
Android安全-内核篇

基础知识
启动命令
1 | emulator \ |
CVE 复现
CVE-2023-21400 - Double Free | DirtyPTE
CVE-2023-21400 是 io_uring 中的 Double-Free 漏洞,影响内核 5.10。
漏洞分析
在io_uring中,当我们提交IOSQE_IO_DRAIN请求时,在之前提交的请求完成前,不会启动该请求。因此,推迟处理该请求,将该请求添加到io_ring_ctx->defer_list双链表中(io_defer_entry 对象)。
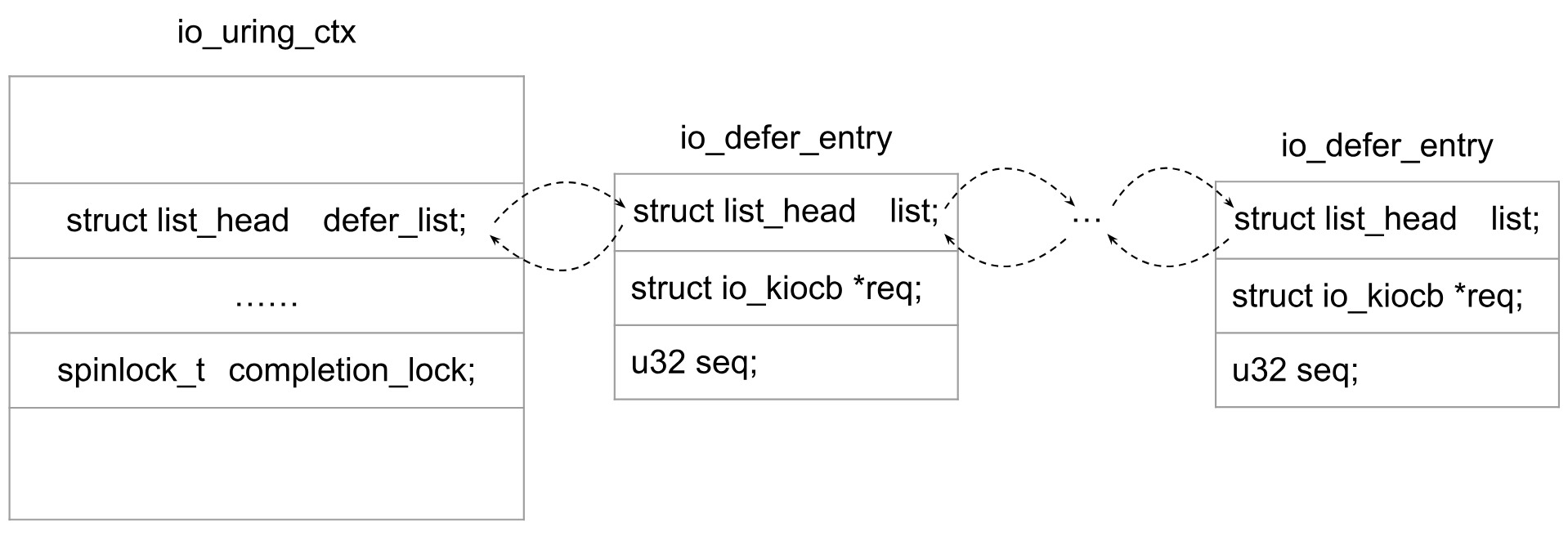
竞争访问1-漏洞对象取出:之前提交的请求完成以后,就会将推迟的请求(io_defer_entry对象)从defer_list中删除。由于可以并发访问defer_list,所以访问defer_list时必须加上自旋锁。但是,有一种情况是在没有completion_lock spinlock保护的情况下访问的defer_list。在io_uring中启用了IORING_SETUP_IOPOLL时,可以通过调用 io_uring_enter(IORING_ENTER_GETEVENTS)来获取事件完成情况,所触发的调用链为 io_uring_enter()->io_iopoll_check()->io_iopoll_getevents()->io_do_iopoll()->io_iopoll_complete()->io_commit_cqring()->__io_queue_deferred()。
1 | // __io_queue_deferred() —— 从`ctx->defer_list`取出延迟的请求 |
竞争访问2:以上函数访问ctx->defer_list时没有获取ctx->completion_lock锁,可能导致竞争条件漏洞。因为除了__io_queue_deferred()函数,io_cancel_defer_files()函数也可以处理ctx->defer_list:
io_cancel_defer_files()函数有两条触发路径:
