
Linux环境编程与内核之线程

线程和进程
在Linux下,程序或可执行文件是一个静态的实体,它只是一组指令的集合,没有执行的含义。进程是一个动态的实体,有自己的生命周期。线程是操作系统进程调度器可以调度的最小执行单元。进程和线程的关系如图:
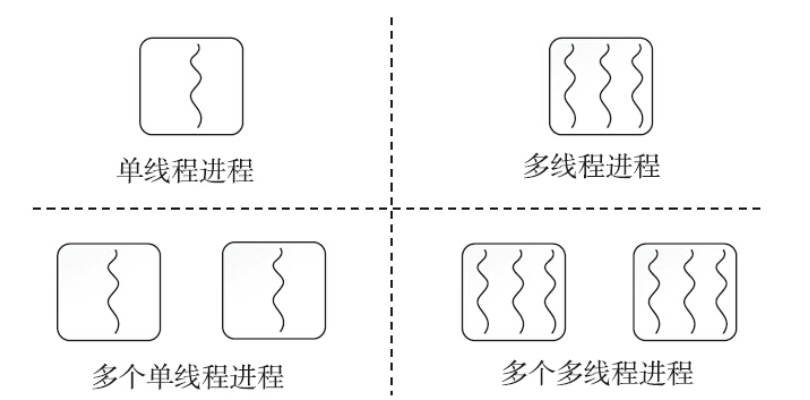
一个进程可能包含多个线程,传统意义上的进程,不过是多线程的一种特例,即该进程只包含一个线程。为什么要有多线程?举个生活中的例子,这就好比去银行办理业务。到达银行后,首先找到领导的机器领取一个号码,然后坐下来安心等待。这时候你一定希望,办理业务的窗口越多越好。如果把整个营业大厅当成一个进程的话,那么每一个窗口就是一个工作线程。这种场景在Linux中屡见不鲜。编程的思想和生活中解决问题的想法总是类似的。
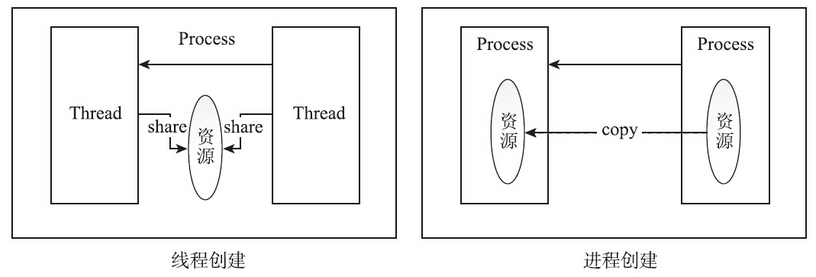
有人说不必非要使用线程,多个进程也能做到这点。的确如此。Unix/Linux原本的设计是没有线程的,类Unix系统包括Linux从设计上更倾向于使用进程,反倒是Windows因为创建进程的开销巨大,而更加钟爱线程。那么线程是不是一种设计上的冗余呢?其实不是这样的。进程之间,彼此的地址空间是独立的,但线程会共享内存地址空间。同一个进程的多个线程共享一份全局内存区域,包括初始化数据段、未初始化数据段和动态分配的堆内存段。
这种共享给线程带来了很多的优势:
- 创建线程花费的时间要少于创建进程花费的时间。
- 终止线程花费的时间要少于终止进程花费的时间。
- 线程之间上下文切换的开销,要小于进程之间的上下文切换。
- 线程之间数据的共享比进程之间的共享要简单。
线程间的上下文切换,指的是同一个进程里不同线程之间发生的上下文切换。由于线程原本属于同一个进程,它们会共享地址空间,大量资源共享,切换的代价小于进程之间的切换是自然而然的事情。线程之间通信的代价低于进程之间通信的代价。线程共享地址空间的设计,让多个线程之间的通信变得非常简单。进程之间的通信代价则要高很多。进程之间不得不采用一些进程间通信的手段(如管道、共享内存及信号量等)来协作。前面是从操作系统的角度来分析线程优势的,从用户或应用的视角来分析,多线程的程序也有很多的优势。
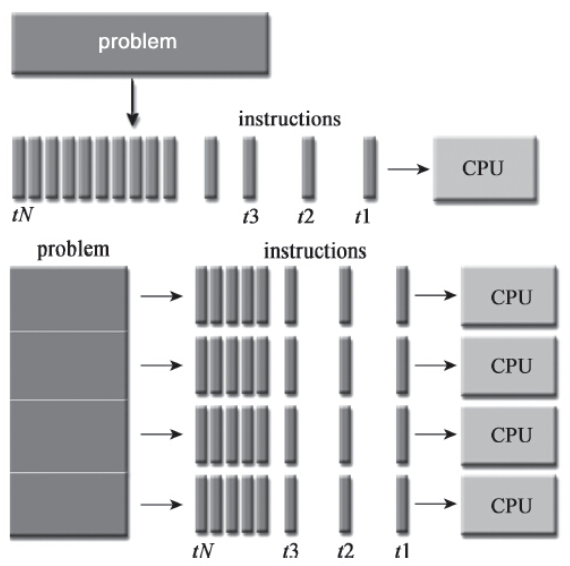
发挥多核优势,充分利用CPU资源
CPU是一种资源,如果一方面CPU资源大量闲置,处于IDLE的状态,另一方面很多任务得不到及时的处理,处于排队等待的状态,这就表明资源没有得到有效的利用,本质上是一种浪费。如果存在多个相同的任务,彼此之间并行不悖,互不依赖(或者依赖性很小),那么启动多个线程并发处理,是一个不错的选择。虽然对每个任务而言,处理的时间并没有缩短,但是在相同时间内,处理了更多的任务。
更自然的编程模型
有很多程序,天生就适合用多线程。将工作切分成多个模块,并为每个模块分配一个或多个执行单元,更符合人类解决问题的思路。以文本编辑程序为例,用户的输入需要及时响应,必须要有线程来监控鼠标和键盘;如果用户删除了第一页的某一行,后面很多页的格式都会受到影响,这时就需要有文本格式化线程在后台执行格式处理;很多文本编辑软件都有自动保存的功能,第三个线程会周期性地将文件内容写入磁盘;很多文本编辑软件都有检测拼写错误的功能,或许我们需要第四个线程……
上述的分工是很自然的事情,想象一下如果将所有工作都放在一个单线程的进程里面,那么该进程是不是就不得不处理庞杂而又繁芜的事情?程序结构也就会变得异常复杂。没有银弹。多线程带来优势的同时,也存在一些弊端。
(1)多线程的进程,因地址空间的共享让该进程变得更加脆弱
多个线程之中,只要有一个线程不够健壮存在bug(如访问了非法地址引发的段错误),就会导致进程内的所有线程一起完蛋。进程的地址空间互相独立,彼此隔离得更加彻底。多个进程之间互相协同,一个进程存在bug导致异常退出,不会影响到其他进程。
(2)线程模型作为一种并发的编程模型,效率并没有想象的那么高,会出现复杂度高、易出错、难以测试和定位的问题目前存在的并发编程,基本可以分成两类:
- 共享状态式
- 消息传递式线程模型采用的是第一种。
从现在开始,停止幻想,欢迎来到真实的世界。一个程序员碰到了一个问题,他决定用多线程来解决。现在两个他问题了有。
——关于线程的冷笑话
在真实的场景中,多线程编程是很复杂的。前面所说的多个任务并行不悖,互不依赖,在大多数情况下只是一种美好的幻想。首先,多个线程之间,存在负载均衡的问题,现实中很难将全部任务等分给每个线程。想象一下,如果存在10个线程,一个线程承担了90%的任务,9个线程承担了10%的任务,整体的效率立刻就降了下来。
有人说,怎么会有这么愚蠢的设计呢。试想如下场景:你需要用支持10个并发线程的服务器去计算1~10^10以内的所有素数,要怎么设计?首先进入脑海的第一反应是不是将1~10^10这个范围平均分成10份,每一份有109个数,10个线程分别查找范围内的素数?这就是糟糕的设计,尽管每个线程负责的范围是相同的,但是每个线程的负载并不均匀,因为判断一个较大的数是不是素数,通常要比判断较小的数所花费的时间更长。当然这个例子有比较妥善的解决方案,但是在很多情况下,很难将负载均匀地分配给各个线程。
其次,多个线程的任务之间还可能存在顺序依赖的关系,一个线程未能完成某些操作之前,其他线程不能或不应该运行。
多个线程之间需要同步。多个线程生活在进程地址空间这同一个屋檐下,若存在多个线程操作共享资源,则需要同步,否则可能会出现结果错误、数据结构遭到破坏甚至是程序崩溃等后果。因此多线程编程中存在临界区的概念,临界区的代码只允许一个线程执行,线程提供了锁机制来保护临界区。当其他线程来到临界区却无法申请到锁时,就可能陷入阻塞,不再处于可执行状态,线程可能不得不让出CPU资源。如果设计不合理,临界区非常多,线程之间的竞争异常激烈,频繁地上下文切换也会导致性能急剧恶化。
上面两种情况的存在,决定了多线程并非总是处于并发的状态,加速也并非线性的。4个工作线程未必能带来4倍的效率,加速比取决于可以串行执行的部分在全部工作中所占的比例。有人曾经这样打比方:多进程属于立体交通系统,虽然造价高,上坡下坡比较耗油,但是堵车少;多线程属于平面交通系统,造价低,但是红绿灯太多,老堵车。
多线程模型的复杂度更是不容小觑。很多人诟病多线程模型,就在于它不符合人的心智模型。俗语道,一心不可两用,人很难同时控制多条走走停停,彼此又有交互和同步的控制流。由于进程调度的无序性,严格来说多线程程序的每次执行其实并不一样,很难穷举所有的时序组合,所以我们永远无法宣称多线程的程序经过了充分的测试。在某些特殊时序的条件下,bug可能会出现,这种bug难以复现,而且难以排查。所以编程时,需要谨慎地设计,以确保程序能够在所有的时序条件下正常运行。对于多线程编程,还存在四大陷阱,一不小心就可能落入陷阱之中。这四个陷阱分别是:
- 死锁(Dead Lock)
- 饿死(Starvation)
- 活锁(Live Lock)
- 竞态条件(Race Condition)
客观地说,多线程编程的难度要更大一些,需要程序员更加小心,更加谨慎。当你需要使用多线程的时候,一定要花费足够的时间小心地规划每个线程的分工,尽可能地减少线程之间的依赖。良好的设计,合理的分工是多线程编程至关重要的环节。若初期随意地设计线程的分工,那么在最后,你很有可能不得不花费大量的时间来优化性能,定位bug,甚至不得不推倒重来。
进程ID和线程ID
在Linux中,目前的线程实现是Native POSIX Thread Library,简称NPTL。在这种实现下,线程又被称为轻量级进程(Light Weighted Process),每一个用户态的线程,在内核之中都对应一个调度实体,也拥有自己的进程描述符(task_struct结构体)。
没有线程之前,一个进程对应内核里的一个进程描述符,对应一个进程ID。但是引入了线程的概念之后,情况就发生了变化,一个用户进程下管辖N个用户态线程,每个线程作为一个独立的调度实体在内核态都有自己的进程描述符,进程和内核的进程描述符一下子就变成了1∶N的关系,POSIX标准又要求进程内的所有线程调用getpid函数时返回相同的进程ID。如何解决上述问题呢?
内核引入了线程组(Thread Group)的概念。
1 | struct task_struct {... |
多线程的进程,又被称为线程组,线程组内的每一个线程在内核之中都存在一个进程描述符(task_struct)与之对应。进程描述符结构体中的pid,表面上看对应的是进程ID,其实不然,它对应的是线程ID;进程描述符中的tgid,含义是Thread Group ID,该值对应的是用户层面的进程ID。

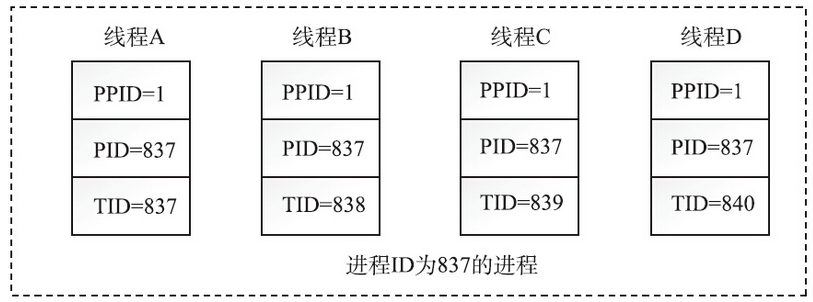
本节介绍的线程ID,不同于后面会讲到的pthread_t类型的线程ID,和进程ID一样,线程ID是pid_t类型的变量,而且是用来唯一标识线程的一个整型变量。那么如何查看一个线程的ID呢?
1 | manu@manu-hacks:~$ ps –eLf |
所以从上面可以看出rsyslogd进程是多线程的,进程ID为837,进程内有4个线程,线程ID分别为837、838、839和840
已知某进程的进程ID,该如何查看该进程内线程的个数及其线程ID呢?其实可以通过/proc/PID/task/目录下的子目录来查看,如下。因为procfs在task下会给进程的每个线程建立一个子目录,目录名为线程ID。
1 | manu@manu-hacks:~$ ll /proc/837/task/总用量 0 |
对于线程,Linux提供了gettid系统调用来返回其线程ID,可惜的是glibc并没有将该系统调用封装起来,再开放出接口来供程序员使用。如果确实需要获取线程ID,可以采用如下方法:
1 |
|
从上面的示例来看,rsyslogd是个多线程的进程,进程ID为837,下面有一个线程的ID也是837,这不是巧合。线程组内的第一个线程,在用户态被称为主线程(main thread),在内核中被称为Group Leader。内核在创建第一个线程时,会将线程组ID的值设置成第一个线程的线程ID,group_leader指针则指向自身,即主线程的进程描述符,如下。
1 | /*线程组ID等于主线程的ID,group_leader指向自身*/ |
所以可以看到,线程组内存在一个线程ID等于进程ID,而该线程即为线程组的主线程。至于线程组其他线程的ID则由内核负责分配,其线程组ID总是和主线程的线程组ID一致,无论是主线程直接创建的线程,还是创建出来的线程再次创建的线程,都是这样。
1 | if (clone_flags & CLONE_THREAD) |
通过group_leader指针,每个线程都能找到主线程。主线程存在一个链表头,后面创建的每一个线程都会链入到该双向链表中。利用上述的结构,每个线程都可以轻松地找到其线程组的主线程(通过group_leader指针),另一方面,通过线程组的主线程,也可以轻松地遍历其所有的组内线程(通过链表)。需要强调的一点是,线程和进程不一样,进程有父进程的概念,但在线程组里面,所有的线程都是对等的关系。
- 并不是只有主线程才能创建线程,被创建出来的线程同样可以创建线程。
- 不存在类似于fork函数那样的父子关系,大家都归属于同一个线程组,进程ID都相等,
group_leader都指向主线程,而且各有各的线程ID。 - 并非只有主线程才能调用
pthread_join连接其他线程,同一线程组内的任意线程都可以对某线程执行pthread_join函数。 - 并非只有主线程才能调用
pthread_detach函数,其实任意线程都可以对同一线程组内的线程执行分离操作。
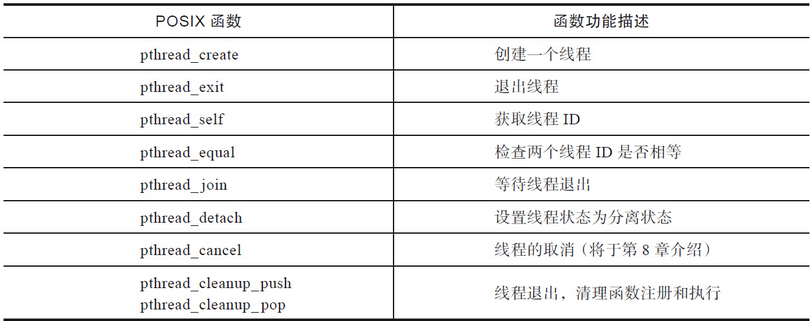
pthread 库接口介绍
后面详细介绍这些函数。
线程的创建和标识
首先要介绍的接口是创建线程的接口,即pthread_create函数。程序开始启动的时候,产生的进程只有一个线程,我们称之为主线程或初始线程。对于单线程的进程而言,只存在主线程一个线程。如果想在主线程之外,再创建一个或多个线程,就需要用到这个接口了。
pthread_create
1 |
|
新建线程如果想要正常工作,则可能需要入参,那么主线程在调用pthread_create的时候,就可以将入参的指针放入第四个参数以传递给新建线程。如果线程的执行函数start_routine需要很多入参,传递一个指针就能提供足够的信息吗?答案是能。线程创建者(一般是主线程)和线程约定一个结构体,创建者便把信息填入该结构体,再将结构体的指针传递给子进程,子进程只要解析该结构体,就能取出需要的信息。如果成功,则pthread_create返回0;如果不成功,则pthread_create返回一个非0的错误码。常见的错误码如表

pthread_create函数的返回情况有些特殊,通常情况下,函数调用失败,则返回-1,并且设置errno。pthread_create函数则不同,它会将errno作为返回值,而不是一个负值。
1 | void * thread_worker(void *) |
线程ID及进程地址空间布局
pthread_create函数,会产生一个线程ID,存放在第一个参数指向的地址中。该线程ID前面提到的线程ID不同。前面提到的线程ID,属于进程调度的范畴。因为线程是轻量级进程,是操作系统调度器的最小单位,所以需要一个数值来唯一标识该线程。而pthread_create函数产生并记录在第一个参数指向地址的线程ID中,属于NPTL线程库的范畴,线程库的后续操作,就是根据该线程ID来操作线程的。
1 |
|
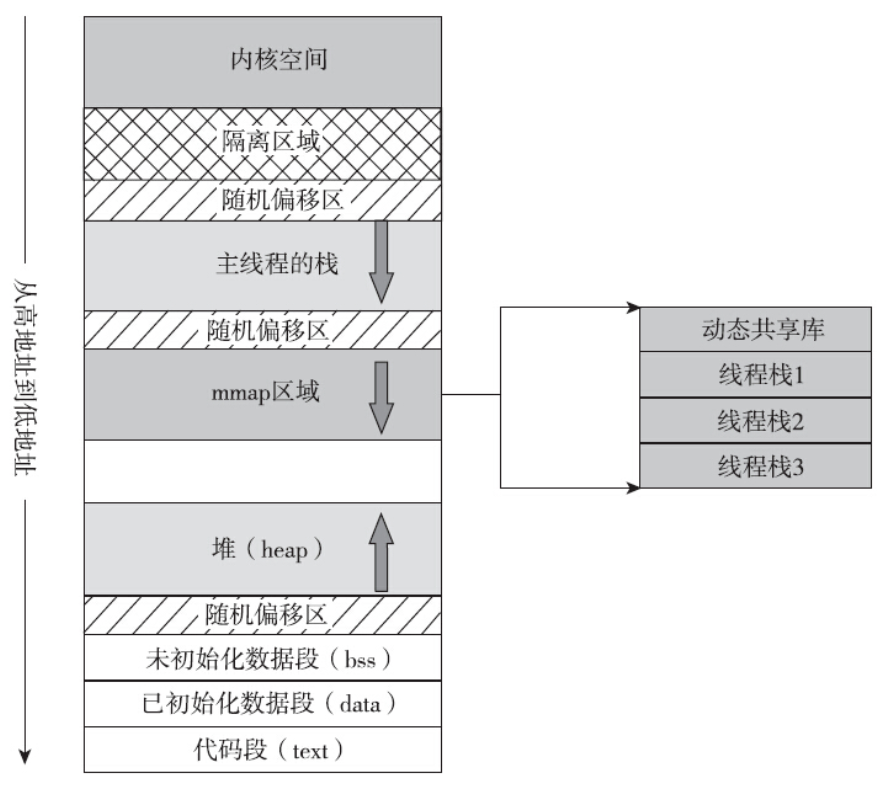
pthread_t到底是个什么样的数据结构呢?因为POSIX标准并没有限制pthread_t的数据类型,所以该类型取决于具体实现。对于Linux目前使用的NPTL实现而言,pthread_t类型的线程ID,本质就是一个进程地址空间上的一个地址。是时候看一下进程地址空间的布局了。在x86_64平台上,用户地址空间为128TB,对于地址空间的布局,系统有如下控制选项:
1 | cat /proc/sys/vm/legacy_va_layout |
该选项影响地址空间的布局,主要是影响mmap区域的基地址位置,以及mmap是向上还是向下增长。如果该值为1,那么mmap的基地址mmap_base变小(约在128T的三分之一处),mmap区域从低地址向高地址扩展。如果该值为0,那么mmap区域的基地址在栈的下面(约在128T空间处),mmap区域从高地址向低地址扩展。默认值为0,布局如下图所示。
可以通过procfs或pmap命令来查看进程的地址空间的情况:
1 | pmap PID |
在接近128TB的巨大地址空间里面,代码段、已初始化数据段、未初始化数据段,以及主线程的栈,所占用的空间非常小,都是KB、MB这个数量级的,如下:
1 | manu@manu-hacks:~$ pmap 3706 |
由于主线程的栈大小并不是固定的,要在运行时才能确定大小(上限大概在8MB左右),因此,在栈中不能存在巨大的局部变量,另外编写递归函数时一定要小心,递归不能太深,否则很可能耗尽栈空间。
进程地址空间之中,最大的两块地址空间是内存映射区域和堆。堆的起始地址特别低,向上扩展,mmap区域的起始地址特别高,向下扩展。用户调用pthread_create函数时,glibc首先要为线程分配线程栈,而线程栈的位置就落在mmap区域。glibc会调用mmap函数为线程分配栈空间。pthread_create函数分配的pthread_t类型的线程ID,不过是分配出来的空间里的一个地址,更确切地说是一个结构体的指针,如下图所示。
