概述 在互联网时代,网络通信编程已经是一个程序员必不可少的技能之一。几乎所有的产品都会涉及网络操作或访问。在Linux编程环境中,系统提供了socket套接字为程序员提供统一的网络编程接口。这里假设读者有一定的Linux网络编程基础,所以对于系统调用的解释都是点到为止,只针对不常见或容易忽视的问题进行详细说明。后面手写一个tcp/ip协议栈,这里除了基本的API不做过多介绍了。
网路连接的建立 socket文件描述符 socket翻译成中文是插座、插槽的意思,而在网络编程中,其被翻译为“套接字”。Linux环境下,我们经常说“一切皆文件”。因此套接字也被视为一种文件描述符。首先,来看看如何使用socket系统调用创建一个套接字,代码如下:
1 2 3 #include <sys/types.h> #include <sys/socket.h> int socket (int domain, int type, int protocol) ;
其中的参数解释如下。
domain :用于指示协议族名字,如AF_INET为IPv4。type :用于指示类型,如基于流通信的SOCK_STREAM。protocol :用于指示对于这种socket的具体协议类型。一般情况下,使用前两个参数限定后,只会存在一种协议类型对应该情况。这时,可以将protocol设置为0。但是在某些情况下,会存在多个协议类型,这时就必须指定具体的协议类型。成功创建socket后,会返回一个文件描述符。失败时,该接口返回-1。
那么对于Linux内核来说,如何知道一个文件描述符是一个套接字,还是一个普通文件呢?其实这个问题也可以扩展到,内核如何知道一个文件描述符的具体类型,如何调用实际类型的操作函数呢?这仍然是VFS的魔力。
文件描述符fd与内核文件结构struct file之间的关系,后者是内核用于管理文件的真正结构,其中的成员变量file->f_op为VFS支持的所有文件操作。VFS层无须关心该文件file的实际类型,它会直接调用file->f_op中的操作函数(这样的处理,与面向对象语言中的多态是类似的)。
对于套接字来说,只要在创建套接字时,将file->f_op设置为正确的套接字操作函数即可。该操作是在socket->sock_map_fd->sock_alloc_file中完成的,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 static int sock_alloc_file (struct socket *sock, struct file **f, int flags) { ………… file = alloc_file(&path, FMODE_READ | FMODE_WRITE, &socket_file_ops); ………… sock->file = file; file->f_flags = O_RDWR | (flags & O_NONBLOCK); file->f_pos = 0 ; file->private_data = sock; *f = file; return fd; }
尽管Linux内核是使用C语言编写的,但是其应用了很多面向对象的设计思想。以这里的file为例,内核利用f_op(对象操作函数指针集合)指向具体对象的操作函数集合。这样一来,对于VFS来说,就只须关心struct file,而无须关心具体的对象类型了,它会在处理过程中,调用正确的处理函数。
绑定IP地址 在成功创建套接字后,该套接字仅仅是一个文件描述符,并没有任何地址与之关联。使用该socket发送数据包时,由于该socket没有任何IP地址,内核会根据策略自动选择一个地址。但是,在某些情况下,我们需要手工指定socket使用哪个IP地址进行发送。这时,就需要使用bind系统调用了。
bind的使用 bind系统调用的接口定义如下:
1 2 3 #include <sys/types.h> #include <sys/socket.h> int bind (int sockfd, const struct sockaddr *addr, socklen_t addrlen) ;
其中的参数解释如下。
sockfd:表示要绑定地址的套接字描述符。
addr:表示绑定到套接字的地址。
addrlen:表示绑定的地址长度。
返回值0表示成功,-1则表示错误。
因为Linux的套接字是针对多种协议族的,而每个协议族都可以有不同的地址类型。所以Linux套接字关于地址的系统调用,统一使用了一个公共结构体,并要求调用者将实际地址参数进行强制类型转换,以此来避免编译警告。
1 2 3 4 struct sockaddr { sa_family_t sa_family; char sa_data[14 ]; }
因为每个协议族的地址类型各不相同,所以需要通过参数addrlen来告诉内核这个地址的实际大小。
struct sockaddr数据类型会在socket涉及地址的所有接口中出现。这是因为套接字接口要支持所有的协议族,所以涉及地址的地方都使用了一个统一的地址结构struct sockaddr。
下面是一个简单示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <stdlib.h> #include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/socket.h> #include <arpa/inet.h> #define LOOPBACK_ADDR 0x7F000001 #define LISTEN_PORT 1234 int main (void ) { int sock; struct sockaddr_in addr ; sock = socket(AF_INET, SOCK_STREAM, 0 ); if (-1 == sock) { printf ("Fail to create socket\n" ); goto err1; } addr.sin_family = AF_INET; addr.sin_addr.s_addr = htonl(LOOPBACK_ADDR); addr.sin_port = htons(LISTEN_PORT); if (0 != bind(sock, (struct sockaddr *)&addr, sizeof (addr))) { printf ("Fail to bind\n" ); goto err2; } if (0 != listen(sock, 3 )) { printf ("Fail to listen\n" ); goto err2; } while (1 ) { sleep(3 ); } close(sock); return 0 ; err2: close(sock); err1: return -1 ; }
在上面的示例中,我们创建了一个TCP套接字,并将回环地址127.0.0.1和端口1234绑定到这个套接字上。运行这个程序,然后通过netstat检查监听端口:
1 2 3 4 [fgao@ubuntu ~]# netstat -ant Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 127.0.0.1:1234 0.0.0.0:* LISTEN
bind 源码分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 SYSCALL_DEFINE3(bind, int , fd, struct sockaddr __user *, umyaddr, int , addrlen) { return __sys_bind(fd, umyaddr, addrlen); } int __sys_bind(int fd, struct sockaddr __user *umyaddr, int addrlen){ struct socket *sock ; struct sockaddr_storage address ; int err, fput_needed; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (sock) { err = move_addr_to_kernel(umyaddr, addrlen, &address); if (!err) { err = security_socket_bind(sock, (struct sockaddr *)&address, addrlen); if (!err) err = sock->ops->bind(sock, (struct sockaddr *)&address, addrlen); } fput_light(sock->file, fput_needed); } return err; }
在bind的调用中,根据不同的协议调用不同的实现函数(Linux的内核代码中,大量使用了这种面向对象的设计思路)。对于AF_INET协议族来说,无论是面向连接的SOCK_STREAM类型,还是SOCK_DGRAM协议类型,其实现函数均是inet_bind。下面来看一下inet_bind的具体实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 int inet_bind (struct socket *sock, struct sockaddr *uaddr, int addr_len) { struct sock *sk = int err; if (sk->sk_prot->bind) { return sk->sk_prot->bind(sk, uaddr, addr_len); } if (addr_len < sizeof (struct sockaddr_in)) return -EINVAL; err = BPF_CGROUP_RUN_PROG_INET4_BIND(sk, uaddr); if (err) return err; return __inet_bind(sk, uaddr, addr_len, false , true ); } EXPORT_SYMBOL(inet_bind); int __inet_bind(struct sock *sk, struct sockaddr *uaddr, int addr_len, bool force_bind_address_no_port, bool with_lock) { struct sockaddr_in *addr =struct sockaddr_in *)uaddr; struct inet_sock *inet = struct net *net = unsigned short snum; int chk_addr_ret; u32 tb_id = RT_TABLE_LOCAL; int err; if (addr->sin_family != AF_INET) { err = -EAFNOSUPPORT; if (addr->sin_family != AF_UNSPEC || addr->sin_addr.s_addr != htonl(INADDR_ANY)) goto out; } tb_id = l3mdev_fib_table_by_index(net, sk->sk_bound_dev_if) ? : tb_id; chk_addr_ret = inet_addr_type_table(net, addr->sin_addr.s_addr, tb_id); err = -EADDRNOTAVAIL; if (!inet_can_nonlocal_bind(net, inet) && addr->sin_addr.s_addr != htonl(INADDR_ANY) && chk_addr_ret != RTN_LOCAL && chk_addr_ret != RTN_MULTICAST && chk_addr_ret != RTN_BROADCAST) goto out; snum = ntohs(addr->sin_port); err = -EACCES; if (snum && inet_port_requires_bind_service(net, snum) && !ns_capable(net->user_ns, CAP_NET_BIND_SERVICE)) goto out; if (with_lock) lock_sock(sk); err = -EINVAL; if (sk->sk_state != TCP_CLOSE || inet->inet_num) goto out_release_sock; inet->inet_rcv_saddr = inet->inet_saddr = addr->sin_addr.s_addr; if (chk_addr_ret == RTN_MULTICAST || chk_addr_ret == RTN_BROADCAST) inet->inet_saddr = 0 ; if (snum || !(inet->bind_address_no_port || force_bind_address_no_port)) { if (sk->sk_prot->get_port(sk, snum)) { inet->inet_saddr = inet->inet_rcv_saddr = 0 ; err = -EADDRINUSE; goto out_release_sock; } err = BPF_CGROUP_RUN_PROG_INET4_POST_BIND(sk); if (err) { inet->inet_saddr = inet->inet_rcv_saddr = 0 ; goto out_release_sock; } } if (inet->inet_rcv_saddr) sk->sk_userlocks |= SOCK_BINDADDR_LOCK; if (snum) sk->sk_userlocks |= SOCK_BINDPORT_LOCK; inet->inet_sport = htons(inet->inet_num); inet->inet_daddr = 0 ; inet->inet_dport = 0 ; sk_dst_reset(sk); err = 0 ; out_release_sock: if (with_lock) release_sock(sk); out: return err; }
无论是APUE还是man手册,在讲解bind的时候都有点问题,或有偏差,或不够详尽。从上面的源码我们知道,通过使用系统控制开关sysctl_ip_nonlocal_bind或套接字选项可以让套接字bind一个非本机地址。但APUE却说套接字只能绑定本机的有效地址——当然这也是由于APUE距现在的时间太久了,而man手册都没有提及非本机地址的事情。
客户端连接过程 connect 的使用 1 2 3 #include <sys/types.h> #include <sys/socket.h> int connect (int sockfd, const struct sockaddr *addr, socklen_t addrlen) ;
其中的参数解释如下:
int sockfd:套接字描述符。const struct sockaddr *addr:要连接的地址。socklen_t addrlen:要连接的地址长度。返回值0表示成功,-1表示失败。
connect的用途是使用指定的套接字去连接指定的地址。对于面向连接的协议(套接字类型为SOCK_STREAM),connect只能成功一次(当然要如此,因为真正的连接已经建立了)。如果重复调用connect,会返回-1表示失败,同时错误码为EISCONN。而对于非面向连接的协议(套接字类型为SOCK_DGRAM),则可以执行多次connect(因为这时的connect仅仅是设置了默认的目的地址)。
对于TCP套接字来说,connect实际上是要真正地进行三次握手,所以其默认是一个阻塞操作。那么是否可以写一个非阻塞的TCP connect代码呢?这是一个合格的网络开发工程师的基本功,具体的实现可以参看UNPv1的实现。更重要是要理解其原理,这样才能在需要的时候,信手拈来。
connect 源码分析 connect的源码入口位于socket.c,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 SYSCALL_DEFINE3(connect, int , fd, struct sockaddr __user *, uservaddr, int , addrlen) { return __sys_connect(fd, uservaddr, addrlen); } int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen){ int ret = -EBADF; struct fd f ; f = fdget(fd); if (f.file) { struct sockaddr_storage address ; ret = move_addr_to_kernel(uservaddr, addrlen, &address); if (!ret) ret = __sys_connect_file(f.file, &address, addrlen, 0 ); if (f.flags) fput(f.file); } return ret; } int __sys_connect_file(struct file *file, struct sockaddr_storage *address, int addrlen, int file_flags) { struct socket *sock ; int err; sock = sock_from_file(file, &err); if (!sock) goto out; err = security_socket_connect(sock, (struct sockaddr *)address, addrlen); if (err) goto out; err = sock->ops->connect(sock, (struct sockaddr *)address, addrlen, sock->file->f_flags | file_flags); out: return err; }