do_exit()->io_uring_files_cancel()->__io_uring_files_cancel()->io_uring_cancel_task_requests()->io_cancel_defer_files()execve()->do_execve()->do_execveat_common()->bprm_execve()->io_uring_task_cancel()->__io_uring_task_cancel()->__io_uring_files_cancel()->io_uring_cancel_task_requests()->io_cancel_defer_files()—— 这种方式不需要退出当前任务,因此更加可控。可选择这种方式来触发。
1 | static void io_cancel_defer_files(struct io_ring_ctx *ctx, |
构造竞争:通过以下代码来构造竞争,同时处理ctx->defer_list。
![]()
改进条件竞争:竞争条件一般会触发内存损坏。对于本例会复杂一点,通常,io_cancel_defer_files()只处理当前任务创建的io_ring_ctx的延迟列表defer_list。因此,exec 任务中的io_cancel_defer_files()不会处理 iopoll 任务中相同的延迟列表。有一个例外,如果我们在exec任务中向 iopoll 任务的io_ring_ctx 提交IOSQE_IO_DRAIN请求时,就可以让exec任务进程中的io_cancel_defer_files()处理该io_ring_ctx的延迟队列。新的条件竞争如下:

在这种情况下,当exec任务和iopoll任务同时处理defer_list时,会触发内存损坏。
触发漏洞
由于竞争无法控制io_cancel_defer_files() 和 __io_queue_deferred() 何时被触发,可通过重复执行exec任务和iopoll任务,如下所示:

两种崩溃情况:
- (1)由无效list造成。
io_cancel_defer_files()和__io_queue_deferred()会竞争遍历ctx->defer_list并从中移除对象,因此ctx->defer_list可能会无效,会触发__list_del_entry_valid()导致内核崩溃。这种情况无法利用。 - (2)由Double-Free造成。情况如下:

尝试
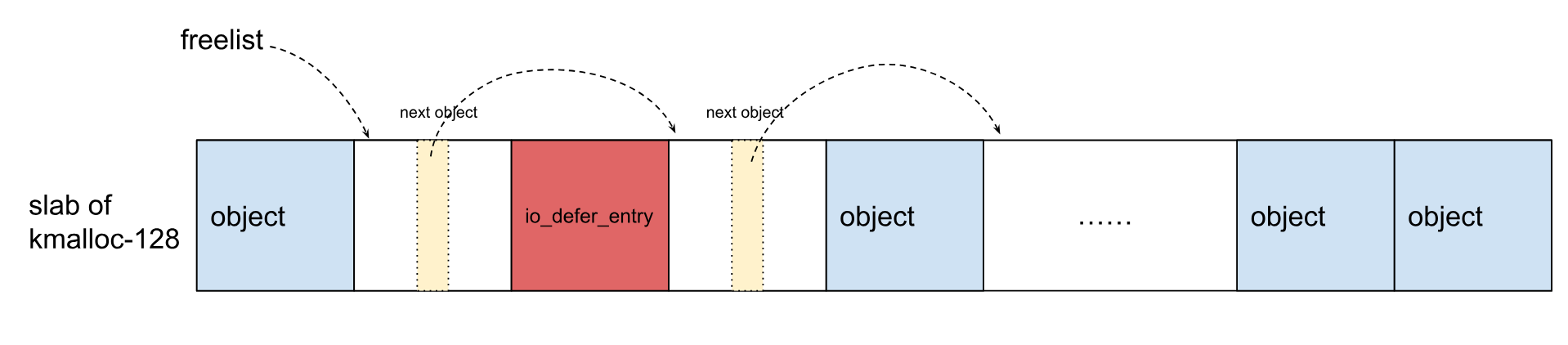
Android内核5.10中,io_defer_entry漏洞对象位于kmalloc-128,触发Double-Free的步骤如下:
(1)在第1次 kfree() 之前:
(2)在第1次 kfree() 之后:
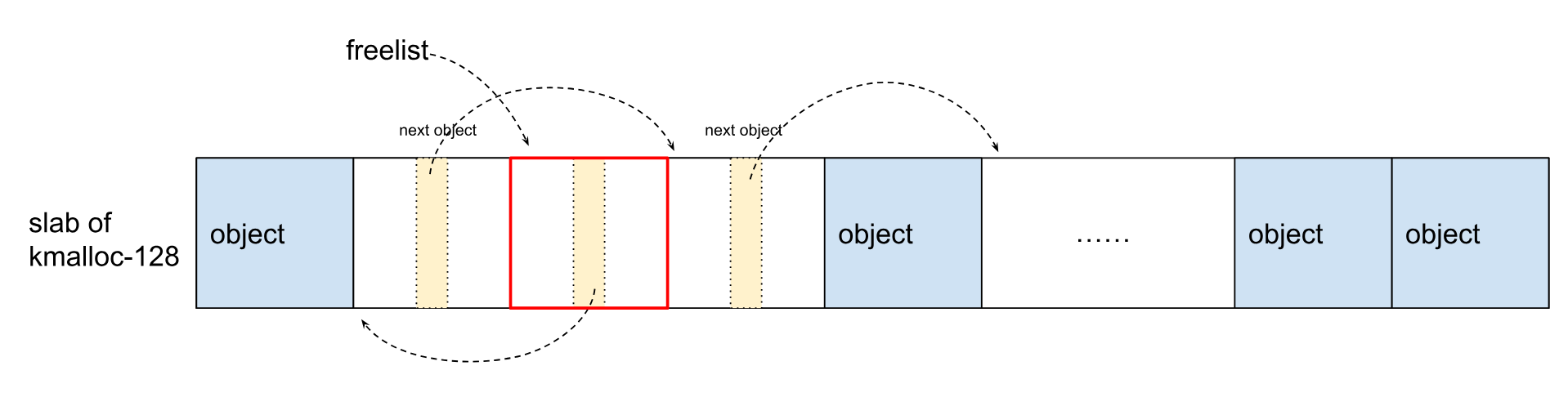
