前言 本文面向有编程经验的Rust学习者,使用 Cargo 作为包管理器。
参考链接
[0]Rust Course
[1]rfcs
[2]Rust权威指南(第二版)
[3]Rust算法教程
[4]rust-lang-learn
[5]rust-lang-blog
[6]claude-sonnet-4-5-20250929-thinking
Rust中的变量 Hello world!
1 2 3 fn main () { println! ("Hello, world!" ); }
变量命名 在命名方面,和其它语言没有区别,不过当给变量命名时,需要遵循 Rust 命名规范 ,也不能使用 Rust关键字 。
变量绑定 上面这条语句将 "hello world" 字符串绑定给了变量a,"hello world" 的所有权也就属于a。在Rust中任何内存对象都是有主人的,而且一般情况下完全属于它的主人,绑定就是把这个对象绑定给一个变量,让这个变量成为它的主人。
所有权转移后,该对象之前的主人就会丧失对该对象的所有权。
1 2 3 4 5 6 7 8 9 10 11 12 13 fn main () { let a = String ::from ("hello world" ); println! ("a 的值: {}" , a); let b = a; println! ("b 的值: {}" , b); }
变量可变性 Rust 的变量在默认情况下是不可变的 。
1 2 3 4 5 6 fn main () { let a = 10 ; println! ("a is a number: {}" , a); println! ("a is a number: {}" , a); }
我们可以通过 mut 关键字让变量变为可变的 。
1 2 3 4 5 6 fn main () { let mut a = 10 ; println! ("a is a number: {}" , a); a = 20 ; println! ("a is a number: {}" , a); }
忽略未使用的变量 如果你创建了一个变量却不在任何地方使用它,Rust 通常会给你一个警告,因为这可能会是个 BUG。但是有时创建一个不会被使用的变量是有用的,比如你正在设计原型或刚刚开始一个项目。这时你希望告诉 Rust 不要警告未使用的变量,为此可以用下划线作为变量名的开头 :
1 2 3 4 fn main () { let _x = 5 ; let y = 10 ; }
变量解构 let 表达式不仅仅用于变量的绑定,还能进行复杂变量的解构:从一个相对复杂的变量中,匹配出该变量的一部分内容:
1 2 3 4 5 6 7 8 fn main () { let (a, mut b): (bool ,bool ) = (true , false ); println! ("a = {:?}, b = {:?}" , a, b); b = true ; assert_eq! (a, b); }
解构式赋值 在 Rust 1.59 版本后,我们可以在赋值语句的左式中使用元组、切片和结构体模式了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct Struct { e: i32 } fn main () { let (a, b, c, d, e); (a, b) = (1 , 2 ); [c, .., d, _] = [1 , 2 , 3 , 4 , 5 ]; Struct { e, .. } = Struct { e: 5 }; println! ("a = {}, b = {}, c = {}, d = {}, e = {}" , a, b, c, d, e); }
变量与常量 变量的值不能更改可能让你想起其他另一个很多语言都有的编程概念:常量 (constant )。与不可变变量一样,常量也是绑定到一个常量名且不允许更改的值,但是常量和变量之间存在一些差异:
常量不允许使用 mut。常量不仅仅默认不可变,而且自始至终不可变 ,因为常量在编译完成后,已经确定它的值。
常量使用 const 关键字而不是 let 关键字来声明,并且值的类型必须 标注。
下面是一个常量声明的例子,其常量名为 MAX_POINTS,值设置为 100,000。(Rust 常量的命名约定是全部字母都使用大写,并使用下划线分隔单词,另外对数字字面量可插入下划线以提高可读性):
1 const MAX_POINTS: u32 = 100_000 ;
常量可以在任意作用域内声明,包括全局作用域,在声明的作用域内,常量在程序运行的整个过程中都有效。对于需要在多处代码共享一个不可变的值时非常有用,例如游戏中允许玩家赚取的最大点数或光速。
变量遮蔽 Rust 允许声明相同的变量名,在后面声明的变量会遮蔽掉前面声明的:
1 2 3 4 5 6 7 8 9 10 11 12 13 fn main () { let x = 5 ; let x = x + 1 ; { let x = x * 2 ; println! ("The value of x in the inner scope is: {}" , x); } println! ("The value of x is: {}" , x); }
变量遮蔽的用处在于,如果你在某个作用域内无需再使用之前的变量(在被遮蔽后,无法再访问到之前的同名变量)。
基本类型 Rust 每个值都有其确切的数据类型,总的来说可以分为两类:基本类型和复合类型。 基本类型意味着它们往往是一个最小化原子类型,无法解构为其它类型(一般意义上来说),由以下组成:
数值类型:有符号整数 (i8, i16, i32, i64, isize)、 无符号整数 (u8, u16, u32, u64, usize) 、浮点数 (f32, f64)、以及有理数、复数
字符串:字符串字面量和字符串切片 &str
布尔类型:true 和 false
字符类型:表示单个 Unicode 字符,存储为 4 个字节
单元类型:即 () ,其唯一的值也是 ()
数值类型 整数类型 整数 是没有小数部分的数字。之前使用过的 i32 类型,表示有符号的 32 位整数( i 是英文单词 integer 的首字母,与之相反的是 u,代表无符号 unsigned 类型)。下表显示了 Rust 中的内置的整数类型:
长度
有符号类型
无符号类型
范围
8 位
i8u8-128 ~ 127 / 0 ~ 255
16 位
i16u16-32,768 ~ 32,767 / 0 ~ 65,535
32 位
i32u32-2³¹ ~ 2³¹-1 / 0 ~ 2³²-1
64 位
i64u64-2⁶³ ~ 2⁶³-1 / 0 ~ 2⁶⁴-1
128 位
i128u128-2¹²⁷ ~ 2¹²⁷-1 / 0 ~ 2¹²⁸-1
视架构而定(32位/64位)
isizeusize同 i32/u32 或 i64/u64
有符号类型 (iN):
范围:-2^(N-1) ~ 2^(N-1) - 1
无符号类型 (uN):
整型字面量可以用下表的形式书写:
数字字面量
示例
十进制
98_222
十六进制
0xff
八进制
0o77
二进制
0b1111_0000
字节 (仅限于 u8)
b'A'
Rust 整型默认使用 i32,例如 let i = 1,那 i 就是 i32 类型,因此你可以首选它,同时该类型也往往是性能最好的。isize 和 usize 的主要应用场景是用作集合的索引。
整型溢出
假设有一个 u8 ,它可以存放从 0 到 255 的值。那么当你将其修改为范围之外的值,比如 256,则会发生整型溢出 。关于这一行为 Rust 有一些有趣的规则:当在 debug 模式编译时,Rust 会检查整型溢出,若存在这些问题,则使程序在编译时 panic (崩溃,Rust 使用这个术语来表明程序因错误而退出)。
在当使用 --release 参数进行 release 模式构建时,Rust 不 检测溢出。相反,当检测到整型溢出时,Rust 会按照补码循环溢出(two’s complement wrapping )的规则处理。简而言之,大于该类型最大值的数值会被补码转换成该类型能够支持的对应数字的最小值。比如在 u8 的情况下,256 变成 0,257 变成 1,依此类推。程序不会 panic ,但是该变量的值可能不是你期望的值。依赖这种默认行为的代码都应该被认为是错误的代码。
要显式处理可能的溢出,可以使用标准库针对原始数字类型提供的这些方法:
使用 wrapping_* 方法在所有模式下都按照补码循环溢出规则处理,例如 wrapping_add
如果使用 checked_* 方法时发生溢出,则返回 None 值
使用 overflowing_* 方法返回该值和一个指示是否存在溢出的布尔值
使用 saturating_* 方法,可以限定计算后的结果不超过目标类型的最大值或低于最小值,例如:
1 2 assert_eq! (100u8 .saturating_add (1 ), 101 );assert_eq! (u8 ::MAX.saturating_add (127 ), u8 ::MAX);
下面是一个演示wrapping_*方法的示例:
1 2 3 4 5 fn main () { let a : u8 = 255 ; let b = a.wrapping_add (20 ); println! ("{}" , b); }
浮点类型 浮点类型数字 是带有小数点的数字,在 Rust 中浮点类型数字也有两种基本类型: f32 和 f64,分别为 32 位和 64 位大小。默认浮点类型是 f64,在现代的 CPU 中它的速度与 f32 几乎相同,但精度更高。
下面是一个演示浮点数的示例:
1 2 3 4 5 fn main () { let x = 2.0 ; let y : f32 = 3.0 ; }
浮点数根据 IEEE-754 标准实现。f32 类型是单精度浮点型,f64 为双精度。
浮点陷阱
浮点数由于底层格式的特殊性,导致了如果在使用浮点数时不够谨慎,就可能造成危险,有两个原因:
浮点数往往是你想要数字的近似表达 浮点数类型是基于二进制实现的,但是我们想要计算的数字往往是基于十进制,例如 0.1 在二进制上并不存在精确的表达形式,但是在十进制上就存在。这种不匹配性导致一定的歧义性,更多的,虽然浮点数能代表真实的数值,但是由于底层格式问题,它往往受限于定长的浮点数精度,如果你想要表达完全精准的真实数字,只有使用无限精度的浮点数才行浮点数在某些特性上是反直觉的 例如大家都会觉得浮点数可以进行比较,对吧?是的,它们确实可以使用 >,>= 等进行比较,但是在某些场景下,这种直觉上的比较特性反而会害了你。因为 f32 , f64 上的比较运算实现的是 std::cmp::PartialEq 特征(类似其他语言的接口),但是并没有实现 std::cmp::Eq 特征,但是后者在其它数值类型上都有定义,说了这么多,可能大家还是云里雾里,用一个例子来举例:
Rust 的 HashMap 数据结构,是一个 KV 类型的 Hash Map 实现,它对于 K 没有特定类型的限制,但是要求能用作 K 的类型必须实现了 std::cmp::Eq 特征,因此这意味着你无法使用浮点数作为 HashMap 的 Key,来存储键值对,但是作为对比,Rust 的整数类型、字符串类型、布尔类型都实现了该特征,因此可以作为 HashMap 的 Key。
为了避免上面说的两个陷阱,你需要遵守以下准则:
避免在浮点数上测试相等性
当结果在数学上可能存在未定义时,需要格外的小心。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 fn main () { let abc : (f32 , f32 , f32 ) = (0.1 , 0.2 , 0.3 ); let xyz : (f64 , f64 , f64 ) = (0.1 , 0.2 , 0.3 ); println! ("abc (f32)" ); println! (" 0.1 + 0.2: {:x}" , (abc.0 + abc.1 ).to_bits ()); println! (" 0.3: {:x}" , (abc.2 ).to_bits ()); println! (); println! ("xyz (f64)" ); println! (" 0.1 + 0.2: {:x}" , (xyz.0 + xyz.1 ).to_bits ()); println! (" 0.3: {:x}" , (xyz.2 ).to_bits ()); println! (); assert! (abc.0 + abc.1 == abc.2 ); assert! (xyz.0 + xyz.1 == xyz.2 ); }
对 f32 类型做加法时,0.1 + 0.2 的结果是 3e99999a,0.3 也是 3e99999a,因此 f32 下的 0.1 + 0.2 == 0.3 通过测试,但是到了 f64 类型时,结果就不一样了,因为 f64 二进制精度高很多,导致了 0.1 + 0.2 并不严格等于 0.3,它们可能在小数点 N 位后存在误差。0.1 + 0.2 以 4 结尾,但是 0.3 以3结尾,这个区别导致 f64 下的测试失败了,并且抛出了异常。
NaN
对于数学上未定义的结果,例如对负数取平方根 -42.1.sqrt() ,会产生一个特殊的结果:Rust 的浮点数类型使用 NaN (not a number) 来处理这些情况。
**所有跟 NaN 交互的操作,都会返回一个 NaN**,而且 NaN 不能用来比较,下面的代码会崩溃:
1 2 3 4 fn main () { let x = (-42.0_f32 ).sqrt (); assert_eq! (x, x); }
出于防御性编程的考虑,可以使用 is_nan() 等方法,可以用来判断一个数值是否是 NaN :
1 2 3 4 5 6 fn main () { let x = (-42.0_f32 ).sqrt (); if x.is_nan () { println! ("未定义的数学行为" ) } }
数字运算 Rust 支持所有数字类型的基本数学运算:加法、减法、乘法、除法和取模运算。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 fn main () { let a = 10 ; let b : i32 = 20 ; let c = 30i32 ; println! ("加法: {} + {} = {}" , a, b, a + b); println! ("减法: {} - {} = {}" , b, a, b - a); println! ("乘法: {} * {} = {}" , a, c, a * c); println! ("除法: {} / {} = {}" , c, a, c / a); println! ("取模: {} % {} = {}" , b, a, b % a); let million : i64 = 1_000_000 ; println! ("百万的平方: {}" , million.pow (2 )); let x = 10.0 ; let y = 3.5f32 ; println! ("浮点除法: {:.2}" , x / 2.0 ); println! ("f32: {:.3}" , y * 2.0 ); }
位运算 Rust 的位运算基本上和其他语言一样
运算符
说明
& 位与
相同位置均为1时则为1,否则为0
| 位或
相同位置只要有1时则为1,否则为0
^ 异或
相同位置不相同则为1,相同则为0
! 位非
把位中的0和1相互取反,即0置为1,1置为0
<< 左移
所有位向左移动指定位数,右位补0(会改变符号位)
>> 右移
所有位向右移动指定位数,行为取决于类型 :
重要说明:
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 fn main () { let a = 0b1100u8 ; let b = 0b1010u8 ; println! ("a = {:08b} ({})" , a, a); println! ("b = {:08b} ({})" , b, b); println! (); println! ("a & b = {:08b} ({})" , a & b, a & b); println! ("a | b = {:08b} ({})" , a | b, a | b); println! ("a ^ b = {:08b} ({})" , a ^ b, a ^ b); println! ("!a = {:08b} ({})" , !a, !a); }
关于移位运算:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 fn main () { let neg : i8 = -120 ; println! ("========== 移位操作对比 ==========\n" ); println! ("测试值: {} = {:08b}\n" , neg, neg as u8 ); println! ("--- 右移2位 ---" ); println! ("算术右移: {} >> 2 = {:3} = {:08b} (补1)" , neg, neg >> 2 , (neg >> 2 ) as u8 ); println! ("逻辑右移: {} >>> 2 = {:3} = {:08b} (补0)" , neg, (neg as u8 ) >> 2 , (neg as u8 ) >> 2 ); println! ("\n--- 左移2位 ---" ); println! ("算术左移: {} << 2 = {:3} = {:08b}" , neg, neg << 2 , (neg << 2 ) as u8 ); println! ("逻辑左移: {} <<< 2 = {:3} = {:08b}" , neg, (neg as u8 ) << 2 , (neg as u8 ) << 2 ); }
序列(Range) Rust 提供了一个非常简洁的方式,用来生成连续的数值,例如 1..5,生成从 1 到 4 的连续数字,不包含 5 ;1..=5,生成从 1 到 5 的连续数字,包含 5,它的用途很简单,常常用于循环中:
1 2 3 for i in 1 ..=5 { println! ("{}" ,i); }
序列只允许用于数字或字符类型,原因是它们可以连续,同时编译器在编译期可以检查该序列是否为空,字符和数字值是 Rust 中仅有的可以用于判断是否为空的类型。如下是一个使用字符类型序列的例子:
1 2 3 for i in 'a' ..='z' { println! ("{}" ,i); }
字符类型 Rust 的字符不仅仅是 ASCII,所有的 Unicode 值都可以作为 Rust 字符,包括单个的中文、日文、韩文、emoji 表情符号等等,都是合法的字符类型。Unicode 值的范围从 U+0000 ~ U+D7FF 和 U+E000 ~ U+10FFFF。由于 Unicode 都是 4 个字节编码,因此Rust的字符类型也是占用 4 个字节。
1 2 3 4 5 6 fn main () { let c = 'z' ; let z = 'ℤ' ; let g = '国' ; let heart_eyed_cat = '😻'; }
布尔类型 Rust 中的布尔类型有两个可能的值:true 和 false,布尔值占用内存的大小为 1 个字节:
1 2 3 4 5 6 7 8 9 fn main () { let t = true ; let f : bool = false ; if f { println! ("这是段毫无意义的代码" ); } }
单元类型 单元类型就是 (),唯一的值也是 () 。
1 2 3 4 5 6 7 8 9 10 11 fn normal () -> () { }fn main () { }println! ("hello" );fn diverge () -> ! { panic! ("crash!" ); }
特性
说明
定义 () 既是类型也是唯一的值
大小 0 字节,不占内存
main 返回 返回 (),不是”无返回值”
用途 占位符、表示”不关心返回值”
区别 -> () 有返回值,-> ! 才是永不返回(发散函数,即没有返回值)
语句和表达式 Rust 的函数体是由一系列语句组成,最后由一个表达式来返回值,例如:
1 2 3 4 5 fn add_with_extra (x: i32 , y: i32 ) -> i32 { let x = x + 1 ; let y = y + 5 ; x + y }
语句会执行一些操作但是不会返回一个值,而表达式会在求值后返回一个值,因此在上述函数体的三行代码中,前两行是语句,最后一行是表达式。
对于 Rust 语言而言,这种基于语句(statement)和表达式(expression)的方式是非常重要的,你需要能明确的区分这两个概念 ,但是对于很多其它语言而言,这两个往往无需区分。基于表达式是函数式语言的重要特征,表达式总要返回值 。
语句 1 2 3 let a = 8 ;let b : Vec <f64 > = Vec ::new ();let (a, c) = ("hi" , false );
以上都是语句,它们完成了一个具体的操作,但是并没有返回值,因此是语句。
由于 let 是语句,因此不能将 let 语句赋值给其它值,如下形式是错误的:
表达式 表达式会进行求值,然后返回一个值。例如 5 + 6,在求值后,返回值 11,因此它就是一条表达式。
表达式可以成为语句的一部分,例如 let y = 6 中,6 就是一个表达式,它在求值后返回一个值 6。调用一个函数是表达式,因为会返回一个值,调用宏也是表达式,用花括号包裹最终返回一个值的语句块也是表达式,总之,能返回值,它就是表达式:
1 2 3 4 5 6 7 8 fn main () { let y = { let x = 3 ; x + 1 }; println! ("The value of y is: {}" , y); }
上面使用一个语句块表达式将值赋给 y 变量,语句块长这样:
该语句块是表达式的原因是:它的最后一行是表达式,返回了 x + 1 的值,注意 x + 1 不能以分号结尾,否则就会从表达式变成语句, 表达式不能包含分号 。这一点非常重要,一旦你在表达式后加上分号,它就会变成一条语句,再也不会 返回一个值,请牢记!
最后,表达式如果不返回任何值,会隐式地返回一个 () 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 fn main () { assert_eq! (ret_unit_type (), ()) } fn ret_unit_type () { let x = 1 ; let y = if x % 2 == 1 { "odd" } else { "even" }; let z = if x % 2 == 1 { "odd" } else { "even" }; }
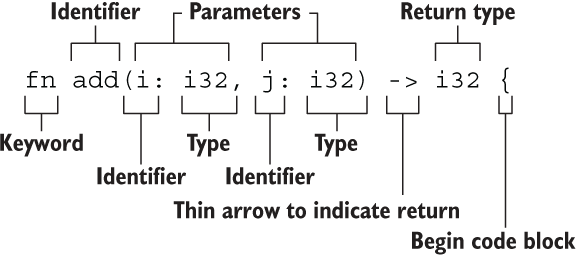
函数 以 add 函数为例,声明函数的关键字 fn,函数名 add(),参数 i: i32 和 j: i32,参数类型和返回值类型都是 i32。
1 2 3 fn add (i: i32 , j: i32 ) -> i32 { i + j }
函数要点
函数名和变量名使用蛇形命名法(snake_case),例如 fn add_two() {}
函数的位置可以随便放,Rust 不关心我们在哪里定义了函数,只要有定义即可
每个函数参数都需要标注类型
函数参数 Rust 是静态类型语言,因此需要你为每一个函数参数都标识出它的具体类型,例如:
1 2 3 4 5 6 7 8 fn main () { another_function (5 , 6.1 ); } fn another_function (x: i32 , y: f32 ) { println! ("The value of x is: {}" , x); println! ("The value of y is: {}" , y); }
another_function 函数有两个参数,其中 x 是 i32 类型,y 是 f32 类型,然后在该函数内部,打印出这两个值。这里去掉 x 或者 y 的任何一个的类型,都会报错。
函数返回 在 Rust 中函数就是表达式,因此我们可以把函数的返回值直接赋给调用者。
函数的返回值就是函数体最后一条表达式的返回值,当然我们也可以使用 return 提前返回,下面的函数使用最后一条表达式来返回一个值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 fn plus_number (x:i32 ) -> i32 { if x == 5 { return 10 ; } else { x + 10 } } fn main () { let x = plus_number (6 ); println! ("The value of x is: {}" , x); }
返回单元类型
单元类型 (),是一个零长度的元组。它没啥作用,但是可以用来表达一个函数没有返回值:
函数没有返回值,那么返回一个 ()
通过 ; 结尾的语句返回一个 ()
1 2 3 4 5 6 7 fn plus_number (x:i32 ) { x + 5 ; } fn plus_number (x:i32 ) -> () { x + 5 ; }
永不返回的发散函数 !
当用 ! 作函数返回类型的时候,表示该函数永不返回( diverging functions ),特别的,这种语法往往用做会导致程序崩溃的函数:
1 2 3 fn dead_end () -> ! { panic! ("dead_end" ); }
下面的函数创建了一个无限循环,该循环永不跳出,因此函数也永不返回:
1 2 3 4 5 fn forever () -> ! { loop { }; }
所有权和借用 所有权 Rust 通过所有权来管理内存 ,这种检查只发生在编译期,因此对于程序运行期,不会有性能上的损失。
Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
变量作用域 作用域是一个变量在程序中有效的范围,假如有这样一个变量:
变量 s 绑定到了一个字符串字面值,该字符串字面值是硬编码到程序代码中的。s 变量从声明的点开始直到当前作用域的结束都是有效的:
1 2 3 4 5 { let s = "hello" ; }
简而言之,s 从创建开始就有效,然后有效期持续到它离开作用域为止,可以看出,就作用域来说,Rust 语言跟其他编程语言没有区别。
所有权转移 先来看一段代码:
这段代码并没有发生所有权的转移,原因很简单: 代码首先将 5 绑定到变量 x,接着拷贝 x 的值赋给 y,最终 x 和 y 都等于 5,因为整数是 Rust 基本数据类型,是固定大小的简单值,因此这两个值都是通过自动拷贝 的方式来赋值的,都被存在栈中,完全无需在堆上分配内存。整个过程中的赋值都是通过值拷贝的方式完成(发生在栈中),因此并不需要所有权转移。
移动(move)
然后再来看一段代码:
1 2 3 4 5 6 fn main () { let s1 = String ::from ("hello" ); let s2 = s1; println! ("{}, world!" , s1); }
String 类型是一个复杂类型,由存储在栈中的堆指针 、字符串长度 、字符串容量 共同组成。String 类型指向了一个堆上的空间,这里存储着它的真实数据。当 s1 被赋予 s2 后,Rust 认为 s1 不再有效,因此也无需在 s1 离开作用域后 drop 任何东西,这就是把所有权从 s1 转移给了 s2,s1 在被赋予 s2 后就马上失效了 。
1 2 3 4 5 6 7 8 9 pub struct String { vec: Vec <u8 >, } pub struct Vec <T> { ptr: *mut T, len: usize , cap: usize , }
深拷贝(clone)
首先,Rust 永远也不会自动创建数据的 “深拷贝” 。因此,任何自动 的复制都不是深拷贝,可以被认为对运行时性能影响较小。
如果我们确实 需要深度复制 String 中堆上的数据,而不仅仅是栈上的数据,可以使用一个叫做 clone 的方法。
1 2 3 4 let s1 = String ::from ("hello" );let s2 = s1.clone ();println! ("s1 = {}, s2 = {}" , s1, s2);
这段代码能够正常运行,说明 s2 确实完整的复制了 s1 的数据。
如果代码性能无关紧要,例如初始化程序时或者在某段时间只会执行寥寥数次时,你可以使用 clone 来简化编程。但是对于执行较为频繁的代码(热点路径),使用 clone 会极大的降低程序性能,需要小心使用!
浅拷贝(copy)
关键点 :
Copy 类型在赋值时会按位复制 (栈上复制)实现 Copy 的类型不能 拥有堆上的数据
Copy 是隐式 的,Clone 是显式 的
Rust 有一个叫做 Copy 的特征,可以用在类似整型这样在栈中存储的类型。如果一个类型拥有 Copy 特征,一个旧的变量在被赋值给其他变量后仍然可用,也就是赋值的过程即是拷贝的过程。
如下是一些 Copy 的类型:
所有整数类型,比如 u32
布尔类型,bool,它的值是 true 和 false
所有浮点数类型,比如 f64
字符类型,char
元组,当且仅当其包含的类型也都是 Copy 的时候。比如,(i32, i32) 是 Copy 的,但 (i32, String) 就不是
不可变引用 &T ,但是注意:可变引用 &mut T 是不可以 Copy的。
一个类型可以是 Copy 的,当且仅当 :
✅ 所有字段都实现了 Copy
✅ 不拥有任何堆上的资源
✅ 没有实现 Drop trait
✅ 是固定大小的(Sized)
函数传值和返回 将值传递给函数,一样会发生 移动 或者 复制,就跟 let 语句一样,下面的代码展示了所有权、作用域的规则:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 fn main () { let s = String ::from ("hello" ); takes_ownership (s); let x = 5 ; makes_copy (x); } fn takes_ownership (some_string: String ) { println! ("{}" , some_string); } fn makes_copy (some_integer: i32 ) { println! ("{}" , some_integer); }
同样的,函数返回值也有所有权,例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 fn main () { let s1 = gives_ownership (); let s2 = String ::from ("hello" ); let s3 = takes_and_gives_back (s2); } fn gives_ownership () -> String { let some_string = String ::from ("hello" ); some_string } fn takes_and_gives_back (a_string: String ) -> String { a_string }
所有权很强大,避免了内存的不安全性,但是也带来了一个新麻烦: 总是把一个值传来传去来使用它 。 传入一个函数,很可能还要从该函数传出去,结果就是语言表达变得非常啰嗦,幸运的是,Rust 提供了新功能解决这个问题。
引用和借用 引用与解引用 常规引用是一个指针类型,指向了对象存储的内存地址。在下面代码中,我们创建一个 i32 值的引用 y,然后使用解引用运算符来解出 y 所使用的值:
1 2 3 4 5 6 7 fn main () { let x = 5 ; let y = &x; assert_eq! (5 , x); assert_eq! (5 , *y); }
变量 x 存放了一个 i32 值 5。y 是 x 的一个引用。可以断言 x 等于 5。然而,如果希望对 y 的值做出断言,必须使用 *y 来解出引用所指向的值(也就是解引用 )。一旦解引用了 y,就可以访问 y 所指向的整型值并可以与 5 做比较。
不可变引用 下面的代码,我们用 s1 的引用作为参数传递给 calculate_length 函数,而不是把 s1 的所有权转移给该函数:
1 2 3 4 5 6 7 8 9 10 11 fn main () { let s1 = String ::from ("hello" ); let len = calculate_length (&s1); println! ("The length of '{}' is {}." , s1, len); } fn calculate_length (s: &String ) -> usize { s.len () }
这里,& 符号即是引用,它们允许你使用值,但是不获取所有权。通过 &s1 语法,我们创建了一个指向 s1 的引用 ,但是并不拥有它。因为并不拥有这个值,当引用离开作用域后,其指向的值也不会被丢弃。
可变引用 1 2 3 4 5 6 7 8 9 fn main () { let mut s = String ::from ("hello" ); change (&mut s); } fn change (some_string: &mut String ) { some_string.push_str (", world" ); }
首先,声明 s 是可变类型,其次创建一个可变的引用 &mut s 和接受可变引用参数 some_string: &mut String 的函数。可变引用同时只能存在一个,可变引用并不是随心所欲、想用就用的,它有一个很大的限制: 同一作用域,特定数据只能有一个可变引用 :
1 2 3 4 5 6 let mut s = String ::from ("hello" );let r1 = &mut s;let r2 = &mut s;println! ("{}, {}" , r1, r2);
1 2 3 4 5 6 7 8 9 10 11 error[E0499]: cannot borrow `s` as mutable more than once at a time 同一时间无法对 `s` 进行两次可变借用 --> src/main.rs:5 :14 | 4 | let r1 = &mut s; | ------ first mutable borrow occurs here 首个可变引用在这里借用 5 | let r2 = &mut s; | ^^^^^^ second mutable borrow occurs here 第二个可变引用在这里借用 6 |7 | println! ("{}, {}" , r1, r2); | -- first borrow later used here 第一个借用在这里使用
在数据被可变借用期间,原所有者完全失去对数据的访问权 ,既不能读也不能写。
1 2 3 4 5 6 let mut s = String ::from ("hello" );let r1 = &mut s;s.push_str (", world!" ); println! ("{}" , r1);
1 2 3 4 5 6 7 8 9 10 error[E0499]: cannot borrow `s` as mutable more than once at a time --> src/main.rs:5 :5 | 4 | let r1 = &mut s; | ------ first mutable borrow occurs here 5 | s.push_str (", world!" ); | ^ second mutable borrow occurs here 6 | 7 | println! ("{}" , r1); | -- first borrow later used here
NLL(非词法生命周期)
概念
何时结束
说明
借用的生命周期 最后一次使用后
NLL 智能推断
值的所有权 作用域 } 结束
drop 时机
复合类型 字符串 Rust 中的字符串主要有两种核心类型:String 和 &str。
两种核心字符串类型 &str(字符串切片)1 2 3 4 5 6 let s1 : &str = "Hello, Rust!" ;let string = String ::from ("Hello" );let s2 : &str = &string[0 ..3 ];
特点:
不可变引用(borrowed)
固定大小的视图
通常作为函数参数使用
String(可增长字符串)1 2 3 4 5 6 7 8 9 let mut s = String ::new ();let s = String ::from ("Hello" );let s = "Hello" .to_string ();let s = String ::with_capacity (100 );
特点:
堆上分配,可增长
拥有所有权(owned)
可修改
内存布局对比 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 ┌─────────────────────────────────────────────────────────────────────┐ │ String 内存布局 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ 栈上 (Stack) 堆上 (Heap) │ │ ┌────────────────┐ ┌───┬───┬───┬───┬───┐ │ │ │ ptr ──────────────────────────►│ H │ e │ l │ l │ o │ │ │ ├────────────────┤ └───┴───┴───┴───┴───┘ │ │ │ len = 5 │ │ │ ├────────────────┤ │ │ │ capacity = 8 │ │ │ └────────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────┘ ┌─────────────────────────────────────────────────────────────────────┐ │ &str 内存布局 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ 栈上 (Stack) 只读内存/堆 │ │ ┌────────────────┐ ┌───┬───┬───┬───┬───┐ │ │ │ ptr ──────────────────────────►│ H │ e │ l │ l │ o │ │ │ ├────────────────┤ └───┴───┴───┴───┴───┘ │ │ │ len = 5 │ (胖指针: ptr + len) │ │ └────────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────┘
String 常用操作 创建与修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 fn main () { let mut s = String ::from ("Hello" ); s.push_str (", World" ); s.push ('!' ); s.insert (0 , '🎉'); s.insert_str (1 , " " ); let new_s = s.replace ("World" , "Rust" ); s.pop (); s.remove (0 ); s.truncate (5 ); s.clear (); }
字符串连接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 fn main () { let s1 = String ::from ("Hello" ); let s2 = String ::from ("World" ); let s3 = s1 + " " + &s2; let s1 = String ::from ("Hello" ); let s4 = format! ("{} {} {}" , s1, s2, "Rust" ); let mut s5 = String ::from ("Hello" ); s5.push_str (" World" ); let s6 = ["Hello" , " " , "World" ].concat (); let s7 = ["Hello" , "World" ].join (" " ); }
UTF-8 编码特性 Rust 字符串强制使用 UTF-8 编码,这带来一些特殊行为:
字符与字节的区别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 fn main () { let s = "你好Rust" ; println! ("字节长度: {}" , s.len ()); println! ("字符数量: {}" , s.chars ().count ()); for b in s.bytes () { print! ("{} " , b); } for c in s.chars () { print! ("{} " , c); } }
索引限制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 fn main () { let s = String ::from ("你好" ); let slice = &s[0 ..3 ]; let first_char = s.chars ().nth (0 ); }
类型转换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 fn main () { let s : String = "hello" .to_string (); let s : String = String ::from ("hello" ); let s : String = "hello" .to_owned (); let s : String = "hello" .into (); let string = String ::from ("hello" ); let slice : &str = &string; let slice : &str = string.as_str (); let slice : &str = &string[..]; let s = String ::from ("hello" ); let bytes : Vec <u8 > = s.into_bytes (); let s = String ::from_utf8 (bytes).unwrap (); let s = "hello" ; let bytes : &[u8 ] = s.as_bytes (); let s = std::str ::from_utf8 (bytes).unwrap (); let n = 42 ; let s = n.to_string (); let s = format! ("{}" , n); let n : i32 = "42" .parse ().unwrap (); let n = "42" .parse::<i32 >().unwrap (); }
Deref 强制转换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 fn print_str (s: &str ) { println! ("{}" , s); } fn main () { let owned = String ::from ("Hello" ); let borrowed = "World" ; print_str (&owned); print_str (borrowed); }
性能与实践 容量预分配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 fn main () { let mut s = String ::new (); for i in 0 ..1000 { s.push_str (&i.to_string ()); } let mut s = String ::with_capacity (4000 ); for i in 0 ..1000 { s.push_str (&i.to_string ()); } println! ("Capacity: {}" , s.capacity ()); }
避免不必要的克隆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 fn process (s: String ) { }let s = String ::from ("hello" );process (s.clone ()); fn process_ref (s: &str ) { }process_ref (&s);use std::borrow::Cow;fn maybe_modify (s: &str ) -> Cow<str > { if s.contains ("old" ) { Cow::Owned (s.replace ("old" , "new" )) } else { Cow::Borrowed (s) } }
函数参数建议
1 2 3 4 5 6 7 8 9 10 11 12 13 fn greet (name: &str ) { println! ("Hello, {}" , name); } greet ("World" );greet (&String ::from ("Rust" ));fn take_ownership (s: String ) { }
常见陷阱总结
陷阱
问题
解决方案
直接索引
s[0] 编译错误使用 s.chars().nth(0)
无效切片边界
&s[0..2] panic(中文)确保在字符边界切分
+ 运算符左侧所有权被移动
使用 format! 或 clone()
比较长度
len() 返回字节数使用 chars().count()
空字符串检查
多种方式
优先用 is_empty()
切片 切片(Slice)是 Rust 中非常核心的概念,它是对连续内存序列 的一个引用视图 ,不拥有数据所有权。
切片基本概念 什么是切片
1 2 3 4 5 6 7 8 fn main () { let arr = [1 , 2 , 3 , 4 , 5 ]; let slice : &[i32 ] = &arr[1 ..4 ]; println! ("{:?}" , slice); }
切片的本质
1 2 3 4 5 6 7 8 9 10 11 12 ┌─────────────────────────────────────────────────────────────────────┐ │ 切片是"胖指针" │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ 普通指针 (8 bytes) 切片/胖指针 (16 bytes) │ │ ┌──────────────┐ ┌──────────────┐ │ │ │ ptr │ │ ptr │ ──► 指向数据起始位置 │ │ └──────────────┘ ├──────────────┤ │ │ │ len │ ──► 元素数量 │ │ └──────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────┘
切片的内存布局 1 2 3 4 5 6 7 8 9 fn main () { let arr : [i32 ; 5 ] = [10 , 20 , 30 , 40 , 50 ]; let slice : &[i32 ] = &arr[1 ..4 ]; println! ("数组地址: {:p}" , &arr); println! ("切片指向: {:p}" , slice.as_ptr ()); println! ("切片长度: {}" , slice.len ()); println! ("切片大小: {} bytes" , std::mem::size_of_val (&slice)); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 内存示意图: arr (栈上连续内存): ┌──────┬──────┬──────┬──────┬──────┐ │ 10 │ 20 │ 30 │ 40 │ 50 │ └──────┴──────┴──────┴──────┴──────┘ [0] [1] [2] [3] [4] ▲ │ │ │ └─────────────┘ slice 覆盖范围 [1..4] slice (胖指针): ┌─────────────────┐ │ ptr ──────────────► 指向 arr[1] 的地址 ├─────────────────┤ │ len = 3 │ └─────────────────┘
切片语法详解 Range 语法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 fn main () { let arr = [0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ]; let a = &arr[2 ..5 ]; let b = &arr[2 ..=5 ]; let c = &arr[..4 ]; let d = &arr[6 ..]; let e = &arr[..]; let full = &arr[0 ..arr.len ()]; println! ("a: {:?}" , a); println! ("b: {:?}" , b); println! ("c: {:?}" , c); println! ("d: {:?}" , d); println! ("e: {:?}" , e); }
范围类型对照表
语法
类型
含义
示例结果
start..endRange[start, end)
[1..4] → 索引1,2,3
start..=endRangeInclusive[start, end]
[1..=4] → 索引1,2,3,4
start..RangeFrom[start, 末尾]
[2..] → 从索引2到末尾
..endRangeTo[0, end)
[..3] → 索引0,1,2
..=endRangeToInclusive[0, end]
[..=3] → 索引0,1,2,3
..RangeFull全部
[..] → 所有元素
常见切片类型 数组切片 &[T]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 fn main () { let arr : [i32 ; 5 ] = [1 , 2 , 3 , 4 , 5 ]; let slice : &[i32 ] = &arr[..]; let vec : Vec <i32 > = vec! [1 , 2 , 3 , 4 , 5 ]; let slice : &[i32 ] = &vec[1 ..4 ]; let sub_slice : &[i32 ] = &slice[0 ..2 ]; println! ("{:?}" , sub_slice); }
字符串切片 &str
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 fn main () { let s1 : &str = "Hello, World!" ; let string = String ::from ("Hello, Rust!" ); let s2 : &str = &string[0 ..5 ]; let chinese = "你好世界" ; let s3 = &chinese[0 ..3 ]; println! ("{}" , s3); }
可变切片 &mut [T]
1 2 3 4 5 6 7 8 9 10 11 12 13 fn main () { let mut arr = [1 , 2 , 3 , 4 , 5 ]; let slice : &mut [i32 ] = &mut arr[1 ..4 ]; slice[0 ] = 20 ; slice[1 ] = 30 ; slice[2 ] = 40 ; println! ("{:?}" , arr); }
切片与所有权类型的关系 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ┌─────────────────────────────────────────────────────────────────────┐ │ 所有权类型 vs 借用类型 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────────┐ ┌─────────────┐ │ │ │ Owned │ │ Borrowed │ │ │ │ (拥有数据) │ ──Deref──► │ (借用视图) │ │ │ └─────────────┘ └─────────────┘ │ │ │ │ ┌─────────────┐ ┌─────────────┐ │ │ │ String │ ──────────────► │ &str │ │ │ └─────────────┘ └─────────────┘ │ │ │ │ ┌─────────────┐ ┌─────────────┐ │ │ │ Vec<T> │ ──────────────► │ &[T] │ │ │ └─────────────┘ └─────────────┘ │ │ │ │ ┌─────────────┐ ┌─────────────┐ │ │ │ [T; N] │ ──────────────► │ &[T] │ │ │ │ (数组) │ │ │ │ │ └─────────────┘ └─────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────┘
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 fn main () { let vec : Vec <i32 > = vec! [1 , 2 , 3 ]; let slice : &[i32 ] = &vec; let slice : &[i32 ] = vec.as_slice (); let slice : &[i32 ] = &vec[..]; let arr : [i32 ; 3 ] = [1 , 2 , 3 ]; let slice : &[i32 ] = &arr; let slice : &[i32 ] = &arr[..]; let string : String = String ::from ("hello" ); let slice : &str = &string; let slice : &str = string.as_str (); }
切片常用方法 基础方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 fn main () { let slice : &[i32 ] = &[10 , 20 , 30 , 40 , 50 ]; println! ("长度: {}" , slice.len ()); println! ("是否为空: {}" , slice.is_empty ()); println! ("第一个: {:?}" , slice.first ()); println! ("最后一个: {:?}" , slice.last ()); println! ("索引2: {:?}" , slice.get (2 )); println! ("索引10: {:?}" , slice.get (10 )); println! ("slice[2] = {}" , slice[2 ]); }
迭代与遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 fn main () { let slice = &[1 , 2 , 3 , 4 , 5 ]; for item in slice.iter () { print! ("{} " , item); } println! (); for (index, item) in slice.iter ().enumerate () { println! ("[{}] = {}" , index, item); } let mut arr = [1 , 2 , 3 , 4 , 5 ]; let slice = &mut arr[..]; for item in slice.iter_mut () { *item *= 2 ; } println! ("{:?}" , arr); }
查找与搜索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 fn main () { let slice = &[3 , 1 , 4 , 1 , 5 , 9 , 2 , 6 ]; println! ("包含 4: {}" , slice.contains (&4 )); println! ("4 的位置: {:?}" , slice.iter ().position (|&x| x == 4 )); println! ("以 [3,1] 开头: {}" , slice.starts_with (&[3 , 1 ])); println! ("以 [2,6] 结尾: {}" , slice.ends_with (&[2 , 6 ])); let sorted = &[1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ]; println! ("二分查找 5: {:?}" , sorted.binary_search (&5 )); println! ("二分查找 10: {:?}" , sorted.binary_search (&10 )); }
分割与连接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 fn main () { let slice = &[1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 ]; let (left, right) = slice.split_at (4 ); println! ("左: {:?}, 右: {:?}" , left, right); let parts : Vec <&[i32 ]> = slice.split (|&x| x % 3 == 0 ).collect (); println! ("{:?}" , parts); for chunk in slice.chunks (3 ) { println! ("块: {:?}" , chunk); } for window in slice.windows (3 ) { println! ("窗口: {:?}" , window); } }
排序与反转(需要可变切片)
1 2 3 4 5 6 7 8 9 10 11 12 fn main () { let mut arr = [3 , 1 , 4 , 1 , 5 , 9 , 2 , 6 ]; let slice = &mut arr[..]; slice.sort (); println! ("排序后: {:?}" , slice); slice.reverse (); println! ("反转后: {:?}" , slice); }
复制与填充
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 fn main () { let src = [1 , 2 , 3 ]; let mut dst = [0 ; 5 ]; dst[..3 ].copy_from_slice (&src); println! ("{:?}" , dst); dst.fill (7 ); println! ("{:?}" , dst); dst.fill_with (|| 42 ); println! ("{:?}" , dst); let mut arr = [1 , 2 , 3 , 4 , 5 ]; arr.swap (0 , 4 ); println! ("{:?}" , arr); }
函数参数中的切片 切片作为参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 fn sum (numbers: &[i32 ]) -> i32 { numbers.iter ().sum () } fn sum_vec (numbers: &Vec <i32 >) -> i32 { numbers.iter ().sum () } fn main () { let arr = [1 , 2 , 3 , 4 , 5 ]; let vec = vec! [1 , 2 , 3 , 4 , 5 ]; println! ("数组求和: {}" , sum (&arr)); println! ("Vec求和: {}" , sum (&vec)); println! ("部分求和: {}" , sum (&arr[1 ..4 ])); println! ("部分求和: {}" , sum (&vec[..3 ])); }
可变切片参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 fn double_values (slice: &mut [i32 ]) { for item in slice.iter_mut () { *item *= 2 ; } } fn main () { let mut arr = [1 , 2 , 3 , 4 , 5 ]; double_values (&mut arr[1 ..4 ]); println! ("{:?}" , arr); double_values (&mut arr); println! ("{:?}" , arr); }
返回切片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 fn first_half (slice: &[i32 ]) -> &[i32 ] { let mid = slice.len () / 2 ; &slice[..mid] } fn first_half_mut (slice: &mut [i32 ]) -> &mut [i32 ] { let mid = slice.len () / 2 ; &mut slice[..mid] } fn main () { let arr = [1 , 2 , 3 , 4 , 5 , 6 ]; let half = first_half (&arr); println! ("{:?}" , half); }
元组 元组是 Rust 中一种重要的复合类型,可以将多个不同类型 的值组合成一个单一的复合值。
元组基本概念 什么是元组
1 2 3 4 5 6 fn main () { let tuple : (i32 , f64 , char , &str ) = (42 , 3.14 , 'R' , "Rust" ); println! ("{:?}" , tuple); }
元组的特点
1 2 3 4 5 6 7 8 9 10 11 ┌─────────────────────────────────────────────────────────────────────┐ │ 元组特性 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ ✓ 固定长度 - 一旦声明,长度不可改变 │ │ ✓ 异构类型 - 每个元素可以是不同类型 │ │ ✓ 有序集合 - 元素按位置索引访问 │ │ ✓ 值类型 - 存储在栈上(如果所有元素都是栈类型) │ │ ✓ 可解构 - 支持模式匹配解构 │ │ │ └─────────────────────────────────────────────────────────────────────┘
元组的创建与类型 基本创建方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 fn main () { let t1 : (i32 , f64 , bool ) = (100 , 2.5 , true ); let t2 = (100 , 2.5 , true ); let t3 : (i32 ,) = (42 ,); let not_tuple = (42 ); let unit : () = (); let nested : ((i32 , i32 ), (f64 , f64 )) = ((1 , 2 ), (3.0 , 4.0 )); println! ("t1: {:?}" , t1); println! ("t3: {:?}" , t3); println! ("nested: {:?}" , nested); }
元组类型签名
1 2 3 4 5 6 7 8 9 10 fn main () { let a : (i32 , i32 ) = (1 , 2 ); let b : (i32 , i64 ) = (1 , 2 ); let c : (i64 , i32 ) = (1 , 2 ); }
内存布局 1 2 3 4 5 6 fn main () { let tuple : (u8 , u32 , u8 ) = (1 , 2 , 3 ); println! ("元组大小: {} bytes" , std::mem::size_of_val (&tuple)); println! ("元组对齐: {} bytes" , std::mem::align_of_val (&tuple)); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ┌─────────────────────────────────────────────────────────────────────┐ │ (u8, u32, u8) 实际内存布局 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ 声明顺序: (u8, u32, u8) │ │ 理论大小: 1 + 3(padding) + 4 + 1 + 3(padding) = 12 bytes │ │ │ │ ═══════════════════════════════════════════════════════════ │ │ │ │ 实际布局(Rust 编译器重排优化后): │ │ │ │ ┌────────────────────────────┬──────┬──────┬──────────────┐ │ │ │ u32 │ u8 │ u8 │ padding │ │ │ │ 4 bytes │ 1B │ 1B │ 2 bytes │ │ │ └────────────────────────────┴──────┴──────┴──────────────┘ │ │ offset: 0 4 5 6 8 │ │ │ │ 实际大小: 4 + 1 + 1 + 2(padding) = 8 bytes │ │ 对齐要求: 4 bytes (最大成员 u32 的对齐) │ │ │ └─────────────────────────────────────────────────────────────────────┘
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #[repr(C)] struct TupleC (u8 , u32 , u8 );struct TupleRust (u8 , u32 , u8 );fn main () { println! ("repr(C) 大小: {} bytes" , std::mem::size_of::<TupleC>()); println! ("repr(Rust) 大小: {} bytes" , std::mem::size_of::<TupleRust>()); }
访问元组元素 索引访问(点号语法)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 fn main () { let tuple = (500 , 6.4 , "hello" , true ); let first = tuple.0 ; let second = tuple.1 ; let third = tuple.2 ; let fourth = tuple.3 ; println! ("第一个元素: {}" , first); println! ("第二个元素: {}" , second); println! ("第三个元素: {}" , third); println! ("第四个元素: {}" , fourth); }
解构(Destructuring)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 fn main () { let tuple = (1 , 2.0 , "three" ); let (x, y, z) = tuple; println! ("x={}, y={}, z={}" , x, y, z); let (a, _, c) = tuple; println! ("a={}, c={}" , a, c); let (first, ..) = tuple; println! ("first={}" , first); let tuple5 = (1 , 2 , 3 , 4 , 5 ); let (head, .., tail) = tuple5; println! ("head={}, tail={}" , head, tail); let nested = ((1 , 2 ), (3 , 4 )); let ((a, b), (c, d)) = nested; println! ("a={}, b={}, c={}, d={}" , a, b, c, d); }
可变元组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 fn main () { let mut tuple = (1 , 2 , 3 ); tuple.0 = 100 ; tuple.1 = 200 ; println! ("{:?}" , tuple); let (ref mut a, ref mut b, _) = tuple; *a = 1000 ; *b = 2000 ; println! ("{:?}" , tuple); }
单元类型 () 我们之间讲到的单元类型也是一种特殊的元组。
单元类型的概念
1 2 3 4 5 6 7 8 9 10 fn main () { let unit : () = (); println! ("() 的大小: {} bytes" , std::mem::size_of::<()>()); assert_eq! (unit, ()); }
单元类型的用途
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 fn no_return () { println! ("这个函数没有显式返回值" ); } fn explicit_unit () -> () { println! ("显式声明返回 ()" ); } fn main () { let result = no_return (); println! ("result: {:?}" , result); let x = { let y = 5 ; }; println! ("x: {:?}" , x); let mut a = 0 ; let b = (a = 5 ); println! ("b: {:?}" , b); } struct Container <T> { value: T, } fn main () { let empty : Container<()> = Container { value: () }; } fn might_fail () -> Result <(), String > { Ok (()) }
元组与函数 作为函数参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 fn print_point (point: (i32 , i32 )) { println! ("Point: ({}, {})" , point.0 , point.1 ); } fn print_point_destructured ((x, y): (i32 , i32 )) { println! ("Point: ({}, {})" , x, y); } fn main () { let p = (10 , 20 ); print_point (p); print_point_destructured (p); }
作为返回值(多返回值)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 fn min_max (numbers: &[i32 ]) -> Option <(i32 , i32 )> { if numbers.is_empty () { return None ; } let mut min = numbers[0 ]; let mut max = numbers[0 ]; for &num in numbers.iter ().skip (1 ) { if num < min { min = num; } if num > max { max = num; } } Some ((min, max)) } fn divide_with_remainder (dividend: i32 , divisor: i32 ) -> (i32 , i32 ) { let quotient = dividend / divisor; let remainder = dividend % divisor; (quotient, remainder) } fn main () { if let Some ((min, max)) = min_max (&[3 , 1 , 4 , 1 , 5 , 9 , 2 , 6 ]) { println! ("最小值: {}, 最大值: {}" , min, max); } let (quotient, remainder) = divide_with_remainder (17 , 5 ); println! ("17 / 5 = {} 余 {}" , quotient, remainder); }
交换值的惯用法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 fn main () { let mut a = 1 ; let mut b = 2 ; println! ("交换前: a={}, b={}" , a, b); (a, b) = (b, a); println! ("交换后: a={}, b={}" , a, b); std::mem::swap (&mut a, &mut b); println! ("再次交换: a={}, b={}" , a, b); }
结构体 结构体是 Rust 中创建自定义数据类型的基本方式,将多个相关值组合成一个整体。
结构体形式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 struct User { username: String , email: String , age: u32 , active: bool , } struct Color (u8 , u8 , u8 );struct Point (f64 , f64 );struct UserId (u64 ); struct Marker ;fn main () { let user = User { username: String ::from ("alice" ), email: String ::from ("alice@example.com" ), age: 25 , active: true , }; let red = Color (255 , 0 , 0 ); let origin = Point (0.0 , 0.0 ); let id = UserId (12345 ); let marker = Marker; println! ("用户名: {}" , user.username); println! ("红色值: {}" , red.0 ); println! ("用户ID: {}" , id.0 ); println! ("Marker大小: {} bytes" , std::mem::size_of::<Marker>()); }
1 2 3 4 5 6 7 8 ┌────────────────┬─────────────────┬─────────────────┬──────────────────┐ │ 特性 │ 常规结构体 │ 元组结构体 │ 单元结构体 │ ├────────────────┼─────────────────┼─────────────────┼──────────────────┤ │ 字段名称 │ 有 │ 无 │ 无 │ │ 访问方式 │ .name │ .0 .1 .2 │ N/A │ │ 内存大小 │ 字段和+对齐 │ 字段和+对齐 │ 0 │ │ 主要用途 │ 数据建模 │ NewType/简单 │ 标记/trait │ └────────────────┴─────────────────┴─────────────────┴──────────────────┘
创建与初始化 基本创建与字段简写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 struct Point { x: i32 , y: i32 , } fn main () { let p1 = Point { x: 10 , y: 20 }; let p2 = Point { y: 50 , x: 30 }; let x = 100 ; let y = 200 ; let p3 = Point { x, y }; println! ("p1: ({}, {})" , p1.x, p1.y); println! ("p3: ({}, {})" , p3.x, p3.y); }
结构体更新语法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 struct Config { host: String , port: u16 , timeout: u32 , debug: bool , } fn main () { let config1 = Config { host: String ::from ("localhost" ), port: 8080 , timeout: 30 , debug: true , }; let config2 = Config { port: 3000 , ..config1 }; println! ("{}" , config1.port); println! ("{}" , config1.debug); println! ("config2 port: {}" , config2.port); }
字段访问与修改 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 struct Rectangle { width: u32 , height: u32 , } fn main () { let rect = Rectangle { width: 30 , height: 50 }; println! ("宽: {}, 高: {}" , rect.width, rect.height); let area = rect.width * rect.height; println! ("面积: {}" , area); let mut rect2 = Rectangle { width: 10 , height: 20 }; rect2.width = 100 ; rect2.height = 200 ; println! ("修改后: {}x{}" , rect2.width, rect2.height); let rect_ref = ▭ println! ("通过引用: {}" , rect_ref.width); modify_rect (&mut rect2); println! ("函数修改后: {}x{}" , rect2.width, rect2.height); } fn modify_rect (r: &mut Rectangle) { r.width *= 2 ; r.height *= 2 ; }
所有权与借用 字段的移动
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 struct Container { data: String , count: u32 , } fn main () { let c = Container { data: String ::from ("hello" ), count: 1 , }; let data = c.data; println! ("{}" , c.count); println! ("{}" , data); }
部分借用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 struct Data { field1: String , field2: String , } fn main () { let mut data = Data { field1: String ::from ("one" ), field2: String ::from ("two" ), }; let r1 = &data.field1; let r2 = &mut data.field2; r2.push_str (" modified" ); println! ("{}, {}" , r1, r2); }
内存布局 默认布局
1 2 3 4 5 6 7 8 9 10 struct Example { a: u8 , b: u32 , c: u8 , } fn main () { println! ("大小: {} bytes" , std::mem::size_of::<Example>()); println! ("对齐: {} bytes" , std::mem::align_of::<Example>()); }
1 2 3 4 5 6 7 Rust 编译器可能重排字段以优化内存: ┌────────────────────────────┬──────┬──────┬──────────────┐ │ b (u32) │ a │ c │ padding │ │ 4 bytes │ 1B │ 1B │ 2 bytes │ └────────────────────────────┴──────┴──────┴──────────────┘ 总大小: 8 bytes(优化后)
repr 属性控制布局
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 struct Example { a: u8 , b: u32 , c: u8 , } #[repr(C)] struct CLayout { a: u8 , b: u32 , c: u8 , } #[repr(packed)] struct Packed { a: u8 , b: u32 , c: u8 , } fn main () { println! ("默认: {} bytes" , std::mem::size_of::<Example>()); println! ("repr(C): {} bytes" , std::mem::size_of::<CLayout>()); println! ("packed: {} bytes" , std::mem::size_of::<Packed>()); }
打印结构体 1 2 3 4 5 6 7 8 9 10 11 12 13 #[derive(Debug)] struct Point { x: i32 , y: i32 , } fn main () { let p = Point { x: 10 , y: 20 }; println! ("{:?}" , p); println! ("{:#?}" , p); }
枚举 枚举是 Rust 中定义”多选一”类型的方式,一个值在某一时刻只能是其中一个变体。
基本枚举定义 简单枚举 (无关联数据)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 enum Direction { Up, Down, Left, Right, } enum Status { Pending, Running, Completed, Failed, } fn main () { let dir = Direction::Up; let status = Status::Running; match dir { Direction::Up => println! ("向上" ), Direction::Down => println! ("向下" ), Direction::Left => println! ("向左" ), Direction::Right => println! ("向右" ), } if let Status ::Running = status { println! ("正在运行中..." ); } }
带关联数据的枚举
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 enum Message { Quit, Move { x: i32 , y: i32 }, Write (String ), ChangeColor (u8 , u8 , u8 ), } fn main () { let m1 = Message::Quit; let m2 = Message::Move { x: 10 , y: 20 }; let m3 = Message::Write (String ::from ("hello" )); let m4 = Message::ChangeColor (255 , 128 , 0 ); match m2 { Message::Quit => println! ("退出" ), Message::Move { x, y } => println! ("移动到 ({}, {})" , x, y), Message::Write (text) => println! ("消息: {}" , text), Message::ChangeColor (r, g, b) => println! ("颜色: RGB({},{},{})" , r, g, b), } }
三种变体形式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 enum Example { Unit, Tuple (i32 , String ), Struct { id: u32 , name: String }, } fn main () { let a = Example::Unit; let b = Example::Tuple (42 , String ::from ("hello" )); let c = Example::Struct { id: 1 , name: String ::from ("test" ) }; match b { Example::Unit => println! ("单元变体" ), Example::Tuple (num, text) => println! ("元组: {}, {}" , num, text), Example::Struct { id, name } => println! ("结构体: {} - {}" , id, name), } }
1 2 3 4 5 6 7 ┌─────────────────┬────────────────────┬─────────────────────────────┐ │ 变体类型 │ 语法 │ 示例 │ ├─────────────────┼────────────────────┼─────────────────────────────┤ │ 单元变体 │ Name │ Quit, None, Empty │ │ 元组变体 │ Name(T1, T2) │ Some(42), Move(10, 20) │ │ 结构体变体 │ Name { f: T } │ Point { x: 1, y: 2 } │ └─────────────────┴────────────────────┴─────────────────────────────┘
枚举的判别值 默认判别值
1 2 3 4 5 6 7 8 9 10 11 12 enum Number { Zero, One, Two, } fn main () { println! ("Zero = {}" , Number::Zero as i32 ); println! ("One = {}" , Number::One as i32 ); println! ("Two = {}" , Number::Two as i32 ); }
自定义判别值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 enum HttpStatus { Ok = 200 , NotFound = 404 , InternalError = 500 , } enum Color { Red = 0xFF0000 , Green = 0x00FF00 , Blue = 0x0000FF , } #[repr(u8)] enum Flag { A = 1 , B = 2 , C = 4 , } fn main () { println! ("OK = {}" , HttpStatus::Ok as i32 ); println! ("NotFound = {}" , HttpStatus::NotFound as i32 ); println! ("Red = 0x{:06X}" , Color::Red as i32 ); println! ("Flag 大小: {} byte" , std::mem::size_of::<Flag>()); }
部分指定 (自动递增)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 enum Mixed { A, B = 10 , C, D, E = 100 , F, } fn main () { println! ("A={}, B={}, C={}, D={}, E={}, F={}" , Mixed::A as i32 , Mixed::B as i32 , Mixed::C as i32 , Mixed::D as i32 , Mixed::E as i32 , Mixed::F as i32 ); }
核心枚举 Option 和 Result 是 Rust 中最重要的两个枚举,用于处理空值 和错误 ,替代了其他语言中的 null 和异常机制。
Option<T> - 可选值 定义
1 2 3 4 5 enum Option <T> { Some (T), None , }
为什么需要 Option?
