
Linux环境编程与内核之信号

信号概念
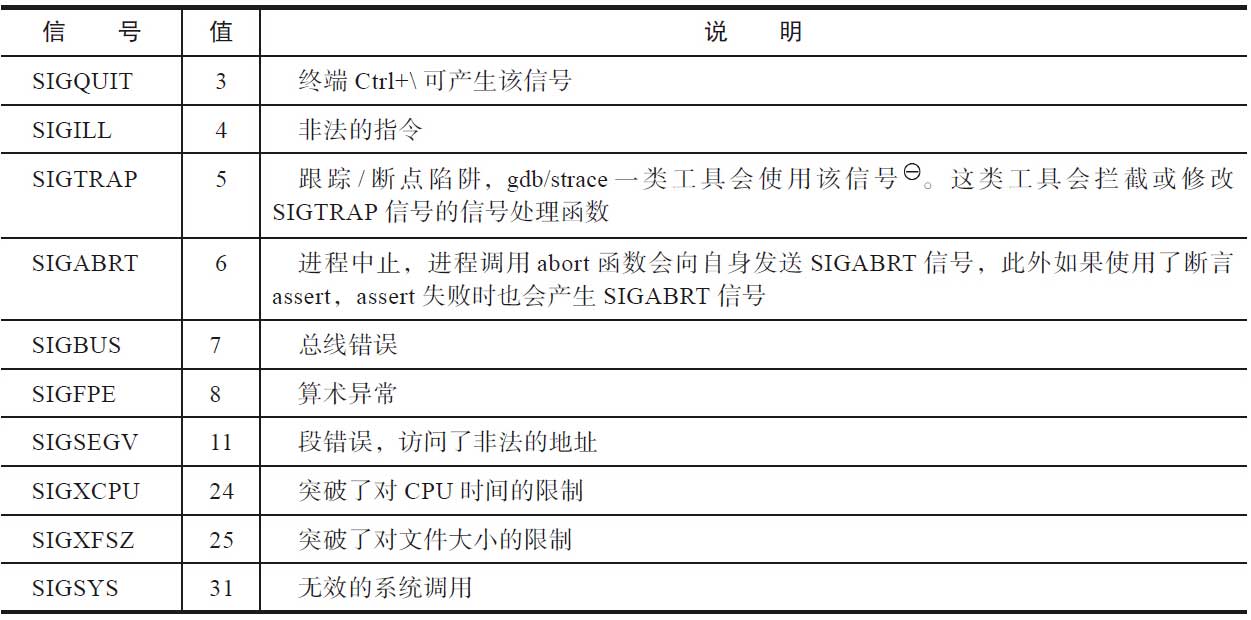
信号是一种软件中断,用来处理异步事件。内核递送这些异步事件到某个进程,告诉进程某个特殊事件发生了。这些异步事件,可能来自硬件,比如访问了非法的内存地址,或者除以0了;可能来自用户的输入,比如shell终端上用户在键盘上敲击了Ctrl+C;还可能来自另一个进程,甚至有些来自进程自身。信号的本质是一种进程间的通信,一个进程向另一个进程发送信号,内核至少传递了信号值这个字段。实际上,通信的内容不止是信号值。信号机制是Unix家族里一个古老的通信机制。传统的信号机制有一些弊端,更为严重的是,信号处理函数的执行流和正常的执行流同时存在,给编程带来了很多的麻烦和困扰,一不小心就可能掉入陷阱。
信号的完整生命周期
前文提到过,信号的本质是一种进程间的通信。进程之间约定好:如果发生了某件事情T(trigger),就向目标进程(destination process)发送某特定信号X,而目标进程看到X,就意识到T事件发生了,目标进程就会执行相应的动作A(action)。
接下来以配置文件改变为例,来描述整个过程。很多应用都有配置文件,如果配置文件发生改变,需要通知进程重新加载配置。一般而言,程序会默认采用SIGHUP信号来通知目标进程重新加载配置文件。目标进程首先约定,只要收到SIGHUP,就执行重新加载配置文件的动作。这个行为称为信号的安装(installation),或者信号处理函数的注册。安装好了之后,因为信号是异步事件,不知道何时会发生,所以目标进程依然正常地干自己的事情。某年某月的某一天,管理员突然改变了配置文件,想通知这个目标进程,于是就向目标进程发送了信号。他可能在终端执行了kill-SIGHUP命令,也可能调用了C的API,不管怎样,信号产生了。这时候,Linux内核收到了产生的信号,然后就在目标进程的进程描述符里记录了一笔:收到信号SIGHUP一枚。Linux内核会在适当的时机,将信号递送(deliver)给进程。在内核收到信号,但是还没有递送给目标进程的这一段时间里,信号处于挂起状态,被称为挂起(pending)信号,也称为未决信号。内核将信号递送给进程,进程就会暂停当前的控制流,转而去执行信号处理函数。这就是一个信号的完整生命周期。
一个典型的信号会按照上面所述的流程来处理,但是实际情况要复杂得多,还有很多场景需要考虑,比如:
- 目标进程正在执行关键代码,不能被信号中断,需要阻塞某些信号,那么在这期间,信号就不允许被递送到进程,直到目标进程解除阻塞。
- 内核发现同一个信号已经存在,那么它该如何处理这种重复的信号,排队还是丢弃?
- 内核递送信号的时候,发现已有多个不同的信号被挂起,那它应该优先递送哪个信号?
- 对于多线程的进程,如果向该进程发送信号,应该由哪个线程来负责响应?
信号的产生
作为进程间通信的一种手段,进程之间可以互相发送信号,然而发给进程的信号,通常源于内核,包括:
- 硬件异常。
- 终端相关的信号。
- 软件事件相关的信号。
硬件异常
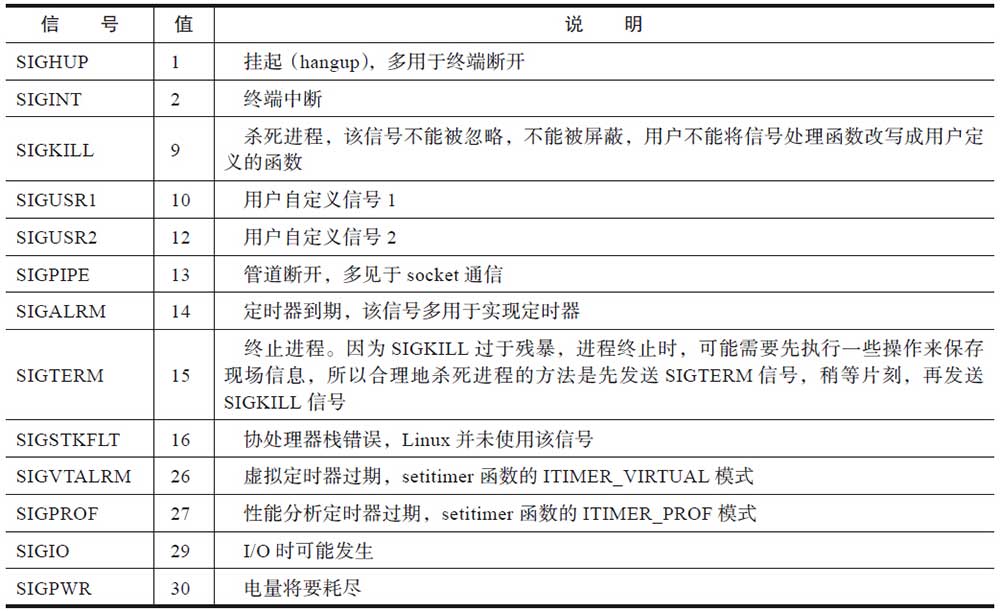
硬件检测到了错误并通知内核,由内核发送相应的信号给相关进程。和硬件异常相关的信号见表。

常见的能触发SIGBUS信号的场景有:
- 变量地址未对齐:很多架构访问数据时有对齐的要求。比如int型变量占用4个字节,因此架构要求int变量的地址必须为4字节对齐,否则就会触发SIGBUS信号。
- mmap映射文件:使用mmap将文件映射入内存,如果文件大小被其他进程截短,那么在访问文件大小以外的内存时,会触发SIGBUS信号。
虽然SIGFPE的后缀FPE是浮点异常(Float Point Exception)的含义,但是该异常并不限于浮点运算,常见的算术运算错误也会引发SIGFPE信号。最常见的就是“整数除以0”的例子。SIGILL的含义是非法指令(illegal instruction)。一般表示进程执行了错误的机器指令。
SIGSEGV是所有C程序员的噩梦。没经历几个刻骨铭心的段错误,很难成长为合格的C程序员。由于C语言可以直接操作指针,就像时常行走在河边的顽童很难避免湿鞋一样,程序员很难避免段错误,没有经验的程序员更是如此。常见的情况有:
- 访问未初始化的指针或NULL指针指向的地址。
- 进程企图在用户态访问内核部分的地址。
- 进程尝试去修改只读的内存地址。
这四种硬件异常,一般是由程序自身引发的,不是由其他进程发送的信号引发的,并且这些异常都比较致命,以至于进程无法继续下去。所以这些信号产生之后,会立刻递送给进程。默认情况下,这四种信号都会使进程终止,并且产生core dump文件以供调试。对于这些信号,进程既不能忽略,也不能阻塞。
终端相关的信号
对于Linux程序员而言,终端操作是免不了的。终端有很多的设置,可以通过执行如下指令来查看:
1 | ➜ ~ stty -a |
很重要的是,终端定义了如下几种信号生成字符:
- Ctrl+C:产生
SIGINT信号。 - Ctrl+\:产生
SIGQUIT信号。 - Ctrl+Z:产生
SIGTSTP信号。
键入这些信号生成字符,相当于向前台进程组发送了对应的信号。
另一个和终端关系比较密切的信号是SIGHUP信号。很多程序员都遇到过这种问题:使用ssh登录到远程的Linux服务器,执行比较耗时的操作(如编译项目代码),却因为网络不稳定,或者需要关机回家,ssh连接被断开,最终导致操作中途被放弃而失败。之所以会如此,是因为一个控制进程在失去其终端之后,内核会负责向其发送一个SIGHUP信号。在登录会话中,shell通常是终端的控制进程,控制进程收到SIGHUP信号后,会引发如下的连锁反应。shell收到SIGHUP后会终止,但是在终止之前,会向由shell创建的前台进程组和后台进程组发送SIGHUP信号,为了防止处于停止状态的任务接收不到SIGHUP信号,通常会在SIGHUP信号之后,发送SIGCONT信号,唤醒处于停止状态的任务。前台进程组和后台进程组的进程收到SIGHUP信号,默认的行为是终止进程,这也是前面提到的耗时任务会中途失败的原因。注意,单纯地将命令放入后台执行(通过&符号,如下所示),并不能摆脱被SIGHUP信号追杀的命运。
1 | command & |
那么如何让进程在后台稳定地执行而不受终端连接断开的影响呢?可以采用如下方法。
1.nohup
1 | nohup command |
标准输入会重定向到/dev/null,标准输出和标准错误会重定向到nohup.out,如果无权限写入当前目录下的nohup.out,则会写入home目录下的nohup.out。nohup仅仅是使启动的进程不再响应SIGHUP信号。
2.setsid
1 | setsid command |
这种方式和nohup的原理不太一样。nohup仅仅是使启动的进程不再响应SIGHUP信号,但是setsid则完全不属于shell所在的会话了,并且其父进程也已经不是shell而是init进程了。
1 | manu@manu-hacks:~$ nohup sleep 200 & |
3.disown
启动命令时,忘记了使用nohup或setsid,可还有办法亡羊补牢?答案是使用作业控制里面的disown,方法如下:
1 | manu@manu-hacks:~$ sleep 1004 & |
当然,还有其他的方法可以做到这点,如screen等。
软件事件相关的信号
软件事件触发信号产生的情况也比较多:
- 子进程退出,内核可能会向父进程发送SIGCHLD信号。
- 父进程退出,内核可能会给子进程发送信号。
- 定时器到期,给进程发送信号。
与子进程退出向父进程发送信号相反,有时候,进程希望父进程退出时向自己发送信号,从而可以得知父进程的退出事件。Linux也提供了这种机制。每一个进程的进程描述符task_struct中都存在如下成员变量:
1 | int pdeath_signal; /* The signal sent when the parent dies */ |
如果父进程退出,子进程希望收到通知,那么子进程可以通过执行如下代码来做到:
1 | prctl(PR_SET_PDEATHSIG, sig); |
父进程退出时,会遍历其子进程,发现有子进程很关心自己的退出,就会向该子进程发送子进程希望收到的信号。很多定时器相关的函数,背后都牵扯到信号,具体见表:
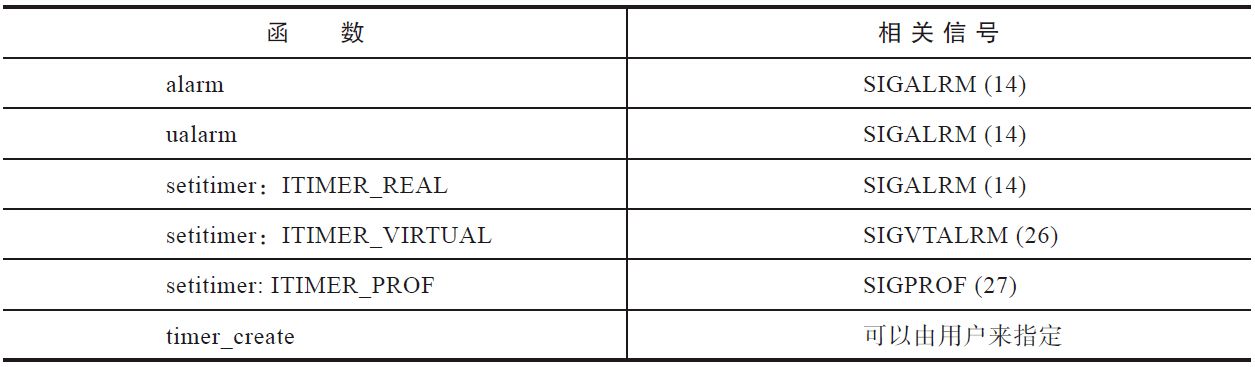
信号的默认处理函数
从上一节可以看出,信号产生的源头有很多。那么内核将信号递送给进程后,进程会执行什么操作呢?很多信号尤其是传统的信号,都会有默认的信号处理方式。如果我们不改变信号的处理函数,那么收到信号之后,就会执行默认的操作。信号的默认操作有以下几种:
- **显式地忽略信号(ignore)**:即内核将会丢弃该信号,信号不会对目标进程产生任何影响。
- **终止进程(terminate)**:很多信号的默认处理是终止进程,即将进程杀死。
- **生成核心转储文件并终止进程(core)**:进程被杀死,并且产生核心转储文件。核心转储文件记录了进程死亡现场的信息。用户可以使用核心转储文件来调试,分析进程死亡的原因。
- **停止进程(stop)**:停止进程不同于终止进程,终止进程是进程已经死亡,但是停止进程仅仅是使进程暂停,将进程的状态设置成
TASK_STOPPED,一旦收到恢复执行的信号,进程还可以继续执行。 - **恢复进程的执行(continue)**:和停止进程相对应,某些信号可以使进程恢复执行。
事实上,根据信号的默认操作,可以将传统信号分成5派,具体见表:
ignore

terminate
core
stop
continue

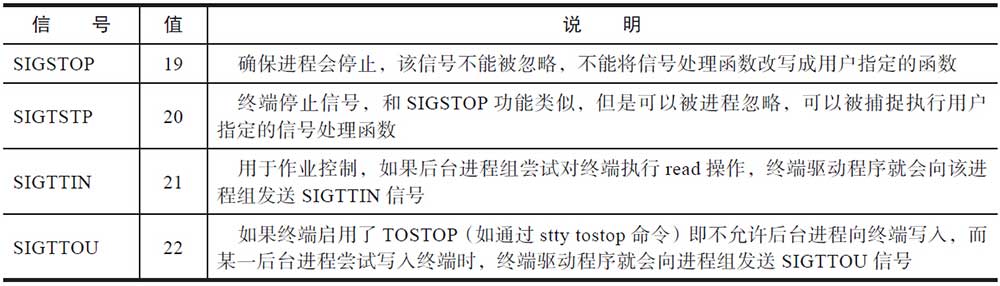
信号的这些默认行为是非常有用的。比如停止行为和恢复执行。系统可能有一些备份的工作,这些工作优先级并不高,但是却消耗了大量的I/O资源,甚至是CPU资源(比如需要先压缩再备份)。这样的工作一般是在夜深人静,业务稀少的时候进行的。在业务比较繁忙的情况下,如果备份工作还在进行,则可能会影响到业务。这时候停止和恢复就非常有用了。在业务繁忙之前,可以通过SIGSTOP信号将备份进程暂停,在几乎没有什么业务的时候,通过SIGCONT信号使备份进程恢复执行。
很多信号产生核心转储文件也是非常有意义的。一般而言,程序出错才会导致SIGSEGV、SIGBUS、SIGFPE、SIGILL及SIGABRT等信号的产生。生成的核心转储文件保留了进程死亡的现场,提供了大量的信息供程序员调试、分析错误产生的原因。核心转储文件的作用有点类似于航空中的黑盒子,可以帮助程序员还原事故现场,找到程序漏洞。
很多情况下,默认的信号处理函数,可能并不能满足实际的需要,这时需要修改信号的信号处理函数。信号发生时,不执行默认的信号处理函数,改而执行用户自定义的信号处理函数。为信号指定新的信号处理函数的动作,被称为信号的安装。glibc提供了signal函数和sigaction函数来完成信号的安装。signal出现得比较早,接口也比较简单,sigaction则提供了精确的控制。