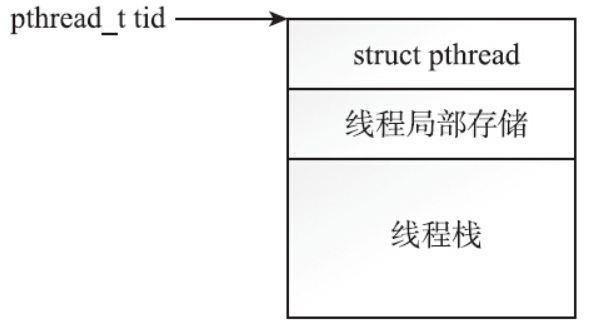
创建两个线程,将其pthread_self()的返回值打印出来,输出如下:
1 | address of tid in thread-1 = 0x7f011ca12700 |
线程ID是进程地址空间内的一个地址,要在同一个线程组内进行线程之间的比较才有意义。不同线程组内的两个线程,哪怕两者的pthread_t值是一样的,也不是同一个线程,这是显而易见的。很有意思的一点是,pthread_t类型的线程ID很有可能会被复用。在满足下列条件时,线程ID就有可能会被复用:
线程退出。
线程组的其他线程对该线程执行了pthread_join,或者线程退出前将分离状态设置为已分离。
再次调用pthread_create创建线程。
对于pthread_t类型的线程ID,虽然在同一时刻不会存在两个线程的ID值相同,但是如果线程退出了,重新创建的线程很可能复用了同一个pthread_t类型的ID。从这个角度看,如果要设计调试日志,用pthread_t类型的线程ID来标识进程就不太合适了。用pid_t类型的线程ID则是一个比较不错的选择。
1 |
|
采用pid_t类型的线程ID来唯一标识进程有以下优势:
- 返回类型是pid_t类型,进程之间不会存在重复的线程ID,而且不同线程之间也不会重复,在任意时刻都是全局唯一的值。
- procfs中记录了线程的相关信息,可以方便地查看/proc/pid/task/tid来获取线程对应的信息。
- ps命令提供了查看线程信息的-L选项,可以通过输出中的LWP和NLWP,来查看同一个线程组的线程个数及线程ID的信息。
另外一个比较有意思的功能是我们可以给线程起一个有意义的名字,命名以后,既可以从procfs中获取到线程的名字,也可以从ps命令中得到线程的名字,这样就可以更好地辨识不同的线程。Linux提供了prctl系统调用:
1 |
|
这个系统调用和ioctl非常类似,通过option来控制系统调用的行为。当需要给线程设定名字的时候,只需要将option设为PR_SET_NAME,同时将线程的名字作为arg2传递给prctl系统调用即可,这样就能给线程命名了。
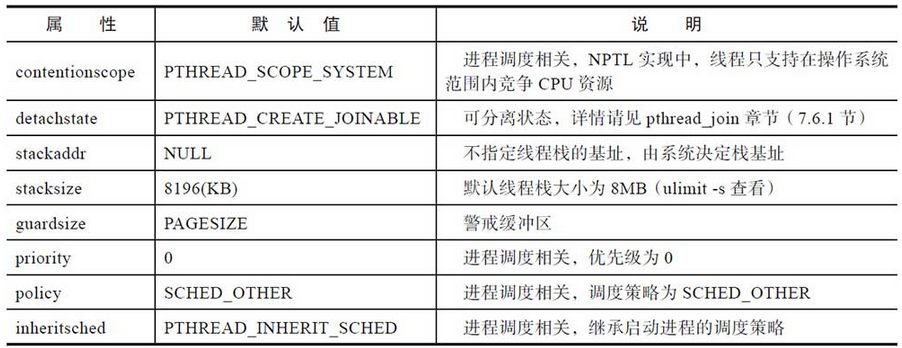
线程创建的默认属性
线程创建的第二个参数是pthread_attr_t类型的指针,pthread_attr_init函数会将线程的属性重置成默认值。
1 | pthread_attr_t attr; |
在创建线程时,传递重置过的属性,或者传递NULL,都可以创建一个具有默认属性的线程,见表:
默认情况下,线程栈的大小为8MB:
1 | manu@manu-hacks:~$ ulimit -s |
调用pthread_attr_getstack函数可以返回线程栈的基地址和栈的大小。出于可移植性的考虑不建议指定线程栈的基地址。但是有时候会有修改线程栈的大小的需要。一个线程需要分配8MB左右的栈空间,就决定了不可能无限地创建线程,在进程地址空间受限的32位系统里尤为如此。在32位系统下,3GB的用户地址空间决定了能创建线程的个数不会太多。如果确实需要很多的线程,可以调用接口来调整线程栈的大小:
1 |
|
线程退出
有生就有灭,线程执行完任务,也需要终止。下面的三种方法中,线程会终止,但是进程不会终止(如果线程不是进程组里的最后一个线程的话):
- 创建线程时的start_routine函数执行了return,并且返回指定值。
- 线程调用pthread_exit。
- 其他线程调用了pthread_cancel函数取消了该线程。
如果线程组中的任何一个线程调用了exit函数,或者主线程在main函数中执行了return语句,那么整个线程组内的所有线程都会终止。
值得注意的是,pthread_exit和线程启动函数(start_routine)执行return是有区别的。在start_routine中调用的任何层级的函数执行pthread_exit()都会引发线程退出,而return,只能是在start_routine函数内执行才能导致线程退出。
1 | // 如果foo函数执行了pthread_exit函数,则线程会立刻退出,后面的bar就会没有机会执行了。 |
1 |
|
这里有一个问题,就是不能将遗言存放到线程的局部变量里,因为如果用户写的线程函数退出了,线程函数栈上的局部变量可能就不复存在了,线程的临终遗言也就无法被接收者读到。那我们应该如何正确地传递返回值呢?
- 如果是int型的变量,则可以使用
pthread_exit((int*)ret)。 - 使用全局变量返回。
- 将返回值填入到用malloc在堆上分配的空间里。
- 使用字符串常量,如pthread_exit(“hello,world”)。
第一种是tricky的做法,我们将返回值ret进行强制类型转换,接收方再把返回值强制转换成int。但是不推荐使用这种方法。这种方法虽然是奏效的,但是太tricky,而且C标准没有承诺将int型转成指针后,再从指针转成int型时,数据一直保持不变。
第二种方法使用全局变量,其他线程调用pthread_join时也可见这个变量。
第三种方法是用malloc,在堆上分配空间,然后将返回值填入其中。因为堆上的空间不会随着线程的退出而释放,所以pthread_join可以取出返回值。切莫忘记释放该空间,否则会引起内存泄漏。
第四种方法之所以可行,是因为字符串常量有静态存储的生存期限。
传递线程的返回值,除了pthread_exit函数可以做到,线程的启动函数(start_routine函数)return也可以做到,两者的数据类型要保持一致,都是void*类型。这也解释了为什么线程的启动函数start_routine的返回值总是void*类型,如下:
1 | void pthread_exit(void *retval); |
线程退出有一种比较有意思的场景,即线程组的其他线程仍在执行的情况下,主线程却调用pthread_exit函数退出了。这会发生什么事情?首先要说明的是这不是常规的做法,但是如果真的这样做了,那么主线程将进入僵尸状态,而其他线程则不受影响,会继续执行。
当主线程调用 pthread_exit(NULL) 时,它会导致主线程自行终止,但不会终止整个进程。具体行为如下:
主线程终止:
pthread_exit(NULL)使得调用线程(在这里是主线程)正常退出。进程继续运行: 如果在
pthread_exit(NULL)被调用时,进程中还有其他线程在运行,那么这些线程会继续执行,进程不会因为主线程的退出而终止。不会执行
return 0;: 在pthread_exit(NULL)被调用后,主线程的控制流不会继续执行,因此pthread_exit(NULL)之后的任何代码,包括return 0;,都不会被执行。进程终止条件: 进程会在所有线程都终止后才会终止。因此,如果主线程调用了
pthread_exit(NULL),而其他线程仍在运行,进程会继续存在,直到所有线程都结束。
如果主线程希望在退出时终止整个进程,通常会使用 exit() 或 return 语句(在 main 函数中)。exit() 会终止进程并停止所有线程的运行,而 return 语句在 main 函数中也会导致进程终止。
线程的连接与分离
线程的连接
线程库提供了pthread_join函数,用来等待某线程的退出并接收它的返回值。这种操作被称为连接(joining)。相关函数的接口定义如下:
1 |
|
根据等待的线程是否退出,可得到如下两种情况:
- 等待的线程尚未退出,那么pthread_join的调用线程就会陷入阻塞。
- 等待的线程已经退出,那么pthread_join函数会将线程的退出值
(void*类型)存放到retval指针指向的位置。
线程的连接(join)操作有点类似于进程等待子进程退出的等待(wait)操作,但细细想来,还是有不同之处:第一点不同之处是进程之间的等待只能是父进程等待子进程,而线程则不然。线程组内的成员是对等的关系,只要是在一个线程组内,就可以对另外一个线程执行连接(join)操作。如图所示,线程F一样可以连接线程A。
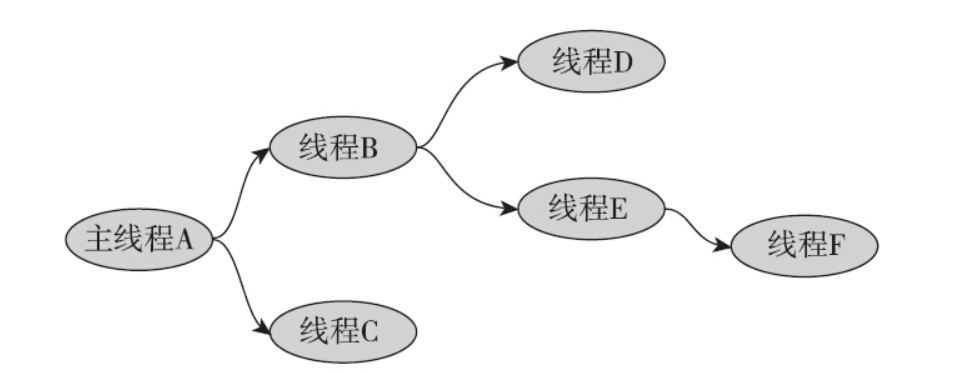
第二点不同之处是进程可以等待任一子进程的退出,但是线程的连接操作没有类似的接口,即不能连接线程组内的任一线程,必须明确指明要连接的线程的线程ID。
1 | wait(&status); |
pthread_join不能连接线程组内任意线程的做法,并不是NPTL线程库设计上的瑕疵,而是有意为之的。如果听任线程连接线程组内的任意线程,那么所谓的任意线程就会包括其他库函数私自创建的线程,当库函数尝试连接(join)私自创建的线程时,发现已经被连接过了,就会返回EINVAL错误。如果库函数需要根据返回值来确定接下来的流程,这就会引发严重的问题。正确的做法是,连接已知线程ID的那些线程,就像pthread_join函数那样。
下面来分析出错的情况,当调用失败时,和pthread_create函数一样,errno作为返回值返回。错误码的情况见表:
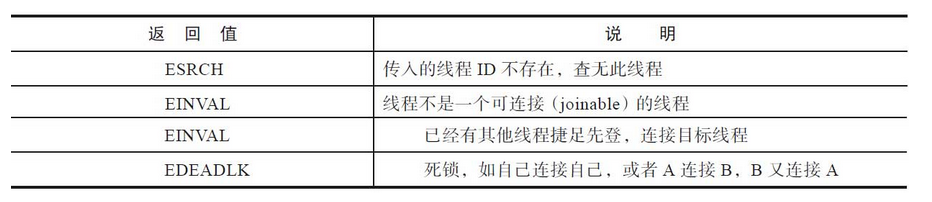
pthread_join函数之所以能够判断是否死锁和连接操作是否被其他线程捷足先登,是因为目标线程的控制结构体struct pthread中,存在如下成员变量,记录了该线程的连接者。
1 | struct pthread *joinid; |
该指针存在三种可能,如下。
- NULL:线程是可连接的,但是尚没有其他线程调用pthread_join来连接它。
- 指向线程自身的struct pthread:表示该线程属于自我了断型,执行过分离操作,或者创建线程时,设置的分离属性为PTHREAD_CREATE_DETACHED,一旦退出,则自动释放所有资源,无需其他线程来连接。
- 指向线程组内其他线程的struct pthread:表示joinid对应的线程会负责连接。
因为有了该成员变量来记录线程的连接者,所以可以判断如下场景,如图所示。
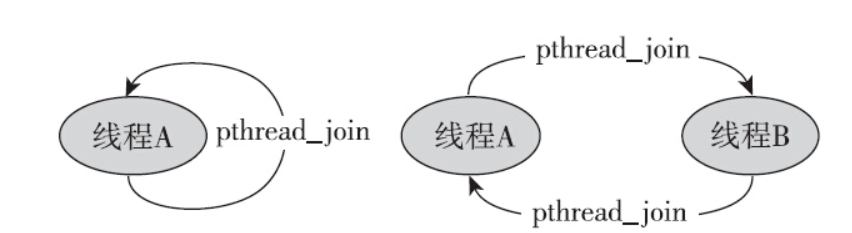
不过两者还是略有区别的,第一种场景,线程A连接线程A,pthread_join函数一定会返回EDEADLK。但是第二种场景,大部分情况下会返回EDEADLK,不过也有例外。不管怎样,不建议两个线程互相连接。如果两个线程几乎同时对处于可连接状态的线程执行连接操作会怎么样?答案是只有一个线程能够成功,另一个则返回EINVAL。NTPL提供了原子性的保证:
1 | (atomic_compare_and_exchange_bool_acq(&pd->joined,self,NULL) |
- 如果是NULL,则设置成调用线程的线程ID,CAS操作(Compare And Swap)是原子操作,不可分割,决定了只有一个线程能成功。
- 如果joinid不是NULL,表示该线程已经被别的线程连接了,或者正处于已分离的状态,在这两种情况下,都会返回EINVAL。
连接退出的线程
不连接已经退出的线程会怎么样?如果不连接已经退出的线程,会导致资源无法释放。所谓资源指的又是什么呢?下面通过一个测试来让事实说话。测试模拟下面两种情况:
- 主线程并不执行连接操作,待确定创建的第一个线程退出后,再创建第二个线程。
- 主线程执行连接操作,等到第一个线程退出后,再创建第二个线程。
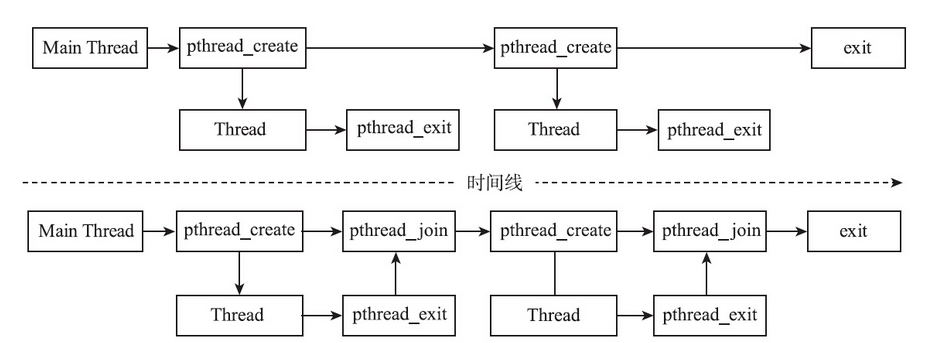
面是代码部分,为了简化程序和便于理解,使用sleep操作来确保创建的第一个线程退出后,再来创建第二个线程。须知sleep并不是同步原语,在真正的项目代码中,用sleep函数来同步线程是不可原谅的。
1 |
|
根据编译选项NO_JOIN,将程序编译成以下两种情况:
- 编译加上
–DNO_JOIN:主线不执行pthread_join,主线程通过sleep足够的时间,来确保第一个线程退出以后,再创建第二个线程。 - 不加
NO_JOIN编译选项:主线程负责连接线程,第一个线程退出以后,再来创建第二个线程。
下面按照编译选项,分别编出pthread_no_join和pthread_has_join两个程序:
1 | gcc -o pthread_no_join pthread_join_cmp.c -DNO_JOIN –lpthread |
1 | // 首先说说pthread_no_join的情况,当创建了第一个线程时: |
从上面的输出可以看出两点:
1)已经退出的线程,其空间没有被释放,仍然在进程的地址空间之内。
2)新创建的线程,没有复用刚才退出的线程的地址空间。
如果仅仅是情况1的话,尚可以理解,但是1和2同时发生,既不释放,也不复用,这就不能忍了,因为这已经属于内存泄漏了。试想如下场景:FTP Server采用thread per connection的模型,每接受一个连接就创建一个线程为之服务,服务结束后,连接断开,线程退出。但线程退出了,线程栈消耗的空间仍不能释放,不能复用,久而久之,内存耗尽,再也不能创建线程,也无法再提供FTP服务。
线程的分离
默认情况下,新创建的线程处于可连接(Joinable)的状态,可连接状态的线程退出后,需要对其执行连接操作,否则线程资源无法释放,从而造成资源泄漏。如果其他线程并不关心线程的返回值,那么连接操作就会变成一种负担:你不需要它,但是你不去执行连接操作又会造成资源泄漏。这时候你需要的东西只是:线程退出时,系统自动将线程相关的资源释放掉,无须等待连接。NPTL提供了pthread_detach函数来将线程设置成已分离(detached)的状态,如果线程处于已分离的状态,那么线程退出时,系统将负责回收线程的资源,如下:
1 |
|
可以是线程组内其他线程对目标线程进行分离,也可以是线程自己执行pthread_detach函数,将自身设置成已分离的状态,如下:
1 | pthread_detach(pthread_self()) |
线程的状态之中,可连接状态和已分离状态是冲突的,一个线程不能既是可连接的,又是已分离的。因此,如果线程处于已分离的状态,其他线程尝试连接线程时,会返回EINVAL错误。pthread_detach出错的情况见表所示。

需要强调的是,不要误解已分离状态的内涵。所谓已分离,并不是指线程失去控制,不归线程组管理,而是指线程退出后,系统会自动释放线程资源。若线程组内的任意线程执行了exit函数,即使是已分离的线程,也仍然会受到影响,一并退出。将线程设置成已分离状态,并非只有pthread_detach一种方法。另一种方法是在创建线程时,将线程的属性设定为已分离:
1 |
|
其中detachstate的可能值如表所示。

有了这个,如果确实不关心线程的返回值,可以在创建线程之初,就指定其分离属性为PTHREAD_CREATE_DETACHED。
互斥量
大部分情况下,线程使用的数据都是局部变量,变量的地址在线程栈空间内,这种情况下,变量归属于单个线程,其他线程无法获取到这种变量。如果所有的变量都是如此,将会省去无数的麻烦。但实际的情况是,很多变量都是多个线程共享的,这样的变量称为共享变量(shared variable)。可以通过数据的共享,完成多个线程之间的交互。但是多个线程并发地操作共享变量,会带来一些问题。
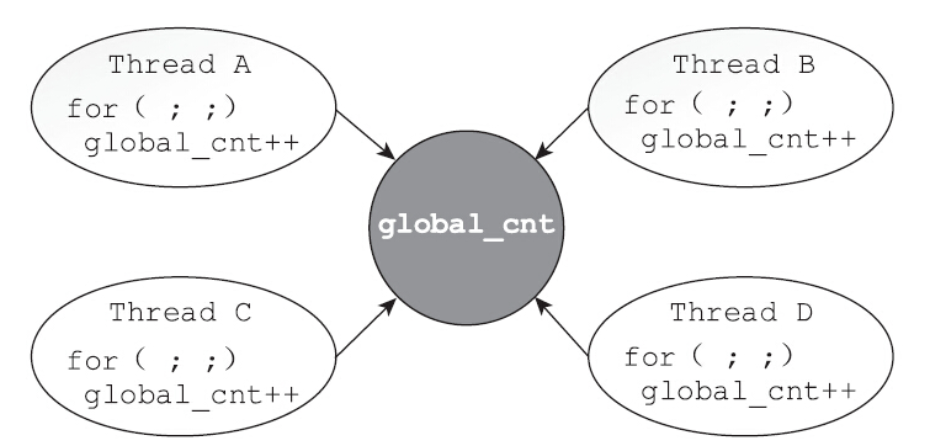
如果存在4个线程,不加任何同步措施,共同操作一个全局变量global_cnt,假设每个线程执行1000万次自加操作,那么会发生什么事情呢?4个线程结束的时候,global_cnt等于几?结果并不是期待的4000万,而是11115156,一个很奇怪的数字。而且每次执行,最后的结果都不相同。为什么无法获得正确的结果?