1 2 3 4 5 6 7 8 9 10 11 12 fn main () { let maybe_number : Option <i32 > = Some (42 ); let no_number : Option <i32 > = None ; }
创建 Option
1 2 3 4 5 6 7 8 9 10 11 12 13 14 fn main () { let a : Option <i32 > = Some (5 ); let b = Some ("hello" ); let c = Some (3.14 ); let d : Option <i32 > = None ; let e : Option <String > = None ; println! ("a = {:?}" , a); println! ("d = {:?}" , d); }
Option 不能直接使用内部值
1 2 3 4 5 6 7 8 9 10 11 fn main () { let x : Option <i32 > = Some (5 ); let y : i32 = 10 ; let sum = x.unwrap () + y; println! ("sum = {}" , sum); }
基本方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 fn main () { let some_val : Option <i32 > = Some (10 ); let none_val : Option <i32 > = None ; println! ("some_val.is_some() = {}" , some_val.is_some ()); println! ("some_val.is_none() = {}" , some_val.is_none ()); println! ("none_val.is_some() = {}" , none_val.is_some ()); println! ("none_val.is_none() = {}" , none_val.is_none ()); let v1 = some_val.unwrap (); println! ("unwrap = {}" , v1); let v2 = some_val.expect ("错误信息" ); println! ("expect = {}" , v2); println! ("some.unwrap_or(0) = {}" , some_val.unwrap_or (0 )); println! ("none.unwrap_or(0) = {}" , none_val.unwrap_or (0 )); let s : Option <String > = None ; println! ("default = '{}'" , s.unwrap_or_default ()); let n : Option <i32 > = None ; println! ("default = {}" , n.unwrap_or_default ()); }
常见使用场景
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 fn main () { let numbers = vec! [1 , 2 , 3 , 4 , 5 ]; let first : Option <&i32 > = numbers.first (); let tenth : Option <&i32 > = numbers.get (10 ); println! ("first = {:?}" , first); println! ("tenth = {:?}" , tenth); let good : Result <i32 , _> = "42" .parse (); let bad : Result <i32 , _> = "abc" .parse (); let good_opt : Option <i32 > = "42" .parse ().ok (); let bad_opt : Option <i32 > = "abc" .parse ().ok (); println! ("good_opt = {:?}" , good_opt); println! ("bad_opt = {:?}" , bad_opt); use std::collections::HashMap; let mut map = HashMap::new (); map.insert ("a" , 1 ); let val : Option <&i32 > = map.get ("a" ); let none : Option <&i32 > = map.get ("b" ); }
Result<T, E> - 错误处理 定义
1 2 3 4 5 enum Result <T, E> { Ok (T), Err (E), }
为什么需要 Result?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 fn divide (a: i32 , b: i32 ) -> Result <i32 , String > { if b == 0 { Err (String ::from ("除数不能为零" )) } else { Ok (a / b) } } fn main () { let result = divide (10 , 2 ); }
创建 Result
1 2 3 4 5 6 7 8 9 10 11 12 13 fn main () { let success : Result <i32 , String > = Ok (42 ); let ok_str : Result <&str , i32 > = Ok ("成功" ); let failure : Result <i32 , String > = Err (String ::from ("失败了" )); let err_num : Result <&str , i32 > = Err (404 ); println! ("success = {:?}" , success); println! ("failure = {:?}" , failure); }
基本方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 fn main () { let ok_val : Result <i32 , &str > = Ok (10 ); let err_val : Result <i32 , &str > = Err ("错误" ); println! ("ok_val.is_ok() = {}" , ok_val.is_ok ()); println! ("ok_val.is_err() = {}" , ok_val.is_err ()); println! ("err_val.is_ok() = {}" , err_val.is_ok ()); println! ("err_val.is_err() = {}" , err_val.is_err ()); let v1 = ok_val.unwrap (); println! ("unwrap = {}" , v1); let v2 = ok_val.expect ("失败了" ); println! ("expect = {}" , v2); let e = err_val.unwrap_err (); println! ("unwrap_err = {}" , e); println! ("ok.unwrap_or(0) = {}" , ok_val.unwrap_or (0 )); println! ("err.unwrap_or(0) = {}" , err_val.unwrap_or (0 )); let opt1 : Option <i32 > = ok_val.ok (); let opt2 : Option <i32 > = err_val.ok (); let opt3 : Option <&str > = err_val.err (); let opt4 : Option <&str > = ok_val.err (); println! ("ok_val.ok() = {:?}" , opt1); println! ("err_val.ok() = {:?}" , opt2); }
常见使用场景
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 use std::fs::File;use std::io::Read;fn main () { let file_result : Result <File, std::io::Error> = File::open ("hello.txt" ); let file = file_result.unwrap_or_else (|error| { panic! ("打开文件失败: {:?}" , error); }); let num : Result <i32 , _> = "42" .parse (); let bad : Result <i32 , _> = "abc" .parse (); println! ("num = {:?}" , num); println! ("bad = {:?}" , bad); fn validate_age (age: i32 ) -> Result <i32 , String > { if age < 0 { Err (String ::from ("年龄不能为负" )) } else if age > 150 { Err (String ::from ("年龄不合理" )) } else { Ok (age) } } println! ("{:?}" , validate_age (25 )); println! ("{:?}" , validate_age (-5 )); println! ("{:?}" , validate_age (200 )); }
相互转换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 fn main () { let opt : Option <i32 > = Some (5 ); let none : Option <i32 > = None ; let res1 : Result <i32 , &str > = opt.ok_or ("无值" ); let res2 : Result <i32 , &str > = none.ok_or ("无值" ); println! ("opt.ok_or() = {:?}" , res1); println! ("none.ok_or() = {:?}" , res2); let ok : Result <i32 , &str > = Ok (10 ); let err : Result <i32 , &str > = Err ("错误" ); let opt1 : Option <i32 > = ok.ok (); let opt2 : Option <i32 > = err.ok (); println! ("ok.ok() = {:?}" , opt1); println! ("err.ok() = {:?}" , opt2); let opt3 : Option <&str > = ok.err (); let opt4 : Option <&str > = err.err (); println! ("ok.err() = {:?}" , opt3); println! ("err.err() = {:?}" , opt4); }
内存布局 基本原理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 enum Simple { A, B, C, } enum WithData { Empty, Number (i32 ), Text (String ), } fn main () { println! ("Simple 大小: {} bytes" , std::mem::size_of::<Simple>()); println! ("WithData 大小: {} bytes" , std::mem::size_of::<WithData>()); println! ("String 大小: {} bytes" , std::mem::size_of::<String >()); }
1 2 3 4 5 6 7 8 9 10 11 枚举内存布局 = 判别值(tag)+ 数据(payload) WithData 布局示意: ┌──────────┬─────────────────────────────────────────┐ │ tag │ payload │ │ (8B) │ (最大变体的大小) │ ├──────────┼─────────────────────────────────────────┤ │ 0 │ (Empty: 无数据,但空间仍保留) │ │ 1 │ Number: i32 (4B) + padding │ │ 2 │ Text: String (24B) │ └──────────┴─────────────────────────────────────────┘
数组 数组是固定长度、存储在栈上的同类型元素集合,长度是类型的一部分。
基本定义与创建 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 fn main () { let arr1 : [i32 ; 5 ] = [1 , 2 , 3 , 4 , 5 ]; let arr2 = [1 , 2 , 3 , 4 , 5 ]; let arr3 = [1.0 , 2.0 , 3.0 ]; let arr4 = ["hello" , "world" ]; let zeros = [0 ; 10 ]; let ones = [1u8 ; 100 ]; let spaces = [' ' ; 20 ]; let empty : [i32 ; 0 ] = []; println! ("arr1: {:?}" , arr1); println! ("zeros: {:?}" , zeros); println! ("empty 长度: {}" , empty.len ()); }
长度是类型的一部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 fn main () { let a : [i32 ; 3 ] = [1 , 2 , 3 ]; let b : [i32 ; 5 ] = [1 , 2 , 3 , 4 , 5 ]; println! ("[i32; 3] 大小: {} bytes" , std::mem::size_of::<[i32 ; 3 ]>()); println! ("[i32; 5] 大小: {} bytes" , std::mem::size_of::<[i32 ; 5 ]>()); fn print_three (arr: [i32 ; 3 ]) { println! ("{:?}" , arr); } print_three (a); }
1 2 3 4 5 6 7 8 9 ┌─────────────────────────────────────────────────────────┐ │ 数组类型 = 元素类型 + 长度 │ │ │ │ [i32; 3] → 3 个 i32,共 12 bytes │ │ [i32; 5] → 5 个 i32,共 20 bytes │ │ [u8; 100] → 100 个 u8,共 100 bytes │ │ │ │ 这三个是完全不同的类型! │ └─────────────────────────────────────────────────────────┘
元素访问 索引访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 fn main () { let arr = [10 , 20 , 30 , 40 , 50 ]; let first = arr[0 ]; let third = arr[2 ]; let last = arr[4 ]; println! ("第一个: {}, 第三个: {}, 最后一个: {}" , first, third, last); let mut arr2 = [1 , 2 , 3 ]; arr2[0 ] = 100 ; arr2[2 ] = 300 ; println! ("修改后: {:?}" , arr2); }
越界检查 (运行时 panic)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 fn main () { let arr = [1 , 2 , 3 , 4 , 5 ]; let index = 10 ; let x = arr[index]; match arr.get (2 ) { Some (value) => println! ("索引 2 的值: {}" , value), None => println! ("索引越界" ), } match arr.get (10 ) { Some (value) => println! ("值: {}" , value), None => println! ("索引 10 越界" ), } if let Some (v) = arr.get (3 ) { println! ("值: {}" , v); } }
遍历数组 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 fn main () { let arr = [10 , 20 , 30 , 40 , 50 ]; println! ("遍历引用:" ); for item in &arr { println! (" {}" , item); } println! ("遍历值:" ); for item in arr { println! (" {}" , item); } println! ("带索引:" ); for (index, value) in arr.iter ().enumerate () { println! (" arr[{}] = {}" , index, value); } println! ("索引遍历:" ); for i in 0 ..arr.len () { println! (" arr[{}] = {}" , i, arr[i]); } let mut arr2 = [1 , 2 , 3 ]; for item in &mut arr2 { *item *= 2 ; } println! ("翻倍后: {:?}" , arr2); }
常用方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 fn main () { let arr = [3 , 1 , 4 , 1 , 5 , 9 , 2 , 6 ]; println! ("长度: {}" , arr.len ()); println! ("是否为空: {}" , arr.is_empty ()); println! ("第一个: {:?}" , arr.first ()); println! ("最后一个: {:?}" , arr.last ()); println! ("get(2): {:?}" , arr.get (2 )); println! ("get(100): {:?}" , arr.get (100 )); let slice = &arr[2 ..5 ]; println! ("切片 [2..5]: {:?}" , slice); println! ("包含 5: {}" , arr.contains (&5 )); println! ("包含 7: {}" , arr.contains (&7 )); let sum : i32 = arr.iter ().sum (); println! ("总和: {}" , sum); let max = arr.iter ().max (); println! ("最大值: {:?}" , max); let pos = arr.iter ().position (|&x| x == 5 ); println! ("5 的位置: {:?}" , pos); }
排序与修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 fn main () { let mut arr = [3 , 1 , 4 , 1 , 5 , 9 , 2 , 6 ]; arr.sort (); println! ("升序: {:?}" , arr); arr.sort_by (|a, b| b.cmp (a)); println! ("降序: {:?}" , arr); arr.reverse (); println! ("反转: {:?}" , arr); let mut arr2 = [0 ; 5 ]; arr2.fill (42 ); println! ("填充: {:?}" , arr2); let mut arr3 = [1 , 2 , 3 , 4 , 5 ]; arr3.swap (0 , 4 ); println! ("交换后: {:?}" , arr3); let mut arr4 = [1 , 2 , 3 , 4 , 5 ]; arr4.rotate_left (2 ); println! ("左旋 2: {:?}" , arr4); }
数组与切片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 fn main () { let arr = [1 , 2 , 3 , 4 , 5 ]; let slice : &[i32 ] = &arr; let part : &[i32 ] = &arr[1 ..4 ]; println! ("部分切片: {:?}" , part); fn sum_slice (data: &[i32 ]) -> i32 { data.iter ().sum () } let arr3 = [1 , 2 , 3 ]; let arr5 = [1 , 2 , 3 , 4 , 5 ]; println! ("sum arr3: {}" , sum_slice (&arr3)); println! ("sum arr5: {}" , sum_slice (&arr5)); println! ("sum part: {}" , sum_slice (&arr5[2 ..])); }
1 2 3 4 5 6 7 8 9 ┌─────────────────────────────────────────────────────────┐ │ 数组 [T; N] vs 切片 &[T] │ ├─────────────────────────────────────────────────────────┤ │ 长度编译时固定 长度运行时确定 │ │ 存储在栈上 是引用(胖指针) │ │ 大小 = N * sizeof(T) 大小 = 2 * 指针 │ │ 类型包含长度 类型不包含长度 │ │ [i32; 3] ≠ [i32; 5] &[i32] 通用 │ └─────────────────────────────────────────────────────────┘
多维数组 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 fn main () { let matrix : [[i32 ; 4 ]; 3 ] = [ [1 , 2 , 3 , 4 ], [5 , 6 , 7 , 8 ], [9 , 10 , 11 , 12 ], ]; println! ("matrix[1][2] = {}" , matrix[1 ][2 ]); for row in &matrix { for col in row { print! ("{:3} " , col); } println! (); } let zeros : [[i32 ; 4 ]; 3 ] = [[0 ; 4 ]; 3 ]; println! ("零矩阵: {:?}" , zeros); let cube : [[[i32 ; 2 ]; 3 ]; 4 ] = [[[0 ; 2 ]; 3 ]; 4 ]; println! ("三维数组大小: {} bytes" , std::mem::size_of_val (&cube)); }
内存布局 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 fn main () { let arr = [1i32 , 2 , 3 , 4 , 5 ]; println! ("数组地址: {:p}" , &arr); println! ("arr[0] 地址: {:p}" , &arr[0 ]); println! ("arr[1] 地址: {:p}" , &arr[1 ]); println! ("arr[2] 地址: {:p}" , &arr[2 ]); println! ("i32 大小: {} bytes" , std::mem::size_of::<i32 >()); println! ("数组大小: {} bytes" , std::mem::size_of_val (&arr)); }
1 2 3 4 5 6 7 8 9 10 内存布局(栈上连续存储): arr: [1i32, 2, 3, 4, 5] 地址: 0x1000 0x1004 0x1008 0x100C 0x1010 ┌────────┬────────┬────────┬────────┬────────┐ │ 1 │ 2 │ 3 │ 4 │ 5 │ │ (i32) │ (i32) │ (i32) │ (i32) │ (i32) │ └────────┴────────┴────────┴────────┴────────┘ │◄──────────────── 20 bytes ───────────────►│
流程控制 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ┌─────────────────────────────────────────────────────────────────────────┐ │ Rust 流程控制 │ ├─────────────────────────────────────────────────────────────────────────┤ │ │ │ 条件判断 循环 模式匹配 │ │ ├── if/else ├── loop ├── match │ │ ├── if let ├── while ├── if let / while let │ │ ├── let else ├── while let ├── @ 绑定 │ │ └── matches! └── for └── 模式语法 │ │ │ │ 跳转控制 错误处理 表达式 │ │ ├── break ├── ? 运算符 └── 块表达式 │ │ ├── continue ├── panic! │ │ ├── return └── unwrap/expect │ │ └── 'label 标签 │ │ │ └─────────────────────────────────────────────────────────────────────────┘
条件判断 if/else 表达式 Rust 中 if 是表达式而非语句,可以返回值。条件必须是 bool 类型,不会自动转换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 fn main () { let number = 42 ; if number > 0 { println! ("正数" ); } else if number < 0 { println! ("负数" ); } else { println! ("零" ); } let description = if number % 2 == 0 { "偶数" } else { "奇数" }; println! ("description: {}" , description); let abs_value = if number >= 0 { number } else { -number }; println! ("abs_value: {}" , abs_value); let category = if number > 100 { "大" } else { if number > 10 { "中" } else { "小" } }; println! ("category: {}" , category); }
if let 表达式 当只关心一种匹配情况时,if let 比 match 更简洁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 fn main () { let some_value : Option <i32 > = Some (42 ); if let Some (x) = some_value { println! ("值为: {}" , x); } else { println! ("无值" ); } match some_value { Some (x) => println! ("值为: {}" , x), _ => println! ("无值" ), } let config : Result <i32 , &str > = Ok (100 ); if let Ok (value) = config { println! ("配置值: {}" , value); } else if let Err (e) = config { println! ("配置错误: {}" , e); } struct Point { x: i32 , y: i32 } let point = Some (Point { x: 10 , y: 20 }); if let Some (Point { x, y }) = point { println! ("坐标: ({}, {})" , x, y); } }
let else 表达式 Rust 1.65 引入,用于匹配失败时必须发散(提前退出)的场景。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 fn get_username (id: Option <u32 >) -> String { let Some (user_id) = id else { return String ::from ("anonymous" ); }; format! ("user_{}" , user_id) } fn find_first_even (numbers: &[i32 ]) -> Option <i32 > { for &n in numbers { let 0 = n % 2 else { continue ; }; return Some (n); } None } fn process_data (data: Option <Result <String , String >>) -> String { let Some (result) = data else { return String ::new (); }; let Ok (content) = result else { return String ::from ("error" ); }; content } fn main () { let username = get_username (Some (123 )); println! ("username: {}" , username); let even = find_first_even (&[1 , 2 , 3 , 4 , 5 ]); println! ("even: {:?}" , even); let data = process_data (Some (Ok (String ::from ("Hello, world!" )))); println! ("data: {}" , data); let data = process_data (Some (Err (String ::from ("Error" )))); println! ("data: {}" , data); let data = process_data (None ); println! ("data: {}" , data); }
matches! 宏 返回 bool 的模式匹配,适合在条件判断中使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 fn main () { let c = 'f' ; let is_lowercase = matches!(c, 'a' ..='z' ); println! ("is_lowercase: {}" , is_lowercase); let is_letter = matches!(c, 'a' ..='z' | 'A' ..='Z' ); println! ("is_letter: {}" , is_letter); let is_hex = matches!(c, '0' ..='9' | 'a' ..='f' | 'A' ..='F' ); println! ("is_hex: {}" , is_hex); let opt = Some (42 ); let is_positive = matches!(opt, Some (x) if x > 0 ); let is_large = matches!(opt, Some (x) if x > 100 ); println! ("is_positive: {}" , is_positive); println! ("is_large: {}" , is_large); enum Status { Active, Inactive, Pending (u32 ) } let status = Status::Pending (5 ); let is_pending = matches!(status, Status::Pending (_)); let is_urgent = matches!(status, Status::Pending (x) if x < 10 ); println! ("is_pending: {}" , is_pending); println! ("is_urgent: {}" , is_urgent); let numbers = vec! [Some (1 ), None , Some (3 ), None , Some (5 )]; let valid : Vec <_> = numbers.iter () .filter (|x| matches!(x, Some (_))) .collect (); println! ("valid: {:?}" , valid); }
循环控制 loop 无限循环 loop 创建无限循环,必须通过 break 退出,可以返回值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 let mut count = 0 ;loop { count += 1 ; if count == 10 { break ; } } let mut counter = 0 ;let result = loop { counter += 1 ; if counter == 10 { break counter * 2 ; } }; let mut attempts = 0 ;let connection = loop { attempts += 1 ; match try_connect () { Ok (conn) => break conn, Err (e) if attempts < 3 => { println! ("重试 {}/3..." , attempts); continue ; } Err (e) => panic! ("连接失败: {}" , e), } }; enum State { Start, Running, Finished }let mut state = State::Start;loop { state = match state { State::Start => { println! ("启动" ); State::Running } State::Running => { println! ("运行中" ); State::Finished } State::Finished => { println! ("完成" ); break ; } }; }
while 条件循环 条件为真时持续执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 let mut n = 0 ;while n < 5 { println! ("{}" , n); n += 1 ; } let mut input = String ::new ();while input.trim () != "quit" { input.clear (); std::io::stdin ().read_line (&mut input).unwrap (); println! ("你输入了: {}" , input.trim ()); } let mut stack = vec! [1 , 2 , 3 , 4 , 5 ];while !stack.is_empty () { let top = stack.pop ().unwrap (); println! ("弹出: {}" , top); }
while let 模式匹配循环 结合模式匹配的条件循环,常用于迭代器和 Option/Result。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 let mut optional = Some (0 );while let Some (i) = optional { if i > 5 { optional = None ; } else { println! ("{}" , i); optional = Some (i + 1 ); } } let mut stack = vec! [1 , 2 , 3 ];while let Some (top) = stack.pop () { println! ("处理: {}" , top); } use std::sync::mpsc;let (tx, rx) = mpsc::channel ();while let Ok (msg) = rx.recv () { println! ("收到: {}" , msg); } let mut pairs = vec! [(1 , 'a' ), (2 , 'b' ), (3 , 'c' )];while let Some ((num, ch)) = pairs.pop () { println! ("{}: {}" , num, ch); }
for 迭代循环 Rust 最常用的循环,遍历任何实现了 IntoIterator 的类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 for i in 0 ..5 { println! ("{}" , i); } for i in 0 ..=5 { println! ("{}" , i); } for i in (0 ..5 ).rev () { println! ("{}" , i); } let v = vec! [1 , 2 , 3 ];for item in &v { println! ("{}" , item); } for item in &mut v { *item += 1 ; } for item in v { println! ("{}" , item); } let colors = vec! ["红" , "绿" , "蓝" ];for (index, color) in colors.iter ().enumerate () { println! ("{}: {}" , index, color); } use std::collections::HashMap;let mut scores = HashMap::new ();scores.insert ("Alice" , 100 ); scores.insert ("Bob" , 85 ); for (name, score) in &scores { println! ("{}: {}" , name, score); } for i in (0 ..10 ).step_by (2 ) { println! ("{}" , i); } let names = vec! ["Alice" , "Bob" ];let ages = vec! [25 , 30 ];for (name, age) in names.iter ().zip (ages.iter ()) { println! ("{} is {} years old" , name, age); }
跳转控制 break 退出循环 退出当前循环,可携带返回值,可指定标签跳出多层循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 for i in 0 ..10 { if i == 5 { break ; } println! ("{}" , i); } let result = loop { let value = compute (); if value > 100 { break value; } }; 'outer : for i in 0 ..5 { for j in 0 ..5 { if i * j > 10 { println! ("在 ({}, {}) 处退出" , i, j); break 'outer ; } } } let result = 'search : loop { for row in 0 ..10 { for col in 0 ..10 { if matrix[row][col] == target { break 'search (row, col); } } } break 'search (-1 , -1 ); };
continue 跳过迭代 跳过当前迭代的剩余部分,进入下一次迭代。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 for i in 0 ..10 { if i % 2 == 0 { continue ; } println! ("{}" , i); } 'outer : for i in 0 ..5 { for j in 0 ..5 { if j == 2 { continue 'outer ; } println! ("({}, {})" , i, j); } } let items = vec! [Some (1 ), None , Some (2 ), None , Some (3 )];for item in items { let Some (value) = item else { continue ; }; println! ("处理: {}" , value); }
return 函数返回 从函数中提前返回,可携带返回值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 fn divide (a: f64 , b: f64 ) -> Option <f64 > { if b == 0.0 { return None ; } Some (a / b) } fn find_in_matrix (matrix: &[Vec <i32 >], target: i32 ) -> Option <(usize , usize )> { for (i, row) in matrix.iter ().enumerate () { for (j, &value) in row.iter ().enumerate () { if value == target { return Some ((i, j)); } } } None } fn square (x: i32 ) -> i32 { x * x } fn process (numbers: Vec <i32 >) -> Vec <i32 > { numbers.into_iter () .filter_map (|n| { if n < 0 { return None ; } Some (n * 2 ) }) .collect () }
标签块表达式 从任意代码块中返回值,不仅限于循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 let result = 'block : { if condition_a { break 'block "A" ; } if condition_b { break 'block "B" ; } "default" }; fn categorize (value: i32 ) -> &'static str { 'check : { if value < 0 { break 'check "negative" ; } if value == 0 { break 'check "zero" ; } if value < 10 { break 'check "small" ; } if value < 100 { break 'check "medium" ; } "large" } } let validated = 'validation : { let Some (name) = get_name () else { break 'validation false }; let Some (age) = get_age () else { break 'validation false }; if age < 18 { break 'validation false }; true };
模式匹配 match 表达式 Rust 最强大的控制流结构,必须穷尽所有可能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 let number = 13 ;match number { 1 => println! ("一" ), 2 => println! ("二" ), 3 => println! ("三" ), _ => println! ("其他" ), } match number { 1 | 2 | 3 => println! ("小数字" ), 4 ..=10 => println! ("中等数字" ), _ => println! ("大数字" ), } match number { n if n < 0 => println! ("负数: {}" , n), n if n == 0 => println! ("零" ), n if n % 2 == 0 => println! ("正偶数: {}" , n), n => println! ("正奇数: {}" , n), } enum Message { Quit, Move { x: i32 , y: i32 }, Write (String ), ChangeColor (u8 , u8 , u8 ), } let msg = Message::ChangeColor (255 , 128 , 0 );match msg { Message::Quit => println! ("退出" ), Message::Move { x, y } => println! ("移动到 ({}, {})" , x, y), Message::Write (text) => println! ("写入: {}" , text), Message::ChangeColor (r, g, b) => println! ("颜色: RGB({}, {}, {})" , r, g, b), } let description = match number { 0 => "零" , 1 ..=9 => "个位数" , 10 ..=99 => "两位数" , _ => "更大的数" , };
@ 绑定 在匹配的同时将值绑定到变量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 let num = 5 ;match num { n @ 1 ..=5 => println! ("1-5 范围内: {}" , n), n @ 6 ..=10 => println! ("6-10 范围内: {}" , n), n => println! ("范围外: {}" , n), } match num { n @ (1 | 3 | 5 | 7 | 9 ) => println! ("奇数: {}" , n), n @ (2 | 4 | 6 | 8 | 10 ) => println! ("偶数: {}" , n), n => println! ("其他: {}" , n), } enum Message { Hello { id: i32 }, } let msg = Message::Hello { id: 5 };match msg { Message::Hello { id: id_var @ 3 ..=7 } => { println! ("id 在 3-7 范围内: {}" , id_var); } Message::Hello { id: 10 ..=12 } => { println! ("id 在 10-12 范围内" ); } Message::Hello { id } => { println! ("其他 id: {}" , id); } } match Some (42 ) { Some (n @ 1 ..=100 ) if n % 2 == 0 => println! ("1-100 的偶数: {}" , n), Some (n) => println! ("其他: {}" , n), None => println! ("无值" ), }
模式语法详解 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 let point = (3 , 5 );match point { (0 , 0 ) => println! ("原点" ), (x, 0 ) => println! ("x轴上, x = {}" , x), (0 , y) => println! ("y轴上, y = {}" , y), (x, y) => println! ("点 ({}, {})" , x, y), } struct Point { x: i32 , y: i32 }let p = Point { x: 0 , y: 7 };match p { Point { x: 0 , y } => println! ("y轴上, y = {}" , y), Point { x, y: 0 } => println! ("x轴上, x = {}" , x), Point { x, y } => println! ("点 ({}, {})" , x, y), } struct Point3D { x: i32 , y: i32 , z: i32 }let p = Point3D { x: 1 , y: 2 , z: 3 };let Point3D { x, .. } = p; let arr = [1 , 2 , 3 , 4 , 5 ];match &arr[..] { [] => println! ("空" ), [single] => println! ("单元素: {}" , single), [first, second] => println! ("两个元素: {}, {}" , first, second), [first, .., last] => println! ("首: {}, 尾: {}" , first, last), } let numbers = [1 , 2 , 3 , 4 , 5 ];match numbers { [first, rest @ ..] => { println! ("首: {}, 剩余: {:?}" , first, rest); } } let mut pair = (String ::from ("hello" ), 42 );match pair { (ref s, ref mut n) => { println! ("字符串: {}" , s); *n += 1 ; } } enum Color { Rgb (u8 , u8 , u8 ), Hsv (u8 , u8 , u8 ), } enum Message { ChangeColor (Color), Quit, } let msg = Message::ChangeColor (Color::Rgb (255 , 128 , 0 ));match msg { Message::ChangeColor (Color::Rgb (r, g, b)) => { println! ("RGB: ({}, {}, {})" , r, g, b); } Message::ChangeColor (Color::Hsv (h, s, v)) => { println! ("HSV: ({}, {}, {})" , h, s, v); } Message::Quit => println! ("退出" ), }
错误处理 ? 运算符 简化错误传播,遇到 Err 或 None 时提前返回。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 use std::fs::File;use std::io::{self , Read};fn read_file (path: &str ) -> Result <String , io::Error> { let mut file = File::open (path)?; let mut content = String ::new (); file.read_to_string (&mut content)?; Ok (content) } fn read_file_compact (path: &str ) -> Result <String , io::Error> { let mut content = String ::new (); File::open (path)?.read_to_string (&mut content)?; Ok (content) } fn first_char (s: &str ) -> Option <char > { s.lines ().next ()?.chars ().next () } fn main () -> Result <(), Box <dyn std::error::Error>> { let content = read_file ("config.txt" )?; println! ("{}" , content); Ok (()) } fn process () -> Result <(), MyError> { let content = std::fs::read_to_string ("file.txt" )?; let data : Data = serde_json::from_str (&content)?; Ok (()) }
panic! 宏 不可恢复错误,终止程序(或在 panic=abort 模式下直接中止)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 fn divide (a: i32 , b: i32 ) -> i32 { if b == 0 { panic! ("除数不能为零!" ); } a / b } fn get_item (index: usize , items: &[&str ]) { if index >= items.len () { panic! ("索引 {} 越界,数组长度为 {}" , index, items.len ()); } } fn process_type (t: &str ) -> i32 { match t { "a" => 1 , "b" => 2 , "c" => 3 , _ => unreachable! ("未知类型: {}" , t), } } fn complex_algorithm () { todo!("待实现复杂算法" ); } fn placeholder () { unimplemented! ("此功能尚未实现" ); }
unwrap 和 expect 快速提取值的方法,失败时 panic。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 let value : Option <i32 > = Some (42 );let v = value.unwrap (); let none : Option <i32 > = None ;let config = std::fs::read_to_string ("config.txt" ) .expect ("无法读取配置文件" ); let num : i32 = "42" .parse ().expect ("硬编码的字符串应该能解析" );let value = some_option.unwrap_or (0 ); let value = some_option.unwrap_or_else (|| compute_default ()); let value = some_option.unwrap_or_default (); let ok_value = result.unwrap_or (default);let ok_value = result.unwrap_or_else (|e| handle_error (e));let err_value = result.unwrap_err ();
块表达式 Rust 中几乎所有代码块都是表达式,最后一行无分号即为返回值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 let result = { let a = 1 ; let b = 2 ; a + b }; let unit = { let a = 1 ; let b = 2 ; a + b; }; let message = { let mut temp = String ::new (); temp.push_str ("Hello, " ); temp.push_str ("World!" ); temp }; let connection = { let config = load_config (); let pool = create_pool (&config); let conn = pool.get_connection (); conn.configure (&config); conn }; let description = match status_code { 200 => "成功" , 404 => { log_not_found (); "未找到" } 500 ..=599 => { let msg = format! ("服务器错误: {}" , status_code); log_error (&msg); "服务器错误" } _ => "未知状态" , }; let ptr_value = unsafe { let ptr = some_raw_ptr; *ptr };
方法 Method 核心概念 方法 是定义在结构体、枚举或 trait 对象上下文中的函数,第一个参数始终是 self,代表调用该方法的实例。
1 2 3 4 5 6 ┌─────────────────────────────────────────────────────┐ │ 方法 vs 函数 │ ├─────────────────────────────────────────────────────┤ │ 函数 (fn) │ 独立存在,不依附于任何类型 │ │ 方法 (method) │ 定义在 impl 块中,绑定到特定类型 │ └─────────────────────────────────────────────────────┘
基本语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 struct Rectangle { width: u32 , height: u32 , } impl Rectangle { fn area (&self ) -> u32 { self .width * self .height } fn new (width: u32 , height: u32 ) -> Self { Rectangle { width, height } } } fn main () { let rect = Rectangle::new (30 , 50 ); println! ("面积: {}" , rect.area ()); }
self 的三种形式
形式
含义
所有权
使用场景
&self不可变借用
借用
只读访问(最常用)
&mut self可变借用
借用
需要修改实例
self获取所有权
转移
转换类型或消费实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 impl Rectangle { fn area (&self ) -> u32 { self .width * self .height } fn scale (&mut self , factor: u32 ) { self .width *= factor; self .height *= factor; } fn to_square (self ) -> Rectangle { let side = self .width.max (self .height); Rectangle { width: side, height: side } } }
自动引用和解引用 Rust 会自动添加 &、&mut 或 *,使方法调用更简洁:
1 2 3 4 5 let rect = Rectangle::new (10 , 20 );rect.area (); (&rect).area ();
多个 impl 块 一个类型可以有多个 impl 块(常用于 trait 实现分离):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 impl Rectangle { fn area (&self ) -> u32 { } } impl Rectangle { fn perimeter (&self ) -> u32 { } } impl std ::fmt::Display for Rectangle { fn fmt (&self , f: &mut std::fmt::Formatter) -> std::fmt::Result { write! (f, "{}x{}" , self .width, self .height) } }
枚举上的方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 enum Message { Quit, Move { x: i32 , y: i32 }, Write (String ), } impl Message { fn call (&self ) { match self { Message::Quit => println! ("退出" ), Message::Move { x, y } => println! ("移动到 ({}, {})" , x, y), Message::Write (s) => println! ("消息: {}" , s), } } }
方法链式调用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 impl Rectangle { fn set_width (mut self , width: u32 ) -> Self { self .width = width; self } fn set_height (mut self , height: u32 ) -> Self { self .height = height; self } } let rect = Rectangle::new (0 , 0 ) .set_width (100 ) .set_height (50 );
泛型 Generics 核心概念 泛型 是一种参数化类型的机制,让代码可以处理多种数据类型,而无需重复编写。
1 2 3 4 5 6 7 8 ┌─────────────────────────────────────────────────────────────┐ │ 泛型的价值 │ ├─────────────────────────────────────────────────────────────┤ │ ✗ 没有泛型:fn max_i32(a: i32, b: i32) -> i32 │ │ fn max_f64(a: f64, b: f64) -> f64 重复代码! │ ├─────────────────────────────────────────────────────────────┤ │ ✓ 使用泛型:fn max<T>(a: T, b: T) -> T 一份代码! │ └─────────────────────────────────────────────────────────────┘
函数泛型 1 2 3 4 5 6 7 8 9 10 fn largest <T: PartialOrd >(a: T, b: T) -> T { if a > b { a } else { b } } fn main () { println! ("{}" , largest (5 , 10 )); println! ("{}" , largest (3.14 , 2.71 )); println! ("{}" , largest ('a' , 'z' )); }
结构体泛型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 struct Point <T> { x: T, y: T, } struct Pair <T, U> { first: T, second: U, } fn main () { let int_point = Point { x: 5 , y: 10 }; let float_point = Point { x: 1.0 , y: 4.0 }; let mixed = Pair { first: 5 , second: "hello" }; }
枚举泛型 标准库中最经典的两个泛型枚举:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 enum Option <T> { Some (T), None , } enum Result <T, E> { Ok (T), Err (E), } fn main () { let number : Option <i32 > = Some (42 ); let text : Option <&str > = None ; let success : Result <i32 , String > = Ok (200 ); let failure : Result <i32 , String > = Err ("错误" .to_string ()); }
方法泛型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 struct Point <T> { x: T, y: T, } impl <T> Point<T> { fn new (x: T, y: T) -> Self { Point { x, y } } fn x (&self ) -> &T { &self .x } } impl Point <f64 > { fn distance_from_origin (&self ) -> f64 { (self .x.powi (2 ) + self .y.powi (2 )).sqrt () } } impl <T> Point<T> { fn mixup <U>(self , other: Point<U>) -> Point<T, U> { Point { x: self .x, y: other.y, } } }
Trait Bounds(特征约束) 基本语法 1 2 3 4 5 6 7 8 9 10 11 12 13 fn print_info <T: std::fmt::Display>(item: T) { println! ("{}" , item); } fn complex_function <T, U>(t: T, u: U) -> i32 where T: Display + Clone , U: Debug + PartialOrd , { }
常见约束模式 1 2 3 4 5 6 7 8 9 ┌──────────────────┬────────────────────────────────────────┐ │ 约束形式 │ 含义 │ ├──────────────────┼────────────────────────────────────────┤ │ T: Clone │ T 必须实现 Clone │ │ T: Clone + Debug │ T 必须同时实现 Clone 和 Debug │ │ T: 'static │ T 不包含非静态引用 │ │ T: ?Sized │ T 可以是动态大小类型 │ │ T: Default │ T 可以有默认值 │ └──────────────────┴────────────────────────────────────────┘
实际示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 use std::fmt::{Display, Debug };fn largest <T: PartialOrd + Copy >(list: &[T]) -> T { let mut largest = list[0 ]; for &item in list { if item > largest { largest = item; } } largest } fn notify <T>(item: &T) where T: Display + Clone { println! ("通知: {}" , item); }
impl Trait 语法糖 1 2 3 4 5 6 7 8 9 fn print (item: impl Display ) { println! ("{}" , item); } fn counter () -> impl Iterator <Item = i32 > { (0 ..10 ).filter (|x| x % 2 == 0 ) }
const 泛型(常量泛型) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct Array <T, const N: usize > { data: [T; N], } impl <T, const N: usize > Array<T, N> { fn len (&self ) -> usize { N } } fn main () { let arr : Array<i32 , 5 > = Array { data: [1 , 2 , 3 , 4 , 5 ] }; println! ("长度: {}" , arr.len ()); }
默认类型参数 1 2 3 4 5 6 7 8 9 10 11 12 13 trait Add <Rhs = Self > { type Output ; fn add (self , rhs: Rhs) -> Self ::Output; } impl Add for Point { type Output = Point; fn add (self , other: Point) -> Point { } }
单态化(零成本抽象) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ┌─────────────────────────────────────────────────────────────┐ │ 编译时单态化 │ ├─────────────────────────────────────────────────────────────┤ │ 源代码: │ │ fn id<T>(x: T) -> T { x } │ │ id(5); // 调用1 │ │ id(3.14); // 调用2 │ ├─────────────────────────────────────────────────────────────┤ │ 编译后生成: │ │ fn id_i32(x: i32) -> i32 { x } │ │ fn id_f64(x: f64) -> f64 { x } │ ├─────────────────────────────────────────────────────────────┤ │ ✓ 运行时零开销 │ │ ✗ 可能增加二进制体积 │ └─────────────────────────────────────────────────────────────┘
常见使用模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 impl <T> Vec <T> { pub fn new () -> Vec <T> { } } fn convert <T: Into <String >>(value: T) -> String { value.into () } impl <T: Display> ToString for T { } trait Iterator { type Item ; fn next (&mut self ) -> Option <Self ::Item>; } trait Container <T> { fn contains (&self , item: &T) -> bool ; }
特征 Trait 核心概念 Trait 定义了类型应该具备的行为 (方法集合),类似于其他语言的接口(Interface),但更强大。
1 2 3 4 5 6 7 8 ┌─────────────────────────────────────────────────────────────┐ │ Trait 的本质 │ ├─────────────────────────────────────────────────────────────┤ │ • 定义共享行为的抽象 │ │ • 实现多态(编译时/运行时) │ │ • 约束泛型参数 │ │ • 扩展现有类型的能力 │ └─────────────────────────────────────────────────────────────┘
基本语法 定义 Trait 1 2 3 4 trait Summary { fn summarize (&self ) -> String ; }
实现 Trait 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 struct Article { title: String , author: String , content: String , } struct Tweet { username: String , content: String , } impl Summary for Article { fn summarize (&self ) -> String { format! ("{} by {}" , self .title, self .author) } } impl Summary for Tweet { fn summarize (&self ) -> String { format! ("@{}: {}" , self .username, self .content) } } fn main () { let article = Article { title: String ::from ("Rust入门" ), author: String ::from ("张三" ), content: String ::from ("..." ), }; println! ("{}" , article.summarize ()); }
默认实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 trait Summary { fn summarize (&self ) -> String { String ::from ("(阅读更多...)" ) } fn summarize_author (&self ) -> String ; fn full_summary (&self ) -> String { format! ("作者: {} - {}" , self .summarize_author (), self .summarize ()) } } impl Summary for Article { fn summarize_author (&self ) -> String { self .author.clone () } } impl Summary for Tweet { fn summarize (&self ) -> String { format! ("@{}: {}" , self .username, self .content) } fn summarize_author (&self ) -> String { format! ("@{}" , self .username) } }
Trait 作为参数 三种等价写法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 fn notify (item: &impl Summary ) { println! ("速报: {}" , item.summarize ()); } fn notify <T: Summary>(item: &T) { println! ("速报: {}" , item.summarize ()); } fn notify <T>(item: &T) where T: Summary { println! ("速报: {}" , item.summarize ()); }
多重约束 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 use std::fmt::{Display, Debug };fn print_info (item: &(impl Summary + Display)) { println! ("{}" , item.summarize ()); println! ("{}" , item); } fn print_info <T: Summary + Display>(item: &T) { }fn complex <T, U>(t: &T, u: &U) -> String where T: Summary + Clone , U: Display + Debug , { format! ("{} - {:?}" , t.summarize (), u) }
Trait 作为返回值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 fn create_summary () -> impl Summary { Tweet { username: String ::from ("test" ), content: String ::from ("hello" ), } } fn create_summary (switch: bool ) -> impl Summary { if switch { Article { } } else { Tweet { } } }
常用标准库 Trait 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ┌─────────────────┬────────────────────────────────────────────┐ │ Trait │ 用途 │ ├─────────────────┼────────────────────────────────────────────┤ │ Clone │ 显式深拷贝 (.clone()) │ │ Copy │ 隐式按位复制(栈上简单类型) │ │ Debug │ 调试格式化 ({:?}) │ │ Display │ 用户友好格式化 ({}) │ │ Default │ 默认值 │ │ PartialEq / Eq │ 相等比较 (== !=) │ │ PartialOrd / Ord│ 排序比较 (< > <= >=) │ │ Hash │ 哈希计算 │ │ Drop │ 析构函数 │ │ From / Into │ 类型转换 │ │ AsRef / AsMut │ 引用转换 │ │ Deref / DerefMut│ 解引用运算符重载 │ │ Iterator │ 迭代器 │ │ Fn/FnMut/FnOnce │ 闭包 │ │ Send / Sync │ 线程安全标记 │ └─────────────────┴────────────────────────────────────────────┘
派生宏 (derive) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #[derive(Debug, Clone, PartialEq, Eq, Hash, Default)] struct Point { x: i32 , y: i32 , } fn main () { let p1 = Point { x: 1 , y: 2 }; let p2 = p1.clone (); println! ("{:?}" , p1); println! ("{}" , p1 == p2); let p3 = Point::default (); }
可派生的 Trait 1 2 3 4 5 6 7 8 9 10 11 12 #[derive( Debug, // 调试输出 Clone, // 克隆 Copy, // 复制(需要 Clone) PartialEq, // 部分相等 Eq, // 完全相等(需要 PartialEq) PartialOrd, // 部分排序 Ord, // 完全排序(需要 PartialOrd + Eq) Hash, // 哈希(需要 Eq) Default, // 默认值 )] struct Data { }
关联类型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 trait Iterator { type Item ; fn next (&mut self ) -> Option <Self ::Item>; } struct Counter { count: u32 , } impl Iterator for Counter { type Item = u32 ; fn next (&mut self ) -> Option <Self ::Item> { self .count += 1 ; if self .count <= 5 { Some (self .count) } else { None } } }
关联类型 vs 泛型参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 trait Iterator { type Item ; fn next (&mut self ) -> Option <Self ::Item>; } trait From <T> { fn from (value: T) -> Self ; } impl From <&str > for String { }impl From <char > for String { }impl From <Vec <u8 >> for String { }
孤儿规则 (Orphan Rule) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 impl Display for MyStruct { }impl MyTrait for Vec <i32 > { }impl Display for Vec <i32 > { } struct Wrapper (Vec <String >);impl Display for Wrapper { fn fmt (&self , f: &mut std::fmt::Formatter) -> std::fmt::Result { write! (f, "[{}]" , self .0 .join (", " )) } }
Supertraits(特征继承) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 use std::fmt::Display;trait OutlinePrint : Display { fn outline_print (&self ) { let output = self .to_string (); let len = output.len (); println! ("{}" , "*" .repeat (len + 4 )); println! ("* {} *" , output); println! ("{}" , "*" .repeat (len + 4 )); } } #[derive(Debug)] struct Point { x: i32 , y: i32 }impl Display for Point { fn fmt (&self , f: &mut std::fmt::Formatter) -> std::fmt::Result { write! (f, "({}, {})" , self .x, self .y) } } impl OutlinePrint for Point {}
完全限定语法 完全限定语法 用于明确指定调用哪个类型或 trait 的方法/函数,解决名称冲突问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 trait Pilot { fn fly (&self ); } trait Wizard { fn fly (&self ); } struct Human ;impl Pilot for Human { fn fly (&self ) { println! ("飞机起飞" ); } } impl Wizard for Human { fn fly (&self ) { println! ("魔法飞行" ); } } impl Human { fn fly (&self ) { println! ("挥动双臂" ); } } fn main () { let person = Human; person.fly (); Pilot::fly (&person); Wizard::fly (&person); <Human as Pilot>::fly (&person); }
关联常量 1 2 3 4 5 6 7 8 9 10 11 12 13 trait Greet { const GREETING: &'static str = "Hello" ; fn greet (&self ) { println! ("{}" , Self ::GREETING); } } struct Japanese ;impl Greet for Japanese { const GREETING: &'static str = "こんにちは" ; }
条件实现 (Blanket Implementation) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 use std::fmt::Display;impl <T: Display> ToString for T { fn to_string (&self ) -> String { format! ("{}" , self ) } } struct Pair <T> { x: T, y: T, } impl <T> Pair<T> { fn new (x: T, y: T) -> Self { Pair { x, y } } } impl <T: Display + PartialOrd > Pair<T> { fn cmp_display (&self ) { if self .x >= self .y { println! ("最大: {}" , self .x); } else { println! ("最大: {}" , self .y); } } }
集合类型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ┌─────────────────┬──────────────┬───────────┬─────────────────────────┐ │ 类型 │ 底层结构 │ 有序 │ 主要用途 │ ├─────────────────┼──────────────┼───────────┼─────────────────────────┤ │ Vec<T> │ 动态数组 │ 插入序 │ 通用序列 │ │ VecDeque<T> │ 环形缓冲 │ 插入序 │ 双端队列 │ │ LinkedList<T> │ 双向链表 │ 插入序 │ 频繁分割合并 │ ├─────────────────┼──────────────┼───────────┼─────────────────────────┤ │ HashMap<K,V> │ 哈希表 │ ✗ │ 快速键值查找 │ │ BTreeMap<K,V> │ B-Tree │ 键有序 │ 有序映射/范围查询 │ ├─────────────────┼──────────────┼───────────┼─────────────────────────┤ │ HashSet<T> │ 哈希表 │ ✗ │ 快速去重/集合运算 │ │ BTreeSet<T> │ B-Tree │ 有序 │ 有序集合/范围查询 │ ├─────────────────┼──────────────┼───────────┼─────────────────────────┤ │ BinaryHeap<T> │ 二叉堆 │ 堆序 │ 优先队列/Top K │ └─────────────────┴──────────────┴───────────┴─────────────────────────┘
序列 Vec<T> 动态数组 ,连续内存存储,最常用的集合类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 fn main () { let mut v1 : Vec <i32 > = Vec ::new (); let mut v2 = vec! [1 , 2 , 3 ]; let v3 = vec! [0 ; 5 ]; let v4 : Vec <i32 > = Vec ::with_capacity (10 ); v2.push (4 ); v2.pop (); v2.insert (0 , 0 ); v2.remove (0 ); let third = &v2[2 ]; let third = v2.get (2 ); for item in &v2 { } for item in &mut v2 { *item += 1 ; } }
操作
时间复杂度
push / pop
O(1) 均摊
insert / remove
O(n)
索引访问
O(1)
VecDeque<T> 双端队列 ,基于环形缓冲区,两端操作高效。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 use std::collections::VecDeque;let mut deque : VecDeque<i32 > = VecDeque::new ();let mut deque = VecDeque::from ([1 , 2 , 3 ]);deque.push_front (0 ); deque.push_back (4 ); deque.pop_front (); deque.pop_back (); let first = deque.front (); let last = deque.back (); let item = deque.get (1 );
操作
时间复杂度
push_front / push_back
O(1) 均摊
pop_front / pop_back
O(1)
索引访问
O(1)
适用场景 :队列、滑动窗口、需要两端频繁操作
LinkedList<T> 双向链表 ,非连续存储,任意位置插入删除高效。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 use std::collections::LinkedList;let mut list : LinkedList<i32 > = LinkedList::new ();let mut list = LinkedList::from ([1 , 2 , 3 ]);list.push_front (0 ); list.push_back (4 ); list.pop_front (); list.pop_back (); let mut other = LinkedList::from ([5 , 6 ]);list.append (&mut other);
操作
时间复杂度
push / pop(两端)
O(1)
append(合并)
O(1)
索引访问
O(n) ⚠️
对比总结 1 2 3 4 5 6 7 8 9 10 ┌──────────────┬────────────┬────────────┬──────────────┐ │ 操作 │ Vec<T> │ VecDeque<T>│ LinkedList<T>│ ├──────────────┼────────────┼────────────┼──────────────┤ │ 头部插入/删除│ O(n) │ O(1) │ O(1) │ │ 尾部插入/删除│ O(1) │ O(1) │ O(1) │ │ 中间插入/删除│ O(n) │ O(n) │ O(1)* │ │ 随机访问 │ O(1) │ O(1) │ O(n) │ │ 内存布局 │ 连续 │ 连续 │ 分散 │ │ 缓存友好 │ ✓✓ │ ✓ │ ✗ │ └──────────────┴────────────┴────────────┴──────────────┘
映射 HashMap<K, V> 哈希映射 ,基于哈希表实现,无序存储,查找极快。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 use std::collections::HashMap;let mut map : HashMap<String , i32 > = HashMap::new ();let mut map = HashMap::from ([("a" , 1 ), ("b" , 2 )]);let map : HashMap<_, _> = vec! [("a" , 1 ), ("b" , 2 )].into_iter ().collect ();map.insert ("c" , 3 ); map.entry ("d" ).or_insert (4 ); map.entry ("c" ).or_insert_with (|| expensive_calc ()); map.entry ("c" ).and_modify (|v| *v += 10 ); let val = map.get ("a" ); let val = map.get_mut ("a" ); let val = map["a" ]; let has = map.contains_key ("a" ); map.remove ("a" ); map.remove_entry ("b" ); for (key, val) in &map { }for key in map.keys () { }for val in map.values_mut () { *val += 1 ; }
操作
平均复杂度
最差复杂度
插入 / 删除
O(1)
O(n)
查找
O(1)
O(n)
遍历
O(n)
O(n)
键的要求 :必须实现 Eq + Hash
惰性计算
or_insert(value)
────────────────────────────────────────
先计算 value ← 总是执行!