信号的分类
在Linux的shell终端,执行kill -l,可以看到所有的信号:
1 | ➜ ~ kill -l |
这些信号可以分成两类:
- 可靠信号。
- 不可靠信号。
信号值在[1,31]之间的所有信号,都被称为不可靠信号;在[SIGRTMIN,SIGRTMAX]之间的信号,被称为可靠信号。不可靠信号是从传统的Unix继承而来的。早期Unix系统信号的机制并不完备,在实践过程中暴露了很多弊端,因此把这些早期出现的信号值在[1,31]之间的信号称之为不可靠信号。所谓不可靠,指的是发送的信号,内核不一定能递送给目标进程,信号可能会丢失。随着时间的流逝,人们意识到原有的信号机制存在弊端。但是[1,31]之间的信号存在已久,在很多应用中被广泛使用,出于兼容性的考虑,不能改变这些信号的行为模式,所以只能新增信号。新增的信号就是我们今天看到的在[SIGRTMIN,SIGRTMAX]范围内的信号,它们被称为可靠信号。
所谓不可靠,指的是发送的信号,内核不一定能递送给目标进程,信号可能会丢失。信号的可靠与否,完全取决于信号的值,而与采用哪种方式安装或发送无关。根本差异在于收到信号后,内核有不同的处理方式。
对于不可靠信号,内核用位图来记录该信号是否处于挂起状态。如果收到某不可靠信号,内核发现已经存在该信号处于未决状态,就会简单地丢弃该信号。因此发送不可靠信号,信号可能会丢失,即内核递送给目标进程的次数,可能小于信号发送的次数。对于可靠信号,内核内部有队列来维护,如果收到可靠信号,内核会将信号挂到相应的队列中,因此不会丢失。严格说来,内核也设有上限,挂起信号的个数也不能无限制地增大,因此只能说,在一定范围之内,可靠信号不会被丢弃。
传统信号特点
传统的signal机制,分为System V风格和BSD风格的signal。glibc提供了signal函数来注册用户定义的信号处理函数,代码如下:
1 |
|
除此以外,Linux还提供了如下两个接口供我们“考古”,下面来探查一下signal机制的演化:
1 |
|
从接口上看,存在4种signal函数,见表:
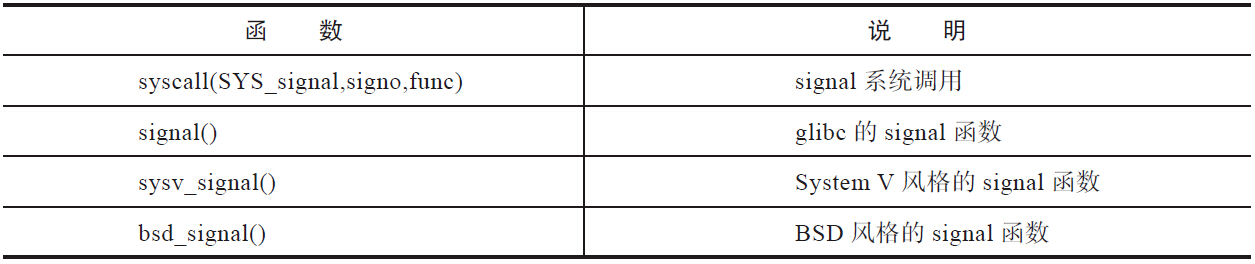
接下来用实验的方法,测试各种不同的信号机制表现出来的行为模式,帮助大家体会传统信号的特点和弊端,以及学习Linux下glibc提供的signal函数的行为特性:
1 |
|
分别采用了Linux操作系统提供的signal系统调用、System V风格的sysv_signal、BSD风格的bsd_signal,还有glibc提供的标准API signal函数。下面来分别体会它们之间的不同之处。
1 | gcc -o systemcall_signal -DSYSCALL_SIGNAL_API signal_comp.c |
信号的ONESHOT特性
传统的System V风格的signal,其注册的信号处理函数是一次性的,信号递送给目标进程之后,信号处理函数会变成默认值SIG_DFL。
1 | manu@manu-hacks:~/code/c/self/signal$ ./sysv_signal |
可以看到第一次实验的时候,输入一个字符串,敲击回车,正常显示了输入的字符串。第二次输入结束之前,按Ctrl+C键,系统会向进程发送SIGINT信号,进程收到信号后,执行了信号处理函数(打印出了OMG,I catch the signal SIGINT),再次向进程发送SIGINT信号,进程就退出了。可见,在System V风格的信号处理机制中,安装的信号处理函数是一次性的,内核把信号递送出去后,信号处理函数恢复成默认值SIG_DFL。因为SIGINT信号的默认处理是终止进程,所以进程就退出了。
Linux系统调用也是如此,信号处理函数同样是一次性的:
1 | manu@manu-hacks:signal$ ./systemcall_signal |
对于这种风格,内核中有个很形象的宏来描述这种行为模式,即SA_ONESHOT。
对于信号而言,是用标志位来控制信号的ONESHOT行为模式的,这个标志位是:
1 | /*架构相关,对于x86平台*/ |
当内核递送信号给进程时,如果发现同时满足以下两个条件,则会将信号处理函数恢复成默认函数:
- 信号处理函数不是默认值。
- 信号处理函数的标志位中,SA_ONESHOT标志置位。
这部分控制逻辑,出现于内核的get_signal_to_deliver函数中:
1 | int get_signal_to_deliver(siginfo_t *info, struct k_sigaction *return_ka, |
使用strace来追踪sysv_signal的执行,可以看到有如下的系统调用:
1 | rt_sigaction(SIGINT, {sa_handler=0x5e6638ebb336, sa_mask=[], sa_flags=SA_RESTORER|SA_INTERRUPT|SA_NODEFER|SA_RESETHAND|0xffffffff00000000, sa_restorer=0x7b41cf642520}, {sa_handler=SIG_DFL, sa_mask=[], sa_flags=0}, 8) = 0 |
BSD风格的signal和glibc的signal函数已经不存在ONESHOT的问题了,代码如下所示:
1 | manu@manu-hacks:signal$ ./bsd_signal |
通过strace追踪bsd_signal和glibc_signal执行的系统调用,可以看到,两者调用rt_sigaction系统调用时都没有设置SA_ONESHOT的标志位。
1 | //glibc |
信号执行时屏蔽自身的特性
在执行信号处理函数期间,很有可能会收到其他的信号,当然也有可能再次收到正在处理的信号。如果在处理A信号期间再次收到A信号,会发生什么呢?对于传统的System V信号机制,在信号处理期间,不会屏蔽对应的信号,而这就会引起信号处理函数的重入。这算是传统的System V信号机制的另一个弊端了。BSD信号处理机制修正了这个缺陷。当然了,BSD信号处理机制只是屏蔽了当前信号,并没有屏蔽当前信号以外的其他信号。
来比较下System V和BSD signal机制的区别。System V风格的系统调用:
1 | //sysv风格 |
BSD风格的信号处理机制,在安装信号的时候,会将自身这个信号添加到信号处理函数的屏蔽集合中。如果在执行A信号的信号处理函数期间,再次收到A信号,那么当前的A信号处理流程则不会被新来A信号打断。简单地说,就是不会嵌套了。System V风格的信号,在其信号处理期间没有屏蔽任何信号,换句话说,执行信号处理函数期间,处理流程可以被任意信号中断,包括正在处理的信号。从前面的实验可以看出,BSD风格的信号处理函数“OMG,I catch the signal SIGINT”,以及“OK,finished process signal SIGINT”总是成对出现的,不可能连续出现两个“OMG,I catch the signal SIGINT”,原因就是SIGINT信号在信号处理函数执行期间被暂时屏蔽了。内核是如何做到这一点的?完整的信号递送流程大致如此:内核首先调用get_signal_to_deliver,在挂起的信号集合中选择一个信号,递送给进程,选择完毕后,调用handler_signal函数。handler_signal函数的作用是为执行信号处理函数做准备。
1 | void handler_signal(int sig, siginfo_t *info, struct k_sigaction *ka, |
从上面代码中不难看出,如果信号没有设置SA_NODEFER标志位,正在处理的信号就必须在信号处理程序执行期间被阻塞。System V风格的signal机制为何会出现不屏蔽自身信号的情况?原因就是sysv_signal函数,在调用rt_sigaction系统调用时加上了SA_NODEFER标志位,如下:
1 | rt_sigaction(SIGINT, {0x8048756, [], SA_INTERRUPT|SA_NODEFER|SA_RESETHAND}, {SIG_DFL, [], 0}, 8) = 0 |
信号中断系统调用的重启特性
系统调用在执行期间,很可能会收到信号,此时进程可能不得不从系统调用中返回,去执行信号处理函数。对于执行时间比较久的系统调用(如wait、read等)被信号中断的可能性会大大增加。系统调用被中断后,一般会返回失败,并置错误码为EINTR。如果程序员希望处理完信号之后,被中断的系统调用能够重启,则需要通过判断errno的值来解决,即如果发现错误码是EINTR,就重新调用系统调用。来看下面的例子:
1 | manu@manu-hacks:~/code/c/self/signal$ ./sysv_signal |
通过strace可以看到,fgets调用了read系统调用,而read系统调用因为等待用户输入而陷入长时间的阻塞。在阻塞过程中,收到了一个SIGINT信号,导致read系统调用被中断,返回了错误码EINTR。
Linux世界中的很多系统调用都会遭遇这种情景,尤其是read、wait这种可能比较耗时的系统调用。《Unix系统编程:通信、并发和线程》一书中存在很多类似的例子:
1 | pid_t r_wait(int *stat_loc) |
这种封装就是用来应对系统调用被信号中断的场景的。当系统调用被信号中断时,程序并不认为这是一种无法处理的错误,相反,程序完全可以通过重新调用系统调用,来完成其想做的事情。在System V信号机制下,系统调用如果被信号中断,则会返回-1,并置errno为EINTR,而不会主动重启被信号中断的系统调用。细细想来,如果所有的系统调用都要判断返回值是否为EINTR,是的话,则重启系统调用,那么程序员就太累了。
BSD风格的signal机制提供了另外一种思路,即如果系统调用被信号中断,内核会在信号处理函数结束之后,自动重启系统调用,无须程序员再次调用系统调用。Linux操作系统提供了一个标志位SA_RESTART来告诉内核,被信号中断后是否要重启系统调用。如果该标志位为1,则表示如果系统调用被信号中断,那么内核会自动重启系统调用。BSD风格的signal函数和glibc的函数,毫无意外地都带有该标志位:
1 | rt_sigaction(SIGINT, {0x8048736, [INT], SA_RESTART}, {SIG_DFL, [], 0}, 8) = 0 |
非常不幸的是,并不是所有的系统调用对信号中断都表现出同样的行为。某些系统调用哪怕设置了SA_RESTART的标志位,也绝不会自动重启。那么问题就来了,在Linux下,如果信号处理函数设置了SA_RESTART,哪些阻塞型的系统调用遭到信号中断后,可以自动重启,哪些系统调用又是死活也无法自动重启的呢?