(3)第2次 kfree() 之后:

(4)如上所示,slab进入了非法状态:freelist和next object都指向同一空闲对象。理想情况下,我们可以从slab中分配对象两次,从而控制slab的freelist。首先,从slab中分配出一个内容可控的对象:
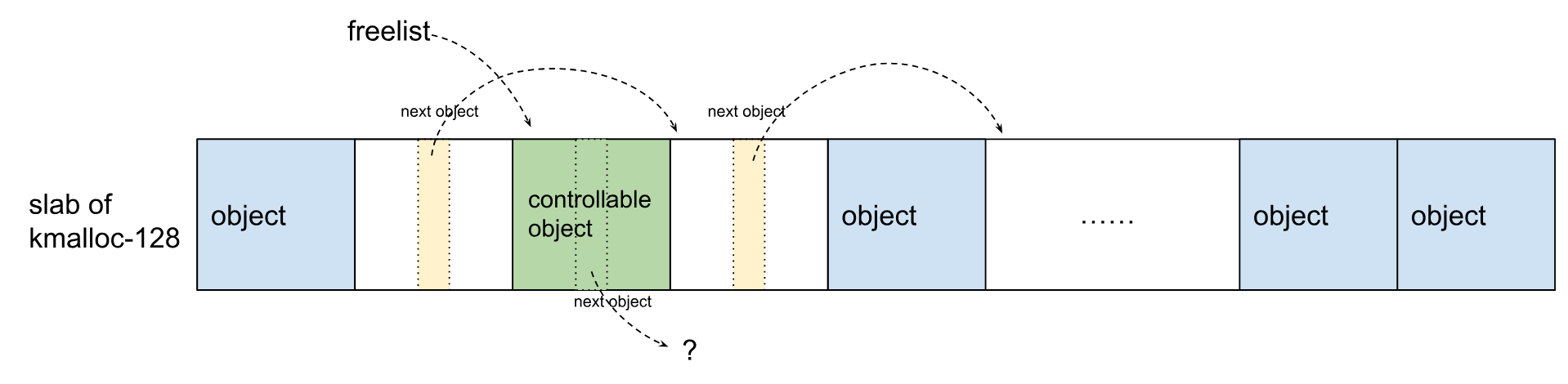
(5)可见,由于分配的对象内容可控,可以让next object指向我们可控的任何虚拟地址。接着,再次从slab中分配一个对象,slab如下所示:
让freelist指向我们可控的虚拟地址,就能轻松提权。问题是Android内核开启了CONFIG_SLAB_FREELIST_HARDENED,会混淆next object指针,由于freelist不可控而导致内核崩溃。
可利用性
目标:将Double-Free转化为UAF。

(1)挑战 1 - 竞争窗口过小:难以在两次释放io_defer_entry之间堆喷占用空闲对象
(2)挑战 2 - 重复触发Double-Free会降低可利用性
重复速度越快,Double-Free错误触发的速度越快。在测试时,可通过添加调试代码来增大两次kfree()之间的时间窗口,
(3)解决挑战1:

问题是,增大了竞争窗口,能够解决挑战1,但是使得重复速度变慢,很难触发Double-Free漏洞了。增大竞争窗口和提高重复速率相矛盾了。
(4)解决挑战 2 - 通过增大ctx->defer_list双链表的长度,增大iopoll任务的遍历时间,以控制竞争点的时序
首先,作者发现ctx->defer_list可以是很长的list,因为io_uring不限制ctx->defer_list中io_defer_entry对象的个数。其次,生成io_defer_entry对象很容易。根据 io_uring 稳定,我们不仅可以生成io_defer_entry对象与启用REQ_F_IO_DRAIN的请求相关联,还可以生成io_defer_entry对象与未启用REQ_F_IO_DRAIN的请求相关联。
2
3
4
5
When this flag is specified, the SQE will not be started before previously
submitted SQEs have completed, and new SQEs will not be started before this one
completes. Available since 5.2.
