空间。通过共享文件映射,两个进程的映射区域指向了同一个物理内存(即前面提到的页高速缓存),这就给进程间通信提供了可能。如果两个进程的共享文件映射都源自同一个文件的同一个区域,那么一个进程对映射区域的修改,对于另外那个进程是立刻可见的,同时内核会负责在合适的时机将修改同步到底层文件。之所以能够做到这点,是因为两个映射区域的对应分页都指向了同一个页高速缓存(Page Cache)。
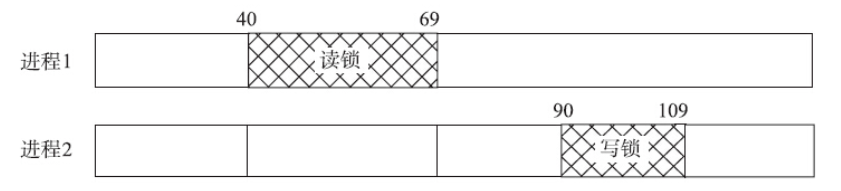
所有的共享内存都会遇到的问题是同步。无论是System V信号量还是POSIX信号量,都可以用于同步对共享内存的操作。除此以外,记录锁也比较适用于操作共享文件映射。fcntl函数提供了记录锁的功能,和flock函数提供的文件锁功能相比,fcntl提供的记录锁可以提供更细粒度的控制。flock函数提供的锁是粗放型锁,锁定的是整个文件,无法锁定文件的某个区域。fcntl提供的锁可以锁定文件的某个区域,如图所示,这样就减少了因竞争而陷入阻塞的概率,从而提高了性能。
fcntl函数接口的定义如下所示:
1 |
|
其中与记录锁相关的cmd为:
- F_SETLKW:尝试锁定文件的对应区域。如果该区域已经被锁定,则陷入阻塞。
- F_SETLK:尝试锁定文件的对应区域。如果该区域已经被锁定,则立刻返回-1。
- F_GETLK:仅仅是查询锁的信息,并不会真正地对某区域加锁。
当执行加锁相关操作时,需要用到flock结构体,代码如下:
1 | struct flock { |
其中l_type用于指定锁的类型,以及指定解锁操作,其合法值及其含义如下:
- F_RDLCK:读锁
- F_WRLCK:写锁
- F_UNLCK:解锁
l_whence的含义和lseek函数的第三个参数whence的含义一样,表示如何解释偏移量,有效值有SEEK_SET, SEEK_CUR, SEEK_END。l_whence参数结合l_start和l_len参数,定义了文件的某个区域。
使用fcntl对文件的某个区域加锁解锁的方法如下示例代码所示:
1 | struct flock fl; |
通过上面的讨论可以看出,fcntl提供的记录锁非常适用于同步共享文件映射的操作。可以轻易地做到读写请求分开,以及更细粒度、更灵活的控制。
注意 flock和fcntl都属于劝告式锁(Advisory Lock),如果同步的进程遵循游戏规则,操作之前先申请锁,就能起到同步的作用;但是如果进程无视劝告式锁的存在,不遵循游戏规则,不申请锁直接操作文件或文件的某个区域,内核也不会阻止这种操作。
共享文件映射的内核实现
对于共享文件映射而言,最大的谜团是:进程地址空间彼此独立,互不干扰,可是多个进程通过mmap映射同一文件的同一区域时,却指向了同一物理页面,修改彼此可见。内核是如何做到的?前面已经提到过,答案是通过页高速缓存。在追踪mmap内核实现之前,首先来简单介绍下页高速缓存。
引入页高速缓存的目的是为了性能。现在访问的文件的某个页面,将来可能还会再访问。如果不将页面缓存进内存,那么每次读取文件,就都不得不操作慢速的块设备,这会极大地影响性能。页高速缓存该如何组织多个页面,以便在需要时可以快速定位到这些缓存页面呢?对于单个文件来说,有些文件系统支持TB级别的文件(比如ext4文件系统就已经支持16TB的单个文件了),4KB一个页面的情况下,页面的数目是巨大的。
如果不能高效地组织页面,那么花费在查找页面上的时间就可能会很长,届时纵然页面已经在缓存中,也会因查找缓存页面太慢而导致性能的急剧恶化。内核使用了基数树(radix tree)来解决这个难题,只要找到文件对应的基数树的根,就可以快速定位到与文件对应的页面(如果它在页高速缓存中的话)上。现在问题就转变成了:当进程操作文件时,如何快速找到与文件对应的基数树。
对于这个话题,毛德操老爷子在《Linux内核情景分析》一书的5.6节中有高屋建瓴的分析。内核文件层有三个核心的数据结构:file、dentry和inode。虽然三种数据结构都可以通过各种指针来跳转,找到与文件对应的页高速缓存,但是inode是和页高速缓存关系最密切的数据结构。struct file数据结构是进程层面的概念,提供的是目标文件的一个上下文信息。对于同一个文件,不同进程可以在该文件上建立不同的上下文,甚至同一个进程也可能因多次打开文件而建立起多个上下文。换句话说,数据结构struct file和实体文件并不是一对一的关系,而是多对一的关系。dentry结构体虽不是进程层面的概念,但是dentry和实体文件也不是一对一的关系,通过文件连接,可以为已存在的文件建立别名。只有inode结构最适合和文件的页缓存关联,因为inode和实体文件是一对一的关系。
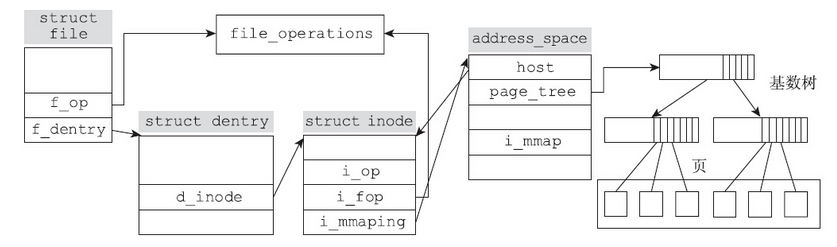
上图给出了内核中文件与页缓存相关的数据结构。不难看出,当进程通过文件系统接口(read/write等),不难找到与文件对应的inode。Linux内核引入了地址空间address_space这个数据结构来管理页高速缓存。inode中的i_mmaping成员变量指向对应的address_space结构体。不论多少个进程通过文件系统API来操作文件,也不论多少个进程通过mmap建立共享文件映射来操作文件,同一个文件只对应一个address_space结构体。通过该数据结构就能找到与页高速缓存对应的基数树,进而找到对应的缓存页(如果存在的话)。通过上图可以很清晰地看出,当通过文件系统接口进行读写时,如何找到与文件对应的缓存页面。但是mmap内存映射区域和页高速缓存如何建立联系却并不明晰。下面我们跟踪mmap系统调用的实现来一探究竟。
调用mmap函数,进入内核之后首先会执行到arch/x86/kernel/sys_x86_64.c中的如下函数:
1 | SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len, |
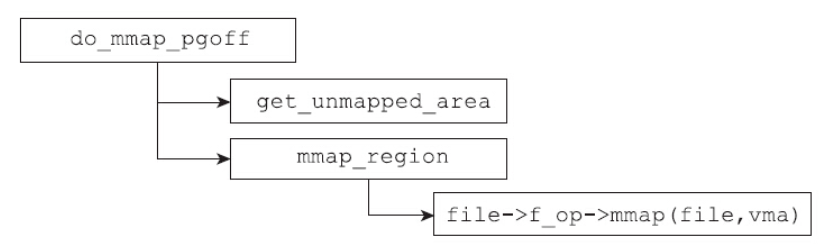
该函数非常简单,把绝大部分工作都委托给了内核的sys_mmap_pgoff函数。该函数定义在mm/mmap.c中,其原型声明如下:
1 | SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len, |
这个函数是分析mmap实现的起点。而该函数将大部分工作都委托给了do_mmap_pgoff。该函数的总体流程如图所示。
内核为了管理进程的地址空间,引入了虚拟内存区域(virtual memory area,VMA)的数据结构。vm_area_struct结构体描述了进程地址空间内一个独立的内存范围。当通过mmap函数创建一个共享文件映射(当然不仅仅是共享文件映射)的时候,内核就会为进程分配一个新的vm_area_struct结构体。每一个vm_area_struct都对应进程地址空间中的唯一一个内存区间。其中成员变量vm_start指向区间的开始地址(vm_start本身属于对应内存区间),vm_end指向内存区间的结束地址(vm_end本身不属于对应内存区间),vm_end减去vm_start的值即为内存区间的长度。对于共享文件映射而言,该长度为调用mmap时指定的length向上取整为页面大小的整数倍。
vm_area_struct结构体中的vm_flags成员变量记录的是该内存区域的VMA标志位。该标志位记录了对应内存区域的一些属性。比如VM_READ标志位表示对应的页面可读取;VM_WRITE标志位表示对应的页面可写;VM_EXEC标志位表示对应的页面可执行;VM_LOCKED表示对应的页面被锁定,等等。
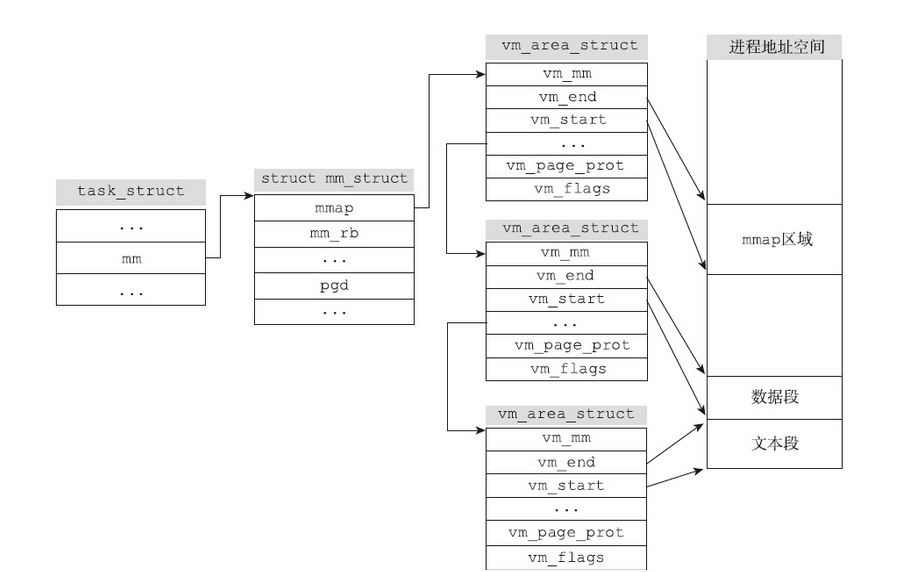
如果虚拟内存区域和文件相关联,那么vm_area_struct结构体中的vm_file成员变量就指向与文件对应的struct file结构。通过该指针,虚拟内存区域就可以和文件发生关联。另外一个很重要的成员变量是vm_ops。该成员是一个指针,指向与内存区域相关的操作函数。
1 | struct vm_operations_struct { |
因为vm_area_struct是一个通用的数据结构,可以代表任意类型的内存区域,因此不同的VMA就有不同的操作函数,vm_ops也就指向了不同的操作函数集合。VMA操作函数集合中的fault函数用于应对这种场景:访问的页面并没有出现在物理内存中;而page_mkwrite用于应对页面为只读,应用程序却尝试写入的情况。这两个函数都会被缺页中断处理程序调用,以处理不同的情景。