检查 key 是否存在
不存在 → 插入 value
存在 → 丢弃 value(浪费了计算)
or_insert_with(|| closure)
────────────────────────────────────────
检查 key 是否存在
不存在 → 执行闭包 → 插入结果
存在 → 什么都不做 ← 节省计算!
BTreeMap<K, V> B树映射 ,基于 B-Tree 实现,有序存储 ,范围查询高效。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 use std::collections::BTreeMap;let mut map : BTreeMap<String , i32 > = BTreeMap::new ();let mut map = BTreeMap::from ([("a" , 1 ), ("c" , 3 ), ("b" , 2 )]);map.insert ("d" , 4 ); map.get ("a" ); map.remove ("a" ); map.entry ("e" ).or_insert (5 ); let first = map.first_key_value (); let last = map.last_key_value (); map.pop_first (); map.pop_last (); for (k, v) in map.range ("b" .."d" ) { println! ("{}: {}" , k, v); } for (k, v) in map.range ("b" ..="d" ) { println! ("{}: {}" , k, v); } for (key, val) in &map { }
操作
时间复杂度
插入 / 删除
O(log n)
查找
O(log n)
范围查询
O(log n + k)*
最小/最大
O(log n)
*k 为范围内元素数量
键的要求 :必须实现 Ord
对比总结 1 2 3 4 5 6 7 8 9 10 11 12 13 ┌──────────────────┬─────────────────┬─────────────────┐ │ 特性 │ HashMap<K,V> │ BTreeMap<K,V> │ ├──────────────────┼─────────────────┼─────────────────┤ │ 底层结构 │ 哈希表 │ B-Tree │ │ 元素顺序 │ 无序 │ 按键有序 │ │ 查找复杂度 │ O(1) │ O(log n) │ │ 插入复杂度 │ O(1) │ O(log n) │ │ 范围查询 │ ✗ │ ✓ │ │ 最小/最大键 │ O(n) │ O(log n) │ │ 键的约束 │ Eq + Hash │ Ord │ │ 内存占用 │ 较大 │ 较小 │ │ 缓存友好 │ ✓ │ ✓ │ └──────────────────┴─────────────────┴─────────────────┘
选择建议 :
场景
推荐
快速查找,顺序无关
HashMap
需要有序遍历
BTreeMap
范围查询(如区间统计)
BTreeMap
频繁取最大/最小
BTreeMap
键不支持 Hash
BTreeMap
默认选择
HashMap
集合 HashSet<T> 哈希集合 ,基于 HashMap 实现,无序存储,元素唯一,查找极快。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 use std::collections::HashSet;let mut set : HashSet<i32 > = HashSet::new ();let mut set = HashSet::from ([1 , 2 , 3 ]);let set : HashSet<_> = vec! [1 , 2 , 2 , 3 ].into_iter ().collect (); set.insert (4 ); set.remove (&2 ); set.take (&3 ); set.contains (&1 ); set.get (&1 ); set.len (); set.is_empty (); for item in &set { }
集合运算 (HashSet 独有优势):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 let a : HashSet<_> = [1 , 2 , 3 , 4 ].into ();let b : HashSet<_> = [3 , 4 , 5 , 6 ].into ();let intersection : HashSet<_> = a.intersection (&b).collect (); let intersection : HashSet<_> = &a & &b; let union : HashSet<_> = a.union (&b).collect (); let union : HashSet<_> = &a | &b;let difference : HashSet<_> = a.difference (&b).collect (); let difference : HashSet<_> = &a - &b;let sym_diff : HashSet<_> = a.symmetric_difference (&b).collect (); let sym_diff : HashSet<_> = &a ^ &b;a.is_subset (&b); a.is_superset (&b); a.is_disjoint (&b);
操作
平均复杂度
插入 / 删除
O(1)
查找
O(1)
集合运算
O(n)
元素要求 :必须实现 Eq + Hash
BTreeSet<T> B树集合 ,基于 BTreeMap 实现,有序存储 ,元素唯一。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 use std::collections::BTreeSet;fn main () { let mut set = BTreeSet::from ([3 , 1 , 4 , 1 , 5 ]); println! ("set: {:?}" , set); set.insert (2 ); println! ("set: {:?}" , set); set.remove (&3 ); println! ("set: {:?}" , set); if set.contains (&1 ) { println! ("set contains 1" ); } else { println! ("set does not contain 1" ); } let first = set.first (); let last = set.last (); println! ("first: {:?}, last: {:?}" , first, last); set.pop_first (); set.pop_last (); println! ("set: {:?}" , set); for x in set.range (2 ..5 ) { println! ("{}" , x); } for num in 0 ..=5 { set.insert (num); } println! ("set: {:?}" , set); let high = set.split_off (&3 ); println! ("high: {:?}" , high); let low = set; println! ("low: {:?}" , low); let a = BTreeSet::from ([1 , 2 , 3 ]); let b = BTreeSet::from ([2 , 3 , 4 ]); let union : BTreeSet<_> = a.union (&b).cloned ().collect (); println! ("union: {:?}" , union); }
操作
时间复杂度
插入 / 删除
O(log n)
查找
O(log n)
最小 / 最大
O(log n)
范围查询
O(log n + k)
元素要求 :必须实现 Ord
集合对比 1 2 3 4 5 6 7 8 9 10 11 ┌──────────────────┬─────────────────┬─────────────────┐ │ 特性 │ HashSet<T> │ BTreeSet<T> │ ├──────────────────┼─────────────────┼─────────────────┤ │ 底层结构 │ 哈希表 │ B-Tree │ │ 元素顺序 │ 无序 │ 有序 │ │ 查找复杂度 │ O(1) │ O(log n) │ │ 插入复杂度 │ O(1) │ O(log n) │ │ 范围查询 │ ✗ │ ✓ │ │ 最小/最大 │ O(n) │ O(log n) │ │ 元素约束 │ Eq + Hash │ Ord │ └──────────────────┴─────────────────┴─────────────────┘
其他 BinaryHeap<T> 二叉堆 ,基于数组的完全二叉树,实现优先队列 ,默认最大堆 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 use std::collections::BinaryHeap;let mut heap : BinaryHeap<i32 > = BinaryHeap::new ();let mut heap = BinaryHeap::from ([3 , 1 , 4 , 1 , 5 ]);heap.push (9 ); heap.pop (); heap.peek (); heap.peek_mut (); heap.len (); heap.is_empty (); heap.capacity (); heap.reserve (10 ); let vec = heap.into_vec (); let sorted = heap.into_sorted_vec (); for item in &heap { }while let Some (max) = heap.pop () { println! ("{}" , max); }
最小堆实现 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 use std::collections::BinaryHeap;use std::cmp::Reverse;let mut min_heap = BinaryHeap::new ();min_heap.push (Reverse (3 )); min_heap.push (Reverse (1 )); min_heap.push (Reverse (4 )); if let Some (Reverse (min)) = min_heap.pop () { println! ("最小值: {}" , min); } #[derive(Eq, PartialEq)] struct MinInt (i32 );impl Ord for MinInt { fn cmp (&self , other: &Self ) -> std::cmp::Ordering { other.0 .cmp (&self .0 ) } } impl PartialOrd for MinInt { fn partial_cmp (&self , other: &Self ) -> Option <std::cmp::Ordering> { Some (self .cmp (other)) } }
经典应用 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 fn top_k (nums: Vec <i32 >, k: usize ) -> Vec <i32 > { let mut heap = BinaryHeap::from (nums); (0 ..k).filter_map (|_| heap.pop ()).collect () } fn merge_k_sorted (arrays: Vec <Vec <i32 >>) -> Vec <i32 > { let mut heap = BinaryHeap::new (); let mut result = Vec ::new (); for (i, arr) in arrays.iter ().enumerate () { if !arr.is_empty () { heap.push (Reverse ((arr[0 ], i, 0 ))); } } while let Some (Reverse ((val, arr_idx, elem_idx))) = heap.pop () { result.push (val); if elem_idx + 1 < arrays[arr_idx].len () { heap.push (Reverse ((arrays[arr_idx][elem_idx + 1 ], arr_idx, elem_idx + 1 ))); } } result } #[derive(Eq, PartialEq)] struct Task { priority: u32 , name: String , } impl Ord for Task { fn cmp (&self , other: &Self ) -> std::cmp::Ordering { self .priority.cmp (&other.priority) } } impl PartialOrd for Task { fn partial_cmp (&self , other: &Self ) -> Option <std::cmp::Ordering> { Some (self .cmp (other)) } } let mut tasks = BinaryHeap::new ();tasks.push (Task { priority: 1 , name: "低优先级" .into () }); tasks.push (Task { priority: 10 , name: "高优先级" .into () });
操作
时间复杂度
push
O(log n)
pop
O(log n)
peek
O(1)
heapify (from)
O(n)
元素要求 :必须实现 Ord
生命周期 一句话定义
生命周期 = 引用保持有效的作用域范围
编译器用它确保:引用永远不会比它指向的数据活得更久
为什么需要生命周期? 1 2 3 4 5 6 7 8 fn main () { let r ; { let x = 5 ; r = &x; } println! ("{}" , r); }
编译器通过生命周期分析,在编译期阻止悬垂引用 。
生命周期注解语法 1 2 3 &i32 &'a i32 &'a mut i32
注解不改变 生命周期长短,只是告诉编译器 多个引用之间的关系
函数中的生命周期 问题场景 1 2 3 4 fn longest (x: &str , y: &str ) -> &str { if x.len () > y.len () { x } else { y } }
解决方案 1 2 3 4 fn longest <'a >(x: &'a str , y: &'a str ) -> &'a str { if x.len () > y.len () { x } else { y } }
理解 'a 的含义 1 2 3 4 5 fn longest <'a >(x: &'a str , y: &'a str ) -> &'a str
1 2 3 x: |=================| y: |==========| 'a:|==========| ← 取交集
结构体中的生命周期 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 struct Excerpt <'a > { part: &'a str , } fn main () { let novel = String ::from ("Call.me.Ishmael" ); let first = novel.split ('.' ).next ().unwrap (); println! ("{:?}" , first); let excerpt = Excerpt { part: first }; println! ("{:?}" , excerpt.part); }
生命周期省略规则 编译器自动推断的三条规则:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 fn foo (x: &str , y: &str )fn foo <'a , 'b >(x: &'a str , y: &'b str )fn foo (x: &str ) -> &str fn foo <'a >(x: &'a str ) -> &'a str impl Foo { fn bar (&self , x: &str ) -> &str fn bar <'a , 'b >(&'a self , x: &'b str ) -> &'a str }
何时必须手动标注? 1 2 3 4 5 6 fn first_word (s: &str ) -> &str { ... }fn longest (x: &str , y: &str ) -> &str { ... } fn longest <'a >(x: &'a str , y: &'a str ) -> &'a str { ... }
静态生命周期 'static 1 2 3 4 5 6 7 8 let s : &'static str = "hello" ; const NAME: &'static str = "Rust" ;static VERSION: &'static str = "1.0" ;
常见模式速查 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 fn pick <'a >(x: &'a str , y: &'a str , flag: bool ) -> &'a str { if flag { x } else { y } } fn first <'a >(x: &'a str , _y: &str ) -> &'a str { x } fn create (x: &str ) -> String { x.to_uppercase () } struct Parser <'a > { input: &'a str , } impl <'a > Parser<'a > { fn new (input: &'a str ) -> Self { Parser { input } } fn parse (&self ) -> &'a str { &self .input[0 ..5 ] } }
生命周期子类型 1 2 3 4 5 6 7 fn foo <'a , 'b >(x: &'a str , y: &'b str ) -> &'b str where 'a : 'b , { if x.len () > 0 { y } else { y } }
常见错误与修复 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 fn bad () -> &str { let s = String ::from ("hello" ); &s } fn good () -> String { String ::from ("hello" ) } fn bad_struct () -> Excerpt { let s = String ::from ("hello" ); Excerpt { part: &s } } fn good_struct (s: &str ) -> Excerpt { Excerpt { part: s } }
心智模型 1 2 3 4 5 6 7 8 ┌─────────────────────────────────────────────┐ │ 生命周期 = 编译器的"借用有效期检查器" │ ├─────────────────────────────────────────────┤ │ 1. 所有引用都有生命周期(大多自动推断) │ │ 2. 注解只是描述关系,不改变实际生命周期 │ │ 3. 目的:编译期消除悬垂引用 │ │ 4. 遇到报错 → 思考"谁应该活得更久?" │ └─────────────────────────────────────────────┘
场景
是否需要标注
函数单个引用输入输出
❌ 自动推断
函数多个引用输入 + 引用输出
✅ 需要
结构体持有引用
✅ 需要
返回 owned 数据
❌ 无需
&'static全局/字面量
包和模块 层级关系 1 2 3 4 5 6 7 Package(包) ├── Cargo.toml(包的配置) └── Crate(编译单元) ├── src/main.rs(二进制 crate 根) ├── src/lib.rs(库 crate 根) └── Module(模块,代码组织单元) └── 函数、结构体、枚举...
Package(包)
1 2 3 4 5 6 7 8 my_project/ ├── Cargo.toml ├── src/ │ ├── main.rs │ └── lib.rs └── src/bin/ ├── tool1.rs └── tool2.rs
规则 :一个包最多 1 个库 crate,可以有多个二进制 crate
Module(模块) 定义方式 1 2 3 4 5 6 7 8 9 10 11 mod math { pub fn add (a: i32 , b: i32 ) -> i32 { a + b } pub mod advanced { pub fn pow (base: i32 , exp: u32 ) -> i32 { base.pow (exp) } } } mod utils;
模块树 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 mod front { pub mod hosting { pub fn seat () {} } mod serving { fn serve () {} } }
路径与可见性 路径类型 1 2 3 4 5 6 7 8 9 10 11 crate::front::hosting::seat (); front::hosting::seat (); self::some_function (); super::parent_function ();
可见性规则 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 mod outer { pub mod inner { pub fn public_fn () {} fn private_fn () {} pub struct Point { pub x: i32 , y: i32 , } pub enum Status { Active, Inactive, } } fn outer_fn () { inner::public_fn (); inner::private_fn (); } }
高级可见性 1 2 3 pub (crate ) fn crate_only () {} pub (super ) fn parent_only () {} pub (in crate::path) fn limited () {}
use 关键字 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 use std::collections::HashMap;use std::collections::{HashMap, HashSet};use std::io::{self , Read, Write}; use std::collections::*;use std::io::Result as IoResult;pub use crate::utils::helper;
惯用法 1 2 3 4 5 6 7 use std::io;io::stdin (); use std::collections::HashMap;let map = HashMap::new ();
常见模式 预导入模式 1 2 3 4 5 6 7 8 pub mod prelude { pub use crate::types::{Error, Result }; pub use crate::traits::{Read, Write}; } use my_crate::prelude::*;
重导出简化路径 1 2 3 4 5 6 7 8 9 10 11 12 mod deep { pub mod nested { pub struct Important ; } } pub use deep::nested::Important;use my_crate::Important;
测试模块 1 2 3 4 5 6 7 8 9 10 11 pub fn add (a: i32 , b: i32 ) -> i32 { a + b }#[cfg(test)] mod tests { use super::*; #[test] fn test_add () { assert_eq! (add (2 , 3 ), 5 ); } }
速查表
关键字
作用
mod x定义/加载模块 x
pub公开可见
use引入路径
pub use重导出
crate::绝对路径
self::当前模块
super::父模块
心智模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ┌──────────────────────────────────────────────────┐ │ Package │ │ ┌─────────────────────────────────────────────┐ │ │ │ Crate (lib.rs / main.rs) │ │ │ │ ┌─────────────────────────────────────────┐│ │ │ │ │ crate (根模块) ││ │ │ │ │ ├── mod A (pub) ││ │ │ │ │ │ ├── fn x (pub) ← crate::A::x ││ │ │ │ │ │ └── fn y ← 私有 ││ │ │ │ │ └── mod B ││ │ │ │ │ └── mod C (pub) ││ │ │ │ │ └── fn z ← crate::B::C::z ││ │ │ │ └─────────────────────────────────────────┘│ │ │ └─────────────────────────────────────────────┘ │ └──────────────────────────────────────────────────┘ 访问规则: 1. 默认私有,需要 pub 公开 2. 父可访问子的公开项 3. 子可访问父(及祖先)的所有项
格式化输出 核心宏家族
宏
用途
输出位置
print!输出不换行
stdout
println!输出并换行
stdout
eprint!错误输出不换行
stderr
eprintln!错误输出并换行
stderr
format!返回 String
不输出
write!写入 buffer
指定位置
基础占位符 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 let name = "Rust" ;let version = 1.75 ;println! ("Hello, {}!" , name); println! ("{:?}" , vec! [1 , 2 , 3 ]); println! ("{:#?}" , vec! [1 , 2 , 3 ]);
参数引用方式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 println! ("{} + {} = {}" , 1 , 2 , 3 ); println! ("{0} vs {0}, {1} wins" , "A" , "B" ); println! ("{name} is {age} years old" , name = "Alice" , age = 30 ); let name = "Bob" ;let age = 25 ;println! ("{name} is {age} years old" );
数值格式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 let num = 255 ;println! ("十进制: {}" , num); println! ("二进制: {:b}" , num); println! ("八进制: {:o}" , num); println! ("十六进制: {:x}" , num); println! ("十六进制: {:X}" , num); println! ("{:#b}" , num); println! ("{:#o}" , num); println! ("{:#x}" , num); let x = 42 ;println! ("{:p}" , &x); let f = 1234.567 ;println! ("{:e}" , f); println! ("{:E}" , f);
宽度与对齐 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 let s = "Hi" ;let n = 42 ;println! ("[{:10}]" , s); println! ("[{:10}]" , n); println! ("[{:<10}]" , s); println! ("[{:>10}]" , s); println! ("[{:^10}]" , s); println! ("[{:*<10}]" , s); println! ("[{:0>10}]" , n); println! ("[{:-^10}]" , s); let width = 8 ;println! ("[{:>width$}]" , s); println! ("[{:>1$}]" , s, width);
精度控制 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 let pi = 3.14159265358979 ;println! ("{:.2}" , pi); println! ("{:.0}" , pi); println! ("{:.6}" , pi); println! ("{:10.2}" , pi); println! ("{:010.2}" , pi); let s = "Hello, World!" ;println! ("{:.5}" , s); let precision = 3 ;println! ("{:.prec$}" , pi, prec = precision); println! ("{:.1$}" , pi, precision); println! ("{pi:.precision$}" );
符号与特殊格式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 let pos = 42 ;let neg = -42 ;println! ("{:+}" , pos); println! ("{:+}" , neg); println! ("{:+010.2}" , 3.14 );
Debug 与 Display Trait 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 use std::fmt;struct Point { x: i32 , y: i32 , } impl fmt ::Display for Point { fn fmt (&self , f: &mut fmt::Formatter) -> fmt::Result { write! (f, "({}, {})" , self .x, self .y) } } #[derive(Debug)] struct Point2 { x: i32 , y: i32 , } fn main () { let p = Point { x: 3 , y: 4 }; println! ("{}" , p); let p2 = Point2 { x: 3 , y: 4 }; println! ("{:?}" , p2); println! ("{:#?}" , p2); }
自定义格式化细节 1 2 3 4 5 6 7 8 9 10 11 12 13 14 impl fmt ::Display for Point { fn fmt (&self , f: &mut fmt::Formatter) -> fmt::Result { if f.alternate () { write! (f, "Point[x={}, y={}]" , self .x, self .y) } else { write! (f, "({}, {})" , self .x, self .y) } } } let p = Point { x: 1 , y: 2 };println! ("{}" , p); println! ("{:#}" , p);
转义与原始输出 1 2 3 4 5 6 7 println! ("{{}}" ); println! ("{{{}}}" , 42 ); println! (r"C:\Users\name" ); println! (r#"She said "Hi""# );
注释与文档 注释类型总览
类型
语法
用途
行注释
//代码说明
块注释
/* */多行代码说明
文档注释(外部)
///为下方项生成文档
文档注释(内部)
//!为所在项生成文档
普通注释 1 2 3 4 5 6 7 8 9 10 11 let x = 1 + 2 ;
文档注释 /// 外部文档(为下方项生成文档)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 pub fn add (a: i32 , b: i32 ) -> i32 { a + b } pub struct Point { pub x: f64 , pub y: f64 , }
//! 内部文档(为所在项生成文档)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 pub fn add (a: i32 , b: i32 ) -> i32 { a + b }
1 2 3 4 5 6 7 8 9 10 11 pub mod utils { pub fn to_upper (s: &str ) -> String { s.to_uppercase () } }
Markdown 支持 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 pub fn example () {}
常用文档节(Sections) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 pub fn fetch (url: &str , timeout: u32 ) -> Result <String , Error> { }
标准节名称
节名
用途
# Examples使用示例(可被测试 )
# Panics何时会 panic
# Errors返回的错误类型及条件
# Safetyunsafe 代码的安全条件
# Arguments参数说明
# Returns返回值说明
# See Also相关项引用
代码块与文档测试 基本文档测试 1 2 3 4 5 6 7 8 9 pub fn factorial (n: u64 ) -> u64 { (1 ..=n).product () }
代码块标记 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 pub fn example () {}
隐藏辅助代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 pub fn read_config (path: &str ) -> Result <Config, std::io::Error> { }
渲染结果只显示:
1 2 let config = my_crate::read_config ("app.toml" )?;println! ("{:?}" , config);
文档链接 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 pub struct MyStruct ;pub fn doc_links () {}
属性与配置 #[doc] 属性1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #[doc = "这是文档注释" ] pub fn foo () {}#[doc = include_str!("../README.md" )] pub struct MyLib ;#[doc(hidden)] pub fn internal_use_only () {}#[doc(alias = "create" )] #[doc(alias = "make" )] pub fn new () -> Self { }
Cargo.toml 文档配置 1 2 3 4 5 6 7 8 [package] name = "my_crate" documentation = "https://docs.rs/my_crate" readme = "README.md" [package.metadata.docs.rs] all-features = true rustdoc-args = ["--cfg" , "docsrs" ]
生成与查看文档 1 2 3 4 5 6 7 8 9 10 11 12 13 14 cargo doc cargo doc --open cargo doc --document-private-items cargo doc --no-deps cargo test --doc
函数式编程 核心概念 1 2 3 4 函数式编程三要素 ├── 闭包(Closure) → 匿名函数,可捕获环境 ├── 迭代器(Iterator) → 惰性序列处理 └── 组合器(Combinator)→ 链式数据转换
闭包(Closure) 基本语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 let add = |a: i32 , b: i32 | -> i32 { a + b };let add = |a, b| a + b;let greet = || println! ("Hello!" );let complex = |x| { let y = x * 2 ; y + 1 }; println! ("{}" , add (2 , 3 )); greet ();
捕获环境变量 Rust 编译器根据闭包内如何使用变量 自动决定捕获方式,选择”刚好够用”的最小权限。
1 2 3 4 5 6 7 8 9 10 let x = 10 ;let y = 20 ;let sum = || x + y;println! ("{}" , sum ()); let add_x = |n| n + x;println! ("{}" , add_x (5 ));
三种捕获方式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 let s = String ::from ("hello" );let print = || println! ("{}" , s); print ();print (); println! ("{}" , s); let mut count = 0 ;let mut inc = || count += 1 ; inc ();inc ();println! ("{}" , count); let s = String ::from ("hello" );let consume = || drop (s); consume ();
Trait 对应关系 1 2 3 4 5 6 7 8 9 10 ┌─────────────────────────────────────────────────────┐ │ 捕获方式 Trait 可调用次数 签名 │ ├─────────────────────────────────────────────────────┤ │ 不可变借用 &T Fn 多次 &self │ │ 可变借用 &mut T FnMut 多次 &mut self │ │ 所有权 T FnOnce 一次 self │ ├─────────────────────────────────────────────────────┤ │ 继承关系: Fn : FnMut : FnOnce │ │ (实现 Fn 的自动实现 FnMut 和 FnOnce) │ └─────────────────────────────────────────────────────┘
move 关键字 1 2 3 4 5 6 7 8 9 10 11 12 let s = String ::from ("hello" );let closure = move || println! ("{}" , s);use std::thread;let data = vec! [1 , 2 , 3 ];let handle = thread::spawn (move || { println! ("{:?}" , data); }); handle.join ().unwrap ();
闭包作为参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 fn apply <F>(f: F) where F: Fn (i32 ) -> i32 { println! ("{}" , f (10 )); } fn apply2 <F: Fn (i32 ) -> i32 >(f: F) { println! ("{}" , f (10 )); } fn apply3 (f: impl Fn (i32 ) -> i32 ) { println! ("{}" , f (10 )); } fn apply_dyn (f: &dyn Fn (i32 ) -> i32 ) { println! ("{}" , f (10 )); } apply (|x| x * 2 ); apply (|x| x + 5 );
闭包作为返回值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 fn make_adder (n: i32 ) -> impl Fn (i32 ) -> i32 { move |x| x + n } fn make_op (op: &str ) -> Box <dyn Fn (i32 , i32 ) -> i32 > { match op { "add" => Box ::new (|a, b| a + b), "mul" => Box ::new (|a, b| a * b), _ => Box ::new (|a, _| a), } } let add5 = make_adder (5 );println! ("{}" , add5 (10 )); let mul = make_op ("mul" );println! ("{}" , mul (3 , 4 ));
迭代器(Iterator) Iterator Trait 1 2 3 4 5 pub trait Iterator { type Item ; fn next (&mut self ) -> Option <Self ::Item>; }
创建迭代器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 let v = vec! [1 , 2 , 3 ];let iter1 = v.iter (); let iter2 = v.iter_mut (); let iter3 = v.into_iter (); for x in v.iter () { } for x in v.into_iter () { } let range = 0 ..10 ; let repeat = std::iter::repeat (1 ); let once = std::iter::once (42 ); let empty : std::iter::Empty<i32 > = std::iter::empty ();
惰性求值 1 2 3 4 5 6 7 8 9 10 11 let v = vec! [1 , 2 , 3 , 4 , 5 ];let mapped = v.iter () .map (|x| { println! ("mapping {}" , x); x * 2 }); let result : Vec <_> = mapped.collect ();
迭代器适配器(Adapter) 适配器返回新迭代器,惰性求值 :
常用适配器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 let v = vec! [1 , 2 , 3 , 4 , 5 , 6 ];v.iter ().map (|x| x * 2 ); v.iter ().filter (|x| *x % 2 == 0 ); v.iter ().filter_map (|x| { if x % 2 == 0 { Some (x * 10 ) } else { None } }); v.iter ().take (3 ); v.iter ().skip (3 ); v.iter ().take_while (|x| **x < 4 ); v.iter ().skip_while (|x| **x < 4 ); v.iter ().enumerate (); let a = [1 , 2 , 3 ];let b = ["a" , "b" , "c" ];a.iter ().zip (b.iter ()); a.iter ().chain (b.iter ()); let nested = vec! [vec! [1 , 2 ], vec! [3 , 4 ]];nested.into_iter ().flatten (); nested.into_iter ().flat_map (|v| v.into_iter ()); v.iter ().rev (); let mut iter = v.iter ().peekable ();iter.peek (); iter.next (); v.iter ().cycle (); v.iter ().cloned (); v.iter ().copied ();
消费者(Consumer) 消费者消耗 迭代器,产生最终结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 let v = vec! [1 , 2 , 3 , 4 , 5 ];let doubled : Vec <i32 > = v.iter ().map (|x| x * 2 ).collect ();let set : HashSet<_> = v.iter ().collect ();let s : String = ['a' , 'b' , 'c' ].iter ().collect ();let total : i32 = v.iter ().sum (); let product : i32 = v.iter ().product (); let count = v.iter ().count (); let sum = v.iter ().fold (0 , |acc, x| acc + x); let concat = v.iter ().fold (String ::new (), |mut acc, x| { acc.push_str (&x.to_string ()); acc }); let max = v.iter ().copied ().reduce (|a, b| a.max (b)); v.iter ().for_each (|x| println! ("{}" , x)); let found = v.iter ().find (|&&x| x > 3 ); let pos = v.iter ().position (|&x| x == 3 ); let has_even = v.iter ().any (|x| x % 2 == 0 ); let all_pos = v.iter ().all (|x| *x > 0 ); let min = v.iter ().min (); let max = v.iter ().max (); let max_by_abs = [-3 , 1 , 2 ].iter () .max_by (|a, b| a.abs ().cmp (&b.abs ())); let third = v.iter ().nth (2 ); let last = v.iter ().last (); let (even, odd): (Vec <_>, Vec <_>) = v.iter () .partition (|x| *x % 2 == 0 );
自定义迭代器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 struct Counter { current: u32 , max: u32 , } impl Counter { fn new (max: u32 ) -> Self { Counter { current: 0 , max } } } impl Iterator for Counter { type Item = u32 ; fn next (&mut self ) -> Option <Self ::Item> { if self .current < self .max { self .current += 1 ; Some (self .current) } else { None } } } let counter = Counter::new (5 );let v : Vec <_> = counter.collect (); let sum : u32 = Counter::new (5 ) .filter (|x| x % 2 == 0 ) .map (|x| x * 10 ) .sum ();
性能:零成本抽象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 let sum : i32 = (1 ..=100 ) .filter (|x| x % 2 == 0 ) .map (|x| x * x) .sum (); let mut sum = 0 ;for x in 1 ..=100 { if x % 2 == 0 { sum += x * x; } }
何时迭代器更快 1 2 3 4 5 6 7 8 9 10 11 12 let v = vec! [1 , 2 , 3 , 4 , 5 ];for i in 0 ..v.len () { println! ("{}" , v[i]); } for x in &v { println! ("{}" , x); }
常见模式 错误处理收集 1 2 3 4 5 6 7 8 9 10 11 12 13 let strings = vec! ["1" , "2" , "three" , "4" ];let result : Result <Vec <i32 >, _> = strings .iter () .map (|s| s.parse::<i32 >()) .collect (); let numbers : Vec <i32 > = strings .iter () .filter_map (|s| s.parse ().ok ()) .collect ();
分组 1 2 3 4 5 6 7 8 9 10 11 use std::collections::HashMap;let data = vec! [("a" , 1 ), ("b" , 2 ), ("a" , 3 ), ("b" , 4 )];let grouped : HashMap<&str , Vec <i32 >> = data .into_iter () .fold (HashMap::new (), |mut map, (k, v)| { map.entry (k).or_default ().push (v); map });
窗口/块处理 1 2 3 4 5 6 7 8 9 10 11 let v = vec! [1 , 2 , 3 , 4 , 5 ];for chunk in v.chunks (2 ) { println! ("{:?}" , chunk); } for window in v.windows (3 ) { println! ("{:?}" , window); }
智能指针 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ┌────────────────────────────────────────────────────────────────────┐ │ 智能指针全景图 │ ├────────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │ │ Box<T> │ │ Rc<T> │ │ Arc<T> │ │RefCell<T>│ │ │ │ 堆分配 │ │ 引用计数 │ │原子引用 │ │内部可变 │ │ │ │ 单一所有 │ │ 共享所有 │ │线程安全 │ │运行时借用│ │ │ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │ │ │ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │ │ Cell<T> │ │ Weak<T> │ │ Cow<T> │ │ │ │Copy可变 │ │ 弱引用 │ │写时复制 │ │ │ └─────────┘ └─────────┘ └─────────┘ │ │ │ │ 智能指针 = 数据 + 元数据 + 自动行为(Deref + Drop) │ └────────────────────────────────────────────────────────────────────┘
Box<T> — 堆上分配 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 pub struct Box < T: ?Sized , A: Allocator = Global, >(Unique<T>, A); #[repr(transparent)] pub struct Unique <T: ?Sized > { pointer: NonNull<T>, _marker: PhantomData<T>, } #[repr(transparent)] pub struct NonNull <T: ?Sized > { pointer: *const T, } pub struct Global ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 fn main () { let b = Box ::new (5 ); println! ("b = {}" , b); #[derive(Debug)] enum List { Cons (i32 , Box <List>), Nil, } use List::{Cons, Nil}; let list = Cons (1 , Box ::new (Cons (2 , Box ::new (Cons (3 , Box ::new (Nil)))))); println! ("{:?}" , list); trait Animal { fn speak (&self ); } struct Dog ; impl Animal for Dog { fn speak (&self ) { println! ("Woof!" ); } } let animal : Box <dyn Animal> = Box ::new (Dog); animal.speak (); let large_array : Box <[i32 ; 1000000 ]> = Box ::new ([0 ; 1000000 ]); println! ("Array length: {}" , large_array.len ()); }
Box 内存布局 1 2 3 4 5 6 7 8 9 10 11 12 13 栈 (Stack) 堆 (Heap) ┌─────────────────┐ ┌─────────────────┐ │ MyBox<T> │ │ │ │ ┌─────────────┐ │ │ T (value) │ │ │ ptr ────────┼─┼─────────►│ 42 │ │ └─────────────┘ │ │ │ │ ┌─────────────┐ │ └─────────────────┘ │ │ _marker │ │ size = size_of::<T>() │ │ (0 bytes) │ │ │ └─────────────┘ │ └─────────────────┘ size = 8 bytes (仅一个指针)
Rc<T> — 引用计数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 pub struct Rc < T: ?Sized , A: Allocator = Global, > { ptr: NonNull<RcInner<T>>, phantom: PhantomData<RcInner<T>>, alloc: A, } #[repr(C)] struct RcInner <T: ?Sized > { strong: Cell<usize >, weak: Cell<usize >, value: T, } pub struct Weak < T: ?Sized , A: Allocator = Global, > { ptr: NonNull<RcInner<T>>, alloc: A, }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 use std::rc::Rc;fn main () { let a = Rc::new (String ::from ("Hello" )); println! ("引用计数: {}" , Rc::strong_count (&a)); let b = Rc::clone (&a); println! ("引用计数: {}" , Rc::strong_count (&a)); { let c = Rc::clone (&a); println! ("引用计数: {}" , Rc::strong_count (&a)); } println! ("引用计数: {}" , Rc::strong_count (&a)); #[derive(Debug)] struct Node { value: i32 , children: Vec <Rc<Node>>, } let leaf = Rc::new (Node { value: 3 , children: vec! [] }); let branch1 = Rc::new (Node { value: 1 , children: vec! [Rc::clone (&leaf)], }); let branch2 = Rc::new (Node { value: 2 , children: vec! [Rc::clone (&leaf)], }); println! ("leaf 引用计数: {}" , Rc::strong_count (&leaf)); }
Rc 内存布局 1 2 3 4 5 6 7 8 9 栈 堆 ┌──────┐ ┌─────────────────┐ │ a │────────────────►│ RcBox<T> │ ├──────┤ │ ┌─────────────┐ │ │ b │────────────────►│ │strong: 3 │ │ ├──────┤ │ │weak: 1 │ │ │ c │────────────────►│ │data: "Hello"│ │ └──────┘ │ └─────────────┘ │ └─────────────────┘
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Rc<T> 使用默认 Global 分配器时: 栈上 (Stack) 堆上 (Heap) ┌────────────────────────────────────┐ ┌────────────────────────────────┐ │ Rc<T, Global> │ │ RcInner<T> │ │ ┌──────────────────────────────┐ │ │ ┌──────────────────────────┐ │ │ │ ptr: NonNull<RcInner<T>> │ │ │ │ strong: Cell<usize> │ │ │ │ └── pointer: *const 8B │──┼────────►│ │ value: usize 8B │ │ │ ├──────────────────────────────┤ │ │ ├──────────────────────────┤ │ │ │ phantom: PhantomData 0B │ │ │ │ weak: Cell<usize> │ │ │ ├──────────────────────────────┤ │ │ │ value: usize 8B │ │ │ │ alloc: Global 0B │ │ │ ├──────────────────────────┤ │ │ └──────────────────────────────┘ │ │ │ value: T │ │ ├────────────────────────────────────┤ │ │ (实际数据) │ │ │ Total: 8 bytes │ │ └──────────────────────────┘ │ └────────────────────────────────────┘ │ Total: 16 + size_of::<T>() │ └────────────────────────────────┘
Arc<T> — 原子引用计数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 pub struct Arc < T: ?Sized , A: Allocator = Global, > { ptr: NonNull<ArcInner<T>>, phantom: PhantomData<ArcInner<T>>, alloc: A, } #[repr(C)] struct ArcInner <T: ?Sized > { strong: AtomicUsize, weak: AtomicUsize, value: T, } pub struct Weak < T: ?Sized , A: Allocator = Global, > { ptr: NonNull<ArcInner<T>>, alloc: A, }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 use std::sync::Arc;use std::thread;fn main () { let data = Arc::new (vec! [1 , 2 , 3 , 4 , 5 ]); let mut handles = vec! []; for i in 0 ..3 { let data_clone = Arc::clone (&data); let handle = thread::spawn (move || { println! ("线程 {}: {:?}" , i, data_clone); }); handles.push (handle); } for handle in handles { handle.join ().unwrap (); } println! ("最终引用计数: {}" , Arc::strong_count (&data)); use std::sync::Mutex; let counter = Arc::new (Mutex::new (0 )); let mut handles = vec! []; for _ in 0 ..10 { let counter = Arc::clone (&counter); let handle = thread::spawn (move || { let mut num = counter.lock ().unwrap (); *num += 1 ; }); handles.push (handle); } for handle in handles { handle.join ().unwrap (); } println! ("计数器: {}" , *counter.lock ().unwrap ()); }
Arc 内存布局 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 Arc<T> 使用默认 Global 分配器时: 栈上 (Stack) 堆上 (Heap) ┌────────────────────────────────────┐ ┌────────────────────────────────┐ │ Arc<T, Global> │ │ ArcInner<T> │ │ ┌──────────────────────────────┐ │ │ ┌──────────────────────────┐ │ │ │ ptr: NonNull<ArcInner<T>> │ │ │ │ strong: AtomicUsize │ │ │ │ └── pointer: *const 8B │──┼────────►│ │ value: usize 8B │ │ │ ├──────────────────────────────┤ │ │ ├──────────────────────────┤ │ │ │ phantom: PhantomData 0B │ │ │ │ weak: AtomicUsize │ │ │ ├──────────────────────────────┤ │ │ │ value: usize 8B │ │ │ │ alloc: Global 0B │ │ │ ├──────────────────────────┤ │ │ └──────────────────────────────┘ │ │ │ value: T │ │ ├────────────────────────────────────┤ │ │ (实际数据) │ │ │ Total: 8 bytes │ │ └──────────────────────────┘ │ └────────────────────────────────────┘ │ Total: 16 + size_of::<T>() │ └────────────────────────────────┘ 注: AtomicUsize 和 usize 大小相同,都是 8 bytes (64位系统) 原子性是通过 CPU 指令保证的,不需要额外空间 Arc<T, A> │ ├── ptr: NonNull<ArcInner<T>> │ │ │ └── *const ArcInner<T> ─────────────────────┐ │ │ ├── phantom: PhantomData<ArcInner<T>> │ │ └── 零大小,表示逻辑上拥有 ArcInner<T> │ │ │ └── alloc: A │ └── 默认 Global (零大小) │ ▼ ┌──────────────────────────┐ │ ArcInner<T> (堆上) │ Weak<T, A> │ │ │ │ strong: AtomicUsize ◄────┼── 原子操作 ├── ptr: NonNull<ArcInner<T>> ──────────►│ weak: AtomicUsize ◄────┼── 原子操作 │ │ value: T │ └── alloc: A └──────────────────────────┘ 所有权与线程安全 ┌─────────────────────────────────────────────────────────────────────────┐ │ │ │ Arc<T> ──────► ArcInner<T> ──────► T │ │ │ │ │ │ │ │ │ └── 多线程共享只读访问 (&T) │ │ │ │ │ │ │ └── 引用计数通过原子操作保护 │ │ │ │ │ └── 可以 Send 到其他线程 (当 T: Send + Sync) │ │ │ │ 要修改 T,需要: │ │ - Arc<Mutex<T>> 或 Arc<RwLock<T>> │ │ - Arc::make_mut (会克隆) │ │ - Arc::get_mut (需要唯一引用) │ │ │ └─────────────────────────────────────────────────────────────────────────┘
多线程共享示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Thread 1 Thread 2 Thread 3 ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │ arc1: Arc │ │ arc2: Arc │ │ arc3: Arc │ │ ┌──────────┐ │ │ ┌──────────┐ │ │ ┌──────────┐ │ │ │ ptr ─────┼─┼───┐ │ │ ptr ─────┼─┼───┐ │ │ ptr ─────┼─┼───┐ │ └──────────┘ │ │ │ └──────────┘ │ │ │ └──────────┘ │ │ └──────────────┘ │ └──────────────┘ │ └──────────────┘ │ │ │ │ │ │ │ ▼ ▼ ▼ ┌─────────────────────────────────────────────────────┐ │ ArcInner<i32 > (堆上,共享) │ │ ┌───────────────────────────────────────────────┐ │ │ │ strong: AtomicUsize = 3 │ │ │ │ ▲ │ │ │ │ │ 原子操作: fetch_add / fetch_sub │ │ │ │ │ 多线程同时修改也安全 │ │ │ ├───────────────────────────────────────────────┤ │ │ │ weak: AtomicUsize = 1 │ │ │ ├───────────────────────────────────────────────┤ │ │ │ value: i32 = 42 │ │ │ └───────────────────────────────────────────────┘ │ └─────────────────────────────────────────────────────┘
Rc vs Arc 对比 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ┌─────────────────────────────────────────────────────────────────────────────┐ │ Rc vs Arc 内部结构对比 │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ RcInner<T> ArcInner<T> │ │ ┌─────────────────────────┐ ┌─────────────────────────┐ │ │ │ strong: Cell<usize> │ │ strong: AtomicUsize │ │ │ │ 普通读写 │ │ 原子操作 │ │ │ │ cell.get() / set() │ │ atomic.load() / fetch_sub() │ │ ├─────────────────────────┤ ├─────────────────────────┤ │ │ │ weak: Cell<usize> │ │ weak: AtomicUsize │ │ │ │ 普通读写 │ │ 原子操作 │ │ │ ├─────────────────────────┤ ├─────────────────────────┤ │ │ │ value: T │ │ value: T │ │ │ └─────────────────────────┘ └─────────────────────────┘ │ │ │ │ ❌ !Send, !Sync ✅ Send + Sync (当 T: Send + Sync) │ │ ✅ 更快 (无同步开销) ❌ 有原子操作开销 │ │ 📍 单线程使用 📍 多线程共享 │ │ │ └─────────────────────────────────────────────────────────────────────────────┘
RefCell<T> — 内部可变性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 pub struct RefCell <T: ?Sized > { borrow: Cell<BorrowFlag>, #[cfg(feature = "debug_refcell" )] borrowed_at: Cell<Option <&'static Location<'static >>>, value: UnsafeCell<T>, } type BorrowFlag = isize ;const UNUSED: BorrowFlag = 0 ; const WRITING: BorrowFlag = -1 ; pub struct Ref <'b , T: ?Sized + 'b > { value: NonNull<T>, borrow: BorrowRef<'b >, } struct BorrowRef <'b > { borrow: &'b Cell<BorrowFlag>, } pub struct RefMut <'b , T: ?Sized + 'b > { value: NonNull<T>, borrow: BorrowRefMut<'b >, #[cfg(feature = "debug_refcell" )] marker: PhantomData<&'b mut T>, } struct BorrowRefMut <'b > { borrow: &'b Cell<BorrowFlag>, }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 use std::cell::RefCell;fn main () { let data = RefCell::new (5 ); *data.borrow_mut () += 1 ; println! ("data = {}" , data.borrow ()); struct Cache { data: RefCell<Option <String >>, } impl Cache { fn new () -> Self { Cache { data: RefCell::new (None ) } } fn get (&self ) -> String { let mut cache = self .data.borrow_mut (); if cache.is_none () { *cache = Some ("computed value" .to_string ()); } cache.clone ().unwrap () } } let cache = Cache::new (); println! ("{}" , cache.get ()); println! ("{}" , cache.get ()); let value = RefCell::new (10 ); let _borrow1 = value.borrow (); let _borrow2 = value.borrow (); }
RefCell 借用规则 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 use std::cell::RefCell;fn demonstrate_refcell_rules () { let cell = RefCell::new (42 ); { let r1 = cell.borrow (); let r2 = cell.borrow (); println! ("{} {}" , r1, r2); } { let mut w = cell.borrow_mut (); *w += 1 ; } if let Ok (r) = cell.try_borrow () { println! ("借用成功: {}" , r); } if let Ok (w) = cell.try_borrow_mut () { println! ("可变借用成功" ); } }
RefCell 内存布局 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 RefCell<T> 布局 (release 模式): ┌─────────────────────────────────────────────────────────────┐ │ RefCell<T> │ │ ┌───────────────────────────────────────────────────────┐ │ │ │ borrow: Cell<BorrowFlag> │ │ │ │ └── value: UnsafeCell<isize> 8B │ │ │ ├───────────────────────────────────────────────────────┤ │ │ │ value: UnsafeCell<T> │ │ │ │ └── value: T size_of<T> │ │ │ └───────────────────────────────────────────────────────┘ │ ├─────────────────────────────────────────────────────────────┤ │ Total: 8 + size_of::<T>() (+ 对齐填充) │ └─────────────────────────────────────────────────────────────┘ RefCell<i32> 具体布局: ┌──────────────────────────────────────┐ │ offset 0: borrow: isize 8B │ 借用计数 ├──────────────────────────────────────┤ │ offset 8: value: i32 4B │ 实际数据 ├──────────────────────────────────────┤ │ offset 12: padding 4B │ 对齐填充 ├──────────────────────────────────────┤ │ Total: 16 bytes │ └──────────────────────────────────────┘
线程安全性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ┌─────────────────────────────────────────────────────────────────────────────┐ │ RefCell 不是线程安全的! │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ RefCell<T>: !Sync │ │ │ │ 原因: borrow 计数使用 Cell<isize >,不是原子操作 │ │ │ │ Thread 1 Thread 2 │ │ ───────── ───────── │ │ b = borrow.get () │ b = borrow.get () │ borrow.set (b-1 ) │ borrow.set (b-1 ) │ 写入数据... │ │ 写入数据... ← 数据竞争!UB! │ │ │ │ 解决方案: │ │ - 单线程: 使用 RefCell │ │ - 多线程: 使用 Mutex 或 RwLock │ │ │ └─────────────────────────────────────────────────────────────────────────────┘ 对比表: ┌────────────────┬─────────────┬─────────────┬─────────────────────────────────┐ │ │ Send │ Sync │ 说明 │ ├────────────────┼─────────────┼─────────────┼─────────────────────────────────┤ │ Cell<T> │ ✅ * │ ❌ │ 不能共享引用到其他线程 │ ├────────────────┼─────────────┼─────────────┼─────────────────────────────────┤ │ RefCell<T> │ ✅ * │ ❌ │ 不能共享引用到其他线程 │ ├────────────────┼─────────────┼─────────────┼─────────────────────────────────┤ │ Mutex<T> │ ✅ * │ ✅ * │ 原子锁,可以跨线程共享 │ ├────────────────┼─────────────┼─────────────┼─────────────────────────────────┤ │ RwLock<T> │ ✅ * │ ✅ * │ 原子锁,可以跨线程共享 │ └────────────────┴─────────────┴─────────────┴─────────────────────────────────┘ * 当 T: Send 时
Cell<T> — Copy 类型的内部可变性 1 2 3 4 5 6 7 8 pub struct Cell <T: ?Sized > { value: UnsafeCell<T>, } #[repr(transparent)] pub struct UnsafeCell <T: ?Sized > { value: T, }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 use std::cell::Cell;fn main () { let cell = Cell::new (5 ); cell.set (10 ); let value = cell.get (); println! ("value = {}" , value); struct Counter { count: Cell<u32 >, } impl Counter { fn new () -> Self { Counter { count: Cell::new (0 ) } } fn increment (&self ) { self .count.set (self .count.get () + 1 ); } fn get (&self ) -> u32 { self .count.get () } } let counter = Counter::new (); counter.increment (); counter.increment (); println! ("count = {}" , counter.get ()); }
Cell vs RefCell 对比 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 Cell<T> 是零开销抽象! ┌─────────────────────────────────────────────────────────────────────────────┐ │ Cell<T> 内存布局 │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ Cell<i32>: 普通 i32: │ │ ┌───────────────────┐ ┌───────────────────┐ │ │ │ value: i32 4B │ === │ value: i32 4B │ │ │ └───────────────────┘ └───────────────────┘ │ │ Total: 4B Total: 4B │ │ │ │ Cell<u8>: │ │ ┌───────────────────┐ │ │ │ value: u8 1B │ size_of::<Cell<T>>() == size_of::<T>() │ │ └───────────────────┘ align_of::<Cell<T>>() == align_of::<T>() │ │ Total: 1B │ │ │ │ Cell<[i32; 4]>: │ │ ┌───────────────────┐ │ │ │ [i32; 4] 16B │ │ │ └───────────────────┘ │ │ Total: 16B │ │ │ └─────────────────────────────────────────────────────────────────────────────┘ 对比 RefCell<T>: ┌──────────────────────────────────────────────────────┐ │ RefCell<i32>: │ │ ┌──────────────────────────────────────────────┐ │ │ │ borrow: Cell<isize> 8B │ │ ← 额外开销! │ ├──────────────────────────────────────────────┤ │ │ │ value: UnsafeCell<i32> 4B │ │ │ ├──────────────────────────────────────────────┤ │ │ │ padding 4B │ │ │ └──────────────────────────────────────────────┘ │ │ Total: 16B (Cell<i32> 的 4 倍!) │ └──────────────────────────────────────────────────────┘