当指定此标志时,SQE将不会在之前提交的SQE完成之前开始处理,新的SQE也不会在这个SQE完成之前开始。5.2开始可用
以下代码用于生成100w个io_defer_entry对象,每个对象都与一个未启用 REQ_F_IO_DRAIN 的请求相关联:
1 | iopoll Task |
由于我们能够生成非常多的io_defer_entry,且与未启用REQ_F_IO_DRAIN的请求相关联,因此可以使 __io_queue_deferred() 遍历ctx->defer_list很长一段时间。这样能使__io_queue_deferred()执行数秒钟,然后同时准确的触发执行io_cancel_defer_files(),准确触发Double-Free。
(5)解决挑战 1 - 利用两次kfree()之间的代码来增大竞争窗口
现在不需要使用重复策略来触发Double-Free了,可以任意扩大 kfree()时间窗。很可惜Jann Horn[1]、Yoochan Lee、Byoungyoung Lee、Chanwoo Min[2]提出的方法都没用。那么 io_cancel_defer_files() 中是否有些代码可以帮助增大时间窗口呢?
作者发现,io_cancel_defer_files()第2次调用kfree()之前有很多唤醒操作,例如,会调用 io_req_complete() -> io_cqring_ev_posted()。
1 | static void io_cqring_ev_posted(struct io_ring_ctx *ctx) |
exec任务有4个地方会唤醒其他任务来运行,可利用第1个来扩大时间窗口。**对 io_uring fd调用epoll_wait(),就能在ctx->cq_wait上设置一个waiter;还需要另一个epoll任务来执行epoll_wait(),这样epoll任务就能在调用wake_up_interruptible()时抢占CPU,从而在第2次调用kfree()之前暂停 io_cancel_defer_files()**。问题是,如果很快就重新执行exec任务,时间窗还是很小。解决办法是采用 Jann Horn[1] 提到的调度器策略,成功将 kfree() 窗口增大数秒。
触发Double-Free并转化为UAF的流程如下:
提权
创建signalfd_ctx受害者对象
signalfd_ctx分配:调用signalfd()就会从 kmalloc-128 分配signalfd_ctx对象。
1 | static int do_signalfd4(int ufd, sigset_t *mask, int flags) |
signalfd_ctx读写操作:如上所示,在堆喷后会往signalfd_ctx开头写入8字节,但不影响利用。除了有限制的写操作,还可以通过show_fdinfo接口(procfs导出)读取signalfd_ctx的前8字节。
1 | static void signalfd_show_fdinfo(struct seq_file *m, struct file *f) |