下面以主流的ext4文件系统为例,追踪一下整个流程。ext4文件系统中inode的i_fop注册成ext4_file_operations。ext4_file_operation的定义位于fs/ext4/file.c中,其中与mmap相关的操作函数定义如下:
1 | const struct file_operations ext4_file_operations = { |
当mmap系统调用在mmap_region中执行file->f_op->mmap(file,vma)时,执行的就是ext4_file_mmap函数。因此对于ext4文件系统而言,文件映射的调用路径就变成了如图所示的路径。
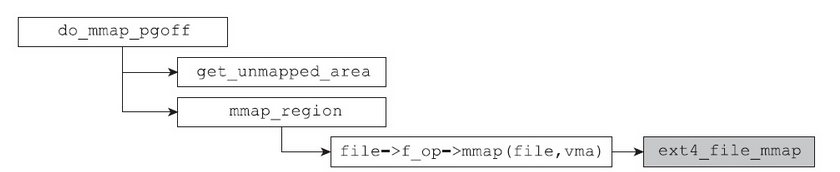
该函数异常简单,简单到我不介意将全函数都贴在这里:
1 | static int ext4_file_mmap(struct file *file, struct vm_area_struct *vma) |
这个ext4_file_map函数仅仅安装了一个内存区操作函数,即把vma的vm_ops指针指向了ext4_file_vm_ops。
1 | static const struct vm_operations_struct ext4_file_vm_ops = { |
注意整个mmap调用的过程中并没有对文件的大小做过判断。换言之,哪怕文件的大小只有100个字节,mmap仍然可以将文件映射到1MB的内存空间。下面的示例代码中,尽管映射了比文件的大小还要多1MB的空间,但是mmap调用依然会成功。
1 | /*省略了error handler*/ |
mmap之后,尽管进程的虚拟地址空间内已经有一块内存区域和文件相对应,但内核并没有将文件的内容加载到内存区域。将虚拟内存区域vma的vm_ops指向ext4_file_vm_ops实例,其实是埋下了伏笔。一旦将来需要访问映射区域的页面,尽管物理内存中没有,但依然可以依靠VMA操作函数集里的对应函数来处理这个危机。
知乎上有一个提问是“有哪些老鸟程序员知道而新手不知道的小技巧”,该提问下有一个很意思很有良心的回复:
把觉得不靠谱的需求放到最后做。很可能到时候需求就变了。
——知乎用户mu mu
这个技巧在计算机科学上也被广泛地使用着。写时复制采用的是这种思想,接下来要介绍的请求调页也是如此。在操作系统领域,未雨绸缪从来不是一个褒义词,因为这往往意味着会做大量的无用功。
请求调页是一种动态内存分配技术,该技术把页面的分配推迟到不能再推迟为止。也就是说,一直推迟到进程要访问的地址不在物理内存为止。这项技术的核心思想是,进程开始运行时并不会访问其地址空间的所有地址,事实上,有些地址进程可能永远都不会访问。
一旦用户访问映射的内存区域,就会触发缺页中断。以arch/x86/mm/fault.c中的do_page_fault为起点,其调用路径如图
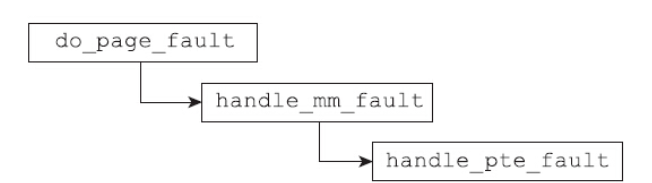
在handle_pte_fault中有如下代码:
1 | entry = *pte; |
pte_present(entry)用于判断页面是否在物理内存中。如果页面并不在物理内存中,那么处理流程如图所示。
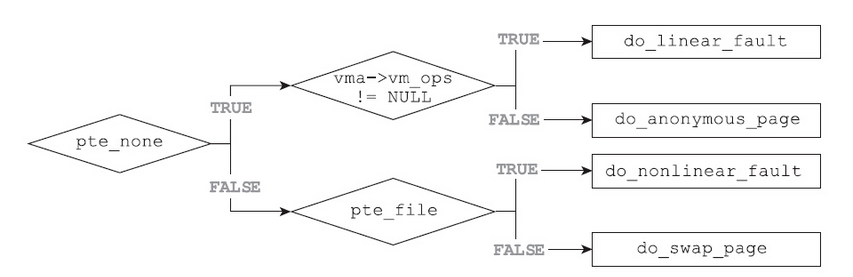
pte_none用于判断是否存在对应的页表项。如果pte_none为true,那么内核必须从头开始加载该页。这种情况下,根据vma的vm_ops是否注册了vm_operation_struct而分成两类:如果vm_ops不是NULL,则表示是基于文件的映射,就会调用do_linear_fault;如果vm_ops等于NULL,则表示是匿名映射,内核就会调用do_anonymous_page来返回一个匿名页。
如果pte_none返回false,则表示页表中保存了相关的信息,这就意味着该页已经被换出,这种情况下应该调用do_swap_page从系统的某个交换区换入该页。
但是有一种特殊情况,即pte_file函数返回true的情况。pte_file函数用于检测页表项是否属于非线性映射,如果该函数返回true,则表示页表项属于非线性映射。所谓非线性映射是指在mmap的基础上分离的映射页。尽管映射的内容仍然是文件的内容,但是与映射区域对应的并不是文件的连续区间,实际情况是每一个内存页都映射的是文件数据的随机页。对于应用程序而言,要想建立非线性映射,首先需要调用mmap创建常规的、连续的内存映射,然后调用remap_file_pages来重新映射某些页面。对于非线性映射而言,已经换出的部分不能像普通页一样被换入,首先必须正确地恢复非线性关联。这种特殊情况,是由do_nonlinear_fault函数负责处理的。
对于共享文件映射,调用的是do_linear_fault函数。在该函数中会执行vma->vm_ops->fault函数。如果对应的文件属于ext4文件系统,那么mmap系统调用中已经将vma的vm_ops指定成了ext4_file_vm_ops,因此,vma->vm_ops->fault指向的就是filemap_fault函数。filemap_fault函数是非常重要的,不仅仅是ext4文件系统,还有很多文件系统都使用filemap_fault来处理缺页。该函数不仅可以读入所需的数据,还实现了预读的功能。接下来,我们来分析下filemap_fault函数。
1 | int filemap_fault(struct vm_area_struct *vma, struct vm_fault *vmf) |
当多个进程mmap同一文件的某个区域时,当操作映射区域时,更多的情况是该页面已经在页缓存之中了。因此filemap_fault首先会调用file_get_page来检查请求页面是否已经在页缓存之中了。如果页缓存中确实不存在请求的页面,则需要调用page_cache_read将内容从底层块设备中读取上来,其函数定义如下:
1 | static int page_cache_read(struct file *file, pgoff_t offset) |
mapping->a_ops是什么?创建ext4 inode的ext4_create函数中有如下一句代码:
1 | ext4_set_aops(inode); |
在这个函数中我们通过上述语句设置了mapping的a_ops。对于readpage函数而言,最终是通过ext4_readpage调用了通用函数mpage_readpage。
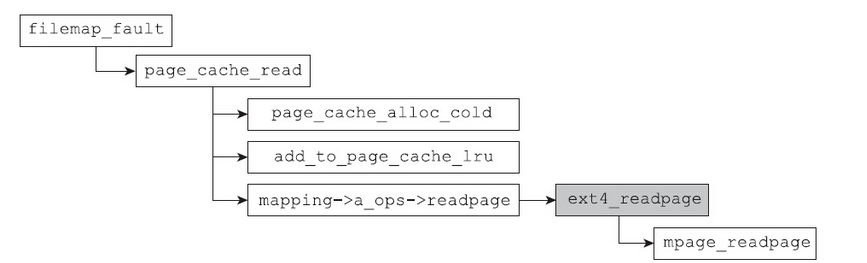
正是因为页缓存的存在,才真正做到了当多个进程mmap同一个文件的某个区域时,其指向的物理内存是同一个分页。事实上,系统文件的所有共享都是基于同一条路线的,不论你是read、write还是mmap,都要遵循这条路线:系统唯一的文件路径到系统唯一的inode,再到相同的address_space,最后到相同的页面。
我们跟踪了文件映射的内核实现,得到的结论是页缓存是联系内存管理系统和文件系统的一条纽带。应用层无论是使用read/write系统调用还是mmap将文件映射到内存,都是基于页缓存的,殊途同归。因此通过映射获取的文件视图和通过I/O系统调用(read、write)获得文件视图是一致的。
理解了这个,我们就可以讨论如下这类的话题了:如果mmap引入的共享文件映射,修改了映射区的内存后,进程却意外死亡,那么进程对内存的修改能否同步到底层文件?答案是肯定的,页高速缓存到底层文件的冲刷(flush)是由内核来负责的。事实上,我们不难验证这一点。对这个话题感兴趣的话,可以阅读stackoverflow上的相关文章[插图]。
关于共享文件映射,另外一个很有意思的现象是:修改映射区的内存,哪怕是几个字节,也可能需要花费很长的时间(比如几百毫秒)。很多人都遇到了这个问题,原因是内核回写线程会负责将脏页回写,它会将正在回写的页设置成写保护。此时如果有用户进程对该页面执行写操作,就会因为碰到了写保护的页面而走到do_page_fault。这种情况下,最终会执行到handle_pte_fault中的如下语句:
1 | if (flags & FAULT_FLAG_WRITE) { |
在do_wp_page函数中会调用page_mkwrite方法,在这里会等待回写线程写完之后才可以完成对页面的写操作。
私有文件映射
当调用mmap时,如果将flags设置成MAP_PRIVATE标志位,那么映射就是私有文件映射。最常见的情况就是前面提到的加载动态共享库,多个进程共享相同的文本段。从下面执行ls时执行的系统调用中可以看出:
从下面执行ls时执行的系统调用中可以看出:
1 | open("/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3 |
一般来讲文本段通常被保护成PROT_READ|PROT_EXEC。为了防止恶意程序篡改内存上的保护信息之后再篡改程序或共享库的文本,通常会直接使用私有文件映射而不是共享文件映射。
相对于出现得更早的静态库,动态库有很多的优点:可执行文件变得更小,节省磁盘空间;内存中只需要一份共享库的实例,不同进程都可以使用因而节省了内存。
共享匿名映射
和文件映射相对应的是匿名映射。这种映射并没有文件与之对应。一般来讲创建匿名映射有两种方法:
- 调用mmap时,在参数flags中指定MAP_ANONYMOUS标志位,并且将参数fd指定为-1。
- 打开/dev/zero设备文件,并将得到的文件描述符fd传递给mmap。
不论采用哪种方式,得到的内存映射中的字节都会被初始化成0。调用mmap创建匿名映射时,如果flags设置了MAP_SHARED标志位,那么创建出来就是共享匿名映射。共享匿名映射的作用是让相关进程共享一块内存区域。比如父进程创建一个共享匿名映射,然后fork创建子进程,这种情况下,父子进程就可以通过这块内存区域来通信。这个过程的代码如下所示。
1 | addr = mmap(NULL,length,PROT_READ|PROT_WRITE, |
私有匿名映射
当创建匿名映射时,如果flags中设置了MAP_PRIVATE标志位,那么创建出来的内存映射就是私有匿名映射。这种映射最典型的用途是分配进程所需的内存。映射出来的内存并没有文件与之关联,对内存的操作也是私有的,不会影响到其他进程。该用途比较典型的例子就是glibc中的malloc实现。当要分配的内存大于MMAP_THREASHOLD字节时,glibc的malloc是使用mmap来实现的。一般来讲该阈值是128KB,可以通过mallopt函数来调整该参数。(学PWN的小伙伴肯定不陌生)。
当代码中有如下内容时:
1 | char *p = malloc(128*1024); |
通过strace来跟踪程序的执行,我们可以清楚地看到程序调用了mmap系统调用:
1 | mmap(NULL, 135168, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f2a29f0c000 |
POSIX 共享内存
前面曾经讲述过,mmap系统调用做了大量的工作,POSIX共享内存和前面的共享文件映射相比,并没有什么特殊之处。如果非要说有差别,那么差别就是,获取文件描述符的方式不同。
1 | 普通文件映射获取fd的方式 |
POSIX共享内存可以在无关的进程之间共享一个内存区域。和System V信号相比,POSIX使用了文件系统来标识共享内存,并且调用操作文件的接口来操作共享内存。
每创建一个POSIX共享内存,挂载在/dev/shm下的tmpfs文件系统中就会新增一个文件。和System V共享内存相比,POSIX共享内存的大小可以动态调整,因为POSIX共享内存是基于文件的,所以可以很方便地通过ftruncate函数来调整共享内存的大小。共享内存的使用者可以通过munmap和mmap重建映射。System V共享内存的大小在创建时就已经确定,无法再做调整。总体来讲,POSIX共享内存要优于System V共享内存,建议使用POSIX共享内存。
共享内存的创建、使用和删除
共享内存的创建本质上是两个接口,首先是调用shm_open返回文件描述符,然后是通过mmap将共享内存映射到进程的地址空间。两个函数的搭配很像System V的shmget函数和shmat函数。
shm_open函数的接口定义如下:
1 |
|
这里的oflag标志要包含O_RDONLY或O_RDWR标志位,除此以外,可以选择的标志位还有O_CREAT(表示创建)、O_EXCL(配合O_CREAT表示排他创建)。另外一个标志位是O_TRUNC,表示将共享内存的size截断成0。
mode参数可配合O_CREAT标志位使用,用于设定共享内存的访问权限。如果仅仅是打开共享内存,则可以传递0。shm_open总是需要mode参数。
shm_open函数调用成功时,会返回一个文件描述符。内核会自动设置FD_CLOEXEC标志位,即如果进程执行了exec函数,则该文件描述符会被自动关闭。
因为共享内存是文件,所以可以调用文件相关的函数,如fstat函数、fchmod函数和fchwon函数。其中最重要常用的函数要属ftruncate函数。因为新创建的共享内存,默认大小总是0。所以在调用mmap之前,需要先调用ftruncate函数,以调整文件的大小。
1 |
|
调整了size之后,就可以调用mmap函数将共享内存映射到进程的地址空间了。对于其他参与通信的进程,可能需要调用fstat接口来获取共享内存区的大小。
1 |
|
通过该接口可以获取到共享内存的大小。在mmap将共享内存映射到进程的地址空间之后,就可以通过操作内存来通信了。对这块内存的所有修改,其他进程都可以看到。
结束通信任务后,可以通过调用munmap函数解除映射。如果彻底不需要共享内存了,可以通过shm_unlink函数来删除。该函数的接口定义如下:
1 | int shm_unlink(const char *name); |
删除一个共享内存对象,并不会影响既有的映射。内核维护有引用计数,当所有的进程都通过munmap解除映射之后,共享内存对象才会真正被删除。
如果不执行shm_unlink,共享内存对象中的数据则具有内核持久性。哪怕所有的进程都通过munmap解除了映射,只要不调用shm_unlink,其中的数据就不会丢失。当然,如果系统重启,那么其中的共享内存对象也就不复存在了。
共享内存与tmpfs
POSIX共享内存是建立在tmpfs基础之上的。事实上,System V共享内存也是建立在tmpfs基础上的。
从glibc的角度来看,shm_open的实现是非常简单的:
1 |
|
该函数就做了三件事:
(1)生成真正的文件名:当用户调用shm_open传递的文件名为name时,文件的全路径是/dev/shm/name。
(2)创建或打开/dev/shm/name文件。
(3)给打开的文件设置FD_CLOEXEC标志位。
前文曾不断提及,mmap才是关键,无论是通过open获取到fd还是根据shm_open获取到fd,并没有什么本质的区别。看到glibc的shm_open实现后,我们更能够理解这个观点,的确没有本质区别,shm_open,不过就是open披了一个马夹。
接下来可以讲讲tmpfs相关的内容了。在shm_open的实现中选择/dev/shm这个路径并不是随意而为之的。glibc为了实现POSIX共享内存,需要将一个tmpfs挂载到/dev/shm这个路径下。tmpfs是一个内存文件系统,该文件系统可将所有的文件内容保持在内存之中,而不会写入到磁盘等持久化的设备中。一旦umount或系统重启,tmpfs里的内容就会全部丢失。
内核的文档中Documentation/filesystems/tmpfs.txt中介绍了tmpfs的作用:
- 总是存在内核的内部挂载(internal mount),这个内部挂载并不依赖于CONFIG_TMPFS,哪怕CONFIG_TMPFS编译选项没有打开,也不会影响到该内部机制的存在。它的存在是为共享匿名映射和System V共享内存服务的。
- glibc自2.2版本以来,为了实现POSIX共享内存的功能,需要一个挂载点为
/dev/shm的tmpfs。
从文档中可以看出,无论是POSIX信号量、System V信号量还是共享匿名映射都是建立在tmpfs的基础上的,其统一的视图如图
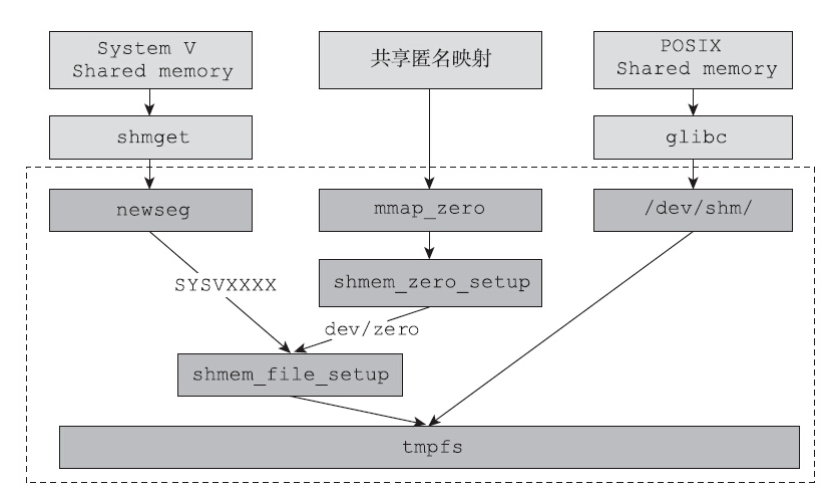
对于System V共享内存而言,其核心是tmpfs,外面封装了一层用来管理IPC的键值。当调用shmget创建System V共享内存时,会调用ipc/shm.c中的newseg函数。该函数会调用位于mm/shmem.c文件中的shmem_file_setup函数来创建一个与共享内存对应的struct file。代码如下所示:
1 | sprintf (name, "SYSV%08x", key); |
当调用shmat函数将System V共享内存attach到进程的地址空间时,内核会通过do_mmap函数,创建出基于该文件的共享映射,提供给用户使用。毫不意外,当用户调用shmdt函数解除映射时,内核会调用do_munmap。