对于AF_INET协议族来说,面向连接的协议类型是SOCK_STREAM,其连接函数为inet_stream_connect,而非面向连接的协议类型SOCK_DGRAM,其连接函数为inet_dgram_connect。这很合理,因为从connect的功能实现上看,两者的实现效果完全不同。让我们先从简单的inet_dgram_connect入手。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 int inet_dgram_connect (struct socket *sock, struct sockaddr *uaddr, int addr_len, int flags) { struct sock *sk = int err; if (addr_len < sizeof (uaddr->sa_family)) return -EINVAL; if (uaddr->sa_family == AF_UNSPEC) return sk->sk_prot->disconnect(sk, flags); if (BPF_CGROUP_PRE_CONNECT_ENABLED(sk)) { err = sk->sk_prot->pre_connect(sk, uaddr, addr_len); if (err) return err; } if (!inet_sk(sk)->inet_num && inet_autobind(sk)) return -EAGAIN; return sk->sk_prot->connect(sk, uaddr, addr_len); } EXPORT_SYMBOL(inet_dgram_connect); int ip4_datagram_connect (struct sock *sk, struct sockaddr *uaddr, int addr_len) { int res; lock_sock(sk); res = __ip4_datagram_connect(sk, uaddr, addr_len); release_sock(sk); return res; } EXPORT_SYMBOL(ip4_datagram_connect); int __ip4_datagram_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len){ struct inet_sock *inet = struct sockaddr_in *usin =struct sockaddr_in *) uaddr; struct flowi4 *fl4 ; struct rtable *rt ; __be32 saddr; int oif; int err; if (addr_len < sizeof (*usin)) return -EINVAL; if (usin->sin_family != AF_INET) return -EAFNOSUPPORT; sk_dst_reset(sk); oif = sk->sk_bound_dev_if; saddr = inet->inet_saddr; if (ipv4_is_multicast(usin->sin_addr.s_addr)) { if (!oif || netif_index_is_l3_master(sock_net(sk), oif)) oif = inet->mc_index; if (!saddr) saddr = inet->mc_addr; } fl4 = &inet->cork.fl.u.ip4; rt = ip_route_connect(fl4, usin->sin_addr.s_addr, saddr, RT_CONN_FLAGS(sk), oif, sk->sk_protocol, inet->inet_sport, usin->sin_port, sk); if (IS_ERR(rt)) { err = PTR_ERR(rt); if (err == -ENETUNREACH) IP_INC_STATS(sock_net(sk), IPSTATS_MIB_OUTNOROUTES); goto out; } if ((rt->rt_flags & RTCF_BROADCAST) && !sock_flag(sk, SOCK_BROADCAST)) { ip_rt_put(rt); err = -EACCES; goto out; } if (!inet->inet_saddr) inet->inet_saddr = fl4->saddr; if (!inet->inet_rcv_saddr) { inet->inet_rcv_saddr = fl4->saddr; if (sk->sk_prot->rehash) sk->sk_prot->rehash(sk); } inet->inet_daddr = fl4->daddr; inet->inet_dport = usin->sin_port; reuseport_has_conns(sk, true ); sk->sk_state = TCP_ESTABLISHED; sk_set_txhash(sk); inet->inet_id = prandom_u32(); sk_dst_set(sk, &rt->dst); err = 0 ; out: return err; } EXPORT_SYMBOL(__ip4_datagram_connect);
由于功能比较简单,所以UDP的connect实现源码也一目了然,可以看到,只是设置了目的IP、端口和路由信息。
下面看一下TCP的connect实现,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 int inet_stream_connect (struct socket *sock, struct sockaddr *uaddr, int addr_len, int flags) { int err; lock_sock(sock->sk); err = __inet_stream_connect(sock, uaddr, addr_len, flags, 0 ); release_sock(sock->sk); return err; } int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr, int addr_len, int flags, int is_sendmsg) { struct sock *sk = int err; long timeo; if (uaddr) { if (addr_len < sizeof (uaddr->sa_family)) return -EINVAL; if (uaddr->sa_family == AF_UNSPEC) { err = sk->sk_prot->disconnect(sk, flags); sock->state = err ? SS_DISCONNECTING : SS_UNCONNECTED; goto out; } } switch (sock->state) { default : err = -EINVAL; goto out; case SS_CONNECTED: err = -EISCONN; goto out; case SS_CONNECTING: if (inet_sk(sk)->defer_connect) err = is_sendmsg ? -EINPROGRESS : -EISCONN; else err = -EALREADY; break ; case SS_UNCONNECTED: err = -EISCONN; if (sk->sk_state != TCP_CLOSE) goto out; if (BPF_CGROUP_PRE_CONNECT_ENABLED(sk)) { err = sk->sk_prot->pre_connect(sk, uaddr, addr_len); if (err) goto out; } err = sk->sk_prot->connect(sk, uaddr, addr_len); if (err < 0 ) goto out; sock->state = SS_CONNECTING; if (!err && inet_sk(sk)->defer_connect) goto out; err = -EINPROGRESS; break ; } timeo = sock_sndtimeo(sk, flags & O_NONBLOCK); if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV)) { int writebias = (sk->sk_protocol == IPPROTO_TCP) && tcp_sk(sk)->fastopen_req && tcp_sk(sk)->fastopen_req->data ? 1 : 0 ; if (!timeo || !inet_wait_for_connect(sk, timeo, writebias)) goto out; err = sock_intr_errno(timeo); if (signal_pending(current)) goto out; } if (sk->sk_state == TCP_CLOSE) goto sock_error; sock->state = SS_CONNECTED; err = 0 ; out: return err; sock_error: err = sock_error(sk) ? : -ECONNABORTED; sock->state = SS_UNCONNECTED; if (sk->sk_prot->disconnect(sk, flags)) sock->state = SS_DISCONNECTING; goto out; }
接下来,就需要进入TCP协议自定义的connect函数tcp_v4_connect了,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 int tcp_v4_connect (struct sock *sk, struct sockaddr *uaddr, int addr_len) { struct sockaddr_in *usin =struct sockaddr_in *)uaddr; struct inet_sock *inet = struct tcp_sock *tp = __be16 orig_sport, orig_dport; __be32 daddr, nexthop; struct flowi4 *fl4 ; struct rtable *rt ; int err; struct ip_options_rcu *inet_opt ; struct inet_timewait_death_row *tcp_death_row = if (addr_len < sizeof (struct sockaddr_in)) return -EINVAL; if (usin->sin_family != AF_INET) return -EAFNOSUPPORT; nexthop = daddr = usin->sin_addr.s_addr; inet_opt = rcu_dereference_protected(inet->inet_opt, lockdep_sock_is_held(sk)); if (inet_opt && inet_opt->opt.srr) { if (!daddr) return -EINVAL; nexthop = inet_opt->opt.faddr; } orig_sport = inet->inet_sport; orig_dport = usin->sin_port; fl4 = &inet->cork.fl.u.ip4; rt = ip_route_connect(fl4, nexthop, inet->inet_saddr, RT_CONN_FLAGS(sk), sk->sk_bound_dev_if, IPPROTO_TCP, orig_sport, orig_dport, sk); if (IS_ERR(rt)) { err = PTR_ERR(rt); if (err == -ENETUNREACH) IP_INC_STATS(sock_net(sk), IPSTATS_MIB_OUTNOROUTES); return err; } if (rt->rt_flags & (RTCF_MULTICAST | RTCF_BROADCAST)) { ip_rt_put(rt); return -ENETUNREACH; } if (!inet_opt || !inet_opt->opt.srr) daddr = fl4->daddr; if (!inet->inet_saddr) inet->inet_saddr = fl4->saddr; sk_rcv_saddr_set(sk, inet->inet_saddr); if (tp->rx_opt.ts_recent_stamp && inet->inet_daddr != daddr) { tp->rx_opt.ts_recent = 0 ; tp->rx_opt.ts_recent_stamp = 0 ; if (likely(!tp->repair)) WRITE_ONCE(tp->write_seq, 0 ); } inet->inet_dport = usin->sin_port; sk_daddr_set(sk, daddr); inet_csk(sk)->icsk_ext_hdr_len = 0 ; if (inet_opt) inet_csk(sk)->icsk_ext_hdr_len = inet_opt->opt.optlen; tp->rx_opt.mss_clamp = TCP_MSS_DEFAULT; tcp_set_state(sk, TCP_SYN_SENT); err = inet_hash_connect(tcp_death_row, sk); if (err) goto failure; sk_set_txhash(sk); rt = ip_route_newports(fl4, rt, orig_sport, orig_dport, inet->inet_sport, inet->inet_dport, sk); if (IS_ERR(rt)) { err = PTR_ERR(rt); rt = NULL ; goto failure; } sk->sk_gso_type = SKB_GSO_TCPV4; sk_setup_caps(sk, &rt->dst); rt = NULL ; if (likely(!tp->repair)) { if (!tp->write_seq) WRITE_ONCE(tp->write_seq, secure_tcp_seq(inet->inet_saddr, inet->inet_daddr, inet->inet_sport, usin->sin_port)); tp->tsoffset = secure_tcp_ts_off(sock_net(sk), inet->inet_saddr, inet->inet_daddr); } inet->inet_id = prandom_u32(); if (tcp_fastopen_defer_connect(sk, &err)) return err; if (err) goto failure; err = tcp_connect(sk); if (err) goto failure; return 0 ; failure: tcp_set_state(sk, TCP_CLOSE); ip_rt_put(rt); sk->sk_route_caps = 0 ; inet->inet_dport = 0 ; return err; }
下面来分析tcp_connect,看看内核是如何发送SYN包的,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 int tcp_connect (struct sock *sk) { struct tcp_sock *tp = struct sk_buff *buff ; int err; tcp_call_bpf(sk, BPF_SOCK_OPS_TCP_CONNECT_CB, 0 , NULL ); if (inet_csk(sk)->icsk_af_ops->rebuild_header(sk)) return -EHOSTUNREACH; tcp_connect_init(sk); if (unlikely(tp->repair)) { tcp_finish_connect(sk, NULL ); return 0 ; } buff = sk_stream_alloc_skb(sk, 0 , sk->sk_allocation, true ); if (unlikely(!buff)) return -ENOBUFS; tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN); tcp_mstamp_refresh(tp); tp->retrans_stamp = tcp_time_stamp(tp); tcp_connect_queue_skb(sk, buff); tcp_ecn_send_syn(sk, buff); tcp_rbtree_insert(&sk->tcp_rtx_queue, buff); err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) : tcp_transmit_skb(sk, buff, 1 , sk->sk_allocation); if (err == -ECONNREFUSED) return err; WRITE_ONCE(tp->snd_nxt, tp->write_seq); tp->pushed_seq = tp->write_seq; buff = tcp_send_head(sk); if (unlikely(buff)) { WRITE_ONCE(tp->snd_nxt, TCP_SKB_CB(buff)->seq); tp->pushed_seq = TCP_SKB_CB(buff)->seq; } TCP_INC_STATS(sock_net(sk), TCP_MIB_ACTIVEOPENS); inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS, inet_csk(sk)->icsk_rto, TCP_RTO_MAX); return 0 ; }
服务端连接过程 listen 的使用 服务器端用listen来监听端口,其原型为:
1 2 3 #include <sys/types.h> #include <sys/socket.h> int listen (int sockfd, int backlog) ;
参数int sockfd:成功创建的TCP套接字。
int backlog:定义TCP未处理连接的队列长度。该队列虽然已经完成了三次握手,但服务器端还没有执行accept的连接。
函数的返回值为0,表示成功;-1表示失败。
listen 源码分析 listen的源码入口位于socket.c,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 SYSCALL_DEFINE2(listen, int , fd, int , backlog) { return __sys_listen(fd, backlog); } int __sys_listen(int fd, int backlog){ struct socket *sock ; int err, fput_needed; int somaxconn; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (sock) { somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn; if ((unsigned int )backlog > somaxconn) backlog = somaxconn; err = security_socket_listen(sock, backlog); if (!err) err = sock->ops->listen(sock, backlog); fput_light(sock->file, fput_needed); } return err; }