**堆喷signalfd_ctx**:在两次kfree()之间,堆喷16000 signalfd_ctx 对象来占用释放的io_defer_entry对象。如果成功占据,那么第2次kfree()就会释放这个signalfd_ctx 对象,我们将其称为受害者signalfd_ctx 对象。
定位受害者signalfd_ctx 对象
思路:堆喷seq_operations对象是为了确定哪一个signalfd_ctx 对象被释放了,也即受害者signalfd_ctx 对象对应的fd,便于后面利用该fd篡改PTE。
第2次kfree()后堆喷16000个seq_operations对象,可调用single_open()来分配(打开/proc/self/status或其他procfs文件可触发single_open())。
1 | int single_open(struct file *file, int (*show)(struct seq_file *, void *), |
如果堆喷的seq_operations对象占据了某个释放的signalfd_ctx对象,如下所示:
方法:通过读取所有信号fd的fdinfo,如果其fdinfo与初始化不同,说明其前8字节被覆盖成了seq_operations的内核地址。该fd和受害者signalfd_ctx对象相关联。这样就定位到了受害者signalfd_ctx 对象
回收受害者signalfd_ctx 对象所在的slab
方法:关闭所有信号fd和/proc/self/status fd,除了受害者signalfd_ctx 对象对应的fd,这样受害者signalfd_ctx对象所在的slab变空,会被页分配器所回收。
用户页表占据受害者slab
目标:堆喷用户页表来占据受害者slab,并定位受害者signalfd_ctx对象的位置。
由于kmalloc-128 slab使用的是1-page,且用户页表也是1-page,这样可以堆喷用户页表来占据受害者slab。如果成功则如下图所示:
可见,通过写入受害者signalfd_ctx对象的前8字节,可以控制用户页表的某个PTE。将PTE的物理地址设置为内核text/data的物理地址,就能修改内核text/data数据。
页表喷射步骤如下:
(1)调用mmap()在虚拟地址空间中创建一块大内存区域
内存区域大小:因为每个末级页表描述了2M的虚拟内存(512*4096),所以如果要喷射512个用户页表,必须调用 mmap() 创建512*2M大小的内存区域。
内存区域计算 —— 内存区域大小 = 页表数量 * 2MiB
起始虚拟地址:起始虚拟地址需与2M(0x200000)对齐。原因是,现在我们只能控制signalfd_ctx的前8字节,并且不知道受害者signalfd_ctx对象在slab中具体位置,可能位于中间。0x200000对齐的起始虚拟地址能确保该地址对应的PTE位于页表的前8个字节。这样在第3步之后页表将如下所示:

(2)页表分配