在Linux实现中,传统的System V共享内存虽然没有显式地调用open-mmap-munmap这套流程,但是内在的核心逻辑是一致的。shmget获得了一个tmpfs的文件实例,shmat函数内部对应mmap,而shmdt函数内部对应munmap。
接下来分析共享匿名映射。创建共享匿名映射有两条路,其中一条就是打开/dev/zero文件,将获得的文件描述符fd传递给mmap函数。/dev/zero是一个特殊的文件,在drivers/char/mem.c中有如下内容:
1 | static const struct memdev { |
如果打开/dev/zero文件,并将获得的文件描述符fd传给mmap系统调用,那么内核中mmap_region函数中调用的file->f_op->mmap函数,实质上调用的是mmap_zero函数,而mmap_zero函数,不过是shmem_zero_setup函数的简单封装。
1 | static int mmap_zero(struct file *file, struct vm_area_struct *vma) |
创建共享匿名映射的另外一条路是调用mmap,传递-1作为fd的值。这种情况下也会走到shmem_zero_setup函数。请看mmap_region函数中的如下代码:
1 | if(file){ |
殊途同归,无论采用哪种方式创建共享匿名映射,最终都会调用到shmem_zero_setup函数。而该函数仅仅是shmem_file_setup的简单封装。
POSIX共享内存前面已经分析过了,通过挂载到/dev/shm路径下的tmpfs来实现内存的共享。glibc的shm_open用于创建一个文件,并且通过mmap映射到进程的地址空间。
从上面的讨论也可以看出,mmap和tmpfs是隐藏在共享内存背后的终极boss。无论是System V共享内存,还是POSIX共享内存,都摆脱不了tmpfs和mmap。区别仅仅是POSIX共享内存很直接,就是直接在tmpfs下创建文件,直接通过mmap来使用内存区域,而System V共享内存穿了马甲,将tmpfs和mmap的相关操作隐藏到了内核中。
标准库
管道
在 Linux 和类 Unix 系统中,pipe 和 mkfifo 是用于进程间通信(IPC)的系统调用和函数。它们分别用于创建无名管道和有名管道(FIFO)。以下是对这两个函数的详细解释:
pipe()
pipe 函数用于创建一个无名管道。无名管道只能在具有亲缘关系的进程(如父子进程)之间使用。
函数原型
1 |
|
参数
pipefd: 一个包含两个整数的数组。pipefd[0]是管道的读端,pipefd[1]是管道的写端。
返回值
- 成功时返回 0。
- 失败时返回 -1,并设置
errno以指示错误类型。
使用示例
1 | int pipefd[2]; |
特性
- 单向通信: 无名管道是单向的,即数据只能从写端流向读端。
- 阻塞行为: 如果管道的缓冲区满,写操作将被阻塞;如果缓冲区为空,读操作将被阻塞。
mkfifo()
mkfifo 函数用于创建一个有名管道(FIFO),它存在于文件系统中,可以用于不相关的进程之间的通信。
函数原型
1 |
|
参数
pathname: 有名管道的路径名。mode: 文件权限位,用于设置管道的权限(如读、写权限)。
返回值
- 成功时返回 0。
- 失败时返回 -1,并设置
errno以指示错误类型。
使用示例
1 | if (mkfifo("/tmp/myfifo", 0666) == -1) { |
特性
- 文件系统中的实体: 有名管道在文件系统中有一个路径名,可以通过路径名进行访问。
- 双向通信: 可以在两个不相关的进程之间进行通信。
- 阻塞行为: 与无名管道类似,具有阻塞特性。
popen()
popen 函数是一个标准的C库函数,用于创建一个管道,启动一个子进程,并打开一个流,以便可以通过该流与子进程进行通信。通常用于执行外部命令并读取其输出或向其输入数据。
函数原型
1 |
|
参数
command: 要执行的命令字符串。可以是任何可以在 shell 中执行的命令。type: 指定流的类型,通常为"r"或"w"。"r": 打开一个管道以读取子进程的标准输出。"w": 打开一个管道以写入子进程的标准输入。
返回值
- 成功时返回一个
FILE指针,表示打开的管道。 - 失败时返回
NULL,并设置errno以指示错误。
用法
popen创建一个管道并 fork 一个子进程。在子进程中,popen调用/bin/sh来执行指定的命令。- 如果
type是"r",则可以通过返回的FILE指针读取子进程的输出。 - 如果
type是"w",则可以通过返回的FILE指针向子进程的输入写入数据。 - 使用
pclose关闭由popen打开的流,并等待子进程终止。
示例
以下是一个使用 popen 的简单示例,演示如何执行一个命令并读取其输出:
1 |
|
注意事项
- 安全性: 使用
popen时要注意命令注入的风险,尤其是在处理用户输入时。确保对输入进行适当的验证和清理。 - 资源管理: 确保使用
pclose关闭管道,以避免资源泄漏。 - 缓冲区: 读取输出时要注意缓冲区的大小,以避免溢出。
- 并发性:
popen和pclose不是线程安全的,避免在多线程环境中同时调用它们。 - 错误处理: 检查
popen和pclose的返回值,以处理可能的错误情况。
pclose()
pclose 函数用于关闭由 popen 打开的管道,并等待与该管道关联的子进程终止。它不仅关闭流,还返回子进程的终止状态。
函数原型
1 |
|
参数
stream: 由popen返回的FILE指针,表示要关闭的管道。
返回值
- 成功时返回子进程的终止状态(与
waitpid返回的状态相同)。 - 失败时返回
-1,并设置errno以指示错误。
用法
pclose关闭与popen打开的管道,并等待子进程终止。- 通过返回值可以获取子进程的退出状态,通常使用宏
WIFEXITED和WEXITSTATUS来检查和提取退出状态。
示例
以下是一个使用 popen 和 pclose 的示例,演示如何执行一个命令并获取其退出状态:
1 |
|
注意事项
- 资源管理: 确保每个
popen调用都有相应的pclose调用,以避免资源泄漏。 - 错误处理: 检查
pclose的返回值,以处理可能的错误情况。 - 信号处理: 如果子进程由于信号而终止,
pclose的返回值将反映这一点。可以使用WIFSIGNALED和WTERMSIG宏来检查和提取信号信息。 - 多次关闭: 不要对同一个
FILE指针调用多次pclose,这会导致未定义行为。
pipe2()
pipe2 是 Linux 特有的系统调用,用于创建一个管道。与传统的 pipe 函数不同,pipe2 允许在创建管道时指定额外的标志,以控制文件描述符的行为。
函数原型
1 |
|
参数
pipefd: 一个包含两个整数的数组,用于存储管道的文件描述符。pipefd[0]是管道的读取端,pipefd[1]是管道的写入端。flags: 用于指定文件描述符的行为,可以是以下标志的组合:O_NONBLOCK: 使管道的文件描述符为非阻塞模式。O_CLOEXEC: 在执行exec系列函数时自动关闭文件描述符。
返回值
- 成功时返回
0,并在pipefd中存储管道的文件描述符。 - 失败时返回
-1,并设置errno以指示错误。
用法
pipe2 的主要用途是创建一个管道,并在创建时设置文件描述符的属性,而不需要在创建后再调用 fcntl 来设置这些属性。
示例
以下是一个使用 pipe2 的简单示例,演示如何创建一个管道并设置文件描述符为非阻塞模式:
1 |
|
注意事项
- 兼容性:
pipe2是 Linux 特有的扩展,不是 POSIX 标准的一部分,因此在移植性要求高的项目中应谨慎使用。 - 错误处理: 检查
pipe2的返回值,以处理可能的错误情况。 - 标志使用: 使用
O_NONBLOCK可以避免在读写操作中阻塞进程,而O_CLOEXEC可以提高安全性,防止文件描述符泄漏到子进程中。
System V 消息队列
在 System V IPC 中,消息队列是一种用于进程间通信的机制。msqid_ds 结构体用于描述消息队列的状态和属性。这个结构体包含了消息队列的各种信息,包括权限、时间戳、消息计数等。
msqid_ds 结构体
在 Linux 系统中,msqid_ds 结构体通常定义在 <sys/msg.h> 头文件中。以下是一个典型的 msqid_ds 结构体定义:
1 |
|
字段解析