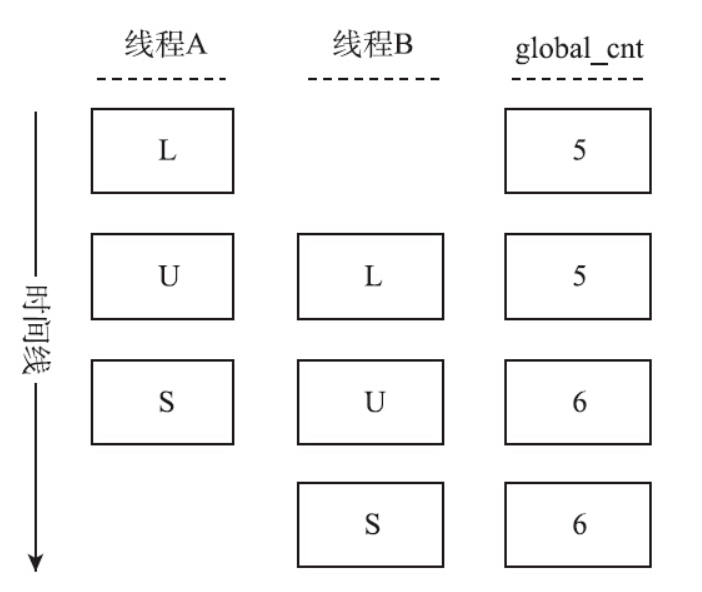
++操作,并不是一个原子操作(atomic operation),而是对应了如下三条汇编指令。
- Load:将共享变量global_cnt从内存加载进寄存器,简称L。
- Update:更新寄存器里面的global_cnt值,执行加1操作,简称U。
- Store:将新的值,从寄存器写回到共享变量global_cnt的内存地址,简称为S。将上述情况用伪代码表示,就是如下情况:
1 | L操作:register = global_cnt |
两个线程为例,如果两个线程的执行如图所示,就会引发结果不一致:执行了两次++操作,最终的结果却只加了1。
上面的例子表明,应该避免多个线程同时操作共享变量,对于共享变量的访问,包括读取和写入,都必须被限制为每次只有一个线程来执行。用更详细的语言来描述下,解决方案需要能够做到以下三点。
1)代码必须要有互斥的行为:当一个线程正在临界区中执行时,不允许其他线程进入该临界区中。
2)如果多个线程同时要求执行临界区的代码,并且当前临界区并没有线程在执行,那么只能允许一个线程进入该临界区。
3)如果线程不在临界区中执行,那么该线程不能阻止其他线程进入临界区。上面说了这么多,本质其实就是一句话,我们需要一把锁
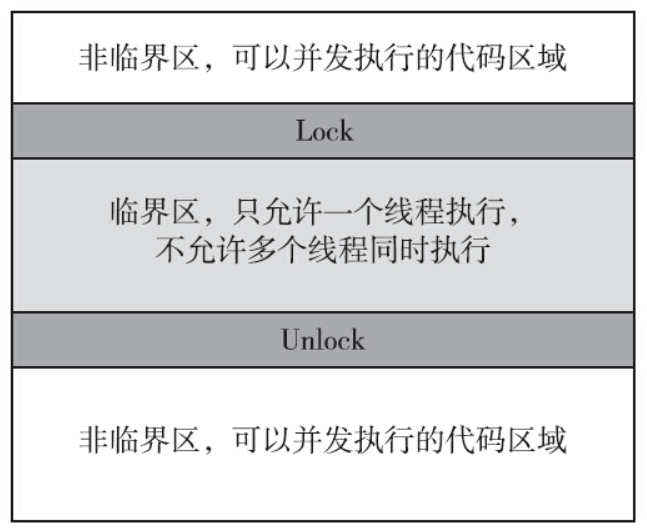
锁是一个很普遍的需求,当然用户可以自行实现锁来保护临界区。但是实现一个正确并且高效的锁非常困难。纵然抛下高效不谈,让用户从零开始实现一个正确的锁也并不容易。正是因为这种需求具有普遍性,所以Linux提供了互斥量。
互斥量的接口
互斥量的初始化
互斥量采用的是英文mutual exclusive(互相排斥之意)的缩写,即mutex。正确地使用互斥量来保护共享数据,首先要定义和初始化互斥量。POSIX提供了两种初始化互斥量的方法。第一种方法是将PTHREAD_MUTEX_INITIALIZER赋值给定义的互斥量,如下:
1 |
|
如果互斥量是动态分配的,或者需要设定互斥量的属性,那么上面静态初始化的方法就不适用了,NPTL提供了另外的函数pthread_mutex_init()对互斥量进行动态的初始化:
1 | int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr); |
第二个pthread_mutexattr_t指针的入参,是用来设定互斥量的属性的。大部分情况下,并不需要设置互斥量的属性,传递NULL即可,表示使用互斥量的默认属性。调用pthread_mutex_init()之后,互斥量处于没有加锁的状态。
互斥量的销毁
在确定不再需要互斥量的时候,就要销毁它。在销毁之前,有三点需要注意:
- 使用
PTHREAD_MUTEX_INITIALIZER初始化的互斥量无须销毁。 - 不要销毁一个已加锁的互斥量,或者是真正配合条件变量使用的互斥量。
- 已经销毁的互斥量,要确保后面不会有线程再尝试加锁。销毁互斥量的接口如下:
1 | int pthread_mutex_destroy(pthread_mutex_t *mutex); |
当互斥量处于已加锁的状态,或者正在和条件变量配合使用,调用pthread_mutex_destroy函数会返回EBUSY错误码。
互斥量的加锁和解锁
POSIX提供了如下接口:
1 | int pthread_mutex_lock(pthread_mutex_t *mutex); |
在调用pthread_lock()的时候,可能会遭遇以下几种情况:
- 互斥量处于未锁定的状态,该函数会将互斥量锁定,同时返回成功。
- 发起函数调用时,其他线程已锁定互斥量,或者存在其他线程同时申请互斥量,但没有竞争到互斥量,那么pthread_lock()调用会陷入阻塞,等待互斥量解锁。
在等待的过程中,如果互斥量持有线程解锁互斥量,可能会发生如下事件:
- 函数调用线程是唯一等待者,获得互斥量,成功返回。
- 函数调用线程不是唯一等待者,但成功获得互斥量,返回。
- 函数调用线程不是唯一等待者,没能获得互斥量,继续阻塞,等待下一轮。
- 如果在调用pthread_lock()线程时,之前已经调用过pthread_lock()且已经持有了互斥量,则根据互斥锁的类型,存在以下三种可能。
- PTHREAD_MUTEX_NORMAL:这是默认类型的互斥锁,这种情况下会发生死锁,调用线程永久阻塞,线程组的其他线程也无法申请到该互斥量。
- PTHREAD_MUTEX_ERRORCHECK:第二次调用pthread_mutex_lock函数时返回EDEADLK。
- PTHREAD_MUTEX_RECURSIVE:这种类型的互斥锁内部维护有引用计数,允许锁的持有者再次调用加锁操作。
1 | pthread_mutex_lock(&mutex); |
有了互斥量,重新运行上面的的程序,将会得到正确的结果。
临界区的大小
现在,我们已经意识到需要用锁来保护共享变量。不过还有另一个需要注意的事项,即合理地设定临界区的范围。第一临界区的范围不能太小,如果太小,可能起不到保护的目的。考虑如下场景,如果哈希表中不存在某元素,那么向哈希表中插入某元素,代码如下:
1 | if(!htable_contain(hashtable,elem.key)) |
表面上看,共享变量hashtable得到了保护,在插入时有锁保护,但是结果却不是我们想要的。上面的程序不希望哈希表中有重复的元素,但是其临界区太小,多线程条件下可能达不到预设的效果。
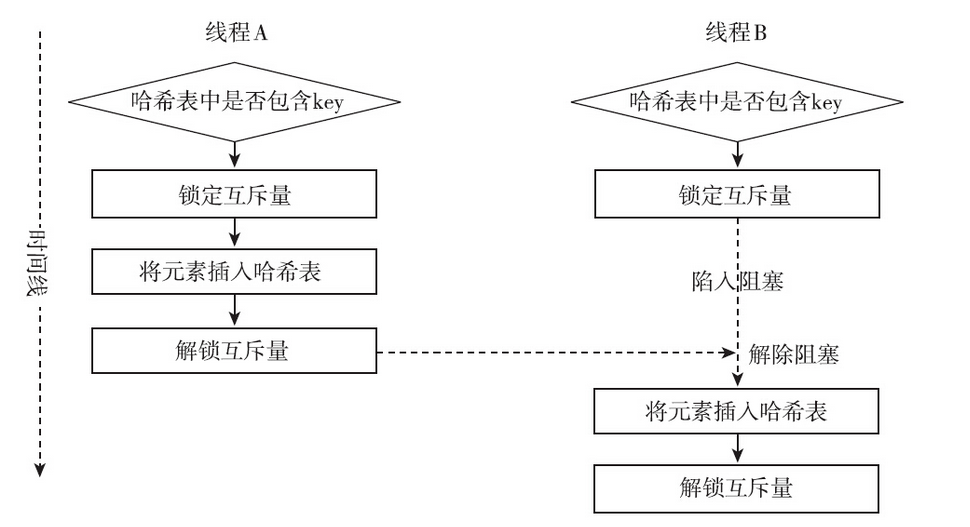
互斥量的性能
还是以前面的例子为例进行说明,4个线程分别对全局变量累加1000万次,使用互斥量版本的程序和不使用互斥量的版本相比,会消耗更多的时间

互斥量版本需要消耗更长的时间,其原因有以下三点:
1)对互斥量的加锁和解锁操作,本身有一定的开销。
2)临界区的代码不能并发执行。
3)进入临界区的次数过于频繁,线程之间对临界区的争夺太过激烈,若线程竞争互斥量失败,就会陷入阻塞,让出CPU,所以执行上下文切换的次数要远远多于不使用互斥量的版本。
Linux下,互斥量的实现采用了futex(fast user space mutex)机制。传统的同步手段,进入临界区之前会申请锁,而此时不得不执行系统调用,查看是否存在竞争;当离开临界区释放锁的时候,需要再次执行系统调用,查看是否需要唤醒正在等待锁的进程。但是在竞争并不激烈的情况下,加锁和解锁的过程中可能会出现以下两种情况:
- 申请锁时,执行系统调用,从用户模式进入内核模式,却发现并无竞争。
- 释放锁时,执行系统调用,从用户模式进入内核模式,尝试唤醒正在等待锁的进程,却发现并没有进程正在等待锁的释放。
考虑到系统调用的开销,这两种情况耗资靡费,却劳而无功。futex机制的出现有效地解决了这两个问题。futex的全称是fast userspace mutex,中文名为快速用户空间互斥体,它是一种用户态和内核态协同工作的同步机制。glibc使用内核提供的futex系统调用实现了互斥量。glibc的互斥量实现,含有大量的汇编代码,不易读懂,下面用伪代码来描述下互斥量的加锁和解锁操作:
1 | void lock(mutex* lock) |
上面的cmpxchg和atomic_dec都是原子操作。
- cmpxchg(lock,a,b):表示如果lock的值等于a,那么将lock改为b,并将原始值返回,否则直接将原始值返回。
- atomic_dec(lock):表示将lock的值减去1,并且返回原始值。glibc的互斥量中维护了一个值lock,该值有以下三种情况。
- 0:表示互斥量并未上锁。
- 1:表示互斥量已经上锁,但是并没有线程正在等待该锁。
- 2:表示互斥量已经上锁,并且有线程正在等待该锁。
加锁时,如果发现该值是0,那么直接将该值改为1,无须执行任何系统调用,因为并没有线程持有该锁,无须等待;解锁时,如果发现该值是1,直接将该值改成0,无须执行任何系统调用,因为并没有线程正在等待该锁,无须唤醒。当然,在这两种情况下,比较和修改操作(Compare And Swap)必须是原子操作,否则会出现问题。如果无竞争,可以看出,互斥量的加锁和解锁非常轻量级。
内核提供了futex_wait和futex_wake两个操作(futex系统调用支持的两个命令):
1 | int futex_wait(int *uaddr, int val); |
futex_wait是用来协助加锁操作的。线程调用pthread_mutex_lock,如果发现锁的值不是0,就会调用futex_wait,告知内核,线程须要等待在uaddr对应的锁上,请将线程挂起。内核会建立与uaddr地址对应的等待队列。为什么需要内核维护等待队列?因为一旦互斥量的持有者线程释放了互斥量,就需要及时通知那些等待在该互斥量上的线程。如果没有等待队列,内核将无法通知到那些正陷入阻塞的线程。如果整个系统有很多这种互斥量,是不是需要为每个uaddr地址建立一个等待队列呢?事实上不需要。理论上讲,futex只需要在内核之中维护一个队列就够了,当线程释放互斥量时,可能会调用futex_wake,此时会将uaddr传进来,内核会去遍历该队列,查找等待在该uaddr地址上的线程,并将相应的线程唤醒。但是只有一个队列的话查找效率有点低,作为优化,内核实现了多个队列。插入等待队列时,会先计算hash值,然后根据hash插入到对应的链表之中
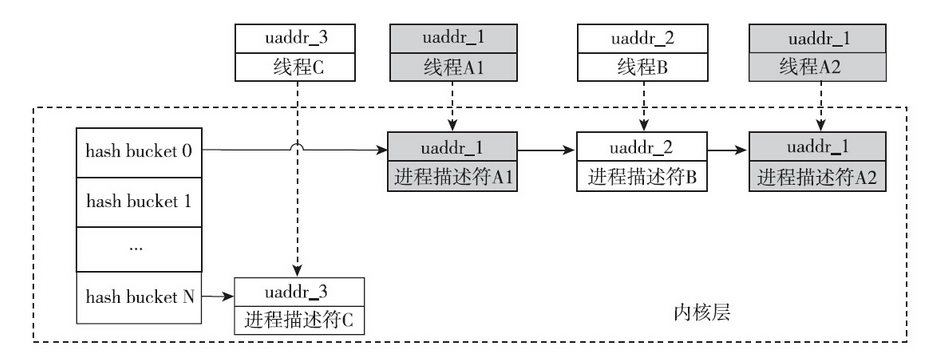
值得一提的是,futex_wait操作需要的val入参,乍看之下好像没什么用处。事实上并非如此。从用户程序判断锁的值,到调用futex_wait操作是有时间窗口的,在这个时间窗口之内,有可能发生线程解锁的操作,从而可能无须等待。因此futex_wait操作会检查uaddr对应的锁的值是否等于val的值,只有在等于val的情况下,内核才会让线程等待在对应的队列上,否则会立刻返回,让用户程序再次申请锁。
futex_wake操作是用来实现解锁操作的。glibc就是使用该操作来实现互斥量的解锁函数pthread_mutex_unlock的。当线程执行完临界区代码,解锁时,内核需要通知那些正在等待该锁的线程。这时候就需要发挥futex_wake操作的作用了。futex_wake的第二个参数n,对于互斥量而言,该值总是1,表示唤醒1个线程。当然,也可以唤醒所有正在等待该锁的线程,但是这样做并无好处,因为被唤醒的多个线程会再次竞争,却只能有一个线程抢到锁,这时其他线程不得不再次睡去,徒增了很多开销。使用strace跟踪系统调用的时候,看不到futex_wait和futex_wake两个系统调用,看到的是futex系统调用,如下。
1 |
|
该系统调用是一个综合的系统调用,根据第二个参数op来决定具体的行为。当op为FUTEX_WAIT时,对应的是前面讨论的futex_wait操作,当op为FUTEX_WAKE时,对应的是前面讨论的futex_wake操作。细心的话,可以发现,互斥量加锁和解锁时,调用futex的op参数并非FUTEX_WAIT和FUTEX_WAKE,而是FUTEX_WAIT_PRIVATE和FUTEX_WAKE_PRIVATE,这是为了改进futex的性能而进行的优化。因为futex也可以用在不同的进程之间,加上后缀_PRIVATE是为了明确告知内核,互斥的行为是用在线程之间的。从上面的角度分析,当存在竞争时,如果线程申请不到互斥量,就会让出CPU,系统会发生上下文切换。在线程个数众多,临界区竞争异常激烈的情况下,上下文切换会是一笔不小的开销。如果临界区非常小,线程之间对临界区的竞争并不激烈,只会偶尔发生,这种情况下,忙-等待的策略要优于互斥量的“让出CPU,陷入阻塞,等待唤醒”的策略。采用忙-等待策略的锁为自旋锁。
互斥锁的公平性
首先要定义什么是公平(fairness)。对于锁而言,如果A在B之前调用lock()方法,那么A应该先于B获得锁,进入临界区。多处理器条件下,很难确定是哪个线程率先调用的lock()方法。纵然能判定是哪个线程率先调用的lock()方法,要实现指令级的公平也是很难的。常见的判断锁公平性的方法是,将锁的实现代码分成如下两个部分:
- 门廊区
- 等待区
如果锁能满足以下条件,就称锁是先来先服务(FCFS)的:如果线程A门廊区的结束在线程B门廊区的开始之前,那么线程A一定不会被线程B赶超。
互斥量也有门廊区和等待区,如果没有竞争,线程执行几个指令就加锁成功,顺利返回了。在这种情况下,互斥量在门廊区就解决了所有的需要。但是如果有竞争,互斥锁在门廊区判断出存在竞争,线程取不到锁,就不得不执行futex_wait,让内核将其挂起,并记录在等待队列上。需要等待多久?不知道。从表面上看,内核会将等待互斥量的线程放入队列,每来一个等待线程,就把线程记录在队列的尾部,当互斥量的持有线程解锁时,内核只会唤醒一个线程,而唤醒的正是队列中等待该互斥量的第一个等待者。队列的先入先出(FIFO),看起来已经保证了互斥量的公平性。但是,这样就能确保公平吗?答案是否定的,互斥锁并没有做到先来先服务。
当互斥量的lock的值是2,或者尝试调用CAS操作将lock从1改成2并且成功时,线程会调用futex_wait陷入阻塞。值得一提的是,CAS操作在尝试将1改成2时,也可能存在竞争,比如其他线程有解锁操作,lock值已经被改成了0,而这时候恰好存在另外一个线程刚刚调用加锁操作,这时就会发生门廊区的争夺,对于这种情况不做详细分析。假设加锁调用了futex_wait,内核将线程挂起在等待队列上,从那时起,线程就进入了漫长的等待区。如果互斥量的持有线程解锁,会首先将互斥量的lock值设置成0,然后唤醒内核等待队列中等待在该地址上的第一个线程。看起来比较公平,但是问题就出在此处,被唤醒的线程并不是自动就持有了互斥锁,反而须要执行while()中包裹的cmpxchg操作,再次竞争互斥量。如果竞争失败,则被另外一个初来乍到的线程将0改成了1,那么线程刚刚醒来就不得不再次执行futex_wait,再次沉睡。这次竞争失败的代价是巨大的,因为futex_wait操作会将线程挂载到等待队列的队尾。由上面的分析可以得出如下结论:
- 线程可能多次调用futex_wait进入等待区,在线程被futex_wait唤醒后,并不会自动拥有互斥量,而是再次进入门廊区,和其他线程争夺锁。
- 在已经有很多线程处于内核等待队列的情况下,新来的加锁请求可能会后发先至,率先获得锁。
- futex_wait唤醒的线程如果没有竞争到锁,那么会再次调用futex_wait函数,陷入睡眠,不过内核会将其放入等待队列的队尾,这种行为加剧了不公平性。
为什么开发者并不在意这种不公平性?因为要实现这种公平性会牺牲性能,而这种牺牲并无必要。绝大多数情况下,由于调度的原因,用户根本无法判断哪个线程会优先调用加锁操作,那么内核或glibc维持这种先来先服务(FCFS)就变得毫无意义。如果可以在不牺牲性能的情况下做到公平,自然最好,但是实际情况并非如此。实现这种公平,对性能的伤害很大。
互斥锁的类型
互斥量有以下4种类型:
- PTHREAD_MUTEX_TIMED_NP
- PTHREAD_MUTEX_RECURSIVE
- PTHREAD_MUTEX_ERRORCHECK
- PTHREAD_MUTEX_ADAPTIVE_NP
glibc提供了接口来查询和设置互斥锁的类型:
1 |
|
可以仿照如下代码来设置互斥量的类型:
1 | /*忽略了出错判断,真实代码中需要判断error*/ |
下面来分别介绍这几个互斥量的特点。
PTHREAD_MUTEX_NORMAL:最普通的一种互斥锁。前文讨论的就是这种类型的锁。它不具备死锁检测功能,如线程对自己锁定的互斥量再次加锁,则会发生死锁。
PTHREAD_MUTEX_RECURSIVE_NP:支持递归的一种互斥锁,该互斥量的内部维护有互斥锁的所有者和一个锁计数器。当线程第一次取到互斥锁时,会将锁计数器置1,后续同一个线程再次执行加锁操作时,会递增该锁计数器的值。解锁则递减该锁计数器的值,直到降至0,才会真正释放该互斥量,此时其他线程才能获取到该互斥量。解锁时,如果互斥量的所有者不是调用解锁的线程,则会返回EPERM。
PTHREAD_MUTEX_ERRORCHECK_NP:支持死锁检测的互斥锁。互斥量的内部会记录互斥锁的当前所有者的线程ID(调度域的线程ID)。如果互斥量的持有线程再次调用加锁操作,则会返回EDEADLK。解锁时,如果发现调用解锁操作的线程并不是互斥锁的持有者,则会返回EPERM。
THREAD_MUTEX_ADAPTIVE_NP:自旋锁副作用大,而互斥量在某些情况下效率可能不够高,有没有一种方法能够结合两种方法的长处呢?答案是肯定的。这就是PTHREAD_MUTEX_ADAPTIVE_NP类型的互斥量,也被称为自适应锁。libc的文档里面直接将其称为fast mutex。