下表列出了设置SA_RESTART标志位后,可以自动重启的阻塞型系统调用。
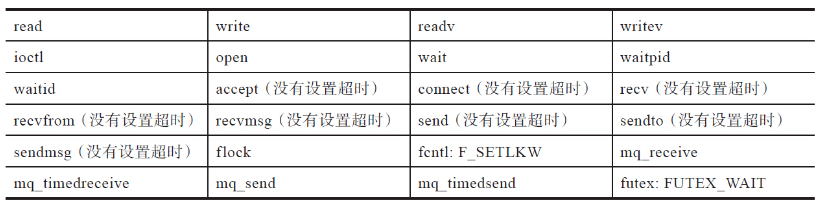
下表是设置了SA_RESTART标志位,也不会重启的系统调用。
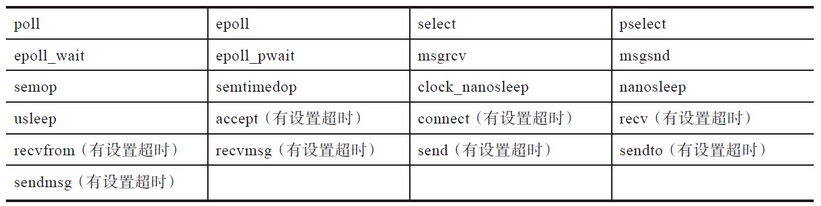
通过man 7 signal就可以获得这些信息。
通过测试得知4种信号函数的不同表现。
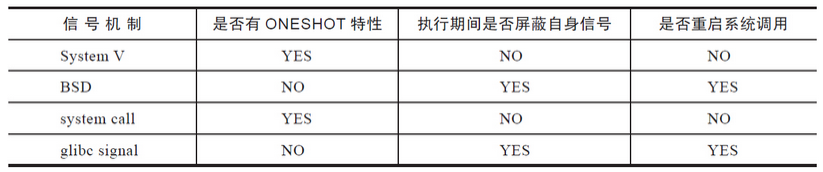
手册明确表示bsd_signal没有ONESHOT特性,信号处理函数不会reset成默认值,无须重复安装信号处理函数;信号处理函数期间,自身信号会被屏蔽;系统调用被中断,会重启系统调用。这三个特性都是可以保证的,但是glibc下signal函数就不一定了,这要取决于操作系统,取决于glibc的版本。这是signal函数被人诟病的一个重要原因。简言之,就是其历史负担太重。通过前面的讨论可以发现,Linux系统会通过一些标志位和屏蔽信号集来完成对某些特性的控制。
- SA_ONESHOT(或SA_RESERTHAND):将信号处理函数恢复成默认值。
- SA_NODEFER(或SA_NOMASK):显式地告诉内核,不要将当前处理信号值添加进阻塞信号集。
- SA_RESTART:将中断的系统调用重启,而不是返回错误码EINTR。
信号的可靠性
传统的信号存在信号丢失的问题,因此被称为不可靠信号。为了对传统的不可靠信号有更直观的认识,下面来做一个简单的实验,让事实来说话。我们可以疯狂地向某个进程发送信号,然后通过比较信号发送的次数和信号处理函数执行的次数来验证是否存在信号丢失的问题。
1 |
|
如果执行时不带参数,那么进程会原地循环,直到收到SIGINT信号为止。在这期间,信号处理函数每执行一次,都会将收到信号的次数加1,进程结束前,会将各种信号收到的次数打印出来。如果执行时带一个参数,那么这个参数的含义是屏蔽信号的时间N,首先将能够阻塞的信号全部阻塞,在信号阻塞期间,虽然会有进程向signal_receiver进程发送信号,但是内核并不会立即将收到的信号递送给进程。在沉睡N秒之后,解除阻塞,内核开始向signal_receiver进程递送信号。
1 |
|
程序比较简单,接受三个参数:目标进程号、信号值和发送次数。有了这个工具,我们可以向目标进程signal_receiver连续发送任意次数的信号X。
首先,signal_receiver不带参数执行(即signal_receiver进程不会让信号阻塞一段时间),向signal_receiver连续发送信号,看看目标进程signal_receiver一共收到多少次信号:
1 | 终端1: |
向9937进程发送信号SIGUSR2 10000次,然后发送SIGINT信号1次来结束signal_receiver进程,下面查看signal_receiver进程一共收到多少次信号:
1 | 终端2 |
1 | 终端1 |
可以看到我们发送12号信号10000次,可是signal_receiver只收到2488次,这个2488也不是固定的,如果多执行几次,你会看到每次收到的信号次数均不相同。
可以看到收到信号的次数是不一定的,但是都不等于发送信号的次数。再进一步,让信号接收进程屏蔽信号一段时间,在这段时间内,发送信号,查询信号处理函数被触发的次数:
1 | 终端1 |
从上面的例子可以看出,如果进程将信号屏蔽一段时间,在此期间向目标进程发送SIGUSR2信号10000次,在解除屏蔽之后,信号处理函数只触发了一次。那么可靠信号的表现又如何呢?实验中发送实时信号36共计10000次,解除屏蔽后信号处理函数共触发了10000次,没有丢失信号,所有信号都被递送给进程去处理了。
从上面的实验可以看出可靠信号和不可靠信号存在着不小的差异。不可靠信号,不能可靠地被传递给进程处理,内核可能会丢弃部分信号。会不会丢弃,以及丢弃多少,取决于信号到来和信号递送给进程的时序。而可靠信号,基本不会丢失信号。
之所以存在这种差异,是因为重复的信号到来时,内核采取了不同的处理方式。从内核收到发给某进程的信号,到内核将信号递送给该进程,中间有个时间窗口。在这个时间窗口内,内核会负责记录收到的信号信息,这些信号被称为挂起信号或未决信号。但是对于可靠信号和不可靠信号,内核采取了不同的记录方式。内核中负责记录挂起信号的数据结构为sigpending结构体,定义代码如下:
1 | struct sigpending { |
在sigpending结构体中,sigset_t类型的成员变量signal本质上是一个位图,用一个比特来记录是否存在与该位置对应的信号处于未决的状态。根据位图可以有效地判断某信号是否已经存在未决信号。因为共有64种不同的信号,因此对于64位的操作系统,一个无符号的长整型就足以描述所有信号的挂起情况了。在sigpending结构体中,第一个成员变量是个链表头。内核定义了结构体sigqueue,代码如下:
1 | struct sigqueue { |
该结构体中info成员变量详细记录了信号的信息。如果内核收到发给某进程的信号,则会分配一个sigqueue结构体,并将该结构体挂入sigpending中第一个成员变量list为表头的链表之中。综上所述,内核的进程描述符提供了两套机制来记录挂起信号:位图和队列。可能有读者会问,存在两套机制,尤其是存在队列,不应该丢失信号啊!正常来讲,来一个信号,只须将信号的相关信息挂入队列之中,就可以确保信号不丢。的确如此,但是实际上,可靠信号和不可靠信号的处理方式不同,不可靠信号并没有充分的队列来确保信号不丢。内核收到不可靠信号时,会检查位图中对应位置是否已经是1,如果不是1,则表示尚无该信号处于挂起状态,然后会分配sigqueue结构体,并将信号挂入链表之中,同时将位图对应位置置1。但是如果位图显示已经存在该不可靠信号,那么内核会直接丢弃本次收到的信号。换句话说,内核的sigpending链表之中,最多只会存在一个不可靠信号的sigqueue结构体。
内核收到可靠信号时,不论是否已经存在该信号处于挂起状态,都会为该信号分配一个sigqueue结构体,并将sigqueue结构体挂入sigpending的链表之中,以确保不会丢失信号。那么可靠信号是不是可以无限制地挂入队列呢?也不是。实际上内核也做了限制,一个进程默认挂起信号的个数是有限的,超过限制,可靠信号也会变得没那么可靠了,也会丢失信号。让我们看看内核代码:
1 | static struct sigqueue * |
实时信号也不能被无限制地挂起。该限制属于资源限制的范畴,该限制项(RLIMIT_SIGPENDING)限制了目标进程所属的真实用户ID信号队列中挂起信号的总数。可以通过如下命令来查看系统的限制:
1 | manu@manu-hacks:~$ ulimit –a |
1 | 终端1 |
向目标进程发送了实时信号36共计20000次,但目标进程只收到了15144次,超出限制的部分都被丢弃掉了。这个挂起信号的上限值是可以修改的,可以用ulimit -i unlimited这个命令将进程挂起信号的最大值设为无穷大,从而确保内核不会主动丢弃实时信号。
信号的安装
前面讲了传统信号的很多弊端,讲了signal的兼容性问题,有问题就会有解决方案。对此,Linux提供了新的信号安装方法:sigaction函数。和signal函数相比,这个函数的优点在于语义明确,可以提供更精确的控制。先来看一下sigaction函数的定义:
1 |
|
上面给出的sigaction结构体的定义并非严格意义上的定义,即结构体必须要有上述的成员变量,但成员变量的具体顺序取决于实现。顾名思义,sa_mask就是信号处理函数执行期间的屏蔽信号集。前文介绍bsd_signal的时候曾提到,为SIGINT安装处理函数时,内核会自动将SIGINT添加入屏蔽信号集,在SIGINT信号处理函数执行期间,SIGINT信号不会被递送给进程。但是,也仅仅是SIGINT,如果执行SIGINT信号处理函数期间,需要屏蔽SIGHUP、SIGUSR1等其他信号,那bsd_signal函数就爱莫能助了。这个屏蔽其他信号的需求对sigaction函数而言,根本就不是问题,只需如下代码即可做到:
1 | struct sigaction sa; |
需要特别指出的是,并不是所有的信号都能被屏蔽。对于SIGKILL和SIGSTOP,不可以为它们安装信号处理函数,也不能屏蔽掉这些信号。原因是,系统总要控制某些进程,如果进程可以自行设计所有信号的处理函数,那么操作系统可能无法控制这些进程。换言之,操作系统是终极boss,需要杀死某些进程的时候,要能够做到,SIGKILL和SIGSTOP不能被屏蔽,就是为了防止出现进程无法无天而操作系统徒叹奈何的困境。
若通过sigaction强行给SIGKILL或SIGSTOP注册信号处理函数,则会返回-1,并置errno为EINVAL。在sigaction函数接口中,比较有意思的是sa_flags。sigaction函数之所以可以提供更精确的控制,大部分都是该参数的功劳。下面简要介绍一下sa_flags的含义,其中很多标志位并不是新面孔,前面已经讨论过了。
(1)SA_NOCLDSTOP这个标志位只用于SIGCHLD信号。父进程可以监测子进程的三种事件:
- 子进程终止(即子进程死亡)
- 子进程停止(即子进程暂停)
- 子进程恢复(即子进程从暂停中恢复执行)
其中SA_NOCLDSTOP标志位是用来控制第二种和第三种事件的。即一旦父进程为SIGCHLD信号设置了这个标志位,那么子进程停止和子进程恢复这两件事情,就无须向父进程发送SIGCHLD信号了。
(2)SA_NOCLDWAIT这个标志只用于SIGCHLD信号。
它可控制上面提到的子进程终止时的行为。如果父进程为SIGCHLD设置了SA_NOCLDWAIT标志位,那么子进程退出时,就不会进入僵尸状态,而是直接自行了断。但是子进程还会不会向父进程发送SIGCHLD信号呢?这取决于具体的实现。对于Linux而言,仍然会发送SIGCHLD信号。这点和上面的SA_NOCLDSTOP略有不同。
(3)SA_ONESHOT和SA_RESETHAND这两个标志位的本质是一样的,表示信号处理函数是一次性的,信号递送出去之后,信号处理函数便恢复成默认值SIG_DFL。
(4)SA_NODEFER和SA_NOMASK这两个标志位的作用是一样的,在信号处理函数执行期间,不阻塞当前信号。
(5)SA_RESTART这个标志位表示,如果系统调用被信号中断,则不返回错误,而是自动重启系统调用。
(6)SA_SIGINFO这个标志位表示信号发送者会提供额外的信息。
这种情况下,信号处理函数应该为三参数的函数,代码如下:
1 | void handle(int, siginfo_t *, void *); |
此处重点讲述一下带SA_SIGINFO标志位的信号安装方式。本章引言中提到过,signal的本质是一种进程间的通信。一个进程向另外一个进程发送信号,能够传递的信息,不仅仅是signo,它还可以发送更多的信息,而接收进程也能获取到发送进程的PID、UID及发送的额外信息。
1 |
|
这个例子比较简单,为36号信号注册了信号处理函数。因为sa_flags带上了SA_SIGINFO标志位,所以必须使用三参数的信号处理函数。
1 | void sig_handler(int signo,siginfo_t *info,void *context) |
本例中的信号处理函数中,info->si_pid记录着信号发送者的PID,info->si_value.sival_int是信号发送进程时额外发送的int值。发送进程和接收进程约定好,发送者使用sigqueue发送信号,同时带上int型的额外信息,接收进程就能获得发送进程的PID及int型的额外信息。
信号的发送
kill、tkill和tgkill
1 |
|
注意,不能望文生义,将kill函数的作用理解为杀死进程。kill函数的作用是发送信号。kill函数不仅可以向特定进程发送信号,也可以向特定进程组发送信号。第一个参数pid的值,决定了kill函数的不同含义,具体来讲,可以分成以下几种情况。
- pid>0:发送信号给进程ID等于pid的进程。
- pid=0:发送信号给调用进程所在的同一个进程组的每一个进程。
- pid=-1:有权限向调用进程发送信号的所有进程发出信号,init进程和进程自身除外。
- pid<-1:向进程组-pid发送信号。
当函数成功时,返回0,失败时,返回-1,并置errno。常见的出错情况见表

有一种情况很有意思,即调用kill函数时,第二个参数signo的值为0。众所周知,没有一个信号的值是为0的,这种情况下,kill函数其实并不是真的向目标进程或进程组发送信号,而是用来检测目标进程或进程组是否存在。如果kill函数返回-1且errno为ESRCH,则可以断定我们关注的进程或进程组并不存在。