msg_perm: 这是一个ipc_perm结构体,定义了消息队列的访问权限,包括用户ID、组ID和模式(读写权限)。msg_stime: 上次成功发送消息的时间(以秒为单位,自纪元开始)。msg_rtime: 上次成功接收消息的时间(以秒为单位,自纪元开始)。msg_ctime: 上次更改消息队列状态的时间(以秒为单位,自纪元开始),例如通过msgctl修改权限。__msg_cbytes: 当前在队列中的字节数。注意,这个字段在某些实现中可能是非标准化的。msg_qnum: 当前在队列中的消息数。msg_qbytes: 队列中允许的最大字节数。这个值可以通过msgctl来设置。msg_lspid: 最后一个发送消息的进程的进程ID。msg_lrpid: 最后一个接收消息的进程的进程ID。
使用示例
msqid_ds 结构体通常与 msgctl 函数一起使用,以获取或设置消息队列的状态。例如:
1 |
|
注意事项
- 权限管理: 确保在操作消息队列时具有适当的权限。
- 资源清理: 使用完消息队列后,记得使用
msgctl和IPC_RMID命令删除消息队列,以避免资源泄漏。 - 兼容性: System V IPC 是一种较老的进程间通信机制,现代应用程序可能更倾向于使用 POSIX 消息队列或其他 IPC 机制。
ftok
ftok 是一个用于生成 System V IPC 键值的函数,定义在 <sys/ipc.h> 头文件中。它的主要作用是将一个文件路径和一个项目标识符组合成一个唯一的键值(key_t 类型),用于标识消息队列、共享内存段或信号量集。
函数原型
1 |
|
参数
pathname: 指向一个现有文件的路径。这个文件不需要是特殊的文件,但它必须存在且对调用进程可访问。通常使用一个常驻的文件路径,以确保生成的键值在系统重启后仍然有效。proj_id: 一个项目标识符,通常是一个字符(整数类型),用于与文件路径组合生成键值。这个标识符的作用是允许同一个文件路径生成不同的键值。
返回值
- 成功时,返回一个
key_t类型的键值。 - 失败时,返回
-1,并设置errno以指示错误原因。
用法示例
以下是一个使用 ftok 生成 IPC 键值的简单示例:
1 |
|
注意事项
文件存在性:
ftok依赖于文件的存在性和可访问性,因此在使用时确保指定的文件路径是有效的。唯一性:
ftok生成的键值不一定是全局唯一的。它依赖于文件的 inode 和设备号以及项目标识符,因此在某些情况下可能会产生相同的键值。为避免冲突,选择不同的proj_id或使用不同的文件路径。跨平台性:
ftok的行为在不同的 Unix-like 系统上可能略有不同,特别是在处理文件路径和项目标识符时。因此,在编写跨平台代码时需要注意这一点。错误处理: 在使用
ftok时,务必检查返回值以确保键值生成成功,并处理可能的错误。常见错误包括文件不存在或不可访问。
msgget
msgget 用于创建一个新的消息队列或获取一个现有的消息队列。
函数原型
1 |
|
参数
key: 消息队列的键值。可以使用ftok函数生成。msgflg: 标志位,用于指定消息队列的权限和行为。常用的标志包括:IPC_CREAT: 如果消息队列不存在,则创建一个新的。IPC_EXCL: 与IPC_CREAT一起使用,确保消息队列不存在时才创建,存在则返回失败。
返回值
- 成功时返回消息队列的标识符。
- 失败时返回
-1,并设置errno。
msgctl
msgctl 用于控制消息队列的操作,如获取状态、设置状态或删除消息队列。
函数原型
1 |
|
参数
msqid: 消息队列的标识符。cmd: 控制命令,可以是以下之一:IPC_STAT: 获取消息队列的状态,结果存储在buf中。IPC_SET: 设置消息队列的状态,使用buf中的数据。IPC_RMID: 删除消息队列。
buf: 指向msqid_ds结构体的指针,用于存储或设置消息队列的状态。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
msgsnd
msgsnd 用于向消息队列发送消息。
函数原型
1 |
|
参数
msqid:- 消息队列标识符。这个ID是通过
msgget函数创建或获取的。
- 消息队列标识符。这个ID是通过
msgp:指向消息的指针。消息必须以一个
long类型的消息类型字段开始,紧接着是消息的数据部分。通常,定义一个结构体来表示消息,例如:
1
2
3
4struct my_msg {
long mtype; // 消息类型,必须是正数
char mtext[100]; // 消息数据
};
msgsz:- 消息数据部分的大小(以字节为单位),不包括消息类型字段。
msgflg:- 控制操作的标志,可以是0或者以下选项的组合:
IPC_NOWAIT: 如果消息队列已满,函数立即返回,而不是阻塞。
- 控制操作的标志,可以是0或者以下选项的组合:
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
msgrcv
msgrcv 用于从消息队列接收消息。
函数原型
1 |
|
参数
msqid:- 消息队列标识符,与
msgsnd中的相同。
- 消息队列标识符,与
msgp:- 指向接收消息的缓冲区。它必须能够容纳一个
long类型的消息类型字段和消息数据。
- 指向接收消息的缓冲区。它必须能够容纳一个
msgsz:- 指定可以接收的最大消息数据大小(以字节为单位),不包括消息类型字段。
msgtyp:- 指定要接收的消息类型:
- 如果
msgtyp为0,则接收队列中的第一个消息。 - 如果
msgtyp为正数,则接收第一个类型为msgtyp的消息。 - 如果
msgtyp为负数,则接收第一个消息类型小于或等于绝对值msgtyp的消息。
- 如果
- 指定要接收的消息类型:
msgflg:- 控制操作的标志,可以是0或者以下选项的组合:
IPC_NOWAIT: 如果没有符合条件的消息,函数立即返回,而不是阻塞。MSG_NOERROR: 如果消息长度大于msgsz,则截断消息而不是失败。
- 控制操作的标志,可以是0或者以下选项的组合:
返回值
- 成功时返回接收的消息正文的大小。
- 失败时返回
-1,并设置errno。
示例
以下是一个简单的示例,演示如何使用这些函数进行消息队列的基本操作:
1 |
|
注意事项
- 消息类型: 消息类型是一个长整型值,用于标识消息的类别。发送和接收消息时需要注意消息类型的匹配。
- 权限管理: 确保在操作消息队列时具有适当的权限。
- 资源清理: 使用完消息队列后,记得删除消息队列以避免资源泄漏。
System V 信号量
在 System V IPC 中,信号量是一种用于进程间同步的机制。semid_ds 结构体用于描述信号量集的状态和属性。这个结构体包含了信号量集的各种信息,包括权限、时间戳、信号量数量等。
semid_ds 结构体
在 Linux 系统中,semid_ds 结构体通常定义在 <sys/sem.h> 头文件中。以下是一个典型的 semid_ds 结构体定义:
1 |
|
字段解析
sem_perm: 这是一个ipc_perm结构体,定义了信号量集的访问权限,包括用户ID、组ID和模式(读写权限)。sem_otime: 上次成功执行信号量操作的时间(以秒为单位,自纪元开始)。sem_ctime: 上次更改信号量集状态的时间(以秒为单位,自纪元开始),例如通过semctl修改权限。sem_nsems: 信号量集中的信号量数量。
使用示例
semid_ds 结构体通常与 semctl 函数一起使用,以获取或设置信号量集的状态。例如:
1 |
|
注意事项
- 权限管理: 确保在操作信号量集时具有适当的权限。
- 资源清理: 使用完信号量集后,记得使用
semctl和IPC_RMID命令删除信号量集,以避免资源泄漏。 - 兼容性: System V IPC 是一种较老的进程间通信机制,现代应用程序可能更倾向于使用 POSIX 信号量或其他同步机制。
在 System V IPC 中,信号量是一种用于进程间同步的机制。以下是与信号量相关的三个主要函数:semget、semctl 和 semop。这些函数用于创建、控制和操作信号量集。
semget
semget 用于创建一个新的信号量集或获取一个现有的信号量集。
函数原型
1 |
|
参数
key: 信号量集的键值。可以使用ftok函数生成。nsems: 信号量集中的信号量数量。semflg: 标志位,用于指定信号量集的权限和行为。常用的标志包括:IPC_CREAT: 如果信号量集不存在,则创建一个新的。IPC_EXCL: 与IPC_CREAT一起使用,确保信号量集不存在时才创建。