分配方法:上一步已经创建了内存区域,现在可以从起始虚拟地址开始每隔0x200000字节执行一次写操作,确保内存区域对应的所有用户页表都被分配。即可堆喷用户页表。
1 | unsigned char *addr = (unsigned char *)start_virtual_address; |
(3)在页表中定位受害者signalfd_ctx对象
在第2步以后,我们只能确保每个页表的第1个PTE有效。因为受害者signalfd_ctx对象可以位于页表中与 128 对齐的任何偏移处,所以必须验证位于页表中所有与128对齐的偏移处的PTE。因此,我们从起始虚拟地址开始,每隔16K字节(每个page含有32个signalfd_ctx对象,对象大小为128字节,128 / 8 * 4096 = 16 page,这里的16K小了,但也能达到目的)进行一次写操作。最终的页表如上图所示。
定位方法:通过读取受害者信号fd的fdinfo,可以泄露受害者signalfd_ctx对象的前8个字节。如果能成功读取一个有效的PTE值,说明成功的用用户页表占用了受害者slab。否则,unmap() 该区域,重映射更大的内存,重复步骤(1)~(3)。
patch内核并提权
现在可通过受害者signalfd_ctx对象控制PTE,下面通过将PTE的物理地址设置为内核text/data地址,patch内核并提权。
(1)定位PTE对应的用户虚拟地址
目的:虽然现在可以控制用户页表的一个PTE,但是还不知道该PTE对应的用户虚拟地址。只有知道了该PTE对应的虚拟地址,才能通过写入该用户虚拟地址来patch内核的text/data。
方法:为了定位该PTE对应的用户虚拟地址,需将该PTE的物理地址修改为其他物理地址。然后遍历之前映射的所有虚拟地址,检查是否有一个虚拟地址上的值不是之前设置的初始值(0xaa)。如果找到这样一个虚拟地址,则说明就是PTE对应的虚拟地址。
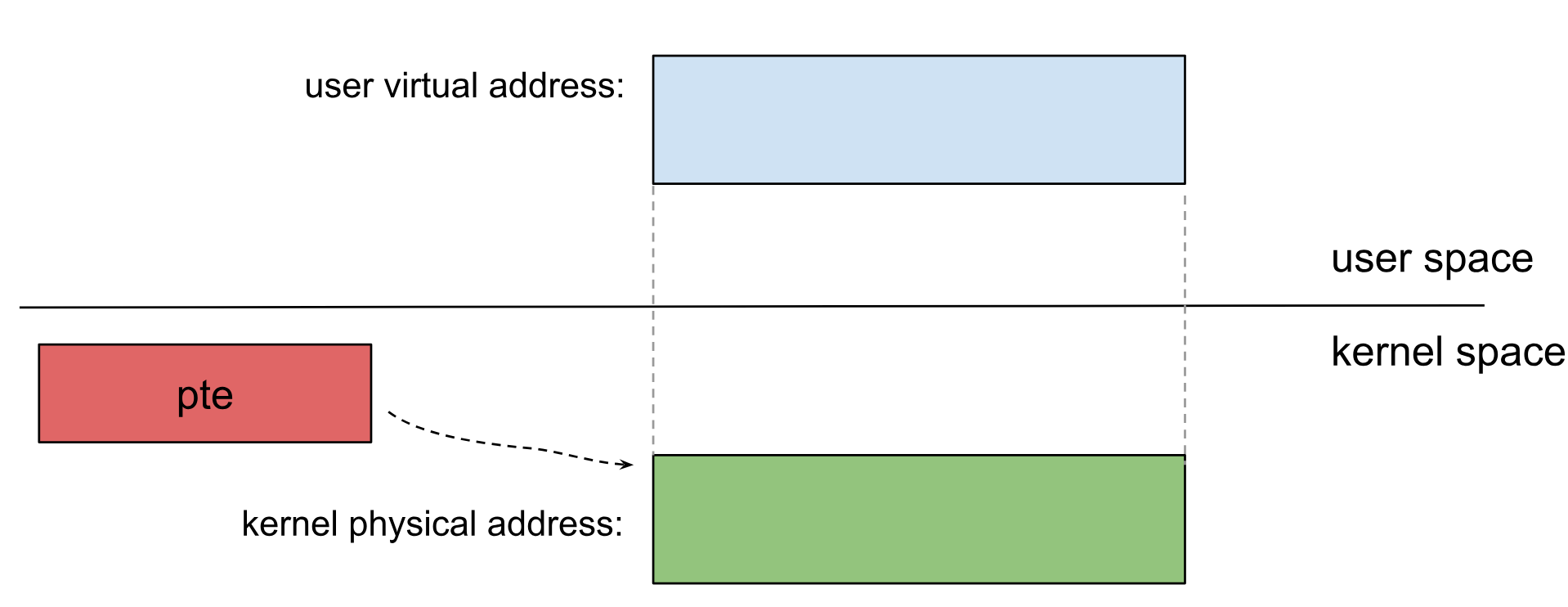
写限制:受害者signalfd_ctx对象的写入能力有限(写入值的bit 18和bit 8被设置为1),无法对内核任意地址进行patch。一个普通PTE对应的用户虚拟地址为0xe800098952ff43,其bit 8总是为1,但是bit 18位于PTE的物理地址中,所以只能对bit 18为1的物理地址进行patch。
该限制是由do_signalfd4()中的sigdelsetmask(mask, sigmask(SIGKILL) | sigmask(SIGSTOP));语句所导致,是否可以对该语句打patch呢?
1 | static int do_signalfd4(int ufd, sigset_t *mask, int flags) |
do_signalfd4()的物理地址的 bit 18 恰好为1,因此可patch sigdelsetmask(mask, sigmask(SIGKILL) | sigmask(SIGSTOP)); 语句。如何找到内核某函数的物理地址?