1 | if(kill(3423,SIGUSR1) == -1) |
Linux提供了tkill和tgkill两个系统调用来向某个线程发送信号:
1 | int tkill(int tid, int sig); |
这两个都是内核提供的系统调用,glibc并没有提供对这两个系统调用的封装,所以如果想使用这两个函数,需要采用syscall的方式,如下:
1 | ret = syscall(SYS_tkill,tid,sig) |
为什么有了tkill,还要引入tgkill?实际上,tkill是一个过时的接口,并不推荐使用它来向线程发送信号。相比之下,tgkill接口更加安全。tgkill系统调用的第一个参数tgid,为线程组中主线程的线程ID,或者称为进程号。这个参数表面看起来是多余的,其实它能起到保护的作用,防止向错误的线程发送信号。进程ID或线程ID这种资源是由内核负责管理的,进程(或线程)有自己的生命周期,比如向线程ID为1234的线程发送信号时,很可能线程1234早就退出了,而线程ID 1234恰好被内核分配给了另一个不相干的进程。这种情况下,如果直接调用tkill,就会将信号发送到不相干的进程上。为了防止出现这种情况,于是内核引入了tgkill系统调用,含义是向线程组ID是tgid、线程ID为tid的线程发送信号。这样,出现误杀的可能就几乎不存在了。
这两个函数都是Linux特有的,存在可移植性的问题。
raise函数
Linux提供了向进程自身发送信号的接口:raise函数,其定义如下:
1 |
|
这个接口对于单线程的程序而言,就相当于执行如下语句:
1 | kill(getpid(),sig) |
这个接口对于多线程的程序而言,就相当于执行如下语句:
1 | pthread_kill(pthread_self(),sig) |
执行成功的时候,返回0,否则返回非零的值,并置errno。如果sig的值是无效的,raise函数就将errno置为EINVAL。值得注意的是,信号处理函数执行完毕之后,raise才能返回。
sigqueue函数
在信号发送的方式当中,sigqueue算是后起之秀,传统的信号多用signal/kill这两个函数搭配,完成信号处理函数的安装和信号的发送。后来因为signal函数的表达力有限,控制不够精准,所以引入了sigaction函数来负责信号的安装,与其对应的是,引入了sigqueue函数来完成实时信号的发送。当然了,sigqueue函数也能发送非实时信号。sigqueue函数的接口定义如下:
1 |
|
sigqueue函数拥有和kill函数类似的语义,也可以发送空信号(信号0)来检查进程是否存在。和kill函数不同的地方在于,它不能通过将pid指定为负值而向整个进程组发送信号。比较有意思的是函数的第三个入参,它指定了信号的伴随数据(或者称为有效载荷,payload),该参数的数据类型是联合体,定义代码如下:
1 | union sigval { |
通过指定sigqueue函数的第三个参数,可以传递一个int值或指针给目标进程。考虑到不同的进程有各自独立的地址空间,传递指针到另一个进程几乎没有任何意义。因此sigqueue函数很少传递指针(sival_ptr),大多是传递整型(sival_int)。
尽管跨进程使用sigval中的指针sival_ptr没有任何意义,但sival_ptr字段并非百无一用。该字段可用于使用sigval联合体的其他函数中,如POSIX计时器的timer_create函数和POSIX消息队列中的mq_notify函数。
sigval联合体的存在,扩展了信号的通信能力。一些简单的消息传递完全可以使用sigqueue函数来进行。比如,通信双方事先定义某些事件为不同的int值,通过sigval联合体,将事件发送给目标进程。目标进程根据联合体中的int值来区分不同的事件,做出不同的响应。但是这种方法传递的消息内容受到了限制,不容易扩展,所以不宜作为常规的通信手段。
下面的例子会使用sigqueue函数向目标进程发送信号,其中目标进程、信号值和发送次数都可指定,发送信号的同时,也发送了伴随数据。
1 |
|
一般来说,sigqueue函数的黄金搭档是sigaction函数。在使用sigaction函数时,只要给成员变量sa_flags置上SA_SIGINFO的标志位,就可以使用三参数的信号处理函数来处理实时信号。
1 | struct sigaction act; |
siginfo_t结构体包含很多信息,目标进程可以通过该数据结构获取到如下的信息:
- si_signo:信号的值。
- si_code:信号来源,可以通过这个值来判断信号的来源,具体见表
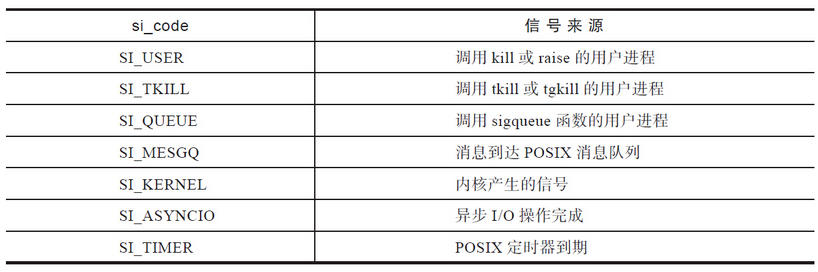
除此之外,一些特殊的信号会产生一些独特的si_code,来表示信号产生的根源或来源。例如,如果无效地址对齐引发SIGBUS信号,si_code就会被置为BUS_ADRALN等。想进一步了解详情,可以查看glibc的bits/siginfo.h头文件。
- si_value:sigqueue函数发送信号时所带的伴随数据。
- si_pid:信号发送进程的进程ID。
- si_uid:信号发送进程的真实用户ID。
- si_addr:仅针对硬件产生的信号SIGBUS、SIGFPE、SIGILL和SIGSEGV设置该字段,该字段表示无效的内存地址(SIGBUS和SIGSEGV)或导致信号产生的程序的指令地址(SIGFPE和SIGILL)。
三参数信号处理函数的第三个参数是void*类型的,其实它是一个ucontext_t类型的变量。
1 | typedef struct ucontext |
这个结构体提供了进程上下文的信息,用于描述进程执行信号处理函数之前进程所处的状态。通常情况下信号处理函数很少会用到这个变量,但是该变量也有很精妙的应用,如下面的例子。对于C程序员而言,基本每个人都会遇到段错误。一般情况下,段错误出现的原因是程序访问了非法的内存地址。当段错误发生时,操作系统会发送一个SIGSEGV信号给进程,导致进程产生核心转储文件并且退出。如何才能让进程先捕捉SIGSEGV信号,打印出有用的方便定位问题的信息,然后再优雅地退出呢?可以通过给SIGSEGV注册信号处理函数来实现,代码如下所示:
1 |
|
上面的函数利用了第三个参数里面的ucontext->uc_mcontext.rip字段,获取到了收到信号前的EIP寄存器的值,根据该值,可以将堆栈信息打印出来,输出如下:
1 | manu@manu-hacks:~/code/me/aple/chapter_05$ ./print_bt |
信号与线程
提到线程与信号的关系,必须先介绍下POSIX标准,POSIX标准对多线程情况下的信号机制提出了一些要求:
- 信号处理函数必须在多线程进程的所有线程之间共享,但是每个线程要有自己的挂起信号集合和阻塞信号掩码。
- POSIX函数kill/sigqueue必须面向进程,而不是进程下的某个特定的线程。
- 每个发给多线程应用的信号仅递送给一个线程,这个线程是由内核从不会阻塞该信号的线程中随意选出来的。
- 如果发送一个致命信号到多线程,那么内核将杀死该应用的所有线程,而不仅仅是接收信号的那个线程。
线程之间共享信号处理函数
对于进程下的多个线程来说,信号处理函数是共享的。在Linux内核实现中,同一个线程组里的所有线程都共享一个struct sighand结构体。该结构体中存在一个action数组,数组共64项,每一个成员都是k_sigaction结构体类型,一个k_sigaction结构体对应一个信号的信号处理函数。相关数据结构定义如下(这与架构相关,这里给出的是x86_64位下的定义):
1 | struct sigaction { |
多线程的进程中,信号处理函数相关的数据结构如图所示。
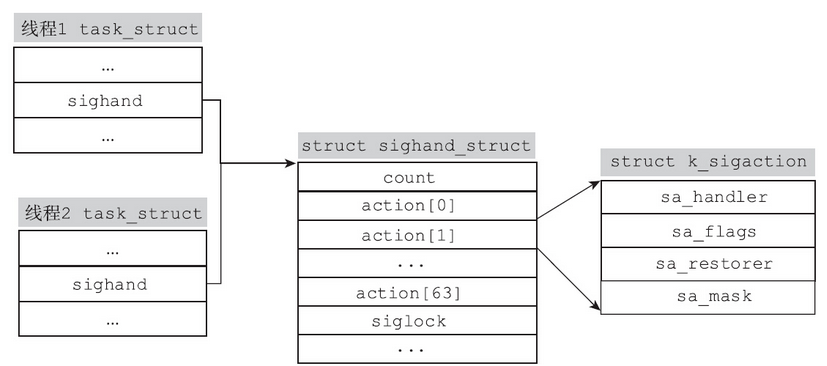
内核中k_sigaction结构体的定义和glibc中sigaction函数中用到的struct sigaction结构体的定义几乎是一样的。通过sigaction函数安装信号处理函数,最终会影响到进程描述符中的sighand指针指向的sighand_struct结构体对应位置上的action成员变量。在创建线程时,最终会执行内核的do_fork函数,由do_fork函数走进copy_sighand来实现线程组内信号处理函数的共享。创建线程时,CLONE_SIGHAND标志位是置位的。创建线程组的主线程时,内核会分配sighand_struct结构体;创建线程组内的其他线程时,并不会另起炉灶,而是共享主线程的sighand_struct结构体,只须增加引用计数而已。
1 | static int copy_sighand(unsigned long clone_flags, struct task_struct *tsk) |
线程有独立的阻塞信号掩码
每个线程都拥有独立的阻塞信号掩码。在介绍这条性质之前,首先需要介绍什么是阻塞信号掩码。就像我们开重要会议时要关闭手机一样,进程在执行某些重要操作时,不希望内核递送某些信号,阻塞信号掩码就是用来实现该功能的。如果进程将某信号添加进了阻塞信号掩码,纵然内核收到了该信号,甚至该信号在挂起队列中已经存在了相当长的时间,内核也不会将信号递送给进程,直到进程解除对该信号的阻塞为止。开会时关闭手机是一种比较极端的例子。更合理的做法是暂时屏蔽部分人的电话。对于某些重要的电话,比如儿子老师的电话、父母的电话或老板的电话,是不希望被屏蔽的。信号也是如此。进程在执行某些操作的时候,可能只需要屏蔽一部分信号,而不是所有信号。为了实现掩码的功能,Linux提供了一种新的数据结构:信号集。多个信号组成的集合被称为信号集,其数据类型为sigset_t。在Linux的实现中,sigset_t的类型是位掩码,每一个比特代表一个信号。Linux提供了两个函数来初始化信号集,如下:
1 |
|
sigemptyset函数用来初始化一个空的未包含任何信号的信号集,而sigfillset函数则会初始化一个包含所有信号的信号集。
必须要调用这两个初始化函数中的一个来初始化信号集,对于声明了sigset_t类型的变量,不能一厢情愿地假设它是空集合,也不能调用memset函数,或者用赋值为0的方式来初始化。
初始化信号之后,Linux提供了sigaddset函数向信号集中添加一个信号,同时还提供了sigdelset函数在信号集中移除一个信号:
1 | int sigaddset(sigset_t *set, int signum); |
为了判断某一个信号是否属于信号集,Linux提供了sigismember函数:
1 | // 如果signum属于信号集,则返回1,否则返回0。出错的时候,返回-1。 |
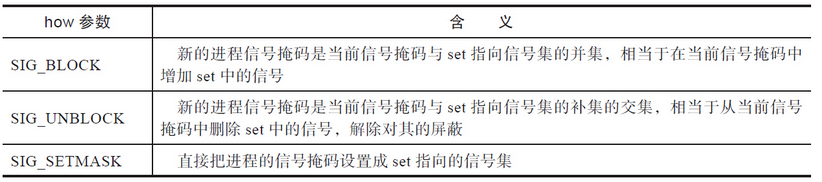
有了信号集,就可以使用信号集来设置进程的阻塞信号掩码了。Linux提供了sigprocmask函数来做这件事情:
1 |
|
sigprocmask根据how的值,提供了三种用于改变进程的阻塞信号掩码的方式,见表
我们知道SIGKILL信号和SIGSTOP信号不能阻塞,可是如果调用sigprocmask函数时,将SIGKILL信号和SIGSTOP信号添加进阻塞信号集中,会怎么样?答案是不怎么样。sigprocmask函数不会报错,但是也不会将SIGKILL和SIGSTOP真的添加进阻塞信号集中。对应的rt_sigprocmask系统调用会执行如下语句,剔除掉集合中的SIGKILL和SIGSTOP:
1 | sigdelsetmask(&new_set, sigmask(SIGKILL)|sigmask(SIGSTOP)); |
对于多线程的进程而言,每一个线程都有自己的阻塞信号集:
1 | struct task_struct{ |
sigprocmask函数改变的是调用线程的阻塞信号掩码,而不是整个进程。sigprocmask出现得比较早,它出现在线程尚未引入Linux的时代。在单线程的时代,进程的阻塞信号掩码和线程的阻塞掩码是一回事,但是引入多线程之后,sigprocmask的语义就变成了设置调用线程的阻塞信号掩码。为了更显式地设置线程的阻塞信号掩码,线程库提供了pthread_sigmask函数来设置线程的阻塞信号掩码:
1 |
|
事实上pthread_sigmask函数和sigprocmask函数的行为是一样的。
私有挂起信号和共享挂起信号
POSIX标准中有如下要求:对于多线程的进程,kill和sigqueue发送的信号必须面对所有的线程,而不是某个线程,内核是如何做到的呢?而系统调用tkill和tgkill发送的信号,又必须递送给进程下某个特定的线程。内核又是如何做到的呢?