glibc引入了线程自旋锁。自旋锁采用了和互斥量完全不同的策略,自旋锁加锁失败,并不会让出CPU,而是不停地尝试加锁,直到成功为止。这种机制在临界区非常小且对临界区的争夺并不激烈的场景下,效果非常好,
#include <pthread.h> int pthread_spin_init(pthread_spinlock_t *lock, int pshared); int pthread_spin_lock(pthread_spinlock_t *lock); int pthread_spin_trylock(pthread_spinlock_t *lock); int pthread_spin_unlock(pthread_spinlock_t *lock); int pthread_spin_destroy(pthread_spinlock_t *lock);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
* 自旋锁的效果好,但是副作用也大,如果使用不当,自旋锁的持有者迟迟无法释放锁,那么,自旋接近于死循环,会消耗大量的CPU资源,造成CPU使用率飙高。因此,使用自旋锁时,一定要确保临界区尽可能地小,不要有系统调用,不要调用sleep。使用strcpy/memcpy等函数也需要谨慎判断操作内存的大小,以及是否会引起缺页中断。
* 大多数操作系统(Solaris、Mac OS X、FreeBSD)都有类似的接口,如果竞争锁失败,首先与自旋锁一样,持续尝试获取,但过了一定时间仍然不能申请到锁,就放弃尝试,让出CPU并等待。PTHREAD_MUTEX_ADAPTIVE_NP类型的互斥量,采用的就是这种机制,如下:
* ```c
if (LLL_MUTEX_TRYLOCK (mutex) != 0)
{
int cnt = 0;
int max_cnt = MIN (MAX_ADAPTIVE_COUNT,
mutex->__data.__spins * 2 + 10);
do
{
if (cnt++ >= max_cnt)
{
/*自旋也没有等到锁,只能睡去*/
LLL_MUTEX_LOCK (mutex);
break;
}
#ifdef BUSY_WAIT_NOP
BUSY_WAIT_NOP;
#endif
}
while (LLL_MUTEX_TRYLOCK (mutex) != 0);
mutex->__data.__spins += (cnt - mutex->__data.__spins) / 8;
}到底等待多长时间才合适呢?这种互斥量定义了一个名为
__spins的变量,该值和MAX_ADAPTIVE_COUNT共同决定自旋多久。该类型之所以叫自适应(ADAPTIVE),是因为带有反馈机制,它会根据实际情况,智能地调整__spins的值。当然自旋不是无止境的向上增长时,MAX_ADAPTIVE_COUNT决定了上限,即调用BUSY_WAIT_NOP的最大次数。对global_cnt自加1000万次的程序,如果把for循环体内的锁换成自适应互斥锁,会比普通的互斥量更快吗?答案是否定的,在这种时时刻刻要加锁和解锁的激烈竞争下,让其他线程睡去,利用上下文切换的时间间隔,让一个线程飞快地自加,执行时间反而是最短的。但是,真实场景下临界区的争夺不可能激烈到这种程度,如果竞争真的激烈到这种程度,那首先需要反省的是设计问题。在临界区非常小,偶尔发生竞争的情况下,自适应互斥锁的性能要优于普通的互斥锁。
死锁和活锁
对于互斥量而言,可能引起的最大问题就是死锁(dead lock)了。最简单、最好构造的死锁就是下图所示的这种场景了。
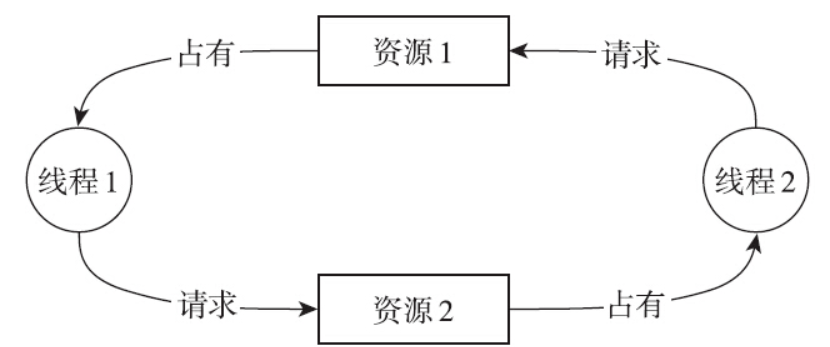
线程1已经成功拿到了互斥量1,正在申请互斥量2,而同时在另一个CPU上,线程2已经拿到了互斥量2,正在申请互斥量1。彼此占有对方正在申请的互斥量,结局就是谁也没办法拿到想要的互斥量,于是死锁就发生了。
上面的例子比较简单,但实际工程中死锁可能会发生在复杂的函数调用之中。可以想象随着程序复杂度的增加,很多死锁并不像上面的例子那样一目了然,
在多线程程序中,如果存在多个互斥量,一定要小心防范死锁的形成。存在多个互斥量的情况下,避免死锁最简单的方法就是总是按照一定的先后顺序申请这些互斥量。还是以刚才的例子为例,如果每个线程都按照先申请互斥量1,再申请互斥量2的顺序执行,死锁就不会发生。有些互斥量有明显的层级关系,但是也有一些互斥量原本就没有特定的层级关系,不过没有关系,可以人为干预,让所有的线程必须遵循同样的顺序来申请互斥量。另一种方法是尝试一下,如果取不到锁就返回。Linux提供了如下接口来表达这种思想:
1 | int pthread_mutex_trylock(pthread_mutex_t *mutex); |
这两个函数反应了这种尝试一下,不行就算了的思想。
对于pthread_mutex_trylock()接口,如果互斥量已然被锁定,那么当即返回EBUSY错误,而不像pthread_mutex_lock()接口一样陷入阻塞。
对于pthread_mutex_timedlock()接口,提供了一个时间参数abs_timeout,如果申请互斥量的时候,互斥量已被锁定,那么等待;如果到了abs_timeout指定的时间,仍然没有申请到互斥量,那么返回ETIMEOUT错误。
除此以外,这两个接口的表现与pthread_mutex_lock是一致的。在实际的应用中,这两个接口使用的频率远低于pthread_mutex_lock函数。
trylock不行就回退的思想有可能会引发活锁(live lock)。生活中也经常遇到两个人迎面走来,双方都想给对方让路,但是让的方向却不协调,反而互相堵住的情况,锁现象与这种场景有点类似。
考虑下面两个线程,线程1首先申请锁mutex_a后,之后尝试申请mutex_b,失败以后,释放mutex_a进入下一轮循环,同时线程2会因为尝试申请mutex_a失败,而释放mutex_b,如果两个线程恰好一直保持这种节奏,就可能在很长的时间内两者都一次次地擦肩而过。当然这毕竟不是死锁,终究会有一个线程同时持有两把锁而结束这种情况。尽管如此,活锁的确会降低性能。这种情况的示例代码如下:
1 | //线程1 |
读写锁
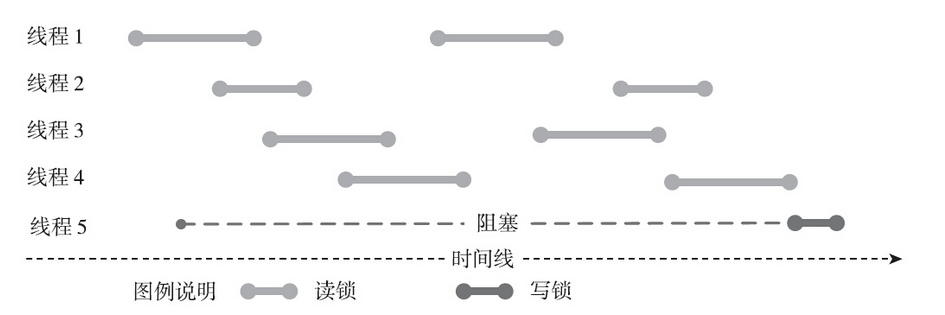
很多时候,对共享变量的访问有以下特点:大多数情况下线程只是读取共享变量的值,并不修改,只有极少数情况下,线程才会真正地修改共享变量的值。对于这种情况,读请求之间是无需同步的,它们之间的并发访问是安全的。然而写请求必须锁住读请求和其他写请求。这种情况在实际中是存在的,比如配置项。大多数时间内,配置是不会发生变化的,偶尔会出现修改配置的情况。如果使用互斥量,完全阻止读请求并发,则会造成性能的损失。出于这种考虑,POSIX引入了读写锁。
读写锁比较简单,从表中可以看出,对于这种情况,读写锁做了优化,允许大家一起读。

读写锁的接口
创建和销毁读写锁
NTPL提供了pthread_rwlock_t类型来表示读写锁。和互斥量一样,它也提供了两种初始化的方法:
1 |
|
对于静态变量,可以采用PTHREAD_RWLOCK_INITIALIZER赋值的方式初始化,对于动态分配的读写锁,或者非默认属性的读写锁,需要用pthread_rwlock_init函数进行初始化。如果第二个属性的参数为NULL,那么采用默认属性。

所谓读者优先的策略,是指当前锁的状态是读锁,如果线程申请读锁,此时纵然有写锁在等待队列上,仍然允许申请者获得读锁,而不是被写锁阻塞。后面会详细讨论读者优先和写者优先对读写锁的影响。对于调用pthread_rwlock_init初始化的读写锁,在不需要读写锁的时候,需要调用pthread_rwlock_destroy销毁,如下:
1 |
|
读写锁的加锁和解锁
读写锁又称共享-独占锁,有共享,也有独占。下面是三个读锁上锁的接口:
1 | int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock); |
而下面三个是写锁上锁的接口:
1 | int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock); |
读锁用于共享模式。如果当前读写锁已经被某线程以读模式占有了,那么其他线程调用pthread_rwlock_rdlock会立刻获得读锁;如果当前读写锁已经被某线程以写模式占有了,那么调用pthread_rwlock_rdlock会陷入阻塞。
写锁用的是独占模式。如果当前读写锁被某线程以写模式占有,则不允许任何读锁请求通过,也不允许任何写锁请求通过,读锁请求和写锁请求都要陷入阻塞,直到线程释放写锁。
无论是读锁还是写锁,锁的释放都是一个接口:
1 | int pthread_rwlock_unlock (pthread_rwlock_t *rwlock); |
无论是读锁还是写锁,都提供了trylock的功能,当不能获得读锁或写锁时,调用线程不会阻塞,而会立即返回,错误码是EBUSY。
无论是读锁还是写锁都提供了限时等待,如果不能获取读写锁,则会陷入阻塞,最多等待到abstime,如果仍然无法获得锁,则返回,错误码是ETIMEOUT。
从表面上看,读写锁介绍到此处就可以打完收工了,其实不然,读写锁是两种类型的锁,当它们都存在时,它们之间的竞争关系如何?如果同时到来一大拨读锁请求和写锁请求,它们之间的响应又有什么特点?事实上,这些是由读写锁的策略决定的。
读写锁的竞争策略
读写锁的属性是pthread_rwlockattr_t类型,属性中有两个部分:lockkind和pshared。所谓lockkind,表示读写锁表现出什么样的行为艺术。对于读写锁,目前有两种策略,一是读者优先,一是写者优先。glibc引入了如下接口来查询和改变读写锁的类型:
1 | int pthread_rwlockattr_getkind_np(const pthread_rwlockattr_t * attr, int * pref); |
其中,读写锁类型的可能值有如下几种:
1 | enum |
前两个都是读者优先的策略,尤其要注意其中的第二个,名字取得很“变态”,名为PREFER_WRITE却干着“挂羊头卖狗肉”的勾当。只有第三个是写者优先的策略。从pthread_rwlock_init函数中可以看出端倪:
1 | rwlock->__data.__flags = iattr->lockkind == PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP; |
可以看到,只有PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP是写者优先,其他一律都是读者优先。读写锁的默认行为是读者优先。
那么,什么是读者优先呢?如果当前锁的状态是读锁,并存在写锁请求被阻塞,那么在写锁后面到来的读锁请求该如何处理就成了问题的关键。如果在写锁请求后面到来的读锁请求不被写锁请求阻塞,就可以立即响应,写锁的下场可能会比较悲惨。如果读锁请求前赴后继源源不断地到来,只要有一个读锁没完成,写锁就没份。这就是所谓的读者优先。这种策略是不公平的,极端情况下,写请求很可能被饿死。这就是多线程中的饥饿(Starvation)现象,即某些线程总是得不到锁资源。
晚于写锁请求到来的读锁请求不排队乱加塞的行为引起了写锁申请者的强烈不满:凭啥仅仅因为当前是读锁,比我晚来的读锁申请者就不用排队,直接响应?鉴于此,glibc又实现了写者优先的策略。所谓写者优先是指,如果当前是读锁,有很多线程在共享读锁,这是允许的,但是一旦线程申请写锁,在写锁请求后面到来的读锁请求就会统统被阻塞,不能先于写请求拿到锁。glibc是如何做到这点的?它引入了下表中的变量。
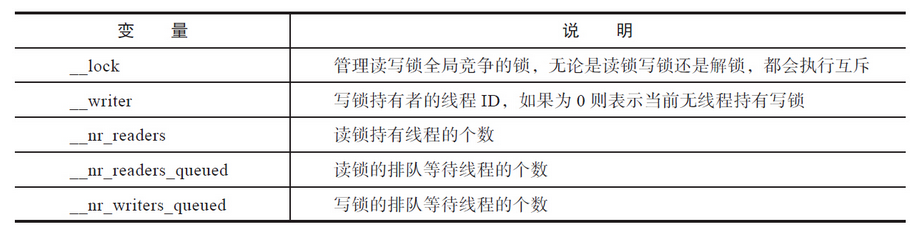
无论是申请读锁还是申请写锁,还是解锁,都至少会做一次全局互斥锁(对应__lock)的加锁和解锁,若不考虑阻塞,单单考虑操作本身的开销,读写锁的加解锁开销是互斥锁的两倍。当然,函数结束前或进入阻塞之前,会将全局的互斥锁释放。下面的讨论先暂时忽略该全局的互斥锁。
对于读锁请求而言,如果:
- 无线程持有写锁,即
__writer==0。 - 采用的是读者优先策略或没有写锁等待者(
__nr_writers_queued=0)。
当满足这两个条件时,读锁请求都可以立刻获得读锁,返回之前执行__nr_readers++,表示多了一个线程占有读锁。
不满足的话,则执行__nr_readers_queued++,表示增加一个读锁等待者,然后调用futex,陷入阻塞。醒来之后,会先执行__nr_readers_queued--,然后再次判断是否同时满足条件1和2。
对于写请求而言,如果:
- 无线程持有写锁,即
__writer==0。 - 没有线程持有读锁,即
__nr_readers==0。
只要满足上述条件,就会立刻拿到写锁,将__writer置为线程的ID(调度域)。如果不满足,那么执行__nr_writers_queued++,表示增加一个写锁等待者线程,然后执行futex陷入等待。醒来后,限制性__nr_writers_queued--,然后重新判断条件1和2。
对于解锁而言,如果当前锁是写锁,则执行如下操作:
(1)执行__writer=0,表示释放写锁。
(2)根据__nr_writers_queued判断有没有写锁等待者,如果有,则唤醒一个写锁等待者。如果没有写锁等待者,则判断有没有读锁等待者;如果有,则将所有的读锁等待者一起唤醒。
如果当前锁是读锁,则执行如下操作:
(1)执行__nr_readers--,表示读锁占有者少了一个。
(2)判断__nr_readers是否等于0,是的话则表示自己是最后一个读锁占有者,需要唤醒写锁等待者或读锁等待者,根据__nr_writers_queued判断是否存在写锁等待者,若有,则唤醒一个写锁等待线程。如果没有写锁等待者,判断是否存在读锁等待者,若有,则唤醒所有的读锁等待者。
通过上面的分析可以看到,如果存在大量的读写请求,竞争非常激烈的条件下,读写锁存在很大的惯性,如果当前锁的状态是读锁状态,在读者优先的策略下,几乎总是读锁请求先得到响应,写锁被阻塞,因此会出现写请求被饿死的情况。解决的方法是设定成写者优先。如果当前锁的状态是写锁,而写锁也源源不断地到来,这时候,读请求就会被饿死。
那么能否实现一款公平的读写锁呢?答案是肯定的。Locklessinc.com中有一篇题为《Sleeping Read-Write Locks》,在分析glibc实现的基础上,给出了一种公平的实现读写锁的方法,测试下来效率很不错。对锁的实现感兴趣的话,可以阅读该文章。
从宏观意义上看,读写锁要比互斥量并发性好,因为读写锁在更多的时间区域内允许并发。
读写锁存在如下的短处。
- 性能:如果临界区比较大,读写锁高并发的优势就会显现出来,但是如果临界区非常小,读写锁的性能短板就会暴露出来。由于读写锁无论是加锁还是解锁,首先都会执行互斥操作,加上读写锁还需要维护当前读者线程的个数、写锁等待线程的个数、读锁等待线程的个数,因此这就决定了读写锁的开销不会小于互斥量。
- 饿死:互斥量虽然不是绝对意义上的公正,但是线程不会饿死。但是如上一小节的讨论,读者优先的策略下,写线程可能会饿死。写者优先的情况下,读线程可能会饿死。
- 死锁:读锁是可重入的,这就可能会引发死锁。考虑如下场景,读写锁采用写者优先的策略,A线程已经持有读锁,B线程申请了写锁,正处于等待状态,而持有读锁的A线程再次申请读锁,就会发生死锁。
比较适合读写锁的场景是:临界区的大小比较可观,绝大多数情况下是读,只有非常少的写。
伪共享
根据局部性原理,存储器是分层的。从距离CPU最近的寄存器到主内存,依次为CPU寄存器、L1 Cache、L2 Cache、L3 Cache和主存。从高层往底层走,存储设备变得更慢,容量更大,单位字节也更便宜。最高层是很少量的寄存器,通常可以在1个时钟周期内访问它们,而接下来的L1 Cache通常可以在4个时钟周期内访问到,L2Cache通常需要10个时钟周期才能访问到,而到了主存,通常需要几百个时钟周期才能访问得到,对这个延迟数据感兴趣的话,可以阅读一下相关文献。在这种分层的存储结构中,对于每一个k,位于k层的更快更小的存储被作为位于k+1层的更大更慢的存储设备的缓存。换句话说更快更小的存储设备的数据来自更慢更大的低一级存储设备。访问的数据在高速缓存中,被称为缓存命中,这种情况下访问速度比较快。如果访问的数据d在k级缓存中不存在,就不得不从k+1级中取出包含d的那个块(block)。如果k级缓存已经满了的话,就可能会覆盖现存的一个块。
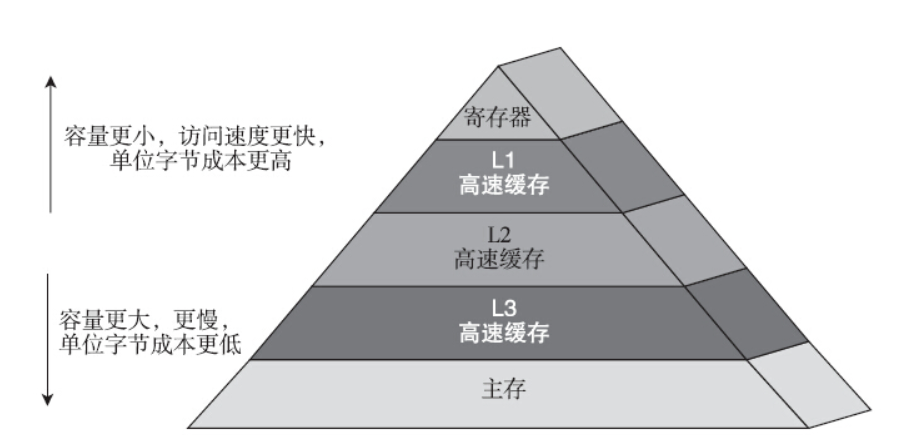
由于高一级缓存的性能远远超过低一级的缓存,所以一旦缓存不命中(Cache miss),对性能的损害就会是比较大的。在典型的多核架构中,每个CPU都有自己的Cache。如果一个内存中的变量在多个CPU Cache中都有副本,则需要保证变量的Cache的一致性。现在大多数的架构实现Cache一致性都是采用MESI协议。