(3)对内核打补丁
目标是对selinux_state和setresuid()/setresgid()等函数打补丁,以提权 Google Pixel 7。由于只有一个PTE可控,所以需要多次修改PTE的物理地址。
(4)调用setresuid()、setresgid()提权
1 | if (setresuid(0, 0, 0) < 0) { |
最终在Google Pixel 7上成功提权:
![]()
CVE-2022-28350 - file UAF | DirtyPTE
file UAF现有利用方法
file UAF漏洞最近比较流行,主要有3种利用方法:
- (1)获取已释放的受害者
file对象,供新打开的特权文件重用,例如/etc/crontab,之后就能写入特权文件提权。Jann Horn[1]、Mathias Krause[5]、Zhenpeng Lin[6]和作者[7]用到了本方法。缺点有3个,一是在新内核上必须赢得竞争,有一定技巧性和概率性;二是Android上无法写入高权限文件,因为这些文件位于只读文件系统中;三是无法逃逸容器。 - (2)攻击系统库或可执行文件的页缓存, Xingyu Jin、Christian Resell、Clement Lecigne、Richard Neal[8] 和 Mathias Krause[9]用到了本方法。利用该方法可向libc.so等系统库中注入恶意代码,当特权进程执行libc.so时将以特权用户的身份执行恶意代码,利用结果类似于DirtyPipe。优点是不需要竞争,稳定性较好,但是要想在Android上完整提权或逃逸容器还很复杂,且不适用于其他类型的UAF漏洞。
- (3)Cross-cache 利用。Yong Wang[10] 和 Maddie Stone[11] 都用到了本方法。提权之前都需要绕过KASLR,Yong Wang[10] 通过重复使用 syscall 代码来猜测 kslides 绕过了KASLR,Maddie Stone[11] 通过另一个信息泄露漏洞绕过了KASLR。绕过KASLR之后,他们伪造了一个
file对象来构造内核读写原语。缺点是需要绕过KASLR。
脏页表方法利用file UAF