前面简单提到过内核维护有挂起队列,尚未递送进程的信号可以挂入挂起队列中。有意思的是,内核的进程描述符task_struct之中,维护了两套sigpending,代码如下所示:
1 | struct task_struct{ |
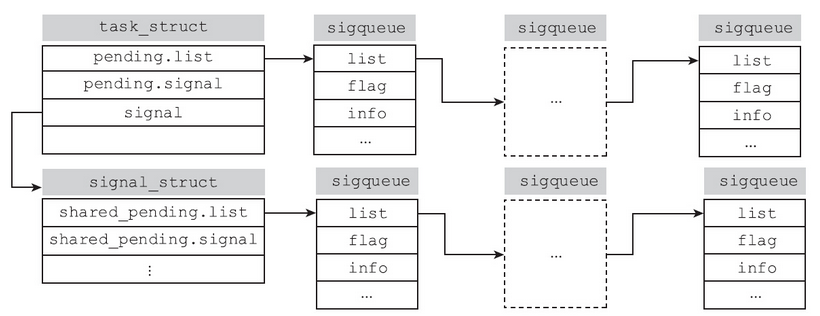
内核就是靠这两个挂起队列实现了POSIX标准的要求。在Linux实现中,线程作为独立的调度实体也有自己的进程描述符。Linux下既可以向进程发送信号,也可以向进程中的特定线程发送信号。因此进程描述符中需要有两套sigpending结构。其中task_struct结构体中的pending,记录的是发送给线程的未决信号;而通过signal指针指向signal_struct结构体的shared_pending,记录的是发送给进程的未决信号。每个线程都有自己的私有挂起队列(pending),但是进程里的所有线程都会共享一个公有的挂起队列(shared_pending)。
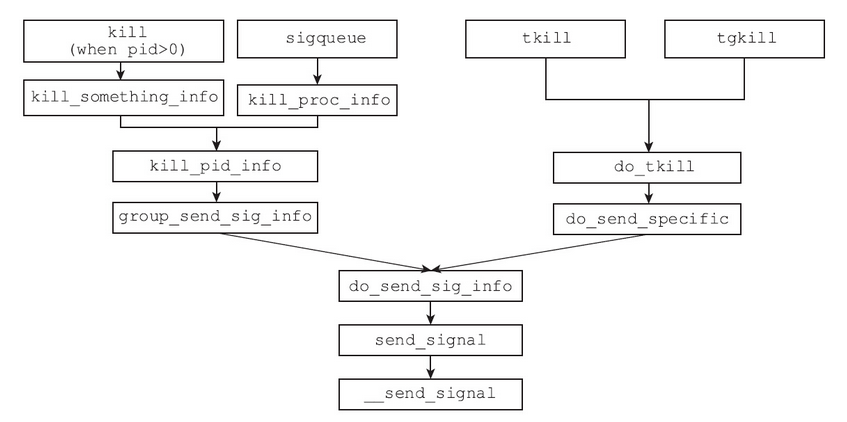
上图描述的是通过kill、sigqueue、tkill和tgkill发送信号后,内核的相关处理流程。从图中可以看出,向进程发送信号也好,向线程发送信号也罢,最终都殊途同归,在do_send_sig_info函数处会师。尽管会师在一处,却还是存在不同。不同的地方在于,到底将信号放入哪个挂起队列。在__send_signal函数中,通过group入参的值来判断需要将信号放入哪个挂起队列(如果需要进队列的话)。
1 | static int __send_signal(int sig, struct siginfo *info, struct task_struct *t, |
如果用户调用的是kill或sigqueue,那么group就是1;如果用户调用的是tkill或tgkill,那么group参数就是0。内核就是以此来区分该信号是发给进程的还是发给某个特定线程的,如表所示。

上述情景并不难理解。多线程的进程就像是一个班级,进程下的每一个线程就像是班级的成员。kill和sigqueue函数发送的信号是给进程的,就像是优秀班集体的荣誉是颁发给整个班级的;tkill和tgkill发送的信号是给特定线程的,就像是三好学生的荣誉是颁发给学生个人的。另一个需要解决的问题是,多线程情况下发送给进程的信号,到底由哪个线程来负责处理?这个问题就和高二(五)班荣获优秀班集体,由谁负责上台领奖一样。内核是不是一定会将信号递送给进程的主线程?答案是不一定。尽管如此,Linux还是采取了尽力而为的策略,尽量地尊重函数调用者的意愿,如果进程的主线程方便的话,则优先选择主线程来处理信号;如果主线程确实不方便,那就有可能由线程组里的其他线程来负责处理信号。
户在调用kill/sigqueue函数之后,内核最终会走到__send_signal函数。在该函数的最后,由complete_signal函数负责寻找合适的线程来处理该信号。因为主线程的线程ID等于进程ID,所以该函数会优先查询进程的主线程是否方便处理信号。如果主线程不方便,则会遍历线程组中的其他线程。如果找到了方便处理信号的线程,就调用signal_wake_up函数,唤醒该线程去处理信号。
1 | signal_wake_up(t, sig == SIGKILL); |
如果线程组内全都不方便处理信号,complete函数也就当即返回了。如何判断方便不方便?内核通过wants_signal函数来判断某个调度实体是否方便处理某信号:
1 | static inline int wants_signal(int sig, struct task_struct *p) |
glibc提供了一个API来获取当前线程的阻塞挂起信号,如下:
1 |
|
该函数很容易产生误解,很多人认为该接口返回的是线程的挂起信号,即还没有来得及处理的信号,这种理解其实是错误的。严格来讲,返回的信号集中的信号必须同时满足以下两个条件:
- 处于挂起状态。
- 信号属于线程的阻塞信号集。
看下内核的do_sigpending函数的内容就不难理解sigpending函数的含义了:
1 | spin_lock_irq(¤t->sighand->siglock); |
因此,返回的挂起阻塞信号集合的计算方式是:
(1)进程共享的挂起信号和线程私有的挂起信号取并集,得到集合1。
(2)对集合1和线程的阻塞信号集取交集,以获得最终的结果。
从此处可以看出,sigprocmask函数会影响到sigpendig函数的输出结果。
致命信号下进程组全体退出
关于进程的退出,前面已经有所提及,Linux为了应对多线程,提供了exit_group系统调用,确保多个线程一起退出。对于线程收到致命信号的这种情况,操作是类似的。可以通过给每个调度实体的pending上挂上一个SIGKILL信号以确保每个线程都会退出。此处就不再赘述了。
等待信号
有时候,需要等待某种信号的发生。POSIX中的pause、sigsuspend和sigwait函数提供了三种方法,可以将进程暂时挂起,等待信号来临。
pause函数
pause函数将调用线程挂起,使进程进入可中断的睡眠状态,直到传递了一个信号为止。这个信号的动作或者是执行用户定义的信号处理函数,或者是终止进程。如果是执行用户自定义的信号处理函数,那么pause会在信号处理函数执行完毕后返回;如果是终止进程,pause函数就不返回了。如果内核发出的信号被忽略,那么进程就不会被唤醒。pause函数的定义如下:
1 |
|
比较有意思的是,pause函数如果可以返回,那它总是返回-1,并且errno为EINTR。
如果希望pause函数等待某个特定的信号,就必须确定哪个信号会让pause返回。事实上,pause并不能主动区分使pause返回的信号是不是正在等待的信号,我们必须间接地完成这个任务。常用的方法是,在期待的特定信号的信号处理函数中,将某变量的值设置为1,待pause返回后,通过查看该变量的值是否为1来判定等待的特定信号是否被捕获,方法如下面的代码所示:
1 | static volatile sig_atomic_t sig_received_flag = 0; |
看起来很美好,可是上面的逻辑是有漏洞的。检查sig_received_flag==0和调用pause之间存在一个时间窗口,如果在该时间窗口内收到信号,并且信号处理函数将sig_received_flag置1,那么主控制流根本就不知道这件事情,进程就会依然阻塞。也就是说,等待的信号已经到来,但是进程错过了。在收到下一个信号之前,pause函数不会返回,进程也就没有机会发现其实在等待的信号早就已经收到了。因为检查和pause之间存在时间窗口,所以就有了错失信号的情况。

下面通过另一个例子来描述一下pause的困境。程序执行过程中,关键部分不期望被信号打断,于是临时阻塞信号,关键部分完成之后,就解除信号的阻塞,然后暂停执行直到有信号到达为止:
1 | /*关键代码结束*/ |
可以看到解除对特定信号的阻塞之后,调用pause之前,信号已经被递送给进程,这个信号已经错失了,pause无法等到这个信号,直到下一个信号递送给进程为止,pause函数都无法返回。这就违背了代码的本意:解除对信号的阻塞并且等待该信号的第一次出现。要避免这种情况,必须将解除信号阻塞和挂起进程等待信号这两个动作封装成一个原子操作。这就是引入sigsuspend系统调用的原因。
sigsuspend函数
在pause之前传递信号是Linux早期遇到的一个困境,并没有好办法来解决这个问题。从本质上讲,必须将解除对信号的阻塞和挂起进程以等待信号的形式封装成一个原子操作,才能解决该问题,而sigsuspend函数就是为了解决这个难题而生的。sigsuspend函数的定义如下:
1 |
|
如果信号终止了进程,那么sigsuspend函数不会返回。如果内核将信号递送给进程,并执行了信号处理函数,那么sigsuspend函数返回-1,并置errno为EINTR。如果mask指针指向的地址不是合法地址,那么sigsuspend函数返回-1,并置errno为EFAULT。sigsuspend函数用mask指向的掩码来设置进程的阻塞掩码,并将进程挂起,直到进程捕捉到信号为止。一旦从信号处理函数中返回,sigsuspend函数就会把进程的阻塞掩码恢复为调用之前的老的阻塞掩码值。
简单地说,sigsuspend相当于以不可中断的方式执行下面的操作:
1 | sigprocmask(SIG_SETMASK,&mask,&old_mask); |
有了sigsuspend函数,就可以完成pause()完成不了的任务了
1 | static volatile sig_atomic_t sig_received_flag = 0; |
假定等待特定信号SIGUSR1,首先要将所有的信号屏蔽掉,如果屏蔽信号之前,已经收到了SIGUSR1,那么sig_received_flag会被设置为1,此时就不需要再调用sigsuspend了,我们已经等到了要等的信号SIGUSR1。如果没收到,则调用sigsuspend,将阻塞掩码设为mask_most,即将所有信号都屏蔽,只有SIGUSR1未被屏蔽。sigsuspend返回时,我们就可以确定,收到了信号SIGUSR1。此时,阻塞掩码也已经恢复成调用sigsuspend之前的mask_all了,然后显式地将阻塞掩码恢复成默认的阻塞掩码mask_old。
等一等,类似于上一节的代码,在判断之后、pause之前,有信号递送,会导致信号错失,那么在上面的代码中,判断sig_received_flag==1之后,调用sigsuspend函数之前,是否会有SIGUSR1被递送给进程,再次导致错失信号一次?答案是否定的,因为我们已经通过setprocmask函数阻塞了所有的信号,因此SIGUSR1没有机会被递送给进程。上面的代码虽然完成了等待某特定信号的任务,但是它也有副作用,就是在等待特定信号期间,所有的其他信号都不能递送,原因是sigsuspend的mask阻塞了SIGUSR1以外的所有信号,导致其他信号无法正常递送。下面的代码对这种情况做了改进:
1 | static volatile sig_atomic_t sig_received_flag = 0; |
上面的例子不仅做到了等待特定信号SIGUSR1,而且期间如果有其他信号,也不会影响其他信号的递送。至此等待特定信号的任务算是圆满地解决了。
sigwait函数和sigwaitinfo函数
sigsuspend函数可以实现等待特定信号的任务,但是上面的示例过于繁复,不够直接。sigwait系列函数就可以比较优雅地等待某个特定信号的到来。sigwait系列函数提供了一种同步接收信号的机制,代码如下:
1 |
|
这三个函数虽然接口上有差异,但是总体来说做的事情是一样的。信号集set里面的信号是进程关心的信号。当调用sigwait系列函数中的任何一个时,内核会查看进程的信号挂起队列(包括私有挂起队列和线程组共享的挂起队列),检查set中是否有信号处于挂起状态。如果有,那么sigwait相关的函数会立刻返回,并将信号从相应的挂起队列中移除;如果没有,进程就会陷入阻塞,进入可中断的睡眠状态,直到进程醒来,再次检查挂起队列。
上面是这三个函数的共同之处,不过它们在接口设计上有些许差异。
- sigwait函数成功返回时,返回值是0,并将导致函数返回的信号记录在sig指向的地址中。如果sigwait调用失败,则返回值不是-1,而是直接将errno返回。
- sigwaitinfo函数是升级加强版的sigwait,通过它可以获取到信号相关的更多信息。当第二个siginfo_t结构体类型的指针info不是NULL时,内核会将信号相关的信息填入该指针指向的地址,从而获得导致函数返回的信号的详细信息。和sigwait函数不同,如果sigwaitinfo函数成功返回,那么返回值则是导致函数返回的信号的值(signo),而不是0;如果sigwaitinfo函数失败,则会返回-1,并置errno。
- sigtimedwait函数和sigwaitinfo函数几乎是一样的,除了前者约定了一个timeout时间之外。如果到了timeout时间,还未等到set中的信号,sigtimedwait就不再继续等待了,而是返回-1,并置errno为EAGAIN。
sigwait系列函数的本质是同步等待信号的到达,所以不需要编写信号处理函数。需要提示的是,纵然某信号遭到了阻塞,sigwaitinfo依然可以获取等待信号。看到这里,不知道读者有没有意识到,引入了sigwait系列函数之后,其实也引入了竞争。正常的信号处理流程,会从信号挂起队列中摘取信号递送给进程,而sigwait函数也会从信号挂起队列中摘取信号,返回给调用进程,两者成了抢生意的关系。
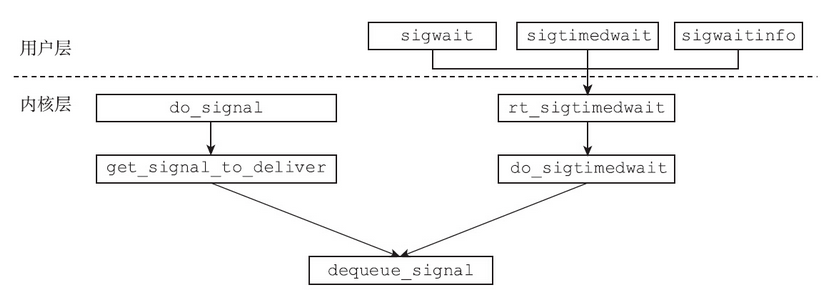
所以在调用sigwait系列函数之前,首先需要将set中的信号阻塞,并将set中信号的独家经营权拿到手,否则,如果调用sigwaitinfo之前或两次sigwaitinfo之间有信号到达,很有可能会被正常地递送给进程,进而执行注册的信号处理函数(如果有的话)或执行默认操作SIG_DFL。sigwait系列函数的典型使用方式如下:
1 | int sigusr1 = 0; |
上面这个例子是统计收到SIGUSR1的次数。在调用sigwaitinfo之前,需要先调用sigprocmask将等待的信号屏蔽。sigtimedwait函数的用法和sigwaitinfo函数类似,只不过timeout参数指定了最大的等待时长。如果调用超时却没有等到任何信号,那么sigtimedwait就返回-1,并且设errno为EAGAIN。最后,SIGKILL和SIGSTOP不能等待,尝试等待SIGKILL和SIGSTOP会被忽略。原因和无法更改SIGKILL和SIGSTOP信号的信号处理函数一样。
通过文件描述符获取信号
从内核2.6.22版本开始,Linux提供了另外一种机制来接收信号:通过文件描述符来获取信号即signalfd机制。这个机制和sigwaitinfo非常地类似,都属于同步等待信号的范畴,都需要首先调用sigprocmask将关注的信号屏蔽,以防止被信号处理函数劫走。不同之处在于,文件描述符方法提供了文件系统的接口,可以通过select、poll和epoll来监控这些文件描述符。signalfd接口的定义如下:
1 |
|
其中,mask参数是信号集,表示关注信号的集合。这些信号的集合应该在调用signalfd函数之前,先调用sigprocmask函数阻塞这些信号,以防止被信号处理函数劫走。首次创建时fd参数应该为-1,该函数会创建一个文件描述符,用于读取mask中到来的信号。如果fd不是-1,则表示是修改操作,一般是修改mask的值,此时fd是之前调用signalfd时返回的值。第三个参数flags用来控制行为,目前支持的标志位如下。
- SFD_CLOEXEC:和普通文件的O_CLOEXEC一样,调用exec函数时,文件描述符会被关闭。
- SFD_NONBLOCK:控制将来的读取操作,如果执行read操作时,并没有信号到来,则立刻返回失败,并设置errno为EAGAIN。
创建文件描述符后,可以使用read函数来读取到来的信号。提供的缓冲区大小一般要足以放下一个signalfd_siginfo结构体,该结构体一般包括如下成员变量:
1 | struct signalfd_siginfo { |
这个结构体和前面提到的siginfo_t结构体几乎可以一一对应。含义和siginfo_t中的成员也一样,在此就不再赘述了。使用signalfd来接收信号的方法如下(此处忽略了一些异常处理):
1 | sigprocmask(SIG_BLOCK,&mask,NULL); |
比较推荐的做法是用文件描述符signalfd和sigwaitinfo两种方法来处理信号,使用传统信号处理函数会因为异步带来很多问题,大量的函数因不是异步信号安全的,而无法用于信号处理函数。本节介绍的signalfd方法更加值得推荐,因为方法简单,且可以和select、poll和epoll函数配合使用,非常灵活。
信号传递顺序
有一个非常有意思的话题,当有多个处于挂起状态的信号时,信号递送的顺序又是如何的呢?信号实质上是一种软中断,中断有优先级,信号也有优先级。如果一个进程有多个未决信号,那么对于同一个未决的实时信号,内核将按照发送的顺序来递送信号。如果存在多个未决的实时信号,那么值(或者说编号)越小的越优先被递送。如果既存在不可靠信号,又存在可靠信号(实时信号),虽然POSIX对这一情况没有明确规定,但Linux系统和大多数遵循POSIX标准的操作系统一样,即将优先递送不可靠信号。虽然是优先递送不可靠信号,但在不可靠信号中,不同信号的优先级又是如何的呢?内核如何实现这些这些优先级的顺序呢?内核选择信号递送给进程的流程如图所示。

下面来分析相关的代码:
1 | int dequeue_signal(struct task_struct *tsk, sigset_t *mask, siginfo_t *info) |