AF_INET协议族的listen实现函数为inet_listen,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 int inet_listen (struct socket *sock, int backlog) { struct sock *sk = unsigned char old_state; int err, tcp_fastopen; lock_sock(sk); err = -EINVAL; if (sock->state != SS_UNCONNECTED || sock->type != SOCK_STREAM) goto out; old_state = sk->sk_state; if (!((1 << old_state) & (TCPF_CLOSE | TCPF_LISTEN))) goto out; WRITE_ONCE(sk->sk_max_ack_backlog, backlog); if (old_state != TCP_LISTEN) { tcp_fastopen = sock_net(sk)->ipv4.sysctl_tcp_fastopen; if ((tcp_fastopen & TFO_SERVER_WO_SOCKOPT1) && (tcp_fastopen & TFO_SERVER_ENABLE) && !inet_csk(sk)->icsk_accept_queue.fastopenq.max_qlen) { fastopen_queue_tune(sk, backlog); tcp_fastopen_init_key_once(sock_net(sk)); } err = inet_csk_listen_start(sk, backlog); if (err) goto out; tcp_call_bpf(sk, BPF_SOCK_OPS_TCP_LISTEN_CB, 0 , NULL ); } err = 0 ; out: release_sock(sk); return err; }
接下来进入inet_csk_listen_start,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 int inet_csk_listen_start (struct sock *sk, int backlog) { struct inet_connection_sock *icsk = struct inet_sock *inet = int err = -EADDRINUSE; reqsk_queue_alloc(&icsk->icsk_accept_queue); sk->sk_ack_backlog = 0 ; inet_csk_delack_init(sk); inet_sk_state_store(sk, TCP_LISTEN); if (!sk->sk_prot->get_port(sk, inet->inet_num)) { inet->inet_sport = htons(inet->inet_num); sk_dst_reset(sk); err = sk->sk_prot->hash(sk); if (likely(!err)) return 0 ; } inet_sk_set_state(sk, TCP_CLOSE); return err; }
现在服务器端已经处于监听状态,可以接收客户端的连接请求了。同时,通过源码跟踪,也可以发现在第二个参数不超过系统限制的最大值的情况下,内核已直接使用其值作为已连接队列的长度了。
accept 的使用 accept用于从指定套接字的连接队列中取出第一个连接,并返回一个新的套接字用于与客户端进行通信,示例代码如下:
1 2 3 4 #include <sys/types.h> #include <sys/socket.h> int accept (int sockfd, struct sockaddr *addr, socklen_t *addrlen) ;int accept4 (int sockfd, struct sockaddr *addr, socklen_t *addrlen, int flags) ;
其中的参数解释如下:
int sockfd:处于监听状态的套接字。struct sockaddr *addr:用于保存对端的地址信息。socklen_t *addrlen:是一个输入输出值。调用者将其初始化为addr缓存的大小,accept返回时,会将其设置为addr的大小。int flags:是新引入的系统调用accept4的标志位;目前支持SOCK_NONBLOCK和SOCK_CLOEXEC。关于返回值,若执行成功,则返回一个非负的文件描述符;若失败则返回-1。
若不关心对端地址信息,则可以将addr和addrlen设置为NULL。
accept 源码分析 accept的源码入口位于文件socket.c,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 SYSCALL_DEFINE3(accept, int , fd, struct sockaddr __user *, upeer_sockaddr, int __user *, upeer_addrlen) { return __sys_accept4(fd, upeer_sockaddr, upeer_addrlen, 0 ); } SYSCALL_DEFINE4(accept4, int , fd, struct sockaddr __user *, upeer_sockaddr, int __user *, upeer_addrlen, int , flags) { return __sys_accept4(fd, upeer_sockaddr, upeer_addrlen, flags); } int __sys_accept4(int fd, struct sockaddr __user *upeer_sockaddr, int __user *upeer_addrlen, int flags) { int ret = -EBADF; struct fd f ; f = fdget(fd); if (f.file) { ret = __sys_accept4_file(f.file, 0 , upeer_sockaddr, upeer_addrlen, flags, rlimit(RLIMIT_NOFILE)); if (f.flags) fput(f.file); } return ret; } int __sys_accept4_file(struct file *file, unsigned file_flags, struct sockaddr __user *upeer_sockaddr, int __user *upeer_addrlen, int flags, unsigned long nofile) { struct socket *sock , *newsock ; struct file *newfile ; int err, len, newfd; struct sockaddr_storage address ; if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK)) return -EINVAL; if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK)) flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK; sock = sock_from_file(file, &err); if (!sock) goto out; err = -ENFILE; newsock = sock_alloc(); if (!newsock) goto out; newsock->type = sock->type; newsock->ops = sock->ops; __module_get(newsock->ops->owner); newfd = __get_unused_fd_flags(flags, nofile); if (unlikely(newfd < 0 )) { err = newfd; sock_release(newsock); goto out; } newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name); if (IS_ERR(newfile)) { err = PTR_ERR(newfile); put_unused_fd(newfd); goto out; } err = security_socket_accept(sock, newsock); if (err) goto out_fd; err = sock->ops->accept(sock, newsock, sock->file->f_flags | file_flags, false ); if (err < 0 ) goto out_fd; if (upeer_sockaddr) { len = newsock->ops->getname(newsock, (struct sockaddr *)&address, 2 ); if (len < 0 ) { err = -ECONNABORTED; goto out_fd; } err = move_addr_to_user(&address, len, upeer_sockaddr, upeer_addrlen); if (err < 0 ) goto out_fd; } fd_install(newfd, newfile); err = newfd; out: return err; out_fd: fput(newfile); put_unused_fd(newfd); goto out; }
对于AF_INET协议族,accept的实现函数为inet_accept,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int inet_accept (struct socket *sock, struct socket *newsock, int flags, bool kern) { struct sock *sk1 = int err = -EINVAL; struct sock *sk2 = if (!sk2) goto do_err; lock_sock(sk2); sock_rps_record_flow(sk2); WARN_ON(!((1 << sk2->sk_state) & (TCPF_ESTABLISHED | TCPF_SYN_RECV | TCPF_CLOSE_WAIT | TCPF_CLOSE))); sock_graft(sk2, newsock); newsock->state = SS_CONNECTED; err = 0 ; release_sock(sk2); do_err: return err; }
对于TCP协议来说,其accept实现函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 struct sock *inet_csk_accept (struct sock *sk, int flags, int *err, bool kern) { struct inet_connection_sock *icsk = struct request_sock_queue *queue = struct request_sock *req ; struct sock *newsk ; int error; lock_sock(sk); error = -EINVAL; if (sk->sk_state != TCP_LISTEN) goto out_err; if (reqsk_queue_empty(queue )) { long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK); error = -EAGAIN; if (!timeo) goto out_err; error = inet_csk_wait_for_connect(sk, timeo); if (error) goto out_err; } req = reqsk_queue_remove(queue , sk); newsk = req->sk; if (sk->sk_protocol == IPPROTO_TCP && tcp_rsk(req)->tfo_listener) { spin_lock_bh(&queue ->fastopenq.lock); if (tcp_rsk(req)->tfo_listener) { req->sk = NULL ; req = NULL ; } spin_unlock_bh(&queue ->fastopenq.lock); } out: release_sock(sk); if (newsk && mem_cgroup_sockets_enabled) { int amt; lock_sock(newsk); amt = sk_mem_pages(newsk->sk_forward_alloc + atomic_read (&newsk->sk_rmem_alloc)); mem_cgroup_sk_alloc(newsk); if (newsk->sk_memcg && amt) mem_cgroup_charge_skmem(newsk->sk_memcg, amt); release_sock(newsk); } if (req) reqsk_put(req); return newsk; out_err: newsk = NULL ; req = NULL ; *err = error; goto out; }
TCP 三次握手的实现分析 前面从客户端和服务器端的系统调用的角度,来分析和学习TCP的连接过程。本节将从TCP三次握手的数据包交互过程,来研究TCP连接的建立。。
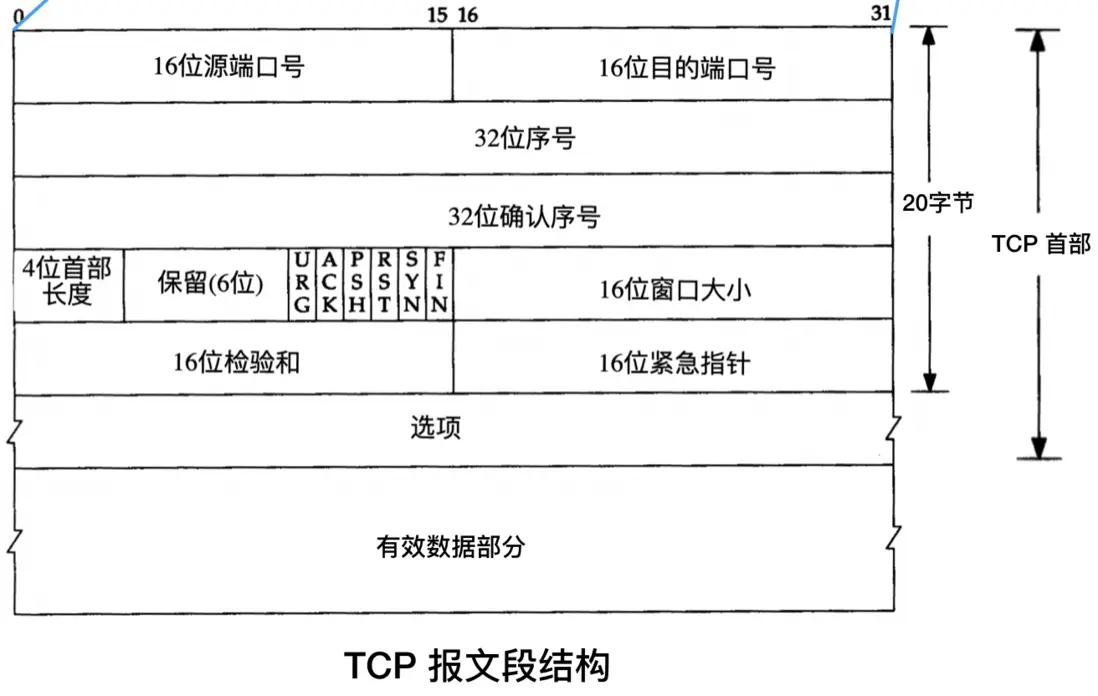
TCP报文格式:
TCP 首部包含以下内容,请留意其中的控制位,在三次握手和四次挥手过程中会频繁出现:
**端口号 (Source Port and Destination Port)**:每个 TCP 报文段都包含源端和目的端的端口号,用于寻找发送端和接收端应用进程。这两个值加上 IP 首部中的源端 IP 地址和目的端 IP 地址就可以确定一个唯一的 TCP 连接。
**序号 (Sequence Number)**:这个字段的主要作用是用于将失序的数据重新排列。TCP 会隐式地对字节流中的每个字节进行编号,而 TCP 报文段的序号被设置为其数据部分的第一个字节的编号。序号是 32 bit 的无符号数,取值范围是0到 232 - 1。
**确认序号 (Acknowledgment Number)**:接收方在接受到数据后,会回复确认报文,其中包含确认序号,作用就是告诉发送方自己接收到了哪些数据,下一次数据从哪里开始发,因此,确认序号应当是上次已成功收到数据字节序号加 1。只有 ACK 标志为 1 时确认序号字段才有效。
**首部长度 (Header Length)**:首部中的选项部分的长度是可变的,因此首部的长度也是可变的,所以需要这个字段来明确表示首部的长度,这个字段占 4 bit,4 位的二进制数最大可以表示 15,而首部长度是以 4 个字节为一个单位的,因此首部最大长度是 15 * 4 = 60 字节。
**保留字段 (Reserved)**:占 6 位,未来可能有具体用途,目前默认值为0.
**控制位 (Control Bits)**:在三次握手和四次挥手中会经常看到 SYN、ACK 和 FIN 的身影,一共有 6 个标志位,它们表示的意义如下:
**URG (Urgent Bit)**:值为 1 时,紧急指针生效
**ACK (Acknowledgment Bit)**:值为 1 时,确认序号生效
**PSH (Push Bit)**:接收方应尽快将这个报文段交给应用层
**RST (Reset Bit)**:发送端遇到问题,想要重建连接
**SYN (Synchronize Bit)**:同步序号,用于发起一个连接
**FIN (Finish Bit)**:发送端要求关闭连接
**窗口大小 (Window)**: TCP的流量控制由连接的每一端通过声明的窗口大小来提供。窗口大小为字节数,起始于确认序号字段指明的值,这个值是接收端正期望接收的字节。窗口大小是一个 16 bit 字段,单位是字节, 因而窗口大小最大为 65535 字节。
**检验和 (Checksum)**:功能类似于数字签名,用于验证数据完整性,也就是确保数据未被修改。检验和覆盖了整个 TCP 报文段,包括 TCP 首部和 TCP 数据,发送端根据特定算法对整个报文段计算出一个检验和,接收端会进行计算并验证。
**紧急指针 (Urgent Pointer)**:当 URG 控制位值为 1 时,此字段生效,紧急指针是一个正的偏移量,和序号字段中的值相加表示紧急数据最后一个字节的序号。 TCP 的紧急方式是发送端向另一端发送紧急数据的一种方式。
**选项 (Options)**:这一部分是可选字段,也就是非必须字段,最常见的可选字段是“最长报文大小 (MSS,Maximum Segment Size)”。
**有效数据部分 (Data)**:这部分也不是必须的,比如在建立和关闭 TCP 连接的阶段,双方交换的报文段就只包含 TCP 首部。
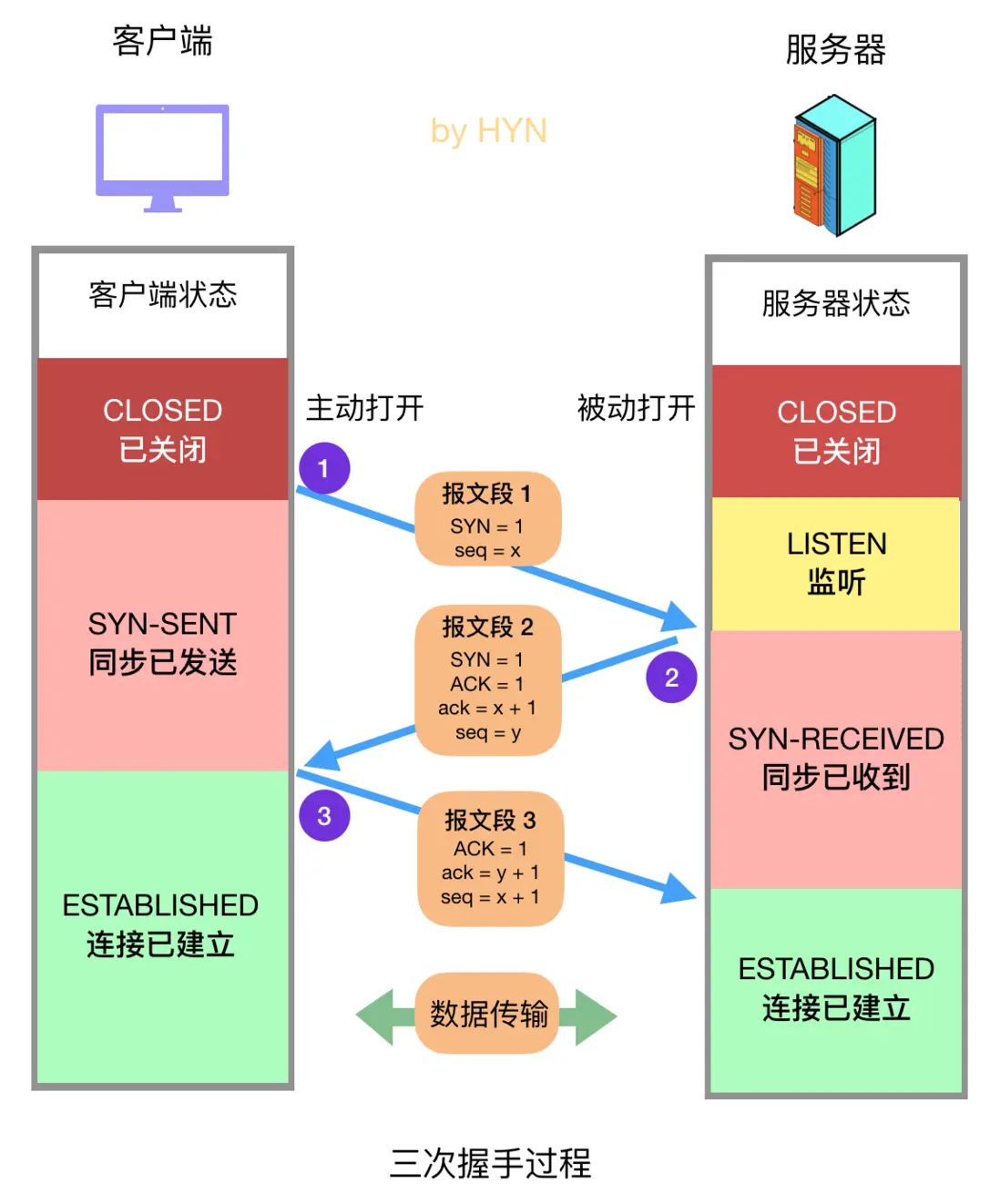
TCP三次握手
三次握手
第一次握手: 客户端向服务器发送报文段1,其中的 SYN 标志位 (前文已经介绍过各种标志位的作用)的值为 1,表示这是一个用于请求发起连接的报文段,其中的序号字段 (Sequence Number,图中简写为seq)被设置为初始序号x (Initial Sequence Number,ISN),TCP 连接双方均可随机选择初始序号。发送完报文段1之后,客户端进入 SYN-SENT 状态,等待服务器的确认。第二次握手: 服务器在收到客户端的连接请求后,向客户端发送报文段2作为应答,其中 ACK 标志位设置为 1,表示对客户端做出应答,其确认序号字段 (Acknowledgment Number,图中简写为小写 ack) 生效,该字段值为 x + 1,也就是从客户端收到的报文段的序号加一,代表服务器期望下次收到客户端的数据的序号。此外,报文段2的 SYN 标志位也设置为1,代表这同时也是一个用于发起连接的报文段,序号 seq 设置为服务器初始序号y。发送完报文段2后,服务器进入 SYN-RECEIVED 状态。第三次握手: 客户端在收到报文段2后,向服务器发送报文段3,其 ACK 标志位为1,代表对服务器做出应答,确认序号字段 ack 为 y + 1,序号字段 seq 为 x + 1。此报文段发送完毕后,双方都进入 ESTABLISHED 状态,表示连接已建立。
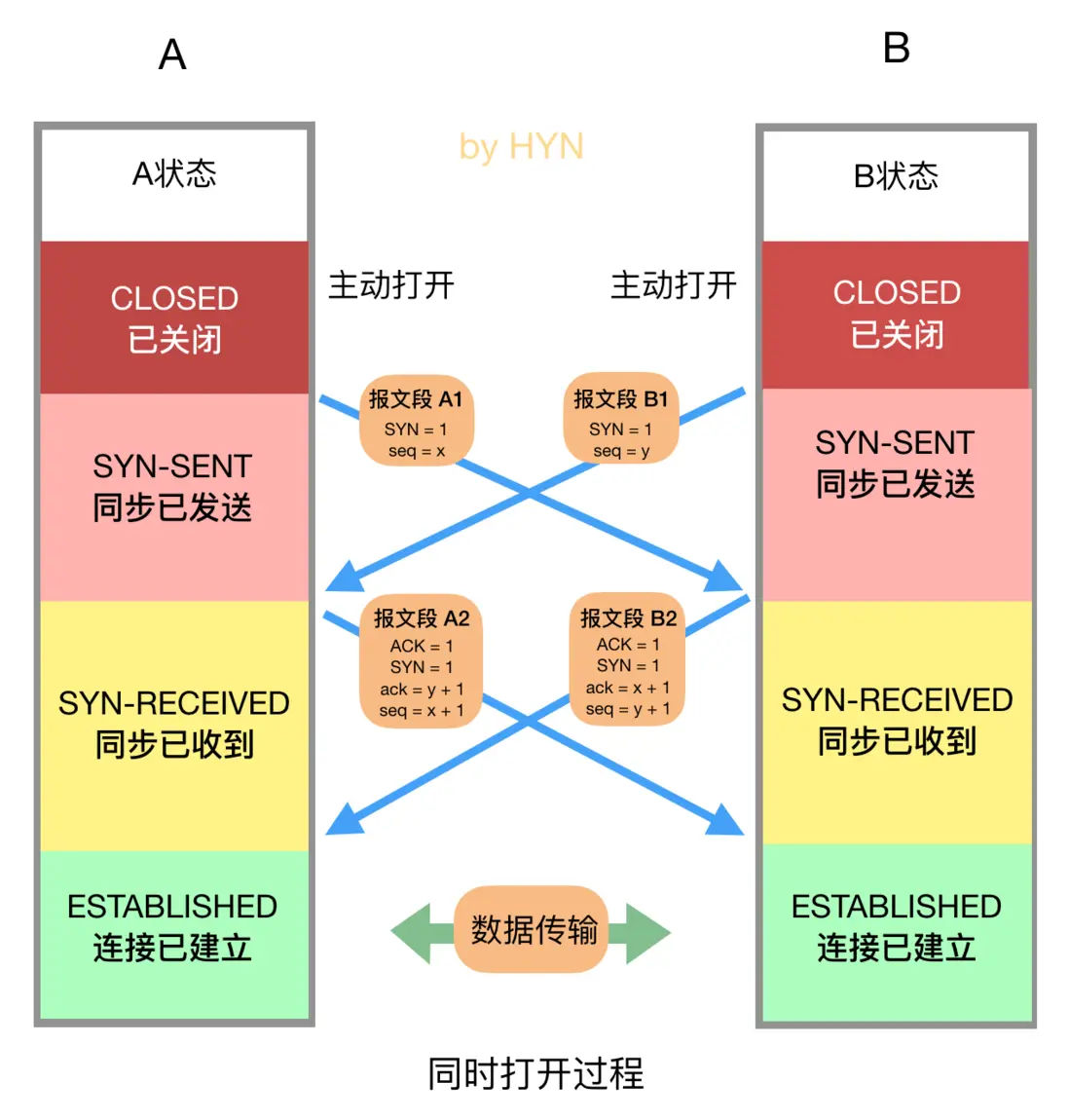
同时打开
这是 TCP 建立连接的特殊情况,有时会出现两台机器同时执行主动打开的情况,不过概率非常小,这种情况大家仅作了解即可。在这种情况下就无所谓发送方和接收方了,双放都可以称为客户端和服务器,同时打开的过程如下:
如图所示,双方在同一时刻发送 SYN 报文段,并进入 SYN-SENT 状态,在收到 SYN 后,状态变为 SYN-RECEIVED,同时它们都再发送一个 SYN + ACK 的报文段,状态都变为 ESTABLISHED,连接成功建立。在此过程中双方一共交换了4个报文段,比三次握手多一个。
TCP 建立连接为什么要三次握手而不是两次?