返回值
- 成功时返回信号量集的标识符。
- 失败时返回
-1,并设置errno。
semctl
semctl 用于控制信号量集的操作,如获取状态、设置状态或删除信号量集。
函数原型
1 |
|
参数
semid: 信号量集的标识符。semnum: 信号量集中的信号量编号(从 0 开始)。cmd: 控制命令,可以是以下之一:IPC_STAT: 获取信号量集的状态,结果存储在semid_ds结构体中。IPC_SET: 设置信号量集的状态,使用semid_ds结构体中的数据。IPC_RMID: 删除信号量集。GETVAL: 获取指定信号量的值。SETVAL: 设置指定信号量的值。GETALL: 获取信号量集的所有信号量的值。SETALL: 设置信号量集的所有信号量的值。
返回值
- 成功时返回命令的结果(通常为
0或信号量的值)。 - 失败时返回
-1,并设置errno。
semop
semop 用于对信号量集中的信号量进行操作(如增加或减少信号量的值)。
函数原型
1 |
|
参数
semid: 信号量集的标识符。sops: 指向sembuf结构体数组的指针,描述要执行的操作。nsops:sops数组中的操作数量。
sembuf 结构体
1 | struct sembuf { |
sem_num: 信号量集中的信号量编号。sem_op: 操作类型,可以是以下之一:- 正数:增加信号量的值。
- 负数:减少信号量的值(如果信号量的值小于操作数的绝对值,则阻塞)。
0:等待信号量的值变为0。
sem_flg: 操作标志,可以是IPC_NOWAIT(不阻塞)或SEM_UNDO(操作可撤销)。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
示例
以下是一个简单的示例,演示如何使用这些函数进行信号量的基本操作:
1 |
|
注意事项
- 信号量初始化: 在使用信号量之前,通常需要使用
semctl初始化信号量的值。 - 权限管理: 确保在操作信号量集时具有适当的权限。
- 资源清理: 使用完信号量集后,记得删除信号量集以避免资源泄漏。
System V 共享内存
在 System V IPC 中,共享内存是一种高效的进程间通信机制,允许多个进程直接访问同一块内存区域。shmid_ds 结构体用于描述共享内存段的状态和属性。
shmid_ds 结构体
在 Linux 系统中,shmid_ds 结构体通常定义在 <sys/shm.h> 头文件中。以下是一个典型的 shmid_ds 结构体定义:
1 |
|
字段解析
shm_perm: 这是一个ipc_perm结构体,定义了共享内存段的访问权限,包括用户ID、组ID和模式(读写权限)。shm_segsz: 共享内存段的大小,以字节为单位。shm_atime: 上次成功附加(attach)共享内存段的时间(以秒为单位,自纪元开始)。shm_dtime: 上次成功分离(detach)共享内存段的时间(以秒为单位,自纪元开始)。shm_ctime: 上次更改共享内存段状态的时间(以秒为单位,自纪元开始),例如通过shmctl修改权限。shm_cpid: 创建共享内存段的进程ID。shm_lpid: 上次操作共享内存段的进程ID。shm_nattch: 当前附加到共享内存段的进程数量。
使用示例
shmid_ds 结构体通常与 shmctl 函数一起使用,以获取或设置信息。例如:
1 |
|
注意事项
- 权限管理: 确保在操作共享内存段时具有适当的权限。
- 资源清理: 使用完共享内存段后,记得使用
shmctl和IPC_RMID命令删除共享内存段,以避免资源泄漏。 - 同步机制: 共享内存本身不提供同步机制,多个进程访问共享内存时需要自行实现同步(如使用信号量或互斥锁)。
在 System V IPC 中,共享内存是一种高效的进程间通信机制。以下是与共享内存相关的三个主要函数:shmget、shmat 和 shmctl。这些函数用于创建、附加、控制和删除共享内存段。
shmget
shmget 用于创建一个新的共享内存段或获取一个现有的共享内存段。
函数原型
1 |
|
参数
key: 共享内存段的键值。可以使用ftok函数生成。size: 共享内存段的大小(以字节为单位)。shmflg: 标志位,用于指定共享内存段的权限和行为。常用的标志包括:IPC_CREAT: 如果共享内存段不存在,则创建一个新的。IPC_EXCL: 与IPC_CREAT一起使用,确保共享内存段不存在时才创建。- 权限标志(如
0666),指定读写权限。
返回值
- 成功时返回共享内存段的标识符。
- 失败时返回
-1,并设置errno。
shmat
shmat 用于将共享内存段附加到调用进程的地址空间。
函数原型
1 |
|
参数
shmid: 共享内存段的标识符。shmaddr: 指定附加的地址。如果为NULL,系统自动选择地址。shmflg: 附加标志,可以是以下之一:SHM_RDONLY: 以只读方式附加。0: 以读写方式附加。
返回值
- 成功时返回指向共享内存段的指针。
- 失败时返回
(void *) -1,并设置errno。
shmctl
shmctl 用于控制共享内存段的操作,如获取状态、设置状态或删除共享内存段。
函数原型
1 |
|
参数
shmid: 共享内存段的标识符。cmd: 控制命令,可以是以下之一:IPC_STAT: 获取共享内存段的状态,结果存储在shmid_ds结构体中。IPC_SET: 设定共享内存段的状态,使用shmid_ds结构体中的数据。IPC_RMID: 删除共享内存段。
buf: 指向shmid_ds结构体的指针,用于存储或设置共享内存段的信息。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
示例
以下是一个简单的示例,演示如何使用这些函数进行共享内存的基本操作:
1 |
|
注意事项
- 权限管理: 确保在操作共享内存段时具有适当的权限。
- 资源清理: 使用完共享内存段后,记得分离和删除共享内存段以避免资源泄漏。
- 同步机制: 共享内存本身不提供同步机制,多个进程访问共享内存时需要自行实现同步(如使用信号量或互斥锁)。
POSIX 消息队列
在 POSIX IPC 中,消息队列提供了一种在进程间传递消息的机制。POSIX 消息队列与 System V 消息队列不同,提供了更丰富的功能和更好的标准化支持。以下是与 POSIX 消息队列相关的三个主要函数:mq_open、mq_close 和 mq_unlink。
mq_open
mq_open 用于打开一个消息队列。如果消息队列不存在,可以选择创建一个新的。
函数原型
1 |
|
参数
name: 消息队列的名称。必须以斜杠(/)开头,类似于文件路径。oflag: 打开标志,可以是以下之一或组合:O_RDONLY: 以只读方式打开。O_WRONLY: 以只写方式打开。O_RDWR: 以读写方式打开。O_CREAT: 如果消息队列不存在,则创建一个新的。O_EXCL: 与O_CREAT一起使用,确保消息队列不存在时才创建。
- 可选参数(当使用
O_CREAT时需要提供):mode_t mode: 权限位,类似于文件权限(如0666)。struct mq_attr *attr: 指向mq_attr结构体的指针,用于指定消息队列的属性(如最大消息数和最大消息大小)。
返回值
- 成功时返回消息队列描述符(
mqd_t类型)。 - 失败时返回
-1,并设置errno。
struct mq_attr 结构体
在 POSIX 标准中,struct mq_attr 通常定义如下:
1 | struct mq_attr { |
mq_flags:
- 用于表示消息队列的当前状态或属性。常见的标志包括非阻塞模式(
O_NONBLOCK),这意味着在执行消息发送或接收操作时,如果消息队列已满或为空,操作不会阻塞。
mq_maxmsg:
- 指定消息队列中可以容纳的最大消息数量。这个值在创建消息队列时设置,通常不能在队列创建后更改。
mq_msgsize:
- 指定单个消息的最大大小(以字节为单位)。这也是在消息队列创建时设置的属性。
mq_curmsgs:
- 表示当前消息队列中消息的数量。这是一个动态值,随着消息的发送和接收而变化。
mq_close
mq_close 用于关闭一个打开的消息队列描述符。
函数原型
1 |
|
参数
mqdes: 消息队列的描述符。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
mq_unlink