Weak<T> — 弱引用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 pub struct Weak < T: ?Sized , A: Allocator = Global, > { ptr: NonNull<RcInner<T>>, alloc: A, } struct RcInner <T: ?Sized > { strong: Cell<usize >, weak: Cell<usize >, value: T, } const WEAK_EMPTY: usize = usize ::MAX;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 use std::rc::{Rc, Weak};use std::cell::RefCell;#[derive(Debug)] struct Node { value: i32 , parent: RefCell<Weak<Node>>, children: RefCell<Vec <Rc<Node>>>, } fn main () { let leaf = Rc::new (Node { value: 3 , parent: RefCell::new (Weak::new ()), children: RefCell::new (vec! []), }); println! ("leaf strong = {}, weak = {}" , Rc::strong_count (&leaf), Rc::weak_count (&leaf)); { let branch = Rc::new (Node { value: 5 , parent: RefCell::new (Weak::new ()), children: RefCell::new (vec! [Rc::clone (&leaf)]), }); *leaf.parent.borrow_mut () = Rc::downgrade (&branch); println! ("branch strong = {}, weak = {}" , Rc::strong_count (&branch), Rc::weak_count (&branch)); if let Some (parent) = leaf.parent.borrow ().upgrade () { println! ("leaf's parent value = {}" , parent.value); } } println! ("leaf's parent = {:?}" , leaf.parent.borrow ().upgrade ()); }
weak 内存布局 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 Weak<T> 有两种状态: 状态 1 : 空的 Weak(Weak::new () 创建) ┌─────────────────────────────────────────────────────────────────────────────┐ │ Weak<T, Global> 栈上布局 │ │ ┌───────────────────────────────────────────────────────────────────────┐ │ │ │ ptr: NonNull<RcInner<T>> │ │ │ │ └── pointer = 0xFFFF_FFFF_FFFF_FFFF (usize ::MAX) 8 B │ │ │ │ 这是一个标记值,表示"没有指向任何东西" │ │ │ ├───────────────────────────────────────────────────────────────────────┤ │ │ │ alloc: Global 0 B │ │ │ └───────────────────────────────────────────────────────────────────────┘ │ │ Total: 8 bytes │ │ │ │ 堆上: 无!不需要分配任何内存 │ └─────────────────────────────────────────────────────────────────────────────┘ 状态 2 : 指向 RcInner 的 Weak(从 Rc::downgrade 创建) ┌─────────────────────────────────────────────────────────────────────────────┐ │ Weak<T, Global> 栈上布局 │ │ ┌───────────────────────────────────────────────────────────────────────┐ │ │ │ ptr: NonNull<RcInner<T>> │ │ │ │ └── pointer = 0x7fff_ xxxx_xxxx (有效堆地址) 8 B │ │ │ ├───────────────────────────────────────────────────────────────────────┤ │ │ │ alloc: Global 0 B │ │ │ └───────────────────────────────────────────────────────────────────────┘ │ │ Total: 8 bytes │ │ │ │ │ │ │ ▼ │ │ ┌─────────────────────────────────────┐ │ │ │ RcInner<T> (堆上,与 Rc 共享) │ │ │ │ ┌─────────────────────────────┐ │ │ │ │ │ strong: Cell<usize > 8 B │ │ │ │ │ ├─────────────────────────────┤ │ │ │ │ │ weak: Cell<usize > 8 B │ │ │ │ │ ├─────────────────────────────┤ │ │ │ │ │ value: T │ │ ← 可能已被 drop! │ │ │ └─────────────────────────────┘ │ │ │ └─────────────────────────────────────┘ │ └─────────────────────────────────────────────────────────────────────────────┘
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 ┌─────────────────────────────────────────────────────────────────────────────┐ │ Rc 和 Weak 共享同一个 RcInner │ ├─────────────────────────────────────────────────────────────────────────────┤ Rc<T> Weak<T> Weak<T> ┌──────────┐ ┌──────────┐ ┌──────────┐ │ ptr ─────┼─────┐ │ ptr ─────┼─────┐ │ ptr ─────┼─────┐ │ phantom │ │ │ alloc │ │ │ alloc │ │ │ alloc │ │ └──────────┘ │ └──────────┘ │ └──────────┘ │ │ │ │ │ │ │ │ │ ▼ ▼ ▼ ┌──────────────────────────────────────────────────────────┐ │ RcInner<T> (堆上) │ │ ┌────────────────────────────────────────────────────┐ │ │ │ strong: Cell<usize > = 1 │ │ │ │ ▲ │ │ │ │ │ Rc 数量 │ │ │ ├────────────────────────────────────────────────────┤ │ │ │ weak: Cell<usize > = 3 │ │ │ │ ▲ │ │ │ │ │ Weak 数量 + 1 (有 Rc 时额外 +1 ) │ │ │ ├────────────────────────────────────────────────────┤ │ │ │ value: T │ │ │ │ ▲ │ │ │ │ │ 当 strong → 0 时被 drop │ │ │ │ │ 但 RcInner 还在(因为 Weak 存在) │ │ │ └────────────────────────────────────────────────────┘ │ └──────────────────────────────────────────────────────────┘ 当 strong = 0 且 weak = 1 时释放 RcInner └─────────────────────────────────────────────────────────────────────────────┘
Cow<T> — 写时复制 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 pub enum Cow <'a , B: ?Sized + 'a >where B: ToOwned , { Borrowed (&'a B), Owned (<B as ToOwned >::Owned), } pub trait ToOwned { type Owned : Borrow<Self >; fn to_owned (&self ) -> Self ::Owned; fn clone_into (&self , target: &mut Self ::Owned) { ... } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 use std::borrow::Cow;fn main () { let s1 : Cow<str > = Cow::Borrowed ("hello" ); let s2 : Cow<str > = Cow::Owned (String ::from ("world" )); println! ("{} {}" , s1, s2); fn process_text (text: &str ) -> Cow<str > { if text.contains ("bad" ) { Cow::Owned (text.replace ("bad" , "good" )) } else { Cow::Borrowed (text) } } let text1 = "this is good" ; let text2 = "this is bad" ; let result1 = process_text (text1); let result2 = process_text (text2); println! ("{}" , result1); println! ("{}" , result2); let mut cow : Cow<str > = Cow::Borrowed ("hello" ); cow.to_mut ().push_str (" world" ); println! ("{}" , cow); fn print_cow <'a >(s: impl Into <Cow<'a , str >>) { let cow : Cow<str > = s.into (); println! ("{}" , cow); } print_cow ("borrowed str" ); print_cow (String ::from ("owned" )); }
Cow 内存布局 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 ┌─────────────────────────────────────────────────────────────────────────────┐ │ │ │ Cow::Borrowed (&str ): │ │ ┌───────────────────────────────────────────────────────────────────────┐ │ │ │ [0 ..8 ] ptr: 指向字符串数据 8 B │ │ │ ├───────────────────────────────────────────────────────────────────────┤ │ │ │ [8 ..16 ] len: 字符串长度 8 B │ │ │ ├───────────────────────────────────────────────────────────────────────┤ │ │ │ [16 ..24 ] marker: usize ::MAX (0xFFFF_FFFF_FFFF_FFFF ) 8 B │ │ │ │ ▲ │ │ │ │ └── 这个特殊值表示 "我是 Borrowed" │ │ │ └───────────────────────────────────────────────────────────────────────┘ │ │ │ │ │ │ Cow::Owned (String ): │ │ ┌───────────────────────────────────────────────────────────────────────┐ │ │ │ [0 ..8 ] ptr: 指向堆上数据 8 B │ │ │ ├───────────────────────────────────────────────────────────────────────┤ │ │ │ [8 ..16 ] len: 字符串长度 8 B │ │ │ ├───────────────────────────────────────────────────────────────────────┤ │ │ │ [16 ..24 ] cap: 分配的容量 (永远 < usize ::MAX) 8 B │ │ │ │ ▲ │ │ │ │ └── 真实的容量值,不会是 MAX │ │ │ └───────────────────────────────────────────────────────────────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────────────┘ 判断逻辑: ┌────────────────────────────────────────────────────────────────┐ │ │ │ fn is_borrowed (cow: &Cow<str >) -> bool { │ │ │ cow.cap_or_marker == usize ::MAX │ │ } │ │ │ │ if cap_or_marker == usize ::MAX { │ │ │ } else { │ │ │ } │ │ │ └────────────────────────────────────────────────────────────────┘
引用计数与数据释放 Rust 中用到引用计数的类型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ┌─────────────────────────────────────────────────────────────────────────────┐ │ Rust 引用计数类型 │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────────────────────────────────────────────────────────────────┐ │ │ │ 类型 │ 模块 │ 适用场景 │ │ │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ Rc<T> │ std::rc │ 单线程共享所有权 │ │ │ │ Weak<T> │ std::rc │ Rc 的弱引用 │ │ │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ Arc<T> │ std::sync │ 多线程共享所有权 │ │ │ │ Weak<T> │ std::sync │ Arc 的弱引用 │ │ │ └─────────────────────────────────────────────────────────────────────┘ │ │ │ │ Rc = Reference Counted │ │ Arc = Atomically Reference Counted │ │ │ └─────────────────────────────────────────────────────────────────────────────┘
内存布局 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ┌─────────────────────────────────────────────────────────────────────────────┐ │ Rc<T> / Arc<T> 内存结构 │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ 栈上 堆上 │ │ ┌─────────┐ ┌──────────────────────────────┐ │ │ │ Rc<T> │ │ RcBox<T> │ │ │ │ │ ├──────────────────────────────┤ │ │ │ ptr ───┼───────────────►│ strong: Cell<usize> │ ← 强引用计数 │ │ │ │ │ weak: Cell<usize> │ ← 弱引用计数 │ │ └─────────┘ ├──────────────────────────────┤ │ │ │ │ │ │ ┌─────────┐ │ value: T │ ← 实际数据 │ │ │ Weak<T> │ │ │ │ │ │ │ │ │ │ │ │ ptr ───┼───────────────►└──────────────────────────────┘ │ │ │ │ │ │ └─────────┘ │ │ │ │ Arc<T> 结构相同,但计数器使用 AtomicUsize(原子操作) │ │ │ └─────────────────────────────────────────────────────────────────────────────┘
计数变化规则 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 use std::rc::{Rc, Weak};fn main () { let a = Rc::new (String ::from ("hello" )); println! ("创建后: strong={}, weak={}" , Rc::strong_count (&a), Rc::weak_count (&a)); let b = Rc::clone (&a); let c = Rc::clone (&a); println! ("clone 两次: strong={}, weak={}" , Rc::strong_count (&a), Rc::weak_count (&a)); let w1 : Weak<String > = Rc::downgrade (&a); let w2 : Weak<String > = Rc::downgrade (&a); println! ("downgrade 两次: strong={}, weak={}" , Rc::strong_count (&a), Rc::weak_count (&a)); drop (b); drop (c); println! ("drop 两个 Rc: strong={}, weak={}" , Rc::strong_count (&a), Rc::weak_count (&a)); drop (w1); println! ("drop 一个 Weak: strong={}, weak={}" , Rc::strong_count (&a), Rc::weak_count (&a)); }
释放时机 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ┌─────────────────────────────────────────────────────────────────────────────┐ │ 数据释放时机 │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────────────────────────────────────────────────────────────────┐ │ │ │ │ │ │ │ strong_count → 0 ══════► value: T 被 drop(析构函数执行) │ │ │ │ │ │ │ │ weak_count → 0 ══════► 整个控制块被释放(需 strong 也为 0) │ │ │ │ │ │ │ └─────────────────────────────────────────────────────────────────────┘ │ │ │ │ │ │ 状态流转: │ │ │ │ s>0, w≥0 s=0, w>0 s=0, w=0 │ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │ │ 数据存活 │ ───► │ 数据已释放│ ───► │ 全部释放 │ │ │ │ 控制块在 │ │ 控制块在 │ │ │ │ │ └──────────┘ └──────────┘ └──────────┘ │ │ │ │ │ │ │ └── Weak.upgrade() 返回 None │ │ └── 可正常访问数据 │ │ │ └─────────────────────────────────────────────────────────────────────────────┘
释放过程演示 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 use std::rc::{Rc, Weak};struct Data { value: i32 , } impl Drop for Data { fn drop (&mut self ) { println! (" 💥 Data({}) 被析构" , self .value); } } fn main () { let weak : Weak<Data>; { let rc1 = Rc::new (Data { value: 42 }); let rc2 = Rc::clone (&rc1); weak = Rc::downgrade (&rc1); println! ("作用域内: strong={}, weak={}" , Rc::strong_count (&rc1), Rc::weak_count (&rc1)); } println! ("作用域外: weak.strong_count()={}" , weak.strong_count ()); match weak.upgrade () { Some (rc) => println! ("数据: {}" , rc.value), None => println! ("upgrade 失败,数据已释放" ), } }
stong=0,weak>0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ┌─────────────────────────────────────────────────────────────────────────────┐ │ 内存状态对比 │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ strong > 0 时 strong = 0, weak > 0 时 │ │ │ │ Weak ───► ┌─────────────────┐ Weak ───► ┌─────────────────┐ │ │ │ strong: 1 │ │ strong: 0 │ │ │ │ weak: 1 │ │ weak: 1 │ │ │ ├─────────────────┤ ├─────────────────┤ │ │ │ │ │ │ │ │ │ Data(42) ✅ │ │ (已释放) ❌ │ │ │ │ │ │ │ │ │ └─────────────────┘ └─────────────────┘ │ │ │ │ │ upgrade(): upgrade(): │ │ │ 1. 读 strong → 1 1. 读 strong → 0 │ 控制块还在 │ │ 2. strong > 0 2. strong == 0 │ 所以能读取 │ │ 3. 返回 Some(Rc) 3. 返回 None │ │ │ │ └─────────────────────────────────────────────────────────────────────────────┘
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ┌─────────────────────────────────────────────────────────────────────────────┐ │ 谁负责释放什么 │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ 操作 │ 行为 │ │ ────────────────────┼─────────────────────────────────────────────────── │ │ drop(Rc) │ strong-- │ │ │ 若 strong→0:释放数据 T │ │ │ 若 strong→0 且 weak=0:释放控制块 │ │ ────────────────────┼─────────────────────────────────────────────────── │ │ drop(Weak) │ weak-- │ │ │ 若 strong=0 且 weak→0:释放控制块 │ │ ────────────────────┼─────────────────────────────────────────────────── │ │ weak.upgrade() │ 只读取 strong_count,返回 Option │ │ │ 不修改计数,不释放任何东西 │ │ │ └─────────────────────────────────────────────────────────────────────────────┘
strong = 0, weak > 0 时,控制块的存在意义就是为了 weak 不访问也指针。
智能指针对比 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ┌─────────────┬──────────┬──────────┬──────────┬─────────────────────┐ │ 智能指针 │ 所有权 │ 可变性 │ 线程安全 │ 主要用途 │ ├─────────────┼──────────┼──────────┼──────────┼─────────────────────┤ │ Box<T> │ 独占 │ 继承 │ ✅ │ 堆分配、递归类型 │ ├─────────────┼──────────┼──────────┼──────────┼─────────────────────┤ │ Rc<T> │ 共享 │ 不可变 │ ❌ │ 单线程共享所有权 │ ├─────────────┼──────────┼──────────┼──────────┼─────────────────────┤ │ Arc<T> │ 共享 │ 不可变 │ ✅ │ 多线程共享所有权 │ ├─────────────┼──────────┼──────────┼──────────┼─────────────────────┤ │ RefCell<T> │ 独占 │内部可变 │ ❌ │ 运行时借用检查 │ ├─────────────┼──────────┼──────────┼──────────┼─────────────────────┤ │ Cell<T> │ 独占 │内部可变 │ ❌ │ Copy类型内部可变 │ ├─────────────┼──────────┼──────────┼──────────┼─────────────────────┤ │ Weak<T> │ 无 │ 不可变 │ 同Rc/Arc │ 打破循环引用 │ ├─────────────┼──────────┼──────────┼──────────┼─────────────────────┤ │ Cow<T> │ 按需 │ 按需 │ ✅ │ 写时复制优化 │ ├─────────────┼──────────┼──────────┼──────────┼─────────────────────┤ │ Mutex<T> │ 共享 │内部可变 │ ✅ │ 多线程互斥访问 │ ├─────────────┼──────────┼──────────┼──────────┼─────────────────────┤ │ RwLock<T> │ 共享 │内部可变 │ ✅ │ 多线程读写锁 │ └─────────────┴──────────┴──────────┴──────────┴─────────────────────┘
选择决策流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 需要智能指针? │ ├─► 需要堆分配? ──► Box<T> │ ├─► 需要共享所有权? │ │ │ ├─► 单线程 ──► Rc<T> │ │ │ │ │ └─► 需要可变? ──► Rc<RefCell<T>> │ │ │ └─► 多线程 ──► Arc<T> │ │ │ └─► 需要可变? ──► Arc<Mutex<T>> 或 Arc<RwLock<T>> │ ├─► 需要内部可变性? │ │ │ ├─► T: Copy ──► Cell<T> │ │ │ └─► 其他 ──► RefCell<T> │ └─► 需要避免克隆? ──► Cow<T>
循环引用 (Cyclic References) 问题本质 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ┌─────────────────────────────────────────────────────────────────────────────┐ │ 使用 Rc (循环引用 - 泄漏!) │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ 栈变量 a 栈变量 b │ │ │ │ │ │ ▼ ▼ │ │ ┌──────────────────┐ ┌──────────────────┐ │ │ │ Rc<RefCell<Node>>│ │ Rc<RefCell<Node>>│ │ │ │ strong_count: 2 │ │ strong_count: 2 │ ← 都是 2! │ │ │ weak_count: 0 │ │ weak_count: 0 │ │ │ ├──────────────────┤ ├──────────────────┤ │ │ │ Node { │ │ Node { │ │ │ │ value: 1 │ │ value: 2 │ │ │ │ next: Some ───┼── Rc ───►│ next: Some ───┼── Rc ──┐ │ │ │ } │ │ } │ │ │ │ └──────────────────┘ └──────────────────┘ │ │ │ ▲ │ │ │ └────────────────────────────────────────────────┘ │ │ │ │ 离开作用域后: │ │ ┌─────────────────────────────────────────────────────────┐ │ │ │ a 析构: strong_count 2 → 1 (b.next 还持有) │ │ │ │ b 析构: strong_count 2 → 1 (a.next 还持有) │ │ │ │ 两者都不为 0,永远无法 drop! 💥 内存泄漏 │ │ │ └─────────────────────────────────────────────────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────────────┘
Rc 导致的内存泄漏 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 use std::cell::RefCell;use std::rc::Rc;struct Node { value: i32 , next: Option <Rc<RefCell<Node>>>, } impl Drop for Node { fn drop (&mut self ) { println! ("🗑️ Dropping Node with value: {}" , self .value); } } fn main () { println! ("=== 创建循环引用 ===" ); { let a = Rc::new (RefCell::new (Node { value: 1 , next: None })); let b = Rc::new (RefCell::new (Node { value: 2 , next: None })); println! ("a strong={}, b strong={} a weak={}, b weak={}" , Rc::strong_count (&a), Rc::strong_count (&b), Rc::weak_count (&a), Rc::weak_count (&b)); a.borrow_mut ().next = Some (Rc::clone (&b)); println! ("a strong={}, b strong={} a weak={}, b weak={}" , Rc::strong_count (&a), Rc::strong_count (&b), Rc::weak_count (&a), Rc::weak_count (&b)); b.borrow_mut ().next = Some (Rc::clone (&a)); println! ("a strong={}, b strong={} a weak={}, b weak={}" , Rc::strong_count (&a), Rc::strong_count (&b), Rc::weak_count (&a), Rc::weak_count (&b)); } println! ("=== 离开作用域 ===" ); println! ("(如果没看到 Drop 消息,说明泄漏了!)" ); }
解决方案:Weak 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 use std::cell::RefCell;use std::rc::{Rc, Weak};struct Node { value: i32 , next: Option <Weak<RefCell<Node>>>, } impl Drop for Node { fn drop (&mut self ) { println! ("🗑️ Dropping Node with value: {}" , self .value); } } fn main () { println! ("=== 使用 Weak 打破循环 ===" ); { let a = Rc::new (RefCell::new (Node { value: 1 , next: None })); let b = Rc::new (RefCell::new (Node { value: 2 , next: None })); println! ("a strong={}, a weak={}\nb strong={}, b weak={}" , Rc::strong_count (&a), Rc::weak_count (&a), Rc::strong_count (&b), Rc::weak_count (&b)); a.borrow_mut ().next = Some (Rc::downgrade (&b)); println! ("a strong={}, a weak={}\nb strong={}, b weak={}" , Rc::strong_count (&a), Rc::weak_count (&a), Rc::strong_count (&b), Rc::weak_count (&b)); b.borrow_mut ().next = Some (Rc::downgrade (&a)); println! ("a strong={}, a weak={}\nb strong={}, b weak={}" , Rc::strong_count (&a), Rc::weak_count (&a), Rc::strong_count (&b), Rc::weak_count (&b)); } println! ("=== 离开作用域 ===" ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ┌─────────────────────────────────────────────────────────────────────────────┐ │ 使用 Weak (打破循环 - 正常释放) │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ 栈变量 a 栈变量 b │ │ │ │ │ │ ▼ ▼ │ │ ┌──────────────────┐ ┌──────────────────┐ │ │ │ Rc<RefCell<Node>>│ │ Rc<RefCell<Node>>│ │ │ │ strong_count: 1 │ │ strong_count: 1 │ ← 都是 1! │ │ │ weak_count: 1 │ │ weak_count: 1 │ │ │ ├──────────────────┤ ├──────────────────┤ │ │ │ Node { │ │ Node { │ │ │ │ value: 1 │ │ value: 2 │ │ │ │ next: Some ───┼─ Weak ─ ─│─ ─next: Some ───┼─ Weak ─ ┐ │ │ │ } │ 弱! │ } │ 弱! │ │ │ └──────────────────┘ └──────────────────┘ │ │ │ ▲ │ │ │ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┘ │ │ (虚线 = Weak,不增加 strong_count) │ │ │ └─────────────────────────────────────────────────────────────────────────────┘
完整的 Weak 方案析构过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 ┌─────────────────────────────────────────────────────────────────────────────┐ │ Weak 方案的完整析构过程 │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ 初始状态: │ │ ══════════ │ │ a b │ │ │ │ │ │ ▼ ▼ │ │ ┌─────────────────┐ Weak ┌─────────────────┐ │ │ │ 控制块 │ │ 控制块 │ │ │ │ strong: 1 │◄─ ─ ─ ─ ─ ─ ─ ─│ strong: 1 │ │ │ │ weak: 1 │ │ weak: 1 │ │ │ ├─────────────────┤ ├─────────────────┤ │ │ │ Node 1 数据 │─ ─ ─ ─ ─ ─ ─ ─►│ Node 2 数据 │ │ │ │ (next: Weak) │ Weak │ (next: Weak) │ │ │ └─────────────────┘ └─────────────────┘ │ │ │ │ │ │ Step 1: 栈变量 a 离开作用域,drop(Rc<Node1>) │ │ ════════════════════════════════════════════ │ │ │ │ 1a. Node1 的 strong: 1→0 │ │ b │ │ │ │ │ ▼ │ │ ┌─────────────────┐ ┌─────────────────┐ │ │ │ 控制块 │ │ 控制块 │ │ │ │ strong: 0 ←改变 │◄─ ─ ─ ─ ─ ─ ─ ─│ strong: 1 │ │ │ │ weak: 1 │ │ weak: 1 │ │ │ ├─────────────────┤ ├─────────────────┤ │ │ │ Node 1 数据 │─ ─ ─ ─ ─ ─ ─ ─►│ Node 2 数据 │ │ │ │ (next: Weak) │ │ (next: Weak) │ │ │ └─────────────────┘ └─────────────────┘ │ │ │ │ 1b. strong=0,触发 drop(Node1 数据),内部 Weak<Node2> 也被 drop │ │ → Node2 的 weak: 1→0 │ │ │ │ b │ │ │ │ │ ▼ │ │ ┌─────────────────┐ ┌─────────────────┐ │ │ │ 控制块 │ │ 控制块 │ │ │ │ strong: 0 │◄─ ─ ─ ─ ─ ─ ─ ─│ strong: 1 │ │ │ │ weak: 1 │ │ weak: 0 ←改变 │ │ │ ├─────────────────┤ ├─────────────────┤ │ │ │ 🗑️ 已释放 │ │ Node 2 数据 │ │ │ │ │ │ (next: Weak) │ │ │ └─────────────────┘ └─────────────────┘ │ │ │ │ 1c. 检查 Node1:strong=0, weak=1 (>0) → 控制块保留 ✓ │ │ 检查 Node2:strong=1, weak=0 → 控制块保留 ✓(strong>0) │ │ │ │ │ │ Step 2: 栈变量 b 离开作用域,drop(Rc<Node2>) │ │ ════════════════════════════════════════════ │ │ │ │ 2a. Node2 的 strong: 1→0 │ │ │ │ ┌─────────────────┐ ┌─────────────────┐ │ │ │ 控制块 │ │ 控制块 │ │ │ │ strong: 0 │◄─ ─ ─ ─ ─ ─ ─ ─│ strong: 0 ←改变 │ │ │ │ weak: 1 │ │ weak: 0 │ │ │ ├─────────────────┤ ├─────────────────┤ │ │ │ (已释放) │ │ Node 2 数据 │ │ │ │ │ │ (next: Weak) │ │ │ └─────────────────┘ └─────────────────┘ │ │ │ │ 2b. strong=0,触发 drop(Node2 数据),内部 Weak<Node1> 也被 drop │ │ → Node1 的 weak: 1→0 │ │ │ │ ┌─────────────────┐ ┌─────────────────┐ │ │ │ 控制块 │ │ 控制块 │ │ │ │ strong: 0 │ │ strong: 0 │ │ │ │ weak: 0 ←改变 │ │ weak: 0 │ │ │ ├─────────────────┤ ├─────────────────┤ │ │ │ (已释放) │ │ 🗑️ 已释放 │ │ │ │ │ │ │ │ │ └─────────────────┘ └─────────────────┘ │ │ │ │ 2c. 检查 Node1:strong=0, weak=0 → 🗑️ 释放控制块! │ │ 检查 Node2:strong=0, weak=0 → 🗑️ 释放控制块! │ │ │ │ │ │ 最终状态: │ │ ══════════ │ │ │ │ 🗑️ 🗑️ │ │ (完全释放) (完全释放) │ │ │ │ │ │ ✅ 数据 + 控制块 全部正常释放,无泄漏! │ │ │ └─────────────────────────────────────────────────────────────────────────────┘
释放规则总结
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 ┌─────────────────────────────────────────────────────────────────────────────┐ │ 释放时机 │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────────────────────────────────────────────────────────────┐ │ │ │ 内存布局 │ │ │ │ ┌─────────────────┐ │ │ │ │ │ 控制块 │ ← weak_count 保护 │ │ │ │ │ strong_count │ │ │ │ │ │ weak_count │ │ │ │ │ ├─────────────────┤ │ │ │ │ │ 数据 T │ ← strong_count 保护 │ │ │ │ └─────────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────┘ │ │ │ │ 释放数据 T: strong → 0 时 │ │ 释放控制块: strong = 0 且 weak → 0 时 │ │ │ │ ═══════════════════════════════════════════════════════════════════ │ │ │ │ 事件 │ 数据 T │ 控制块 │ │ ─────────────────┼──────────────┼──────────────────────────────── │ │ strong: 1→0 │ 🗑️ 释放 │ 检查 weak │ │ weak: 1→0 │ (已释放) │ 若 strong=0 则 🗑️ 释放 │ │ │ └─────────────────────────────────────────────────────────────────────────────┘
关键点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ┌──────────────────────────────────────────────────────────────────┐ │ │ │ 为什么 Step 1 后 Node1 控制块还在? │ │ │ │ → Node2 的 Weak 还指向 Node1 │ │ → Node1 的 weak_count = 1 │ │ → 控制块必须保留,否则 Node2 的 Weak 变野指针 │ │ │ │ ──────────────────────────────────────────────────────────── │ │ │ │ 什么时候 Node1 控制块才释放? │ │ │ │ → Step 2 中 drop(Node2 数据) 时 │ │ → Node2 内部的 Weak<Node1> 被 drop │ │ → Node1 的 weak: 1→0 │ │ → 此时 strong=0, weak=0 → 释放控制块 │ │ │ └──────────────────────────────────────────────────────────────────┘
自引用 (Self-Referential Structs) 问题本质 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct SelfRef { data: String , ptr: &str , } fn main () { let mut s = SelfRef { data: String ::from ("hello" ), ptr: ???, }; s.ptr = &s.data; let s2 = s; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ┌─────────────────────────────────────────────────────────────────────────────┐ │ 移动导致自引用失效 │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ 移动前 (栈地址 0x1000): 移动后 (栈地址 0x2000): │ │ ┌────────────────────────┐ ┌────────────────────────┐ │ │ │ data: String │ │ data: String │ │ │ │ ptr ─────────────────┼──┐ │ ptr ─────────────────┼──┐ │ │ │ len: 5 │ │ │ len: 5 │ │ │ │ │ cap: 5 │ │ │ cap: 5 │ │ │ │ ├────────────────────────┤ │ ├────────────────────────┤ │ │ │ │ ptr: &str ─────────────┼──┤ │ ptr: &str ─────────────┼──┼── 悬垂! │ │ │ (指向 0x1000.data) │ │ │ (仍指向 0x1000!) │ │ │ │ └────────────────────────┘ │ └────────────────────────┘ │ │ │ ▲ │ │ │ │ └────────────────┘ │ │ │ ✓ 有效 ✗ 无效! ────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────────────┘
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 ┌─────────────────────────────────────────────────────────────────────────────┐ │ 移动 = memcpy │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ 栈 (高地址 → 低地址) │ │ ═══════════════════ │ │ │ │ 移动前: 移动后: │ │ │ │ ┌─────────────────┐ 0x2000 ┌─────────────────┐ 0x2000 │ │ │ s2: ??? │ │ s2 (有效) │ ◄── 字节被复制到这里 │ │ │ │ │ [完整的数据] │ │ │ └─────────────────┘ └─────────────────┘ │ │ │ │ ┌─────────────────┐ 0x1000 ┌─────────────────┐ 0x1000 │ │ │ s (有效) │ ════► │ s (无效) │ ◄── 编译器禁止访问 │ │ │ [完整的数据] │ memcpy │ [数据还在!] │ 但字节仍在内存中 │ │ └─────────────────┘ └─────────────────┘ │ │ │ │ 堆 (不变) 堆 (不变) │ │ ═════════ ═════════ │ │ ┌─────────────────┐ 0x8000 ┌─────────────────┐ 0x8000 │ │ │ "hello" │ │ "hello" │ │ │ └─────────────────┘ └─────────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────────────┘ ┌─────────────────────────────────────────────────────────────────────────────┐ │ 移动后的真实内存状态 │ ├─────────────────────────────────────────────────────────────────────────────┤ │ │ │ let s1 = String::from("hello"); │ │ let s2 = s1; // 移动 │ │ │ │ 栈内存 (物理真实状态): │ │ ┌─────────────────────┐ 0x2000 │ │ │ s2: │ │ │ │ ptr: 0x8000 ──────┼───┐ ✅ 有效,编译器允许访问 │ │ │ len: 5 │ │ │ │ │ cap: 5 │ │ │ │ └─────────────────────┘ │ │ │ │ │ │ ┌─────────────────────┐ 0x1000 │ │ │ s1 (残留数据): │ │ │ │ │ ptr: 0x8000 ──────┼───┤ ❌ 无效,编译器禁止访问 │ │ │ len: 5 │ │ 但字节确实还在! │ │ │ cap: 5 │ │ │ │ └─────────────────────┘ │ │ │ │ │ │ 堆内存: │ │ │ ┌─────────────────────┐ 0x8000 │ │ │ "hello" │◄──┴── 两个指针都指向这里 │ │ └─────────────────────┘ 但只有 s2 能用 │ │ │ └─────────────────────────────────────────────────────────────────────────────┘
解决方案 使用索引代替引用 1 2 3 4 5 6 7 8 9 10 11 12 struct Document { buffer: String , tokens: Vec <(usize , usize )>, } impl Document { fn get_token (&self , idx: usize ) -> &str { let (start, end) = self .tokens[idx]; &self .buffer[start..end] } }
Pin + PhantomPinned 两个组件的作用
1 2 use std::pin::Pin; use std::marker::PhantomPinned;
1 2 3 4 5 6 7 8 ┌─────────────────────────────────────────────────────────────────┐ │ │ │ Pin<P> → "我保证不会移动 P 指向的数据" │ │ PhantomPinned → "我需要被钉住,移动我会出问题" │ │ │ │ 两者配合:Pin 才能真正阻止移动 │ │ │ └─────────────────────────────────────────────────────────────────┘
完整示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 use std::pin::Pin;use std::marker::PhantomPinned;struct SelfRef { data: String , ptr: *const String , _pin: PhantomPinned, } impl SelfRef { fn new (data: String ) -> Self { SelfRef { data, ptr: std::ptr::null (), _pin: PhantomPinned, } } fn init (self : Pin<&mut Self >) { unsafe { let this = self .get_unchecked_mut (); this.ptr = &this.data; } } fn get_data (self : Pin<&Self >) -> &str { unsafe { &*self .ptr } } } fn main () { let mut pinned = Box ::pin (SelfRef::new ("hello" .into ())); pinned.as_mut ().init (); println! ("{}" , pinned.as_ref ().get_data ()); }
为什么需要 PhantomPinned?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct Normal { data: String } let mut n = Normal { data: "hi" .into () };let pinned = Pin::new (&mut n);let moved = *pinned.get_mut (); struct Pinned { data: String , _pin: PhantomPinned }
ouroboros 添加依赖
1 2 [dependencies] ouroboros = "0.18.5"
基本用法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 use ouroboros::self_referencing;#[self_referencing] struct SelfRef { data: String , #[borrows(data)] data_ref: &'this str , } fn main () { let s = SelfRefBuilder { data: "hello" .into (), data_ref_builder: |data| data.as_str (), }.build (); s.with_data_ref (|r| println! ("{}" , r)); }
可变访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 use ouroboros::self_referencing;#[self_referencing] struct MutableSelf { data: String , #[borrows(mut data)] slice: &'this mut str , } fn main () { let mut s = MutableSelfBuilder { data: "hello" .into (), slice_builder: |data| data.as_mut_str (), }.build (); s.with_slice_mut (|s| { s.make_ascii_uppercase (); }); s.with_slice (|s| println! ("{}" , s)); }
ouroboros 宏展开解析
这些都是 ouroboros 宏自动生成的
1 2 3 4 5 ┌─────────────────────────────────────────────────────────────────┐ │ 'this → ouroboros 定义的特殊生命周期占位符 │ │ SelfRefBuilder → 宏根据结构体名生成的 Builder 结构体 │ │ data_ref_builder → 宏根据字段名生成的初始化闭包字段 │ └─────────────────────────────────────────────────────────────────┘
感兴趣的同学可以使用 cargo expand 来查看展开后的代码。
1 2 cargo install cargo-expand cargo expand
命名规则
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 ┌────────────────────────────────────────────────────────────────────┐ │ 对于 #[self_referencing] struct Foo { ... } │ ├────────────────────────────────────────────────────────────────────┤ │ │ │ 类型名 作用 │ │ ───────────────────────────────────────────────────────────── │ │ Foo 主结构体 │ │ FooBuilder Builder 结构体 │ │ FooHeads 非借用字段的所有权集合 │ │ BorrowedFields with() 中使用的引用集合 │ │ BorrowedMutFields with_mut() 中使用的可变引用集合 │ │ │ ├────────────────────────────────────────────────────────────────────┤ │ │ │ 方法名 作用 │ │ ───────────────────────────────────────────────────────────── │ │ Foo::new() 直接构造 │ │ Foo::try_new() 可能失败的构造 │ │ Foo::try_new_or_recover() 失败时返回 heads │ │ FooBuilder::build() 从 builder 构造 │ │ │ │ .with_xxx() 访问字段 xxx │ │ .with_xxx_mut() 可变访问字段 xxx │ │ .with() 访问所有字段 │ │ .with_mut() 可变访问所有字段 │ │ .borrow_xxx() 直接引用 xxx(仅非自引用字段) │ │ .borrow_xxx_mut() 直接可变引用 xxx │ │ .into_heads() 消耗 self,返回 heads │ │ │ └───────────────────────────────────────────────────────────────────
完整对照示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 use ouroboros::self_referencing;#[self_referencing] struct Parser { source: String , #[borrows(source)] tokens: Vec <&'this str >, } fn main () { let p = ParserBuilder { source: "hello world" .into (), tokens_builder: |src: &String | { src.split_whitespace ().collect () }, }.build (); p.with_tokens (|tokens| { println! ("{:?}" , tokens); }); p.with_source (|s| { println! ("{}" , s); }); }
为什么需要闭包 builder?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ┌─────────────────────────────────────────────────────────────────┐ │ 问题:自引用字段依赖其他字段,必须按顺序初始化 │ │ │ │ tokens 引用 source → source 必须先存在 │ │ │ │ 解决:用闭包延迟执行 │ │ │ │ ParserBuilder { │ │ source: "...", // 1. 先有 source │ │ tokens_builder: |src| { // 2. 闭包等 source 就位后调用 │ │ src.split()... // 此时 src 地址已固定 │ │ } │ │ }.build() // 3. build 时按顺序执行 │ │ │ └─────────────────────────────────────────────────────────────────┘
总结 :'this、XxxBuilder、xxx_builder、with_xxx() 全部是 ouroboros 宏生成的。
深入类型 dyn trait 基本概念 dyn Trait 是 trait 对象 ,用于实现运行时多态 (动态分发)。
1 2 3 4 5 6 7 8 fn main () { let x : &dyn std::fmt::Debug = &42 ; let y : Box <dyn std::fmt::Debug > = Box ::new ("hello" ); }
静态分发 vs 动态分发 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 trait Animal { fn speak (&self ); } struct Dog ;struct Cat ;impl Animal for Dog { fn speak (&self ) { println! ("Woof!" ); } } impl Animal for Cat { fn speak (&self ) { println! ("Meow!" ); } } fn static_speak <T: Animal>(animal: &T) { animal.speak (); } fn dynamic_speak (animal: &dyn Animal) { animal.speak (); } fn main () { let dog = Dog; let cat = Cat; static_speak (&dog); static_speak (&cat); dynamic_speak (&dog); dynamic_speak (&cat); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ┌─────────────────────────────────────────────────────────────────────┐ │ 静态分发 vs 动态分发 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ 特性 静态分发 (impl Trait/泛型) 动态分发 (dyn Trait)│ │ ───────────────────────────────────────────────────────────────── │ │ 类型确定时机 编译时 运行时 │ │ 性能 更快(可内联) 有虚表查找开销 │ │ 二进制大小 更大(每类型一份代码) 更小(共享代码) │ │ 异构集合 ❌ 不支持 ✅ 支持 │ │ 编译时间 更长 更短 │ │ 语法 impl Trait 或 <T: Trait> dyn Trait │ │ │ └─────────────────────────────────────────────────────────────────────┘
Trait 对象的内存结构 1 2 3 4 5 6 7 8 9 10 use std::mem::size_of;fn main () { println! ("{}" , size_of::<&i32 >()); println! ("{}" , size_of::<&dyn Send >()); println! ("{}" , size_of::<Box <dyn Send >>()); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ┌─────────────────────────────────────────────────────────────────────┐ │ &dyn Trait 胖指针结构 │ │ │ │ ┌──────────────────────────────────────────────────────────────┐ │ │ │ data_ptr (8 bytes) │ vtable_ptr (8 bytes) │ │ │ │ 指向实际数据 │ 指向虚函数表 │ │ │ └──────────────────────────────────────────────────────────────┘ │ │ │ │ vtable(虚函数表)内容: │ │ ┌──────────────────────────────────────────────────────────────┐ │ │ │ drop_fn │ 析构函数指针 │ │ │ │ size │ 类型大小 │ │ │ │ align │ 类型对齐 │ │ │ │ method_1 │ trait 方法 1 的函数指针 │ │ │ │ method_2 │ trait 方法 2 的函数指针 │ │ │ │ ... │ │ │ │ └──────────────────────────────────────────────────────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────┘
为什么需要 dyn Trait 异构集合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 trait Drawable { fn draw (&self ); } struct Circle { radius: f64 }struct Rectangle { width: f64 , height: f64 }impl Drawable for Circle { fn draw (&self ) { println! ("Drawing circle r={}" , self .radius); } } impl Drawable for Rectangle { fn draw (&self ) { println! ("Drawing rect {}x{}" , self .width, self .height); } } fn main () { let shapes : Vec <Box <dyn Drawable>> = vec! [ Box ::new (Circle { radius: 1.0 }), Box ::new (Rectangle { width: 2.0 , height: 3.0 }), ]; for shape in &shapes { shape.draw (); } }
返回不同类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 trait Animal { fn speak (&self ) -> &str ; } struct Dog ;struct Cat ;impl Animal for Dog { fn speak (&self ) -> &str { "Woof" } } impl Animal for Cat { fn speak (&self ) -> &str { "Meow" } } fn get_animal (is_dog: bool ) -> Box <dyn Animal> { if is_dog { Box ::new (Dog) } else { Box ::new (Cat) } } fn main () { let animal = get_animal (true ); println! ("{}" , animal.speak ()); }
存储回调/闭包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 struct Button { on_click: Box <dyn Fn ()>, } impl Button { fn new (callback: impl Fn () + 'static ) -> Self { Button { on_click: Box ::new (callback), } } fn click (&self ) { (self .on_click)(); } } fn main () { let btn1 = Button::new (|| println! ("Button 1 clicked" )); let btn2 = Button::new (|| println! ("Button 2 clicked" )); btn1.click (); btn2.click (); }
对象安全(Object Safety) **不是所有 trait 都能变成 dyn Trait**,必须是”对象安全”的。
对象安全的要求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 trait Safe { fn method (&self ); fn method_with_param (&self , x: i32 ) -> i32 ; } trait NotSafe1 { fn generic_method <T>(&self , t: T); } trait NotSafe2 { fn clone (&self ) -> Self ; } trait NotSafe3 { fn by_value (self ); } trait NotSafe4 { fn associated () -> i32 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ┌─────────────────────────────────────────────────────────────────────┐ │ 对象安全规则(所有方法必须满足) │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ 1. 不能有泛型类型参数 │ │ 2. 第一个参数必须是 self 相关类型: │ │ - &self │ │ - &mut self │ │ - self: Box<Self> │ │ - self: Rc<Self> │ │ - self: Arc<Self> │ │ - self: Pin<&Self> │ │ 3. 返回值不能是 Self │ │ 4. 没有 where Self: Sized 约束 │ │ │ └─────────────────────────────────────────────────────────────────────┘
绕过限制的技巧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 trait MyTrait { fn generic <T>(&self , t: T) where Self : Sized ; fn normal (&self ); } struct Foo ;impl MyTrait for Foo { fn generic <T>(&self , t: T) { } fn normal (&self ) { println! ("normal" ); } } fn main () { let obj : &dyn MyTrait = &Foo; obj.normal (); }
常见的 dyn Trait 用法 错误处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 use std::error::Error;fn might_fail () -> Result <(), Box <dyn Error>> { let _file = std::fs::File::open ("nonexistent.txt" )?; let _num : i32 = "not a number" .parse ()?; Ok (()) } fn main () { if let Err (e) = might_fail () { println! ("Error: {}" , e); } }
闭包存储
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 type Callback = Box <dyn Fn (i32 ) -> i32 >;type AsyncCallback = Box <dyn Fn () + Send + Sync >; struct EventHandler { callbacks: Vec <Box <dyn Fn (&str )>>, } impl EventHandler { fn new () -> Self { EventHandler { callbacks: vec! [] } } fn add_callback (&mut self , cb: impl Fn (&str ) + 'static ) { self .callbacks.push (Box ::new (cb)); } fn trigger (&self , event: &str ) { for cb in &self .callbacks { cb (event); } } }
插件系统
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 trait Plugin { fn name (&self ) -> &str ; fn execute (&self ); } struct PluginManager { plugins: Vec <Box <dyn Plugin>>, } impl PluginManager { fn new () -> Self { PluginManager { plugins: vec! [] } } fn register (&mut self , plugin: impl Plugin + 'static ) { self .plugins.push (Box ::new (plugin)); } fn run_all (&self ) { for plugin in &self .plugins { println! ("Running: {}" , plugin.name ()); plugin.execute (); } } }
多个 trait 约束
1 2 3 4 5 6 7 8 9 10 11 use std::fmt::Debug ;fn print_debug (val: &(dyn Debug + Send + Sync )) { println! ("{:?}" , val); } fn boxed_multi () -> Box <dyn Debug + Send + Sync > { Box ::new (42 ) }
Sized 与动态大小类型 (DST) Sized Trait 基础 1 2 3 4 5 fn foo <T>(t: T) {} fn bar <T: ?Sized >(t: &T) {}
类型大小分类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ┌─────────────────────────────────────────────────────────────────────┐ │ Rust 类型大小分类 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ Sized 类型(编译时已知大小) │ │ ├── 原始类型: i32, f64, bool, char │ │ ├── 固定数组: [T; N] │ │ ├── 元组: (A, B, C) │ │ ├── 结构体/枚举(所有字段都是 Sized) │ │ └── 指针/引用: &T, &mut T, *const T, Box<T> │ │ │ │ DST - 动态大小类型(编译时大小未知) │ │ ├── str 字符串切片 │ │ ├── [T] 数组切片 │ │ └── dyn Trait trait 对象 │ │ │ │ ZST - 零大小类型 │ │ ├── () 单元类型 │ │ ├── struct Foo; 空结构体 │ │ └── PhantomData<T> │ │ │ └─────────────────────────────────────────────────────────────────────┘
DST 与胖指针 1 2 3 4 5 6 7 8 9 10 11 12 13 14 use std::mem::size_of;fn main () { println! ("{}" , size_of::<&i32 >()); println! ("{}" , size_of::<&[i32 ; 10 ]>()); println! ("{}" , size_of::<Box <i32 >>()); println! ("{}" , size_of::<&str >()); println! ("{}" , size_of::<&[i32 ]>()); println! ("{}" , size_of::<&dyn Send >()); println! ("{}" , size_of::<Box <dyn Send >>()); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ┌─────────────────────────────────────────────────────────────────────┐ │ 胖指针内部结构 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ &[T] / &str: │ │ ┌──────────────────┬──────────────────┐ │ │ │ data pointer │ length │ │ │ │ (8 bytes) │ (8 bytes) │ │ │ └──────────────────┴──────────────────┘ │ │ │ │ &dyn Trait: │ │ ┌──────────────────┬──────────────────┐ │ │ │ data pointer │ vtable pointer │ │ │ │ (8 bytes) │ (8 bytes) │ │ │ └──────────────────┴──────────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────┘
?Sized 约束的使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 fn print_sized <T: std::fmt::Debug >(val: &T) { println! ("{:?}" , val); } fn print_any <T: std::fmt::Debug + ?Sized >(val: &T) { println! ("{:?}" , val); } fn main () { let s : &str = "hello" ; let arr : &[i32 ] = &[1 , 2 , 3 ]; print_any (s); print_any (arr); print_any (&42i32 ); }
结构体中的 DST 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 struct MySlice <T> { len: usize , data: [T], } #[repr(transparent)] struct Path { inner: std::ffi::OsStr, } impl Path { fn new <S: AsRef <std::ffi::OsStr> + ?Sized >(s: &S) -> &Path { unsafe { &*(s.as_ref () as *const std::ffi::OsStr as *const Path) } } }