前文讲过,线程的挂起信号队列有两个:线程私有的挂起队列(pending)和整个线程组共享的挂起队列(signal->shared_pending)。如上面的代码所示,选择信号的顺序是优先从私有的挂起队列中选择,如果没有找到,则从线程组共享的挂起队列中选择信号递送给线程。当然选择的时候需要考虑线程的阻塞掩码,属于阻塞掩码集中的信号不会被选出。在挂起信号队列(无论是共享挂起队列还是私有挂起队列)中,选择信号的工作交给了next_signal函数,其逻辑如下:
1 | int next_signal(struct sigpending *pending, sigset_t *mask) |
由于不同平台long的长度不同,所以算法略有不同,但是思想是一样的,如下。
(1)出现在阻塞掩码集中的信号不能被选出。
(2)优先选择同步信号,所谓同步信号指的是以下6种信号:
1 | {SIGSEGV,SIGBUS,SIGILL,SIGTRAP,SIGFPE,SIGSYS}, |
这6种信号都是与硬件相关的信号。
(3)如果没有上面6种信号,非实时信号优先;如果存在多种非实时信号,小信号值的信号优先。
(4)如果没有非实时信号,那么实时信号按照信号值递送,小信号值的信号优先递送。
异步信号安全
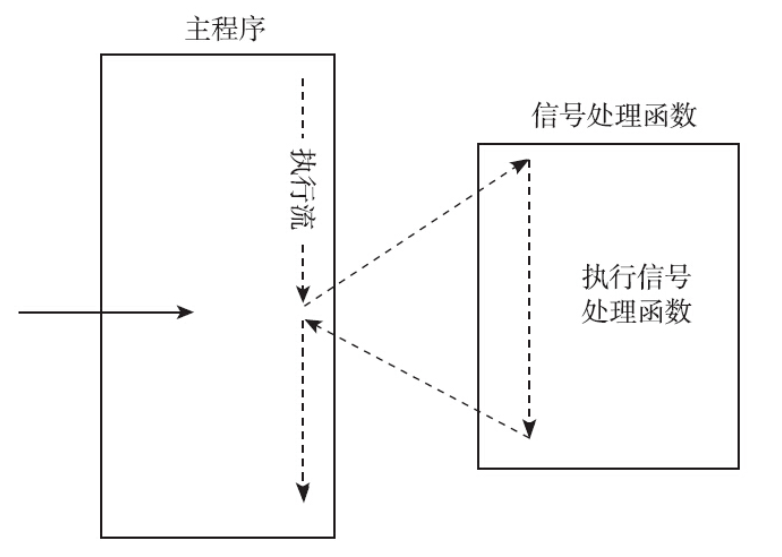
设计信号处理函数是一件很头疼的事情,原因就藏在下图中。当内核递送信号给进程时,进程正在执行的指令序列就会被中断,转而执行信号处理函数。待信号处理函数执行完毕返回(如果可以返回的话),则继续执行被中断的正常指令序列。此时,问题就来了,同一个进程中出现了两条执行流,而两条执行流正是信号机制众多问题的根源。
在信号处理函数中有很多函数都不可以使用,原因就是它们并不是异步信号安全的,强行使用这些不安全的函数隐患重重,还可能带来很诡异的bug。引入多线程后,很多库函数为了保证线程安全,不得不使用锁来保护临界区。比如malloc就是一种典型的场景。
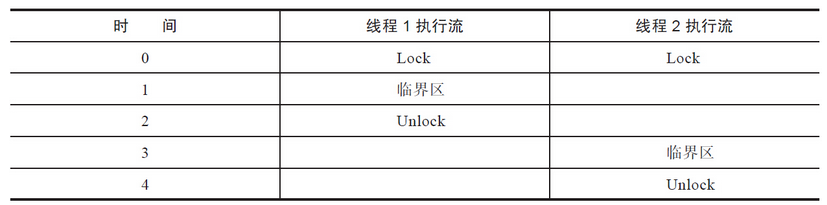
加锁保护临界区的方法,虽然不可重入,却是实现线程安全的一种选择。但是这种方法无法保证异步信号安全见表。

还是以malloc为例,如果主程序执行流调用malloc已经持有了锁,但是尚未完成临界区的操作,这时候被信号中断,转而执行信号处理函数,如果信号处理函数中再次调用malloc加锁,就会发生死锁。从上面的讨论可以看出,异步信号安全是一个很苛刻的条件。事实上只有非常有限的函数才能保证异步信号安全。
一般说来,不安全的函数大抵上可以分为以下几种情况:
- 使用了静态变量,典型的是strtok、localtime等函数。
- 使用了malloc或free函数。
- 标准I/O函数,如printf。
读者可以通过man 7 signal的Async-signal-safe functions小节查看异步信号安全的函数列表,在此就不罗列了。本书中有很多地方在信号处理函数中调用了printf函数,其实这是不对的,在真正的工程代码中,是不允许非异步信号安全的函数出现在信号处理函数中的。在正常程序流里面工作得很正常的函数,在异步信号的条件下,会出现很诡异的bug。这种bug的触发,经常依赖信号到达的时间、进程调度等不可控制的时序条件,很难重现。因此编写信号处理函数就像将船驶入暗礁丛生的海域,不可不小心。既然陷阱重重,那该如何使用信号机制呢?
轻量级信号处理函数
这是一种比较常见的做法,就是信号处理函数非常短,基本就是设置标志位,然后由主程序执行流根据标志位来获知信号已经到达。这种做法可用伪代码的形式表示,如下:
1 | volatile sig_atomic_t get_SIGINT = 0; |
这是一种常见的设计,信号处理函数非常简单,非常轻量,仅仅是设置了一个标志位。程序的主流程会周期性地检查标志,以此来判断是否收到某信号。若收到信号,则执行相应的操作,通常也会将标志重新清零。一般来讲定义标志的时候,会将标志的类型定义成:
1 | volatile sig_atomic_t flag; |
sig_atomic_t是C语言标志定义的一种数据类型,该数据类型可以保证读写操作的原子性。而volatile关键字则是告诉编译器,flag的值是易变的,每次使用它的时候,都要到flag的内存地址去取。之所以这么做,是因为编译器会做优化,编译器如果发现两次取flag值之间,并没有代码修改过flag,就有可能将上一次的flag值拿来用。而由于主程序和信号处理不在一个控制流之中,因此编译器几乎总是会做这种优化,这就违背了设计的本意。因此使用volatile来保证主程序流能够看到信号处理函数对flag的修改。
化异步为同步
由于信号处理函数的存在,进程会同时存在两条执行流,这带来了很多问题,因此操作系统也想了一些办法,就是前面提到的sigwait和signalfd机制。sigwait的设计本意是同步地等待信号。在执行流中,执行sigwait函数会陷入阻塞,直到等待的信号降临。一般来讲,sigwait用在多线程的程序中,而等待信号降临的使命,一般落在主线程身上。具体做法如下:
1 | sigfillset(&set_all); |
sigwait虽然化异步为同步,但是也废掉了一条执行流。signalfd机制则提供了另外一种思路:
1 |
|
具体步骤如下:
(1)将关心的信号放入集合。
(2)调用sigprocmask函数,阻塞关心的信号。
(3)调用signalfd函数,返回一个文件描述符。有了文件描述符,就可以使用select/poll/epoll等I/O多路复用函数来监控它。
这样,当信号来临时,就可以通过read接口来获取到信号的相关信息:
1 | struct signalfd_info signalfd_info; |
在引入signalfd机制以前,有一种很有意思的化异步为同步的方式被广泛使用。这种技术被称为“self-pipe trick”。简单地讲,就是打开一个无名管道,在信号处理函数中向管道写入一个字节(write函数是异步信号安全的),而主程序从无名管道中读取一个字节。通过这种方式也做到了在主程序流中处理信号的目的。
《Linux高性能服务器编程》一书中,在“统一事件源”一节中详细介绍了这个技术。不过使用的不是无名管道,而是socketpair函数。
1 | static int pipefd[2] |
将socketpair的一端置于select/poll/epoll等函数的监控下,当信号到达的时候,信号处理函数会往socketpair的另一端写入1个字节,即信号的值。此时,主程序的select/poll/epoll函数就能侦测到此事,对socketpair执行recv操作,获取到信号处理函数写入的信号值,进行相应的处理。
标准库
在 Linux 和其他类 UNIX 系统中,硬件异常信号用于通知进程发生了特定的硬件异常。这些信号通常由内核在检测到某些错误条件时发送给进程。以下是常见的硬件异常信号及其解析:
显式地忽略信号(ignore)
内核将会丢弃该信号,信号不会对目标进程产生任何影响。
忽略信号
忽略信号意味着进程在接收到信号时不执行默认动作或自定义处理程序。可以通过使用 signal 或 sigaction 系统调用将信号的处理程序设置为 SIG_IGN 来忽略信号。例如:
1 |
|
SIGHUP (Hangup)
- 信号编号: 通常为 1。
- 描述: 挂起信号。最初用于通知终端断开连接。对于守护进程,通常表示需要重新读取配置文件或重新启动。
- 默认处理: 终止进程。
- 忽略用途: 如果不希望进程在终端断开连接时被终止,可以选择忽略 SIGHUP。对于守护进程,通常会捕获此信号来实现配置重读,而不是忽略。
SIGURG (Urgent Condition)
- 信号编号: 通常为 23。
- 描述: 紧急条件信号。用于通知进程在套接字上有紧急数据可读(如带外数据)。
- 默认处理: 忽略。
- 忽略用途: 默认情况下,SIGURG 已经被忽略。如果应用程序不处理带外数据,可以继续忽略此信号。
SIGWINCH (Window Change)
- 信号编号: 通常为 28。
- 描述: 窗口大小改变信号。当终端窗口的大小发生变化时,系统会向前台进程组发送此信号。
- 默认处理: 忽略。
- 忽略用途: 如果应用程序不关心终端窗口大小的变化,可以忽略此信号。然而,许多终端应用程序会捕获此信号来调整显示内容。
终止进程(terminate)
在 Linux 系统中,许多信号的默认行为是终止进程。这些信号通常用于通知进程发生了特定事件,进程可以选择捕获这些信号以执行自定义的处理逻辑,或者允许它们按照默认行为终止进程。以下是一些默认会终止进程的信号解析:
SIGHUP (Hangup)
- 信号编号: 1
- 描述: 通知终端断开连接。对于守护进程,通常表示需要重新加载配置。
- 默认处理: 终止进程。
SIGINT (Interrupt)
- 信号编号: 2
- 描述: 由用户通过终端生成的中断信号(通常是 Ctrl+C)。
- 默认处理: 终止进程。
SIGKILL (Kill)
- 信号编号: 9
- 描述: 强制终止进程,无法被捕获、阻塞或忽略。
- 默认处理: 立即终止进程。
SIGUSR1 (User-defined Signal 1)
- 信号编号: 10
- 描述: 用户自定义信号,通常用于应用程序内部的自定义事件。
- 默认处理: 终止进程。
SIGUSR2 (User-defined Signal 2)
- 信号编号: 12
- 描述: 用户自定义信号,类似于 SIGUSR1。
- 默认处理: 终止进程。
SIGPIPE (Broken Pipe)
- 信号编号: 13
- 描述: 当进程向一个没有读端的管道写入数据时触发。
- 默认处理: 终止进程。
SIGALRM (Alarm Clock)
- 信号编号: 14
- 描述: 由
alarm系统调用设置的计时器到期时产生。 - 默认处理: 终止进程。
SIGTERM (Termination)
- 信号编号: 15
- 描述: 请求进程终止,通常用于正常的进程关闭。
- 默认处理: 终止进程。
SIGSTKFLT (Stack Fault)
- 信号编号: 16
- 描述: 与协处理器相关的堆栈错误(在现代 Linux 系统中很少使用)。
- 默认处理: 终止进程。
SIGVTALRM (Virtual Alarm Clock)
- 信号编号: 26
- 描述: 虚拟计时器到期。
- 默认处理: 终止进程。
SIGPROF (Profiling Timer Expired)
- 信号编号: 27
- 描述: 分析计时器到期。
- 默认处理: 终止进程。
SIGIO (I/O Now Possible)
- 信号编号: 29
- 描述: 通知进程可以执行非阻塞 I/O 操作。
- 默认处理: 终止进程。
SIGPWR (Power Failure)
- 信号编号: 30
- 描述: 电源故障警告(通常不常用)。
- 默认处理: 终止进程。
信号处理建议
- 捕获和处理信号: 可以通过
signal或sigaction函数捕获信号并定义自定义处理程序,以便在信号发生时执行特定操作,而不是终止进程。 - 忽略信号: 某些信号可以被忽略(如 SIGHUP、SIGINT),但不建议忽略所有信号,尤其是 SIGKILL 和 SIGTERM,因为它们用于进程的正常关闭。
- 调试和日志记录: 在信号处理程序中添加日志记录,以帮助调试和分析信号触发的原因和上下文。
通过合理地处理这些信号,可以提高程序的健壮性和稳定性,确保在各种情况下都能正常运行或安全终止。
生成核心转储文件并终止进程(core)
在 Linux 中,当某些信号导致进程终止时,系统会生成一个核心转储文件(core dump),该文件包含进程的内存映像和调试信息。这对于调试和分析进程崩溃的原因非常有用。以下是一些默认情况下会生成核心转储文件并终止进程的信号:
SIGQUIT (Quit)
- 信号编号: 3
- 描述: 由用户发出的退出信号(通常是 Ctrl+\),用于请求进程退出并生成核心转储。
- 默认处理: 生成核心转储文件并终止进程。
SIGILL (Illegal Instruction)
- 信号编号: 4
- 描述: 非法指令信号,通常由于执行了非法或未定义的 CPU 指令。
- 默认处理: 生成核心转储文件并终止进程。
SIGTRAP (Trace/Breakpoint Trap)
- 信号编号: 5
- 描述: 断点陷阱,通常用于调试器中。
- 默认处理: 生成核心转储文件并终止进程。
SIGABRT (Abort)
- 信号编号: 6
- 描述: 由调用
abort()函数触发,表示进程异常终止。 - 默认处理: 生成核心转储文件并终止进程。
SIGBUS (Bus Error)
- 信号编号: 7
- 描述: 总线错误,通常由于内存访问对齐错误。
- 默认处理: 生成核心转储文件并终止进程。
SIGFPE (Floating Point Exception)
- 信号编号: 8
- 描述: 浮点异常,例如除以零或浮点溢出。
- 默认处理: 生成核心转储文件并终止进程。
SIGSEGV (Segmentation Fault)
- 信号编号: 11
- 描述: 段错误,通常由于非法内存访问。
- 默认处理: 生成核心转储文件并终止进程。
SIGXCPU (CPU Time Limit Exceeded)
- 信号编号: 24
- 描述: 超过 CPU 时间限制。
- 默认处理: 生成核心转储文件并终止进程。
SIGXFSZ (File Size Limit Exceeded)
- 信号编号: 25
- 描述: 超过文件大小限制。
- 默认处理: 生成核心转储文件并终止进程。
SIGSYS (Bad System Call)
- 信号编号: 31
- 描述: 错误的系统调用。
- 默认处理: 生成核心转储文件并终止进程。
核心转储文件的使用
启用核心转储: 默认情况下,核心转储可能被限制或禁用。可以使用
ulimit -c命令来查看或设置核心转储文件的大小限制。例如,ulimit -c unlimited可以允许生成不受限制大小的核心转储文件。分析核心转储: 核心转储文件通常用于调试崩溃问题。可以使用调试器(如
gdb)加载核心文件以查看崩溃时的调用栈和内存状态。例如:1
gdb /path/to/executable core
存储位置和命名: 核心转储文件的存储位置和命名可以通过
/proc/sys/kernel/core_pattern配置。可以自定义以便更好地管理和分析。
通过了解和处理这些信号,开发人员可以更有效地诊断和解决程序中的问题,从而提高软件的稳定性和可靠性。
停止进程(stop)
在 Linux 中,有一些信号用于停止(暂停)进程的执行。这些信号不会终止进程,而是将其暂停,直到收到继续执行的信号(如 SIGCONT)。以下是与停止进程相关的信号:
SIGSTOP (Stop)
- 信号编号: 19
- 描述: 无条件停止进程的执行。这个信号不能被捕获、阻塞或忽略。
- 默认处理: 暂停进程。
SIGTSTP (Terminal Stop)
- 信号编号: 20
- 描述: 由用户通过终端生成的停止信号(通常是 Ctrl+Z)。与 SIGSTOP 不同,这个信号可以被捕获或忽略。
- 默认处理: 暂停进程。
SIGTTIN (Terminal Input for Background Process)
- 信号编号: 21
- 描述: 当后台进程尝试从终端读取输入时触发。通常用于防止后台进程干扰前台任务。
- 默认处理: 暂停进程。
SIGTTOU (Terminal Output for Background Process)
- 信号编号: 22
- 描述: 当后台进程尝试向终端写入输出时触发。
- 默认处理: 暂停进程。
使用和管理
恢复进程: 一个被停止的进程可以通过发送 SIGCONT 信号来恢复执行。可以使用命令
kill -CONT <pid>来实现。信号处理: 虽然 SIGSTOP 不能被处理,但其他信号(如 SIGTSTP、SIGTTIN、SIGTTOU)可以被捕获和处理。开发人员可以实现自定义的信号处理程序,以便在这些信号触发时执行特定操作。
前后台任务管理: 这些信号在任务控制中非常有用,允许用户在前台和后台之间切换任务。例如,使用
fg命令可以将后台任务恢复到前台执行。
通过对这些信号的理解和管理,用户可以更有效地控制进程的执行流,特别是在需要暂停和恢复进程的场景中。
恢复进程的执行(continue)
在 Linux 中,SIGCONT 信号用于恢复一个被暂停的进程的执行。这个信号是任务控制的重要组成部分,允许用户在进程被暂停后继续其执行。
SIGCONT (Continue)
- 信号编号: 18
- 描述: 用于恢复一个被
SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU信号暂停的进程。 - 默认处理: 恢复进程的执行。如果进程之前处于暂停状态,那么它将继续运行。
- 捕获与处理:
SIGCONT可以被进程捕获和处理,这意味着进程可以在接收到SIGCONT时执行特定的操作。不过,默认行为是继续执行,不需要额外处理。
使用场景
恢复暂停的进程: 当一个进程被暂停(例如,通过
SIGSTOP或用户按下 Ctrl+Z 发送SIGTSTP),可以通过发送SIGCONT来恢复它。可以使用命令:1