需要注意的是,CPU Cache是以缓存线(Cache line)为单位进行读写的。通常来说,一条缓存线的大小为64字节。换言之,就是访问1字节的数据,系统也会将该字节所在的整条缓存线的数据都搬到缓存中。因为CPU Cache具有以Cache line为单位进行读写的性质,所以在多线程编程中,稍有不慎,就会掉入伪共享的陷阱,造成性能恶化。
1 | int sum1; |
这部分代码定义了两个全局变量sum1和sum2,两个线程分别将计算结果放入各自的全局变量中,看起来并行不悖。但是由于这两个全局变量紧挨着定义,编译器给这两个变量分配的内存几乎总是紧挨着的,因此这两个变量很可能在同一条Cache line中。
尽管线程1所在的CPU并不需要sum2的值,但是由于sum2和sum1在同一条Cache line中,因此sum2的值也随同sum1一并被加载到了thread1所在CPU的Cache中了。
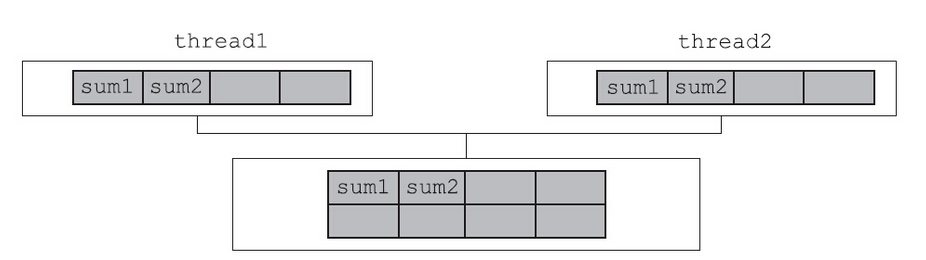
当thread1修改sum1的值时,尽管并未更新sum2的值,但影响的是整条Cache line,它会将thread2所在CPU对应的Cache line置为Invalidate。如果thread2尝试更新sum2,会触发缓存不命中。反过来,thread2修改sum2时,也会影响到sum1的缓存命中。可以想见,就因为两个值彼此毗邻,落在同一条Cache line中,会导致大量的缓存不命中,从而影响性能。
条件等待
条件等待是线程间同步的另一种方法。
线程经常遇到这种情况:要想继续执行,可能要依赖某种条件。如果条件不满足,它能做的事情就是等待,等到条件满足为止。通常条件的达成,很可能取决于另一个线程,比如生产者-消费者模型。当另外一个线程发现条件符合的时候,它会选择一个时机去通知等待在这个条件上的线程。有两种可能性,一种是唤醒一个线程,一种是广播,唤醒其他线程。
线程在条件不满足的情况下,主动让出互斥量,让其他线程去折腾,线程在此处等待,等待条件的满足;一旦条件满足,线程就可以立刻被唤醒。线程之所以可以安心等待,依赖的是其他线程的协作,它确信会有一个线程在发现条件满足以后,将向它发送信号,并且让出互斥量。
条件变量的创建和销毁
NPTL使用pthread_cond_t类型的变量来表示条件变量。条件变量不是一个值,我们无法给条件变量赋值。一个线程如果要等待某个事件的发生,或者某个条件的满足,那么这个线程需要的是条件变量:线程等待在条件变量上。
和互斥锁一样,条件变量在使用之前要先初始化。互斥锁有静态初始化,条件变量也一样。简单地把PTHREAD_COND_INITIALIZER赋值给pthread_cond_t类型的变量就可完成条件变量的初始化:
1 | pthread_cond_t cond = PTHREAD_COND_INITIALIZER; |
动态分配条件变量,或者对条件变量的属性有所定制,都需要用pthread_cond_init进行初始化,如果采用默认属性,可以将NULL作为第二个参数:
1 | int pthread_cond_init(pthread_cond_t *cond, const pthread_condattr_t *attr); |
对于pthread_cond_init初始化的条件变量,不要忘记调用pthread_cond_destroy来销毁。其接口定义如下:
1 | int pthread_cond_destroy(pthread_cond_t *cond); |
对于条件变量的初始化和销毁,需要注意以下几点:
- 永远不要用一个条件变量对另一个条件变量赋值,即
pthread_cond_t cond_b=cond_a不合法,这种行为是未定义的。 - 使用
PTHREAD_COND_INITIALIZE静态初始化的条件变量,不需要被销毁。 - 要调用
pthread_cond_destroy销毁的条件变量可以调用pthread_cond_init重新进行初始化。 - 不要引用已经销毁的条件变量,这种行为是未定义的。
条件变量的使用
条件变量,天生就是与条件的满足与否相伴而生的。通常,线程会对一个条件进行测试,如果条件不满足,就等待(pthread_cond_wait),或者等待一段有限的时间(pthread_cond_timedwait)。相关函数的定义如下:
1 | int pthread_cond_wait(pthread_cond_t *restrict cond, |
条件等待是线程间同步的一种手段,如果只有一个线程,条件不满足,那么等待千年也是枉然,所以必须要有一个线程通过某些操作,改变共享数据,使原先不满足的条件变得满足了,并且友好地通知等待在条件变量上的线程。条件不会无缘无故地突然变得满足了,必然会牵扯到共享数据的变化。所以一定要有互斥锁来保护。没有互斥锁,就无法安全地获取和修改共享数据。
下面的伪代码显示了POSIX如何使用条件变量v和互斥量m来等待条件的发生:
1 | pthread_mutex_lock(&m); |
pthread_cond_wait函数只能由拥有互斥量的线程来调用,当该函数返回的时候,系统会确保该线程再次持有互斥量,所以这个接口容易给人一种误解,就是该线程一直在持有互斥量。事实上并不是这样的。这个接口向系统声明了我在等待之后,就把互斥量给释放了。这样其他线程就有机会持有互斥量,操作共享数据,触发变化,使线程等待的条件得到满足。
pthread_cond_timedwait函数与pthread_cond_wait的工作方式几乎是一样的,只是调用时需要指定一个超时的时间。注意这个时间是绝对时间,而不是相对时间。如果最多等待2分钟,那么这个值应该是当前时间加上2分钟。
上面将互斥量和条件变量配合使用的示范代码中有个很有意思的地方,就是用了while语句,醒来之后要再次判断条件是否满足。
唤醒以后,再次检查条件是否满足,是不是多此一举?答案是不得不如此。因为唤醒中存在虚假唤醒(spurious wakeup),换言之,条件尚未满足,pthread_cond_wait就返回了。在一些实现中,即使没有其他线程向条件变量发送信号,等待此条件变量的线程也有可能会醒来。看起来这像是个bug,但它是实实在在存在的。为什么会存在虚假唤醒?一个原因是pthread_cond_wait是futex系统调用,属于阻塞型的系统调用,当系统调用被信号中断的时候,会返回-1,并且把errno置为EINTR。很多这种系统调用为了防止被信号中断都会重启系统调用,代码如下:
1 | pid_t r_wait(int *stat_loc) |
但是futex不一样,在futex返回之后,到重启系统调用之前,可能已经调用过pthread_cond_signal或pthread_cond_broadcast。一旦错失,再次调用pthread_cond_wait可能就会导致无限制地等待下去。为了防止这种情况,宁可虚假唤醒,也不能再次调用pthread_cond_wait,以免陷入无穷的等待中。
除了上面的信号因素外,还存在以下情况:条件满足了发送信号,但等到调用pthread_cond_wait的线程得到CPU资源时,条件又再次不满足了。好在无论是哪种情况,醒来之后再次测试条件是否满足就可以解决虚假等待的问题。
条件等待,等于把控制权交给了别的线程,它信任别的线程会在合适的时机通知它,这是多大的信任啊。如果其他线程忘记发送信号了,那么条件等待的线程就彻底“悲剧”了。如何发送信号来通知等待的线程呢?POSIX提供了如下两个接口:
1 | int pthread_cond_signal(pthread_cond_t *cond); |
pthread_cond_signal负责唤醒等待在条件变量上的一个线程,pthread_cond_broadcast,顾名思义,就是广播唤醒等待在条件变量上的所有线程。等一下,刚才讲解pthread_cond_wait的时候曾提到过,线程醒来时会确保持有互斥量,为何广播还能唤醒等待在条件变量上的所有线程呢,不是前后矛盾吗?答案是不矛盾,所有的线程被广播唤醒了之后,集体争夺互斥锁,没抢到的继续睡。从内核中醒来,然后继续睡去,是一种性能的浪费。使用通知机制来完成线程同步,代码范例如下:
1 | //为让流程更加清晰,此处忽略了error handle |
发送信号,通知等待在条件上的线程,然后解锁互斥量。注意范例代码中先发送信号,然后解锁互斥量,这个顺序不是必须的,也可以颠倒。标准允许任意顺序执行这两个调用。有什么区别吗?先通知条件变量、后解锁互斥量,效率会比先解锁、后通知条件变量低。因为先通知后解锁,执行pthread_cond_wait的线程可能在互斥量已然处于加锁状态的时候醒来,发现互斥量仍然没有解锁,就会再次休眠,从而导致了多余的上下文切换。某些实现使用等待变形(wait morphing)来优化这个问题:并不真正地唤醒执行pthread_cond_wait的线程,而是将线程从条件变量的等待队列转移到互斥量的等待队列上,从而消除无谓的上下文切换。
glibc对pthread_cond_broadcast做了类似的优化,即只唤醒一个线程,将其他线程从条件变量的等待队列搬移到了互斥量的等待队列中。
先解锁、后通知条件变量虽然可能会有性能上的优势,但是也会带来其他的问题。如果存在一个高优先级的线程,既等待在互斥量上,也等待在条件变量上;同时还存在一个低优先级的线程,只等待在互斥量上。一旦先解锁互斥量,低优先级的进程就可能会抢先获得互斥量,待调用pthread_cond_signal之后,高优先级的进程会发现互斥量已经被低优先级的进程抢走了。
线程取消
线程可以通过调用pthread_cancel函数来请求取消同一进程中的其他线程。从编程的角度来讲,不建议使用这个接口。笔者对该接口的评价不高,该接口实现了一个似是而非的功能,却引入了一堆问题。
Linux提供了如下函数来控制线程的取消:
1 | int pthread_cancel(pthread_t thread); |
一个线程可以通过调用该函数向另一个线程发送取消请求。这不是个阻塞型接口,发出请求后,函数就立刻返回了,而不会等待目标线程退出之后才返回。如果成功,该函数返回0,否则将错误码返回。对于glibc实现而言,调用pthread_cancel时,会向目标线程发送一个SIGCANCEL的信号,该信号就是被NPTL征用的32号信号。线程收到取消请求后,会采取什么行动呢?这取决于该线程的设定。NPTL提供了函数来设置线程是否允许取消,以及在允许取消的情况下,如何取消。pthread_setcancelstate函数用来设置线程是否允许取消,函数定义如下:
1 | int pthread_setcancelstate(int state, int *oldstate); |
取消类型有两种值:
- PTHREAD_CANCEL_DEFERRED
- PTHREAD_CANCEL_ASYNCHRONOUS
PTHREAD_CANCEL_ASYNCHRONOUS为异步取消,即线程可能在任何时间点(可能是立即取消,但也不一定)取消线程。这种取消方式的最大问题在于,你不知道取消时线程执行到了哪一步。所以,这种取消方式太粗暴,很容易造成后续的混乱。因此不建议使用该取消方式。PTHREAD_CANCEL_DEFERRED是延迟取消,线程会一直执行,直到遇到一个取消点,这种方式也是新建线程的默认取消类型。
什么是取消点?就是对于某些函数,如果线程允许取消且取消类型是延迟取消,并且线程也收到了取消请求,那么当执行到这些函数的时候,线程就可以退出了。标准规定了很多函数必须是取消点,由于太多(有好几十个之多),就不一一罗列了,通过man pthreads可以查询到这些取消点函数。
线程执行到取消点,会自动处理取消请求,但是如果线程没有用到任何取消点函数,那该怎么办,如何响应取消请求?为了应对这种场景,系统引入了pthread_testcancel函数,该函数一定是取消点。所以编程者可以周期性地调用该函数,只要有取消请求,线程就能响应。该函数定义如下:
1 | void pthread_testcancel(void); |
如果线程被取消,并且其分离状态是可连接的,那么需要由其他线程对其进行连接。连接之后,pthread_join函数的第二个参数会被置成PTHREAD_CANCELED,通过该值可以知道线程并不是“寿终正寝”,而是被其他线程取消而导致的退出。
接口都介绍完了,是时候讨论下线程取消的弊端了。线程取消是一种在线程的外部强行终止线程的执行做法,由于无法预知目标线程内部的情况,尤其是第一种异步取消类型,因此可能会带来毁灭性的结果。目标线程可能会持有互斥量、信号量或其他类型的锁,这时候如果收到取消请求,并且取消类型是异步取消,那么可能目标线程掌握的资源还没有来得及释放就被迫退出了,这可能会给其他线程带来不可恢复的后果,比如死锁(其他线程再也无法获得资源)。即使执行异步取消也安然无恙的函数称为异步取消安全函数(async-cancel-safe function),手册里说只有下述三个函数是异步取消安全函数,所以对于其他函数,一律都不是异步取消安全函数。
1 | pthread_cancel() |
所以对编程人员而言,应该遵循以下原则:
- 第一,轻易不要调用pthread_cancel函数,在外部杀死线程是很糟糕的做法,毕竟如果想通知目标线程退出,还可以采取其他方法。
- 第二,如果不得不允许线程取消,那么在某些非常关键不容有失的代码区域,暂时将线程设置成不可取消状态,退出关键区域之后,再恢复成可以取消的状态。
- 第三,在非关键的区域,也要将线程设置成延迟取消,永远不要设置成异步取消。
假设遇到取消请求,线程执行到了取消点,却没有来得及做清理动作(如动态申请的内存没有释放,申请的互斥量没有解锁等),可能会导致错误的产生,比如死锁,甚至是进程崩溃。
为了避免这种情况,线程可以设置一个或多个清理函数,线程取消或退出时,会自动执行这些清理函数,以确保资源处于一致的状态。其相关接口定义如下:
1 | void pthread_cleanup_push(void (*routine)(void *),void *arg); |
标准允许用宏(macro)来实现这两个接口,Linux就是用宏来实现的。这意味着这两个函数必须同时出现,并且属于同一个语法块。
其中pthread_cleanup_pop的用处是,删除注册的清理函数。如果参数是非0值,那么执行一次,再删除清理函数。否则的话,就直接删除清理函数。
第三个问题最关键,何时会触发注册的清理函数:
- 当线程的主函数是调用pthread_exit返回的,清理函数总是会被执行。
- 当线程是被其他线程调用pthread_cancel取消的,清理函数总是会被执行。
- 当线程的主函数是通过return返回的,并且
pthread_cleanup_pop的唯一参数execute是0时,清理函数不会被执行。 - 当线程的主函数是通过return返回的,并且
pthread_cleanup_pop的唯一参数execute是非零值时,清理函数会执行一次。
线程局部存储
使用线程局部存储(Thread Local Storage)技术能为每一个线程都分别维护一个变量的副本,尽管名字相同却分别存储,并行不悖。在Linux下有两种方法可以实现线程局部存储:
- 使用NPTL提供的函数。
- 使用编译器扩展的
__thread关键字。
NPTL库
1 | int pthread_key_create(pthread_key_t *key,void (*destructor)(void*)); |
pthread_key_create函数会为线程局部存储创建一个新键,并通过给key赋值,返回给用户使用。因为进程中的所有线程都可以使用返回的键,所以参数key应该指向一个全局变量。参数destructor指向一个自定义的函数:
1 | void * destructor(void *value) |
线程终止时,如果key关联的值不是NULL,那么NTPL会自动执行定义的destructor函数。如果无须解构,可以将destructor设置为NULL。
1 |
|
记录槽位分配情况的数据结构pthread_keys是进程唯一的。对于上面的示例代码而言,第一次调用pthread_key_create毫无疑问会领到slot 0。即thread_log_key的值为0,表示占用了0号槽位.
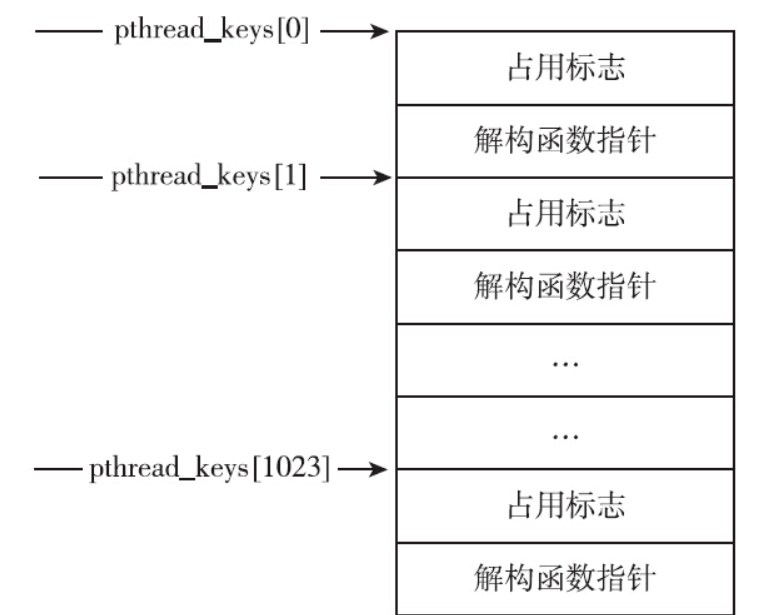
目前,各个线程还没有数据和该key相关联。接下来线程函数通过调用pthread_setspecific函数,将key分别与各自的线程数据关联起来。
1 | pthread_setspecific(thread_log_key,thread_log); |
每个线程槽位号0各自指向了线程自己的数据。从此处开始分家,key是同一个key,但每个线程指向的数据各不相同.