零大小类型 (ZST) ZST 类型示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 use std::mem::size_of;use std::marker::PhantomData;struct Empty ;struct NoFields {}struct Marker ;fn main () { println! ("{}" , size_of::<()>()); println! ("{}" , size_of::<Empty>()); println! ("{}" , size_of::<NoFields>()); println! ("{}" , size_of::<PhantomData<i32 >>()); println! ("{}" , size_of::<[i32 ; 0 ]>()); let a = Empty; let b = Empty; println! ("{:p}" , &a); println! ("{:p}" , &b); }
PhantomData 用途 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 use std::marker::PhantomData;struct Slice <'a , T> { ptr: *const T, len: usize , _marker: PhantomData<&'a T>, } struct Iter <'a , T> { ptr: *const T, end: *const T, _marker: PhantomData<&'a T>, } struct Builder <State> { data: String , _state: PhantomData<State>, } struct Initial ;struct Configured ;struct Built ;impl Builder <Initial> { fn new () -> Self { Builder { data: String ::new (), _state: PhantomData } } fn configure (self , data: &str ) -> Builder<Configured> { Builder { data: data.into (), _state: PhantomData } } } impl Builder <Configured> { fn build (self ) -> Builder<Built> { Builder { data: self .data, _state: PhantomData } } } struct DropChecker <T> { ptr: *mut T, _marker: PhantomData<T>, } impl <T> Drop for DropChecker <T> { fn drop (&mut self ) { unsafe { std::ptr::drop_in_place (self .ptr); } } }
PhantomData 变体 1 2 3 4 5 6 7 8 9 10 11 use std::marker::PhantomData;struct Container <T> { ptr: *const T, _owned: PhantomData<T>, _ref : PhantomData<&'static T>, _fn : PhantomData<fn (T)>, _fn_ret: PhantomData<fn () -> T>, }
Newtype 模式 基本定义 1 2 3 4 5 struct Meters (f64 );struct Seconds (f64 );struct UserId (u64 );struct Email (String );
核心用途 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 struct Meters (f64 );struct Feet (f64 );fn calculate_distance (m: Meters) -> Meters { Meters (m.0 * 2.0 ) } fn main () { let m = Meters (100.0 ); let f = Feet (100.0 ); calculate_distance (m); } use std::fmt;struct Wrapper (Vec <String >);impl fmt ::Display for Wrapper { fn fmt (&self , f: &mut fmt::Formatter) -> fmt::Result { write! (f, "[{}]" , self .0 .join (", " )) } } pub struct PublicApi (InternalType); struct NonEmpty <T>(Vec <T>);impl <T> NonEmpty<T> { fn new (first: T) -> Self { NonEmpty (vec! [first]) } fn first (&self ) -> &T { &self .0 [0 ] } } struct SortedVec <T: Ord >(Vec <T>);impl <T: Ord > SortedVec<T> { fn new (mut v: Vec <T>) -> Self { v.sort (); SortedVec (v) } fn binary_search (&self , x: &T) -> Option <usize > { self .0 .binary_search (x).ok () } }
Newtype 便捷实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 use std::ops::{Deref, DerefMut, Add};#[derive(Debug, Clone, Copy, PartialEq, PartialOrd)] struct Meters (f64 );impl Deref for Meters { type Target = f64 ; fn deref (&self ) -> &f64 { &self .0 } } impl Add for Meters { type Output = Self ; fn add (self , other: Self ) -> Self { Meters (self .0 + other.0 ) } } impl From <f64 > for Meters { fn from (v: f64 ) -> Self { Meters (v) } } impl From <Meters> for f64 { fn from (m: Meters) -> Self { m.0 } } fn main () { let m = Meters (10.0 ); println! ("{}" , m.abs ()); println! ("{}" , m.sin ()); let total = Meters (10.0 ) + Meters (20.0 ); let m : Meters = 5.0 .into (); let v : f64 = m.into (); }
使用 derive_more 简化 1 2 3 [dependencies] derive_more = "0.99"
1 2 3 4 5 6 7 8 9 10 11 use derive_more::{From , Into , Deref, DerefMut, Add, Display};#[derive(Debug, Clone, Copy, From, Into, Deref, Add, Display)] #[display(fmt = "{}m" , _0)] struct Meters (f64 );fn main () { let m : Meters = 10.0 .into (); let sum = m + Meters (5.0 ); println! ("{}" , sum); }
类型别名 基本语法 1 2 3 4 5 6 7 8 9 10 11 12 type Kilometers = i32 ;type Thunk = Box <dyn Fn () + Send + 'static >;type Result <T> = std::result::Result <T, std::io::Error>;fn main () { let x : Kilometers = 5 ; let y : i32 = 10 ; let z = x + y; }
类型别名常见用途 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 type Callback = Box <dyn Fn (i32 ) -> i32 + Send + Sync + 'static >;type ParseResult <'a > = Result <(&'a str , Token), ParseError>;pub type Result <T> = std::result::Result <T, MyError>;pub fn foo () -> Result <i32 > { Ok (42 ) } type Pair <T> = (T, T);type StringMap <V> = std::collections::HashMap<String , V>;fn main () { let p : Pair<i32 > = (1 , 2 ); let mut m : StringMap<i32 > = StringMap::new (); m.insert ("a" .into (), 1 ); } trait Container { type Item ; type Iter <'a >: Iterator <Item = &'a Self ::Item> where Self : 'a ; } type Never = !;
类型转换 as 强制转换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 fn main () { let a : i32 = 42 ; let b : i64 = a as i64 ; let c : i16 = a as i16 ; let d : f64 = a as f64 ; let e : i32 = 3.14 as i32 ; let ptr : *const i32 = &42 ; let addr : usize = ptr as usize ; let ptr2 : *const i32 = addr as *const i32 ; let r : &i32 = &42 ; let p : *const i32 = r as *const i32 ; #[repr(u8)] enum Color { Red = 1 , Green = 2 , Blue = 3 } let n : u8 = Color::Red as u8 ; let c : char = 'A' ; let n : u32 = c as u32 ; let c2 : char = 66u8 as char ; }
From/Into trait
消耗原值 :调用 .into() 会获取所有权并转换为目标类型。自动实现 :实现了 From<T> 的类型会自动拥有 *Into<T>*。泛型约束常用 :在泛型函数中使用 T: Into<U> 可以让函数接受更多可转换的类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 use std::convert::From ;struct Meters (f64 );impl From <f64 > for Meters { fn from (v: f64 ) -> Self { Meters (v) } } impl From <i32 > for Meters { fn from (v: i32 ) -> Self { Meters (v as f64 ) } } fn main () { let m1 = Meters::from (10.5 ); let m2 = Meters::from (10 ); let m3 : Meters = 10.5 .into (); let m4 : Meters = 10 .into (); fn process (m: impl Into <Meters>) { let meters = m.into (); println! ("{}" , meters.0 ); } process (10.5 ); process (10i32 ); }
TryFrom/TryInto(可能失败的转换) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 use std::convert::TryFrom;use std::num::TryFromIntError;fn main () { let a : i32 = 1000 ; let b : Result <u8 , _> = u8 ::try_from (a); let c : i32 = 100 ; let d : u8 = u8 ::try_from (c).unwrap (); let e : Result <u8 , _> = a.try_into (); } #[derive(Debug)] struct PositiveInt (i32 );#[derive(Debug)] struct NegativeError ;impl TryFrom <i32 > for PositiveInt { type Error = NegativeError; fn try_from (value: i32 ) -> Result <Self , Self ::Error> { if value > 0 { Ok (PositiveInt (value)) } else { Err (NegativeError) } } } fn example () { let p : Result <PositiveInt, _> = 42 .try_into (); let n : Result <PositiveInt, _> = (-1 ).try_into (); }
AsRef/AsMut(廉价引用转换) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 fn print_path <P: AsRef <std::path::Path>>(path: P) { println! ("{}" , path.as_ref ().display ()); } fn print_bytes <B: AsRef <[u8 ]>>(bytes: B) { println! ("{:?}" , bytes.as_ref ()); } fn main () { print_path ("hello.txt" ); print_path (String ::from ("hello.txt" )); print_path (std::path::Path::new ("hello.txt" )); print_bytes ("hello" ); print_bytes (vec! [1 , 2 , 3 ]); print_bytes ([1 , 2 , 3 ]); } struct MyString (String );impl AsRef <str > for MyString { fn as_ref (&self ) -> &str { &self .0 } } impl AsRef <[u8 ]> for MyString { fn as_ref (&self ) -> &[u8 ] { self .0 .as_bytes () } }
Borrow/BorrowMut 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 use std::borrow::Borrow;use std::collections::HashMap;fn main () { let mut map : HashMap<String , i32 > = HashMap::new (); map.insert ("hello" .into (), 42 ); let v = map.get ("hello" ); }
Deref 强制转换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 use std::ops::Deref;struct MyBox <T>(T);impl <T> Deref for MyBox <T> { type Target = T; fn deref (&self ) -> &T { &self .0 } } fn hello (name: &str ) { println! ("Hello, {}" , name); } fn main () { let s = MyBox (String ::from ("world" )); hello (&s); hello (&(*s)[..]); }
类型转换总结 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ┌─────────────────────────────────────────────────────────────────────┐ │ 类型转换方式对比 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ 方式 成本 安全性 用途 │ │ ────────────────────────────────────────────────────────────── │ │ as 零/低 不安全 原始类型转换、指针转换 │ │ From/Into 可变 安全 值类型转换(不会失败) │ │ TryFrom/Into 可变 安全 可能失败的转换 │ │ AsRef/AsMut 零 安全 引用借用 │ │ Borrow 零 安全 集合键查找 │ │ Deref 零 安全 智能指针透明访问 │ │ │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ 转换关系链: │ │ │ │ From<T> ──自动实现──> Into<T> │ │ TryFrom<T> ──自动实现──> TryInto<T> │ │ Deref ──启用──> 自动解引用强制转换 │ │ │ └─────────────────────────────────────────────────────────────────────┘
进阶模式 类型状态模式(Typestate Pattern) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 use std::marker::PhantomData;struct Locked ;struct Unlocked ;struct Door <State> { _state: PhantomData<State>, } impl Door <Locked> { fn unlock (self ) -> Door<Unlocked> { println! ("Unlocking..." ); Door { _state: PhantomData } } } impl Door <Unlocked> { fn lock (self ) -> Door<Locked> { println! ("Locking..." ); Door { _state: PhantomData } } fn open (&self ) { println! ("Opening door" ); } } fn new_door () -> Door<Locked> { Door { _state: PhantomData } } fn main () { let door = new_door (); let door = door.unlock (); door.open (); let door = door.lock (); }
透明 Newtype 1 2 3 4 5 6 7 8 9 10 11 12 13 #[repr(transparent)] struct Wrapper (u32 );impl Wrapper { fn from_ref (r: &u32 ) -> &Wrapper { unsafe { &*(r as *const u32 as *const Wrapper) } } fn from_slice (s: &[u32 ]) -> &[Wrapper] { unsafe { std::mem::transmute (s) } } }
不可构造类型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 enum Void {}fn diverge () -> Void { loop {} } fn always_works () -> Result <i32 , Void> { Ok (42 ) } fn main () { let v = always_works ().unwrap_or_else (|void| match void {}); }
全局变量 核心概念对比 1 2 3 4 5 6 7 8 9 10 11 12 13 ┌─────────────────────────────────────────────────────────────────────┐ │ Rust 全局变量方案 │ ├──────────────┬──────────────┬───────────────┬──────────────────────┤ │ 方案 │ 可变性 │ 初始化时机 │ 线程安全 │ ├──────────────┼──────────────┼───────────────┼──────────────────────┤ │ const │ 不可变 │ 编译期 │ ✓ │ │ static │ 不可变 │ 编译期 │ ✓ │ │ static mut │ 可变 │ 编译期 │ ✗ (unsafe) │ │ lazy_static! │ 不可变* │ 首次访问 │ ✓ │ │ OnceLock │ 不可变* │ 首次访问 │ ✓ (std 1.70+) │ │ Mutex/RwLock │ 可变 │ 首次访问 │ ✓ │ └──────────────┴──────────────┴───────────────┴──────────────────────┘ * 内部可变性除外
基础:const vs static 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 const MAX_SIZE: usize = 1024 ;const PI: f64 = 3.14159265359 ;const GREETING: &str = "Hello, Rust!" ;static VERSION: &str = "1.0.0" ;static COUNTER_INIT: i32 = 0 ;fn main () { println! ("Max: {}" , MAX_SIZE); let ver_ptr : &'static str = VERSION; println! ("Version at {:p}" , ver_ptr); }
选择原则 :
简单标量/字符串 → 优先用 const
需要固定地址或大型数据 → 用 static
可变全局变量(危险区域) static mut(不推荐) 1 2 3 4 5 6 7 8 9 static mut COUNTER: i32 = 0 ;fn main () { unsafe { COUNTER += 1 ; println! ("Counter: {}" , COUNTER); } }
安全的运行时初始化方案 std::sync::OnceLock Rust 1.70+ 推荐:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 use std::sync::OnceLock;static CONFIG: OnceLock<Config> = OnceLock::new ();struct Config { db_url: String , max_conn: u32 , } fn get_config () -> &'static Config { CONFIG.get_or_init (|| { Config { db_url: std::env::var ("DB_URL" ).unwrap_or_default (), max_conn: 100 , } }) } fn main () { println! ("DB: {}" , get_config ().db_url); println! ("Max: {}" , get_config ().max_conn); }
lazy_static! 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 use lazy_static::lazy_static;use std::collections::HashMap;lazy_static! { static ref CACHE: HashMap<&'static str , i32 > = { let mut m = HashMap::new (); m.insert ("one" , 1 ); m.insert ("two" , 2 ); m }; static ref REGEX: regex::Regex = regex::Regex::new (r"^\d{4}-\d{2}-\d{2}$" ).unwrap (); } fn main () { println! ("one = {}" , CACHE.get ("one" ).unwrap ()); println! ("Valid: {}" , REGEX.is_match ("2024-01-15" )); }
once_cell 1 2 3 4 5 6 7 8 9 10 11 12 13 14 use once_cell::sync::Lazy;static LOGGER: Lazy<Logger> = Lazy::new (|| { Logger::new ("app.log" ) }); fn expensive_computation () -> &'static Vec <i32 > { static RESULT: Lazy<Vec <i32 >> = Lazy::new (|| { (0 ..1000000 ).collect () }); &RESULT }
线程安全的可变全局变量 Mutex 方案 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 use std::sync::Mutex;use std::sync::OnceLock;static GLOBAL_STATE: OnceLock<Mutex<AppState>> = OnceLock::new ();struct AppState { count: u64 , name: String , } fn state () -> &'static Mutex<AppState> { GLOBAL_STATE.get_or_init (|| { Mutex::new (AppState { count: 0 , name: String ::from ("App" ), }) }) } fn main () { { let mut s = state ().lock ().unwrap (); s.count += 1 ; s.name = String ::from ("Updated" ); } println! ("Count: {}" , state ().lock ().unwrap ().count); }
RwLock 读多写少场景。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 use std::sync::RwLock;use once_cell::sync::Lazy;static SETTINGS: Lazy<RwLock<Settings>> = Lazy::new (|| { RwLock::new (Settings::default ()) }); #[derive(Default)] struct Settings { debug: bool , level: u8 , } fn main () { let debug = SETTINGS.read ().unwrap ().debug; SETTINGS.write ().unwrap ().level = 5 ; }
原子类型 1 2 3 4 5 6 7 8 9 10 11 12 13 use std::sync::atomic::{AtomicU64, Ordering};static REQUEST_COUNT: AtomicU64 = AtomicU64::new (0 );fn handle_request () { REQUEST_COUNT.fetch_add (1 , Ordering::Relaxed); } fn main () { handle_request (); handle_request (); println! ("Total requests: {}" , REQUEST_COUNT.load (Ordering::Relaxed)); }
方案选择流程图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 需要全局变量? │ ├── 编译期已知值? │ ├── 是 → const(简单值)或 static(需要地址) │ └── 否 ↓ │ ├── 运行时初始化,只读? │ └── OnceLock / Lazy / lazy_static! │ ├── 需要可变? │ ├── 简单整数 → AtomicXxx │ ├── 读多写少 → RwLock<T> │ └── 一般情况 → Mutex<T> │ └── 避免全局变量? └── 依赖注入 / 传参(最佳实践)
⚠️ 黄金法则 :尽量避免全局可变状态,优先使用依赖注入传递配置和状态。全局变量会增加代码耦合度和测试难度。
多线程 核心概念总览 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ┌─────────────────────────────────────────────────────────────────────────┐ │ Rust 并发安全保证 │ ├─────────────────────────────────────────────────────────────────────────┤ │ 编译期检查: Send + Sync trait → 消除数据竞争 │ │ 运行时保护: Mutex / RwLock / Atomic → 安全共享可变状态 │ │ 所有权转移: move 闭包 → 明确数据归属 │ └─────────────────────────────────────────────────────────────────────────┘ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │ 消息传递 │ │ 共享状态 │ │ 原子操作 │ │ (Channel) │ │ (Mutex/Arc) │ │ (Atomic*) │ ├──────────────┤ ├──────────────┤ ├──────────────┤ │ 无共享,安全 │ │ 锁保护,灵活 │ │ 无锁,高性能 │ │ 适合流水线 │ │ 适合复杂状态 │ │ 适合简单计数 │ └──────────────┘ └──────────────┘ └──────────────┘
线程基础 创建与等待 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 use std::thread;use std::time::Duration;fn main () { let handle = thread::spawn (|| { for i in 1 ..5 { println! ("子线程: {}" , i); thread::sleep (Duration::from_millis (100 )); } 42 }); for i in 1 ..3 { println! ("主线程: {}" , i); thread::sleep (Duration::from_millis (150 )); } let result = handle.join ().unwrap (); println! ("子线程返回: {}" , result); }
move 闭包 —— 转移所有权 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 use std::thread;fn main () { let data = vec! [1 , 2 , 3 ]; let handle = thread::spawn (move || { println! ("{:?}" , data); }); handle.join ().unwrap (); }
线程配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 use std::thread;fn main () { let builder = thread::Builder::new () .name ("worker-1" .into ()) .stack_size (4 * 1024 * 1024 ); let handle = builder.spawn (|| { println! ("线程名: {:?}" , thread::current ().name ()); println! ("线程ID: {:?}" , thread::current ().id ()); }).unwrap (); handle.join ().unwrap (); println! ("CPU 核心数: {}" , thread::available_parallelism ().unwrap ()); }
消息传递(Channel) 多生产者单消费者(mpsc) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 use std::sync::mpsc;use std::thread;fn main () { let (tx, rx) = mpsc::channel (); thread::spawn (move || { let messages = vec! ["hello" , "from" , "thread" ]; for msg in messages { tx.send (msg).unwrap (); thread::sleep (std::time::Duration::from_millis (100 )); } }); for received in rx { println! ("收到: {}" , received); } }
多生产者 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 use std::sync::mpsc;use std::thread;fn main () { let (tx, rx) = mpsc::channel (); for id in 0 ..3 { let tx_clone = tx.clone (); thread::spawn (move || { tx_clone.send (format! ("来自线程 {}" , id)).unwrap (); }); } drop (tx); for msg in rx { println! ("{}" , msg); } }
同步通道(有界) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 use std::sync::mpsc;use std::thread;fn main () { let (tx, rx) = mpsc::sync_channel (2 ); thread::spawn (move || { for i in 0 ..5 { println! ("发送 {}" , i); tx.send (i).unwrap (); println! ("已发送 {}" , i); } }); thread::sleep (std::time::Duration::from_secs (1 )); for val in rx { println! ("收到: {}" , val); } }
Channel 方法对比 1 2 3 4 5 6 7 8 9 10 ┌─────────────┬─────────────────────────────────────────────┐ │ 方法 │ 行为 │ ├─────────────┼─────────────────────────────────────────────┤ │ send() │ 发送,通道关闭返回 Err │ │ recv() │ 阻塞接收,通道关闭返回 Err │ │ try_recv() │ 非阻塞,无数据返回 Err(TryRecvError::Empty) │ │ recv_timeout() │ 超时接收 │ │ iter() │ 阻塞迭代器,通道关闭结束 │ │ try_iter() │ 非阻塞迭代器 │ └─────────────┴─────────────────────────────────────────────┘
共享状态 Arc + Mutex 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 use std::sync::{Arc, Mutex};use std::thread;fn main () { let counter = Arc::new (Mutex::new (0 )); let mut handles = vec! []; for _ in 0 ..10 { let counter = Arc::clone (&counter); let handle = thread::spawn (move || { let mut num = counter.lock ().unwrap (); *num += 1 ; }); handles.push (handle); } for handle in handles { handle.join ().unwrap (); } println! ("结果: {}" , *counter.lock ().unwrap ()); }
RwLock 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 use std::sync::{Arc, RwLock};use std::thread;fn main () { let data = Arc::new (RwLock::new (vec! [1 , 2 , 3 ])); let mut handles = vec! []; for i in 0 ..3 { let data = Arc::clone (&data); handles.push (thread::spawn (move || { let read_guard = data.read ().unwrap (); println! ("读者 {}: {:?}" , i, *read_guard); })); } { let data = Arc::clone (&data); handles.push (thread::spawn (move || { let mut write_guard = data.write ().unwrap (); write_guard.push (4 ); println! ("写者: 已添加 4" ); })); } for h in handles { h.join ().unwrap (); } }
锁的注意事项 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 use std::sync::{Arc, Mutex};fn main () { let data = Arc::new (Mutex::new (5 )); { let mut guard = data.lock ().unwrap (); *guard += 1 ; } let result = data.lock (); match result { Ok (guard) => println! ("值: {}" , *guard), Err (poisoned) => { let guard = poisoned.into_inner (); println! ("恢复中毒锁,值: {}" , *guard); } } }
原子操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 use std::sync::atomic::{AtomicUsize, AtomicBool, Ordering};use std::thread;use std::sync::Arc;fn main () { let counter = Arc::new (AtomicUsize::new (0 )); let running = Arc::new (AtomicBool::new (true )); let mut handles = vec! []; for _ in 0 ..4 { let counter = Arc::clone (&counter); let running = Arc::clone (&running); handles.push (thread::spawn (move || { while running.load (Ordering::Relaxed) { counter.fetch_add (1 , Ordering::SeqCst); if counter.load (Ordering::SeqCst) >= 100 { running.store (false , Ordering::Relaxed); } } })); } for h in handles { h.join ().unwrap (); } println! ("最终计数: {}" , counter.load (Ordering::SeqCst)); }
Ordering 说明 1 2 3 4 5 6 7 8 9 ┌──────────────┬────────────────────────────────────────────┐ │ Ordering │ 语义 │ ├──────────────┼────────────────────────────────────────────┤ │ Relaxed │ 最弱,仅保证原子性,不保证顺序 │ │ Acquire │ 读操作,阻止后续操作重排到此之前 │ │ Release │ 写操作,阻止之前操作重排到此之后 │ │ AcqRel │ 同时 Acquire + Release │ │ SeqCst │ 最强,全局顺序一致(默认安全选择) │ └──────────────┴────────────────────────────────────────────┘
同步原语 Barrier(屏障) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 use std::sync::{Arc, Barrier};use std::thread;fn main () { let barrier = Arc::new (Barrier::new (3 )); let mut handles = vec! []; for i in 0 ..3 { let barrier = Arc::clone (&barrier); handles.push (thread::spawn (move || { println! ("线程 {} 阶段1完成" , i); barrier.wait (); println! ("线程 {} 阶段2开始" , i); })); } for h in handles { h.join ().unwrap (); } }
Condvar(条件变量) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 use std::sync::{Arc, Mutex, Condvar};use std::thread;fn main () { let pair = Arc::new ((Mutex::new (false ), Condvar::new ())); let pair_clone = Arc::clone (&pair); let waiter = thread::spawn (move || { let (lock, cvar) = &*pair_clone; let mut ready = lock.lock ().unwrap (); while !*ready { ready = cvar.wait (ready).unwrap (); } println! ("收到通知,继续执行!" ); }); thread::sleep (std::time::Duration::from_secs (1 )); let (lock, cvar) = &*pair; { let mut ready = lock.lock ().unwrap (); *ready = true ; } cvar.notify_one (); waiter.join ().unwrap (); }
线程池(Rayon) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 use rayon::prelude::*;fn main () { let sum : i64 = (1 ..1_000_000i64 ) .into_par_iter () .filter (|&x| x % 2 == 0 ) .map (|x| x * x) .sum (); println! ("平方和: {}" , sum); let mut data : Vec <i32 > = (0 ..100000 ).rev ().collect (); data.par_sort (); let (a, b) = rayon::join ( || expensive_computation_a (), || expensive_computation_b (), ); } fn expensive_computation_a () -> i32 { 1 }fn expensive_computation_b () -> i32 { 2 }
Send 和 Sync 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 use std::rc::Rc;use std::sync::Arc;use std::cell::RefCell;use std::thread;fn main () { let arc = Arc::new (5 ); thread::spawn (move || println! ("{}" , arc)).join ().unwrap (); }
常见模式 生产者-消费者 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 use std::sync::mpsc;use std::thread;fn main () { let (tx, rx) = mpsc::channel (); for i in 0 ..3 { let tx = tx.clone (); thread::spawn (move || { for j in 0 ..3 { tx.send ((i, j)).unwrap (); } }); } drop (tx); while let Ok ((producer, item)) = rx.recv () { println! ("生产者 {} 产出 {}" , producer, item); } }
工作窃取模式(crossbeam) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 use crossbeam::channel;use std::thread;fn main () { let (tx, rx) = channel::unbounded (); for i in 0 ..10 { tx.send (i).unwrap (); } drop (tx); let handles : Vec <_> = (0 ..4 ).map (|id| { let rx = rx.clone (); thread::spawn (move || { while let Ok (task) = rx.recv () { println! ("Worker {} 处理任务 {}" , id, task); } }) }).collect (); for h in handles { h.join ().unwrap (); } }
总结对比 1 2 3 4 5 6 7 8 9 10 11 ┌────────────────┬─────────────────┬─────────────────┬─────────────────┐ │ 方案 │ 适用场景 │ 性能 │ 复杂度 │ ├────────────────┼─────────────────┼─────────────────┼─────────────────┤ │ thread::spawn │ 少量长期任务 │ 中等 │ 低 │ │ mpsc::channel │ 生产者-消费者 │ 中等 │ 低 │ │ Arc<Mutex<T>> │ 共享可变状态 │ 中等 │ 中 │ │ Arc<RwLock<T>> │ 读多写少 │ 较高 │ 中 │ │ Atomic* │ 简单计数/标志 │ 高 │ 中 │ │ Rayon │ 数据并行 │ 高 │ 低 │ │ crossbeam │ 复杂并发 │ 高 │ 中 │ └────────────────┴─────────────────┴─────────────────┴─────────────────┘
黄金法则 :优先消息传递,必要时再用共享状态;优先用高级抽象(Rayon),避免手动管理线程。
多进程 核心概念总览 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ┌─────────────────────────────────────────────────────────────────────────┐ │ Rust 多进程体系 │ ├─────────────────────────────────────────────────────────────────────────┤ │ std::process::Command → 创建和管理子进程 │ │ std::process::Child → 子进程句柄 │ │ std::process::Stdio → 标准输入/输出/错误配置 │ └─────────────────────────────────────────────────────────────────────────┘ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │ 管道 │ │ 共享内存 │ │ Socket/文件 │ │ (Pipe) │ │ (SharedMem) │ │ (IPC) │ ├──────────────┤ ├──────────────┤ ├──────────────┤ │ 父子进程通信 │ │ 高性能数据 │ │ 任意进程通信 │ │ 简单易用 │ │ 交换 │ │ 灵活通用 │ └──────────────┘ └──────────────┘ └──────────────┘
创建子进程 简单执行命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 use std::process::Command;fn main () { let status = Command::new ("echo" ) .arg ("Hello, Rust!" ) .status () .expect ("执行失败" ); println! ("退出状态: {}" , status); println! ("成功: {}" , status.success ()); if let Some (code) = status.code () { println! ("退出码: {}" , code); } }
获取输出 1 2 3 4 5 6 7 8 9 10 11 12 13 14 use std::process::Command;fn main () { let output = Command::new ("ls" ) .arg ("-la" ) .arg ("/tmp" ) .output () .expect ("执行失败" ); println! ("状态: {}" , output.status); println! ("stdout:\n{}" , String ::from_utf8_lossy (&output.stdout)); println! ("stderr:\n{}" , String ::from_utf8_lossy (&output.stderr)); }
命令构建详解 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 use std::process::Command;use std::collections::HashMap;use std::path::Path;fn main () { let mut cmd = Command::new ("python3" ); cmd.arg ("-c" ) .arg ("import os; print(os.getcwd())" ) .args (["-v" , "--version" ]); cmd.env ("MY_VAR" , "my_value" ) .env ("PATH" , "/usr/bin:/bin" ) .env_clear () .envs ([("KEY1" , "VAL1" ), ("KEY2" , "VAL2" )]); cmd.current_dir ("/tmp" ); let output = cmd.output ().expect ("失败" ); println! ("{}" , String ::from_utf8_lossy (&output.stdout)); }
Stdio 控制 重定向配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 use std::process::{Command, Stdio};use std::fs::File;fn main () { let status = Command::new ("ls" ) .stdout (Stdio::null ()) .stderr (Stdio::null ()) .status () .unwrap (); let file = File::create ("/tmp/output.txt" ).unwrap (); let status = Command::new ("echo" ) .arg ("写入文件" ) .stdout (Stdio::from (file)) .status () .unwrap (); let input_file = File::open ("/etc/hosts" ).unwrap (); let output = Command::new ("head" ) .arg ("-n5" ) .stdin (Stdio::from (input_file)) .output () .unwrap (); println! ("{}" , String ::from_utf8_lossy (&output.stdout)); }
管道通信 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 use std::process::{Command, Stdio};use std::io::{Write, BufRead, BufReader};fn main () { let mut child = Command::new ("cat" ) .stdin (Stdio::piped ()) .stdout (Stdio::piped ()) .spawn () .expect ("启动失败" ); let mut stdin = child.stdin.take ().expect ("获取 stdin 失败" ); std::thread::spawn (move || { stdin.write_all (b"Hello\nWorld\n" ).unwrap (); }); let stdout = child.stdout.take ().expect ("获取 stdout 失败" ); let reader = BufReader::new (stdout); for line in reader.lines () { println! ("收到: {}" , line.unwrap ()); } let status = child.wait ().unwrap (); println! ("子进程退出: {}" , status); }
进程管道链 命令管道(类似 shell |) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 use std::process::{Command, Stdio};fn main () { let ls = Command::new ("ls" ) .arg ("-la" ) .stdout (Stdio::piped ()) .spawn () .unwrap (); let grep = Command::new ("grep" ) .arg (".rs" ) .stdin (Stdio::from (ls.stdout.unwrap ())) .stdout (Stdio::piped ()) .spawn () .unwrap (); let head = Command::new ("head" ) .arg ("-5" ) .stdin (Stdio::from (grep.stdout.unwrap ())) .output () .unwrap (); println! ("{}" , String ::from_utf8_lossy (&head.stdout)); }
封装管道函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 use std::process::{Command, Stdio, Child};use std::io::Result ;fn pipe_commands (commands: Vec <Vec <&str >>) -> Result <String > { let mut prev_stdout : Option <std::process::ChildStdout> = None ; let mut children : Vec <Child> = Vec ::new (); for (i, cmd_args) in commands.iter ().enumerate () { let (cmd, args) = cmd_args.split_first ().unwrap (); let mut command = Command::new (cmd); command.args (args); if let Some (stdout) = prev_stdout.take () { command.stdin (Stdio::from (stdout)); } if i < commands.len () - 1 { command.stdout (Stdio::piped ()); } let child = command.spawn ()?; prev_stdout = child.stdout; children.push (child); } let mut final_output = String ::new (); if let Some (last) = children.last_mut () { let output = last.wait_with_output ()?; final_output = String ::from_utf8_lossy (&output.stdout).to_string (); } Ok (final_output) } fn main () { let result = pipe_commands (vec! [ vec! ["echo" , "hello\nworld\nrust" ], vec! ["grep" , "o" ], vec! ["wc" , "-l" ], ]).unwrap (); println! ("结果: {}" , result.trim ()); }
子进程管理 Child 句柄操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 use std::process::{Command, Stdio};use std::time::Duration;use std::thread;fn main () { let mut child = Command::new ("sleep" ) .arg ("10" ) .spawn () .expect ("启动失败" ); println! ("子进程 PID: {}" , child.id ()); match child.try_wait () { Ok (Some (status)) => println! ("已退出: {}" , status), Ok (None ) => println! ("仍在运行" ), Err (e) => println! ("错误: {}" , e), } thread::sleep (Duration::from_secs (2 )); child.kill ().expect ("终止失败" ); println! ("已发送 SIGKILL" ); let status = child.wait ().expect ("等待失败" ); println! ("最终状态: {}" , status); }
超时执行 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 use std::process::Command;use std::time::{Duration, Instant};use std::thread;fn run_with_timeout (cmd: &str , args: &[&str ], timeout: Duration) -> Result <String , String > { let mut child = Command::new (cmd) .args (args) .stdout (std::process::Stdio::piped ()) .stderr (std::process::Stdio::piped ()) .spawn () .map_err (|e| e.to_string ())?; let start = Instant::now (); loop { match child.try_wait () { Ok (Some (status)) => { let output = child.wait_with_output ().unwrap (); if status.success () { return Ok (String ::from_utf8_lossy (&output.stdout).to_string ()); } else { return Err (String ::from_utf8_lossy (&output.stderr).to_string ()); } } Ok (None ) => { if start.elapsed () > timeout { child.kill ().ok (); child.wait ().ok (); return Err ("执行超时" .to_string ()); } thread::sleep (Duration::from_millis (100 )); } Err (e) => return Err (e.to_string ()), } } } fn main () { match run_with_timeout ("sleep" , &["5" ], Duration::from_secs (2 )) { Ok (output) => println! ("输出: {}" , output), Err (e) => println! ("错误: {}" , e), } }
进程间通信(IPC) 匿名管道(父子进程) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 use std::process::{Command, Stdio};use std::io::{BufRead, BufReader, Write};fn main () { let mut child = Command::new ("sh" ) .arg ("-c" ) .arg ("read line; echo \"子进程收到: $line\"" ) .stdin (Stdio::piped ()) .stdout (Stdio::piped ()) .spawn () .unwrap (); if let Some (ref mut stdin) = child.stdin { writeln! (stdin, "Hello from parent" ).unwrap (); } child.stdin.take (); if let Some (stdout) = child.stdout.take () { for line in BufReader::new (stdout).lines () { println! ("父进程收到: {}" , line.unwrap ()); } } child.wait ().unwrap (); }
命名管道(FIFO)- Unix 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #[cfg(unix)] mod unix_fifo { use std::fs::{File, OpenOptions}; use std::io::{Read, Write}; use std::os::unix::fs::OpenOptionsExt; use std::process::Command; pub fn demo () { let fifo_path = "/tmp/my_fifo" ; Command::new ("mkfifo" ) .arg (fifo_path) .status () .ok (); let writer = std::thread::spawn (move || { let mut file = OpenOptions::new () .write (true ) .open (fifo_path) .unwrap (); file.write_all (b"Hello via FIFO" ).unwrap (); }); let reader = std::thread::spawn (move || { let mut file = File::open (fifo_path).unwrap (); let mut buf = String ::new (); file.read_to_string (&mut buf).unwrap (); println! ("读取: {}" , buf); }); writer.join ().unwrap (); reader.join ().unwrap (); std::fs::remove_file (fifo_path).ok (); } }
共享内存 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 use shared_memory::*;fn main () -> Result <(), Box <dyn std::error::Error>> { let shmem_name = "my_shared_mem" ; let shmem = ShmemConf::new () .size (4096 ) .os_id (shmem_name) .create ()?; unsafe { let ptr = shmem.as_ptr (); std::ptr::copy_nonoverlapping ( b"Hello Shared Memory" .as_ptr (), ptr, 20 ); } println! ("共享内存已创建,其他进程可通过 '{}' 访问" , shmem_name); Ok (()) }
Unix Domain Socket 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #[cfg(unix)] mod unix_socket { use std::os::unix::net::{UnixListener, UnixStream}; use std::io::{Read, Write}; use std::thread; pub fn demo () { let socket_path = "/tmp/my_socket.sock" ; std::fs::remove_file (socket_path).ok (); let server = thread::spawn (move || { let listener = UnixListener::bind (socket_path).unwrap (); println! ("服务端监听中..." ); for stream in listener.incoming () { match stream { Ok (mut stream) => { let mut buf = [0u8 ; 1024 ]; let n = stream.read (&mut buf).unwrap (); println! ("服务端收到: {}" , String ::from_utf8_lossy (&buf[..n])); stream.write_all (b"Hello from server" ).unwrap (); break ; } Err (e) => eprintln!("错误: {}" , e), } } }); thread::sleep (std::time::Duration::from_millis (100 )); let client = thread::spawn (move || { let mut stream = UnixStream::connect (socket_path).unwrap (); stream.write_all (b"Hello from client" ).unwrap (); let mut buf = [0u8 ; 1024 ]; let n = stream.read (&mut buf).unwrap (); println! ("客户端收到: {}" , String ::from_utf8_lossy (&buf[..n])); }); server.join ().unwrap (); client.join ().unwrap (); std::fs::remove_file (socket_path).ok (); } }
IPC 方案对比 1 2 3 4 5 6 7 8 9 10 11 ┌─────────────────┬──────────────┬──────────────┬────────────────────────┐ │ 方案 │ 性能 │ 使用范围 │ 特点 │ ├─────────────────┼──────────────┼──────────────┼────────────────────────┤ │ 匿名管道 │ 高 │ 父子进程 │ 简单,单向 │ │ 命名管道(FIFO) │ 高 │ 任意进程 │ 文件系统可见 │ │ Unix Socket │ 高 │ 同一主机 │ 双向,支持多连接 │ │ TCP Socket │ 中 │ 跨网络 │ 通用,开销较大 │ │ 共享内存 │ 最高 │ 同一主机 │ 需要同步机制 │ │ 内存映射文件 │ 高 │ 同一主机 │ 持久化,大数据 │ │ 消息队列 │ 中 │ 同一主机 │ 解耦,异步 │ └─────────────────┴──────────────┴──────────────┴────────────────────────┘
信号处理 使用 ctrlc 库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 use std::sync::atomic::{AtomicBool, Ordering};use std::sync::Arc;fn main () { let running = Arc::new (AtomicBool::new (true )); let r = running.clone (); ctrlc::set_handler (move || { println! ("\n收到 Ctrl+C,正在优雅退出..." ); r.store (false , Ordering::SeqCst); }).expect ("设置处理器失败" ); println! ("运行中... 按 Ctrl+C 退出" ); while running.load (Ordering::SeqCst) { std::thread::sleep (std::time::Duration::from_millis (100 )); } println! ("清理完成,退出" ); }
使用 signal-hook 库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 use signal_hook::{consts::*, iterator::Signals};use std::thread;fn main () { let mut signals = Signals::new (&[ SIGTERM, SIGINT, SIGHUP, SIGQUIT, ]).unwrap (); thread::spawn (move || { for sig in signals.forever () { match sig { SIGTERM | SIGINT => { println! ("收到终止信号,退出" ); std::process::exit (0 ); } SIGHUP => { println! ("收到 SIGHUP,重新加载配置" ); } _ => unreachable! (), } } }); loop { println! ("工作中..." ); thread::sleep (std::time::Duration::from_secs (1 )); } }
发送信号给子进程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #[cfg(unix)] fn send_signal_demo () { use std::process::Command; use nix::sys::signal::{self , Signal}; use nix::unistd::Pid; let child = Command::new ("sleep" ) .arg ("100" ) .spawn () .unwrap (); let pid = Pid::from_raw (child.id () as i32 ); signal::kill (pid, Signal::SIGTERM).unwrap (); println! ("已发送 SIGTERM 给 PID {}" , child.id ()); }
守护进程 使用 daemonize 库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #[cfg(unix)] fn daemonize_demo () { use daemonize::Daemonize; use std::fs::File; let stdout = File::create ("/tmp/daemon.out" ).unwrap (); let stderr = File::create ("/tmp/daemon.err" ).unwrap (); let daemonize = Daemonize::new () .pid_file ("/tmp/daemon.pid" ) .chown_pid_file (true ) .working_directory ("/tmp" ) .user ("nobody" ) .group ("daemon" ) .stdout (stdout) .stderr (stderr) .privileged_action (|| "执行特权操作" ); match daemonize.start () { Ok (_) => { println! ("守护进程启动成功" ); loop { std::thread::sleep (std::time::Duration::from_secs (10 )); } } Err (e) => eprintln!("守护进程启动失败: {}" , e), } }
进程池模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 use std::process::{Command, Child, Stdio};use std::collections::VecDeque;use std::io::Write;struct ProcessPool { workers: Vec <Child>, max_workers: usize , } impl ProcessPool { fn new (max_workers: usize ) -> Self { Self { workers: Vec ::new (), max_workers, } } fn spawn_worker (&mut self , task: &str ) -> std::io::Result <()> { self .workers.retain_mut (|child| { match child.try_wait () { Ok (Some (_)) => false , _ => true , } }); while self .workers.len () >= self .max_workers { std::thread::sleep (std::time::Duration::from_millis (100 )); self .workers.retain_mut (|child| { child.try_wait ().map (|s| s.is_none ()).unwrap_or (true ) }); } let child = Command::new ("sh" ) .arg ("-c" ) .arg (task) .spawn ()?; self .workers.push (child); Ok (()) } fn wait_all (&mut self ) { for child in &mut self .workers { child.wait ().ok (); } self .workers.clear (); } } fn main () { let mut pool = ProcessPool::new (4 ); for i in 0 ..10 { let task = format! ("echo '任务 {}'; sleep 1" , i); pool.spawn_worker (&task).unwrap (); println! ("提交任务 {}" , i); } pool.wait_all (); println! ("所有任务完成" ); }
实用工具函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 use std::process::{Command, Output, ExitStatus};use std::io::{Result , Error, ErrorKind};pub fn exec (cmd: &str ) -> Result <String > { let output = if cfg! (target_os = "windows" ) { Command::new ("cmd" ).args (["/C" , cmd]).output ()? } else { Command::new ("sh" ).args (["-c" , cmd]).output ()? }; if output.status.success () { Ok (String ::from_utf8_lossy (&output.stdout).trim ().to_string ()) } else { Err (Error::new ( ErrorKind::Other, String ::from_utf8_lossy (&output.stderr).to_string () )) } } pub fn command_exists (cmd: &str ) -> bool { Command::new ("which" ) .arg (cmd) .stdout (Stdio::null ()) .stderr (Stdio::null ()) .status () .map (|s| s.success ()) .unwrap_or (false ) } pub fn process_info () { println! ("PID: {}" , std::process::id ()); println! ("当前目录: {:?}" , std::env::current_dir ().unwrap ()); println! ("可执行文件: {:?}" , std::env::current_exe ().unwrap ()); println! ("参数: {:?}" , std::env::args ().collect::<Vec <_>>()); } fn main () { match exec ("uname -a" ) { Ok (output) => println! ("系统信息: {}" , output), Err (e) => eprintln!("错误: {}" , e), } println! ("git 存在: {}" , command_exists ("git" )); process_info (); }
总结对比 1 2 3 4 5 6 7 8 9 10 11 12 13 ┌─────────────────────────────────────────────────────────────────────────┐ │ 多线程 vs 多进程 选择指南 │ ├─────────────────┬───────────────────────┬───────────────────────────────┤ │ 维度 │ 多线程 │ 多进程 │ ├─────────────────┼───────────────────────┼───────────────────────────────┤ │ 内存共享 │ 直接共享 │ 需要 IPC │ │ 创建开销 │ 小 │ 大 │ │ 通信开销 │ 小 │ 大 │ │ 隔离性 │ 弱(崩溃影响整体) │ 强(独立地址空间) │ │ 调试难度 │ 高(竞态条件) │ 中 │ │ 适用场景 │ CPU 密集、共享状态 │ 隔离执行、调用外部程序 │ │ Rust 安全性 │ 编译期保证 │ 运行时 │ └─────────────────┴───────────────────────┴───────────────────────────────┘
推荐库
用途
库
基础进程
std::process
Unix 系统调用
nix
信号处理
signal-hook, ctrlc
共享内存
shared_memory
守护进程
daemonize
跨平台 IPC
ipc-channel
选择原则 :优先使用多线程处理 CPU 密集任务;需要隔离、调用外部程序、或利用多核避免 GIL(其他语言)时使用多进程。
异步编程 核心概念总览 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ┌─────────────────────────────────────────────────────────────────┐ │ Rust 异步编程架构 │ ├─────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────────────┐ │ │ │ async/await │ ← 语法糖(语言内置) │ │ └────────┬────────┘ │ │ │ │ │ ┌────────▼────────┐ │ │ │ Future Trait │ ← 核心抽象(标准库) │ │ └────────┬────────┘ │ │ │ │ │ ┌────────▼────────┐ │ │ │ Runtime │ ← 执行引擎(第三方:tokio/async-std) │ │ │ (Executor + │ │ │ │ Reactor) │ │ │ └─────────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────┘
关键点:Rust 只提供语法和抽象,不提供运行时!