答:网上大多数资料对这个问题的回答只有简单的一句:防止已过期的连接请求报文突然又传送到服务器,因而产生错误,这既不够全面也不够具体。下面给出比较详细而全面的回答:
防止已过期的连接请求报文突然又传送到服务器,因而产生错误
在双方两次握手即可建立连接的情况下,假设客户端发送 A 报文段请求建立连接,由于网络原因造成 A 暂时无法到达服务器,服务器接收不到请求报文段就不会返回确认报文段,客户端在长时间得不到应答的情况下重新发送请求报文段 B,这次 B 顺利到达服务器,服务器随即返回确认报文并进入 ESTABLISHED 状态,客户端在收到 确认报文后也进入 ESTABLISHED 状态,双方建立连接并传输数据,之后正常断开连接。此时姗姗来迟的 A 报文段才到达服务器,服务器随即返回确认报文并进入 ESTABLISHED 状态,但是已经进入 CLOSED 状态的客户端无法再接受确认报文段,更无法进入 ESTABLISHED 状态,这将导致服务器长时间单方面等待,造成资源浪费。
三次握手才能让双方均确认自己和对方的发送和接收能力都正常
第一次握手:客户端只是发送处请求报文段,什么都无法确认,而服务器可以确认自己的接收能力和对方的发送能力正常;
第二次握手:客户端可以确认自己发送能力和接收能力正常,对方发送能力和接收能力正常;
第三次握手:服务器可以确认自己发送能力和接收能力正常,对方发送能力和接收能力正常;
可见三次握手才能让双方都确认自己和对方的发送和接收能力全部正常,这样就可以愉快地进行通信了。
告知对方自己的初始序号值,并确认收到对方的初始序号值
TCP 实现了可靠的数据传输,原因之一就是 TCP 报文段中维护了序号字段和确认序号字段,也就是图中的 seq 和 ack,通过这两个字段双方都可以知道在自己发出的数据中,哪些是已经被对方确认接收的。这两个字段的值会在初始序号值得基础递增,如果是两次握手,只有发起方的初始序号可以得到确认,而另一方的初始序号则得不到确认。
TCP 建立连接为什么要三次握手而不是四次?
相比上个问题而言,这个问题就简单多了。因为三次握手已经可以确认双方的发送接收能力正常,双方都知道彼此已经准备好,而且也可以完成对双方初始序号值得确认,也就无需再第四次握手了。
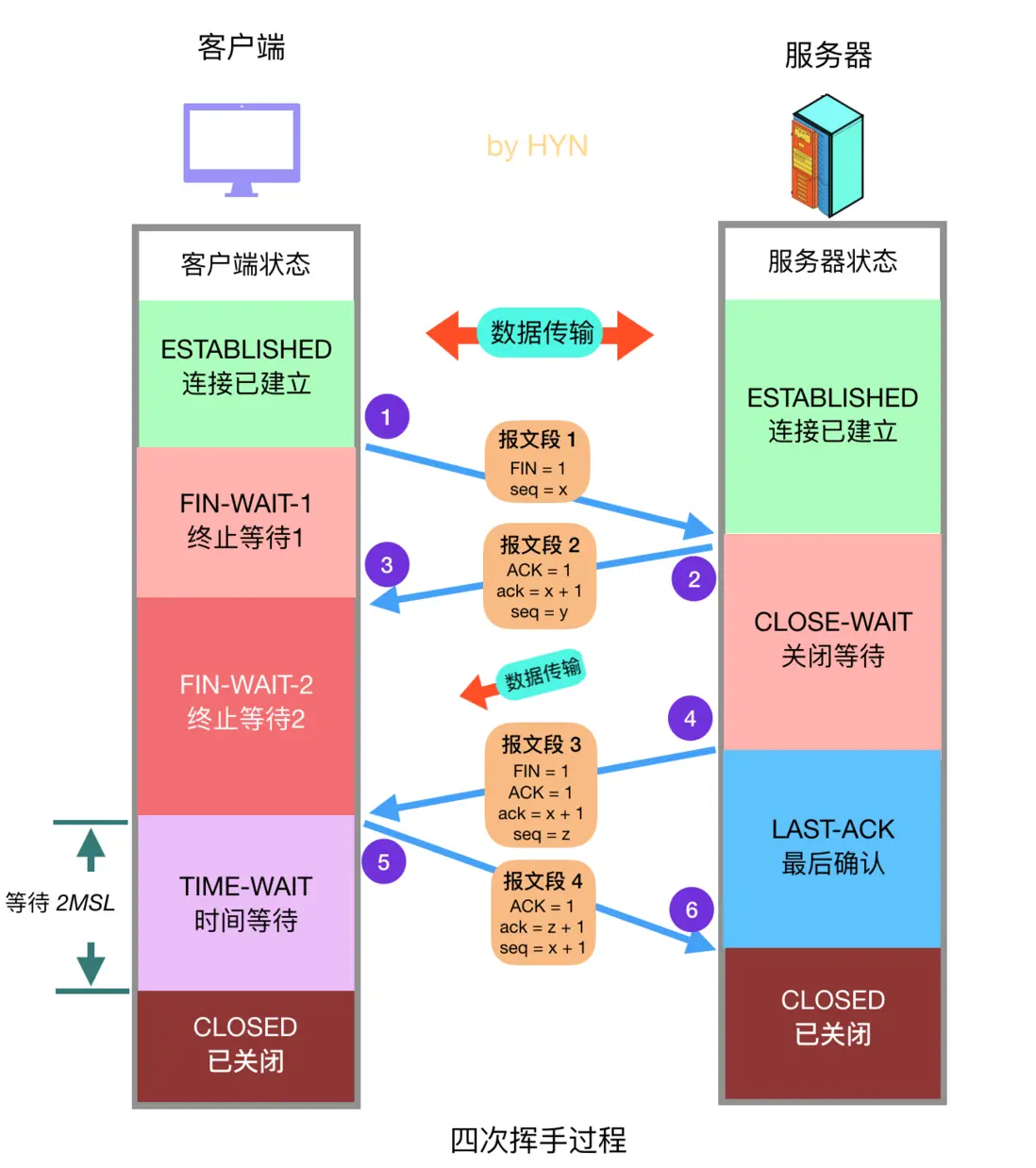
TCP 四次挥手的实现分析 建立一个连接需要三次握手,而终止一个连接要经过 4次握手。这由 TCP 的半关闭( half-close) 造成的。既然一个 TCP 连接是全双工 (即数据在两个方向上能同时传递), 因此每个方向必须单独地进行关闭。这原则就是当一方完成它的数据发送任务后就能发送一个 FIN 来终止这个方向连接。当一端收到一个 FIN,它必须通知应用层另一端已经终止了数据传送。理论上客户端和服务器都可以发起主动关闭,但是更多的情况下是客户端主动发起。
四次挥手详细过程如下:
客户端发送关闭连接的报文段,FIN 标志位1,请求关闭连接,并停止发送数据。序号字段 seq = x (等于之前发送的所有数据的最后一个字节的序号加一),然后客户端会进入 FIN-WAIT-1 状态,等待来自服务器的确认报文。
服务器收到 FIN 报文后,发回确认报文,ACK = 1, ack = x + 1,并带上自己的序号 seq = y,然后服务器就进入 CLOSE-WAIT 状态。服务器还会通知上层的应用程序对方已经释放连接,此时 TCP 处于半关闭状态,也就是说客户端已经没有数据要发送了,但是服务器还可以发送数据,客户端也还能够接收。
客户端收到服务器的 ACK 报文段后随即进入 FIN-WAIT-2 状态,此时还能收到来自服务器的数据,直到收到 FIN 报文段。
服务器发送完所有数据后,会向客户端发送 FIN 报文段,各字段值如图所示,随后服务器进入 LAST-ACK 状态,等待来自客户端的确认报文段。
客户端收到来自服务器的 FIN 报文段后,向服务器发送 ACK 报文,随后进入 TIME-WAIT 状态,等待 2MSL(2 * Maximum Segment Lifetime,两倍的报文段最大存活时间) ,这是任何报文段在被丢弃前能在网络中存在的最长时间,常用值有30秒、1分钟和2分钟。如无特殊情况,客户端会进入 CLOSED 状态。
服务器在接收到客户端的 ACK 报文后会随即进入 CLOSED 状态,由于没有等待时间,一般而言,服务器比客户端更早进入 CLOSED 状态。
为什么 TCP 关闭连接为什么要四次而不是三次?
服务器在收到客户端的 FIN 报文段后,可能还有一些数据要传输,所以不能马上关闭连接,但是会做出应答,返回 ACK 报文段,接下来可能会继续发送数据,在数据发送完后,服务器会向客户单发送 FIN 报文,表示数据已经发送完毕,请求关闭连接,然后客户端再做出应答,因此一共需要四次挥手。
客户端为什么需要在 TIME-WAIT 状态等待 2MSL 时间才能进入 CLOSED 状态?