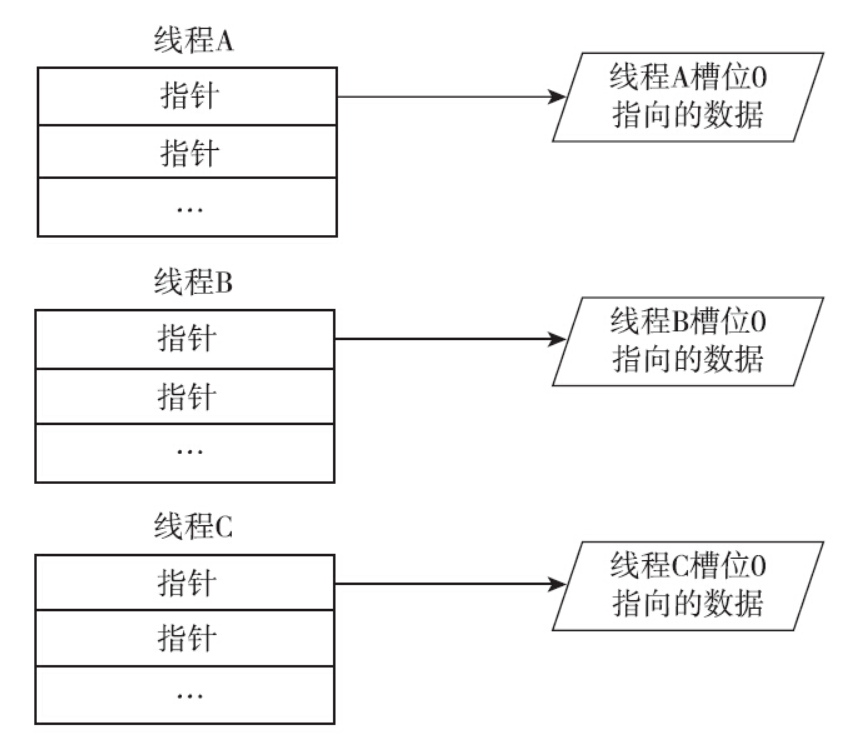
线程如果想要使用各自的值怎么办?拿这个key,去找到与key关联的数据结构,这是pthread_getspecific函数的职责所在。
因为线程知道key关联的数据结构是什么类型,所以可以从key直接获取到key指向的value。取到线程的特有数据之后,就可以操作了。由于key属于全局变量,因此取到的线程特有数据value就变成了线程内部的“全局变量”。1024个key,对于普通的应用来说足够了。如果一个多线程应用确实需要很多的线程特有数据,那么可以将其封装在一个数据结构之内。这种方法,允许的键值个数有限并不是问题的关键,问题的关键是它的接口太难用了,接口设计得有点反人类。
__thread关键字
由于NPTL提供的接口太难用,有人想到了在编译器中增加新功能,支持特定的关键字__thread,隐式地构造线程局部变量。它的使用方法非常简单:
1 | __thread int val = 0; |
凡是带有__thread关键字的变量,每个线程都会有该变量的一个拷贝,并行不悖,互不干扰。该局部变量一直都在,直到线程退出为止。使用线程局部变量需要注意以下几点:
- 如果变量生命中使用了关键字static或extern,那么关键字
__thread应该紧随其后。 - 声明时,可以正常初始化。
- 可以通过取地址操作符(&)获取到线程局部变量的地址。
1 |
|
线程和信号
信号出现地要比线程早,所以设计信号时,尚没有线程。在引入线程之后,如何设计信号成了一个难点。既要保证传统的语义不变,又要设计出适用于多线程环境的信号模型,确实难度不小。
- 信号处理函数是进程层面的概念,或者说是线程组层面的概念,线程组内所有线程共享对信号的处理函数。
- 对于发送给进程的信号,内核会任选一个线程来执行信号处理函数,执行完后,会将其从挂起信号队列中去除,其他进程不会对一个信号重复响应。
- 可以针对进程中的某个线程发送信号,那么只有该线程能响应,执行相应的信号处理函数。
- 信号掩码是线程层面的概念,信号处理函数在线程组内是统一的,但是信号掩码是各自独立可配置的,各个线程独立配置自己要阻止或放行的信号集合。
- 挂起信号(内核已经收到,但尚未递送给线程处理的信号)既是针对进程的,又是针对线程的。内核维护两个挂起信号队列,一个是进程共享的挂起信号队列,一个是线程特有的挂起信号队列。调用函数sigpending返回的是两者的并集。对于线程而言,优先递送发给线程自身的信号。
上面这些内容,基本概括了多线程条件下信号的模型。内核如何做到这些模型,在信号篇中基本都有介绍,在此处就不再赘述了。
设置线程的信号掩码
前面已提到过,信号掩码是针对线程的,每个线程都可以自行设置自己的信号掩码。如果自己不设置,就会继承创建者的信号掩码。NPTL实现了如下接口来设置线程的信号掩码:
1 |
|
how 的值用来指定如何更改信号组:
SIG_BLOCK向当前信号掩码中添加new,其中new表示要阻塞的信号组。SIG_UNBLOCK从当前信号掩码中删除new,其中new表示要取消阻塞的信号组。SIG_SETMASK将当前信号掩码替换为new,其中new表示新的信号掩码。
该接口的使用方式和sigprocmask一模一样,在Linux上,两个函数的实现是相同的。
IGCANCEL和SIGSETXID信号被用于NPTL实现,因此用户不能也不应该改变这两个信号的行为方式。好在用户不用操心这两个信号,sigprocmask函数和pthread_sigmask函数对这两者都做了特殊处理。
向线程发送信号
之前提到过向线程发送信号的系统调用tkill/tgkill,无奈glibc并未将它们封装成可以直接调用的函数。不过,幸好提供了另外一个函数:
1 | int pthread_kill(pthread_t thread, int sig); |
由于pthread_t类型的线程ID只在线程组内是唯一的,其他进程完全可能存在线程ID相同的线程,所以pthread_kill只能向同一个进程的线程发送信号。除了这个接口外,Linux还提供了特有的函数将pthread_kill和sigqueue功能累加在一起:
1 |
|
这个接口和sigqueue一样,可以发送携带数据的信号。当然,只能发给同一个进程内的线程。
多线程程序对信号的处理
单线程的程序,对信号的处理已经比较复杂了。因为信号打断了进程的控制流,所以信号处理函数只能调用异步信号安全的函数。而异步信号安全是个很苛刻的条件。多线程的引入,加剧了这种复杂度。因为信号可以发送给进程,也可以发送给进程内的某一线程。不同线程还可以设置自己的掩码来实现对信号的屏蔽。而且,没有一个线程相关的函数是异步信号安全的,信号处理函数不能调用任何pthread函数,也不能通过条件变量来通知其他线程。
在多线程程序中,使用信号的第一原则就是不要使用信号。
在多线程程序中,使用信号的第一原则就是不要使用信号。
在多线程程序中,使用信号的第一原则就是不要使用信号。
- 不要主动使用信号作为进程间通信的手段,收益和引入的风险完全不成比例。
- 不主动改变异常处理信号的信号处理函数。用于管道和
socket的SIGPIPE可能是例外,默认语义是终止进程,很多情况下,需要忽略该信号。 - 如果无法避免,必须要处理信号,那么就采用
sigwaitinfo或signalfd的方式同步处理信号,减少异步处理带来的风险和引入bug的可能。
多线程与fork
多线程和fork函数的协作性非常差。对于多线程和fork,最重要的建议就是:
永远不要在多线程程序里面调用fork。
永远不要在多线程程序里面调用fork。
永远不要在多线程程序里面调用fork。
Linux的fork函数,会复制一个进程,对于多线程程序而言,fork函数复制的是调用fork的那个线程,而并不复制其他的线程。fork之后其他线程都不见了。Linux不存在forkall语义的系统调用,无法做到将多线程全部复制。多线程程序在fork之前,其他线程可能正持有互斥量处理临界区的代码。fork之后,其他线程都不见了,那么互斥量的值可能处于不可用的状态,也不会有其他线程来将互斥量解锁。
1 |
|
上面的代码比较简单,创建了一个线程周期性地执行setenv函数,修改环境变量。主线程会fork子进程,子进程负责执行unsetenv函数,同时调用了alarm,一秒钟后会收到SIGALRM信号。子进程通过执行signal函数,注册了SIGALRM信号的处理函数,即向标准错误打印字母a。fork创建的子进程在调用alarm注册的闹钟之后,只执行unsetenv函数,然后就会调用exit退出。因此,在正常情况下子进程很快就会退出,alarm约定的1秒钟时间还未到就退出了。也就是说,信号处理函数不应该被执行,自然也就不应该打印出字母a。
实际上:
1 | ./thread_fork |
原因何在?在某些情况下,子进程为什么不能及时退出,以至于过了1秒之后,子进程还没有退出?选择一个阻塞的线程,用gdb调试下,看看到底阻塞在何处。
1 | (gdb) bt |
现在的库函数,为了做到可重入,其内部维护的变量通常会使用互斥量来保护。这些锁对用户一般是透明的,用户也不关心。setenv和unsetenv就是这样。尽管上述代码并没有显式地定义,但是进程内部已经维护了一个互斥量。互斥量中维护了一个锁的值:0表示未上锁,1表示已上锁但是没有等待线程,2表示已上锁,并且有线程等待该锁。
对于我们的例子而言,由于线程每100微秒就执行一次setenv,很有可能在主线程调用fork创建子进程的瞬间,互斥量的值是1。而这个值1被拷贝到了子进程。对于父进程而言互斥量的值是1自然没有关系,因为父进程中有线程worker不停地加锁、解锁。但是子进程的情况就不同了,子进程中没有worker。子进程自创建成功开始,setenv相关的互斥量的值就一直是1。子进程调用unsetenv函数时,“地雷”被引爆了。unsetenv无法获得互斥量,反而是通过调用futex系统调用陷入休眠,内核将其挂入对应的等待队列。父进程的worker线程的解锁操作会唤醒子进程吗?下面是内核get_futex_key函数中的部分代码:
1 | if (!fshared) { |
新建立的futex使用mm结构指针和地址address作为futex的键值,由于父子进程之间并不共享mm_struct,也就是说子进程的futex和父进程futex并不共享等待队列。换句话说,父进程通过setenv解锁时,根本就不会唤醒子进程。因此,子进程永远都不可能被唤醒了。这仅仅是setenv/unsetenv函数,库函数中类似这种的函数并不少见:
- malloc函数的内部实现一定会有锁。
- printf系列的函数,其他线程可能持有stdout/stderr的锁。
- syslog函数内部实现也会用到锁。
综合上面的讨论,唯一安全的做法是,fork之后子进程立即调用exec执行另外的程序,彻底断绝子进程与父进程之间的关系,注意是立即,不要在调用exec之前执行任何语句,哪怕是不起眼的printf。
标准库
相关结构体
pthread_attr_t 结构体
pthread_attr_t 是POSIX线程库中定义的一个结构体类型,用于设置和获取线程属性。通过这类属性,可以控制线程的行为和特性,比如栈大小、调度策略等。
常用的线程属性功能
pthread_attr_t 结构体的具体定义通常是隐藏的,它通过API来进行交互。在使用线程属性时,涉及到以下一些常用的函数:
初始化和销毁属性对象
pthread_attr_init(pthread_attr_t *attr): 初始化线程属性对象,设置为默认值。pthread_attr_destroy(pthread_attr_t *attr): 释放线程属性对象。
设置和获取线程栈大小
pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize): 设置线程的栈大小。pthread_attr_getstacksize(pthread_attr_t *attr, size_t *stacksize): 获取线程的栈大小。
设置和获取线程调度策略
pthread_attr_setschedpolicy(pthread_attr_t *attr, int policy): 设置线程的调度策略(如SCHED_FIFO,SCHED_RR,SCHED_OTHER)。pthread_attr_getschedpolicy(pthread_attr_t *attr, int *policy): 获取线程的调度策略。
设置和获取调度参数
pthread_attr_setschedparam(pthread_attr_t *attr, const struct sched_param *param): 设置线程的调度参数,通常用于设置优先级。pthread_attr_getschedparam(pthread_attr_t *attr, struct sched_param *param): 获取线程的调度参数。
设置和获取线程是否为可加入
pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate): 设置线程的可加入状态(PTHREAD_CREATE_JOINABLE,PTHREAD_CREATE_DETACHED)。pthread_attr_getdetachstate(pthread_attr_t *attr, int *detachstate): 获取线程的可加入状态。
设置和获取继承调度属性
pthread_attr_setinheritsched(pthread_attr_t *attr, int inheritsched): 设置调度属性继承方式。pthread_attr_getinheritsched(pthread_attr_t *attr, int *inheritsched): 获取调度属性继承方式。
使用示例
下面是一个简单示例,演示如何设置线程的栈大小:
1 |
|
通过上述API与pthread_attr_t结构体互动,我们可以灵活管理线程的各种属性以适应不同应用场景。
pthread_spinlock_t 结构体
pthread_spinlock_t 是 POSIX 线程库中用于实现自旋锁的结构体。自旋锁是一种简单的锁机制,用于在多处理器系统中实现线程同步。与互斥锁不同,自旋锁在等待锁释放时不会使线程进入休眠状态,而是不断地检查锁的状态(即“自旋”),直到获得锁或满足其他条件。
自旋锁的特性
- 忙等待: 自旋锁在等待锁释放时会一直占用 CPU 资源进行循环检查,因此适合用于锁持有时间非常短的场景。
- 低开销: 由于不涉及线程调度和上下文切换,自旋锁的开销较低。
- 适用场景: 适用于多处理器系统中短时间的锁定操作,不适合单处理器系统或长时间的锁定操作,因为会导致 CPU 资源浪费。
pthread_spinlock_t 通常是一个简单的整数或指针类型,用于表示锁的状态。具体实现可能因平台和编译器而异,但通常它是一个原子类型,以便在多线程环境中安全地进行操作。
使用自旋锁的函数
POSIX 线程库提供了一组函数用于操作自旋锁:
初始化和销毁:
int pthread_spin_init(pthread_spinlock_t *lock, int pshared);- 初始化自旋锁。
pshared参数指定锁是否在进程间共享,通常为PTHREAD_PROCESS_PRIVATE。
int pthread_spin_destroy(pthread_spinlock_t *lock);- 销毁自旋锁。
锁定和解锁:
int pthread_spin_lock(pthread_spinlock_t *lock);- 获取自旋锁。如果锁已经被持有,调用线程将一直自旋等待。
int pthread_spin_trylock(pthread_spinlock_t *lock);- 尝试获取自旋锁。如果锁已经被持有,立即返回而不自旋。
int pthread_spin_unlock(pthread_spinlock_t *lock);- 释放自旋锁。
使用示例
下面是一个简单的示例,演示如何使用自旋锁进行线程同步:
1 |
|
注意事项
- 忙等待的代价: 自旋锁在等待时会消耗 CPU 资源,因此在锁持有时间较长时可能导致性能下降。
- 适用场景: 自旋锁适用于多处理器系统中短时间的锁定操作,不适合单处理器系统或长时间的锁定操作。
- 正确初始化和销毁: 确保在使用自旋锁之前正确初始化,并在不再需要时销毁以释放资源。
通过合理使用 pthread_spinlock_t,可以在合适的场景中实现高效的线程同步。
pthread_rwlock_t 结构体
pthread_rwlock_t 是 POSIX 线程库中用于实现读写锁的结构体。读写锁允许多个线程同时读取共享资源,但在写入时,只有一个线程可以进行操作。这种机制提高了对共享资源的并发访问效率,特别是在读操作远多于写操作的场景中。
读写锁的基本概念
- 读锁(共享锁): 多个线程可以同时持有读锁,只要没有线程持有写锁。
- 写锁(独占锁): 当一个线程持有写锁时,其他线程不能持有读锁或写锁。
pthread_rwlock_t 是一个不透明的数据类型,其具体实现是由系统库提供的。用户不需要关心其内部结构,只需通过提供的 API 进行操作。
相关函数
以下是与 pthread_rwlock_t 相关的主要函数:
初始化和销毁
初始化:
pthread_rwlock_init: 初始化读写锁。1
int pthread_rwlock_init(pthread_rwlock_t *rwlock, const pthread_rwlockattr_t *attr);
参数:
rwlock: 指向读写锁对象的指针。attr: 指向读写锁属性对象的指针,通常为NULL表示使用默认属性。
销毁:
pthread_rwlock_destroy: 销毁读写锁。1
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
参数:
rwlock: 指向读写锁对象的指针。
加锁和解锁
读锁:
pthread_rwlock_rdlock: 获取读锁。1
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
pthread_rwlock_tryrdlock: 尝试获取读锁(非阻塞)。1
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
写锁:
pthread_rwlock_wrlock: 获取写锁。1
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
pthread_rwlock_trywrlock: 尝试获取写锁(非阻塞)。1
int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);
解锁:
pthread_rwlock_unlock: 释放读锁或写锁。1
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
使用示例
以下是一个简单的示例,演示如何使用读写锁:
1 |
|
注意事项
- 初始化后使用: 在使用读写锁之前,必须先初始化。
- 正确解锁: 确保在持有锁的线程完成操作后,正确地释放锁。
- 避免死锁: 小心避免死锁,特别是在多个锁交替使用的情况下。
- 性能考虑: 读写锁在读操作多于写操作时可以提高性能,但在写操作频繁的情况下,可能会导致写线程饥饿。
pthread_cond_t 结构体
pthread_cond_t 是 POSIX 线程库中用于条件变量的结构体。条件变量提供了一种线程间的同步机制,允许线程在等待某个条件满足时进入睡眠状态,并在条件满足时被唤醒。条件变量通常与互斥锁结合使用,以确保对共享资源的安全访问。
pthread_cond_t 是一个用于条件变量的结构体类型。它的具体实现细节在不同的操作系统和库版本中可能有所不同,因此通常不直接访问其内部成员,而是通过提供的 API 函数进行操作。
相关函数
以下是与 pthread_cond_t 相关的一些主要函数:
初始化和销毁
pthread_cond_init: 初始化条件变量。
1
int pthread_cond_init(pthread_cond_t *cond, const pthread_condattr_t *attr);
cond: 指向条件变量的指针。attr: 指向条件变量属性的指针,通常为NULL使用默认属性。
pthread_cond_destroy: 销毁条件变量。
1
int pthread_cond_destroy(pthread_cond_t *cond);
cond: 指向要销毁的条件变量的指针。
等待和唤醒
pthread_cond_wait: 使线程等待条件变量。
1
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
cond: 指向条件变量的指针。mutex: 指向互斥锁的指针。调用此函数时,互斥锁必须已被锁定。函数会自动释放锁并等待条件变量,条件满足时重新锁定互斥锁。
pthread_cond_timedwait: 使线程等待条件变量,带有超时功能。
1
int pthread_cond_timedwait(pthread_cond_t *cond, pthread_mutex_t *mutex, const struct timespec *abstime);
abstime: 指定绝对时间的timespec结构体,超时后函数返回。
pthread_cond_signal: 唤醒一个等待条件变量的线程。
1
int pthread_cond_signal(pthread_cond_t *cond);
cond: 指向条件变量的指针。
pthread_cond_broadcast: 唤醒所有等待条件变量的线程。
1
int pthread_cond_broadcast(pthread_cond_t *cond);
cond: 指向条件变量的指针。
使用示例
条件变量通常与互斥锁结合使用,以确保对共享资源的安全访问。以下是一个简单的示例:
1 |
|
注意事项
- 互斥锁配合使用: 在等待条件变量时,必须持有相关的互斥锁,以防止竞争条件。
- 避免虚假唤醒:
pthread_cond_wait可能会出现虚假唤醒,因此通常在循环中检查条件。 - 资源管理: 确保在程序结束时正确销毁条件变量和互斥锁,以避免资源泄漏。
pthread_key_t 类型
pthread_key_t 是用于线程特定数据(Thread-Specific Data, TSD)的键类型。是一个类型定义,用于标识线程特定数据的键。每个线程都有自己独立的线程特定数据副本,这些数据可以通过键来访问。
线程特定数据概述
线程特定数据允许每个线程拥有自己的数据副本,而不需要显式地将数据传递给每个函数。这在需要线程本地存储的情况下非常有用,例如在多线程环境中使用全局变量的替代方案。
相关函数
以下是与 pthread_key_t 相关的主要函数:
pthread_key_create
用于创建一个新的线程特定数据键。
1 |
|
key: 指向pthread_key_t类型的指针,用于存储创建的键。destructor: 可选的析构函数指针,当线程退出时用于清理线程特定数据。如果不需要,可以传递NULL。
pthread_key_delete
用于删除一个线程特定数据键。
1 |
|
key: 要删除的键。
pthread_setspecific
用于为当前线程设置与键关联的线程特定数据。
1 |
|
key: 线程特定数据的键。value: 要与键关联的值。
pthread_getspecific
用于获取当前线程与键关联的线程特定数据。
1 |
|
key: 线程特定数据的键。
示例
以下是一个简单的示例,演示如何使用线程特定数据:
1 |
|
注意事项
- 析构函数: 如果为
pthread_key_create提供了析构函数,当线程退出时,系统会自动调用该函数来清理线程特定数据。 - 内存管理: 线程特定数据的内存管理由程序员负责,确保在适当的时候释放内存。
- 性能: 使用线程特定数据可能会有一定的性能开销,尤其是在频繁访问的情况下,因此应根据具体需求合理使用。
线程相关API
gettid
gettid 函数用于获取调用线程的线程ID(Thread ID)。线程ID在Linux系统中用来标识一个线程,通常在多线程应用程序中使用。
函数原型
1 |
|
参数
gettid不接受任何参数。
返回值
- 返回调用线程的线程ID。
- 在错误的情况下,通常不返回任何错误值。
注意事项
gettid并不是POSIX标准的一部分,而是Linux特有的系统调用。在某些系统上,可能需要通过syscall来调用。
使用示例
1 |
|
特性
- 线程标识:
gettid返回的线程ID是全局唯一的,类似于进程ID(PID),但其与线程的生命周期密切相关。 - 区别于