标准库内置支持 Future Trait(核心) 1 2 3 4 5 6 7 8 9 10 11 pub trait Future { type Output ; fn poll (self : Pin<&mut Self >, cx: &mut Context<'_ >) -> Poll<Self ::Output>; } pub enum Poll <T> { Ready (T), Pending, }
async/await 语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 async fn fetch_data () -> String { let response = make_request ().await ; response.body } fn fetch_data () -> impl Future <Output = String > { async { let response = make_request ().await ; response.body } }
惰性执行特性 1 2 3 4 5 6 7 8 async fn hello () { println! ("Hello!" ); } fn main () { let future = hello (); }
为什么需要 Runtime 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ┌────────────────────────────────────────────────────────────┐ │ 异步运行时职责 │ ├────────────────────────────────────────────────────────────┤ │ │ │ ┌──────────────┐ ┌──────────────┐ │ │ │ Executor │ │ Reactor │ │ │ │ (执行器) │ │ (反应器) │ │ │ ├──────────────┤ ├──────────────┤ │ │ │ • 调度任务 │ │ • I/O 事件 │ │ │ │ • 调用 poll │ │ 监听 │ │ │ │ • 任务切换 │ │ • 唤醒任务 │ │ │ └──────────────┘ └──────────────┘ │ │ │ │ │ │ └───────┬───────────┘ │ │ ▼ │ │ ┌────────────────┐ │ │ │ 异步任务队列 │ │ │ └────────────────┘ │ │ │ └────────────────────────────────────────────────────────────┘
Tokio 详解 基础设置 1 2 3 4 5 [dependencies] tokio = { version = "1" , features = ["full" ] }
入口点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #[tokio::main] async fn main () { println! ("Hello from tokio!" ); } fn main () { let rt = tokio::runtime::Runtime::new ().unwrap (); rt.block_on (async { println! ("Hello from tokio!" ); }); } #[tokio::main(flavor = "current_thread" )] async fn main () { }
任务生成 (spawn) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 use tokio::task;#[tokio::main] async fn main () { let handle1 = task::spawn (async { expensive_computation ().await }); let handle2 = task::spawn (async { fetch_from_network ().await }); let (result1, result2) = tokio::join!(handle1, handle2); println! ("Results: {:?}, {:?}" , result1, result2); }
核心异步原语 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 use tokio::time::{sleep, timeout, Duration};use tokio::sync::{mpsc, Mutex, RwLock, oneshot};async fn time_examples () { sleep (Duration::from_secs (1 )).await ; let result = timeout (Duration::from_secs (5 ), slow_operation ()).await ; match result { Ok (value) => println! ("完成: {}" , value), Err (_) => println! ("超时!" ), } } async fn channel_example () { let (tx, mut rx) = mpsc::channel::<String >(100 ); tokio::spawn (async move { tx.send ("Hello" .to_string ()).await .unwrap (); }); while let Some (msg) = rx.recv ().await { println! ("收到: {}" , msg); } let (tx, rx) = oneshot::channel::<i32 >(); tx.send (42 ).unwrap (); let value = rx.await .unwrap (); } async fn lock_example () { let data = Mutex::new (vec! [1 , 2 , 3 ]); { let mut guard = data.lock ().await ; guard.push (4 ); } }
异步 I/O 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 use tokio::net::{TcpListener, TcpStream};use tokio::io::{AsyncReadExt, AsyncWriteExt};async fn tcp_server () -> std::io::Result <()> { let listener = TcpListener::bind ("127.0.0.1:8080" ).await ?; loop { let (socket, addr) = listener.accept ().await ?; println! ("新连接: {}" , addr); tokio::spawn (async move { handle_connection (socket).await ; }); } } async fn handle_connection (mut socket: TcpStream) { let mut buffer = [0u8 ; 1024 ]; loop { let n = match socket.read (&mut buffer).await { Ok (0 ) => return , Ok (n) => n, Err (_) => return , }; socket.write_all (&buffer[..n]).await .unwrap (); } }
文件操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 use tokio::fs;use tokio::io::{AsyncBufReadExt, BufReader};async fn file_operations () -> std::io::Result <()> { let content = fs::read_to_string ("config.txt" ).await ?; fs::write ("output.txt" , "Hello, World!" ).await ?; let file = fs::File::open ("data.txt" ).await ?; let reader = BufReader::new (file); let mut lines = reader.lines (); while let Some (line) = lines.next_line ().await ? { println! ("{}" , line); } Ok (()) }
并发控制模式 并发 vs 顺序执行 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 async fn concurrent_operations () { let a = fetch_a ().await ; let b = fetch_b ().await ; let c = fetch_c ().await ; let (a, b, c) = tokio::join!( fetch_a (), fetch_b (), fetch_c () ); tokio::select! { result = fetch_a () => println! ("A 先完成: {:?}" , result), result = fetch_b () => println! ("B 先完成: {:?}" , result), } }
Select 用法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 use tokio::sync::mpsc;use tokio::time::{sleep, Duration};async fn select_example () { let (tx, mut rx) = mpsc::channel::<i32 >(10 ); loop { tokio::select! { Some (msg) = rx.recv () => { println! ("收到消息: {}" , msg); } _ = sleep (Duration::from_secs (1 )) => { println! ("心跳..." ); } _ = tokio::signal::ctrl_c () => { println! ("收到退出信号" ); break ; } } } }
常见陷阱 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 use std::sync::Mutex;async fn bad_lock (data: &Mutex<Vec <i32 >>) { let mut guard = data.lock ().unwrap (); some_async_fn ().await ; guard.push (1 ); } use tokio::sync::Mutex;async fn good_lock (data: &Mutex<Vec <i32 >>) { let mut guard = data.lock ().await ; guard.push (1 ); } async fn bad_blocking () { std::thread::sleep (Duration::from_secs (10 )); std::fs::read_to_string ("file.txt" ); } async fn good_async () { tokio::time::sleep (Duration::from_secs (10 )).await ; tokio::fs::read_to_string ("file.txt" ).await ; tokio::task::spawn_blocking (|| { heavy_cpu_computation () }).await ; } async fn forget_await () { let _ = async_operation (); async_operation ().await ; }
为什么异步编程需要 Lock 和 Mutex 核心原因图解 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 ┌─────────────────────────────────────────────────────────────────────┐ │ 为什么异步也需要锁? │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ 原因1: Tokio 默认是多线程运行时 │ │ ┌─────────────────────────────────────────────────────────┐ │ │ │ Thread 1 Thread 2 Thread 3 │ │ │ │ ┌───────┐ ┌───────┐ ┌───────┐ │ │ │ │ │Task A │ │Task B │ │Task C │ │ │ │ │ └───┬───┘ └───┬───┘ └───┬───┘ │ │ │ │ │ │ │ │ │ │ │ └────────────────┼────────────────┘ │ │ │ │ ▼ │ │ │ │ ┌────────────────┐ │ │ │ │ │ 共享数据 Vec │ ← 真正的并行访问! │ │ │ │ └────────────────┘ │ │ │ └─────────────────────────────────────────────────────────┘ │ │ │ │ 原因2: 即使单线程,await 点也会切换任务 │ │ ┌─────────────────────────────────────────────────────────┐ │ │ │ 时间线 ──────────────────────────────────────────────► │ │ │ │ │ │ │ │ Task A: [读取 x=5] ──await──────────────► [写入 x=6] │ │ │ │ ↓ │ │ │ │ Task B: [读取 x=5] [写入 x=10] │ │ │ │ │ │ │ │ 结果: x 最终是 6 还是 10?取决于执行顺序! │ │ │ └─────────────────────────────────────────────────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────┘
具体场景演示 场景1:多线程运行时
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 use std::sync::Arc;use tokio::task;#[tokio::main] async fn wrong_example () { let mut counter = 0 ; let handle1 = task::spawn (async { counter += 1 ; }); let handle2 = task::spawn (async { counter += 1 ; }); } use tokio::sync::Mutex;#[tokio::main] async fn correct_example () { let counter = Arc::new (Mutex::new (0 )); let counter1 = Arc::clone (&counter); let handle1 = task::spawn (async move { let mut guard = counter1.lock ().await ; *guard += 1 ; }); let counter2 = Arc::clone (&counter); let handle2 = task::spawn (async move { let mut guard = counter2.lock ().await ; *guard += 1 ; }); handle1.await .unwrap (); handle2.await .unwrap (); println! ("Counter: {}" , *counter.lock ().await ); }
场景2:单线程但有逻辑竞争
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 use std::cell::RefCell;use std::rc::Rc;#[tokio::main(flavor = "current_thread" )] async fn single_thread_problem () { let balance = Rc::new (RefCell::new (100 )); let b1 = Rc::clone (&balance); let withdraw1 = async move { let current = *b1.borrow (); tokio::time::sleep (tokio::time::Duration::from_millis (10 )).await ; if current >= 80 { *b1.borrow_mut () = current - 80 ; } }; let b2 = Rc::clone (&balance); let withdraw2 = async move { let current = *b2.borrow (); tokio::time::sleep (tokio::time::Duration::from_millis (5 )).await ; if current >= 80 { *b2.borrow_mut () = current - 80 ; } }; tokio::join!(withdraw1, withdraw2); }
关键概念区分 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ┌────────────────────────────────────────────────────────────────────┐ │ 两种不同的"竞争"问题 │ ├──────────────────────────┬─────────────────────────────────────────┤ │ Data Race │ Race Condition │ │ (数据竞争) │ (竞态条件) │ ├──────────────────────────┼─────────────────────────────────────────┤ │ • 多线程同时访问同一内存 │ • 操作的执行顺序不确定 │ │ • 至少一个是写操作 │ • 导致逻辑结果不正确 │ │ • 没有同步机制 │ • 单线程也可能发生 │ ├──────────────────────────┼─────────────────────────────────────────┤ │ Rust 编译器完全阻止 ✅ │ Rust 编译器无法检测 ⚠️ │ ├──────────────────────────┼─────────────────────────────────────────┤ │ 需要:Mutex, RwLock │ 需要:Mutex + 正确的锁粒度 │ └──────────────────────────┴─────────────────────────────────────────┘
await 的危险性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 async fn transfer (from: &Mutex<i32 >, to: &Mutex<i32 >, amount: i32 ) { let mut from_guard = from.lock ().await ; *from_guard -= amount; drop (from_guard); do_something_slow ().await ; let mut to_guard = to.lock ().await ; *to_guard += amount; } async fn safe_transfer (from: &Mutex<i32 >, to: &Mutex<i32 >, amount: i32 ) { let (mut from_guard, mut to_guard) = tokio::join!( from.lock (), to.lock () ); *from_guard -= amount; *to_guard += amount; }
何时需要/不需要锁 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ┌─────────────────────────────────────────────────────────────────┐ │ 决策流程图 │ └─────────────────────────────────────────────────────────────────┘ 有共享可变状态吗? │ ┌───────────┴───────────┐ ▼ ▼ YES NO │ │ ▼ ▼ 跨多个任务吗? 不需要锁 ✅ │ (每个任务有自己的数据) ┌─────────┴─────────┐ ▼ ▼ YES NO │ │ ▼ ▼ 需要锁 🔒 可能不需要 │ (但要小心 await) │ ▼ 多线程运行时? │ ┌──┴──┐ ▼ ▼ YES NO (current_thread) │ │ ▼ ▼ Arc + Rc + RefCell 可行 Mutex 但仍建议用 Mutex
不需要锁的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 use tokio::sync::mpsc;async fn no_lock_needed () { let (tx, mut rx) = mpsc::channel (100 ); tokio::spawn (async move { tx.send (42 ).await .unwrap (); }); while let Some (value) = rx.recv ().await { println! ("{}" , value); } } async fn process_item (item: String ) { let mut local_data = Vec ::new (); local_data.push (item); } async fn read_only_sharing () { let config = Arc::new (Config::load ()); let c1 = Arc::clone (&config); tokio::spawn (async move { println! ("{}" , c1.name); }); }
std::sync::Mutex vs tokio::sync::Mutex 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 let std_mutex = std::sync::Mutex::new (0 );let guard = std_mutex.lock ().unwrap (); let tokio_mutex = tokio::sync::Mutex::new (0 );let guard = tokio_mutex.lock ().await ; async fn use_std_mutex (data: &std::sync::Mutex<Vec <i32 >>) { { let mut guard = data.lock ().unwrap (); guard.push (1 ); } do_async_work ().await ; } async fn use_tokio_mutex (data: &tokio::sync::Mutex<Vec <i32 >>) { let mut guard = data.lock ().await ; let result = fetch_data ().await ; guard.push (result); }
误解
事实
“异步是单线程的”
Tokio 默认多线程,任务可能并行
“单线程不需要锁”
await 点会切换任务,造成竞态条件
“用 channel 就不需要锁”
channel 内部也用了锁,但封装好了
“锁会影响性能”
正确使用锁的开销很小,数据损坏更可怕
黄金法则:如果多个任务需要修改同一数据,就需要同步机制(Mutex/Channel/Atomic)
总结对比表
特性
标准库
Tokio
async/await
✅
✅
Future trait
✅
✅
Runtime
❌
✅ 多线程/单线程
异步 I/O
❌
✅ TCP/UDP/Unix
定时器
❌
✅ sleep/timeout
通道
❌
✅ mpsc/broadcast/watch
异步锁
❌
✅ Mutex/RwLock/Semaphore
文件 I/O
❌
✅
选择建议:
网络服务/高并发 → Tokio
简单异步需求 → async-std (更简单的 API)
嵌入式/WASM → smol 或自定义
网络编程 核心概念架构 1 2 3 4 5 6 7 8 9 10 11 ┌─────────────────────────────────────────────────────────────────┐ │ Rust 网络编程生态 │ ├─────────────────────────────────────────────────────────────────┤ │ 应用层框架 │ actix-web │ axum │ rocket │ warp │ hyper │ ├─────────────────────────────────────────────────────────────────┤ │ 异步运行时 │ tokio │ async-std │ smol │ ├─────────────────────────────────────────────────────────────────┤ │ 标准库 │ std::net (同步阻塞式) │ ├─────────────────────────────────────────────────────────────────┤ │ 协议层 │ TCP │ UDP │ HTTP │ WebSocket │ └─────────────────────────────────────────────────────────────────┘
标准库同步网络编程 (std::net) TCP 服务端/客户端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 use std::net::{TcpListener, TcpStream};use std::io::{Read, Write};use std::thread;fn tcp_server () -> std::io::Result <()> { let listener = TcpListener::bind ("127.0.0.1:8080" )?; println! ("Server listening on port 8080" ); for stream in listener.incoming () { let stream = stream?; thread::spawn (move || { handle_client (stream).unwrap_or_else (|e| eprintln!("Error: {}" , e)); }); } Ok (()) } fn handle_client (mut stream: TcpStream) -> std::io::Result <()> { let mut buffer = [0u8 ; 1024 ]; loop { let bytes_read = stream.read (&mut buffer)?; if bytes_read == 0 { break ; } stream.write_all (&buffer[..bytes_read])?; } Ok (()) } fn tcp_client () -> std::io::Result <()> { let mut stream = TcpStream::connect ("127.0.0.1:8080" )?; stream.write_all (b"Hello, Server!" )?; let mut buffer = [0u8 ; 1024 ]; let n = stream.read (&mut buffer)?; println! ("Received: {}" , String ::from_utf8_lossy (&buffer[..n])); Ok (()) }
UDP 通信 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 use std::net::UdpSocket;fn udp_server () -> std::io::Result <()> { let socket = UdpSocket::bind ("127.0.0.1:8080" )?; let mut buf = [0u8 ; 1024 ]; loop { let (len, src_addr) = socket.recv_from (&mut buf)?; println! ("Received {} bytes from {}" , len, src_addr); socket.send_to (&buf[..len], src_addr)?; } } fn udp_client () -> std::io::Result <()> { let socket = UdpSocket::bind ("0.0.0.0:0" )?; socket.connect ("127.0.0.1:8080" )?; socket.send (b"Hello UDP!" )?; let mut buf = [0u8 ; 1024 ]; let len = socket.recv (&mut buf)?; println! ("Response: {}" , String ::from_utf8_lossy (&buf[..len])); Ok (()) }
异步网络编程 Cargo.toml 配置 1 2 [dependencies] tokio = { version = "1" , features = ["full" ] }
异步 TCP 服务端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 use tokio::net::{TcpListener, TcpStream};use tokio::io::{AsyncReadExt, AsyncWriteExt};#[tokio::main] async fn main () -> Result <(), Box <dyn std::error::Error>> { let listener = TcpListener::bind ("127.0.0.1:8080" ).await ?; println! ("Async server listening on 8080" ); loop { let (socket, addr) = listener.accept ().await ?; println! ("New connection from: {}" , addr); tokio::spawn (async move { handle_connection (socket).await ; }); } } async fn handle_connection (mut socket: TcpStream) { let mut buffer = vec! [0u8 ; 1024 ]; loop { match socket.read (&mut buffer).await { Ok (0 ) => break , Ok (n) => { if socket.write_all (&buffer[..n]).await .is_err () { break ; } } Err (_) => break , } } }
异步 TCP 客户端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 use tokio::net::TcpStream;use tokio::io::{AsyncReadExt, AsyncWriteExt};#[tokio::main] async fn main () -> Result <(), Box <dyn std::error::Error>> { let mut stream = TcpStream::connect ("127.0.0.1:8080" ).await ?; stream.write_all (b"Hello Async!" ).await ?; let mut buffer = vec! [0u8 ; 1024 ]; let n = stream.read (&mut buffer).await ?; println! ("Received: {}" , String ::from_utf8_lossy (&buffer[..n])); Ok (()) }
HTTP 客户端 1 2 3 4 [dependencies] reqwest = { version = "0.11" , features = ["json" ] }tokio = { version = "1" , features = ["full" ] }serde = { version = "1" , features = ["derive" ] }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 use reqwest;use serde::{Deserialize, Serialize};#[derive(Debug, Serialize, Deserialize)] struct Post { id: Option <u32 >, title: String , body: String , #[serde(rename = "userId" )] user_id: u32 , } #[tokio::main] async fn main () -> Result <(), reqwest::Error> { let response = reqwest::get ("https://jsonplaceholder.typicode.com/posts/1" ) .await ? .json::<Post>() .await ?; println! ("GET: {:?}" , response); let new_post = Post { id: None , title: "foo" .into (), body: "bar" .into (), user_id: 1 , }; let client = reqwest::Client::new (); let res = client .post ("https://jsonplaceholder.typicode.com/posts" ) .json (&new_post) .send () .await ?; println! ("POST Status: {}" , res.status ()); Ok (()) }
Web 服务器框架 1 2 3 4 5 [dependencies] axum = "0.7" tokio = { version = "1" , features = ["full" ] }serde = { version = "1" , features = ["derive" ] }serde_json = "1"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 use axum::{ routing::{get, post}, Router, Json, extract::Path, http::StatusCode, }; use serde::{Deserialize, Serialize};use std::net::SocketAddr;#[derive(Serialize)] struct User { id: u64 , name: String , } #[derive(Deserialize)] struct CreateUser { name: String , } async fn root () -> &'static str { "Hello, World!" } async fn get_user (Path (id): Path<u64 >) -> Json<User> { Json (User { id, name: "Alice" .into () }) } async fn create_user (Json (payload): Json<CreateUser>) -> (StatusCode, Json<User>) { let user = User { id: 1 , name: payload.name, }; (StatusCode::CREATED, Json (user)) } #[tokio::main] async fn main () { let app = Router::new () .route ("/" , get (root)) .route ("/users/:id" , get (get_user)) .route ("/users" , post (create_user)); let addr = SocketAddr::from (([127 , 0 , 0 , 1 ], 3000 )); println! ("Server running at http://{}" , addr); let listener = tokio::net::TcpListener::bind (addr).await .unwrap (); axum::serve (listener, app).await .unwrap (); }
WebSocket 1 2 3 4 [dependencies] tokio = { version = "1" , features = ["full" ] }tokio-tungstenite = "0.21" futures-util = "0.3"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 use tokio::net::TcpListener;use tokio_tungstenite::accept_async;use futures_util::{StreamExt, SinkExt};#[tokio::main] async fn main () { let listener = TcpListener::bind ("127.0.0.1:9000" ).await .unwrap (); println! ("WebSocket server on ws://127.0.0.1:9000" ); while let Ok ((stream, addr)) = listener.accept ().await { tokio::spawn (async move { let ws_stream = accept_async (stream).await .unwrap (); println! ("WebSocket connection from: {}" , addr); let (mut write, mut read) = ws_stream.split (); while let Some (msg) = read.next ().await { if let Ok (msg) = msg { if msg.is_text () || msg.is_binary () { write.send (msg).await .unwrap (); } } } }); } }
关键对比总结
特性
std::net
tokio
async-std
模型 同步阻塞
异步非阻塞
异步非阻塞
并发方式 多线程
任务(Task)
任务(Task)
性能 中等
高
高
复杂度 简单
中等
中等
适用场景 简单工具/学习
高并发服务
高并发服务
生态库推荐
用途
推荐库
HTTP 客户端
reqwest
HTTP 服务器
axum, actix-web
WebSocket
tokio-tungstenite
gRPC
tonic
底层 HTTP
hyper
DNS 解析
trust-dns
TLS
rustls, native-tls
文件操作 核心概念架构 1 2 3 4 5 6 7 8 9 10 11 ┌─────────────────────────────────────────────────────────────────┐ │ Rust 文件操作体系 │ ├─────────────────────────────────────────────────────────────────┤ │ 路径处理 │ std::path::Path │ std::path::PathBuf │ ├─────────────────────────────────────────────────────────────────┤ │ 文件系统 │ std::fs (同步) │ tokio::fs (异步) │ ├─────────────────────────────────────────────────────────────────┤ │ I/O Traits │ Read │ Write │ Seek │ BufRead │ BufWriter │ ├─────────────────────────────────────────────────────────────────┤ │ 高级封装 │ 读: read_to_string │ 写: write │ 追加: append │ └─────────────────────────────────────────────────────────────────┘
快速文件读写 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 use std::fs;fn main () -> std::io::Result <()> { let content = fs::read_to_string ("config.txt" )?; println! ("{}" , content); let bytes = fs::read ("image.png" )?; println! ("File size: {} bytes" , bytes.len ()); fs::write ("output.txt" , "Hello, Rust!" )?; fs::write ("data.bin" , &[0x48 , 0x65 , 0x6c , 0x6c , 0x6f ])?; Ok (()) }
File 结构体操作 打开和创建文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 use std::fs::{File, OpenOptions};use std::io::{Read, Write, Seek, SeekFrom};fn main () -> std::io::Result <()> { let file = File::open ("input.txt" )?; let file = File::create ("output.txt" )?; let mut file = OpenOptions::new () .append (true ) .open ("log.txt" )?; let mut file = OpenOptions::new () .read (true ) .write (true ) .open ("data.txt" )?; let file = OpenOptions::new () .write (true ) .create_new (true ) .open ("new_file.txt" )?; let mut file = OpenOptions::new () .read (true ) .write (true ) .create (true ) .truncate (false ) .open ("config.txt" )?; Ok (()) }
读取操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 use std::fs::File;use std::io::{Read, BufRead, BufReader};fn main () -> std::io::Result <()> { let mut file = File::open ("data.txt" )?; let mut content = String ::new (); file.read_to_string (&mut content)?; let mut file = File::open ("data.bin" )?; let mut buffer = Vec ::new (); file.read_to_end (&mut buffer)?; let mut file = File::open ("large.bin" )?; let mut chunk = [0u8 ; 1024 ]; loop { let bytes_read = file.read (&mut chunk)?; if bytes_read == 0 { break ; } println! ("Read {} bytes" , bytes_read); } let file = File::open ("log.txt" )?; let reader = BufReader::new (file); for line in reader.lines () { let line = line?; println! ("{}" , line); } let file = File::open ("data.txt" )?; let reader = BufReader::new (file); for line in reader.split (b'\n' ) { let line = line?; } Ok (()) }
写入操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 use std::fs::File;use std::io::{Write, BufWriter};fn main () -> std::io::Result <()> { let mut file = File::create ("output.txt" )?; file.write_all (b"Hello, World!\n" )?; writeln! (file, "Number: {}" , 42 )?; writeln! (file, "Name: {}" , "Alice" )?; file.sync_all ()?; let file = File::create ("large_output.txt" )?; let mut writer = BufWriter::new (file); for i in 0 ..10000 { writeln! (writer, "Line {}" , i)?; } writer.flush ()?; let file = File::create ("data.txt" )?; let mut writer = BufWriter::with_capacity (64 * 1024 , file); Ok (()) }
文件指针定位 (Seek) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 use std::fs::OpenOptions;use std::io::{Read, Write, Seek, SeekFrom};fn main () -> std::io::Result <()> { let mut file = OpenOptions::new () .read (true ) .write (true ) .open ("data.txt" )?; file.seek (SeekFrom::Start (0 ))?; file.seek (SeekFrom::End (0 ))?; file.seek (SeekFrom::Current (10 ))?; file.seek (SeekFrom::Current (-5 ))?; let pos = file.stream_position ()?; println! ("Current position: {}" , pos); file.rewind ()?; Ok (()) }
路径操作 (Path/PathBuf) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 use std::path::{Path, PathBuf};use std::ffi::OsStr;fn main () { let path = Path::new ("/home/user/file.txt" ); let mut path_buf = PathBuf::from ("/home/user" ); path_buf.push ("documents" ); path_buf.push ("file.txt" ); println! ("{}" , path_buf.display ()); let path = Path::new ("/home/user/document.tar.gz" ); println! ("文件名: {:?}" , path.file_name ()); println! ("文件干名: {:?}" , path.file_stem ()); println! ("扩展名: {:?}" , path.extension ()); println! ("父目录: {:?}" , path.parent ()); let path = Path::new ("./config.toml" ); println! ("是否绝对路径: {}" , path.is_absolute ()); println! ("是否相对路径: {}" , path.is_relative ()); println! ("是否存在: {}" , path.exists ()); println! ("是文件: {}" , path.is_file ()); println! ("是目录: {}" , path.is_dir ()); println! ("是符号链接: {}" , path.is_symlink ()); let mut path = PathBuf::from ("/home/user/file.txt" ); path.set_file_name ("new_file.txt" ); path.set_extension ("md" ); let full_path = Path::new ("/home" ).join ("user" ).join ("file.txt" ); let path = Path::new ("/home/user/../user/./file.txt" ); if let Ok (canonical) = path.canonicalize () { println! ("规范路径: {}" , canonical.display ()); } let path = Path::new ("/home/user/docs/file.txt" ); for component in path.components () { println! ("{:?}" , component); } for ancestor in path.ancestors () { println! ("{}" , ancestor.display ()); } }
目录操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 use std::fs::{self , DirEntry};use std::path::Path;fn main () -> std::io::Result <()> { fs::create_dir ("new_dir" )?; fs::create_dir_all ("path/to/nested/dir" )?; fs::remove_dir ("empty_dir" )?; fs::remove_dir_all ("dir_with_contents" )?; for entry in fs::read_dir ("." )? { let entry = entry?; let path = entry.path (); let file_type = entry.file_type ()?; if file_type.is_dir () { println! ("[DIR] {}" , path.display ()); } else if file_type.is_file () { println! ("[FILE] {}" , path.display ()); } else if file_type.is_symlink () { println! ("[LINK] {}" , path.display ()); } } fn visit_dirs (dir: &Path, depth: usize ) -> std::io::Result <()> { if dir.is_dir () { for entry in fs::read_dir (dir)? { let entry = entry?; let path = entry.path (); let indent = " " .repeat (depth); println! ("{}{}" , indent, path.file_name ().unwrap ().to_string_lossy ()); if path.is_dir () { visit_dirs (&path, depth + 1 )?; } } } Ok (()) } visit_dirs (Path::new ("." ), 0 )?; let cwd = std::env::current_dir ()?; println! ("当前目录: {}" , cwd.display ()); std::env::set_current_dir ("/tmp" )?; let temp_dir = std::env::temp_dir (); println! ("临时目录: {}" , temp_dir.display ()); Ok (()) }
文件元数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 use std::fs::{self , Metadata, Permissions};use std::os::unix::fs::PermissionsExt; use std::time::SystemTime;fn main () -> std::io::Result <()> { let metadata = fs::metadata ("file.txt" )?; println! ("是文件: {}" , metadata.is_file ()); println! ("是目录: {}" , metadata.is_dir ()); println! ("是符号链接: {}" , metadata.is_symlink ()); println! ("文件大小: {} bytes" , metadata.len ()); if let Ok (modified) = metadata.modified () { println! ("修改时间: {:?}" , modified); } if let Ok (accessed) = metadata.accessed () { println! ("访问时间: {:?}" , accessed); } if let Ok (created) = metadata.created () { println! ("创建时间: {:?}" , created); } #[cfg(unix)] { let permissions = metadata.permissions (); let mode = permissions.mode (); println! ("权限: {:o}" , mode); println! ("只读: {}" , permissions.readonly ()); let mut perms = fs::metadata ("file.txt" )?.permissions (); perms.set_mode (0o644 ); fs::set_permissions ("file.txt" , perms)?; let mut perms = fs::metadata ("file.txt" )?.permissions (); perms.set_readonly (true ); fs::set_permissions ("file.txt" , perms)?; } let link_metadata = fs::symlink_metadata ("symlink" )?; Ok (()) }
文件系统操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 use std::fs;use std::path::Path;fn main () -> std::io::Result <()> { let bytes_copied = fs::copy ("source.txt" , "dest.txt" )?; println! ("复制了 {} 字节" , bytes_copied); fs::rename ("old_name.txt" , "new_name.txt" )?; fs::rename ("file.txt" , "subdir/file.txt" )?; fs::remove_file ("to_delete.txt" )?; fs::hard_link ("original.txt" , "hardlink.txt" )?; #[cfg(unix)] std::os::unix::fs::symlink ("target.txt" , "symlink.txt" )?; #[cfg(windows)] std::os::windows::fs::symlink_file ("target.txt" , "symlink.txt" )?; let target = fs::read_link ("symlink.txt" )?; println! ("链接指向: {}" , target.display ()); Ok (()) }
异步文件操作 (Tokio) 1 2 [dependencies] tokio = { version = "1" , features = ["full" ] }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 use tokio::fs::{self , File};use tokio::io::{AsyncReadExt, AsyncWriteExt, BufReader, AsyncBufReadExt};#[tokio::main] async fn main () -> Result <(), Box <dyn std::error::Error>> { let content = fs::read_to_string ("config.txt" ).await ?; let bytes = fs::read ("data.bin" ).await ?; fs::write ("output.txt" , "Hello Async!" ).await ?; let mut file = File::open ("input.txt" ).await ?; let mut content = String ::new (); file.read_to_string (&mut content).await ?; let mut file = File::create ("output.txt" ).await ?; file.write_all (b"Hello!" ).await ?; file.sync_all ().await ?; let file = File::open ("log.txt" ).await ?; let reader = BufReader::new (file); let mut lines = reader.lines (); while let Some (line) = lines.next_line ().await ? { println! ("{}" , line); } fs::create_dir_all ("path/to/dir" ).await ?; fs::remove_dir_all ("old_dir" ).await ?; let mut entries = fs::read_dir ("." ).await ?; while let Some (entry) = entries.next_entry ().await ? { println! ("{}" , entry.path ().display ()); } Ok (()) }
实用工具库 walkdir - 递归目录遍历 1 2 [dependencies] walkdir = "2"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 use walkdir::WalkDir;fn main () { for entry in WalkDir::new ("." ).into_iter ().filter_map (|e| e.ok ()) { println! ("{}" , entry.path ().display ()); } for entry in WalkDir::new ("." ) .max_depth (3 ) .into_iter () .filter_entry (|e| !e.file_name ().to_str ().map (|s| s.starts_with ("." )).unwrap_or (false )) .filter_map (|e| e.ok ()) { if entry.file_type ().is_file () { println! ("{}" , entry.path ().display ()); } } }
glob - 文件模式匹配 1 2 [dependencies] glob = "0.3"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 use glob::glob;fn main () -> Result <(), Box <dyn std::error::Error>> { for entry in glob ("src/**/*.rs" )? { println! ("{}" , entry?.display ()); } for entry in glob ("*.{txt,md,toml}" )? { println! ("{}" , entry?.display ()); } Ok (()) }
tempfile - 临时文件 1 2 [dependencies] tempfile = "3"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 use tempfile::{tempfile, tempdir, NamedTempFile};use std::io::Write;fn main () -> std::io::Result <()> { let mut file = tempfile ()?; writeln! (file, "temporary data" )?; let mut named_file = NamedTempFile::new ()?; writeln! (named_file, "data" )?; println! ("临时文件路径: {}" , named_file.path ().display ()); let (file, path) = NamedTempFile::new ()?.keep ()?; let temp_dir = tempdir ()?; let file_path = temp_dir.path ().join ("temp.txt" ); std::fs::write (&file_path, "data" )?; Ok (()) }
错误处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 use std::fs::File;use std::io::{self , Read, ErrorKind};use std::path::Path;fn read_file_verbose (path: &str ) -> io::Result <String > { let mut file = match File::open (path) { Ok (f) => f, Err (e) => match e.kind () { ErrorKind::NotFound => { eprintln!("文件不存在: {}" , path); return Err (e); } ErrorKind::PermissionDenied => { eprintln!("权限不足: {}" , path); return Err (e); } _ => { eprintln!("打开文件失败: {}" , e); return Err (e); } } }; let mut content = String ::new (); file.read_to_string (&mut content)?; Ok (content) } use anyhow::{Context, Result };fn read_config (path: &Path) -> Result <String > { std::fs::read_to_string (path) .with_context (|| format! ("无法读取配置文件: {}" , path.display ())) } fn safe_read (path: &Path) -> io::Result <String > { if !path.exists () { return Err (io::Error::new (ErrorKind::NotFound, "文件不存在" )); } if !path.is_file () { return Err (io::Error::new (ErrorKind::InvalidInput, "不是文件" )); } std::fs::read_to_string (path) }
数据库编程 核心生态架构 1 2 3 4 5 6 7 8 9 10 11 12 13 ┌─────────────────────────────────────────────────────────────────────┐ │ Rust 数据库生态 │ ├─────────────────────────────────────────────────────────────────────┤ │ ORM 框架 │ Diesel (同步) │ SeaORM (异步) │ rbatis │ ├─────────────────────────────────────────────────────────────────────┤ │ SQL 工具库 │ SQLx (异步/编译时检查) │ rusqlite (SQLite) │ ├─────────────────────────────────────────────────────────────────────┤ │ NoSQL │ mongodb │ redis │ sled (嵌入式) │ ├─────────────────────────────────────────────────────────────────────┤ │ 连接池 │ deadpool │ r2d2 │ bb8 │ ├─────────────────────────────────────────────────────────────────────┤ │ 支持数据库 │ PostgreSQL │ MySQL │ SQLite │ MSSQL │ MongoDB │ └─────────────────────────────────────────────────────────────────────┘
库选择指南
库
类型
特点
适用场景
SQLx SQL工具
编译时检查、异步、轻量
需要原生SQL控制
Diesel ORM
类型安全、同步、成熟
传统同步应用
SeaORM ORM
异步、动态查询、ActiveRecord
异步Web服务
rusqlite SQLite
同步、嵌入式、简单
本地应用/测试
SQLx - 异步 SQL 工具库 项目配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [dependencies] sqlx = { version = "0.7" , features = [ "runtime-tokio" , "tls-rustls" , "postgres" , "macros" , "chrono" , "uuid" , ] } tokio = { version = "1" , features = ["full" ] }chrono = { version = "0.4" , features = ["serde" ] }uuid = { version = "1" , features = ["v4" , "serde" ] }serde = { version = "1" , features = ["derive" ] }
连接与连接池 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 use sqlx::{PgPool, Pool, Postgres};use sqlx::postgres::PgPoolOptions;#[tokio::main] async fn main () -> Result <(), sqlx::Error> { let pool = PgPool::connect ("postgres://user:pass@localhost/dbname" ).await ?; let pool = PgPoolOptions::new () .max_connections (10 ) .min_connections (2 ) .acquire_timeout (std::time::Duration::from_secs (30 )) .idle_timeout (std::time::Duration::from_secs (600 )) .max_lifetime (std::time::Duration::from_secs (1800 )) .connect ("postgres://user:pass@localhost/dbname" ) .await ?; let pool = PgPool::connect (&std::env::var ("DATABASE_URL" )?).await ?; sqlx::query ("SELECT 1" ).execute (&pool).await ?; println! ("数据库连接成功!" ); Ok (()) }
基本 CRUD 操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 use sqlx::{PgPool, Row, FromRow};use chrono::{DateTime, Utc};use uuid::Uuid;#[derive(Debug, FromRow)] struct User { id: i32 , username: String , email: String , created_at: DateTime<Utc>, } #[derive(Debug)] struct CreateUser { username: String , email: String , } async fn crud_examples (pool: &PgPool) -> Result <(), sqlx::Error> { let result = sqlx::query ( "INSERT INTO users (username, email) VALUES ($1, $2)" ) .bind ("alice" ) .bind ("alice@example.com" ) .execute (pool) .await ?; println! ("插入 {} 行" , result.rows_affected ()); let id : (i32 ,) = sqlx::query_as ( "INSERT INTO users (username, email) VALUES ($1, $2) RETURNING id" ) .bind ("bob" ) .bind ("bob@example.com" ) .fetch_one (pool) .await ?; println! ("新用户ID: {}" , id.0 ); let user : User = sqlx::query_as ("SELECT * FROM users WHERE id = $1" ) .bind (1 ) .fetch_one (pool) .await ?; println! ("用户: {:?}" , user); let user : Option <User> = sqlx::query_as ("SELECT * FROM users WHERE id = $1" ) .bind (999 ) .fetch_optional (pool) .await ?; let users : Vec <User> = sqlx::query_as ("SELECT * FROM users LIMIT $1" ) .bind (10i64 ) .fetch_all (pool) .await ?; use futures::TryStreamExt; let mut stream = sqlx::query_as::<_, User>("SELECT * FROM users" ) .fetch (pool); while let Some (user) = stream.try_next ().await ? { println! ("流式: {:?}" , user); } let result = sqlx::query ( "UPDATE users SET email = $1 WHERE id = $2" ) .bind ("newemail@example.com" ) .bind (1 ) .execute (pool) .await ?; println! ("更新 {} 行" , result.rows_affected ()); let result = sqlx::query ("DELETE FROM users WHERE id = $1" ) .bind (1 ) .execute (pool) .await ?; println! ("删除 {} 行" , result.rows_affected ()); Ok (()) }
编译时检查宏 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 use sqlx::{PgPool, FromRow};#[derive(Debug, FromRow)] struct User { id: i32 , username: String , email: String , } async fn compile_time_checked (pool: &PgPool) -> Result <(), sqlx::Error> { let row = sqlx::query!( "SELECT id, username, email FROM users WHERE id = $1" , 1i32 ) .fetch_one (pool) .await ?; println! ("ID: {}, Username: {}" , row.id, row.username); let user = sqlx::query_as!( User, "SELECT id, username, email FROM users WHERE id = $1" , 1i32 ) .fetch_one (pool) .await ?; let row = sqlx::query!( r#"SELECT id, username, bio as "bio?" FROM users WHERE id = $1"# , 1i32 ) .fetch_one (pool) .await ?; let row = sqlx::query!( r#"SELECT id, username as "username!" FROM users WHERE id = $1"# , 1i32 ) .fetch_one (pool) .await ?; let row = sqlx::query!( r#"SELECT COUNT(*) as "count!: i64" FROM users"# ) .fetch_one (pool) .await ?; println! ("总数: {}" , row.count); Ok (()) }
事务处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 use sqlx::PgPool;async fn transfer_money ( pool: &PgPool, from_id: i32 , to_id: i32 , amount: f64 , ) -> Result <(), sqlx::Error> { let mut tx = pool.begin ().await ?; sqlx::query ("UPDATE accounts SET balance = balance - $1 WHERE id = $2" ) .bind (amount) .bind (from_id) .execute (&mut *tx) .await ?; sqlx::query ("UPDATE accounts SET balance = balance + $1 WHERE id = $2" ) .bind (amount) .bind (to_id) .execute (&mut *tx) .await ?; tx.commit ().await ?; Ok (()) } async fn nested_transaction (pool: &PgPool) -> Result <(), sqlx::Error> { let mut tx = pool.begin ().await ?; sqlx::query ("INSERT INTO logs (msg) VALUES ('outer')" ) .execute (&mut *tx) .await ?; let mut savepoint = tx.begin ().await ?; let result = sqlx::query ("INSERT INTO users (name) VALUES ('test')" ) .execute (&mut *savepoint) .await ; match result { Ok (_) => savepoint.commit ().await ?, Err (_) => { savepoint.rollback ().await ?; } } tx.commit ().await ?; Ok (()) }
Diesel - 类型安全 ORM 项目配置 1 2 3 4 5 6 [dependencies] diesel = { version = "2" , features = ["postgres" , "r2d2" , "chrono" ] }dotenvy = "0.15" [dependencies.diesel_migrations] version = "2"
初始化项目 1 2 3 4 5 6 7 8 9 10 11 12 13 14 cargo install diesel_cli --no-default-features --features postgres diesel setup diesel migration generate create_users diesel migration run diesel migration revert
迁移文件 1 2 3 4 5 6 7 8 9 10 CREATE TABLE users ( id SERIAL PRIMARY KEY, username VARCHAR (100 ) NOT NULL UNIQUE , email VARCHAR (255 ) NOT NULL , created_at TIMESTAMP NOT NULL DEFAULT NOW() ); DROP TABLE users;
Schema 和模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 diesel::table! { users (id) { id -> Int4, username -> Varchar, email -> Varchar, created_at -> Timestamp, } } use diesel::prelude::*;use chrono::NaiveDateTime;use crate::schema::users;#[derive(Debug, Queryable, Selectable)] #[diesel(table_name = users)] pub struct User { pub id: i32 , pub username: String , pub email: String , pub created_at: NaiveDateTime, } #[derive(Debug, Insertable)] #[diesel(table_name = users)] pub struct NewUser <'a > { pub username: &'a str , pub email: &'a str , } #[derive(Debug, AsChangeset)] #[diesel(table_name = users)] pub struct UpdateUser <'a > { pub username: Option <&'a str >, pub email: Option <&'a str >, }
CRUD 操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 use diesel::prelude::*;use diesel::pg::PgConnection;use diesel::r2d2::{self , ConnectionManager};type DbPool = r2d2::Pool<ConnectionManager<PgConnection>>;fn establish_pool () -> DbPool { let database_url = std::env::var ("DATABASE_URL" ).expect ("DATABASE_URL must be set" ); let manager = ConnectionManager::<PgConnection>::new (database_url); r2d2::Pool::builder () .max_size (10 ) .build (manager) .expect ("Failed to create pool" ) } fn create_user (conn: &mut PgConnection, name: &str , mail: &str ) -> QueryResult<User> { use crate::schema::users; let new_user = NewUser { username: name, email: mail, }; diesel::insert_into (users::table) .values (&new_user) .returning (User::as_returning ()) .get_result (conn) } fn create_users (conn: &mut PgConnection, new_users: &[NewUser]) -> QueryResult<Vec <User>> { use crate::schema::users; diesel::insert_into (users::table) .values (new_users) .returning (User::as_returning ()) .get_results (conn) } fn get_user (conn: &mut PgConnection, user_id: i32 ) -> QueryResult<User> { use crate::schema::users::dsl::*; users.find (user_id).first (conn) } fn get_user_by_name (conn: &mut PgConnection, name: &str ) -> QueryResult<Option <User>> { use crate::schema::users::dsl::*; users .filter (username.eq (name)) .first (conn) .optional () } fn list_users (conn: &mut PgConnection, page: i64 , per_page: i64 ) -> QueryResult<Vec <User>> { use crate::schema::users::dsl::*; users .order (created_at.desc ()) .limit (per_page) .offset (page * per_page) .load (conn) } fn search_users (conn: &mut PgConnection, query: &str ) -> QueryResult<Vec <User>> { use crate::schema::users::dsl::*; users .filter (username.ilike (format! ("%{}%" , query))) .or_filter (email.ilike (format! ("%{}%" , query))) .order (username.asc ()) .load (conn) } fn update_user (conn: &mut PgConnection, user_id: i32 , update: UpdateUser) -> QueryResult<User> { use crate::schema::users::dsl::*; diesel::update (users.find (user_id)) .set (&update) .returning (User::as_returning ()) .get_result (conn) } fn delete_user (conn: &mut PgConnection, user_id: i32 ) -> QueryResult<usize > { use crate::schema::users::dsl::*; diesel::delete (users.find (user_id)).execute (conn) }
事务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 fn transfer_in_transaction (conn: &mut PgConnection) -> QueryResult<()> { conn.transaction (|conn| { diesel::update (accounts.find (1 )) .set (balance.eq (balance - 100 )) .execute (conn)?; diesel::update (accounts.find (2 )) .set (balance.eq (balance + 100 )) .execute (conn)?; Ok (()) }) }
SeaORM - 异步 ORM 项目配置 1 2 3 4 5 6 7 [dependencies] sea-orm = { version = "0.12" , features = [ "runtime-tokio-rustls" , "sqlx-postgres" , "macros" , ] } tokio = { version = "1" , features = ["full" ] }
Entity 定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 use sea_orm::entity::prelude::*;#[derive(Clone, Debug, PartialEq, DeriveEntityModel)] #[sea_orm(table_name = "users" )] pub struct Model { #[sea_orm(primary_key)] pub id: i32 , #[sea_orm(unique)] pub username: String , pub email: String , pub created_at: DateTimeUtc, } #[derive(Copy, Clone, Debug, EnumIter, DeriveRelation)] pub enum Relation { #[sea_orm(has_many = "super::post::Entity" )] Posts, } impl Related <super::post::Entity> for Entity { fn to () -> RelationDef { Relation::Posts.def () } } impl ActiveModelBehavior for ActiveModel {}
CRUD 操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 use sea_orm::*;async fn connect () -> Result <DatabaseConnection, DbErr> { let db = Database::connect ("postgres://user:pass@localhost/db" ).await ?; Ok (db) } async fn create_user (db: &DatabaseConnection) -> Result <user::Model, DbErr> { let new_user = user::ActiveModel { username: Set ("alice" .to_owned ()), email: Set ("alice@example.com" .to_owned ()), ..Default ::default () }; new_user.insert (db).await } async fn find_user (db: &DatabaseConnection, id: i32 ) -> Result <Option <user::Model>, DbErr> { User::find_by_id (id).one (db).await } async fn find_users (db: &DatabaseConnection) -> Result <Vec <user::Model>, DbErr> { User::find () .filter (user::Column::Username.contains ("a" )) .order_by_asc (user::Column::Id) .limit (10 ) .all (db) .await } async fn update_user (db: &DatabaseConnection, id: i32 ) -> Result <user::Model, DbErr> { let user : user::ActiveModel = User::find_by_id (id) .one (db) .await ? .ok_or (DbErr::RecordNotFound ("User not found" .into ()))? .into (); let mut user = user; user.email = Set ("new@example.com" .to_owned ()); user.update (db).await } async fn delete_user (db: &DatabaseConnection, id: i32 ) -> Result <DeleteResult, DbErr> { User::delete_by_id (id).exec (db).await } async fn transaction_example (db: &DatabaseConnection) -> Result <(), DbErr> { db.transaction::<_, (), DbErr>(|txn| { Box ::pin (async move { let user = user::ActiveModel { username: Set ("bob" .to_owned ()), email: Set ("bob@example.com" .to_owned ()), ..Default ::default () }; user.insert (txn).await ?; Ok (()) }) }) .await }
SQLite 1 2 [dependencies] rusqlite = { version = "0.31" , features = ["bundled" ] }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 use rusqlite::{Connection, Result , params};#[derive(Debug)] struct User { id: i32 , name: String , email: String , } fn main () -> Result <()> { let conn = Connection::open ("app.db" )?; conn.execute ( "CREATE TABLE IF NOT EXISTS users ( id INTEGER PRIMARY KEY, name TEXT NOT NULL, email TEXT NOT NULL UNIQUE )" , [], )?; conn.execute ( "INSERT INTO users (name, email) VALUES (?1, ?2)" , params!["Alice" , "alice@example.com" ], )?; let last_id = conn.last_insert_rowid (); let mut stmt = conn.prepare ("SELECT id, name, email FROM users WHERE id = ?1" )?; let user = stmt.query_row ([1 ], |row| { Ok (User { id: row.get (0 )?, name: row.get (1 )?, email: row.get (2 )?, }) })?; println! ("{:?}" , user); let mut stmt = conn.prepare ("SELECT id, name, email FROM users" )?; let users = stmt.query_map ([], |row| { Ok (User { id: row.get (0 )?, name: row.get (1 )?, email: row.get (2 )?, }) })?; for user in users { println! ("{:?}" , user?); } let tx = conn.transaction ()?; tx.execute ("INSERT INTO users (name, email) VALUES (?1, ?2)" , params!["Bob" , "bob@example.com" ])?; tx.commit ()?; Ok (()) }
Redis 1 2 3 [dependencies] redis = { version = "0.25" , features = ["tokio-comp" , "connection-manager" ] }tokio = { version = "1" , features = ["full" ] }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 use redis::AsyncCommands;#[tokio::main] async fn main () -> redis::RedisResult<()> { let client = redis::Client::open ("redis://127.0.0.1/" )?; let mut con = client.get_multiplexed_async_connection ().await ?; con.set ("key" , "value" ).await ?; let val : String = con.get ("key" ).await ?; con.set_ex ("temp_key" , "temp_value" , 60 ).await ?; con.hset ("user:1" , "name" , "Alice" ).await ?; con.hset ("user:1" , "email" , "alice@example.com" ).await ?; let name : String = con.hget ("user:1" , "name" ).await ?; let all : std::collections::HashMap<String , String > = con.hgetall ("user:1" ).await ?; con.rpush ("queue" , "item1" ).await ?; con.rpush ("queue" , "item2" ).await ?; let item : String = con.lpop ("queue" , None ).await ?; con.sadd ("tags" , "rust" ).await ?; con.sadd ("tags" , "database" ).await ?; let members : Vec <String > = con.smembers ("tags" ).await ?; con.zadd ("leaderboard" , "player1" , 100 ).await ?; con.zadd ("leaderboard" , "player2" , 200 ).await ?; let top : Vec <(String , i32 )> = con.zrevrange_withscores ("leaderboard" , 0 , 9 ).await ?; let (k1, k2): (String , String ) = redis::pipe () .get ("key1" ) .get ("key2" ) .query_async (&mut con) .await ?; Ok (()) }
MongoDB 1 2 3 4 5 [dependencies] mongodb = "2" tokio = { version = "1" , features = ["full" ] }serde = { version = "1" , features = ["derive" ] }futures = "0.3"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 use mongodb::{Client, Collection, bson::doc};use serde::{Deserialize, Serialize};use futures::TryStreamExt;#[derive(Debug, Serialize, Deserialize)] struct User { #[serde(rename = "_id" , skip_serializing_if = "Option::is_none" )] id: Option <mongodb::bson::oid::ObjectId>, username: String , email: String , age: i32 , } #[tokio::main] async fn main () -> mongodb::error::Result <()> { let client = Client::with_uri_str ("mongodb://localhost:27017" ).await ?; let db = client.database ("mydb" ); let collection : Collection<User> = db.collection ("users" ); let user = User { id: None , username: "alice" .to_string (), email: "alice@example.com" .to_string (), age: 25 , }; let result = collection.insert_one (user, None ).await ?; println! ("Inserted ID: {:?}" , result.inserted_id); let users = vec! [ User { id: None , username: "bob" .into (), email: "bob@example.com" .into (), age: 30 }, User { id: None , username: "carol" .into (), email: "carol@example.com" .into (), age: 28 }, ]; collection.insert_many (users, None ).await ?; let user = collection.find_one (doc! { "username" : "alice" }, None ).await ?; println! ("{:?}" , user); let mut cursor = collection.find (doc! { "age" : { "$gte" : 25 } }, None ).await ?; while let Some (user) = cursor.try_next ().await ? { println! ("{:?}" , user); } collection.update_one ( doc! { "username" : "alice" }, doc! { "$set" : { "age" : 26 } }, None , ).await ?; collection.delete_one (doc! { "username" : "bob" }, None ).await ?; let pipeline = vec! [ doc! { "$match" : { "age" : { "$gte" : 20 } } }, doc! { "$group" : { "_id" : null, "avg_age" : { "$avg" : "$age" } } }, ]; let mut cursor = collection.aggregate (pipeline, None ).await ?; while let Some (doc) = cursor.try_next ().await ? { println! ("{:?}" , doc); } Ok (()) }
数据库迁移管理 SQLx 迁移 1 2 3 4 5 6 7 8 sqlx migrate add create_users sqlx migrate run sqlx migrate revert
1 2 3 4 5 6 7 8 9 use sqlx::migrate::Migrator;static MIGRATOR: Migrator = sqlx::migrate!("./migrations" );async fn run_migrations (pool: &PgPool) -> Result <(), sqlx::Error> { MIGRATOR.run (pool).await ?; Ok (()) }
Diesel 迁移 1 2 3 4 diesel migration generate create_users diesel migration run diesel migration revert diesel migration redo
总结对比
特性
SQLx
Diesel
SeaORM
异步支持 ✅
❌
✅
编译时检查 ✅ 宏
✅ 类型系统
❌
学习曲线 低
中
中
原生SQL ✅
部分
部分
ORM功能 ❌
✅
✅
动态查询 ✅
中等
✅
迁移工具 ✅
✅
✅
Unsafe 编程 核心概念 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ┌─────────────────────────────────────────────────────────────────────┐ │ Rust 安全模型 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ Safe Rust │ 编译器保证内存安全、无数据竞争 │ │ ───────────────────────────────────────────────────────────── │ │ Unsafe Rust │ 程序员承诺代码安全,编译器信任 │ │ │ ├─────────────────────────────────────────────────────────────────────┤ │ Unsafe 五大超能力 │ ├─────────────────────────────────────────────────────────────────────┤ │ 1. 解引用裸指针 *const T / *mut T │ │ 2. 调用 unsafe 函数 unsafe fn / extern "C" fn │ │ 3. 访问可变静态变量 static mut │ │ 4. 实现 unsafe trait Send / Sync 等 │ │ 5. 访问 union 字段 union 类型 │ └─────────────────────────────────────────────────────────────────────┘
unsafe 不意味着什么 1 2 3 4 5 6 7 8 9 10 11 unsafe { let mut s = String ::from ("hello" ); let r1 = &s; let r2 = &mut s; } unsafe { let x : i32 = "hello" ; }
裸指针 (Raw Pointers) 基本操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 fn main () { let x = 42 ; let y = &x as *const i32 ; let z = &x as *const i32 as *mut i32 ; let mut value = 10 ; let ptr_mut = &mut value as *mut i32 ; let reference = &value; let ptr = reference as *const i32 ; unsafe { println! ("y = {}" , *y); *ptr_mut = 20 ; println! ("value = {}" , *ptr_mut); } let null_ptr : *const i32 = std::ptr::null (); let null_mut : *mut i32 = std::ptr::null_mut (); if !null_ptr.is_null () { unsafe { println! ("{}" , *null_ptr); } } let addr = 0x012345usize ; let _ptr = addr as *const i32 ; }
指针算术 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 fn main () { let arr = [1 , 2 , 3 , 4 , 5 ]; let ptr = arr.as_ptr (); unsafe { println! ("arr[0] = {}" , *ptr); println! ("arr[2] = {}" , *ptr.add (2 )); println! ("arr[4] = {}" , *ptr.offset (4 )); for i in 0 ..arr.len () { println! ("{}" , *ptr.add (i)); } } let mut arr = [1 , 2 , 3 , 4 , 5 ]; let ptr = arr.as_mut_ptr (); unsafe { *ptr.add (2 ) = 100 ; ptr.add (3 ).write (200 ); let val = ptr.add (1 ).read (); println! ("val = {}" , val); } println! ("{:?}" , arr); }
指针与切片转换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 use std::slice;fn main () { let arr = [1 , 2 , 3 , 4 , 5 ]; let ptr = arr.as_ptr (); unsafe { let slice = slice::from_raw_parts (ptr, 3 ); println! ("{:?}" , slice); } let mut arr = [1 , 2 , 3 , 4 , 5 ]; let ptr = arr.as_mut_ptr (); unsafe { let slice = slice::from_raw_parts_mut (ptr, arr.len ()); slice[0 ] = 100 ; } println! ("{:?}" , arr); fn split_at_mut <T>(slice: &mut [T], mid: usize ) -> (&mut [T], &mut [T]) { let len = slice.len (); let ptr = slice.as_mut_ptr (); assert! (mid <= len); unsafe { ( slice::from_raw_parts_mut (ptr, mid), slice::from_raw_parts_mut (ptr.add (mid), len - mid), ) } } let mut arr = [1 , 2 , 3 , 4 , 5 ]; let (left, right) = split_at_mut (&mut arr, 2 ); println! ("{:?}, {:?}" , left, right); }
Unsafe 函数与方法 定义和调用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 unsafe fn dangerous () { println! ("危险操作!" ); } unsafe fn process_raw_pointer (ptr: *const i32 ) -> i32 { *ptr } fn main () { unsafe { dangerous (); let x = 42 ; let val = process_raw_pointer (&x); println! ("val = {}" , val); } } fn safe_get (v: &Vec <i32 >, index: usize ) -> i32 { assert! (index < v.len (), "索引越界" ); unsafe { *v.as_ptr ().add (index) } }
unsafe trait 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 unsafe trait UnsafeTrait { fn do_something (&self ); } unsafe impl UnsafeTrait for i32 { fn do_something (&self ) { println! ("i32: {}" , self ); } } struct MyBox (*mut i32 );unsafe impl Send for MyBox {}unsafe impl Sync for MyBox {}use std::marker::PhantomData;struct NotSend { _marker: PhantomData<*const ()>, }
静态变量与内部可变性 可变静态变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 static GREETING: &str = "Hello, World!" ;static COUNT: i32 = 42 ;static mut COUNTER: i32 = 0 ;fn increment () { unsafe { COUNTER += 1 ; } } fn get_count () -> i32 { unsafe { COUNTER } } fn main () { println! ("{}" , GREETING); increment (); increment (); println! ("Counter: {}" , get_count ()); } use std::sync::atomic::{AtomicI32, Ordering};use std::sync::OnceLock;static ATOMIC_COUNTER: AtomicI32 = AtomicI32::new (0 );fn safe_increment () { ATOMIC_COUNTER.fetch_add (1 , Ordering::SeqCst); } static CONFIG: OnceLock<String > = OnceLock::new ();fn get_config () -> &'static String { CONFIG.get_or_init (|| { String ::from ("default_config" ) }) }