mq_unlink 用于删除一个消息队列。删除操作会在所有进程关闭该消息队列后生效。
函数原型
1 |
|
参数
name: 要删除的消息队列的名称。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
示例
以下是一个简单的示例,演示如何使用这些函数进行消息队列的基本操作:
1 |
|
注意事项
- 命名规则: POSIX 消息队列的名称必须以斜杠开头,并且在系统中是全局唯一的。
- 权限管理: 确保在创建和访问消息队列时具有适当的权限。
- 资源清理: 使用完消息队列后,记得关闭和删除消息队列以避免资源泄漏。
- 同步机制: POSIX 消息队列提供了阻塞和非阻塞模式,可以根据需要选择合适的模式。
在 POSIX IPC 中,消息队列提供了一种在进程间传递消息的机制。mq_send 和 mq_receive 是用于发送和接收消息的两个主要函数。以下是对这两个函数的详细解析:
mq_send
mq_send 用于将消息发送到指定的消息队列。
函数原型
1 |
|
参数
mqdes: 消息队列的描述符,通过mq_open获得。msg_ptr: 指向要发送的消息的指针。msg_len: 消息的长度(字节数)。必须小于或等于消息队列的最大消息大小(mq_msgsize)。msg_prio: 消息的优先级。优先级越高,消息越早被接收。优先级范围为 0 到MQ_PRIO_MAX-1,其中MQ_PRIO_MAX是实现定义的常量,通常为 32,767。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:EAGAIN: 队列已满(在非阻塞模式下)。EMSGSIZE: 消息长度超过队列允许的最大消息大小。EBADF: 无效的消息队列描述符。EINVAL: 参数无效。
mq_receive
mq_receive 用于从指定的消息队列接收消息。
函数原型
1 |
|
参数
mqdes: 消息队列的描述符,通过mq_open获得。msg_ptr: 指向用于存储接收消息的缓冲区。msg_len: 缓冲区的长度。必须大于或等于消息队列的最大消息大小(mq_msgsize)。msg_prio: 指向一个无符号整数的指针,用于存储接收消息的优先级。如果不需要优先级信息,可以传递NULL。
返回值
- 成功时返回接收的消息长度。
- 失败时返回
-1,并设置errno。常见错误包括:EAGAIN: 队列为空(在非阻塞模式下)。EMSGSIZE: 缓冲区长度小于消息队列的最大消息大小。EBADF: 无效的消息队列描述符。EINVAL: 参数无效。
示例
以下是一个简单的示例,演示如何使用 mq_send 和 mq_receive 进行消息的发送和接收:
1 |
|
注意事项
- 消息大小: 发送的消息长度必须小于或等于消息队列的最大消息大小。
- 优先级: 使用优先级可以控制消息的接收顺序,优先级高的消息会被优先接收。
- 阻塞与非阻塞: 默认情况下,
mq_send和mq_receive是阻塞的。可以通过在mq_open中使用O_NONBLOCK标志来设置非阻塞模式。
在 POSIX IPC 中,消息队列提供了一种在进程间传递消息的机制。除了基本的发送和接收操作外,POSIX 消息队列还提供了一些函数用于获取和设置消息队列的属性,以及注册消息通知。以下是对 mq_getattr、mq_setattr 和 mq_notify 函数的详细解析:
mq_getattr
mq_getattr 用于获取消息队列的属性。
函数原型
1 |
|
参数
mqdes: 消息队列的描述符,通过mq_open获得。attr: 指向mq_attr结构体的指针,用于存储消息队列的属性。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:EBADF: 无效的消息队列描述符。EINVAL: 参数无效。
mq_attr 结构体
1 | struct mq_attr { |
mq_setattr
mq_setattr 用于设置消息队列的属性。
函数原型
1 |
|
参数
mqdes: 消息队列的描述符,通过mq_open获得。newattr: 指向mq_attr结构体的指针,用于指定新的消息队列属性。oldattr: 指向mq_attr结构体的指针,用于存储旧的消息队列属性。如果不需要旧属性,可以传递NULL。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:EBADF: 无效的消息队列描述符。EINVAL: 参数无效。
注意
- 只有
mq_flags可以被设置,其他属性(如mq_maxmsg、mq_msgsize)在队列创建后不能更改。
mq_notify
mq_notify 用于注册一个进程,以便在消息队列变为非空时接收通知。
函数原型
1 |
|
参数
mqdes: 消息队列的描述符,通过mq_open获得。sevp: 指向sigevent结构体的指针,用于指定通知方式。如果为NULL,表示取消注册。
sigevent 结构体
sigevent 结构体用于指定通知的方式,可以是信号通知或线程通知。
1 | struct sigevent { |
sigev_notify可以是以下之一:SIGEV_NONE: 不进行通知。SIGEV_SIGNAL: 通过信号进行通知。SIGEV_THREAD: 通过线程进行通知。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:EBADF: 无效的消息队列描述符。EINVAL: 参数无效。EAGAIN: 已有其他进程注册了通知。
示例
以下是一个简单的示例,演示如何使用这些函数:
1 |
|
注意事项
- 属性设置: 只能更改
mq_flags,其他属性在创建时确定。 - 通知注册: 每个消息队列同时只能有一个注册的通知进程。
- 信号与线程通知: 根据应用需求选择合适的通知方式。信号通知适合简单的通知机制,而线程通知适合更复杂的处理。
POSIX 信号量
在 Linux POSIX IPC 中,信号量提供了一种用于进程间同步的机制。POSIX 信号量可以是命名信号量或未命名信号量。命名信号量可以在不同进程间共享,而未命名信号量通常用于线程间同步。以下是对 sem_open、sem_close 和 sem_unlink 函数的详细解析,这些函数主要用于命名信号量的操作。
sem_open
sem_open 用于打开或创建一个命名信号量。
函数原型
1 |
|
参数
name: 信号量的名称。名称必须以斜杠开头,并且不能包含其他斜杠。oflag: 打开标志,可以是以下之一或组合:O_CREAT: 如果信号量不存在,则创建它。O_EXCL: 与O_CREAT一起使用时,如果信号量已存在则失败。
- 可选参数(当
O_CREAT标志被使用时):mode_t mode: 用于设置信号量的权限(如0644)。unsigned int value: 信号量的初始值。
返回值
- 成功时返回指向信号量对象的指针。
- 失败时返回
SEM_FAILED,并设置errno。常见错误包括:EEXIST: 信号量已存在(与O_EXCL一起使用时)。EINVAL: 初始值超出范围。ENAMETOOLONG: 名称太长。ENOENT: 信号量不存在(未使用O_CREAT时)。
sem_close
sem_close 用于关闭一个命名信号量。
函数原型
1 |
|
参数
sem: 指向信号量对象的指针,通过sem_open获得。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:EINVAL: 无效的信号量指针。
注意
sem_close仅关闭信号量的描述符,不删除信号量本身。信号量仍然存在于系统中,直到被sem_unlink删除。
sem_unlink
sem_unlink 用于删除一个命名信号量。
函数原型
1 |
|
参数
name: 信号量的名称。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:ENOENT: 信号量不存在。
注意
sem_unlink删除信号量,使其不再可用。即使有进程仍然打开该信号量,它们也可以继续使用直到关闭,但不能再通过sem_open打开。
示例
以下是一个简单的示例,演示如何使用这些函数:
1 |
|
注意事项
- 命名约定: 信号量名称必须以斜杠开头,并且不能包含其他斜杠。
- 权限设置: 创建信号量时需要设置适当的权限,以确保其他进程可以访问。
- 信号量删除: 使用
sem_unlink删除信号量,以确保系统资源不会被浪费。