pthread_self: 与pthread_self返回的线程标识符不同,gettid提供的是内核级的线程ID。使用POSIX线程库时通常用pthread_self,因为gettid在移植性和可读性上可能不如POSIX函数。 - 系统相关性: 因为
gettid是一个系统调用,在不同的Unix或类Unix操作系统上可能存在差异,因此在需要跨平台的场景下,应谨慎使用这一函数。
pthread_create
pthread_create 函数用于创建一个新的线程,并执行指定的函数。它是POSIX线程(pthreads)库的一部分,主要用于实现多线程并发程序。
函数原型
1 |
|
参数
thread: 一个指向pthread_t类型的指针,用于输出新创建线程的标识符。attr: 一个指向pthread_attr_t的指针,用于设置线程的属性。如果使用默认属性,传递NULL。start_routine: 线程要运行的函数,该函数的签名必须是void *function(void *)类型。arg: 传递给start_routine的参数。如果不需要传参,可以传递NULL。
返回值
- 成功时,返回 0。
- 失败时,返回错误号码(errno)。
使用示例
1 |
|
特性
并发执行:
pthread_create启动的线程与调用线程并发执行,可以利用多核以及处理器的多线程能力提高程序性能。可选属性: 可以通过
attr设置线程的各种属性,如栈大小、调度策略等;使用NULL默认属性。线程同步: 通常与
pthread_join配合使用,确保主线程等待子线程完成。强制转换: 如果在 C++ 中使用,应对
start_routine函数进行extern "C"声明,避免名字修饰导致的链接错误。
pthread_exit
pthread_exit 函数用于终止调用它的线程并返回一个退出状态给已经加入此线程的线程。
函数原型
1 |
|
参数
retval: 是一个指向任意类型的指针,用于返回线程的退出状态或结果信息。
使用示例
1 |
|
特性
- 线程终止: 通过
pthread_exit终止线程时,线程的状态可以由retval返回。 - 资源清理:
pthread_exit会在线程退出前自动执行使用pthread_cleanup_push注册的清理处理程序。 - 避免主线程提前退出: 在主线程调用
pthread_exit可以避免程序在子线程完成之前退出。
pthread_self
pthread_self 函数用于获取调用它的线程自身的线程标识符。
函数原型
1 |
|
返回值
- 返回调用线程的
pthread_t类型的线程标识符。
使用示例
1 |
|
特性
- 线程标识:
pthread_self可以用来获取当前线程的标识符,这在调试、日志记录或需要线程标识的操作中非常有用。 - 可移植的类型:
pthread_t类型可能在不同平台上有不同的实现,因此打印或比较时通常需要进行适当的转换,例如转为unsigned long。
pthread_equal
pthread_equal 函数用于比较两个线程标识符以确定它们是否表示同一个线程。
函数原型
1 |
|
参数
t1: 第一个线程标识符。t2: 第二个线程标识符。
返回值
- 如果两个线程标识符表示同一个线程,返回非零值。
- 如果两个线程标识符表示不同的线程,返回零。
使用示例
1 |
|
特性
- 线程比较:
pthread_equal提供了一种兼容并可移植的方式来比较线程标识符,因为pthread_t类型的具体实现可能因平台而异,不能简单使用==运算符直接比较。 - 常用于验证: 适用于需要验证两个线程是否为同一个的场景,例如在复杂多线程环境中进行一致性检查。
pthread_join
pthread_join 函数用于等待一个线程的终止。调用它的线程将阻塞,直到指定的线程完成其执行。
函数原型
1 |
|
参数
thread: 要等待的线程的标识符。retval: 指向存储线程退出状态的指针。如果调用pthread_exit提供了一个返回值,retval将指向这个值。传NULL表示不关心线程的返回值。
返回值
- 成功返回 0。
- 失败返回错误码,可能的错误有:
EINVAL: 线程不可连接,或已连接过。ESRCH: 无法找到指定线程。EDEADLK: 死锁检测到(例如,线程尝试连接自己)。
使用示例
1 |
|
特性
- 同步机制:
pthread_join是一个常用的线程同步机制,用于确保一个线程在使用线程结果之前等待其他线程完成。 - 资源回收: 确保线程已经终止,并为它分配的所有资源(如线程栈)被正确回收。如果不调用
pthread_join,在某些实现中可能导致资源泄漏。 - 线程的可连接性: 一个线程只能被连接一次。多次对同一线程调用
pthread_join会导致未定义行为或错误。
pthread_detach
pthread_detach 函数用于将一个线程的状态设置为“分离”,即表示该线程将独立运行,它的退出状态不需要被其他线程关心,系统资源可以在线程终止后立即回收。
函数原型
1 |
|
参数
thread: 要分离的线程的标识符。
返回值
- 成功返回 0。
- 失败返回错误码,可能的错误包括:
EINVAL: 无效的线程标识或者线程已经处于分离状态。ESRCH: 无法找到指定线程。
使用示例
1 |
|
特性
- 不需等待: 分离状态的线程不需要被其他线程
pthread_join,它的资源将在终止时被自动回收。 - 资源管理: 如果一个线程没有被分离状态也没有被
pthread_join,可能会导致内存泄漏,因为系统不能自动回收线程的资源。 - 单独使用: 一旦线程被分离,不能再被
pthread_join,即程序无法获取线程的退出状态。 - 适用场景: 适用于不需要关心线程完成状态或返回值的情况,例如一些后台任务或操作。
pthread_cancel
pthread_cancel 用于请求取消一个线程的执行。当线程接收到取消请求时,它会尝试退出。这个函数并不会立即终止被请求的线程,而是发送一个取消信号,该线程将在某个取消点(cancelation point)响应该信号。
函数原型
1 |
|
参数
thread: 要取消的线程的标识符。
返回值
- 成功返回 0。
- 失败返回错误码,例如:
ESRCH: 无法找到指定的线程。
线程的取消状态
每个线程都有一个取消状态和取消类型,可以使用 pthread_setcancelstate 和 pthread_setcanceltype 来设置。
取消状态:
PTHREAD_CANCEL_ENABLE(默认): 线程可以被取消。PTHREAD_CANCEL_DISABLE: 线程不响应取消请求。
取消类型:
PTHREAD_CANCEL_DEFERRED(默认): 取消请求要等到线程到达取消点时才生效。常见的取消点包括:pthread_join、pthread_cond_wait、read、write等。PTHREAD_CANCEL_ASYNCHRONOUS: 取消请求尽快生效(可能会有不安全行为,因此很少使用)。
使用示例
1 |
|
特性
- 安全性: 使用
pthread_cancel要谨慎,尤其是在资源管理方面,因为线程可能在不安全点被取消。 - 清理处理程序: 可以使用
pthread_cleanup_push和pthread_cleanup_pop注册清理代码,以确保在线程取消时释放资源。 - 取消点: 注意线程取消是在取消点生效的,代码编写时应该识别并合理使用这些点,确保数据一致性和资源管理。
pthread_cleanup_push / pthread_cleanup_pop
pthread_cleanup_push 和 pthread_cleanup_pop 是用于在 POSIX 线程中注册清理处理程序的宏。这些处理程序在线程被取消时或在退出函数之前被调用,以确保释放资源并进行必要的清理操作。
头文件
1 |
使用语法
1 | void pthread_cleanup_push(void (*routine)(void *), void *arg); |
pthread_cleanup_push:注册一个清理处理程序routine。当线程被取消或通过pthread_exit退出时,routine将会被调用,并且传递arg作为参数。pthread_cleanup_pop:从清理处理程序栈中移除最顶层的处理程序。如果execute非零,则调用此处理程序。
注意:这两个宏必须成对使用,并且在同一层次的代码块中,通常是同一作用域内。
使用示例
1 |
|
特性
- 清理顺序: 清理处理程序按照后进先出(LIFO)的顺序调用。
- 资源管理: 可以用于管理线程资源,如锁、动态分配的内存等,以确保在线程取消或正常退出时资源能够被正确释放。
- 逻辑一致性:
pthread_cleanup_push和pthread_cleanup_pop必须成对使用且在同一代码块中,典型用法是围绕一个可能导致线程退出的函数调用。 - 线程安全: 确保在处理不期而遇的取消请求时,不会破坏数据和导致死锁。
pthread_cleanup_pop 是一个与 pthread_cleanup_push 成对使用的重要宏,用于从清理处理程序栈中移除最顶层的清理处理程序。这个清理处理程序可以在线程因取消或正常退出时被调用,以实现资源管理和清理操作。
互斥量相关API
pthread_mutex_init()
pthread_mutex_init 是一个用于初始化互斥锁(mutex)的函数。在多线程编程中,互斥锁用于保护共享资源,以确保只有一个线程能够在任意给定时间访问该资源。这是实现线程同步的重要机制之一。
头文件
1 |
函数原型
1 | int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr); |
参数:
pthread_mutex_t *mutex: 指向需要初始化的互斥锁对象。const pthread_mutexattr_t *attr: 可选的互斥锁属性。通常传递为NULL,它表示使用默认的互斥锁属性。
返回值:
- 成功时返回 0。
- 如果出错,则返回一个错误码,用于指示具体的错误类型。
使用步骤
声明互斥锁对象:
在使用互斥锁之前,需要声明一个pthread_mutex_t类型的变量。初始化互斥锁:
调用pthread_mutex_init函数来初始化互斥锁对象。这通常在创建线程或使用互斥锁的任何代码之前完成。使用互斥锁:
在需要保护的代码块之前调用pthread_mutex_lock和在之后调用pthread_mutex_unlock。销毁互斥锁:
当互斥锁不再需要时,使用pthread_mutex_destroy来销毁它。
使用示例
1 |
|
注意事项
属性参数:
pthread_mutex_init中的attr通常使用NULL,表示使用默认属性。如果需要指定属性,可以使用pthread_mutexattr_init和相关函数来设置。错误处理: 在
pthread_mutex_lock和pthread_mutex_unlock失败时,要进行适当的错误处理,尤其是相应的资源管理。使用互斥锁: 在访问共享资源时,确保正确的锁操作,以避免死锁或竞争条件。
销毁互斥锁: 在销毁互斥锁之前,确保没有任何线程持有它,否则会引发未定义行为。
pthread_mutex_destroy()
pthread_mutex_destroy 是用于销毁(释放)一个互斥锁对象的函数。当互斥锁不再需要使用时,应使用此函数以确保释放相关资源。
头文件
1 |
函数原型
1 | int pthread_mutex_destroy(pthread_mutex_t *mutex); |
参数:
pthread_mutex_t *mutex: 指向需要销毁的互斥锁对象。
返回值:
- 成功时返回 0。
- 如果出错,返回一个错误码,例如互斥锁仍然被锁定。
使用步骤
确保互斥锁未被锁定: 在调用
pthread_mutex_destroy之前,确保没有线程持有该互斥锁。销毁互斥锁: 调用
pthread_mutex_destroy来释放与互斥锁相关的资源。
使用示例
1 |
|
注意事项
未定义行为: 在互斥锁被持有时销毁它会导致未定义行为。
资源管理: 在不使用
pthread_mutex_destroy释放互斥锁之前,可能会导致内存泄漏。互斥锁重用: 销毁后的互斥锁不能再使用,除非重新初始化。
正确释放: 没有正在持有或等待的情况下销毁互斥锁,避免不必要的资源占用或内存泄漏。
pthread_mutex_lock()
pthread_mutex_lock 是一个用于锁定互斥锁的函数。在多线程编程中,互斥锁用于确保只有一个线程可以在同一时间访问共享资源。通过使用 pthread_mutex_lock,线程可以进入临界区,确保对共享资源的独占访问。
头文件
1 |
函数原型
1 | int pthread_mutex_lock(pthread_mutex_t *mutex); |
参数:
pthread_mutex_t *mutex: 指向需要锁定的互斥锁对象。
返回值:
- 成功时返回 0。
- 如果出错,返回一个错误码。例如,
EDEADLK表示检测到死锁。
使用步骤
初始化互斥锁: 在使用互斥锁之前,必须先初始化它,通常使用
pthread_mutex_init。锁定互斥锁: 使用
pthread_mutex_lock来锁定互斥锁。如果互斥锁已经被其他线程锁定,则调用线程会阻塞,直到互斥锁可用。进入临界区: 在互斥锁成功锁定后,线程可以安全地访问共享资源。
解锁互斥锁: 完成对共享资源的访问后,使用
pthread_mutex_unlock解锁互斥锁,以便其他线程可以访问。
使用示例
1 |
|
注意事项
死锁检测: 如果同一线程尝试再次锁定已经持有的互斥锁,可能会导致死锁。某些系统会返回
EDEADLK错误码。阻塞行为:
pthread_mutex_lock是阻塞调用,如果互斥锁不可用,线程会阻塞直到锁可用。正确的锁/解锁对: 确保每个
pthread_mutex_lock都有对应的pthread_mutex_unlock,否则可能会导致资源不可用或死锁。错误处理: 在锁定失败时进行适当的错误处理,以确保程序的健壮性。
pthread_mutex_trylock()
pthread_mutex_trylock 是一个用于尝试锁定互斥锁的非阻塞函数。与 pthread_mutex_lock 不同的是,如果互斥锁已经被其他线程锁定,pthread_mutex_trylock 不会阻塞当前线程,而是立即返回一个错误码。这对于需要在不阻塞的情况下尝试获取锁的场景非常有用。
头文件
1 |
函数原型
1 | int pthread_mutex_trylock(pthread_mutex_t *mutex); |
参数:
pthread_mutex_t *mutex: 指向需要尝试锁定的互斥锁对象。
返回值:
- 成功时返回 0,表示锁定成功。
- 如果互斥锁已经被锁定,返回
EBUSY。 - 其他错误码可能指示其他错误情况。
使用步骤
初始化互斥锁: 在使用互斥锁之前,必须先初始化它,通常使用
pthread_mutex_init。尝试锁定互斥锁: 使用
pthread_mutex_trylock来尝试锁定互斥锁。如果互斥锁已经被其他线程锁定,则立即返回EBUSY,而不是阻塞。进入临界区: 如果锁定成功,线程可以安全地访问共享资源。
解锁互斥锁: 完成对共享资源的访问后,使用
pthread_mutex_unlock解锁互斥锁,以便其他线程可以访问。
使用示例
1 |
|
注意事项
非阻塞行为:
pthread_mutex_trylock不会阻塞调用线程,这使得它适用于需要在不阻塞的情况下尝试获取锁的场景。错误处理: 如果返回
EBUSY,表示锁已经被其他线程持有,调用线程可以选择执行其他操作或重试。死锁预防: 与
pthread_mutex_lock一样,确保每个成功的锁定都有对应的解锁操作。使用场景: 适用于需要在不阻塞的情况下检查锁状态的场景,例如在事件循环中或需要执行其他任务时。
pthread_mutex_unlock()
pthread_mutex_unlock 是一个用于解锁互斥锁的函数。在多线程编程中,互斥锁用于确保对共享资源的独占访问。当一个线程完成对共享资源的访问后,必须使用 pthread_mutex_unlock 来释放互斥锁,以便其他线程可以获取锁并访问资源。
头文件
1 |
函数原型
1 | int pthread_mutex_unlock(pthread_mutex_t *mutex); |
参数:
pthread_mutex_t *mutex: 指向需要解锁的互斥锁对象。
返回值:
- 成功时返回 0。
- 如果出错,返回一个错误码。例如,如果当前线程并未持有锁,行为是未定义的。
使用步骤
锁定互斥锁: 在进入临界区之前,线程应使用
pthread_mutex_lock或pthread_mutex_trylock来锁定互斥锁。访问共享资源: 在互斥锁成功锁定后,线程可以安全地访问共享资源。
解锁互斥锁: 完成对共享资源的访问后,使用
pthread_mutex_unlock解锁互斥锁。
使用示例
1 |
|
注意事项
正确的锁/解锁对: 确保每个
pthread_mutex_lock或pthread_mutex_trylock都有对应的pthread_mutex_unlock,否则可能会导致死锁或资源不可用。未定义行为: 如果一个线程试图解锁一个它没有锁定的互斥锁,行为是未定义的。这可能会导致程序崩溃或其他不可预测的行为。
错误处理: 在解锁失败时进行适当的错误处理,以确保程序的健壮性。
多次解锁: 不要尝试多次解锁一个已经解锁的互斥锁,这会导致未定义行为。
通过正确使用 pthread_mutex_unlock,可以确保共享资源在多线程环境中的安全访问。
futex()
futex 是通过 syscall 系统调用实现的,通常不直接调用,而是通过封装函数。
头文件
1 |
函数原型
1 | int futex(int *uaddr, int futex_op, int val, const struct timespec *timeout, int *uaddr2, int val3); |
参数:
int *uaddr: 指向用户空间的整型地址,表示要操作的 futex。int futex_op: 指定要执行的操作,如FUTEX_WAIT或FUTEX_WAKE。int val: 用于FUTEX_WAIT时,指定期望的*uaddr值。const struct timespec *timeout: 用于FUTEX_WAIT时,指定超时时间。int *uaddr2: 用于某些高级操作,通常为NULL。int val3: 用于某些高级操作,通常为0。
返回值:
- 成功时返回 0 或唤醒的线程数量。
- 失败时返回 -1,并设置
errno来指示错误。
使用示例
下面是一个简单的示例,演示如何使用 futex 实现基本的等待和唤醒机制。
1 |
|
注意事项
用户空间条件检查: 在调用
futex_wait之前,应该在用户空间检查条件是否满足,以避免不必要的系统调用。内核态开销:
futex的优势在于它只在必要时进入内核态,因此在条件满足时,用户空间的条件检查可以避免系统调用的开销。超时处理: 可以使用
timeout参数来指定超时时间,以避免线程无限期等待。错误处理: 在使用
futex操作时,注意检查返回值并处理错误。
通过正确使用 futex,可以实现高效的用户空间同步机制,减少内核态切换的开销。
futex(fast user-space mutex)是 Linux 内核提供的一种轻量级同步原语,主要用于实现用户空间的锁机制。futex 的主要优势在于它在用户空间和内核空间之间的切换非常高效,只有在必要时才进入内核空间。
futex_wait()
futex_wait 是 futex 操作的一部分,用于在用户空间等待一个特定条件满足。它通常与 futex_wake 一起使用。
futex_wait 的基本思想是:线程在用户空间检测到某个条件不满足时,调用 futex_wait 进入睡眠状态,直到其他线程通过 futex_wake 唤醒它。
头文件
1 |
函数原型
futex_wait 是通过 syscall 系统调用实现的,通常不直接调用,而是通过封装函数。
1 | int futex_wait(int *uaddr, int val, const struct timespec *timeout); |
参数:
int *uaddr: 指向用户空间的整型地址,表示要等待的 futex。int val: 期望*uaddr的值。如果*uaddr不等于val,futex_wait立即返回。const struct timespec *timeout: 指定等待的超时时间。如果为NULL,则无限期等待。
返回值:
- 成功时返回 0。
- 失败时返回 -1,并设置
errno来指示错误。
使用步骤
初始化: 在用户空间初始化一个整型变量作为 futex。
等待条件: 当线程检测到某个条件不满足时,调用
futex_wait进入睡眠状态。唤醒线程: 其他线程在条件满足时调用
futex_wake来唤醒等待的线程。
使用示例
1 |
|
注意事项
用户空间条件检查: 在调用
futex_wait之前,应该在用户空间检查条件是否满足,以避免不必要的系统调用。内核态开销:
futex的优势在于它只在必要时进入内核态,因此在条件满足时,用户空间的条件检查可以避免系统调用的开销。超时处理: 可以使用
timeout参数来指定超时时间,以避免线程无限期等待。错误处理: 在使用
futex_wait和futex_wake时,注意检查返回值并处理错误。
通过正确使用 futex_wait 和 futex_wake,可以实现高效的用户空间同步机制,减少内核态切换的开销。
futex_wake()
futex_wake 是 futex 操作的一部分,用于唤醒等待在指定地址上的一个或多个线程。它通常与 futex_wait 配合使用,以实现用户空间的同步机制。
futex_wake 的基本功能是通知等待在某个地址上的线程,使其从休眠状态中唤醒。
头文件
1 |
函数原型
futex_wake 是通过 syscall 系统调用实现的,通常不直接调用,而是通过封装函数。
1 | int futex_wake(int *uaddr, int num); |
参数:
int *uaddr: 指向用户空间的整型地址,表示要唤醒的 futex。int num: 指定唤醒的线程数量。如果为1,则唤醒一个等待线程;如果为INT_MAX,则唤醒所有等待线程。
返回值:
- 成功时返回唤醒的线程数量。
- 失败时返回 -1,并设置
errno来指示错误。
使用步骤
初始化: 在用户空间初始化一个整型变量作为 futex。
等待线程: 使用
futex_wait让线程在某个条件不满足时进入睡眠。唤醒线程: 使用
futex_wake在条件满足时唤醒等待的线程。
使用示例
1 |
|
注意事项
用户空间条件检查: 在调用