kill -CONT <pid>
其中
<pid>是进程的 ID。任务控制: 在命令行中,用户可以使用
bg命令将暂停的任务放到后台继续执行,或使用fg命令将其恢复到前台。这些命令隐式地使用SIGCONT信号。信号处理: 虽然
SIGCONT的默认行为是继续执行,但进程可以设置一个信号处理程序来在接收到SIGCONT时执行一些恢复操作,如重新初始化某些资源或状态。
示例
假设你有一个正在运行的进程,你可以通过以下步骤暂停并恢复它:
- 暂停进程: 使用
kill -STOP <pid>或在终端中按下Ctrl+Z。 - 恢复进程: 使用
kill -CONT <pid>或在终端中使用bg或fg。
通过理解 SIGCONT 及其相关信号,用户可以更有效地管理进程的生命周期,特别是在需要暂停和恢复进程的场景中。
信号安装
在 Linux 和其他类 Unix 系统中,信号处理是一个重要的机制,用于进程间通信和异常处理。以下是一些常用的信号安装函数及其详细说明:
signal()
描述: 最基本的信号处理安装函数,用于设置一个信号处理器。
原型:
1
void (*signal(int signum, void (*handler)(int)))(int);
特点:
- 简单易用,但行为可能因系统实现而异。
- 在某些系统上,信号处理器在信号到达后会被重置为默认值,这意味着需要在处理器中重新安装。
- 不支持信号的阻塞和排队。
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
void handler(int signum) {
printf("Received signal %d\n", signum);
}
int main() {
signal(SIGINT, handler); // 设置 SIGINT 的处理器
while (1) {
printf("Running...\n");
sleep(1);
}
return 0;
}
sysv_signal()
描述: 提供 System V 风格的信号处理。
原型:
1
void (*sysv_signal(int signum, void (*handler)(int)))(int);
特点:
- 自动重置: 默认情况下,当信号被捕获后,信号处理程序会被自动重置为默认行为。这意味着每次捕获信号后,需要重新设置信号处理程序。
- 信号阻塞: 在信号处理程序执行期间,当前信号通常不会被阻塞,这可能导致信号处理程序重入。
- 可移植性: sysv_signal 是 System V 的特性,在现代系统中通常不推荐使用,因为它的行为可能不一致。
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
void handler(int signum) {
printf("Received signal %d\n", signum);
}
int main() {
sysv_signal(SIGINT, handler); // 设置 SIGINT 的处理器
while (1) {
printf("Running...\n");
sleep(1);
}
return 0;
}
bsd_signal()
描述: 提供 BSD 风格的信号处理。
原型:
1
void (*bsd_signal(int signum, void (*handler)(int)))(int);
特点:
- 自动重置: 默认情况下,当信号被捕获后,信号处理程序不会自动重置为默认行为。这意味着信号处理程序在信号被捕获后仍然有效。
- 信号阻塞: 在信号处理程序执行期间,当前信号会被阻塞。这可以防止信号处理程序重入。
- 可移植性: 由于
bsd_signal是 BSD 系统的特性,因此在非 BSD 系统上可能不可用或表现不一致。
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
void handler(int signum) {
printf("Received signal %d\n", signum);
}
int main() {
bsd_signal(SIGINT, handler); // 设置 SIGINT 的处理器
while (1) {
printf("Running...\n");
sleep(1);
}
return 0;
}
sigaction()
- 描述: 提供更强大和灵活的信号处理机制,是现代 Unix 系统中推荐的信号处理方式。
- 原型:
1
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);
- 特点:
- 支持信号的阻塞和排队,允许更复杂的信号处理。
struct sigaction结构体包含信号处理器、信号掩码和标志位,提供更精细的控制。- 信号处理器不会被自动重置。
- 可以设置额外的标志,如
SA_RESTART,用于自动重启被信号中断的系统调用。
struct sigaction 结构体
1 | struct sigaction { |
sa_handler:指定信号处理函数,或使用SIG_IGN忽略信号,或SIG_DFL使用默认处理。sa_sigaction:用于处理带有附加信息的信号(需要设置SA_SIGINFO标志)。sa_mask:在处理该信号时要阻塞的其他信号。sa_flags:控制信号处理行为的标志。SA_NOCLDSTOP:- 当设置在处理
SIGCHLD信号时,表示在子进程停止或继续时不产生SIGCHLD信号。默认情况下,子进程停止(如被SIGSTOP信号暂停)或继续(如被SIGCONT信号恢复)时,父进程会收到SIGCHLD信号。
- 当设置在处理
SA_NOCLDWAIT:- 当设置在处理
SIGCHLD信号时,表示子进程终止时不进入僵尸状态。这样,子进程终止后,系统会自动回收其资源,而不需要父进程显式调用wait()或waitpid()。
- 当设置在处理
SA_NODEFER:- 当信号处理程序正在处理信号时,允许该信号再次被中断。默认情况下,信号处理程序正在处理信号时,系统会阻塞该信号,直到处理程序返回。
SA_ONSTACK:- 指定信号处理程序在替代信号堆栈上执行。通常用于需要在不同的堆栈上处理信号的场合,特别是在处理栈溢出等异常时。
SA_RESETHAND:- 在信号处理程序被调用后,将信号的处理行为重置为默认行为。这意味着信号处理程序只会被调用一次,之后信号的处理方式会恢复为默认。
SA_RESTART:- 使被信号中断的系统调用自动重启。通常,某些系统调用在被信号中断后会返回错误(
EINTR),设置此标志可以避免这种情况。
- 使被信号中断的系统调用自动重启。通常,某些系统调用在被信号中断后会返回错误(
SA_SIGINFO:- 允许信号处理程序接收额外的信息。使用此标志时,信号处理程序的类型应为
void (*sa_sigaction)(int, siginfo_t *, void *),而不是void (*sa_handler)(int)。这使得处理程序可以访问有关信号的更多信息,如信号来源、附加数据等。
- 允许信号处理程序接收额外的信息。使用此标志时,信号处理程序的类型应为
1 |
|
SYSCALL
在 Linux 中,信号处理通常通过用户空间的库函数(如 signal 或 sigaction)来完成。然而,底层实现是通过系统调用(syscall)来实现的。在 Linux 内核中,信号处理可以通过以下系统调用来实现:
rt_sigaction
描述:
rt_sigaction是现代 Linux 系统中用于安装信号处理器的系统调用,支持实时信号。原型:
1
int rt_sigaction(int signum, const struct sigaction *act, struct sigaction *oldact, size_t sigsetsize);
参数:
signum: 信号编号。act: 指向struct sigaction,用于指定新的信号行为。oldact: 指向struct sigaction,用于保存旧的信号行为。sigsetsize:sigset_t的大小,通常使用sizeof(sigset_t)。
使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
void handler(int signum) {
printf("Received signal %d\n", signum);
}
int main() {
struct sigaction sa;
sa.sa_handler = handler;
sa.sa_flags = 0;
sigemptyset(&sa.sa_mask);
syscall(SYS_rt_sigaction, SIGINT, &sa, NULL, sizeof(sigset_t));
while (1) {
printf("Running...\n");
sleep(1);
}
return 0;
}
sigprocmask / rt_sigprocmask
描述: 用于修改进程的信号屏蔽字。
原型:
1
int rt_sigprocmask(int how, const sigset_t *set, sigset_t *oldset, size_t sigsetsize);
参数:
how: 指定如何修改信号掩码,可以是SIG_BLOCK,SIG_UNBLOCK,SIG_SETMASK。set: 指向新的信号掩码。oldset: 指向旧的信号掩码。sigsetsize:sigset_t的大小。
使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
int main() {
sigset_t set;
sigemptyset(&set);
sigaddset(&set, SIGINT);
// 阻塞 SIGINT
syscall(SYS_rt_sigprocmask, SIG_BLOCK, &set, NULL, sizeof(sigset_t));
printf("SIGINT is blocked. Press Ctrl+C now will not stop the program.\n");
sleep(5);
// 解除阻塞 SIGINT
syscall(SYS_rt_sigprocmask, SIG_UNBLOCK, &set, NULL, sizeof(sigset_t));
printf("SIGINT is unblocked.\n");
while (1) {
printf("Running...\n");
sleep(1);
}
return 0;
}
注意事项
- 使用系统调用需要通过
syscall函数来实现,SYS_rt_sigaction和SYS_rt_sigprocmask是系统调用号。 - 这些系统调用提供了更底层的接口,通常不直接在应用程序中使用,而是通过标准库函数间接使用。
rt_sigaction和rt_sigprocmask是现代 Linux 系统中推荐使用的接口,支持实时信号和更大的信号集。
总结
signal()是最简单的信号处理方式,但在不同系统上可能有不同的行为。sysv_signal()和bsd_signal()提供 System V 和 BSD 风格的信号处理,适合需要特定兼容性的应用。sigaction()是最灵活和强大的信号处理方式,推荐在现代 Unix 系统中使用。它提供了对信号处理的更精细控制,并且在信号处理后不会自动重置处理器。
信号发送
在 Linux 和其他类 UNIX 系统中,信号发送函数用于向进程或线程发送信号。以下是 kill, tkill, tgkill, raise, 和 sigqueue 等函数的解析:
kill
- 功能: 向指定的进程或进程组发送信号。
- 原型:
1
2
3
int kill(pid_t pid, int sig); - 参数:
pid: 接收信号的进程 ID 或者进程组 ID。0: 发送信号给指定进程。
- =0: 发送信号给调用进程所在的进程组中的所有进程。
- <0: 发送信号给进程组 ID 为
-pid的所有进程。
sig: 要发送的信号编号。
- 返回值:
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
- 成功时返回
- 用法示例:
1
kill(1234, SIGTERM); // 向进程 ID 为 1234 的进程发送 SIGTERM 信号
tkill
- 功能: 向指定线程发送信号。
- 原型:
1
2
3
int tkill(pid_t tid, int sig); - 参数:
tid: 接收信号的线程 ID。sig: 要发送的信号编号。
- 返回值:
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
- 成功时返回
- 用法示例:
1
tkill(5678, SIGUSR1); // 向线程 ID 为 5678 的线程发送 SIGUSR1 信号
tgkill
- 功能: 向指定线程发送信号,同时指定进程 ID,避免信号发送到错误的进程。
- 原型:
1
2
3
int tgkill(pid_t tgid, pid_t tid, int sig); - 参数:
tgid: 线程所在的进程 ID。tid: 接收信号的线程 ID。sig: 要发送的信号编号。
- 返回值:
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
- 成功时返回
- 用法示例:
1
tgkill(1234, 5678, SIGUSR2); // 向进程 ID 为 1234 中线程 ID 为 5678 的线程发送 SIGUSR2 信号
raise
功能: 向调用进程发送信号。
原型:
1
2
3
int raise(int sig);参数:
sig: 要发送的信号编号。
返回值:
- 成功时返回
0。 - 失败时返回非零值。
- 成功时返回
用法示例:
1
raise(SIGINT); // 向调用进程自身发送 SIGINT 信号
sigqueue
功能: 向指定进程发送信号,并携带一个用户定义的值。
原型:
1
2
3
int sigqueue(pid_t pid, int sig, const union sigval value);参数:
pid: 接收信号的进程 ID。sig: 要发送的信号编号。value: 联合类型sigval,可以包含一个整数或指针,用于传递附加信息。
union sigval是一个用于信号处理的联合体,特别是在使用sigqueue函数时,用于传递附加信息。它允许用户在发送信号时附带一个整数或指针值,这在发送实时信号时尤其有用。union sigval定义union sigval的定义通常如下:1
2
3
4union sigval {
int sival_int; // 整数值
void *sival_ptr; // 指针值
};成员解析
sival_int:- 类型为
int。 - 用于传递一个整数值。
- 在某些应用中,可以用作标识符、状态码或其他需要传递的整数信息。
- 类型为
sival_ptr:- 类型为
void *。 - 用于传递一个指针值。
- 可以指向任意类型的数据结构,允许传递复杂的数据。
- 需要注意的是,传递指针时,接收方必须在同一地址空间中(例如,同一进程内的线程之间),否则指针将无效。
- 类型为
返回值:
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
- 成功时返回
用法示例
在使用 sigqueue 函数时,可以选择使用 sival_int 或 sival_ptr 来传递附加信息:
1 |
|
注意事项
union sigval主要用于实时信号(如SIGRTMIN和SIGRTMAX)的附加数据传递。- 当使用
sival_ptr时,确保指针指向的内存在信号处理期间是有效的,并且发送和接收方在同一地址空间中。 siginfo_t结构体的si_value成员用于接收union sigval传递的值,通常在信号处理程序中使用。
通过 union sigval,用户可以在发送信号时传递额外的信息,增强了信号处理的灵活性和功能性。
总结
kill是最常用的信号发送函数,用于发送信号给进程或进程组。tkill和tgkill是 Linux 特有的,用于发送信号到特定线程,tgkill提供了更精确的控制。raise用于向自身进程发送信号。sigqueue可以发送带有附加数据的信号,通常用于实时信号。
信号同步
在 Linux 和其他类 UNIX 系统中,信号等待函数用于挂起进程或线程的执行,直到接收到信号。以下是 pause, sigsuspend, sigwait, sigwaitinfo, 和 sigtimedwait 等函数的用法解析:
pause
- 功能: 挂起调用进程,直到捕获到一个信号。
- 原型:
1
2
3
int pause(void); - 返回值:
pause总是返回-1,并将errno设置为EINTR,因为它唯一的退出方式是通过信号处理程序。