按照常理,在网络正常的情况下,四个报文段发送完后,双方就可以关闭连接进入 CLOSED 状态了,但是网络并不总是可靠的,如果客户端发送的 ACK 报文段丢失,服务器在接收不到 ACK 的情况下会一直重发 FIN 报文段,这显然不是我们想要的。因此客户端为了确保服务器收到了 ACK,会设置一个定时器,并在 TIME-WAIT 状态等待 2MSL 的时间,如果在此期间又收到了来自服务器的 FIN 报文段,那么客户端会重新设置计时器并再次等待 2MSL 的时间,如果在这段时间内没有收到来自服务器的 FIN 报文,那就说明服务器已经成功收到了 ACK 报文,此时客户端就可以进入 CLOSED 状态了。
数据报文的发送 发送相关接口 1 2 3 4 5 6 #include <sys/types.h> #include <sys/socket.h> ssize_t send (int sockfd, const void *buf, size_t len, int flags) ;ssize_t sendto (int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen) ;ssize_t sendmsg (int sockfd, const struct msghdr *msg, int flags) ;
send只能用于处理已连接状态的套接字。而sendto可以在调用时,指定目的地址。这样的话,如果套接字已经是连接状态,那么目的地址dest_addr与地址长度就应该为NULL和0,不然就可能会返回错误。sendmsg则比较特殊,无论是要发送的数据还是目的地址,都保存在msg中。其中msg.msg_name和msg.msg_len用于指明目的地址,而msg.msg_iov则用于保存要发送的数据。这三个系统调用都支持设置指示标志位flags。
稍微现代些的系统调用,一般都会拥有或保留一个指示标志参数。通过标志位flags,可以从容地为系统调用增加新功能,并同时兼容老版本。dup、dup2和dup3则是这方面的一个反面典型。在不支持flag的情况下,不得不一再创建新的dup接口,直到dup3加入了对flag的支持为止。
由于socket同时还是文件描述符,所以为文件提供的写操作(如write、writev等),也可以被socket套接字直接调用,在此就不重复叙述了。
数据包从用户空间到内核空间的流程 send的内核实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 SYSCALL_DEFINE6(sendto, int , fd, void __user *, buff, size_t , len, unsigned int , flags, struct sockaddr __user *, addr, int , addr_len) { return __sys_sendto(fd, buff, len, flags, addr, addr_len); } SYSCALL_DEFINE4(send, int , fd, void __user *, buff, size_t , len, unsigned int , flags) { return __sys_sendto(fd, buff, len, flags, NULL , 0 ); } int __sys_sendto(int fd, void __user *buff, size_t len, unsigned int flags, struct sockaddr __user *addr, int addr_len) { struct socket *sock ; struct sockaddr_storage address ; int err; struct msghdr msg ; struct iovec iov ; int fput_needed; err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter); if (unlikely(err)) return err; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; msg.msg_name = NULL ; msg.msg_control = NULL ; msg.msg_controllen = 0 ; msg.msg_namelen = 0 ; if (addr) { err = move_addr_to_kernel(addr, addr_len, &address); if (err < 0 ) goto out_put; msg.msg_name = (struct sockaddr *)&address; msg.msg_namelen = addr_len; } if (sock->file->f_flags & O_NONBLOCK) flags |= MSG_DONTWAIT; msg.msg_flags = flags; err = sock_sendmsg(sock, &msg); out_put: fput_light(sock->file, fput_needed); out: return err; }
这里又调用到sock_sendmsg了,从名字上就能感觉到它可能也会被第三个接口sendmsg所调用。下面让我们来验证这个猜想。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 SYSCALL_DEFINE3(sendmsg, int , fd, struct user_msghdr __user *, msg, unsigned int , flags) { return __sys_sendmsg(fd, msg, flags, true ); } long __sys_sendmsg(int fd, struct user_msghdr __user *msg, unsigned int flags, bool forbid_cmsg_compat) { int fput_needed, err; struct msghdr msg_sys ; struct socket *sock ; if (forbid_cmsg_compat && (flags & MSG_CMSG_COMPAT)) return -EINVAL; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; err = ___sys_sendmsg(sock, msg, &msg_sys, flags, NULL , 0 ); fput_light(sock->file, fput_needed); out: return err; } static int ____sys_sendmsg(struct socket *sock, struct msghdr *msg_sys, unsigned int flags, struct used_address *used_address, unsigned int allowed_msghdr_flags) { unsigned char ctl[sizeof (struct cmsghdr) + 20 ] __aligned(sizeof (__kernel_size_t )); unsigned char *ctl_buf = ctl; int ctl_len; ssize_t err; err = -ENOBUFS; if (msg_sys->msg_controllen > INT_MAX) goto out; flags |= (msg_sys->msg_flags & allowed_msghdr_flags); ctl_len = msg_sys->msg_controllen; if ((MSG_CMSG_COMPAT & flags) && ctl_len) { err = cmsghdr_from_user_compat_to_kern(msg_sys, sock->sk, ctl, sizeof (ctl)); if (err) goto out; ctl_buf = msg_sys->msg_control; ctl_len = msg_sys->msg_controllen; } else if (ctl_len) { BUILD_BUG_ON(sizeof (struct cmsghdr) != CMSG_ALIGN(sizeof (struct cmsghdr))); if (ctl_len > sizeof (ctl)) { ctl_buf = sock_kmalloc(sock->sk, ctl_len, GFP_KERNEL); if (ctl_buf == NULL ) goto out; } err = -EFAULT; if (copy_from_user(ctl_buf, (void __user __force *)msg_sys->msg_control, ctl_len)) goto out_freectl; msg_sys->msg_control = ctl_buf; } msg_sys->msg_flags = flags; if (sock->file->f_flags & O_NONBLOCK) msg_sys->msg_flags |= MSG_DONTWAIT; if (used_address && msg_sys->msg_name && used_address->name_len == msg_sys->msg_namelen && !memcmp (&used_address->name, msg_sys->msg_name, used_address->name_len)) { err = sock_sendmsg_nosec(sock, msg_sys); goto out_freectl; } err = sock_sendmsg(sock, msg_sys); if (used_address && err >= 0 ) { used_address->name_len = msg_sys->msg_namelen; if (msg_sys->msg_name) memcpy (&used_address->name, msg_sys->msg_name, used_address->name_len); } out_freectl: if (ctl_buf != ctl) sock_kfree_s(sock->sk, ctl_buf, ctl_len); out: return err; }
看完了__sys_sendmsg,我们可以确定,无论是哪个发送数据的系统调用,最终都会调用到sock_sendmsg。下面是sock_sendmsg的相关代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int sock_sendmsg (struct socket *sock, struct msghdr *msg) { int err = security_socket_sendmsg(sock, msg, msg_data_left(msg)); return err ?: sock_sendmsg_nosec(sock, msg); } static inline int sock_sendmsg_nosec (struct socket *sock, struct msghdr *msg) { int ret = INDIRECT_CALL_INET(sock->ops->sendmsg, inet6_sendmsg, inet_sendmsg, sock, msg, msg_data_left(msg)); BUG_ON(ret == -EIOCBQUEUED); return ret; }
到此,我们完成了数据包从用户空间到内核空间的流程跟踪。接下来的数据包发送过程,将根据不同的协议,走不同的流程。
数据报文的接收 系统调用接口 1 2 3 4 5 6 #include <sys/types.h> #include <sys/socket.h> ssize_t recv (int sockfd, void *buf, size_t len, int flags) ;ssize_t recvfrom (int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen) ;ssize_t recvmsg (int sockfd, struct msghdr *msg, int flags) ;
与send类似,recv一般也是面向连接的套接字。原因在于,对于非面向连接的套接字来说,若使用recv接收数据,通过该接口将不能获得发送端的地址,也就是说不知道这个数据是谁发过来的。所以,如果使用者不关心发送端信息,或者该信息可以从数据中获得,那么recv接口同样也可以用于非面向连接的套接字。再来看看recvfrom,它会通过额外的参数src_addr和addrlen,来获得发送方的地址,其中需要注意的是addrlen,它既是输入值又是输出值。最后是recvmsg,它与sendmsg一样,把接收到的数据和地址都保存在了msg中。其中msg.msg_name和msg.msg_len用于保存接收端地址,而msg.msg_iov用于保存接收到的数据。这三个系统调用与对应的发送接口一样,都支持设置标志位flags,都是比较现代的接口设计方法。
数据包从内核空间到用户空间的流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 SYSCALL_DEFINE4(recv, int , fd, void __user *, ubuf, size_t , size, unsigned int , flags) { return __sys_recvfrom(fd, ubuf, size, flags, NULL , NULL ); } SYSCALL_DEFINE6(recvfrom, int , fd, void __user *, ubuf, size_t , size, unsigned int , flags, struct sockaddr __user *, addr, int __user *, addr_len) { return __sys_recvfrom(fd, ubuf, size, flags, addr, addr_len); } int __sys_recvfrom(int fd, void __user *ubuf, size_t size, unsigned int flags, struct sockaddr __user *addr, int __user *addr_len) { struct socket *sock ; struct iovec iov ; struct msghdr msg ; struct sockaddr_storage address ; int err, err2; int fput_needed; err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter); if (unlikely(err)) return err; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; msg.msg_control = NULL ; msg.msg_controllen = 0 ; msg.msg_name = addr ? (struct sockaddr *)&address : NULL ; msg.msg_namelen = 0 ; msg.msg_iocb = NULL ; msg.msg_flags = 0 ; if (sock->file->f_flags & O_NONBLOCK) flags |= MSG_DONTWAIT; err = sock_recvmsg(sock, &msg, flags); if (err >= 0 && addr != NULL ) { err2 = move_addr_to_user(&address, msg.msg_namelen, addr, addr_len); if (err2 < 0 ) err = err2; } fput_light(sock->file, fput_needed); out: return err; } int sock_recvmsg (struct socket *sock, struct msghdr *msg, int flags) { int err = security_socket_recvmsg(sock, msg, msg_data_left(msg), flags); return err ?: sock_recvmsg_nosec(sock, msg, flags); } static inline int sock_recvmsg_nosec (struct socket *sock, struct msghdr *msg, int flags) { return INDIRECT_CALL_INET(sock->ops->recvmsg, inet6_recvmsg, inet_recvmsg, sock, msg, msg_data_left(msg), flags); }
recvmsg 函数最后也会进入sock_recvmsg_nosec,后面的接收流程就要依赖于具体的协议实现了。。
标准库 相关结构体 Socket编程涉及多个重要的结构体,主要分为以下几类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 struct sockaddr // 通用地址结构struct sockaddr_in // IPv4 地址结构struct sockaddr_in6 // IPv6 地址结构struct sockaddr_un // Unix 域套接字地址struct sockaddr_storage // 通用存储结构// 网络信息结构体 struct addrinfo // 地址信息struct hostent // 主机信息struct servent // 服务信息// 数据传输结构体 struct msghdr // 消息头struct iovec // I /O 向量struct cmsghdr // 控制消息// 其他辅助结构体 struct linger // 延迟关闭struct timeval // 超时设置fd_set // 文件描述符集合
结构体
用途
大小
协议
sockaddr通用地址(接口)
16字节
所有
sockaddr_inIPv4地址
16字节
IPv4
sockaddr_in6IPv6地址
28字节
IPv6
sockaddr_unUnix域套接字
110字节
本地IPC
sockaddr_storage通用存储
128字节
协议无关
addrinfo地址信息(现代)
-
协议无关
msghdr高级I/O
-
所有
iovec分散/聚集I/O
-
所有
地址结构体族 struct sockaddr - 通用地址结构1 2 3 4 struct sockaddr { sa_family_t sa_family; char sa_data[14 ]; };
字段说明 :
sa_family:地址族类型(2字节)
AF_INET:IPv4AF_INET6:IPv6AF_UNIX/AF_LOCAL:Unix域套接字
sa_data:实际地址数据(14字节)
用途 :
作为函数接口的通用类型
实际使用时需要强制转换为具体类型
1 2 3 4 struct sockaddr_in addr ;connect(sock, (struct sockaddr*)&addr, sizeof (addr));
内存布局 (16字节):
1 2 3 4 5 6 +-------------------+ | sa_family (2字节) | +-------------------+ | sa_data[14] | | | +-------------------+
struct sockaddr_in - IPv4地址结构1 2 3 4 5 6 7 8 9 10 struct sockaddr_in { sa_family_t sin_family; in_port_t sin_port; struct in_addr sin_addr ; char sin_zero[8 ]; }; struct in_addr { uint32_t s_addr; };
字段详解 :
字段
类型
大小
说明
sin_familysa_family_t2字节
必须设置为AF_INET
sin_portin_port_t2字节
端口号(网络字节序)
sin_addrstruct in_addr4字节
IPv4地址(网络字节序)
sin_zerochar[8]8字节
填充为0,不使用
总大小 :16字节
内存布局 :
1 2 3 4 5 6 7 8 9 +----------------------+ | sin_family (2字节) | AF_INET +----------------------+ | sin_port (2字节) | 端口(大端序) +----------------------+ | sin_addr (4字节) | IP地址(大端序) +----------------------+ | sin_zero[8] | 填充0 +----------------------+
完整使用示例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <stdio.h> #include <string.h> #include <arpa/inet.h> int main () { struct sockaddr_in server_addr ; memset (&server_addr, 0 , sizeof (server_addr)); server_addr.sin_family = AF_INET; server_addr.sin_port = htons(8080 ); server_addr.sin_addr.s_addr = INADDR_ANY; inet_pton(AF_INET, "192.168.1.100" , &server_addr.sin_addr); char ip_str[INET_ADDRSTRLEN]; inet_ntop(AF_INET, &server_addr.sin_addr, ip_str, sizeof (ip_str)); printf ("IP: %s, Port: %d\n" , ip_str, ntohs(server_addr.sin_port)); return 0 ; }
常用宏定义 :
1 2 3 #define INADDR_ANY 0x00000000 #define INADDR_LOOPBACK 0x7f000001 #define INADDR_BROADCAST 0xffffffff
struct sockaddr_in6 - IPv6地址结构1 2 3 4 5 6 7 8 9 10 11 struct sockaddr_in6 { sa_family_t sin6_family; in_port_t sin6_port; uint32_t sin6_flowinfo; struct in6_addr sin6_addr ; uint32_t sin6_scope_id; }; struct in6_addr { uint8_t s6_addr[16 ]; };