futex_wake之前,通常需要在用户空间检查条件是否满足。唤醒数量:
num参数允许指定唤醒的线程数量,合理使用可以控制并发程度。错误处理: 在使用
futex_wake时,注意检查返回值并处理错误。同步机制:
futex本身只是一个低级原语,通常与其他同步机制(如条件变量、信号量)结合使用以实现复杂的同步逻辑。
通过正确使用 futex_wake,可以高效地唤醒等待线程,减少内核态切换的开销,实现用户空间的同步机制。
futex(fast user-space mutex)是 Linux 内核提供的一种高效的同步原语,用于在用户空间实现锁和其他同步机制。futex 的主要优点在于,它在大多数情况下不需要进入内核空间,只有在竞争激烈或需要等待时才会进行系统调用,从而减少了上下文切换的开销。
pthread_mutexattr_gettype()
pthread_mutexattr_gettype 是一个用于获取互斥锁属性类型的函数。它与 pthread_mutexattr_settype 一起使用,用于设置和获取互斥锁的类型属性。互斥锁类型决定了锁的行为,特别是在递归锁和错误检查方面。
函数原型
1 |
|
参数:
const pthread_mutexattr_t *attr: 指向互斥锁属性对象的指针。int *type: 指向一个整数的指针,用于存储互斥锁的类型。
返回值:
- 成功时返回 0。
- 失败时返回一个错误码。
互斥锁类型
互斥锁类型决定了锁的行为,主要有以下几种:
PTHREAD_MUTEX_NORMAL: 普通锁,不支持递归锁定。如果一个线程再次锁定它已经持有的锁,会导致死锁。
PTHREAD_MUTEX_RECURSIVE: 递归锁,允许同一线程多次锁定。锁需要被解锁相同次数才能释放。
PTHREAD_MUTEX_ERRORCHECK: 错误检查锁,如果一个线程再次锁定它已经持有的锁,会返回错误而不是死锁。
PTHREAD_MUTEX_DEFAULT: 默认锁类型,通常与
PTHREAD_MUTEX_NORMAL相同,但具体行为可能依赖于实现。
使用示例
下面是一个简单的示例,演示如何使用 pthread_mutexattr_gettype 获取互斥锁的类型。
1 |
|
注意事项
初始化和销毁: 在使用
pthread_mutexattr_gettype之前,确保互斥锁属性对象已经通过pthread_mutexattr_init初始化,并在使用完后通过pthread_mutexattr_destroy销毁。错误检查: 在调用
pthread_mutexattr_gettype时,检查返回值以确保操作成功。互斥锁类型选择: 根据应用需求选择合适的互斥锁类型,以避免死锁或不必要的错误。
通过正确使用 pthread_mutexattr_gettype,可以有效地管理和调试互斥锁的行为,确保线程同步的正确性和效率。
pthread_mutexattr_settype()
pthread_mutexattr_settype 是一个用于设置互斥锁属性类型的函数。它允许你指定互斥锁的行为类型,这对于控制锁的递归性和错误检查特性非常重要。
函数原型
1 |
|
参数:
pthread_mutexattr_t *attr: 指向互斥锁属性对象的指针。int type: 要设置的互斥锁类型。
返回值:
- 成功时返回 0。
- 失败时返回一个错误码,例如
EINVAL,表示提供的类型无效。
互斥锁类型
互斥锁类型决定了锁的行为,主要有以下几种:
PTHREAD_MUTEX_NORMAL: 普通锁,不支持递归锁定。如果一个线程再次锁定它已经持有的锁,会导致死锁。
PTHREAD_MUTEX_RECURSIVE: 递归锁,允许同一线程多次锁定。锁需要被解锁相同次数才能释放。
PTHREAD_MUTEX_ERRORCHECK: 错误检查锁,如果一个线程再次锁定它已经持有的锁,会返回错误而不是死锁。
PTHREAD_MUTEX_DEFAULT: 默认锁类型,通常与
PTHREAD_MUTEX_NORMAL相同,但具体行为可能依赖于实现。
使用示例
下面是一个简单的示例,演示如何使用 pthread_mutexattr_settype 设置互斥锁的类型。
1 |
|
注意事项
初始化和销毁: 在使用
pthread_mutexattr_settype之前,确保互斥锁属性对象已经通过pthread_mutexattr_init初始化,并在使用完后通过pthread_mutexattr_destroy销毁。错误检查: 在调用
pthread_mutexattr_settype时,检查返回值以确保操作成功。互斥锁类型选择: 根据应用需求选择合适的互斥锁类型,以避免死锁或不必要的错误。递归锁适用于需要在同一线程中多次锁定的场景,而错误检查锁可以帮助调试锁定错误。
通过正确使用 pthread_mutexattr_settype,可以有效地管理互斥锁的行为,确保线程同步的正确性和效率。
自旋锁相关API
pthread_spin_init()
pthread_spin_init 是用于初始化自旋锁的函数。自旋锁是一种轻量级的锁机制,适用于短时间的锁定操作,特别是在多处理器系统中。自旋锁在等待锁释放时会一直占用 CPU 资源进行循环检查,而不是使线程进入休眠状态。
函数原型
1 |
|
参数:
pthread_spinlock_t *lock: 指向自旋锁对象的指针。这个对象在初始化后用于表示锁的状态。int pshared: 指定锁是否可以在进程间共享。PTHREAD_PROCESS_PRIVATE: 自旋锁用于单个进程中的线程同步。PTHREAD_PROCESS_SHARED: 自旋锁可以在多个进程间共享(如果系统支持)。
返回值:
- 成功时返回 0。
- 失败时返回一个错误码,例如
EINVAL(参数无效)或ENOMEM(内存不足)。
使用示例
以下是一个简单的示例,演示如何使用 pthread_spin_init 初始化自旋锁,并在多线程环境中进行同步:
1 |
|
注意事项
- 初始化: 在使用自旋锁之前,必须通过
pthread_spin_init进行初始化。 - 共享选项:
pshared参数决定了自旋锁的共享范围。通常情况下,使用PTHREAD_PROCESS_PRIVATE,除非需要在多个进程间共享锁。 - 销毁: 在不再需要自旋锁时,使用
pthread_spin_destroy销毁它,以释放相关资源。 - 适用场景: 自旋锁适用于锁持有时间非常短的场景,因为它会在等待时消耗 CPU 资源。对于长时间的锁定操作,互斥锁可能是更好的选择。
通过正确地初始化和使用自旋锁,可以在合适的场景中实现高效的线程同步。
pthread_spin_destroy()
pthread_spin_destroy 是用于销毁自旋锁的函数。自旋锁在使用完毕后需要被销毁,以释放相关资源并避免内存泄漏。销毁自旋锁是线程同步机制中资源管理的重要部分。
函数原型
1 |
|
参数:
pthread_spinlock_t *lock: 指向需要销毁的自旋锁对象的指针。
返回值:
- 成功时返回 0。
- 失败时返回一个错误码,例如
EINVAL(表示锁无效或未初始化)。
使用示例
以下是一个简单的示例,演示如何使用 pthread_spin_destroy 销毁自旋锁:
1 |
|
注意事项
- 正确销毁: 在不再需要自旋锁时,务必调用
pthread_spin_destroy销毁它。未销毁的锁可能导致资源泄漏。 - 锁状态: 确保在销毁自旋锁之前,所有使用该锁的线程都已经完成操作,并且锁未被持有。否则,可能导致未定义行为。
- 重复销毁: 不要重复销毁同一个自旋锁。重复销毁可能导致错误或未定义行为。
- 初始化后销毁: 自旋锁必须在初始化后才能被销毁。未初始化或已经销毁的锁不能再次销毁。
通过正确地销毁自旋锁,可以确保程序的资源管理更加高效和安全。
pthread_spin_lock、pthread_spin_trylock 和 pthread_spin_unlock 是用于操作自旋锁的函数。自旋锁是一种轻量级的锁机制,适用于短时间的锁定操作,尤其是在多处理器系统中。以下是这些函数的用法解析:
pthread_spin_lock()
pthread_spin_lock 用于获取自旋锁。如果锁已经被其他线程持有,调用线程将一直忙等待(自旋)直到锁可用。
函数原型
1 |
|
参数:
pthread_spinlock_t *lock: 指向自旋锁对象的指针。
返回值:
- 成功时返回 0。
- 失败时返回一个错误码(通常不会发生)。
使用示例
1 | pthread_spin_lock(&spinlock); |
pthread_spin_trylock()
pthread_spin_trylock 尝试获取自旋锁。如果锁已经被其他线程持有,它不会阻塞,而是立即返回一个错误码。
函数原型
1 |
|
参数:
pthread_spinlock_t *lock: 指向自旋锁对象的指针。
返回值:
- 成功时返回 0。
- 如果锁已经被持有,返回
EBUSY。
使用示例
1 | if (pthread_spin_trylock(&spinlock) == 0) { |
pthread_spin_unlock()
pthread_spin_unlock 用于释放自旋锁,使其他线程可以获取该锁。
函数原型
1 |
|
参数:
pthread_spinlock_t *lock: 指向自旋锁对象的指针。
返回值:
- 成功时返回 0。
- 失败时返回一个错误码(通常不会发生)。
使用示例
1 | pthread_spin_lock(&spinlock); |
注意事项
- 忙等待:
pthread_spin_lock会导致忙等待,因此在锁持有时间较长的情况下,可能会导致 CPU 资源浪费。 - 适用场景: 自旋锁适用于锁持有时间非常短的场景。对于长时间的锁定操作,互斥锁(
pthread_mutex_t)可能是更好的选择。 - 锁的状态: 确保在调用
pthread_spin_unlock之前,锁已经被当前线程持有,否则可能导致未定义行为。 - 错误处理: 使用
pthread_spin_trylock时,应处理锁不可用的情况,以避免程序逻辑错误。
通过正确地使用这些函数,可以在多线程环境中实现高效的同步机制。
读写锁相关API
pthread_rwlock_init
pthread_rwlock_init 用于初始化一个读写锁对象。在使用读写锁之前,必须先调用此函数进行初始化。
函数原型
1 |
|
参数:
pthread_rwlock_t *rwlock: 指向要初始化的读写锁对象的指针。const pthread_rwlockattr_t *attr: 指向读写锁属性对象的指针。如果为NULL,则使用默认属性。
返回值:
- 成功时返回 0。
- 失败时返回一个错误码,如
ENOMEM(内存不足)或EINVAL(无效的属性)。
使用示例
1 | pthread_rwlock_t rwlock; |
pthread_rwlock_destroy
pthread_rwlock_destroy 用于销毁一个读写锁对象。当一个读写锁不再需要使用时,应调用此函数释放相关资源。
函数原型
1 |
|
参数:
pthread_rwlock_t *rwlock: 指向要销毁的读写锁对象的指针。
返回值:
- 成功时返回 0。
- 失败时返回一个错误码,如
EBUSY(锁仍然被持有)。
使用示例
1 | if (pthread_rwlock_destroy(&rwlock) != 0) { |
pthread_rwlock_rdlock
pthread_rwlock_rdlock 用于获取一个读锁。如果其他线程持有写锁,则调用线程会阻塞,直到写锁被释放。
函数原型
1 |
|
参数:
pthread_rwlock_t *rwlock: 指向要获取读锁的读写锁对象的指针。
返回值:
- 成功时返回 0。
- 失败时返回一个错误码,如
EDEADLK(检测到死锁)或EINVAL(无效的锁对象)。
使用示例
1 | pthread_rwlock_t rwlock; |
pthread_rwlock_tryrdlock
pthread_rwlock_tryrdlock 尝试获取一个读锁,但不会阻塞。如果读锁不可用(例如,其他线程持有写锁),则立即返回。
函数原型
1 |
|
参数:
pthread_rwlock_t *rwlock: 指向要获取读锁的读写锁对象的指针。
返回值:
- 成功时返回 0。
- 失败时返回一个错误码,如
EBUSY(锁不可用)或EINVAL(无效的锁对象)。
使用示例
1 | pthread_rwlock_t rwlock; |
pthread_rwlock_wrlock
pthread_rwlock_wrlock 用于获取一个写锁。如果其他线程持有读锁或写锁,则调用线程会阻塞,直到所有读锁和写锁被释放。
函数原型
1 |
|
参数:
pthread_rwlock_t *rwlock: 指向要获取写锁的读写锁对象的指针。
返回值:
- 成功时返回 0。
- 失败时返回一个错误码,如
EDEADLK(检测到死锁)或EINVAL(无效的锁对象)。
使用示例
1 | pthread_rwlock_t rwlock; |
pthread_rwlock_trywrlock
pthread_rwlock_trywrlock 尝试获取一个写锁,但不会阻塞。如果写锁不可用(例如,其他线程持有读锁或写锁),则立即返回。
函数原型
1 |
|
参数:
pthread_rwlock_t *rwlock: 指向要获取写锁的读写锁对象的指针。
返回值:
- 成功时返回 0。
- 失败时返回一个错误码,如
EBUSY(锁不可用)或EINVAL(无效的锁对象)。
使用示例
1 | zpthread_rwlock_t rwlock; |
pthread_rwlock_unlock
pthread_rwlock_unlock 是用于释放先前获取的读写锁的函数。无论是读锁还是写锁,都可以使用这个函数来解锁。
函数原型
1 |
|
参数:
pthread_rwlock_t *rwlock: 指向要释放的读写锁对象的指针。
返回值:
- 成功时返回 0。
- 失败时返回一个错误码,如
EPERM(当前线程没有持有该锁)或EINVAL(无效的锁对象)。
使用示例
在使用读写锁时,无论是读锁还是写锁,都需要在操作完成后调用 pthread_rwlock_unlock 来释放锁。
释放读锁
1 | pthread_rwlock_t rwlock; |
释放写锁
1 | pthread_rwlock_t rwlock; |
条件等待相关API
pthread_cond_init 和 pthread_cond_destroy 是用于初始化和销毁条件变量的函数。条件变量用于线程间的同步,允许线程等待某个条件的发生。
pthread_cond_init
函数原型
1 |
|
参数
cond: 指向要初始化的条件变量的指针。attr: 指向条件变量属性对象的指针。如果使用默认属性,可以传递NULL。
返回值
- 成功时返回 0。
- 失败时返回一个错误码,如
ENOMEM(内存不足)或EINVAL(无效的属性)。
用法
静态初始化: 如果不需要自定义属性,可以使用 PTHREAD_COND_INITIALIZER 进行静态初始化。
1 | pthread_cond_t cond = PTHREAD_COND_INITIALIZER; |
动态初始化: 使用 pthread_cond_init 进行动态初始化,适用于需要自定义属性的情况。
1 | pthread_cond_t cond; |
自定义属性: 如果需要自定义条件变量的属性,可以先使用 pthread_condattr_init 初始化属性对象,然后在 pthread_cond_init 中传递该对象。
1 | pthread_condattr_t attr; |
示例
1 |
|
pthread_cond_destroy
函数原型
1 |
|
参数
cond: 指向要销毁的条件变量的指针。
返回值
- 成功时返回 0。
- 失败时返回一个错误码,如
EBUSY(条件变量上仍有线程在等待)或EINVAL(无效的条件变量)。
用法
- 确保没有线程在等待: 在调用
pthread_cond_destroy之前,必须确保没有线程在等待该条件变量。否则,会导致EBUSY错误。 - 与互斥锁配合: 通常,条件变量与互斥锁一起使用。在销毁条件变量之前,确保相关的互斥锁已经被正确处理。
- 初始化和销毁匹配: 确保每个通过
pthread_cond_init初始化的条件变量都被正确地销毁。
示例
1 |
|
pthread_cond_wait
函数原型
1 |
|
参数
cond: 指向条件变量的指针。mutex: 指向互斥锁的指针。调用此函数时,互斥锁必须已被锁定。
返回值
- 成功时返回 0。
- 失败时返回一个错误码。
用法
- 在调用
pthread_cond_wait时,线程必须持有互斥锁。函数会自动释放该锁并使线程进入等待状态。 - 当条件变量被其他线程信号(通过
pthread_cond_signal或pthread_cond_broadcast)时,线程会被唤醒并重新锁定互斥锁。
示例
1 |
|
pthread_cond_timedwait
函数原型
1 |
|
参数
cond: 指向条件变量的指针。mutex: 指向互斥锁的指针。调用此函数时,互斥锁必须已被锁定。abstime: 指向timespec结构体的指针,指定绝对时间(相对于 Epoch 时间)作为超时时间。
返回值
- 成功时返回 0。
- 超时时返回
ETIMEDOUT。 - 失败时返回其他错误码。
用法
- 与
pthread_cond_wait类似,但增加了超时功能。 - 如果在指定时间内没有收到信号,函数会返回
ETIMEDOUT。
示例
1 |
|
pthread_cond_signal 和 pthread_cond_broadcast 是用于唤醒等待条件变量的线程的函数。它们通常与条件变量和互斥锁一起使用,以实现线程间的同步。
pthread_cond_signal
函数原型
1 |
|
参数
cond: 指向条件变量的指针。
返回值
- 成功时返回 0。
- 失败时返回一个错误码。
用法
pthread_cond_signal用于唤醒至少一个正在等待该条件变量的线程。- 如果有多个线程在等待,具体唤醒哪个线程是由实现决定的。
- 通常用于通知一个等待线程某个条件已经满足。
示例
1 |
|
pthread_cond_broadcast
函数原型
1 |
|
参数
cond: 指向条件变量的指针。
返回值
- 成功时返回 0。
- 失败时返回一个错误码。
用法
pthread_cond_broadcast用于唤醒所有正在等待该条件变量的线程。- 通常用于需要通知所有等待线程某个条件已经满足的情况。
示例
1 |
|
局部存储相关API
仅作记录,推荐使用__thread 关键字。
pthread_key_create 和 pthread_key_delete 是用于管理线程特定数据(Thread-Specific Data, TSD)的函数。它们用于创建和删除线程特定数据的键,允许每个线程拥有自己的数据副本。
pthread_key_create
函数原型
1 |
|
参数
key: 指向pthread_key_t类型的指针,用于存储创建的键。destructor: 可选的析构函数指针,当线程退出时用于清理线程特定数据。如果不需要清理,可以传递NULL。
返回值
- 成功时返回 0。
- 失败时返回一个错误码,例如:
EAGAIN: 系统资源不足,无法创建更多的键。ENOMEM: 内存不足,无法分配键。
用法
- 创建一个线程特定数据键,并指定一个可选的析构函数。
- 每个线程可以使用该键来存储和检索自己的数据。
pthread_key_delete
函数原型
1 |
|
参数
key: 要删除的键。
返回值
- 成功时返回 0。
- 失败时返回一个错误码,例如:
EINVAL: 提供的键无效。
用法
- 删除一个线程特定数据键。
- 删除键后,不能再使用该键来存储或检索数据。
示例
以下是一个简单的示例,演示如何使用 pthread_key_create 和 pthread_key_delete:
1 |
|
注意事项
- 析构函数: 如果提供了析构函数,当线程退出时,系统会自动调用该函数来清理线程特定数据。
- 内存管理: 线程特定数据的内存管理由程序员负责,确保在适当的时候释放内存。
- 键的生命周期: 在不再需要使用键时,应调用
pthread_key_delete删除它,以释放系统资源。 - 线程安全:
pthread_key_create和pthread_key_delete是线程安全的,可以在多线程环境中安全使用。
pthread_setspecific 和 pthread_getspecific 是用于管理线程特定数据(Thread-Specific Data, TSD)的函数。它们允许每个线程存储和检索与特定键关联的数据。
pthread_setspecific
函数原型
1 |
|
参数
key: 线程特定数据的键,必须是通过pthread_key_create创建的。value: 要与键关联的值。可以是任意类型的数据指针。
返回值
- 成功时返回 0。
- 失败时返回一个错误码,例如:
EINVAL: 提供的键无效。ENOMEM: 内存不足,无法存储数据。
用法
- 将一个数据指针与指定的键关联。每个线程可以为同一个键存储不同的数据。
pthread_getspecific
函数原型
1 |
|
参数
key: 线程特定数据的键,必须是通过pthread_key_create创建的。
返回值
- 返回与键关联的值。
- 如果没有为该键设置值,则返回
NULL。
用法
- 检索与指定键关联的线程特定数据。
示例
以下是一个简单的示例,演示如何使用 pthread_setspecific 和 pthread_getspecific:
1 |
|
注意事项
- 线程隔离: 每个线程对同一个键可以存储不同的数据,
pthread_setspecific和pthread_getspecific操作仅影响调用线程。 - 内存管理: 由
pthread_setspecific设置的值的内存管理由程序员负责。确保在适当的时候释放内存,通常通过析构函数。 - 初始值: 如果没有为某个键设置值,
pthread_getspecific将返回NULL。这可以用来检查是否已经为键设置了值。
- Title: Linux环境编程与内核之线程
- Author: 韩乔落
- Created at : 2025-02-06 14:49:11
- Updated at : 2025-08-06 18:44:18
- Link: https://jelasin.github.io/2025/02/06/Linux环境编程与内核之线程/
- License: This work is licensed under CC BY-NC-SA 4.0.