- 用法示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
void handler(int signum) {
printf("Signal %d received\n", signum);
}
int main() {
signal(SIGINT, handler); // 设置信号处理程序
printf("Waiting for signal...\n");
pause(); // 等待信号
return 0;
}
sigsuspend
功能: 暂时替换进程的信号掩码,并挂起进程直到捕获到信号。
原型:
1
2
3
int sigsuspend(const sigset_t *mask);参数:
mask: 新的信号掩码,指定哪些信号应该被阻塞。
返回值:
- 总是返回
-1,并将errno设置为EINTR。
- 总是返回
用法示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
void handler(int signum) {
printf("Signal %d received\n", signum);
}
int main() {
struct sigaction sa;
sigset_t mask;
sa.sa_handler = handler;
sigemptyset(&sa.sa_mask);
sa.sa_flags = 0;
sigaction(SIGINT, &sa, NULL);
sigemptyset(&mask);
sigaddset(&mask, SIGINT);
printf("Waiting for signal...\n");
sigsuspend(&mask); // 临时替换信号掩码并等待信号
return 0;
}
sigwait
- 功能: 阻塞直到指定信号集中的一个信号被捕获,并将信号编号返回。
- 原型:
1
2
3
int sigwait(const sigset_t *set, int *sig); - 参数:
set: 信号集,包含要等待的信号。sig: 用于存储接收到的信号编号。
- 返回值:
- 成功时返回
0。 - 失败时返回错误码。
- 成功时返回
- 用法示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int main() {
sigset_t mask;
int sig;
sigemptyset(&mask);
sigaddset(&mask, SIGINT);
sigprocmask(SIG_BLOCK, &mask, NULL); // 阻塞 SIGINT
printf("Waiting for SIGINT...\n");
sigwait(&mask, &sig); // 等待 SIGINT
printf("Signal %d received\n", sig);
return 0;
}
sigwaitinfo
- 功能: 类似于
sigwait,但还提供信号的附加信息。 - 原型:
1
2
3
int sigwaitinfo(const sigset_t *set, siginfo_t *info); - 参数:
set: 信号集,包含要等待的信号。info: 用于存储信号的附加信息。
- 返回值:
- 成功时返回接收到的信号编号。
- 失败时返回
-1,并设置errno。
- 用法示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int main() {
sigset_t mask;
siginfo_t info;
sigemptyset(&mask);
sigaddset(&mask, SIGINT);
sigprocmask(SIG_BLOCK, &mask, NULL); // 阻塞 SIGINT
printf("Waiting for SIGINT...\n");
sigwaitinfo(&mask, &info); // 等待 SIGINT
printf("Signal %d received\n", info.si_signo);
return 0;
}
sigtimedwait
- 功能: 类似于
sigwaitinfo,但允许指定超时时间。 - 原型:
1
2
3
4
int sigtimedwait(const sigset_t *set, siginfo_t *info, const struct timespec *timeout); - 参数:
set: 信号集,包含要等待的信号。info: 用于存储信号的附加信息。timeout: 超时时间,使用timespec结构体指定。
- 返回值:
- 成功时返回接收到的信号编号。
- 失败时返回
-1,并设置errno。
- 用法示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int main() {
sigset_t mask;
siginfo_t info;
struct timespec timeout;
sigemptyset(&mask);
sigaddset(&mask, SIGINT);
sigprocmask(SIG_BLOCK, &mask, NULL); // 阻塞 SIGINT
timeout.tv_sec = 5; // 设置超时时间为 5 秒
timeout.tv_nsec = 0;
printf("Waiting for SIGINT with timeout...\n");
if (sigtimedwait(&mask, &info, &timeout) == -1) {
perror("sigtimedwait");
} else {
printf("Signal %d received\n", info.si_signo);
}
return 0;
}
总结
pause和sigsuspend用于挂起进程直到捕获到信号。sigwait,sigwaitinfo, 和sigtimedwait用于在阻塞状态下等待信号,并可以选择获取信号的附加信息。sigwaitinfo和sigtimedwait提供了更丰富的信号信息,而sigtimedwait还允许设置超时时间。
其他常用API
signalfd 是 Linux 提供的一个用于信号处理的系统调用,它允许应用程序通过文件描述符来接收信号。这种方法可以将信号处理整合到基于文件描述符的事件循环中,比如 select、poll 或 epoll,从而简化了信号处理逻辑。
signalfd
头文件:
1
原型:
1
int signalfd(int fd, const sigset_t *mask, int flags);
参数:
fd: 如果为-1,则创建一个新的 signalfd 文件描述符;如果是一个有效的文件描述符,则修改该文件描述符的信号掩码。mask: 指向一个sigset_t,指定要监控的信号集。flags: 控制文件描述符的行为,可以是以下标志的组合:SFD_CLOEXEC: 在执行exec系列函数时关闭文件描述符。SFD_NONBLOCK: 以非阻塞模式打开文件描述符。
返回值:
- 成功时返回一个新的文件描述符。
- 失败时返回
-1,并设置errno。
使用步骤
- 创建信号集: 使用
sigemptyset、sigaddset等函数初始化和设置信号集。 - 阻塞信号: 使用
sigprocmask阻塞要通过signalfd接收的信号,防止它们被默认处理。 - 创建 signalfd: 使用
signalfd创建一个文件描述符,用于接收信号。 - 读取信号: 使用
read从 signalfd 读取信号信息。
signalfd_siginfo 结构体
从 signalfd 读取的数据是一个或多个 signalfd_siginfo 结构体:
1 | struct signalfd_siginfo { |
用法示例
以下是一个简单的示例,展示如何使用 signalfd 来捕获 SIGINT 信号:
1 |
|
总结
signalfd提供了一种通过文件描述符接收信号的机制,使得信号处理可以与其他文件描述符事件统一管理。- 使用
signalfd时,需要先阻塞信号,以确保它们不会被默认处理。 - 通过
read函数从 signalfd 读取信号信息,可以获取信号的详细信息。
sigemptyset()
sigemptyset 是一个用于信号集操作的函数,常用于信号处理程序中。它的主要作用是初始化一个信号集,并将其清空,即将所有信号从集合中移除。
函数原型
1 |
|
参数
set: 指向sigset_t类型的指针,用于存储信号集。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno以指示错误类型。
用法
sigemptyset 通常用于初始化一个信号集,以便在后续的信号操作中使用。初始化后的信号集不包含任何信号。常见的用法是在设置信号处理程序时,清空信号集,然后根据需要添加或删除特定信号。
示例
下面是一个简单的示例,展示如何使用 sigemptyset 来初始化信号集,并结合 sigaddset 添加信号:
1 |
|
说明
- 初始化: 使用
sigemptyset清空信号集set,确保它不包含任何信号。 - 添加信号: 使用
sigaddset将SIGINT信号添加到信号集中。 - 检查信号: 使用
sigismember检查SIGINT是否在信号集中。
注意事项
- 在对信号集进行任何操作之前,应该先使用
sigemptyset或sigfillset初始化信号集。 sigemptyset是信号集操作的一部分,通常与其他信号集函数(如sigaddset,sigdelset,sigismember)一起使用,以实现复杂的信号处理逻辑。
在 Linux 和其他类 UNIX 系统中,信号集操作函数用于管理和操作信号集。以下是 sigfillset, sigaddset, sigdelset, 和 sigismember 的用法解析:
sigfillset
- 功能: 初始化一个信号集,并将所有可用信号添加到集合中。
- 原型:
1
2
3
int sigfillset(sigset_t *set); - 参数:
set: 指向sigset_t类型的指针,用于存储信号集。
- 返回值:
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
- 成功时返回
- 用法示例:
1
2
3
4sigset_t set;
if (sigfillset(&set) == -1) {
perror("Failed to fill signal set");
}
sigaddset
- 功能: 向信号集中添加一个特定的信号。
- 原型:
1
2
3
int sigaddset(sigset_t *set, int signum); - 参数:
set: 指向sigset_t类型的指针,用于存储信号集。signum: 要添加的信号编号。
- 返回值:
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
- 成功时返回
- 用法示例:
1
2
3
4
5sigset_t set;
sigemptyset(&set); // 初始化并清空信号集
if (sigaddset(&set, SIGINT) == -1) {
perror("Failed to add SIGINT to signal set");
}
sigdelset
- 功能: 从信号集中删除一个特定的信号。
- 原型:
1
2
3
int sigdelset(sigset_t *set, int signum); - 参数:
set: 指向sigset_t类型的指针,用于存储信号集。signum: 要删除的信号编号。
- 返回值:
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
- 成功时返回
- 用法示例:
1
2
3
4
5sigset_t set;
sigfillset(&set); // 初始化并填充信号集
if (sigdelset(&set, SIGINT) == -1) {
perror("Failed to delete SIGINT from signal set");
}
sigismember
- 功能: 检查特定信号是否在信号集中。
- 原型:
1
2
3
int sigismember(const sigset_t *set, int signum); - 参数:
set: 指向sigset_t类型的指针,用于存储信号集。signum: 要检查的信号编号。
- 返回值:
- 如果信号在集合中,返回
1。 - 如果信号不在集合中,返回
0。 - 失败时返回
-1,并设置errno。
- 如果信号在集合中,返回
- 用法示例:
1
2
3
4
5
6
7sigset_t set;
sigaddset(&set, SIGINT); // 添加 SIGINT 到信号集
if (sigismember(&set, SIGINT)) {
printf("SIGINT is in the signal set.\n");
} else {
printf("SIGINT is not in the signal set.\n");
}
在 Linux 和其他类 UNIX 系统中,信号相关的 API 提供了一套机制来管理和处理信号。以下是一些常用的信号相关 API,包括 sigprocmask 和 sigpending 等函数的解析:
sigprocmask
- 功能: 用于检查或更改进程的信号掩码。
- 原型:
1
2
3
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset); - 参数:
how: 指定如何修改信号掩码,可取值为SIG_BLOCK,SIG_UNBLOCK, 或SIG_SETMASK。SIG_BLOCK: 将set中的信号添加到当前信号掩码中。SIG_UNBLOCK: 从当前信号掩码中移除set中的信号。SIG_SETMASK: 将当前信号掩码设置为set。
set: 指向一个信号集,指定要修改的信号。oldset: 如果不为NULL,存储之前的信号掩码。
- 返回值:
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
- 成功时返回
- 用法示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
int main() {
sigset_t newmask, oldmask;
sigemptyset(&newmask);
sigaddset(&newmask, SIGINT); // 添加 SIGINT 到信号集
// 阻塞 SIGINT,并保存旧的信号掩码
if (sigprocmask(SIG_BLOCK, &newmask, &oldmask) < 0) {
perror("sigprocmask");
return 1;
}
printf("SIGINT is blocked\n");
// 恢复旧的信号掩码
if (sigprocmask(SIG_SETMASK, &oldmask, NULL) < 0) {
perror("sigprocmask");
return 1;
}
printf("SIGINT is unblocked\n");
return 0;
}
sigpending
- 功能: 检查当前进程中未决的信号。
- 原型:
1
2
3
int sigpending(sigset_t *set); - 参数:
set: 用于存储未决信号集。
- 返回值:
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
- 成功时返回
- 用法示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
int main() {
sigset_t pendingset;
// 获取未决信号集
if (sigpending(&pendingset) < 0) {
perror("sigpending");
return 1;
}
if (sigismember(&pendingset, SIGINT)) {
printf("SIGINT is pending\n");
} else {
printf("SIGINT is not pending\n");
}
return 0;
}
- Title: Linux环境编程与内核之信号
- Author: 韩乔落
- Created at : 2025-02-06 14:48:59
- Updated at : 2025-03-19 18:23:20
- Link: https://jelasin.github.io/2025/02/06/Linux环境编程与内核之信号/
- License: This work is licensed under CC BY-NC-SA 4.0.