以下是对 sem_post、sem_wait、sem_trywait、sem_timedwait 和 sem_getvalue 函数的详细解析,在 Linux POSIX IPC 中,这些函数用于操作信号量的值和状态。
sem_post
sem_post 用于增加信号量的值,通常用于释放信号量。
函数原型
1 |
|
参数
sem: 指向信号量对象的指针。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:EINVAL: 无效的信号量指针。
注意
sem_post增加信号量的值,并唤醒等待该信号量的进程或线程(如果有)。
sem_wait
sem_wait 用于减少信号量的值,通常用于获取信号量。如果信号量的值为零,则调用进程会阻塞,直到信号量的值大于零。
函数原型
1 |
|
参数
sem: 指向信号量对象的指针。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:EINVAL: 无效的信号量指针。EINTR: 调用被信号中断。
sem_trywait
sem_trywait 类似于 sem_wait,但如果信号量的值为零,则不会阻塞,而是立即返回。
函数原型
1 |
|
参数
sem: 指向信号量对象的指针。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:EINVAL: 无效的信号量指针。EAGAIN: 信号量的值为零,无法立即获取。
sem_timedwait
sem_timedwait 类似于 sem_wait,但允许指定一个超时时间。如果在超时时间内信号量的值没有变为正数,则调用失败。
函数原型
1 |
|
参数
sem: 指向信号量对象的指针。abs_timeout: 指向timespec结构体的指针,指定绝对时间的超时时间。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:EINVAL: 无效的信号量指针或无效的时间值。ETIMEDOUT: 超时发生。EINTR: 调用被信号中断。
sem_getvalue
sem_getvalue 用于获取信号量的当前值。
函数原型
1 |
|
参数
sem: 指向信号量对象的指针。sval: 指向整数的指针,用于存储信号量的当前值。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:EINVAL: 无效的信号量指针。
注意
sem_getvalue返回信号量的当前值,但该值可能在返回后立即被其他进程或线程修改。
示例
以下是一个简单的示例,演示如何使用这些函数:
1 |
|
注意事项
- 信号量的值: 信号量的值不能为负数。
sem_wait和sem_trywait会阻塞或返回错误,而不是使信号量的值变为负数。 - 线程安全: POSIX 信号量是线程安全的,可以在多线程环境中使用。
- 超时处理: 使用
sem_timedwait时,确保正确设置timespec结构体的值,以避免不必要的超时错误。
sem_init 和 sem_destroy 函数用于初始化和销毁未命名信号量。未命名信号量通常用于线程间同步,因为它们在进程间共享时需要通过共享内存来实现。
sem_init
sem_init 用于初始化一个未命名信号量。
函数原型
1 |
|
参数
sem: 指向信号量对象的指针。信号量对象通常是一个sem_t类型的变量。pshared: 指定信号量是用于进程间共享还是仅用于线程间共享。- 如果
pshared为 0,信号量用于线程间同步。 - 如果
pshared非 0,信号量用于进程间同步,并且信号量对象必须位于共享内存中。
- 如果
value: 信号量的初始值。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:EINVAL: 无效的信号量初始值。ENOSYS: 系统不支持进程间共享信号量。
注意
sem_init初始化的信号量是未命名的,与sem_open创建的命名信号量不同。- 在使用信号量之前,必须先调用
sem_init进行初始化。
sem_destroy
sem_destroy 用于销毁一个未命名信号量。
函数原型
1 |
|
参数
sem: 指向信号量对象的指针。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:EINVAL: 无效的信号量指针。EBUSY: 有线程正在等待该信号量。
注意
sem_destroy只能用于未命名信号量。- 在销毁信号量之前,确保没有线程在等待该信号量,否则可能导致未定义行为。
示例
以下是一个简单的示例,演示如何使用 sem_init 和 sem_destroy:
1 |
|
注意事项
- 线程安全:
sem_init和sem_destroy只能在信号量未被其他线程使用时调用。 - 共享内存: 如果
pshared非 0,确保信号量对象位于共享内存中,以便在进程间共享。 - 信号量的生命周期: 在信号量不再需要时,使用
sem_destroy释放资源。
POSIX 共享内存
在 Linux POSIX IPC 中,共享内存是一种高效的进程间通信机制。以下是对 shm_open、mmap、munmap 和 shm_unlink 函数的详细解析,这些函数用于创建、映射、解除映射和删除共享内存对象。
shm_open
shm_open 用于创建或打开一个 POSIX 共享内存对象。
函数原型
1 |
|
参数
name: 共享内存对象的名称。名称必须以斜杠/开头,例如/my_shm。oflag: 打开标志,类似于open函数的标志。常用标志包括:O_CREAT: 如果共享内存对象不存在,则创建它。O_EXCL: 与O_CREAT一起使用,确保调用创建对象时对象不存在。O_RDWR: 以读写方式打开。O_RDONLY: 以只读方式打开。
mode: 权限位,类似于文件权限,例如0666。
返回值
- 成功时返回共享内存对象的文件描述符。
- 失败时返回
-1,并设置errno。常见错误包括:EEXIST: 对象已存在(当使用O_CREAT | O_EXCL时)。ENOENT: 对象不存在(当未使用O_CREAT时)。
mmap
mmap 用于将共享内存对象映射到进程的地址空间。
函数原型
1 |
|
参数
addr: 映射的起始地址,通常为NULL,由系统选择。length: 映射的字节数。prot: 内存保护标志,常用值包括:PROT_READ: 可读。PROT_WRITE: 可写。
flags: 映射标志,常用值包括:MAP_SHARED: 共享映射,写入会影响其他进程。
fd: 共享内存对象的文件描述符。offset: 映射的偏移量,通常为0。
返回值
- 成功时返回指向映射区域的指针。
- 失败时返回
MAP_FAILED,并设置errno。常见错误包括:EINVAL: 无效参数。ENOMEM: 内存不足。
munmap
munmap 用于解除映射的内存区域。
函数原型
1 |
|
参数
addr: 指向要解除映射的内存区域的指针。length: 要解除映射的字节数。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:EINVAL: 无效的地址或长度。
shm_unlink
shm_unlink 用于删除一个 POSIX 共享内存对象。
函数原型
1 |
|
参数
name: 共享内存对象的名称。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno。常见错误包括:ENOENT: 对象不存在。
示例
以下是一个简单的示例,演示如何使用这些函数:
1 |
|
注意事项
- 命名规则: 共享内存对象的名称必须以斜杠
/开头。 - 权限管理: 确保正确设置权限,以便允许所需的进程访问共享内存。
- 资源清理: 使用完共享内存后,确保调用
munmap和shm_unlink以释放资源。
- Title: Linux环境编程与内核之进程间通信
- Author: 韩乔落
- Created at : 2025-02-06 14:49:30
- Updated at : 2025-03-25 14:27:25
- Link: https://jelasin.github.io/2025/02/06/Linux环境编程与内核之进程间通信/
- License: This work is licensed under CC BY-NC-SA 4.0.