外部静态变量 1 2 3 4 5 6 7 8 9 10 11 12 extern "C" { static errno: i32 ; static mut global: i32 ; } fn check_errno () { unsafe { if errno != 0 { println! ("Error: {}" , errno); } } }
Union 类型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #[repr(C)] union IntOrFloat { i: i32 , f: f32 , } fn main () { let mut u = IntOrFloat { i: 42 }; unsafe { println! ("As int: {}" , u.i); println! ("As float: {}" , u.f); } u.f = 3.14 ; unsafe { println! ("As float: {}" , u.f); println! ("As int: {}" , u.i); } } union FloatBits { f: f32 , bits: u32 , } fn float_to_bits (f: f32 ) -> u32 { let fb = FloatBits { f }; unsafe { fb.bits } } fn bits_to_float (bits: u32 ) -> f32 { let fb = FloatBits { bits }; unsafe { fb.f } } use std::mem::ManuallyDrop;union MaybeString { none: (), some: ManuallyDrop<String >, } impl MaybeString { fn new_some (s: String ) -> Self { MaybeString { some: ManuallyDrop::new (s), } } fn new_none () -> Self { MaybeString { none: () } } unsafe fn take (&mut self ) -> String { ManuallyDrop::take (&mut self .some) } }
FFI(外部函数接口) 调用 C 函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 use std::ffi::{CStr, CString};use std::os::raw::{c_char, c_int, c_void};extern "C" { fn abs (input: c_int) -> c_int; fn strlen (s: *const c_char) -> usize ; fn printf (format: *const c_char, ...) -> c_int; fn malloc (size: usize ) -> *mut c_void; fn free (ptr: *mut c_void); } fn main () { unsafe { println! ("abs(-5) = {}" , abs (-5 )); let s = CString::new ("Hello" ).unwrap (); println! ("strlen = {}" , strlen (s.as_ptr ())); let fmt = CString::new ("Number: %d\n" ).unwrap (); printf (fmt.as_ptr (), 42 as c_int); } } fn rust_to_c_string (s: &str ) -> CString { CString::new (s).expect ("CString::new failed" ) } fn c_to_rust_string (ptr: *const c_char) -> String { unsafe { CStr::from_ptr (ptr) .to_string_lossy () .into_owned () } }
链接外部库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 fn main () { println! ("cargo:rustc-link-lib=m" ); println! ("cargo:rustc-link-lib=ssl" ); println! ("cargo:rustc-link-lib=static=mylib" ); println! ("cargo:rustc-link-search=native=/path/to/lib" ); } fn main () { cc::Build::new () .file ("src/native.c" ) .compile ("native" ); }
1 2 3 4 5 6 #include <stdint.h> int32_t add (int32_t a, int32_t b) { return a + b; }
1 2 3 4 5 6 7 8 9 10 extern "C" { fn add (a: i32 , b: i32 ) -> i32 ; } fn main () { unsafe { println! ("1 + 2 = {}" , add (1 , 2 )); } }
暴露 Rust 函数给 C 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #[no_mangle] pub extern "C" fn rust_add (a: i32 , b: i32 ) -> i32 { a + b } #[no_mangle] pub extern "C" fn rust_hello () { println! ("Hello from Rust!" ); } type Callback = extern "C" fn (i32 ) -> i32 ;#[no_mangle] pub extern "C" fn process_with_callback (x: i32 , cb: Callback) -> i32 { cb (x * 2 ) } use std::ffi::CString;use std::os::raw::c_char;#[no_mangle] pub extern "C" fn get_greeting () -> *mut c_char { let s = CString::new ("Hello from Rust!" ).unwrap (); s.into_raw () } #[no_mangle] pub extern "C" fn free_string (s: *mut c_char) { if !s.is_null () { unsafe { drop (CString::from_raw (s)); } } }
复杂数据结构传递 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 use std::os::raw::{c_char, c_int};#[repr(C)] pub struct Point { x: f64 , y: f64 , } #[repr(C)] pub struct Person { name: *const c_char, age: c_int, } extern "C" { fn process_point (p: Point) -> f64 ; fn process_point_ptr (p: *const Point) -> f64 ; } #[repr(C)] pub struct OpaqueHandle { _private: [u8 ; 0 ], } pub struct RealData { data: Vec <u8 >, name: String , } #[no_mangle] pub extern "C" fn create_handle () -> *mut OpaqueHandle { let data = Box ::new (RealData { data: vec! [1 , 2 , 3 ], name: "test" .to_string (), }); Box ::into_raw (data) as *mut OpaqueHandle } #[no_mangle] pub extern "C" fn destroy_handle (handle: *mut OpaqueHandle) { if !handle.is_null () { unsafe { drop (Box ::from_raw (handle as *mut RealData)); } } }
内联汇编 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 use std::arch::asm;fn main () { let x : u64 ; unsafe { asm!( "mov {}, 42" , out (reg) x, ); } println! ("x = {}" , x); let a : u64 = 10 ; let b : u64 = 20 ; let result : u64 ; unsafe { asm!( "add {0}, {1}" , inout (reg) a => result, in (reg) b, ); } println! ("10 + 20 = {}" , result); let value : u64 ; unsafe { asm!( "mov {tmp}, {x}" , "add {tmp}, {y}" , "mov {out}, {tmp}" , x = in (reg) 5u64 , y = in (reg) 6u64 , tmp = out (reg) _, out = out (reg) value, ); } println! ("5 + 6 = {}" , value); #[cfg(target_os = "linux" )] { let msg = "Hello from syscall!\n" ; let len = msg.len (); let ptr = msg.as_ptr (); unsafe { asm!( "syscall" , in ("rax" ) 1 , in ("rdi" ) 1 , in ("rsi" ) ptr, in ("rdx" ) len, out ("rcx" ) _, out ("r11" ) _, options (nostack), ); } } } #[cfg(target_arch = "x86_64" )] fn get_cpu_vendor () -> String { let mut ebx : u32 ; let mut ecx : u32 ; let mut edx : u32 ; unsafe { asm!( "cpuid" , inout ("eax" ) 0 => _, out ("ebx" ) ebx, out ("ecx" ) ecx, out ("edx" ) edx, ); } let vendor = [ebx, edx, ecx]; let bytes : &[u8 ] = unsafe { std::slice::from_raw_parts (vendor.as_ptr () as *const u8 , 12 ) }; String ::from_utf8_lossy (bytes).to_string () }
内存布局控制 repr 属性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #[repr(C)] struct CStruct { a: u8 , b: u32 , c: u16 , } #[repr(packed)] struct PackedStruct { a: u8 , b: u32 , c: u16 , } #[repr(align(16))] struct Aligned16 { data: [u8 ; 4 ], } #[repr(C, packed)] struct CPackedStruct { a: u8 , b: u32 , } #[repr(C, align(8))] struct CAligned8 { a: u32 , } #[repr(transparent)] struct Wrapper (u32 ); fn main () { use std::mem::{size_of, align_of}; println! ("CStruct: size={}, align={}" , size_of::<CStruct>(), align_of::<CStruct>()); println! ("PackedStruct: size={}, align={}" , size_of::<PackedStruct>(), align_of::<PackedStruct>()); println! ("Aligned16: size={}, align={}" , size_of::<Aligned16>(), align_of::<Aligned16>()); }
手动内存管理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 use std::alloc::{alloc, dealloc, realloc, Layout};use std::ptr;fn main () { unsafe { let layout = Layout::new::<u32 >(); let ptr = alloc (layout) as *mut u32 ; if ptr.is_null () { panic! ("内存分配失败" ); } ptr.write (42 ); println! ("value = {}" , ptr.read ()); dealloc (ptr as *mut u8 , layout); let layout = Layout::array::<i32 >(10 ).unwrap (); let arr = alloc (layout) as *mut i32 ; for i in 0 ..10 { arr.add (i).write (i as i32 ); } for i in 0 ..10 { print! ("{} " , arr.add (i).read ()); } println! (); dealloc (arr as *mut u8 , layout); let layout = Layout::array::<i32 >(5 ).unwrap (); let ptr = alloc (layout) as *mut i32 ; let new_layout = Layout::array::<i32 >(10 ).unwrap (); let new_ptr = realloc (ptr as *mut u8 , layout, new_layout.size ()) as *mut i32 ; dealloc (new_ptr as *mut u8 , new_layout); } } fn box_operations () { let ptr = Box ::into_raw (Box ::new (42 )); unsafe { println! ("value = {}" , *ptr); let _ = Box ::from_raw (ptr); } let layout = Layout::new::<[u8 ; 1024 ]>(); let ptr = unsafe { alloc (layout) }; unsafe { dealloc (ptr, layout) }; }
常见 Unsafe 模式 自引用结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 use std::pin::Pin;use std::marker::PhantomPinned;struct SelfReferential { data: String , ptr: *const String , _pin: PhantomPinned, } impl SelfReferential { fn new (data: String ) -> Pin<Box <Self >> { let mut boxed = Box ::new (SelfReferential { data, ptr: std::ptr::null (), _pin: PhantomPinned, }); let ptr = &boxed.data as *const String ; boxed.ptr = ptr; Box ::into_pin (boxed) } fn get_data (self : Pin<&Self >) -> &str { &self .data } fn get_ptr_data (self : Pin<&Self >) -> &str { unsafe { &*self .ptr } } }
内部可变性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 use std::cell::UnsafeCell;pub struct MyCell <T> { value: UnsafeCell<T>, } impl <T: Copy > MyCell<T> { pub fn new (value: T) -> Self { MyCell { value: UnsafeCell::new (value), } } pub fn get (&self ) -> T { unsafe { *self .value.get () } } pub fn set (&self , value: T) { unsafe { *self .value.get () = value; } } }
侵入式链表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 use std::ptr::NonNull;struct Node <T> { data: T, next: Option <NonNull<Node<T>>>, prev: Option <NonNull<Node<T>>>, } pub struct LinkedList <T> { head: Option <NonNull<Node<T>>>, tail: Option <NonNull<Node<T>>>, len: usize , } impl <T> LinkedList<T> { pub fn new () -> Self { LinkedList { head: None , tail: None , len: 0 , } } pub fn push_back (&mut self , data: T) { let node = Box ::new (Node { data, next: None , prev: self .tail, }); let node_ptr = NonNull::new (Box ::into_raw (node)); match self .tail { None => { self .head = node_ptr; } Some (mut tail) => unsafe { tail.as_mut ().next = node_ptr; } } self .tail = node_ptr; self .len += 1 ; } pub fn pop_front (&mut self ) -> Option <T> { self .head.map (|node| unsafe { let node = Box ::from_raw (node.as_ptr ()); self .head = node.next; match self .head { None => self .tail = None , Some (mut head) => head.as_mut ().prev = None , } self .len -= 1 ; node.data }) } } impl <T> Drop for LinkedList <T> { fn drop (&mut self ) { while self .pop_front ().is_some () {} } }
Unsafe 实践 最小化 unsafe 范围 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 unsafe fn bad_approach (data: &[u8 ]) -> u32 { let ptr = data.as_ptr () as *const u32 ; *ptr } fn good_approach (data: &[u8 ]) -> u32 { assert! (data.len () >= 4 , "数据太短" ); unsafe { let ptr = data.as_ptr () as *const u32 ; ptr.read_unaligned () } }
文档化安全约束 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 pub unsafe fn read_u32 (data: &[u8 ]) -> u32 { debug_assert! (data.len () >= 4 ); let ptr = data.as_ptr () as *const u32 ; ptr.read_unaligned () } pub fn safe_read_u32 (data: &[u8 ]) -> Option <u32 > { if data.len () >= 4 { Some (unsafe { read_u32 (data) }) } else { None } }
使用 debug_assert 1 2 3 4 5 6 7 8 pub fn get_unchecked <T>(slice: &[T], index: usize ) -> &T { debug_assert! (index < slice.len (), "索引越界" ); unsafe { slice.get_unchecked (index) } }
安全抽象模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 pub struct RingBuffer <T, const N: usize > { buffer: [std::mem::MaybeUninit<T>; N], head: usize , tail: usize , len: usize , } impl <T, const N: usize > RingBuffer<T, N> { pub fn new () -> Self { Self { buffer: unsafe { std::mem::MaybeUninit::uninit ().assume_init () }, head: 0 , tail: 0 , len: 0 , } } pub fn push (&mut self , item: T) -> Result <(), T> { if self .len == N { return Err (item); } unsafe { self .buffer[self .tail].as_mut_ptr ().write (item); } self .tail = (self .tail + 1 ) % N; self .len += 1 ; Ok (()) } pub fn pop (&mut self ) -> Option <T> { if self .len == 0 { return None ; } let item = unsafe { self .buffer[self .head].as_ptr ().read () }; self .head = (self .head + 1 ) % N; self .len -= 1 ; Some (item) } } impl <T, const N: usize > Drop for RingBuffer <T, N> { fn drop (&mut self ) { while self .pop ().is_some () {} } }
速查表
操作
是否需要 unsafe
创建裸指针
❌ 安全
解引用裸指针
✅ unsafe
调用 unsafe fn
✅ unsafe
实现 unsafe trait
✅ unsafe impl
读写 static mut
✅ unsafe
读取 union 字段
✅ unsafe
FFI 函数调用
✅ unsafe
内联汇编
✅ unsafe
transmute
✅ unsafe
from_raw_parts
✅ unsafe
关键函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 std::mem::transmute::<T, U>(value) std::mem::transmute_copy::<T, U>(&val) std::ptr::read (ptr) std::ptr::write (ptr, val) std::ptr::copy (src, dst, count) std::ptr::copy_nonoverlapping (...) std::ptr::swap (x, y) std::ptr::drop_in_place (ptr) std::slice::from_raw_parts (ptr, len) std::slice::from_raw_parts_mut (ptr, len)
Macro 宏编程 宏系统概览 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ┌─────────────────────────────────────────────────────────────────────┐ │ Rust 宏系统 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ 声明宏 (Declarative) │ 过程宏 (Procedural) │ │ macro_rules! │ │ │ ───────────────────────────────────────────────────────────── │ │ • 模式匹配 │ • 函数式宏 proc_macro │ │ • 代码模板替换 │ • derive 宏 proc_macro_derive │ │ • 编译时展开 │ • 属性宏 proc_macro_attribute│ │ │ ├─────────────────────────────────────────────────────────────────────┤ │ 调用方式 │ ├─────────────────────────────────────────────────────────────────────┤ │ macro!() macro![] macro!{} │ │ #[derive(Mac)] #[mac] #[mac(...)] │ └─────────────────────────────────────────────────────────────────────┘
宏 vs 函数
特性
宏
函数
执行时机
编译时
运行时
参数数量
可变
固定
类型检查
展开后检查
调用时检查
代码生成
✅
❌
调试难度
较高
较低
声明宏 (macro_rules!) 基础语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 macro_rules! say_hello { () => { println! ("Hello!" ); }; } macro_rules! say { ($msg:expr) => { println! ("{}" , $msg); }; } macro_rules! greet { () => { println! ("Hello, World!" ); }; ($name:expr) => { println! ("Hello, {}!" , $name); }; ($name:expr, $times:expr) => { for _ in 0 ..$times { println! ("Hello, {}!" , $name); } }; } fn main () { say_hello!(); say!("Hi there" ); greet!(); greet!("Alice" ); greet!("Bob" , 3 ); }
元变量类型 (Fragment Specifiers) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 macro_rules! demo_fragments { (expr: $e:expr) => { println! ("expr: {:?}" , $e) }; (ident: $i:ident) => { let $i = 42 ; }; (ty: $t:ty) => { let _ : $t; }; (pat: $p:pat) => { let $p = (1 , 2 ); }; (stmt: $s:stmt) => { $s }; (block: $b:block) => { $b }; (item: $i:item) => { $i }; (path: $p:path) => { type Alias = $p; }; (tt: $t:tt) => { $t }; (lit: $l:literal) => { println! ("{}" , $l) }; (lt: $lt:lifetime) => { fn foo <$lt>() {} }; (meta: $m:meta) => { #[$m] struct S ; }; (vis: $v:vis) => { $v fn visible () {} }; } fn main () { demo_fragments!(expr: 1 + 2 ); demo_fragments!(ident: my_var); demo_fragments!(ty: Vec <i32 >); demo_fragments!(pat: (a, b)); demo_fragments!(stmt: let x = 5 ); demo_fragments!(block: { println! ("block" ); }); demo_fragments!(lit: "hello" ); }
重复模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 macro_rules! vec_of_strings { ($($x:expr),*) => { vec! [$($x.to_string ()),*] }; } macro_rules! sum { ($($x:expr),+) => { { let mut total = 0 ; $(total += $x;)+ total } }; } macro_rules! optional_param { ($name:ident $(: $ty:ty)?) => { struct $name { value: $($ty)? } }; } macro_rules! hash_map { ($($key:expr => $value:expr),* $(,)?) => {{ let mut map = std::collections::HashMap::new (); $(map.insert ($key, $value);)* map }}; } fn main () { let v = vec_of_strings!["a" , "b" , "c" ]; println! ("{:?}" , v); let total = sum!(1 , 2 , 3 , 4 , 5 ); println! ("sum: {}" , total); let map = hash_map! { "one" => 1 , "two" => 2 , "three" => 3 , }; println! ("{:?}" , map); }
实用宏示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 macro_rules! dbg_vars { ($($var:ident),+ $(,)?) => { $( println! ("{} = {:?}" , stringify! ($var), $var); )+ }; } macro_rules! define_enum { ( $(#[$meta:meta] )* $vis:vis enum $name:ident { $($variant:ident),* $(,)? } ) => { $(#[$meta] )* $vis enum $name { $($variant),* } impl $name { pub fn as_str (&self ) -> &'static str { match self { $(Self ::$variant => stringify! ($variant)),* } } pub fn variants () -> &'static [&'static str ] { &[$(stringify! ($variant)),*] } } impl std ::fmt::Display for $name { fn fmt (&self , f: &mut std::fmt::Formatter) -> std::fmt::Result { write! (f, "{}" , self .as_str ()) } } }; } define_enum! { #[derive(Debug, Clone, Copy)] pub enum Color { Red, Green, Blue, } } macro_rules! builder { ( $struct_name:ident { $($field:ident : $type :ty),* $(,)? } ) => { pub struct $struct_name { $($field: $type ),* } paste::paste! { pub struct [<$struct_name Builder>] { $($field: Option <$type >),* } impl [<$struct_name Builder>] { pub fn new () -> Self { Self { $($field: None ),* } } $( pub fn $field (mut self , value: $type ) -> Self { self .$field = Some (value); self } )* pub fn build (self ) -> Result <$struct_name, &'static str > { Ok ($struct_name { $($field: self .$field.ok_or (concat! (stringify! ($field), " is required" ))?),* }) } } } }; } macro_rules! test_cases { ($test_fn:ident: $($name:ident => ($($input:expr),*) == $expected:expr);+ $(;)?) => { $( #[test] fn $name () { assert_eq! ($test_fn ($($input),*), $expected); } )+ }; } fn add (a: i32 , b: i32 ) -> i32 { a + b }test_cases! { add: test_add_positive => (2 , 3 ) == 5 ; test_add_negative => (-1 , -1 ) == -2 ; test_add_zero => (0 , 0 ) == 0 ; } fn main () { let x = 42 ; let name = "Alice" ; dbg_vars!(x, name); let color = Color::Red; println! ("{}" , color); println! ("{:?}" , Color::variants ()); }
递归宏 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 macro_rules! count { () => { 0usize }; ($head:tt $($tail:tt)*) => { 1usize + count!($($tail)*) }; } macro_rules! tuple_index { ($tuple:expr; $($idx:tt),+ $(,)?) => { ($($tuple.$idx),+) }; } macro_rules! nested_vec { ($elem:expr) => { $elem }; ($head:expr, $($tail:expr),+) => { vec! [nested_vec!($head), nested_vec!($($tail),+)] }; } macro_rules! impl_trait_for { ($trait_name:ident for $($ty:ty),+ $(,)?) => { $( impl $trait_name for $ty {} )+ }; } trait Printable {}impl_trait_for!(Printable for i32 , i64 , f32 , f64 , String ); fn main () { let n = count!(a b c d e); println! ("count: {}" , n); let tuple = (1 , "hello" , 3.14 , true ); let selected = tuple_index!(tuple; 0 , 2 ); println! ("{:?}" , selected); }
宏的卫生性 (Hygiene) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 macro_rules! using_a { ($e:expr) => { { let a = 42 ; $e } }; } fn main () { let a = 10 ; let result = using_a!(a * 2 ); println! ("{}" , result); } macro_rules! declare_var { ($name:ident, $value:expr) => { let $name = $value; }; } fn main () { declare_var!(x, 100 ); println! ("{}" , x); }
过程宏 (Procedural Macros) 项目结构 1 2 3 4 5 6 7 8 9 my_macros/ ├── Cargo.toml └── src/ └── lib.rs my_app/ ├── Cargo.toml └── src/ └── main.rs
1 2 3 4 5 6 7 8 9 10 11 12 13 [package] name = "my_macros" version = "0.1.0" edition = "2021" [lib] proc-macro = true [dependencies] syn = { version = "2" , features = ["full" ] }quote = "1" proc-macro2 = "1"
函数式过程宏 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 use proc_macro::TokenStream;use quote::quote;use syn::{parse_macro_input, LitStr};#[proc_macro] pub fn make_hello (input: TokenStream) -> TokenStream { let name = parse_macro_input!(input as LitStr); let name_value = name.value (); let expanded = quote! { fn hello () { println! ("Hello, {}!" , #name_value); } }; expanded.into () } #[proc_macro] pub fn sql (input: TokenStream) -> TokenStream { let input_str = input.to_string (); if !input_str.to_uppercase ().starts_with ("SELECT" ) { return syn::Error::new ( proc_macro2::Span::call_site (), "SQL must start with SELECT" ) .to_compile_error () .into (); } let expanded = quote! { { let query = #input_str; query } }; expanded.into () } use syn::parse::{Parse, ParseStream};use syn::{Ident, Token, Expr};struct MathExpr { left: Expr, op: Ident, right: Expr, } impl Parse for MathExpr { fn parse (input: ParseStream) -> syn::Result <Self > { let left = input.parse ()?; input.parse::<Token![,]>()?; let op = input.parse ()?; input.parse::<Token![,]>()?; let right = input.parse ()?; Ok (MathExpr { left, op, right }) } } #[proc_macro] pub fn math (input: TokenStream) -> TokenStream { let MathExpr { left, op, right } = parse_macro_input!(input as MathExpr); let op_str = op.to_string (); let expanded = match op_str.as_str () { "add" => quote! { #left + #right }, "sub" => quote! { #left - #right }, "mul" => quote! { #left * #right }, "div" => quote! { #left / #right }, _ => { return syn::Error::new (op.span (), "Unknown operation" ) .to_compile_error () .into (); } }; expanded.into () }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 use my_macros::{make_hello, sql, math};make_hello!("World" ); fn main () { hello (); let query = sql!(SELECT * FROM users WHERE id = 1 ); println! ("{}" , query); let result = math!(10 , add, 5 ); println! ("{}" , result); }
Derive 宏 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 use proc_macro::TokenStream;use quote::quote;use syn::{parse_macro_input, DeriveInput, Data, Fields};#[proc_macro_derive(HelloMacro)] pub fn hello_macro_derive (input: TokenStream) -> TokenStream { let input = parse_macro_input!(input as DeriveInput); let name = input.ident; let expanded = quote! { impl HelloMacro for #name { fn hello_macro () { println! ("Hello, Macro! My name is {}" , stringify! (#name)); } } }; expanded.into () } #[proc_macro_derive(Builder, attributes(builder))] pub fn builder_derive (input: TokenStream) -> TokenStream { let input = parse_macro_input!(input as DeriveInput); let name = &input.ident; let builder_name = syn::Ident::new ( &format! ("{}Builder" , name), name.span () ); let fields = match &input.data { Data::Struct (data) => match &data.fields { Fields::Named (fields) => &fields.named, _ => panic! ("Only named fields are supported" ), }, _ => panic! ("Only structs are supported" ), }; let builder_fields = fields.iter ().map (|f| { let name = &f.ident; let ty = &f.ty; quote! { #name: Option <#ty> } }); let setters = fields.iter ().map (|f| { let name = &f.ident; let ty = &f.ty; quote! { pub fn #name (mut self , value: #ty) -> Self { self .#name = Some (value); self } } }); let build_fields = fields.iter ().map (|f| { let name = &f.ident; quote! { #name: self .#name.ok_or (concat! (stringify! (#name), " is not set" ))? } }); let init_fields = fields.iter ().map (|f| { let name = &f.ident; quote! { #name: None } }); let expanded = quote! { pub struct #builder_name { #(#builder_fields),* } impl #builder_name { #(#setters)* pub fn build (self ) -> Result <#name, &'static str > { Ok (#name { #(#build_fields),* }) } } impl #name { pub fn builder () -> #builder_name { #builder_name { #(#init_fields),* } } } }; expanded.into () } #[proc_macro_derive(MyDebug)] pub fn my_debug_derive (input: TokenStream) -> TokenStream { let input = parse_macro_input!(input as DeriveInput); let name = &input.ident; let fields = match &input.data { Data::Struct (data) => match &data.fields { Fields::Named (fields) => fields.named.iter ().map (|f| { let name = &f.ident; quote! { .field (stringify! (#name), &self .#name) } }).collect::<Vec <_>>(), Fields::Unnamed (fields) => fields.unnamed.iter ().enumerate ().map (|(i, _)| { let index = syn::Index::from (i); quote! { .field (&self .#index) } }).collect::<Vec <_>>(), Fields::Unit => vec! [], }, _ => panic! ("Only structs are supported" ), }; let expanded = quote! { impl std ::fmt::Debug for #name { fn fmt (&self , f: &mut std::fmt::Formatter<'_ >) -> std::fmt::Result { f.debug_struct (stringify! (#name)) #(#fields)* .finish () } } }; expanded.into () }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 use my_macros::{HelloMacro, Builder, MyDebug};trait HelloMacro { fn hello_macro (); } #[derive(HelloMacro)] struct Pancakes ;#[derive(Builder)] struct Command { executable: String , args: Vec <String >, current_dir: String , } #[derive(MyDebug)] struct Point { x: i32 , y: i32 , } fn main () { Pancakes::hello_macro (); let cmd = Command::builder () .executable ("cargo" .to_string ()) .args (vec! ["build" .to_string ()]) .current_dir ("." .to_string ()) .build () .unwrap (); let point = Point { x: 10 , y: 20 }; println! ("{:?}" , point); }
属性宏 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 use proc_macro::TokenStream;use quote::quote;use syn::{parse_macro_input, ItemFn, AttributeArgs, NestedMeta, Lit, Meta};#[proc_macro_attribute] pub fn log_call (_attr: TokenStream, item: TokenStream) -> TokenStream { let input = parse_macro_input!(item as ItemFn); let fn_name = &input.sig.ident; let fn_block = &input.block; let fn_sig = &input.sig; let fn_vis = &input.vis; let expanded = quote! { #fn_vis #fn_sig { println! ("[LOG] Entering {}" , stringify! (#fn_name)); let result = (|| #fn_block)(); println! ("[LOG] Exiting {}" , stringify! (#fn_name)); result } }; expanded.into () } #[proc_macro_attribute] pub fn retry (attr: TokenStream, item: TokenStream) -> TokenStream { let args = parse_macro_input!(attr as AttributeArgs); let input = parse_macro_input!(item as ItemFn); let mut retries = 3usize ; for arg in args { if let NestedMeta ::Meta (Meta::NameValue (nv)) = arg { if nv.path.is_ident ("times" ) { if let Lit ::Int (lit) = nv.lit { retries = lit.base10_parse ().unwrap (); } } } } let fn_name = &input.sig.ident; let fn_block = &input.block; let fn_sig = &input.sig; let fn_vis = &input.vis; let expanded = quote! { #fn_vis #fn_sig { let mut attempts = 0 ; loop { attempts += 1 ; let result = (|| #fn_block)(); if result.is_ok () || attempts >= #retries { return result; } println! ("[RETRY] {} attempt {} failed" , stringify! (#fn_name), attempts); } } }; expanded.into () } #[proc_macro_attribute] pub fn route (attr: TokenStream, item: TokenStream) -> TokenStream { let attr_str = attr.to_string (); let input = parse_macro_input!(item as ItemFn); let fn_name = &input.sig.ident; let parts : Vec <&str > = attr_str.split (',' ).map (|s| s.trim ().trim_matches ('"' )).collect (); let method = parts.get (0 ).unwrap_or (&"GET" ); let path = parts.get (1 ).unwrap_or (&"/" ); let expanded = quote! { #input inventory::submit! { Route { method: #method, path: #path, handler: #fn_name, } } }; expanded.into () } #[proc_macro_attribute] pub fn test_case (attr: TokenStream, item: TokenStream) -> TokenStream { let input = parse_macro_input!(item as ItemFn); let fn_name = &input.sig.ident; let fn_block = &input.block; let test_name = syn::Ident::new ( &format! ("test_{}" , fn_name), fn_name.span () ); let expanded = quote! { #input #[test] fn #test_name () { #fn_block } }; expanded.into () }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 use my_macros::{log_call, retry, route};#[log_call] fn compute (x: i32 ) -> i32 { x * 2 } #[retry(times = 5)] fn fetch_data () -> Result <String , &'static str > { Err ("network error" ) } #[route("GET" , "/users" )] fn get_users () -> Vec <String > { vec! ["Alice" .to_string (), "Bob" .to_string ()] } fn main () { compute (21 ); }
syn 和 quote 深入 syn - 解析 Rust 代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 use syn::{ parse_macro_input, DeriveInput, Data, Fields, Type, Attribute, Expr, Lit, Meta, NestedMeta, ItemStruct, ItemFn, ItemEnum, Generics, GenericParam, TypeParam, }; fn parse_struct (input: DeriveInput) { let name = input.ident; let generics = input.generics; let attrs = input.attrs; for param in generics.params { match param { GenericParam::Type (TypeParam { ident, .. }) => { println! ("Type param: {}" , ident); } GenericParam::Lifetime (lt) => { println! ("Lifetime: {}" , lt.lifetime); } GenericParam::Const (c) => { println! ("Const: {}" , c.ident); } } } if let Data ::Struct (data) = input.data { match data.fields { Fields::Named (fields) => { for field in fields.named { let field_name = field.ident.unwrap (); let field_type = field.ty; println! ("Field: {} : {:?}" , field_name, field_type); } } Fields::Unnamed (fields) => { for (i, field) in fields.unnamed.iter ().enumerate () { println! ("Field {}: {:?}" , i, field.ty); } } Fields::Unit => println! ("Unit struct" ), } } } fn parse_attributes (attrs: &[Attribute]) { for attr in attrs { if attr.path.is_ident ("derive" ) { println! ("Found derive attribute" ); } if attr.path.is_ident ("my_attr" ) { if let Ok (Meta::List (list)) = attr.parse_meta () { for nested in list.nested { if let NestedMeta ::Meta (Meta::NameValue (nv)) = nested { if nv.path.is_ident ("key" ) { if let Lit ::Str (s) = nv.lit { println! ("key = {}" , s.value ()); } } } } } } } } fn analyze_type (ty: &Type) { match ty { Type::Path (type_path) => { if let Some (segment) = type_path.path.segments.last () { println! ("Type: {}" , segment.ident); if segment.ident == "Option" { println! ("This is an Option type" ); } } } Type::Reference (reference) => { println! ("Reference type, mutable: {}" , reference.mutability.is_some ()); } Type::Array (array) => { println! ("Array type" ); } _ => {} } }
quote - 生成代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 use quote::{quote, quote_spanned, format_ident, ToTokens};use proc_macro2::{Span, TokenStream};fn basic_quote () -> TokenStream { let name = format_ident!("MyStruct" ); let field = format_ident!("value" ); let ty = quote! { i32 }; quote! { struct #name { #field: #ty, } } } fn quote_repetition (names: &[&str ]) -> TokenStream { let fields = names.iter ().map (|name| { let ident = format_ident!("{}" , name); quote! { #ident: String } }); let inits = names.iter ().map (|name| { let ident = format_ident!("{}" , name); quote! { #ident: String ::new () } }); quote! { struct MyStruct { #(#fields),* } impl Default for MyStruct { fn default () -> Self { Self { #(#inits),* } } } } } fn conditional_quote (include_debug: bool ) -> TokenStream { let debug_impl = if include_debug { Some (quote! { impl std ::fmt::Debug for MyStruct { fn fmt (&self , f: &mut std::fmt::Formatter<'_ >) -> std::fmt::Result { write! (f, "MyStruct" ) } } }) } else { None }; quote! { struct MyStruct ; #debug_impl } } fn quote_with_span (field_name: &syn::Ident, field_type: &syn::Type) -> TokenStream { quote_spanned! {field_name.span ()=> impl HasField for MyStruct { type FieldType = #field_type; fn get_field (&self ) -> &Self ::FieldType { &self .#field_name } } } } fn nested_quote () -> TokenStream { let inner = quote! { println! ("inner" ) }; let outer = quote! { fn wrapper () { #inner } }; outer }
高级模式与技巧 TT Muncher(Token 咀嚼器) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 macro_rules! parse_commands { () => {}; (SET $key:ident = $value:expr; $($rest:tt)*) => { println! ("Setting {} = {:?}" , stringify! ($key), $value); parse_commands!($($rest)*); }; (GET $key:ident; $($rest:tt)*) => { println! ("Getting {}" , stringify! ($key)); parse_commands!($($rest)*); }; (DELETE $key:ident; $($rest:tt)*) => { println! ("Deleting {}" , stringify! ($key)); parse_commands!($($rest)*); }; } fn main () { parse_commands! { SET name = "Alice" ; SET age = 30 ; GET name; DELETE age; } }
Push-Down Accumulator(下推累加器) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 macro_rules! reverse { ([$($input:tt)*]) => { reverse!([$($input)*] -> []) }; ([] -> [$($output:tt)*]) => { ($($output)*) }; ([$head:tt $($tail:tt)*] -> [$($output:tt)*]) => { reverse!([$($tail)*] -> [$head $($output)*]) }; } fn main () { let reversed = reverse!([1 2 3 4 5 ]); } macro_rules! nested { ($($items:tt)*) => { nested!(@build [] $($items)*) }; (@build [$($acc:tt)*]) => { $($acc)* }; (@build [$($acc:tt)*] $item:tt $($rest:tt)*) => { nested!(@build [{ $item $($acc)* }] $($rest)*) }; }
内部规则模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 macro_rules! complex_macro { ($($input:tt)*) => { complex_macro!(@parse $($input)*) }; (@parse struct $name:ident { $($fields:tt)* }) => { complex_macro!(@gen_struct $name [] $($fields)*) }; (@gen_struct $name:ident [$($processed:tt)*]) => { struct $name { $($processed)* } }; (@gen_struct $name:ident [$($processed:tt)*] $field:ident : $ty:ty, $($rest:tt)*) => { complex_macro!(@gen_struct $name [$($processed)* $field: $ty,] $($rest)*) }; (@gen_struct $name:ident [$($processed:tt)*] $field:ident : $ty:ty) => { complex_macro!(@gen_struct $name [$($processed)* $field: $ty,]) }; } complex_macro! { struct User { name: String , age: u32 } }
Callback 模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 macro_rules! call_with_result { ($callback:ident, $($input:tt)*) => { $callback!([ processed: $($input)* ]) }; } macro_rules! my_callback { ([ processed: $($data:tt)* ]) => { println! ("Received: {}" , stringify! ($($data)*)); }; } fn main () { call_with_result!(my_callback, hello world); }
调试宏 展开宏 1 2 3 4 5 6 7 8 9 cargo install cargo-expand cargo expand cargo expand module_name cargo expand --test test_name
编译时调试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 macro_rules! debug_macro { ($($tokens:tt)*) => { compile_error!(concat! ("Input: " , stringify! ($($tokens)*))); }; } #![feature(trace_macros)] trace_macros!(true ); my_macro!(some input); trace_macros!(false ); #![feature(log_syntax)] macro_rules! debug { ($($t:tt)*) => { log_syntax!($($t)*); }; }
过程宏调试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #[proc_macro_derive(MyDerive)] pub fn my_derive (input: TokenStream) -> TokenStream { eprintln!("Input: {:#?}" , input); let input = parse_macro_input!(input as DeriveInput); eprintln!("Parsed: {:#?}" , input); let expanded = quote! { }; eprintln!("Output: {}" , expanded); expanded.into () }
实战示例 完整的 Derive 宏:自动实现 From 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 use proc_macro::TokenStream;use quote::quote;use syn::{parse_macro_input, DeriveInput, Data, Fields, Type, Path};#[proc_macro_derive(AutoFrom, attributes(from))] pub fn auto_from_derive (input: TokenStream) -> TokenStream { let input = parse_macro_input!(input as DeriveInput); let name = &input.ident; let Data ::Struct (data) = &input.data else { return syn::Error::new_spanned (&input, "AutoFrom only works on structs" ) .to_compile_error () .into (); }; let Fields ::Named (fields) = &data.fields else { return syn::Error::new_spanned (&input, "AutoFrom requires named fields" ) .to_compile_error () .into (); }; let mut from_impls = Vec ::new (); for field in &fields.named { let field_name = field.ident.as_ref ().unwrap (); let field_type = &field.ty; let has_from = field.attrs.iter ().any (|attr| attr.path.is_ident ("from" )); if has_from { let other_fields = fields.named.iter () .filter (|f| f.ident.as_ref () != Some (field_name)) .map (|f| { let name = &f.ident; quote! { #name: Default ::default () } }); from_impls.push (quote! { impl From <#field_type> for #name { fn from (value: #field_type) -> Self { Self { #field_name: value, #(#other_fields),* } } } }); } } let expanded = quote! { #(#from_impls)* }; expanded.into () }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 use my_macros::AutoFrom;#[derive(AutoFrom, Default, Debug)] struct User { #[from] name: String , #[from] age: u32 , active: bool , } fn main () { let user1 : User = "Alice" .to_string ().into (); let user2 : User = 25u32 .into (); println! ("{:?}" , user1); println! ("{:?}" , user2); }
DSL:查询构建器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 macro_rules! query { ( SELECT $($col:ident),+ FROM $table:ident $(WHERE $($cond:tt)+)? $(ORDER BY $order_col:ident $order_dir:ident)? $(LIMIT $limit:expr)? ) => {{ let mut q = format! ( "SELECT {} FROM {}" , vec! [$(stringify! ($col)),+].join (", " ), stringify! ($table) ); $( q.push_str (&format! (" WHERE {}" , stringify! ($($cond)+))); )? $( q.push_str (&format! (" ORDER BY {} {}" , stringify! ($order_col), stringify! ($order_dir) )); )? $( q.push_str (&format! (" LIMIT {}" , $limit)); )? q }}; } fn main () { let q1 = query!( SELECT id, name, email FROM users WHERE id > 10 AND active = true ORDER BY name ASC LIMIT 10 ); println! ("{}" , q1); }
类型安全的 HTML 构建器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 macro_rules! html { ($text:literal) => { $text.to_string () }; ($tag:ident) => { format! ("<{}></{}>" , stringify! ($tag), stringify! ($tag)) }; ($tag:ident [$($attr:ident = $value:expr),* $(,)?]) => { format! ( "<{} {}></{}>" , stringify! ($tag), vec! [$(format! ("{}=\"{}\"" , stringify! ($attr), $value)),*].join (" " ), stringify! ($tag) ) }; ($tag:ident { $($child:tt)* }) => { format! ( "<{}>{}</{}>" , stringify! ($tag), html!(@children $($child)*), stringify! ($tag) ) }; ($tag:ident [$($attr:ident = $value:expr),* $(,)?] { $($child:tt)* }) => { format! ( "<{} {}>{}</{}>" , stringify! ($tag), vec! [$(format! ("{}=\"{}\"" , stringify! ($attr), $value)),*].join (" " ), html!(@children $($child)*), stringify! ($tag) ) }; (@children) => { String ::new () }; (@children $tag:ident $($rest:tt)*) => { format! ("{}{}" , html!($tag), html!(@children $($rest)*)) }; (@children $tag:ident [$($attr:tt)*] $($rest:tt)*) => { format! ("{}{}" , html!($tag [$($attr)*]), html!(@children $($rest)*)) }; (@children $tag:ident { $($inner:tt)* } $($rest:tt)*) => { format! ("{}{}" , html!($tag { $($inner)* }), html!(@children $($rest)*)) }; (@children $tag:ident [$($attr:tt)*] { $($inner:tt)* } $($rest:tt)*) => { format! ("{}{}" , html!($tag [$($attr)*] { $($inner)* }), html!(@children $($rest)*)) }; (@children $text:literal $($rest:tt)*) => { format! ("{}{}" , $text, html!(@children $($rest)*)) }; } fn main () { let page = html!( html { head { title { "My Page" } } body { h1 [class = "title" ] { "Hello" } div [id = "content" , class = "container" ] { p { "Welcome to my page!" } a [href = "https://example.com" ] { "Click here" } } } } ); println! ("{}" , page); }
常用宏 Crate
Crate
用途
syn解析 Rust 代码
quote生成 Rust 代码
proc-macro2TokenStream 处理
darling简化属性解析
paste标识符拼接
thiserror错误类型派生
serde序列化派生
darling 示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 use darling::{FromDeriveInput, FromField};use proc_macro::TokenStream;use quote::quote;use syn::{parse_macro_input, DeriveInput};#[derive(FromDeriveInput)] #[darling(attributes(my_attr))] struct MyInputReceiver { ident: syn::Ident, data: darling::ast::Data<(), MyFieldReceiver>, #[darling(default)] rename: Option <String >, } #[derive(FromField)] #[darling(attributes(my_attr))] struct MyFieldReceiver { ident: Option <syn::Ident>, ty: syn::Type, #[darling(default)] skip: bool , } #[proc_macro_derive(MyDerive, attributes(my_attr))] pub fn my_derive (input: TokenStream) -> TokenStream { let input = parse_macro_input!(input as DeriveInput); let receiver = MyInputReceiver::from_derive_input (&input).unwrap (); let name = &receiver.ident; let rename = receiver.rename.as_ref ().map (|r| quote! { #r }).unwrap_or (quote! { stringify! (#name) }); quote! { impl Named for #name { fn name (&self ) -> &'static str { #rename } } }.into () }
速查表 声明宏元变量
类型
说明
示例
expr表达式
1 + 2, foo()
ident标识符
foo, x
ty类型
i32, Vec<T>
pat模式
Some(x), _
stmt语句
let x = 1;
block代码块
{ ... }
item项
fn foo() {}
path路径
std::io::Result
ttToken Tree
任何单个 token
literal字面量
"hello", 42
lifetime生命周期
'a
meta属性元数据
derive(Debug)
vis可见性
pub, pub(crate)
重复符号
符号
含义
$(...)*零次或多次
$(...)+一次或多次
$(...)?零次或一次
过程宏类型
类型
属性
用途
函数式
#[proc_macro]自定义语法
Derive
#[proc_macro_derive]自动实现 trait
属性
#[proc_macro_attribute]修改/增强代码
自动化测试 测试体系概览 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ┌─────────────────────────────────────────────────────────────────────┐ │ Rust 测试金字塔 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────┐ │ │ │ E2E │ ← 端到端测试(最少) │ │ ┌─┴─────────┴─┐ │ │ │ 集成测试 │ ← tests/ 目录 │ │ ┌─┴─────────────┴─┐ │ │ │ 单元测试 │ ← #[cfg(test)] mod tests │ │ ┌─┴─────────────────┴─┐ │ │ │ 文档测试 │ ← /// ``` 代码块 │ │ └─────────────────────┘ │ │ │ ├─────────────────────────────────────────────────────────────────────┤ │ 项目结构 │ ├─────────────────────────────────────────────────────────────────────┤ │ my_project/ │ │ ├── Cargo.toml │ │ ├── src/ │ │ │ ├── lib.rs ← 单元测试 + 文档测试 │ │ │ └── main.rs │ │ ├── tests/ ← 集成测试 │ │ │ ├── integration_test.rs │ │ │ └── common/mod.rs ← 测试辅助模块 │ │ └── benches/ ← 基准测试 │ │ └── benchmark.rs │ └─────────────────────────────────────────────────────────────────────┘
单元测试基础 基本语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 pub fn add (a: i32 , b: i32 ) -> i32 { a + b } pub fn divide (a: f64 , b: f64 ) -> Option <f64 > { if b == 0.0 { None } else { Some (a / b) } } #[cfg(test)] mod tests { use super::*; #[test] fn test_add () { assert_eq! (add (2 , 3 ), 5 ); } #[test] fn test_add_negative () { assert_eq! (add (-1 , -1 ), -2 ); } #[test] fn test_divide () { assert_eq! (divide (10.0 , 2.0 ), Some (5.0 )); } #[test] fn test_divide_by_zero () { assert_eq! (divide (10.0 , 0.0 ), None ); } }
断言宏 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #[cfg(test)] mod tests { #[test] fn test_assertions () { assert! (true ); assert! (1 + 1 == 2 ); assert_eq! (4 , 2 + 2 ); assert_ne! (4 , 2 + 1 ); let x = 5 ; assert! (x > 0 , "x should be positive, but got {}" , x); assert_eq! (x, 5 , "Expected 5, got {}" , x); let a = 0.1 + 0.2 ; let b = 0.3 ; assert! ((a - b).abs () < f64 ::EPSILON); } #[test] fn test_debug_assertions () { debug_assert! (true ); debug_assert_eq! (1 , 1 ); debug_assert_ne! (1 , 2 ); } }
测试属性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #[cfg(test)] mod tests { #[test] #[should_panic] fn test_panic () { panic! ("This test should panic" ); } #[test] #[should_panic(expected = "divide by zero" )] fn test_panic_message () { panic! ("divide by zero error" ); } #[test] #[ignore] fn expensive_test () { std::thread::sleep (std::time::Duration::from_secs (10 )); } #[test] #[ignore = "需要外部服务" ] fn test_external_service () { } #[test] fn test_with_result () -> Result <(), String > { if 2 + 2 == 4 { Ok (()) } else { Err ("math is broken" .to_string ()) } } #[test] fn test_with_question_mark () -> Result <(), Box <dyn std::error::Error>> { let value : i32 = "42" .parse ()?; assert_eq! (value, 42 ); Ok (()) } }
测试私有函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 fn internal_add (a: i32 , b: i32 ) -> i32 { a + b } pub fn public_add (a: i32 , b: i32 ) -> i32 { internal_add (a, b) } #[cfg(test)] mod tests { use super::*; #[test] fn test_internal_add () { assert_eq! (internal_add (1 , 2 ), 3 ); } }
集成测试 基本结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 use my_project::{add, divide};#[test] fn test_add_integration () { assert_eq! (add (10 , 20 ), 30 ); } #[test] fn test_divide_integration () { assert_eq! (divide (100.0 , 4.0 ), Some (25.0 )); }
共享测试辅助代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 pub struct TestContext { pub temp_dir: std::path::PathBuf, } impl TestContext { pub fn new () -> Self { let temp_dir = std::env::temp_dir ().join (format! ("test_{}" , rand::random::<u32 >())); std::fs::create_dir_all (&temp_dir).unwrap (); TestContext { temp_dir } } pub fn create_file (&self , name: &str , content: &str ) -> std::path::PathBuf { let path = self .temp_dir.join (name); std::fs::write (&path, content).unwrap (); path } } impl Drop for TestContext { fn drop (&mut self ) { let _ = std::fs::remove_dir_all (&self .temp_dir); } } pub fn setup () { } mod common;use common::TestContext;#[test] fn test_file_operations () { common::setup (); let ctx = TestContext::new (); let file = ctx.create_file ("test.txt" , "hello" ); assert! (file.exists ()); }
子目录组织 1 2 3 4 5 6 7 8 tests/ ├── api/ │ ├── mod.rs ← 声明子模块 │ ├── users_test.rs │ └── orders_test.rs ├── common/ │ └── mod.rs └── api_tests.rs ← 入口文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 mod common;mod api;mod users_test;mod orders_test;use crate::common::TestContext;#[test] fn test_create_user () { }
文档测试 基本文档测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 pub fn add (a: i32 , b: i32 ) -> i32 { a + b } pub fn divide (a: f64 , b: f64 ) -> Option <f64 > { if b == 0.0 { None } else { Some (a / b) } }
文档测试属性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 pub fn example () {}
文档测试中使用 ? 操作符 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 pub fn parse_config (input: &str ) -> Result <std::collections::HashMap<String , String >, &'static str > { Ok (std::collections::HashMap::new ()) }
运行测试 cargo test 命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 cargo test cargo test test_name cargo test test_add cargo test tests:: cargo test --test integration_test cargo test --doc cargo test --lib cargo test -- --ignored cargo test -- --include-ignored cargo test -- --nocapture cargo test -- --test-threads=1 cargo test -- --list cargo test --no-run cargo test --release cargo test -- --show-output
测试过滤 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #[cfg(test)] mod tests { #[test] fn test_feature_a_basic () {} #[test] fn test_feature_a_advanced () {} #[test] fn test_feature_b_basic () {} #[test] #[ignore] fn test_slow () {} }
1 2 3 4 5 6 7 8 9 10 11 cargo test feature_a cargo test -- --exact test_feature_a_basic cargo test -- --skip feature_b cargo test feature_a -- --skip advanced
异步测试 使用 tokio 1 2 [dev-dependencies] tokio = { version = "1" , features = ["full" , "test-util" ] }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #[tokio::test] async fn test_async_function () { let result = async_add (1 , 2 ).await ; assert_eq! (result, 3 ); } async fn async_add (a: i32 , b: i32 ) -> i32 { tokio::time::sleep (std::time::Duration::from_millis (10 )).await ; a + b } #[tokio::test(flavor = "multi_thread" , worker_threads = 2)] async fn test_multi_thread () { } #[tokio::test(flavor = "current_thread" )] async fn test_single_thread () { } #[tokio::test] async fn test_with_timeout () { let result = tokio::time::timeout ( std::time::Duration::from_secs (5 ), async_operation () ).await ; assert! (result.is_ok ()); } async fn async_operation () -> i32 { 42 }
使用 async-std 1 2 [dev-dependencies] async-std = { version = "1" , features = ["attributes" ] }
1 2 3 4 5 #[async_std::test] async fn test_with_async_std () { let result = async { 42 }.await ; assert_eq! (result, 42 ); }
测试异步流 1 2 3 4 5 6 7 8 use tokio_stream::StreamExt;#[tokio::test] async fn test_stream () { let stream = tokio_stream::iter (vec! [1 , 2 , 3 , 4 , 5 ]); let sum : i32 = stream.fold (0 , |acc, x| async move { acc + x }).await ; assert_eq! (sum, 15 ); }
测试组织与模式 Setup 和 Teardown 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #[cfg(test)] mod tests { use std::sync::Once; static INIT: Once = Once::new (); fn setup () { INIT.call_once (|| { println! ("Global setup" ); }); } struct TestGuard { name: String , } impl TestGuard { fn new (name: &str ) -> Self { println! ("Setup: {}" , name); TestGuard { name: name.to_string () } } } impl Drop for TestGuard { fn drop (&mut self ) { println! ("Teardown: {}" , self .name); } } #[test] fn test_with_guard () { setup (); let _guard = TestGuard::new ("test_with_guard" ); assert! (true ); } }
Test Fixtures 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #[cfg(test)] mod tests { struct DatabaseFixture { connection: String , } impl DatabaseFixture { fn new () -> Self { DatabaseFixture { connection: "test_db" .to_string (), } } fn insert (&self , data: &str ) { println! ("Inserting: {} into {}" , data, self .connection); } fn query (&self , id: i32 ) -> Option <String > { Some (format! ("data_{}" , id)) } } impl Drop for DatabaseFixture { fn drop (&mut self ) { println! ("Cleaning up {}" , self .connection); } } #[test] fn test_database_insert () { let db = DatabaseFixture::new (); db.insert ("test_data" ); let result = db.query (1 ); assert! (result.is_some ()); } }
Builder 模式测试数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 #[derive(Debug, Clone)] struct User { id: u64 , name: String , email: String , age: u8 , active: bool , } #[cfg(test)] mod tests { use super::*; struct UserBuilder { id: u64 , name: String , email: String , age: u8 , active: bool , } impl UserBuilder { fn new () -> Self { UserBuilder { id: 1 , name: "Test User" .to_string (), email: "test@example.com" .to_string (), age: 25 , active: true , } } fn id (mut self , id: u64 ) -> Self { self .id = id; self } fn name (mut self , name: &str ) -> Self { self .name = name.to_string (); self } fn inactive (mut self ) -> Self { self .active = false ; self } fn build (self ) -> User { User { id: self .id, name: self .name, email: self .email, age: self .age, active: self .active, } } } #[test] fn test_user_creation () { let user = UserBuilder::new () .id (42 ) .name ("Alice" ) .build (); assert_eq! (user.id, 42 ); assert_eq! (user.name, "Alice" ); assert! (user.active); } }
Mocking 和依赖注入 Trait 抽象和手动 Mock 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 trait Database { fn get (&self , key: &str ) -> Option <String >; fn set (&mut self , key: &str , value: &str ); } struct RealDatabase { } impl Database for RealDatabase { fn get (&self , key: &str ) -> Option <String > { None } fn set (&mut self , key: &str , value: &str ) { } } struct UserService <D: Database> { db: D, } impl <D: Database> UserService<D> { fn new (db: D) -> Self { UserService { db } } fn get_user (&self , id: &str ) -> Option <String > { self .db.get (&format! ("user:{}" , id)) } } #[cfg(test)] mod tests { use super::*; use std::collections::HashMap; struct MockDatabase { data: HashMap<String , String >, } impl MockDatabase { fn new () -> Self { MockDatabase { data: HashMap::new () } } fn with_data (data: HashMap<String , String >) -> Self { MockDatabase { data } } } impl Database for MockDatabase { fn get (&self , key: &str ) -> Option <String > { self .data.get (key).cloned () } fn set (&mut self , key: &str , value: &str ) { self .data.insert (key.to_string (), value.to_string ()); } } #[test] fn test_get_user () { let mut data = HashMap::new (); data.insert ("user:1" .to_string (), "Alice" .to_string ()); let mock_db = MockDatabase::with_data (data); let service = UserService::new (mock_db); assert_eq! (service.get_user ("1" ), Some ("Alice" .to_string ())); assert_eq! (service.get_user ("2" ), None ); } }
使用 mockall crate 1 2 [dev-dependencies] mockall = "0.12"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 use mockall::{automock, predicate::*};#[automock] trait HttpClient { fn get (&self , url: &str ) -> Result <String , String >; fn post (&self , url: &str , body: &str ) -> Result <String , String >; } struct ApiService <C: HttpClient> { client: C, } impl <C: HttpClient> ApiService<C> { fn fetch_user (&self , id: u64 ) -> Result <String , String > { self .client.get (&format! ("/users/{}" , id)) } } #[cfg(test)] mod tests { use super::*; #[test] fn test_fetch_user () { let mut mock = MockHttpClient::new (); mock.expect_get () .with (eq ("/users/42" )) .times (1 ) .returning (|_| Ok (r#"{"name": "Alice"}"# .to_string ())); let service = ApiService { client: mock }; let result = service.fetch_user (42 ); assert! (result.is_ok ()); assert! (result.unwrap ().contains ("Alice" )); } #[test] fn test_fetch_user_error () { let mut mock = MockHttpClient::new (); mock.expect_get () .returning (|_| Err ("Network error" .to_string ())); let service = ApiService { client: mock }; let result = service.fetch_user (1 ); assert! (result.is_err ()); } }
使用 mock_derive 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 use mockall::mock;mock! { pub Database { fn connect (&self ) -> bool ; fn query (&self , sql: &str ) -> Vec <String >; } } #[test] fn test_with_mock_database () { let mut mock = MockDatabase::new (); mock.expect_connect () .returning (|| true ); mock.expect_query () .with (mockall::predicate::str ::starts_with ("SELECT" )) .returning (|_| vec! ["row1" .to_string (), "row2" .to_string ()]); assert! (mock.connect ()); assert_eq! (mock.query ("SELECT * FROM users" ).len (), 2 ); }
参数化测试 使用 test-case crate 1 2 [dev-dependencies] test-case = "3"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 use test_case::test_case;fn add (a: i32 , b: i32 ) -> i32 { a + b } #[test_case(1, 1, 2; "one plus one" )] #[test_case(2, 2, 4; "two plus two" )] #[test_case(-1, 1, 0; "negative plus positive" )] #[test_case(0, 0, 0; "zeros" )] fn test_add (a: i32 , b: i32 , expected: i32 ) { assert_eq! (add (a, b), expected); } #[test_case("hello" , 5)] #[test_case("" , 0)] #[test_case("rust" , 4)] fn test_string_length (input: &str , expected: usize ) { assert_eq! (input.len (), expected); } #[test_case(4 => 2; "sqrt of 4" )] #[test_case(9 => 3; "sqrt of 9" )] fn test_sqrt (input: i32 ) -> i32 { (input as f64 ).sqrt () as i32 } #[test_case(0 => panics "divide by zero" )] fn test_divide_panic (divisor: i32 ) { let _ = 100 / divisor; } #[test_case("42" => matches Ok(_))] #[test_case("hello" => matches Err(_))] fn test_parse (input: &str ) -> Result <i32 , std::num::ParseIntError> { input.parse () }