字段说明 :
字段
大小
说明
sin6_family2字节
必须是AF_INET6
sin6_port2字节
端口号(网络字节序)
sin6_flowinfo4字节
流标签和优先级(通常设为0)
sin6_addr16字节
128位IPv6地址
sin6_scope_id4字节
接口索引(链路本地地址使用)
总大小 :28字节
使用示例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct sockaddr_in6 server_addr ;memset (&server_addr, 0 , sizeof (server_addr));server_addr.sin6_family = AF_INET6; server_addr.sin6_port = htons(8080 ); server_addr.sin6_addr = in6addr_any; inet_pton(AF_INET6, "2001:db8::1" , &server_addr.sin6_addr); server_addr.sin6_addr = in6addr_loopback;
常用IPv6地址 :
1 2 extern const struct in6_addr in6addr_any ;extern const struct in6_addr in6addr_loopback ;
struct sockaddr_un - Unix域套接字1 2 3 4 struct sockaddr_un { sa_family_t sun_family; char sun_path[108 ]; };
用途 :
本地进程间通信(IPC)
比TCP/IP更快(无网络协议栈开销)
使用文件系统路径作为地址
使用示例 :
1 2 3 4 5 6 7 8 9 struct sockaddr_un server_addr ;memset (&server_addr, 0 , sizeof (server_addr));server_addr.sun_family = AF_UNIX; strcpy (server_addr.sun_path, "/tmp/my_socket" );int sock = socket(AF_UNIX, SOCK_STREAM, 0 );bind(sock, (struct sockaddr*)&server_addr, sizeof (server_addr));
注意事项 :
sun_path必须是有效的文件系统路径绑定前需要确保路径不存在(或先unlink)
程序结束时应删除套接字文件
1 2 3 4 5 6 7 unlink("/tmp/my_socket" ); bind(sock, ...); close(sock); unlink("/tmp/my_socket" );
struct sockaddr_storage - 通用存储结构1 2 3 4 5 struct sockaddr_storage { sa_family_t ss_family; char __ss_padding[...]; uint64_t __ss_align; };
特点 :
足够大,可以容纳任何地址族
大小通常为128字节
用于编写协议无关的代码
典型用法 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 struct sockaddr_storage client_addr ;socklen_t addr_len = sizeof (client_addr);int client_sock = accept(server_sock, (struct sockaddr*)&client_addr, &addr_len); if (client_addr.ss_family == AF_INET) { struct sockaddr_in * addr4 =struct sockaddr_in*)&client_addr; char ip[INET_ADDRSTRLEN]; inet_ntop(AF_INET, &addr4->sin_addr, ip, sizeof (ip)); printf ("IPv4 client: %s:%d\n" , ip, ntohs(addr4->sin_port)); } else if (client_addr.ss_family == AF_INET6) { struct sockaddr_in6* addr6 = (struct sockaddr_in6*)&client_addr; char ip[INET6_ADDRSTRLEN]; inet_ntop(AF_INET6, &addr6->sin6_addr, ip, sizeof (ip)); printf ("IPv6 client: %s:%d\n" , ip, ntohs(addr6->sin6_port)); }
地址转换函数 字节序转换 1 2 3 4 5 uint16_t htons (uint16_t hostshort) ; uint32_t htonl (uint32_t hostlong) ; uint16_t ntohs (uint16_t netshort) ; uint32_t ntohl (uint32_t netlong) ;
何时使用 :
1 2 3 4 5 6 7 8 9 server_addr.sin_port = htons(8080 ); int port = ntohs(server_addr.sin_port);inet_pton(AF_INET, "192.168.1.1" , &addr.sin_addr); addr.sin_addr.s_addr = htonl(INADDR_LOOPBACK);
IP地址转换(推荐) 1 2 3 4 5 int inet_pton (int af, const char *src, void *dst) ;const char *inet_ntop (int af, const void *src, char *dst, socklen_t size) ;
完整示例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct sockaddr_in addr ;char ip_str[INET_ADDRSTRLEN]; if (inet_pton(AF_INET, "192.168.1.100" , &addr.sin_addr) <= 0 ) { perror("inet_pton failed" ); return -1 ; } if (inet_ntop(AF_INET, &addr.sin_addr, ip_str, sizeof (ip_str)) == NULL ) { perror("inet_ntop failed" ); return -1 ; } printf ("IP: %s\n" , ip_str);
IPv6示例 :
1 2 3 4 5 6 struct sockaddr_in6 addr6 ;char ip6_str[INET6_ADDRSTRLEN]; inet_pton(AF_INET6, "2001:db8::1" , &addr6.sin6_addr); inet_ntop(AF_INET6, &addr6.sin6_addr, ip6_str, sizeof (ip6_str)); printf ("IPv6: %s\n" , ip6_str);
旧式转换函数(已弃用) 1 2 3 in_addr_t inet_addr (const char *cp) ; char *inet_ntoa (struct in_addr in) ;
网络信息结构体 struct addrinfo - 地址信息1 2 3 4 5 6 7 8 9 10 struct addrinfo { int ai_flags; int ai_family; int ai_socktype; int ai_protocol; socklen_t ai_addrlen; struct sockaddr *ai_addr ; char *ai_canonname; struct addrinfo *ai_next ; };
配合getaddrinfo使用 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <sys/types.h> #include <sys/socket.h> #include <netdb.h> int main () { struct addrinfo hints , *result , *rp ; int sock; memset (&hints, 0 , sizeof (hints)); hints.ai_family = AF_UNSPEC; hints.ai_socktype = SOCK_STREAM; hints.ai_flags = AI_PASSIVE; int status = getaddrinfo(NULL , "8080" , &hints, &result); if (status != 0 ) { fprintf (stderr , "getaddrinfo: %s\n" , gai_strerror(status)); return 1 ; } for (rp = result; rp != NULL ; rp = rp->ai_next) { sock = socket(rp->ai_family, rp->ai_socktype, rp->ai_protocol); if (sock == -1 ) continue ; if (bind(sock, rp->ai_addr, rp->ai_addrlen) == 0 ) { break ; } close(sock); } if (rp == NULL ) { fprintf (stderr , "Could not bind\n" ); return 1 ; } freeaddrinfo(result); close(sock); return 0 ; }
常用flags :
1 2 3 4 5 AI_PASSIVE AI_CANONNAME AI_NUMERICHOST AI_NUMERICSERV AI_V4MAPPED
struct hostent - 主机信息(旧式)1 2 3 4 5 6 7 8 9 struct hostent { char *h_name; char **h_aliases; int h_addrtype; int h_length; char **h_addr_list; }; #define h_addr h_addr_list[0]
使用示例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct hostent *host ="www.example.com" );if (host == NULL ) { herror("gethostbyname" ); return -1 ; } printf ("Official name: %s\n" , host->h_name);for (int i = 0 ; host->h_addr_list[i] != NULL ; i++) { char ip[INET_ADDRSTRLEN]; inet_ntop(AF_INET, host->h_addr_list[i], ip, sizeof (ip)); printf ("Address %d: %s\n" , i, ip); }
注意 :gethostbyname已弃用,推荐使用getaddrinfo。
数据传输结构体 struct msghdr - 消息头1 2 3 4 5 6 7 8 9 struct msghdr { void *msg_name; socklen_t msg_namelen; struct iovec *msg_iov ; size_t msg_iovlen; void *msg_control; size_t msg_controllen; int msg_flags; };
用于高级I/O函数 :
1 2 ssize_t sendmsg (int sockfd, const struct msghdr *msg, int flags) ;ssize_t recvmsg (int sockfd, struct msghdr *msg, int flags) ;
使用示例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <sys/socket.h> #include <sys/uio.h> void send_multiple_buffers (int sock) { char header[] = "HEADER" ; char body[] = "This is the message body" ; char footer[] = "FOOTER" ; struct iovec iov [3]; iov[0 ].iov_base = header; iov[0 ].iov_len = strlen (header); iov[1 ].iov_base = body; iov[1 ].iov_len = strlen (body); iov[2 ].iov_base = footer; iov[2 ].iov_len = strlen (footer); struct msghdr msg =0 }; msg.msg_iov = iov; msg.msg_iovlen = 3 ; ssize_t sent = sendmsg(sock, &msg, 0 ); printf ("Sent %zd bytes\n" , sent); }
struct iovec - I/O向量1 2 3 4 struct iovec { void *iov_base; size_t iov_len; };
配合readv/writev使用 :
1 2 3 4 #include <sys/uio.h> ssize_t readv (int fd, const struct iovec *iov, int iovcnt) ;ssize_t writev (int fd, const struct iovec *iov, int iovcnt) ;
分散读取示例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 char header[16 ];char body[1024 ];char footer[16 ];struct iovec iov [3];iov[0 ].iov_base = header; iov[0 ].iov_len = sizeof (header); iov[1 ].iov_base = body; iov[1 ].iov_len = sizeof (body); iov[2 ].iov_base = footer; iov[2 ].iov_len = sizeof (footer); ssize_t n = readv(sock, iov, 3 );
Socket选项结构体 struct linger - 延迟关闭1 2 3 4 struct linger { int l_onoff; int l_linger; };
使用场景 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct linger ling ;ling.l_onoff = 1 ; ling.l_linger = 0 ; setsockopt(sock, SOL_SOCKET, SO_LINGER, &ling, sizeof (ling)); ling.l_onoff = 1 ; ling.l_linger = 10 ; setsockopt(sock, SOL_SOCKET, SO_LINGER, &ling, sizeof (ling)); ling.l_onoff = 0 ; setsockopt(sock, SOL_SOCKET, SO_LINGER, &ling, sizeof (ling));
行为对比 :
l_onoff
l_linger
close()行为
未发送数据
0
忽略
立即返回
后台发送
非0
0
立即返回
立即丢弃,发送RST
非0
>0
阻塞等待
尝试发送,超时则RST
struct timeval - 超时设置1 2 3 4 struct timeval { time_t tv_sec; suseconds_t tv_usec; };
设置socket超时 :
1 2 3 4 5 6 7 8 9 struct timeval timeout ;timeout.tv_sec = 5 ; timeout.tv_usec = 0 ; setsockopt(sock, SOL_SOCKET, SO_RCVTIMEO, &timeout, sizeof (timeout)); setsockopt(sock, SOL_SOCKET, SO_SNDTIMEO, &timeout, sizeof (timeout));
select超时 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 fd_set readfds; FD_ZERO(&readfds); FD_SET(sock, &readfds); struct timeval tv ;tv.tv_sec = 2 ; tv.tv_usec = 500000 ; int ret = select(sock + 1 , &readfds, NULL , NULL , &tv);if (ret == 0 ) { printf ("Timeout\n" ); } else if (ret > 0 ) { }
完整的服务器示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #define PORT 8080 #define BACKLOG 10 int main () { int server_sock, client_sock; struct sockaddr_in server_addr , client_addr ; socklen_t client_len = sizeof (client_addr); char buffer[1024 ]; server_sock = socket(AF_INET, SOCK_STREAM, 0 ); if (server_sock < 0 ) { perror("socket failed" ); exit (EXIT_FAILURE); } int opt = 1 ; setsockopt(server_sock, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof (opt)); memset (&server_addr, 0 , sizeof (server_addr)); server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = INADDR_ANY; server_addr.sin_port = htons(PORT); if (bind(server_sock, (struct sockaddr*)&server_addr, sizeof (server_addr)) < 0 ) { perror("bind failed" ); close(server_sock); exit (EXIT_FAILURE); } if (listen(server_sock, BACKLOG) < 0 ) { perror("listen failed" ); close(server_sock); exit (EXIT_FAILURE); } printf ("Server listening on port %d\n" , PORT); while (1 ) { client_sock = accept(server_sock, (struct sockaddr*)&client_addr, &client_len); if (client_sock < 0 ) { perror("accept failed" ); continue ; } char client_ip[INET_ADDRSTRLEN]; inet_ntop(AF_INET, &client_addr.sin_addr, client_ip, sizeof (client_ip)); printf ("Client connected: %s:%d\n" , client_ip, ntohs(client_addr.sin_port)); ssize_t n = recv(client_sock, buffer, sizeof (buffer) - 1 , 0 ); if (n > 0 ) { buffer[n] = '\0' ; printf ("Received: %s\n" , buffer); send(client_sock, buffer, n, 0 ); } close(client_sock); } close(server_sock); return 0 ; }
连接到建立 在 Linux 网络编程中,socket 、bind、connect、listen 和 accept 是用于网络套接字编程的关键系统调用。它们在服务器和客户端通信中扮演着重要的角色。以下是这些函数的详细用法:
socket 函数用途 socket 函数创建一个新的套接字,并返回一个文件描述符用于后续的网络操作。
函数原型 1 int socket (int domain, int type, int protocol) ;
参数详解 1. domain 参数(地址族/协议族)
domain 参数指定套接字使用的通信域,决定了套接字的地址格式和通信范围:
**AF_INET**:IPv4 网络通信
使用 32 位 IPv4 地址
最常用的网络通信方式
**AF_INET6**:IPv6 网络通信
使用 128 位 IPv6 地址
支持更大的地址空间
AF_UNIXAF_LOCAL):本地进程间通信
**AF_NETLINK**:内核与用户空间通信
**AF_PACKET**:底层包访问
2. type 参数(套接字类型)
type 参数指定套接字的通信语义和服务类型:
**SOCK_STREAM**:流式套接字(TCP)
提供可靠、面向连接的字节流服务
数据按序到达,无重复,无丢失
双向通信
**SOCK_DGRAM**:数据报套接字(UDP)
提供无连接的数据报服务
不保证数据到达顺序和可靠性
更高的传输效率
**SOCK_RAW**:原始套接字
绕过传输层,直接访问网络层
需要 root 权限
用于实现自定义协议或网络诊断工具
**SOCK_SEQPACKET**:有序数据包套接字
类似 SOCK_STREAM 但保持消息边界
不常用
**SOCK_NONBLOCK**:非阻塞标志(Linux 2.6.27+)
可以与其他类型组合使用(通过 | 运算符)
等效于创建后调用 fcntl 设置 O_NONBLOCK
**SOCK_CLOEXEC**:执行时关闭标志
3. protocol 参数(具体协议)
protocol 参数指定套接字使用的具体协议,通常设为 0 让系统根据 domain 和 type 自动选择:
**0**:自动选择协议(推荐)
AF_INET + SOCK_STREAM → TCPAF_INET + SOCK_DGRAM → UDP