使用 rstest crate 1 2 [dev-dependencies] rstest = "0.18"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 use rstest::rstest;#[rstest] #[case(1, 1, 2)] #[case(2, 2, 4)] #[case(0, 0, 0)] fn test_add (#[case] a: i32 , #[case] b: i32 , #[case] expected: i32 ) { assert_eq! (a + b, expected); } #[rstest] fn test_with_fixture (#[values(1, 2, 3)] x: i32 ) { assert! (x > 0 ); } #[rstest] fn test_combinations ( #[values(1, 2)] a: i32 , #[values("x" , "y" )] b: &str ) { println! ("a={}, b={}" , a, b); } #[rstest::fixture] fn database () -> MockDatabase { MockDatabase::new () } #[rstest] fn test_with_db_fixture (database: MockDatabase) { assert! (database.is_connected ()); } #[rstest] #[tokio::test] async fn test_async_with_params (#[values(1, 2, 3)] x: i32 ) { let result = async { x * 2 }.await ; assert_eq! (result, x * 2 ); }
手动参数化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #[cfg(test)] mod tests { struct TestCase { input: i32 , expected: i32 , } #[test] fn test_double () { let cases = vec! [ TestCase { input: 1 , expected: 2 }, TestCase { input: 2 , expected: 4 }, TestCase { input: -1 , expected: -2 }, TestCase { input: 0 , expected: 0 }, ]; for (i, case) in cases.iter ().enumerate () { let result = case.input * 2 ; assert_eq! ( result, case.expected, "Case {} failed: {} * 2 = {}, expected {}" , i, case.input, result, case.expected ); } } }
属性测试 (Property-Based Testing) 使用 proptest 1 2 [dev-dependencies] proptest = "1"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 use proptest::prelude::*;proptest! { #[test] fn test_add_commutative (a: i32 , b: i32 ) { prop_assert_eq!(a.wrapping_add (b), b.wrapping_add (a)); } #[test] fn test_string_reverse_reverse (s: String ) { let reversed : String = s.chars ().rev ().collect (); let double_reversed : String = reversed.chars ().rev ().collect (); prop_assert_eq!(s, double_reversed); } } proptest! { #[test] fn test_vec_sort (mut v: Vec <i32 >) { v.sort (); for window in v.windows (2 ) { prop_assert!(window[0 ] <= window[1 ]); } } #[test] fn test_percentage (n in 0 ..=100i32 ) { prop_assert!(n >= 0 && n <= 100 ); } #[test] fn test_email_like ( local in "[a-z]{1,10}" , domain in "[a-z]{1,10}" ) { let email = format! ("{}@{}.com" , local, domain); prop_assert!(email.contains ('@' )); } } fn user_strategy () -> impl Strategy <Value = User> { ( "[a-zA-Z]{1,20}" , "[a-z]+@[a-z]+\\.[a-z]+" , 18 ..100u8 , ).prop_map (|(name, email, age)| User { name, email, age }) } proptest! { #[test] fn test_user_serialization (user in user_strategy ()) { let json = serde_json::to_string (&user).unwrap (); let deserialized : User = serde_json::from_str (&json).unwrap (); prop_assert_eq!(user, deserialized); } }
使用 quickcheck 1 2 3 [dev-dependencies] quickcheck = "1" quickcheck_macros = "1"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 use quickcheck_macros::quickcheck;#[quickcheck] fn test_reverse_reverse (xs: Vec <i32 >) -> bool { let reversed : Vec <i32 > = xs.iter ().rev ().cloned ().collect (); let double_reversed : Vec <i32 > = reversed.iter ().rev ().cloned ().collect (); xs == double_reversed } #[quickcheck] fn test_sort_length (mut xs: Vec <i32 >) -> bool { let original_len = xs.len (); xs.sort (); xs.len () == original_len }
模糊测试 (Fuzzing) 使用 cargo-fuzz 1 2 3 4 5 6 7 8 cargo install cargo-fuzz cargo fuzz init cargo fuzz add my_target
1 2 3 4 5 6 7 8 9 10 11 #![no_main] use libfuzzer_sys::fuzz_target;use my_project::parse_input;fuzz_target!(|data: &[u8 ]| { if let Ok (s) = std::str ::from_utf8 (data) { let _ = parse_input (s); } });
1 2 3 4 5 cargo +nightly fuzz run my_target cargo +nightly fuzz run my_target -- -max_total_time=60
使用 arbitrary 1 2 [dev-dependencies] arbitrary = { version = "1" , features = ["derive" ] }
1 2 3 4 5 6 7 8 9 10 11 12 13 use arbitrary::{Arbitrary, Unstructured};#[derive(Debug, Arbitrary)] struct MyInput { name: String , age: u8 , scores: Vec <i32 >, } fuzz_target!(|input: MyInput| { process (input); });
基准测试 内置基准测试(nightly) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #![feature(test)] extern crate test;use test::Bencher;#[bench] fn bench_add (b: &mut Bencher) { b.iter (|| { test::black_box (add (1 , 2 )) }); } fn add (a: i32 , b: i32 ) -> i32 { a + b }
使用 criterion 1 2 3 4 5 6 [dev-dependencies] criterion = { version = "0.5" , features = ["html_reports" ] }[[bench]] name = "my_benchmark" harness = false
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 use criterion::{black_box, criterion_group, criterion_main, Criterion, BenchmarkId};fn fibonacci (n: u64 ) -> u64 { match n { 0 => 1 , 1 => 1 , n => fibonacci (n - 1 ) + fibonacci (n - 2 ), } } fn bench_fibonacci (c: &mut Criterion) { c.bench_function ("fib 20" , |b| { b.iter (|| fibonacci (black_box (20 ))) }); } fn bench_fibonacci_group (c: &mut Criterion) { let mut group = c.benchmark_group ("Fibonacci" ); for i in [10 , 15 , 20 ].iter () { group.bench_with_input (BenchmarkId::new ("recursive" , i), i, |b, i| { b.iter (|| fibonacci (black_box (*i))) }); } group.finish (); } fn fibonacci_iterative (n: u64 ) -> u64 { let mut a = 1 ; let mut b = 1 ; for _ in 0 ..n { let tmp = a; a = b; b = tmp + b; } a } fn bench_compare (c: &mut Criterion) { let mut group = c.benchmark_group ("Fibonacci Comparison" ); let n = 20 ; group.bench_function ("recursive" , |b| { b.iter (|| fibonacci (black_box (n))) }); group.bench_function ("iterative" , |b| { b.iter (|| fibonacci_iterative (black_box (n))) }); group.finish (); } fn bench_throughput (c: &mut Criterion) { let data : Vec <u8 > = (0 ..1024 ).map (|i| i as u8 ).collect (); let mut group = c.benchmark_group ("Throughput" ); group.throughput (criterion::Throughput::Bytes (data.len () as u64 )); group.bench_function ("process" , |b| { b.iter (|| { data.iter ().sum::<u8 >() }) }); group.finish (); } criterion_group!( benches, bench_fibonacci, bench_fibonacci_group, bench_compare, bench_throughput ); criterion_main!(benches);
1 2 3 4 5 6 7 8 9 10 11 cargo bench cargo bench -- fibonacci cargo bench -- --save-baseline main cargo bench -- --baseline main
代码覆盖率 使用 cargo-tarpaulin 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 cargo install cargo-tarpaulin cargo tarpaulin cargo tarpaulin --out Html cargo tarpaulin --ignore-tests cargo tarpaulin --out Xml --out Html cargo tarpaulin --fail-under 80
使用 llvm-cov 1 2 3 4 5 6 7 8 9 10 11 12 13 14 cargo install cargo-llvm-cov cargo llvm-cov cargo llvm-cov --html cargo llvm-cov --open cargo llvm-cov --summary-only
CI 配置示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 name: Coverage on: [push , pull_request ]jobs: coverage: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: dtolnay/rust-toolchain@stable - name: Install tarpaulin run: cargo install cargo-tarpaulin - name: Run coverage run: cargo tarpaulin --out Xml - name: Upload to codecov uses: codecov/codecov-action@v3 with: file: cobertura.xml
CI/CD 集成 GitHub Actions 完整配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 name: CI on: push: branches: [main ] pull_request: branches: [main ] env: CARGO_TERM_COLOR: always jobs: fmt: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: dtolnay/rust-toolchain@stable with: components: rustfmt - run: cargo fmt --all -- --check clippy: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: dtolnay/rust-toolchain@stable with: components: clippy - run: cargo clippy --all-targets --all-features -- -D warnings test: runs-on: ${{ matrix.os }} strategy: matrix: os: [ubuntu-latest , windows-latest , macos-latest ] rust: [stable , beta ] steps: - uses: actions/checkout@v4 - uses: dtolnay/rust-toolchain@master with: toolchain: ${{ matrix.rust }} - run: cargo test --all-features --verbose doc: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: dtolnay/rust-toolchain@stable - run: cargo doc --no-deps --all-features env: RUSTDOCFLAGS: -D warnings coverage: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: dtolnay/rust-toolchain@stable - uses: taiki-e/install-action@cargo-llvm-cov - run: cargo llvm-cov --all-features --lcov --output-path lcov.info - uses: codecov/codecov-action@v3 with: files: lcov.info fail_ci_if_error: true
最佳实践 测试命名规范 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #[cfg(test)] mod tests { #[test] fn test_add_positive_numbers_returns_sum () {} #[test] fn test_add_negative_numbers_returns_sum () {} #[test] fn test_divide_by_zero_returns_none () {} #[test] fn test_parse_valid_json_returns_ok () {} #[test] fn test_parse_invalid_json_returns_error () {} }
测试组织 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #[cfg(test)] mod tests { use super::*; mod add { use super::*; #[test] fn positive_numbers () {} #[test] fn negative_numbers () {} } mod subtract { use super::*; #[test] fn positive_numbers () {} } fn create_test_user () -> User { User::new ("test" , "test@example.com" ) } }
测试隔离 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #[cfg(test)] mod tests { use std::sync::Mutex; use once_cell::sync::Lazy; static TEST_MUTEX: Lazy<Mutex<()>> = Lazy::new (|| Mutex::new (())); #[test] fn test_that_modifies_global_state () { let _lock = TEST_MUTEX.lock ().unwrap (); } }
错误信息 1 2 3 4 5 6 7 8 9 10 11 12 13 #[test] fn test_with_good_error_message () { let input = vec! [1 , 2 , 3 ]; let result = process (&input); assert! ( result.len () == 3 , "Expected result length 3, got {}. Input: {:?}, Result: {:?}" , result.len (), input, result ); }
速查表 常用命令 1 2 3 4 5 6 7 8 9 cargo test cargo test test_name cargo test -- --nocapture cargo test -- --test-threads=1 cargo test -- --ignored cargo test --doc cargo test --lib cargo test --test name cargo bench
测试属性
属性
用途
#[test]标记测试函数
#[should_panic]期望 panic
#[should_panic(expected = "msg")]期望特定 panic 消息
#[ignore]跳过测试
#[ignore = "reason"]带原因跳过
#[cfg(test)]仅测试时编译
断言宏
宏
用途
assert!(expr)断言为真
assert_eq!(a, b)断言相等
assert_ne!(a, b)断言不相等
debug_assert!Debug 模式断言
panic!("msg")触发 panic
常用测试 Crate
Crate
用途
mockallMock 对象
test-case参数化测试
rstest参数化 + Fixtures
proptest属性测试
criterion基准测试
fake假数据生成
wiremockHTTP Mock
tempfile临时文件
serial_test串行测试
Cargo 概览 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ┌─────────────────────────────────────────────────────────────────────┐ │ Cargo 功能 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │ │ 包管理器 │ │ 构建系统 │ │ 任务运行器 │ │ │ ├─────────────┤ ├─────────────┤ ├─────────────┤ │ │ │ • 依赖解析 │ │ • 编译代码 │ │ • 运行测试 │ │ │ │ • 版本管理 │ │ • 增量构建 │ │ • 运行示例 │ │ │ │ • 发布包 │ │ • 多目标 │ │ • 基准测试 │ │ │ │ • 下载依赖 │ │ • 构建脚本 │ │ • 文档生成 │ │ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │ │ ├─────────────────────────────────────────────────────────────────────┤ │ 项目结构 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ my_project/ │ │ ├── Cargo.toml # 项目配置文件 │ │ ├── Cargo.lock # 依赖锁定文件(自动生成) │ │ ├── src/ │ │ │ ├── lib.rs # 库入口 │ │ │ ├── main.rs # 二进制入口 │ │ │ └── bin/ # 多个二进制 │ │ │ └── other.rs │ │ ├── tests/ # 集成测试 │ │ ├── benches/ # 基准测试 │ │ ├── examples/ # 示例代码 │ │ └── build.rs # 构建脚本(可选) │ │ │ └─────────────────────────────────────────────────────────────────────┘
基础命令 项目管理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 cargo new my_project cargo new my_lib --lib cargo new my_project --vcs none cargo init cargo init --lib cargo build cargo build --release cargo build --target x86_64-unknown-linux-gnu cargo run cargo run --release cargo run --bin my_bin cargo run --example my_example cargo run -- arg1 arg2 cargo check cargo check --all-targets
测试和文档 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 cargo test cargo test test_name cargo test --lib cargo test --doc cargo test --test integration cargo test -- --nocapture cargo test -- --test-threads=1 cargo doc cargo doc --open cargo doc --no-deps cargo doc --document-private-items cargo bench cargo bench --bench my_bench
依赖管理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 cargo add serde cargo add serde --features derive cargo add tokio@1.0 cargo add --dev pretty_assertions cargo add --build cc cargo remove serde cargo update cargo update -p serde cargo tree cargo tree -d cargo tree -i serde cargo tree --format "{p} {f}" cargo search serde cargo info serde
发布 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 cargo login cargo package cargo package --list cargo publish cargo publish --dry-run cargo publish --allow-dirty cargo install ripgrep cargo install --path . cargo install --git https://github.com/user/repo cargo uninstall ripgrep
其他实用命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 cargo clean cargo clean -p my_crate cargo fmt cargo fmt -- --check cargo clippy cargo clippy -- -D warnings cargo audit cargo outdated cargo locate-project cargo metadata cargo version cargo --list
Cargo.toml 详解 基本结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 [package] name = "my_project" version = "0.1.0" edition = "2021" rust-version = "1.70" authors = ["Your Name <email@example.com>" ]description = "A short description" documentation = "https://docs.rs/my_project" readme = "README.md" homepage = "https://example.com" repository = "https://github.com/user/my_project" license = "MIT OR Apache-2.0" license-file = "LICENSE" keywords = ["keyword1" , "keyword2" ] categories = ["development-tools" ] exclude = ["tests/*" , "benches/*" ] include = ["src/**/*" , "Cargo.toml" ] build = "build.rs" links = "foo" autobins = true autoexamples = true autotests = true autobenches = true resolver = "2" [lib] name = "my_lib" path = "src/lib.rs" crate-type = ["lib" ] doc = true test = true doctest = true bench = true [[bin]] name = "my_bin" path = "src/main.rs" test = true bench = true doc = true [[bin]] name = "another_bin" path = "src/bin/another.rs" [[example]] name = "my_example" path = "examples/my_example.rs" crate-type = ["bin" ] required-features = ["feature1" ] [[test]] name = "integration_test" path = "tests/integration.rs" harness = true [[bench]] name = "my_bench" path = "benches/my_bench.rs" harness = false
依赖配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 [dependencies] serde = "1.0" serde = { version = "1.0" , features = ["derive" ] }serde_json = { version = "1.0" , optional = true }my_crate = { git = "https://github.com/user/repo" }my_crate = { git = "https://github.com/user/repo" , branch = "main" }my_crate = { git = "https://github.com/user/repo" , tag = "v1.0" }my_crate = { git = "https://github.com/user/repo" , rev = "abc123" }my_crate = { path = "../my_crate" }my_crate = { path = "../my_crate" , version = "1.0" }serde_json_renamed = { package = "serde_json" , version = "1.0" }tokio = { version = "1" , default-features = false , features = ["rt" ] }[target.'cfg(windows)'.dependencies] winapi = "0.3" [target.'cfg(unix)'.dependencies] libc = "0.2" [target.'cfg(target_arch = "wasm32")'.dependencies] wasm-bindgen = "0.2" [dev-dependencies] pretty_assertions = "1.0" mockall = "0.11" criterion = { version = "0.5" , features = ["html_reports" ] }[build-dependencies] cc = "1.0" bindgen = "0.69"
版本规范 1 2 3 4 5 6 7 8 9 10 11 [dependencies] exact = "=1.2.3" caret = "^1.2.3" tilde = "~1.2.3" wildcard = "1.*" range = ">=1.2, <1.5" latest_1x = "1" patch_only = "~1.2"
Features 配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [features] default = ["std" , "derive" ]std = []derive = ["serde/derive" ] full = ["std" , "derive" , "async" ]async = ["tokio" , "async-trait" ]serde = ["dep:serde" ] json = ["dep:serde_json" , "serde" ] [dependencies] serde = { version = "1.0" , optional = true }serde_json = { version = "1.0" , optional = true }tokio = { version = "1" , optional = true }async-trait = { version = "0.1" , optional = true }
Profiles 配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 [profile.dev] opt-level = 0 debug = true split-debuginfo = "..." debug-assertions = true overflow-checks = true lto = false panic = "unwind" incremental = true codegen-units = 256 rpath = false [profile.release] opt-level = 3 debug = false debug-assertions = false overflow-checks = false lto = true panic = "abort" incremental = false codegen-units = 1 strip = true [profile.test] opt-level = 0 debug = 2 [profile.bench] opt-level = 3 debug = false [profile.release-with-debug] inherits = "release" debug = true [profile.dev.package."*"] opt-level = 2 [profile.dev.package.serde] opt-level = 3 [profile.dev.build-override] opt-level = 3
工作空间 (Workspace) 基本结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 my_workspace/ ├── Cargo.toml # 工作空间配置 ├── crates/ │ ├── core/ │ │ ├── Cargo.toml │ │ └── src/lib.rs │ ├── utils/ │ │ ├── Cargo.toml │ │ └── src/lib.rs │ └── app/ │ ├── Cargo.toml │ └── src/main.rs └── shared/ ├── Cargo.toml └── src/lib.rs
工作空间配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 [workspace] members = [ "crates/*" , "shared" , ] exclude = [ "crates/experimental" , ] default-members = [ "crates/app" , ] resolver = "2" [workspace.package] version = "0.1.0" edition = "2021" authors = ["Your Name <email@example.com>" ]license = "MIT" repository = "https://github.com/user/repo" [workspace.dependencies] serde = { version = "1.0" , features = ["derive" ] }tokio = { version = "1" , features = ["full" ] }thiserror = "1.0" my_core = { path = "crates/core" , version = "0.1.0" }my_utils = { path = "crates/utils" , version = "0.1.0" }
成员 crate 配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [package] name = "my_core" version.workspace = true edition.workspace = true authors.workspace = true license.workspace = true [dependencies] serde.workspace = true tokio = { workspace = true , features = ["rt" ] } [package] name = "my_app" version.workspace = true edition.workspace = true [dependencies] my_core.workspace = true my_utils = { workspace = true , optional = true }
工作空间命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 cargo build --workspace cargo build -p my_core cargo build -p my_app cargo test --workspace cargo run -p my_app cargo publish -p my_core cargo publish -p my_utils cargo publish -p my_app
构建脚本 (build.rs) 基本结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 fn main () { println! ("cargo:rerun-if-changed=build.rs" ); println! ("cargo:rerun-if-changed=src/wrapper.h" ); println! ("cargo:rustc-cfg=feature=\"special\"" ); println! ("cargo:rustc-link-lib=mylib" ); println! ("cargo:rustc-link-search=native=/usr/local/lib" ); println! ("cargo:root=/path/to/root" ); println! ("cargo:warning=Something to note" ); }
常用指令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 fn main () { println! ("cargo:rerun-if-changed=PATH" ); println! ("cargo:rerun-if-env-changed=VAR" ); println! ("cargo:rustc-link-lib=static=foo" ); println! ("cargo:rustc-link-lib=dylib=bar" ); println! ("cargo:rustc-link-lib=framework=CoreFoundation" ); println! ("cargo:rustc-link-search=native=/path" ); println! ("cargo:rustc-link-search=framework=/path" ); println! ("cargo:rustc-link-arg=-fuse-ld=lld" ); println! ("cargo:rustc-link-arg-bins=-Wl,-rpath,/path" ); println! ("cargo:rustc-flags=-l foo -L /path" ); println! ("cargo:rustc-cfg=my_cfg" ); println! ("cargo:rustc-cfg=feature=\"foo\"" ); println! ("cargo:rustc-env=VAR=value" ); println! ("cargo:rustc-cdylib-link-arg=-Wl,--version-script=exports.txt" ); println! ("cargo:KEY=VALUE" ); }
实用示例 1 2 3 4 5 6 7 8 9 10 11 12 fn main () { cc::Build::new () .file ("src/foo.c" ) .file ("src/bar.c" ) .include ("include" ) .flag ("-Wall" ) .compile ("mylib" ); println! ("cargo:rerun-if-changed=src/foo.c" ); println! ("cargo:rerun-if-changed=src/bar.c" ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 fn main () { let bindings = bindgen::Builder::default () .header ("wrapper.h" ) .parse_callbacks (Box ::new (bindgen::CargoCallbacks::new ())) .generate () .expect ("Unable to generate bindings" ); let out_path = std::path::PathBuf::from (std::env::var ("OUT_DIR" ).unwrap ()); bindings .write_to_file (out_path.join ("bindings.rs" )) .expect ("Couldn't write bindings!" ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 fn main () { let target = std::env::var ("TARGET" ).unwrap (); if target.contains ("windows" ) { println! ("cargo:rustc-cfg=windows_build" ); } if target.contains ("linux" ) { println! ("cargo:rustc-link-lib=pthread" ); } let has_avx2 = std::env::var ("CARGO_CFG_TARGET_FEATURE" ) .map (|f| f.contains ("avx2" )) .unwrap_or (false ); if has_avx2 { println! ("cargo:rustc-cfg=has_avx2" ); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 use std::env;use std::fs;use std::path::Path;fn main () { let out_dir = env::var ("OUT_DIR" ).unwrap (); let dest_path = Path::new (&out_dir).join ("generated.rs" ); let code = r#" pub const VERSION: &str = env!("CARGO_PKG_VERSION"); pub const BUILD_TIME: &str = "2024-01-01"; pub fn generated_function() -> i32 { 42 } "# ; fs::write (&dest_path, code).unwrap (); println! ("cargo:rerun-if-changed=build.rs" ); }
构建脚本环境变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 fn main () { let pkg_name = env! ("CARGO_PKG_NAME" ); let pkg_version = env! ("CARGO_PKG_VERSION" ); let manifest_dir = env! ("CARGO_MANIFEST_DIR" ); let out_dir = std::env::var ("OUT_DIR" ).unwrap (); let target = std::env::var ("TARGET" ).unwrap (); let host = std::env::var ("HOST" ).unwrap (); let profile = std::env::var ("PROFILE" ).unwrap (); let opt_level = std::env::var ("OPT_LEVEL" ).unwrap (); let num_jobs = std::env::var ("NUM_JOBS" ).unwrap (); let target_arch = std::env::var ("CARGO_CFG_TARGET_ARCH" ).unwrap (); let target_os = std::env::var ("CARGO_CFG_TARGET_OS" ).unwrap (); let target_env = std::env::var ("CARGO_CFG_TARGET_ENV" ).unwrap_or_default (); let has_serde = std::env::var ("CARGO_FEATURE_SERDE" ).is_ok (); }
配置文件 .cargo/config.toml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 [build] jobs = 8 rustc-wrapper = "sccache" target = "x86_64-unknown-linux-gnu" target-dir = "target" incremental = true rustflags = ["-C" , "target-cpu=native" ]rustdocflags = ["--cfg" , "docsrs" ][target.x86_64-unknown-linux-gnu] linker = "clang" rustflags = ["-C" , "link-arg=-fuse-ld=lld" ]runner = "my_runner" [target.thumbv7em-none-eabihf] runner = "probe-rs run --chip STM32F411CEUx" rustflags = [ "-C" , "link-arg=-Tlink.x" , ] [target.'cfg(target_os = "linux")'] rustflags = ["-C" , "target-feature=+crt-static" ][alias] b = "build" c = "check" t = "test" r = "run" rr = "run --release" br = "build --release" xtask = "run --package xtask --" coverage = "llvm-cov --html" ci = ["fmt -- --check" , "clippy" , "test" ][registries] my-registry = { index = "https://my-registry.example.com/git/index" }[registry] default = "crates-io" [source.crates-io] replace-with = "ustc" [source.ustc] registry = "https://mirrors.ustc.edu.cn/crates.io-index" [source.my-git] git = "https://github.com/example/repo" [source.crates-io.replace-with] local-registry = "/path/to/local/registry" [net] retry = 2 git-fetch-with-cli = true offline = false [http] proxy = "http://proxy.example.com:8080" timeout = 30 cainfo = "/path/to/cert.pem" check-revoke = true ssl-version = "tlsv1.3" low-speed-limit = 5 multiplexing = true [term] verbose = false color = "auto" progress.when = "auto" progress.width = 80 [env] MY_VAR = "value" MY_PATH = { value = "/path" , relative = true }MY_FORCE = { value = "forced" , force = true }
环境变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 CARGO_HOME=~/.cargo CARGO_TARGET_DIR=./target CARGO_BUILD_JOBS=8 CARGO_INCREMENTAL=1 CARGO_PROFILE_RELEASE_LTO=true RUSTFLAGS="-C target-cpu=native" RUSTDOCFLAGS="--cfg docsrs" CARGO_HTTP_TIMEOUT=30 CARGO_NET_RETRY=3 CARGO_NET_OFFLINE=true RUST_TEST_THREADS=1 RUST_BACKTRACE=1 CARGO_LOG=debug RUST_LOG=cargo=debug
Cargo 扩展工具 常用扩展 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 cargo install cargo-edit cargo install cargo-watch cargo install cargo-audit cargo install cargo-outdated cargo install cargo-deny cargo install cargo-bloat cargo install cargo-expand cargo install cargo-flamegraph cargo install cargo-llvm-lines cargo install cargo-tarpaulin cargo install cargo-llvm-cov cargo install cargo-fuzz cargo install cargo-nextest cargo install cargo-release cargo install cargo-semver-checks cargo install cargo-binutils cargo install cargo-flash cargo install cargo-embed cargo install cargo-make cargo install cargo-generate cargo install cargo-udeps
cargo-watch 1 2 3 4 5 6 7 8 9 10 11 cargo watch -x check cargo watch -x test cargo watch -x "run -- --arg" cargo watch -x clippy -x test cargo watch -w src -w tests cargo watch --ignore "*.txt" cargo watch -c cargo watch -d 2
cargo-make 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [env] RUST_BACKTRACE = "1" [tasks.format] command = "cargo" args = ["fmt" , "--all" ][tasks.lint] command = "cargo" args = ["clippy" , "--all-targets" , "--" , "-D" , "warnings" ][tasks.test] command = "cargo" args = ["test" , "--all-features" ][tasks.build-release] command = "cargo" args = ["build" , "--release" ][tasks.ci] dependencies = ["format" , "lint" , "test" ][tasks.dev] run_task = { name = ["format" , "lint" , "test" ], parallel = true }[tasks.build-windows] condition = { platforms = ["windows" ] }command = "cargo" args = ["build" , "--target" , "x86_64-pc-windows-msvc" ]
1 2 3 cargo make ci cargo make dev cargo make build-release
cargo-release 1 2 3 4 5 6 7 8 9 10 [package.metadata.release] sign-commit = true sign-tag = true pre-release-commit-message = "Release {{version}}" tag-message = "Release {{version}}" tag-prefix = "v" pre-release-replacements = [ { file = "CHANGELOG.md" , search = "Unreleased" , replace = "{{version}}" }, ]
1 2 3 4 5 cargo release patch cargo release minor cargo release major cargo release --dry-run cargo release --execute
发布到 crates.io 准备工作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [package] name = "my_crate" version = "0.1.0" edition = "2021" license = "MIT OR Apache-2.0" description = "A short description" repository = "https://github.com/user/repo" documentation = "https://docs.rs/my_crate" readme = "README.md" keywords = ["keyword1" , "keyword2" ]categories = ["development-tools" ]exclude = [ "tests/*" , "benches/*" , ".github/*" , "*.log" , ]
发布前检查 1 2 3 4 5 6 7 8 9 10 11 cargo publish --dry-run cargo package --list cargo install --path . cargo semver-checks check-release
发布流程 1 2 3 4 5 6 7 8 9 cargo login <token> cargo publish cargo yank --version 0.1.0 cargo yank --version 0.1.0 --undo
文档发布
1 2 3 4 5 [package.metadata.docs.rs] all-features = true rustdoc-args = ["--cfg" , "docsrs" ]targets = ["x86_64-unknown-linux-gnu" ]
1 2 3 4 5 6 7 #![cfg_attr(docsrs, feature(doc_cfg))] #[cfg(feature = "advanced" )] #[cfg_attr(docsrs, doc(cfg(feature = "advanced" )))] pub fn advanced_function () {}
常见模式 条件编译 1 2 3 4 5 6 7 8 [features] default = ["std" ]std = []alloc = [][dependencies] serde = { version = "1" , optional = true }
1 2 3 4 5 6 7 8 9 10 11 #![cfg_attr(not(feature = "std" ), no_std)] #[cfg(feature = "alloc" )] extern crate alloc;#[cfg(feature = "std" )] pub fn std_only () {}#[cfg(feature = "serde" )] mod serde_impl;
多平台支持 1 2 3 4 5 6 7 8 9 [target.'cfg(windows)'.dependencies] winapi = "0.3" [target.'cfg(unix)'.dependencies] libc = "0.2" [target.'cfg(target_arch = "wasm32")'.dependencies] wasm-bindgen = "0.2"
示例项目组织 1 2 3 4 5 6 7 8 9 10 11 12 13 [[example]] name = "async_example" required-features = ["tokio" ][[example]] name = "serde_example" required-features = ["serde" ][dev-dependencies] tokio = { version = "1" , features = ["full" ] }
xtask 模式 1 2 3 4 5 6 my_project/ ├── Cargo.toml ├── src/ ├── xtask/ │ ├── Cargo.toml │ └── src/main.rs
1 2 3 4 5 6 7 [workspace] members = ["." , "xtask" ][alias] xtask = "run --package xtask --"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 use std::process::Command;fn main () { let args : Vec <String > = std::env::args ().skip (1 ).collect (); match args.first ().map (|s| s.as_str ()) { Some ("dist" ) => dist (), Some ("coverage" ) => coverage (), Some ("ci" ) => ci (), _ => { eprintln!("Usage: cargo xtask <task>" ); eprintln!("Tasks: dist, coverage, ci" ); } } } fn dist () { Command::new ("cargo" ) .args (["build" , "--release" ]) .status () .expect ("Failed to build" ); } fn coverage () { Command::new ("cargo" ) .args (["llvm-cov" , "--html" ]) .status () .expect ("Failed to run coverage" ); } fn ci () { }
1 2 cargo xtask dist cargo xtask coverage
速查表 常用命令
命令
说明
cargo new/init创建项目
cargo build构建
cargo run构建并运行
cargo check快速检查
cargo test运行测试
cargo bench运行基准测试
cargo doc生成文档
cargo publish发布
cargo add/remove管理依赖
cargo update更新依赖
cargo tree依赖树
cargo fmt格式化
cargo clippyLint
cargo clean清理
常用标志
标志
说明
--releaseRelease 模式
--workspace所有工作空间成员
-p <name>指定包
--all-features启用所有 features
--no-default-features禁用默认 features
--features "a b"启用指定 features
--target <triple>指定目标
--verbose/-v详细输出
--jobs/-j <N>并行任务数
环境变量
变量
说明
CARGO_HOMECargo 主目录
CARGO_TARGET_DIR输出目录
RUSTFLAGS编译器标志
CARGO_INCREMENTAL增量编译
RUST_BACKTRACE错误回溯
文件
文件
说明
Cargo.toml项目配置
Cargo.lock依赖锁定
.cargo/config.tomlCargo 配置
build.rs构建脚本
rust-toolchain.toml工具链配置
no_std 编程 概念概览 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ┌─────────────────────────────────────────────────────────────────────┐ │ Rust 标准库层次 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────────────────────────────────────────────────────┐ │ │ │ std │ │ │ │ • 依赖操作系统(文件、网络、线程、时间...) │ │ │ │ • 自动链接,提供运行时 │ │ │ ├─────────────────────────────────────────────────────────┤ │ │ │ alloc │ │ │ │ • 堆内存分配(Box, Vec, String, Rc, Arc...) │ │ │ │ • 需要全局分配器 │ │ │ ├─────────────────────────────────────────────────────────┤ │ │ │ core │ │ │ │ • 无任何依赖(Option, Result, Iterator, 切片...) │ │ │ │ • 纯 Rust,可在任何环境运行 │ │ │ └─────────────────────────────────────────────────────────┘ │ │ │ ├─────────────────────────────────────────────────────────────────────┤ │ no_std 应用场景 │ ├─────────────────────────────────────────────────────────────────────┤ │ • 嵌入式系统 (ARM Cortex-M, RISC-V, AVR...) │ │ • 操作系统内核开发 │ │ • Bootloader │ │ • WebAssembly (部分场景) │ │ • 驱动程序 │ │ • 实时系统 │ └─────────────────────────────────────────────────────────────────────┘
std vs no_std 对比
特性
std
no_std
no_std + alloc
堆内存
✅
❌
✅
Vec/String/Box
✅
❌
✅
文件 I/O
✅
❌
❌
网络
✅
❌
❌
线程
✅
❌
❌
时间
✅
❌
❌
HashMap
✅
❌
❌
println!
✅
❌
❌
panic 信息
✅
需实现
需实现
基础 no_std 项目 最小示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #![no_std] use core::panic::PanicInfo;#[panic_handler] fn panic (_info: &PanicInfo) -> ! { loop {} } pub fn add (a: i32 , b: i32 ) -> i32 { a + b } pub fn find_max (slice: &[i32 ]) -> Option <&i32 > { slice.iter ().max () }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [package] name = "my_no_std_lib" version = "0.1.0" edition = "2021" [lib] [profile.release] panic = "abort" lto = true opt-level = "z"
core 库详解 可用类型和 trait 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #![no_std] use core::{ mem, ptr, slice, str , cmp::{Ord , PartialOrd , Eq , PartialEq , Ordering}, convert::{From , Into , TryFrom, TryInto, AsRef , AsMut }, default::Default , fmt::{Debug , Display, Formatter, Write}, hash::{Hash, Hasher}, iter::{Iterator , IntoIterator , FromIterator}, marker::{Copy , Send , Sync , Sized , PhantomData}, ops::{Add, Sub, Mul, Div, Index, Deref, Drop , Fn , FnMut , FnOnce }, option::Option , result::Result , num::Wrapping, sync::atomic::{AtomicBool, AtomicUsize, Ordering as AtomicOrdering}, cell::{Cell, RefCell, UnsafeCell}, time::Duration, any::Any, borrow::{Borrow, BorrowMut}, clone::Clone , hint, }; pub fn sum_slice (data: &[i32 ]) -> i32 { data.iter ().fold (0 , |acc, x| acc.wrapping_add (*x)) } pub fn find_index <T: PartialEq >(slice: &[T], target: &T) -> Option <usize > { slice.iter ().position (|x| x == target) }
格式化输出(无 println!) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #![no_std] use core::fmt::{self , Write};pub struct Buffer { data: [u8 ; 256 ], pos: usize , } impl Buffer { pub const fn new () -> Self { Buffer { data: [0 ; 256 ], pos: 0 , } } pub fn as_str (&self ) -> &str { unsafe { core::str ::from_utf8_unchecked (&self .data[..self .pos]) } } pub fn clear (&mut self ) { self .pos = 0 ; } } impl Write for Buffer { fn write_str (&mut self , s: &str ) -> fmt::Result { let bytes = s.as_bytes (); let remaining = self .data.len () - self .pos; if bytes.len () > remaining { return Err (fmt::Error); } self .data[self .pos..self .pos + bytes.len ()].copy_from_slice (bytes); self .pos += bytes.len (); Ok (()) } } pub fn format_number (buf: &mut Buffer, n: i32 ) -> fmt::Result { write! (buf, "Number: {}" , n) } pub struct Point { x: i32 , y: i32 , } impl fmt ::Debug for Point { fn fmt (&self , f: &mut fmt::Formatter<'_ >) -> fmt::Result { write! (f, "Point {{ x: {}, y: {} }}" , self .x, self .y) } } impl fmt ::Display for Point { fn fmt (&self , f: &mut fmt::Formatter<'_ >) -> fmt::Result { write! (f, "({}, {})" , self .x, self .y) } }
原子操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #![no_std] use core::sync::atomic::{AtomicUsize, AtomicBool, Ordering};pub struct Counter { value: AtomicUsize, } impl Counter { pub const fn new () -> Self { Counter { value: AtomicUsize::new (0 ), } } pub fn increment (&self ) -> usize { self .value.fetch_add (1 , Ordering::SeqCst) } pub fn get (&self ) -> usize { self .value.load (Ordering::SeqCst) } } pub struct SpinLock { locked: AtomicBool, } impl SpinLock { pub const fn new () -> Self { SpinLock { locked: AtomicBool::new (false ), } } pub fn lock (&self ) { while self .locked.compare_exchange_weak ( false , true , Ordering::Acquire, Ordering::Relaxed ).is_err () { core::hint::spin_loop (); } } pub fn unlock (&self ) { self .locked.store (false , Ordering::Release); } pub fn try_lock (&self ) -> bool { self .locked .compare_exchange (false , true , Ordering::Acquire, Ordering::Relaxed) .is_ok () } } static COUNTER: Counter = Counter::new ();static LOCK: SpinLock = SpinLock::new ();
alloc 库使用 启用 alloc 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #![no_std] extern crate alloc;use alloc::{ boxed::Box , vec::Vec , vec, string::String , format, rc::Rc, sync::Arc, collections::{BTreeMap, BTreeSet, VecDeque, LinkedList, BinaryHeap}, borrow::Cow, }; pub fn create_vector () -> Vec <i32 > { vec! [1 , 2 , 3 , 4 , 5 ] } pub fn boxed_value () -> Box <[u8 ; 1024 ]> { Box ::new ([0u8 ; 1024 ]) } pub fn use_btree_map () -> BTreeMap<&'static str , i32 > { let mut map = BTreeMap::new (); map.insert ("one" , 1 ); map.insert ("two" , 2 ); map }
全局分配器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 #![no_std] #![feature(alloc_error_handler)] extern crate alloc;use core::alloc::{GlobalAlloc, Layout};pub struct BumpAllocator { heap_start: usize , heap_end: usize , next: core::sync::atomic::AtomicUsize, } impl BumpAllocator { pub const fn new () -> Self { BumpAllocator { heap_start: 0 , heap_end: 0 , next: core::sync::atomic::AtomicUsize::new (0 ), } } pub unsafe fn init (&mut self , heap_start: usize , heap_size: usize ) { self .heap_start = heap_start; self .heap_end = heap_start + heap_size; self .next.store (heap_start, core::sync::atomic::Ordering::SeqCst); } } unsafe impl GlobalAlloc for BumpAllocator { unsafe fn alloc (&self , layout: Layout) -> *mut u8 { use core::sync::atomic::Ordering; loop { let current = self .next.load (Ordering::Relaxed); let aligned = align_up (current, layout.align ()); let new_next = aligned + layout.size (); if new_next > self .heap_end { return core::ptr::null_mut (); } if self .next.compare_exchange_weak ( current, new_next, Ordering::SeqCst, Ordering::Relaxed ).is_ok () { return aligned as *mut u8 ; } } } unsafe fn dealloc (&self , _ptr: *mut u8 , _layout: Layout) { } } fn align_up (addr: usize , align: usize ) -> usize { (addr + align - 1 ) & !(align - 1 ) } #[global_allocator] static ALLOCATOR: BumpAllocator = BumpAllocator::new ();#[alloc_error_handler] fn alloc_error (_layout: Layout) -> ! { loop {} }
使用现有分配器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #![no_std] #![feature(alloc_error_handler)] extern crate alloc;use linked_list_allocator::LockedHeap;#[global_allocator] static ALLOCATOR: LockedHeap = LockedHeap::empty ();pub fn init_heap (heap_start: usize , heap_size: usize ) { unsafe { ALLOCATOR.lock ().init (heap_start as *mut u8 , heap_size); } } #[alloc_error_handler] fn alloc_error_handler (layout: core::alloc::Layout) -> ! { panic! ("allocation error: {:?}" , layout) } use alloc::vec::Vec ;pub fn test_alloc () -> Vec <i32 > { let mut v = Vec ::new (); v.push (1 ); v.push (2 ); v }
Panic 处理 基本 panic handler 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #![no_std] use core::panic::PanicInfo;#[panic_handler] fn panic (_info: &PanicInfo) -> ! { loop {} } #[panic_handler] fn panic_with_info (info: &PanicInfo) -> ! { if let Some (location) = info.location () { let _file = location.file (); let _line = location.line (); let _column = location.column (); } if let Some (message) = info.message () { let _ = message; } loop {} }
输出 panic 信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #![no_std] use core::panic::PanicInfo;use core::fmt::Write;struct UartWriter ;impl Write for UartWriter { fn write_str (&mut self , s: &str ) -> core::fmt::Result { for byte in s.bytes () { unsafe { core::ptr::write_volatile (0x1000_0000 as *mut u8 , byte); } } Ok (()) } } #[panic_handler] fn panic (info: &PanicInfo) -> ! { let mut writer = UartWriter; let _ = writeln! (writer, "\n!!! PANIC !!!" ); if let Some (location) = info.location () { let _ = writeln! ( writer, "Location: {}:{}:{}" , location.file (), location.line (), location.column () ); } if let Some (message) = info.message () { let _ = writeln! (writer, "Message: {}" , message); } loop { core::hint::spin_loop (); } }
panic = “abort” 配置 1 2 3 4 5 6 7 [profile.dev] panic = "abort" [profile.release] panic = "abort"
1 2 3 4 5 6 7 8 9 10 #![no_std] use core::panic::PanicInfo;#[panic_handler] fn panic (_: &PanicInfo) -> ! { loop {} }
嵌入式开发 项目结构 1 2 3 4 5 6 7 8 9 embedded_project/ ├── Cargo.toml ├── .cargo/ │ └── config.toml ├── memory.x # 链接脚本 ├── build.rs └── src/ ├── main.rs └── lib.rs
Cortex-M 示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [package] name = "embedded_app" version = "0.1.0" edition = "2021" [dependencies] cortex-m = "0.7" cortex-m-rt = "0.7" panic-halt = "0.2" [profile.release] opt-level = "z" lto = true debug = true
1 2 3 4 5 6 7 8 9 10 [target.thumbv7em-none-eabihf] runner = "probe-rs run --chip STM32F411CEUx" rustflags = [ "-C" , "link-arg=-Tlink.x" , ] [build] target = "thumbv7em-none-eabihf"
1 2 3 4 5 6 MEMORY { FLASH : ORIGIN = 0x08000000 , LENGTH = 512 K RAM : ORIGIN = 0x20000000 , LENGTH = 128 K }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #![no_std] #![no_main] use cortex_m_rt::entry;use panic_halt as _;#[entry] fn main () -> ! { let peripherals = cortex_m::Peripherals::take ().unwrap (); loop { cortex_m::asm::delay (1_000_000 ); } }
RISC-V 示例 1 2 3 4 5 6 7 8 9 10 [package] name = "riscv_app" version = "0.1.0" edition = "2021" [dependencies] riscv = "0.10" riscv-rt = "0.11" panic-halt = "0.2"
1 2 3 4 5 6 7 8 9 [target.riscv32imac-unknown-none-elf] rustflags = [ "-C" , "link-arg=-Tmemory.x" , "-C" , "link-arg=-Tlink.x" , ] [build] target = "riscv32imac-unknown-none-elf"
1 2 3 4 5 6 7 8 9 10 11 12 13 #![no_std] #![no_main] use riscv_rt::entry;use panic_halt as _;#[entry] fn main () -> ! { loop { riscv::asm::wfi (); } }
GPIO 操作示例(embedded-hal) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #![no_std] #![no_main] use cortex_m_rt::entry;use panic_halt as _;use embedded_hal::digital::v2::{OutputPin, InputPin};#[entry] fn main () -> ! { loop { } }
中断处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #![no_std] #![no_main] use cortex_m::peripheral::NVIC;use cortex_m_rt::{entry, exception};use panic_halt as _;#[exception] fn SysTick () { static mut COUNT: u32 = 0 ; *COUNT += 1 ; } #[exception] fn HardFault (ef: &cortex_m_rt::ExceptionFrame) -> ! { let _ = ef; loop {} } #[entry] fn main () -> ! { let mut peripherals = cortex_m::Peripherals::take ().unwrap (); let sysclk = 8_000_000 ; peripherals.SYST.set_reload (sysclk / 1000 - 1 ); peripherals.SYST.clear_current (); peripherals.SYST.enable_counter (); peripherals.SYST.enable_interrupt (); loop { cortex_m::asm::wfi (); } }
裸机/OS 开发 基本裸机程序(x86_64) 1 2 3 4 5 6 7 8 9 10 11 [package] name = "bare_metal" version = "0.1.0" edition = "2021" [profile.dev] panic = "abort" [profile.release] panic = "abort"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 { "llvm-target" : "x86_64-unknown-none" , "data-layout" : "e-m:e-i64:64-f80:128-n8:16:32:64-S128" , "arch" : "x86_64" , "target-endian" : "little" , "target-pointer-width" : "64" , "target-c-int-width" : "32" , "os" : "none" , "executables" : true , "linker-flavor" : "ld.lld" , "linker" : "rust-lld" , "panic-strategy" : "abort" , "disable-redzone" : true , "features" : "-mmx,-sse,+soft-float" }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #![no_std] #![no_main] #![feature(asm_const)] use core::panic::PanicInfo;const VGA_BUFFER: *mut u8 = 0xb8000 as *mut u8 ;#[no_mangle] pub extern "C" fn _start () -> ! { for i in 0 ..(80 * 25 * 2 ) { unsafe { *VGA_BUFFER.add (i) = 0 ; } } let hello = b"Hello, Bare Metal!" ; for (i, &byte) in hello.iter ().enumerate () { unsafe { *VGA_BUFFER.add (i * 2 ) = byte; *VGA_BUFFER.add (i * 2 + 1 ) = 0x0f ; } } loop { unsafe { core::arch::asm!("hlt" ); } } } #[panic_handler] fn panic (_info: &PanicInfo) -> ! { loop {} }
VGA 文本缓冲区抽象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 #![no_std] use core::fmt::{self , Write};use core::ptr;const VGA_WIDTH: usize = 80 ;const VGA_HEIGHT: usize = 25 ;const VGA_BUFFER_ADDR: usize = 0xb8000 ;#[repr(u8)] #[derive(Clone, Copy)] pub enum Color { Black = 0 , Blue = 1 , Green = 2 , Cyan = 3 , Red = 4 , Magenta = 5 , Brown = 6 , LightGray = 7 , DarkGray = 8 , LightBlue = 9 , LightGreen = 10 , LightCyan = 11 , LightRed = 12 , Pink = 13 , Yellow = 14 , White = 15 , } #[repr(transparent)] #[derive(Clone, Copy)] struct ColorCode (u8 );impl ColorCode { const fn new (foreground: Color, background: Color) -> Self { ColorCode ((background as u8 ) << 4 | (foreground as u8 )) } } #[repr(C)] #[derive(Clone, Copy)] struct ScreenChar { ascii: u8 , color: ColorCode, } pub struct Writer { col: usize , row: usize , color: ColorCode, buffer: &'static mut [[ScreenChar; VGA_WIDTH]; VGA_HEIGHT], } impl Writer { pub fn new () -> Self { Writer { col: 0 , row: 0 , color: ColorCode::new (Color::White, Color::Black), buffer: unsafe { &mut *(VGA_BUFFER_ADDR as *mut _) }, } } pub fn write_byte (&mut self , byte: u8 ) { match byte { b'\n' => self .new_line (), byte => { if self .col >= VGA_WIDTH { self .new_line (); } self .buffer[self .row][self .col] = ScreenChar { ascii: byte, color: self .color, }; self .col += 1 ; } } } fn new_line (&mut self ) { if self .row < VGA_HEIGHT - 1 { self .row += 1 ; } else { for row in 1 ..VGA_HEIGHT { for col in 0 ..VGA_WIDTH { self .buffer[row - 1 ][col] = self .buffer[row][col]; } } for col in 0 ..VGA_WIDTH { self .buffer[VGA_HEIGHT - 1 ][col] = ScreenChar { ascii: b' ' , color: self .color, }; } } self .col = 0 ; } pub fn clear (&mut self ) { for row in 0 ..VGA_HEIGHT { for col in 0 ..VGA_WIDTH { self .buffer[row][col] = ScreenChar { ascii: b' ' , color: self .color, }; } } self .col = 0 ; self .row = 0 ; } } impl Write for Writer { fn write_str (&mut self , s: &str ) -> fmt::Result { for byte in s.bytes () { match byte { 0x20 ..=0x7e | b'\n' => self .write_byte (byte), _ => self .write_byte (0xfe ), } } Ok (()) } } use spin::Mutex;lazy_static::lazy_static! { pub static ref WRITER: Mutex<Writer> = Mutex::new (Writer::new ()); } #[macro_export] macro_rules! print { ($($arg:tt)*) => { $crate::vga::_print(format_args! ($($arg)*)) }; } #[macro_export] macro_rules! println { () => ($crate::print! ("\n" )); ($($arg:tt)*) => ($crate::print! ("{}\n" , format_args! ($($arg)*))); } pub fn _print (args: fmt::Arguments) { use core::fmt::Write; WRITER.lock ().write_fmt (args).unwrap (); }
简单内存管理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 #![no_std] use core::alloc::{GlobalAlloc, Layout};use core::ptr::NonNull;pub struct FixedBlockAllocator { blocks_16: FreeList<16 >, blocks_64: FreeList<64 >, blocks_256: FreeList<256 >, blocks_1024: FreeList<1024 >, } struct FreeList <const SIZE: usize > { head: Option <NonNull<FreeNode>>, area_start: usize , area_end: usize , } struct FreeNode { next: Option <NonNull<FreeNode>>, } impl <const SIZE: usize > FreeList<SIZE> { pub const fn new () -> Self { FreeList { head: None , area_start: 0 , area_end: 0 , } } pub unsafe fn init (&mut self , start: usize , size: usize ) { self .area_start = start; self .area_end = start + size; let block_count = size / SIZE; for i in 0 ..block_count { let block_addr = start + i * SIZE; self .push (block_addr as *mut FreeNode); } } unsafe fn push (&mut self , node: *mut FreeNode) { (*node).next = self .head; self .head = Some (NonNull::new_unchecked (node)); } fn pop (&mut self ) -> Option <*mut u8 > { self .head.map (|node| { unsafe { self .head = node.as_ref ().next; node.as_ptr () as *mut u8 } }) } } impl FixedBlockAllocator { pub const fn new () -> Self { FixedBlockAllocator { blocks_16: FreeList::new (), blocks_64: FreeList::new (), blocks_256: FreeList::new (), blocks_1024: FreeList::new (), } } fn find_size_class (size: usize ) -> Option <usize > { match size { 0 ..=16 => Some (16 ), 17 ..=64 => Some (64 ), 65 ..=256 => Some (256 ), 257 ..=1024 => Some (1024 ), _ => None , } } } unsafe impl GlobalAlloc for FixedBlockAllocator { unsafe fn alloc (&self , layout: Layout) -> *mut u8 { let size = layout.size ().max (layout.align ()); core::ptr::null_mut () } unsafe fn dealloc (&self , ptr: *mut u8 , layout: Layout) { } }
常用 no_std Crate 核心工具 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 [dependencies] embassy-executor = { version = "0.5" , features = ["arch-cortex-m" , "executor-thread" ] }embassy-stm32 = { version = "0.1" , features = ["stm32f411ce" , "time-driver-any" ] }embassy-time = "0.3" embassy-sync = "0.6" defmt = "0.3" defmt-rtt = "0.4" panic-probe = { version = "0.3" , features = ["print-defmt" ] }heapless = "0.8" arrayvec = { version = "0.7" , default-features = false }spin = "0.9" lock_api = "0.4" ufmt = "0.2" bitflags = "2" bitfield = "0.14" serde = { version = "1" , default-features = false }postcard = "1" hashbrown = { version = "0.14" , default-features = false }thiserror-no-std = "2" log = "0.4" defmt = "0.3"
heapless 示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #![no_std] use heapless::{Vec , String , FnvIndexMap};fn use_heapless_vec () { let mut v : Vec <i32 , 16 > = Vec ::new (); v.push (1 ).unwrap (); v.push (2 ).unwrap (); for item in &v { } } fn use_heapless_string () { let mut s : String <64 > = String ::new (); use core::fmt::Write; write! (s, "Hello, {}!" , "world" ).unwrap (); } fn use_heapless_map () { let mut map : FnvIndexMap<&str , i32 , 16 > = FnvIndexMap::new (); map.insert ("one" , 1 ).unwrap (); map.insert ("two" , 2 ).unwrap (); if let Some (val) = map.get ("one" ) { } } use heapless::spsc::Queue;static mut QUEUE: Queue<u32 , 8 > = Queue::new ();fn producer () { unsafe { let mut producer = QUEUE.split ().0 ; producer.enqueue (42 ).unwrap (); } } fn consumer () { unsafe { let mut consumer = QUEUE.split ().1 ; if let Some (val) = consumer.dequeue () { } } }
embedded-hal 生态 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #![no_std] use embedded_hal::{ digital::{InputPin, OutputPin, StatefulOutputPin}, delay::DelayNs, spi::SpiDevice, i2c::I2c, }; pub struct SensorDriver <SPI> { spi: SPI, } impl <SPI, E> SensorDriver<SPI>where SPI: SpiDevice<Error = E>, { pub fn new (spi: SPI) -> Self { SensorDriver { spi } } pub fn read_value (&mut self ) -> Result <u16 , E> { let mut buf = [0u8 ; 2 ]; self .spi.transfer_in_place (&mut buf)?; Ok (u16 ::from_be_bytes (buf)) } } pub struct Led <PIN> { pin: PIN, } impl <PIN: OutputPin> Led<PIN> { pub fn new (pin: PIN) -> Self { Led { pin } } pub fn on (&mut self ) -> Result <(), PIN::Error> { self .pin.set_high () } pub fn off (&mut self ) -> Result <(), PIN::Error> { self .pin.set_low () } } impl <PIN: StatefulOutputPin> Led<PIN> { pub fn toggle (&mut self ) -> Result <(), PIN::Error> { self .pin.toggle () } } pub fn blink <PIN, DELAY>(led: &mut Led<PIN>, delay: &mut DELAY, times: u32 )where PIN: OutputPin, DELAY: DelayNs, { for _ in 0 ..times { led.on ().ok (); delay.delay_ms (500 ); led.off ().ok (); delay.delay_ms (500 ); } }
defmt 日志 1 2 3 4 [dependencies] defmt = "0.3" defmt-rtt = "0.4" panic-probe = { version = "0.3" , features = ["print-defmt" ] }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #![no_std] #![no_main] use defmt::{info, warn, error, debug, trace};use defmt_rtt as _;use panic_probe as _;#[cortex_m_rt::entry] fn main () -> ! { info!("Application started" ); let value = 42 ; debug!("Value: {}" , value); #[derive(defmt::Format)] struct SensorReading { temperature: i16 , humidity: u8 , } let reading = SensorReading { temperature: 25 , humidity: 60 , }; info!("Sensor reading: {:?}" , reading); loop { trace!("Loop iteration" ); cortex_m::asm::wfi (); } }
测试 no_std 代码 主机测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #![cfg_attr(not(test), no_std)] pub fn add (a: i32 , b: i32 ) -> i32 { a + b } #[cfg(test)] mod tests { use super::*; #[test] fn test_add () { assert_eq! (add (1 , 2 ), 3 ); } }
QEMU 测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [package] name = "no_std_tests" version = "0.1.0" edition = "2021" [[test]] name = "should_panic" harness = false [[test]] name = "integration" harness = false [dependencies] [dev-dependencies] x86_64 = "0.14" uart_16550 = "0.2"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #![no_std] #![no_main] #![feature(custom_test_frameworks)] #![test_runner(test_runner)] #![reexport_test_harness_main = "test_main" ] use core::panic::PanicInfo;#[no_mangle] pub extern "C" fn _start () -> ! { test_main (); loop {} } pub fn test_runner (tests: &[&dyn Fn ()]) { for test in tests { test (); exit_qemu (QemuExitCode::Failed); } exit_qemu (QemuExitCode::Success); } fn exit_qemu (exit_code: QemuExitCode) { use x86_64::instructions::port::Port; unsafe { let mut port = Port::new (0xf4 ); port.write (exit_code as u32 ); } } #[repr(u32)] enum QemuExitCode { Success = 0x10 , Failed = 0x11 , } #[panic_handler] fn panic (_info: &PanicInfo) -> ! { exit_qemu (QemuExitCode::Success); loop {} } #[test_case] fn should_panic () { panic! ("This should panic" ); }
使用 probe-rs 测试 1 2 3 4 5 cargo install probe-rs --features cli cargo test --target thumbv7em-none-eabihf
优化技巧 减小二进制大小 1 2 3 4 5 6 7 8 9 10 [profile.release] opt-level = "z" lto = true codegen-units = 1 panic = "abort" strip = true [profile.release.build-override] opt-level = "z"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 fn process <T: AsRef <[u8 ]>>(data: T) { process_inner (data.as_ref ()) } fn process_inner (data: &[u8 ]) { } #[inline(never)] fn large_function () { }
零成本抽象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #![no_std] const BUFFER_SIZE: usize = 256 ;pub struct Uart <STATE> { _state: core::marker::PhantomData<STATE>, } pub struct Disabled ;pub struct Enabled ;impl Uart <Disabled> { pub fn enable (self ) -> Uart<Enabled> { Uart { _state: core::marker::PhantomData } } } impl Uart <Enabled> { pub fn send (&mut self , byte: u8 ) { } pub fn disable (self ) -> Uart<Disabled> { Uart { _state: core::marker::PhantomData } } }
内存对齐优化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #![no_std] #[repr(align(4))] struct Aligned4 { data: [u8 ; 3 ], } #[repr(packed)] struct Packed { a: u8 , b: u32 , } #[repr(C)] struct CCompatible { field1: u32 , field2: u16 , field3: u8 , }
好了,你现在已经了解 Rust 的基本使用了,请用它来写一个操作系统吧!
版本更新变化