**IPPROTO_TCP**:明确指定 TCP 协议
**IPPROTO_UDP**:明确指定 UDP 协议
**IPPROTO_ICMP**:ICMP 协议(需要 SOCK_RAW)
**IPPROTO_RAW**:原始 IP 协议
返回值
成功 :返回非负整数的套接字文件描述符
这是一个小的非负整数,用作后续系统调用的标识符
从 0 开始分配,通常前三个(0、1、2)被标准输入/输出/错误占用
失败 :返回 -1,并设置全局变量 errno 指示错误类型
返回值 成功: 返回套接字文件描述符(非负整数)失败: 返回 -1,并设置 errno
示例 1 2 3 4 int tcp_sockfd = socket(AF_INET, SOCK_STREAM, 0 );int udp_sockfd = socket(AF_INET, SOCK_DGRAM, 0 );
bind 函数用途 bind 函数将套接字与特定的IP地址和端口号绑定在一起。
函数原型 1 int bind (int sockfd, const struct sockaddr *addr, socklen_t addrlen) ;
参数
sockfd:套接字文件描述符,通过 socket() 创建。addr:指向特定协议地址的指针,通常是 struct sockaddr_in、struct sockaddr_in6 或 struct sockaddr_un。addrlen:地址的长度,以字节为单位。
返回值
成功:返回 0。
失败:返回 -1,并设置 errno。
示例 1 2 3 4 5 6 7 struct sockaddr_in server_addr ;server_addr.sin_family = AF_INET; server_addr.sin_port = htons(PORT); server_addr.sin_addr.s_addr = INADDR_ANY; int sockfd = socket(AF_INET, SOCK_STREAM, 0 );bind(sockfd, (struct sockaddr *)&server_addr, sizeof (server_addr));
connect 函数用途 connect 函数用于客户端向服务器发起连接。
函数原型 1 int connect (int sockfd, const struct sockaddr *addr, socklen_t addrlen) ;
参数
sockfd:套接字文件描述符。addr:指向服务器地址的指针。addrlen:地址的长度。
返回值
成功:返回 0。
失败:返回 -1,并设置 errno。
示例 1 2 3 4 5 6 7 struct sockaddr_in server_addr ;server_addr.sin_family = AF_INET; server_addr.sin_port = htons(PORT); inet_pton(AF_INET, "127.0.0.1" , &server_addr.sin_addr); int sockfd = socket(AF_INET, SOCK_STREAM, 0 );connect(sockfd, (struct sockaddr *)&server_addr, sizeof (server_addr));
listen 函数用途 listen 函数用于将绑定到特定端口的套接字转换为一个被动套接字,以便接受来自客户端的连接请求。
函数原型 1 int listen (int sockfd, int backlog) ;
参数
sockfd:套接字文件描述符。backlog:等待连接队列的最大长度。
返回值
成功:返回 0。
失败:返回 -1,并设置 errno。
示例 1 2 3 int sockfd = socket(AF_INET, SOCK_STREAM, 0 );bind(sockfd, (struct sockaddr *)&server_addr, sizeof (server_addr)); listen(sockfd, 5 );
accept 函数用途 accept 函数从连接请求队列中提取下一个连接请求,并为该连接返回一个新的套接字。
函数原型 1 int accept (int sockfd, struct sockaddr *addr, socklen_t *addrlen) ;
参数
sockfd:监听套接字的文件描述符。addr:用于返回发起连接请求的实体的地址。addrlen:指向地址长度的指针。
返回值
成功:返回一个新的套接字文件描述符(用于与客户端通信)。
失败:返回 -1,并设置 errno。
示例 1 2 3 struct sockaddr_in client_addr ;socklen_t client_len = sizeof (client_addr);int new_sockfd = accept(sockfd, (struct sockaddr *)&client_addr, &client_len);
使用这些函数,您可以创建一个基本的 TCP 服务器和客户端模型。服务器负责监听和接受客户端连接,而客户端则主动连接到服务器。
accept4 是 Linux 特定的系统调用,类似于 accept 函数,但它具有更多的灵活性,因为它允许在接受连接时指定额外的套接字标志。这种功能可以帮助在创建新套接字时避免竞争条件(race condition)或减少系统调用。accept4 是 GNU C Library (glibc) 的一部分,在一些 Unix-like 操作系统上可用。
accept4 函数用途 accept4 函数用于从连接请求队列中提取下一个连接请求,并返回一个新的套接字,同时可以指定标志来设置新套接字的特性,比如非阻塞方式或关闭执行标志。
函数原型 1 int accept4 (int sockfd, struct sockaddr *addr, socklen_t *addrlen, int flags) ;
参数
sockfd:监听套接字的文件描述符。addr:用于存储发起连接请求的客户端地址(可以为 NULL)。addrlen:指向地址长度的指针,表示 addr 的空间大小,也用于返回实际地址的长度(可以为 NULL)。flags:用于指定新套接字的属性标志,可以是以下标志的组合:
O_NONBLOCK:将套接字设置为非阻塞模式。SOCK_CLOEXEC:设置关闭执行标志(close-on-exec),这对于多线程或 fork/exec 模型很有用。
返回值
成功:返回一个新的套接字文件描述符(用于与客户端的通信)。
失败:返回 -1,并设置 errno。
示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <fcntl.h> int main () { int sockfd = socket(AF_INET, SOCK_STREAM, 0 ); struct sockaddr_in server_addr , client_addr ; socklen_t client_len = sizeof (client_addr); server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = INADDR_ANY; server_addr.sin_port = htons(8080 ); bind(sockfd, (struct sockaddr *)&server_addr, sizeof (server_addr)); listen(sockfd, 5 ); int new_sockfd = accept4(sockfd, (struct sockaddr *)&client_addr, &client_len, O_NONBLOCK); if (new_sockfd < 0 ) { perror("accept4 failed" ); } close(new_sockfd); close(sockfd); return 0 ; }
注意事项
accept4 提供的特性主要用于优化和简化套接字的使用过程,但在使用时需要检查平台是否支持此函数。如果你在一个不支持 accept4 的平台工作,可以通过 accept 和再调用 fcntl 来实现类似的功能。
尽管 accept4 对应用程序性能和可靠性有帮助,要确保理解每个标志的影响,合理地组合使用。
报文的发送 在 Linux 网络编程中,send、sendto 和 sendmsg 是用于发送数据的函数。虽然它们具有相似的功能,但每个函数针对不同的场景进行了优化和设计。
send 函数用途 send 函数用于通过连接的 TCP 套接字发送数据。
函数原型 1 ssize_t send (int sockfd, const void *buf, size_t len, int flags) ;
参数
sockfd:套接字文件描述符,必须是已连接的套接字。buf:指向待发送数据缓冲区的指针。len:要发送的数据长度。flags:指定传输选项,通常为 0,也可以是以下一个或多个标志的组合:
MSG_DONTWAIT:非阻塞操作。MSG_NOSIGNAL:避免在对等端崩溃的情况下发送 SIGPIPE 信号。
返回值
成功:返回实际发送的字节数。
失败:返回 -1,并设置 errno。
示例 1 2 char *message = "Hello, World!" ;int bytes_sent = send(sockfd, message, strlen (message), 0 );
sendto 函数用途 sendto 函数用于通过未连接的套接字(如 UDP)发送数据,并允许指定目标地址。
函数原型 1 ssize_t sendto (int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen) ;
参数
sockfd:套接字文件描述符,可以是已连接或未连接的套接字。buf:指向待发送数据缓冲区的指针。len:要发送的数据长度。flags:传输选项,与 send 的类似。dest_addr:指向目标地址的指针。addrlen:目标地址的长度。
返回值
成功:返回实际发送的字节数。
失败:返回 -1,并设置 errno。
示例 1 2 3 4 5 6 7 struct sockaddr_in dest_addr ;dest_addr.sin_family = AF_INET; dest_addr.sin_port = htons(PORT); inet_pton(AF_INET, "127.0.0.1" , &dest_addr.sin_addr); char *message = "Hello, UDP World!" ;int bytes_sent = sendto(sockfd, message, strlen (message), 0 , (struct sockaddr *)&dest_addr, sizeof (dest_addr));
sendmsg 函数用途 sendmsg 函数是一种高级接口,用于发送带辅助数据的消息,也可以用于原始套接字或发送带有控制信息的数据包,可以用于已连接和未连接的套接字,已连接套接字不需要目标地址。
函数原型 1 ssize_t sendmsg (int sockfd, const struct msghdr *msg, int flags) ;
参数
sockfd:套接字文件描述符。msg:指向 msghdr 结构的指针,该结构包含要发送的数据和可选的地址和控制信息。flags:传输选项,与 send 的类似。
msghdr 结构1 2 3 4 5 6 7 8 9 struct msghdr { void *msg_name; socklen_t msg_namelen; struct iovec *msg_iov ; size_t msg_iovlen; void *msg_control; size_t msg_controllen; int msg_flags; };
返回值
成功:返回实际发送的字节数。
失败:返回 -1,并设置 errno。
示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct msghdr msg ;struct iovec iov [1];char *message = "Hello, Advanced World!" ;iov[0 ].iov_base = message; iov[0 ].iov_len = strlen (message); msg.msg_name = NULL ; msg.msg_namelen = 0 ; msg.msg_iov = iov; msg.msg_iovlen = 1 ; msg.msg_control = NULL ; msg.msg_controllen = 0 ; msg.msg_flags = 0 ; int bytes_sent = sendmsg(sockfd, &msg, 0 );
这三个函数分别用于在不同的场景中发送数据:send 用于简单的已连接套接字,sendto 用于未连接的套接字,sendmsg 则用于更复杂的消息结构和控制信息。选择合适的函数取决于您的应用程序需求。
报文的接收 在 Linux 网络编程中,recv、recvfrom 和 recvmsg 是用于接收数据的函数。每个函数都有其特定的用途,根据不同的网络通信需求和场景进行设计。
recv 函数用途 recv 函数用于从已连接的套接字接收数据,通常用于 TCP 连接。
函数原型 1 ssize_t recv (int sockfd, void *buf, size_t len, int flags) ;
参数
sockfd:套接字文件描述符,必须是已连接的。buf:指向存储接收数据的缓冲区的指针。len:要接收的最大字节数(缓冲区大小)。flags:指定接收选项,通常为 0,但可以是以下一个或多个标志的组合:
MSG_DONTWAIT:非阻塞操作。MSG_PEEK:查看数据而不将其从队列中移除。MSG_WAITALL:等待完整请求数据到达。
返回值
成功:返回实际接收到的字节数。
失败:返回 -1,并设置 errno。
示例 1 2 char buffer[1024 ];int bytes_received = recv(sockfd, buffer, sizeof (buffer), 0 );
recvfrom 函数用途 recvfrom 函数用于从未连接的套接字(如 UDP)接收数据,并可以获取数据来源的地址。
函数原型 1 ssize_t recvfrom (int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen) ;
参数
sockfd:套接字文件描述符,可以是已连接或未连接的。buf:指向存储接收数据的缓冲区的指针。len:要接收的最大字节数。flags:接收选项,与 recv 的类似。src_addr:指向用于存储源地址的 sockaddr 结构。addrlen:指向 src_addr 的长度,调用后返回实际地址长度。
返回值
成功:返回实际接收到的字节数。
失败:返回 -1,并设置 errno。
示例 1 2 3 4 struct sockaddr_in src_addr ;socklen_t addrlen = sizeof (src_addr);char buffer[1024 ];int bytes_received = recvfrom(sockfd, buffer, sizeof (buffer), 0 , (struct sockaddr *)&src_addr, &addrlen);
recvmsg 函数用途 recvmsg 提供了一个高级接口,用于接收包含辅助数据的消息,适用于需要处理控制信息或者更复杂协议的场景。
函数原型 1 ssize_t recvmsg (int sockfd, struct msghdr *msg, int flags) ;
参数
sockfd:套接字文件描述符。msg:指向 msghdr 结构的指针,包含接收的数据和可选控制信息。flags:接收选项,与 recv 的类似。
msghdr 结构1 2 3 4 5 6 7 8 9 struct msghdr { void *msg_name; socklen_t msg_namelen; struct iovec *msg_iov ; size_t msg_iovlen; void *msg_control; size_t msg_controllen; int msg_flags; };
返回值
成功:返回实际接收到的字节数。
失败:返回 -1,并设置 errno。
示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct msghdr msg ;struct iovec iov [1];char buffer[1024 ];iov[0 ].iov_base = buffer; iov[0 ].iov_len = sizeof (buffer); msg.msg_name = NULL ; msg.msg_namelen = 0 ; msg.msg_iov = iov; msg.msg_iovlen = 1 ; msg.msg_control = NULL ; msg.msg_controllen = 0 ; msg.msg_flags = 0 ; int bytes_received = recvmsg(sockfd, &msg, 0 );
Utils 地址转换函数 inet_aton & inet_ntoa (IPv4专用)1 2 int inet_aton (const char *cp, struct in_addr *inp) ;char *inet_ntoa (struct in_addr in) ;
局限 :
仅支持IPv4
非线程安全(inet_ntoa使用静态缓冲区)
无错误码返回
替代方案 :
1 2 3 const char *inet_ntop (int af, const void *src, char *dst, socklen_t size) ;int inet_pton (int af, const char *src, void *dst) ;
示例对比 :
1 2 3 4 5 6 7 8 9 10 struct in_addr addr ;inet_aton("192.168.1.1" , &addr); printf ("%s\n" , inet_ntoa(addr));char str[INET6_ADDRSTRLEN];struct in6_addr addr6 ;inet_pton(AF_INET6, "2001:db8::1" , &addr6); inet_ntop(AF_INET6, &addr6, str, sizeof (str));
字节序转换函数 基础函数 1 2 3 4 uint16_t htons (uint16_t hostshort) ; uint32_t htonl (uint32_t hostlong) ; uint16_t ntohs (uint16_t netshort) ; uint32_t ntohl (uint32_t netlong) ;
现代扩展 :
1 2 3 4 5 6 7 uint64_t htobe64 (uint64_t host_64bits) ; uint64_t be64toh (uint64_t big_endian_64bits) ; float htonf (float host_float) ;double htond (double host_double) ;
最佳实践 :
1 2 3 4 5 6 7 8 #pragma pack(push, 1) struct Packet { uint32_t magic; uint16_t version; float timestamp; }; #pragma pack(pop)
主机与服务查询 gethostbyname & getservbyname (传统方案)1 2 struct hostent *gethostbyname (const char *name) ;struct servent *getservbyname (const char *name, const char *proto) ;
缺陷 :
现代替代方案 getaddrinfo 1 2 3 int getaddrinfo (const char *node, const char *service, const struct addrinfo *hints, struct addrinfo **res) ;
高级用法 :
1 2 3 4 5 ares_getaddrinfo(channel, "example.com" , NULL , &hints, callback, arg); avahi_service_resolver_new(...);
配置示例 :
1 2 3 4 5 struct addrinfo hints = .ai_family = AF_UNSPEC, .ai_socktype = SOCK_STREAM, .ai_flags = AI_V4MAPPED | AI_ADDRCONFIG | AI_CANONNAME };
接口控制函数 ioctl (传统控制)1 int ioctl (int fd, unsigned long request, ...) ;
常见操作 :
1 2 3 4 5 6 7 struct ifreq ifr ;ioctl(sockfd, SIOCGIFADDR, &ifr); int flags = fcntl(fd, F_GETFL, 0 );fcntl(fd, F_SETFL, flags | O_NONBLOCK);
现代替代方案 netlink 1 2 3 4 5 6 7 int nl_sock = socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE);struct nlmsghdr *nlh ;send(nl_sock, &req, sizeof (req), 0 ); recv(nl_sock, buf, sizeof (buf), 0 );
高级诊断工具 getsockopt / setsockopt1 2 int getsockopt (int sockfd, int level, int optname, void *optval, socklen_t *optlen) ;
关键选项 :
Level
Option
用途
现代扩展
SOL_SOCKET
SO_TIMESTAMPNS
纳秒级时间戳
SO_TXTIME (时间敏感网络)
IPPROTO_TCP
TCP_CONGESTION
设置拥塞控制算法
bpf_tcp_ca (eBPF扩展)
SOL_TLS
TLS_TX
内核TLS卸载
KTLS_FORCE_TX (强制加密)
IPPROTO_IPV6
IPV6_V6ONLY
禁用IPv4映射
IPV6_BINDV6ONLY
示例 :
1 2 3 4 5 6 7 8 struct tcp_info info ;socklen_t len = sizeof (info);getsockopt(sockfd, IPPROTO_TCP, TCP_INFO, &info, &len); char ca_name[TCP_CA_NAME_MAX] = "bbr" ;setsockopt(sockfd, IPPROTO_TCP, TCP_CONGESTION, ca_name, sizeof (ca_name));
现代辅助函数 内存安全操作 1 2 3 4 5 6 7 strlcpy(ifr.ifr_name, "eth0" , sizeof (ifr.ifr_name)); if (inet_pton(AF_INET, ip_str, &addr) != 1 ) { }
eBPF辅助函数 1 2 3 4 5 setsockopt(sockfd, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd, sizeof (prog_fd)); bpf_map_lookup_elem(&stats_map, &key, &value);
跨平台兼容方案 可移植地址处理 1 2 3 4 5 6 7 8 9 10 11 12 struct sockaddr_storage addr ;socklen_t addr_len = sizeof (addr);if (addr.ss_family == AF_INET) { struct sockaddr_in *s =struct sockaddr_in *)&addr; } else if (addr.ss_family == AF_INET6) { struct sockaddr_in6 *s6 = (struct sockaddr_in6 *)&addr; }
CMake检测模块 1 2 3 4 5 6 7 8 9 include (CheckSymbolExists)check_symbol_exists(accept4 "sys/socket.h" HAVE_ACCEPT4) check_symbol_exists(TCP_FASTOPEN "netinet/tcp.h" HAVE_TCP_FASTOPEN) target_compile_definitions (myapp PRIVATE $<$<BOOL:${HAVE_ACCEPT4} >:USE_ACCEPT4> )
工具函数使用指南 迁移路线图
传统函数
问题
现代替代
inet_aton仅IPv4, 无错误处理
inet_pton
gethostbyname阻塞, 非线程安全
getaddrinfo
ioctl接口不一致
netlink 或 libmnl
getservbyname无协议无关设计
getaddrinfo
错误处理模板 1 2 3 4 5 6 7 8 if (inet_pton(AF_INET6, ip_str, &addr6) != 1 ) { if (errno == EAFNOSUPPORT) { fprintf (stderr , "IPv6 not supported\n" ); } else { perror("Invalid address format" ); } exit (EXIT_FAILURE); }
性能关键路径优化 1 2 3 4 5 6 7 8 9 10 static inline void fast_pton (uint32_t *dst, const char *src) { uint32_t a,b,c,d; sscanf (src, "%u.%u.%u.%u" , &a, &b, &c, &d); *dst = (a<<24 ) | (b<<16 ) | (c<<8 ) | d; } int val = 1 ;setsockopt(sockfd, SOL_SOCKET, SO_ZEROCOPY, &val, sizeof (val));
本扩展新增:
完整的传统工具函数与现代替代方案对照表
网络命名空间感知的现代函数(如netlink)
eBPF辅助函数的实际集成示例
跨平台兼容性解决方案
CMake构建系统检测模块
性能关键路径优化技巧
详细的错误代码处理模板
所有推荐方案均支持IPv6双栈环境,符合现代网络安全和性能要求,适用于云原生、IoT边缘计算及高性能网络中间件开发场景。
现代扩展 套接字创建与基础配置 socket函数原型 1 2 #include <sys/socket.h> int socket (int domain, int type, int protocol) ;
参数详解
1. domain(协议域/地址族)
指定套接字使用的协议族:
AF_INET : IPv4协议族AF_INET6 : IPv6协议族AF_UNIX/AF_LOCAL : 本地通信(Unix域套接字)AF_NETLINK : 内核与用户空间通信
2. type(套接字类型)
指定套接字的通信类型:
SOCK_STREAM : 流式套接字(TCP)
提供可靠、有序、双向的字节流
面向连接
保证数据完整性
SOCK_DGRAM : 数据报套接字(UDP)
SOCK_RAW : 原始套接字
3. protocol(协议)
指定具体的传输协议:
0 : 自动选择(推荐)IPPROTO_TCP : TCP协议IPPROTO_UDP : UDP协议IPPROTO_ICMP : ICMP协议
返回值
成功 : 返回非负整数的文件描述符失败 : 返回-1,并设置errno
socket() - 创建通信端点1 int socket (int domain, int type, int protocol) ;
现代扩展 :
支持新协议类型:
SOCK_NONBLOCK:创建非阻塞套接字(Linux 2.6.27+)SOCK_CLOEXEC:执行时关闭(close-on-exec)
协议选择:1 2 int quic_fd = socket(AF_INET, SOCK_DGRAM, IPPROTO_QUIC);
最佳实践 :
1 2 int sockfd = socket(AF_INET6, SOCK_STREAM | SOCK_NONBLOCK | SOCK_CLOEXEC, 0 );
关于Linux C中socket函数的现代扩展,我来详细介绍一下近年来的重要发展和新特性。
现代socket扩展特性 1. socket()函数的现代标志位
1 2 3 4 5 6 7 #include <sys/socket.h> int socket (int domain, int type, int protocol) ;int sockfd = socket(AF_INET, SOCK_STREAM | SOCK_CLOEXEC | SOCK_NONBLOCK, 0 );
现代标志位:
SOCK_CLOEXEC : 在exec()时自动关闭套接字,避免文件描述符泄漏SOCK_NONBLOCK : 创建非阻塞套接字,无需额外调用fcntl()
2. 新的协议族支持
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int sockfd;sockfd = socket(AF_INET6, SOCK_STREAM, 0 ); sockfd = socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE); sockfd = socket(AF_BLUETOOTH, SOCK_STREAM, BTPROTO_RFCOMM); sockfd = socket(AF_CAN, SOCK_RAW, CAN_RAW); sockfd = socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL));
3. 高性能I/O模型
epoll(Linux特有)
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <sys/epoll.h> int epoll_create1 (int flags) ;int epoll_ctl (int epfd, int op, int fd, struct epoll_event *event) ;int epoll_wait (int epfd, struct epoll_event *events, int maxevents, int timeout) ;int epfd = epoll_create1(EPOLL_CLOEXEC);struct epoll_event ev , events [MAX_EVENTS ];ev.events = EPOLLIN | EPOLLET; ev.data.fd = sockfd; epoll_ctl(epfd, EPOLL_CTL_ADD, sockfd, &ev);
io_uring(最新异步I/O)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <liburing.h> struct io_uring ring ;struct io_uring_sqe *sqe ;struct io_uring_cqe *cqe ;io_uring_queue_init(256 , &ring, 0 ); sqe = io_uring_get_sqe(&ring); io_uring_prep_socket(sqe, AF_INET, SOCK_STREAM, 0 , 0 ); io_uring_submit(&ring); io_uring_wait_cqe(&ring, &cqe);
4. 现代套接字选项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int flag = 1 ;setsockopt(sockfd, IPPROTO_TCP, TCP_NODELAY, &flag, sizeof (flag)); int reuse = 1 ;setsockopt(sockfd, SOL_SOCKET, SO_REUSEPORT, &reuse, sizeof (reuse)); int qlen = 5 ;setsockopt(sockfd, IPPROTO_TCP, TCP_FASTOPEN, &qlen, sizeof (qlen)); unsigned int timeout = 30000 ; setsockopt(sockfd, IPPROTO_TCP, TCP_USER_TIMEOUT, &timeout, sizeof (timeout)); int busy_poll = 50 ; setsockopt(sockfd, SOL_SOCKET, SO_BUSY_POLL, &busy_poll, sizeof (busy_poll));
5. 现代网络命名空间支持
1 2 3 4 5 6 7 #include <sched.h> #include <sys/socket.h> int netns_fd = open("/proc/self/ns/net" , O_RDONLY);setns(netns_fd, CLONE_NEWNET); int sockfd = socket(AF_INET, SOCK_STREAM, 0 );
6. 多队列网络接口支持
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <sys/socket.h> #include <unistd.h> void create_server_socket (int port) { int sockfd = socket(AF_INET, SOCK_STREAM, 0 ); int reuse = 1 ; setsockopt(sockfd, SOL_SOCKET, SO_REUSEPORT, &reuse, sizeof (reuse)); struct sockaddr_in addr ; addr.sin_family = AF_INET; addr.sin_addr.s_addr = INADDR_ANY; addr.sin_port = htons(port); bind(sockfd, (struct sockaddr*)&addr, sizeof (addr)); listen(sockfd, 128 ); }
7. 现代TLS/SSL集成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <openssl/ssl.h> #include <openssl/err.h> typedef struct { int sockfd; SSL *ssl; SSL_CTX *ctx; } secure_socket_t ; secure_socket_t * create_secure_socket () { secure_socket_t *ssock = malloc (sizeof (secure_socket_t )); ssock->sockfd = socket(AF_INET, SOCK_STREAM | SOCK_CLOEXEC, 0 ); SSL_library_init(); ssock->ctx = SSL_CTX_new(TLS_client_method()); ssock->ssl = SSL_new(ssock->ctx); SSL_set_fd(ssock->ssl, ssock->sockfd); return ssock; }
8. 现代错误处理和调试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <sys/socket.h> #include <errno.h> int create_socket_with_retry (int domain, int type, int protocol) { int sockfd; int retry_count = 0 ; const int max_retries = 3 ; while (retry_count < max_retries) { sockfd = socket(domain, type | SOCK_CLOEXEC, protocol); if (sockfd != -1 ) { return sockfd; } switch (errno) { case EMFILE: case ENFILE: usleep(100000 ); retry_count++; break ; case EPROTONOSUPPORT: case EAFNOSUPPORT: return -1 ; default : perror("socket" ); return -1 ; } } return -1 ; }
9. 现代网络性能优化
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <sys/sendfile.h> ssize_t sendfile (int out_fd, int in_fd, off_t *offset, size_t count) ;#include <fcntl.h> ssize_t splice (int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags) ;send(sockfd, buffer, size, MSG_ZEROCOPY);
10. 现代监控和调试工具集成
1 2 3 4 5 6 7 8 9 10 11 #include <sys/socket.h> #include <linux/sockios.h> struct tcp_info info ;socklen_t info_len = sizeof (info);getsockopt(sockfd, IPPROTO_TCP, TCP_INFO, &info, &info_len); printf ("RTT: %u us\n" , info.tcpi_rtt);printf ("RTT variance: %u us\n" , info.tcpi_rttvar);printf ("Send MSS: %u\n" , info.tcpi_snd_mss);
实际应用示例 高性能Web服务器框架 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <sys/socket.h> #include <sys/epoll.h> #include <fcntl.h> #define MAX_EVENTS 1024 #define LISTEN_BACKLOG 128 int create_modern_server (int port) { int sockfd = socket(AF_INET, SOCK_STREAM | SOCK_CLOEXEC | SOCK_NONBLOCK, 0 ); int reuse = 1 ; setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof (reuse)); setsockopt(sockfd, SOL_SOCKET, SO_REUSEPORT, &reuse, sizeof (reuse)); int nodelay = 1 ; setsockopt(sockfd, IPPROTO_TCP, TCP_NODELAY, &nodelay, sizeof (nodelay)); int fastopen = 5 ; setsockopt(sockfd, IPPROTO_TCP, TCP_FASTOPEN, &fastopen, sizeof (fastopen)); struct sockaddr_in addr ; addr.sin_family = AF_INET; addr.sin_addr.s_addr = INADDR_ANY; addr.sin_port = htons(port); bind(sockfd, (struct sockaddr*)&addr, sizeof (addr)); listen(sockfd, LISTEN_BACKLOG); return sockfd; }
高级地址管理 getaddrinfo() - 协议无关地址解析1 2 3 int getaddrinfo (const char *node, const char *service, const struct addrinfo *hints, struct addrinfo **res) ;
现代特性 :
1 2 3 4 5 setenv("RES_OPTIONS" , "use-vc trust-ad" , 1 ); ares_gethostbyname(channel, "example.com" , AF_INET, callback, arg);
配置示例 :
1 2 3 4 5 struct addrinfo hints = .ai_family = AF_UNSPEC, .ai_socktype = SOCK_STREAM, .ai_flags = AI_V4MAPPED | AI_ADDRCONFIG };
高性能I/O多路复用 epoll API - 可扩展事件通知1 2 3 int epoll_create1 (int flags) ;int epoll_ctl (int epfd, int op, int fd, struct epoll_event *event) ;int epoll_wait (int epfd, struct epoll_event *events, int maxevents, int timeout) ;
现代扩展 :
边缘触发优化 :1 event.events = EPOLLIN | EPOLLET | EPOLLRDHUP;
多线程优化 :1 2 event.events |= EPOLLEXCLUSIVE;
io_uring - 下一代异步I/O1 2 3 4 struct io_uring_sqe *sqe =io_uring_prep_send(sqe, sockfd, buf, len, flags); io_uring_sqe_set_flags(sqe, IOSQE_ASYNC);
性能对比 :
特性
select/poll
epoll
io_uring
时间复杂度
O(n)
O(1)
O(1)
内存拷贝
全量复制
部分复制
零拷贝
系统调用
同步
同步
异步提交
支持操作
基础I/O
基础I/O
全异步操作
零拷贝数据传输 splice() - 内核级管道传输1 2 3 ssize_t splice (int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags) ;
现代用例 :
1 2 3 4 while ((ret = splice(net_in, NULL , pipefd[1 ], NULL , 4096 , SPLICE_F_MOVE)) > 0 ) { splice(pipefd[0 ], NULL , net_out, NULL , ret, SPLICE_F_MOVE); }
AF_XDP - 超高性能数据面1 2 3 struct xsk_socket *xsk ;xsk_socket__create(&xsk, ifname, queue_id, umem, &rx, &tx, &config);
协议栈扩展与优化 TCP Fast Open (TFO) 1 2 3 4 5 setsockopt(sockfd, IPPROTO_TCP, TCP_FASTOPEN_CONNECT, &(int ){1 }, sizeof (int )); setsockopt(sockfd, IPPROTO_TCP, TCP_FASTOPEN, &(int ){1024 }, sizeof (int ));
eBPF 套接字扩展 1 2 3 4 5 6 7 setsockopt(sockfd, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd, sizeof (prog_fd));
安全增强函数 TLS 1.3 套接字扩展1 2 3 setsockopt(sockfd, SOL_TCP, TCP_ULP, "tls" , sizeof ("tls" )); setsockopt(sockfd, SOL_TLS, TLS_TX, &crypto_info, sizeof (crypto_info));
量子安全加密 1 2 SSL_CTX_set_ciphersuites(ctx, "TLS_AES_256_GCM_SHA384:KYBER-512-R3" );
诊断与调试工具 getsockopt 扩展1 2 3 4 5 6 7 8 9 struct tcp_info info ;socklen_t len = sizeof (info);getsockopt(sockfd, IPPROTO_TCP, TCP_INFO, &info, &len);
BPF_PERF_OUTPUT 跟踪1 2 bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU, &data, sizeof (data));
现代网络编程
协议无关设计 :
1 struct sockaddr_storage addr ;
零拷贝架构 :
1 2 3 4 graph LR A[网卡DMA] -->|XDP| B[eBPF程序] B -->|AF_XDP| C[用户空间] C -->|io_uring| D[存储/网络]
安全基线配置 :
1 2 3 4 5 setsockopt(sockfd, IPPROTO_TCP, TCP_SYNCNT, &(int ){3 }, sizeof (int )); setsockopt(sockfd, SOL_SOCKET, SO_BINDTODEVICE, "eth0" , 5 ); int val = 1 ;setsockopt(sockfd, SOL_TCP, TCP_FASTOPEN, &val, sizeof (val));
云原生支持 :
1 2 setsockopt(sockfd, IPPROTO_TCP, TCP_REPAIR, &(int ){1 }, sizeof (int ));