以CVE-2022-28350和内核版本为5.10的Android为例,介绍Dirty Pagetable的工作原理。
介绍:位于ARM Mali GPU驱动中的 file UAF 漏洞,影响Android 12 和 Android 13。漏洞原因如下。
1 | static int kbase_kcpu_fence_signal_prepare(...) { |
可见,调用 fd_install() 将 file 对象与 fd 关联起来。通过copy_to_user()将fd传递到用户空间,但如果拷贝失败,将释放 file 对象,导致一个有效的fd和已释放的file对象关联起来:
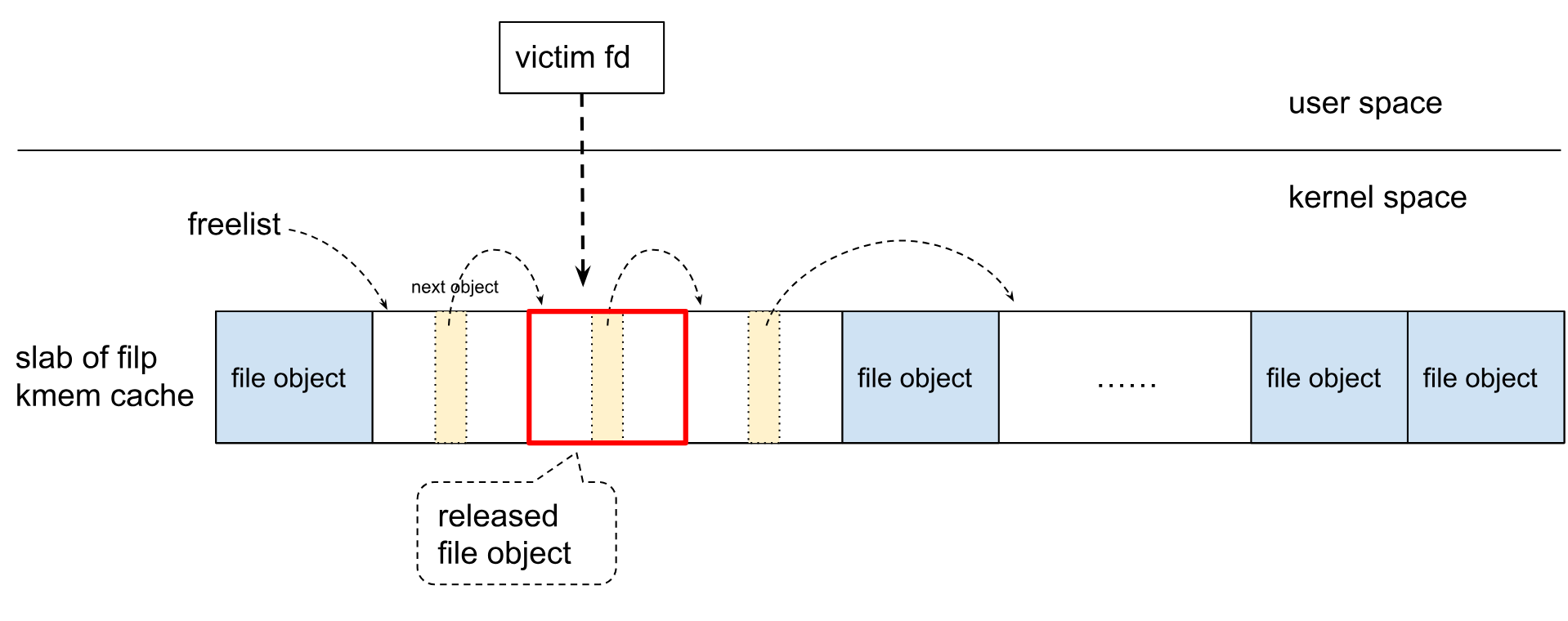
回收受害者slab
释放受害者slab上所有对象后,页分配器会回收该slab。
用户页表占据受害者slab
Android上 filp slab的大小是2-page,而用户页表大小是1-page。虽然二者大小不同,但是堆喷用户页表来占用受害者slab的成功率几乎是100%,占用成功后内存布局如下:
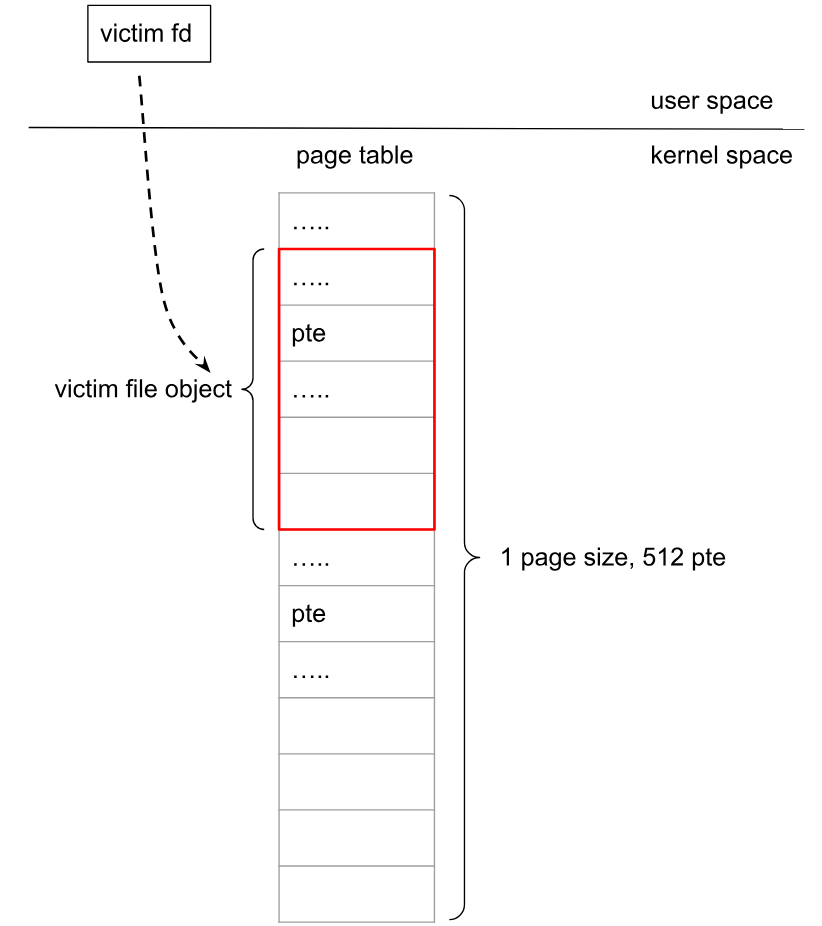
递增原语+定位受害者PTE对应的虚拟用户地址
递增原语:目的是构造写原语来篡改PTE。受害者file对象被用户页表所覆写,对该file对象进行操作可能导致内核崩溃。但是作者发现,调用 dup() 将file对象的f_count递增1,不会触发崩溃,问题是 dup() 会消耗fd资源,单个进程最多打开32768个fd,所以f_count最多递增32768。作者又发现fork()+dup()可突破该限制,先调用fork(),会将受害者file对象的f_count加1,子进程中可将f_count增加32768。由于可以多次重复fork()+dup(),所以成功突破限制。
PTE与f_count重叠:下一步是让受害者PTE的位置与f_count重合,这样就能利用递增原语来控制PTE。
file对象的对齐大小为320字节,f_count的偏移是56,占8字节。
1 | (gdb) ptype /o struct file |
filp cache的slab大小为2-page,一个filp cache的slab中有25个file对象,slab的结构如下所示:
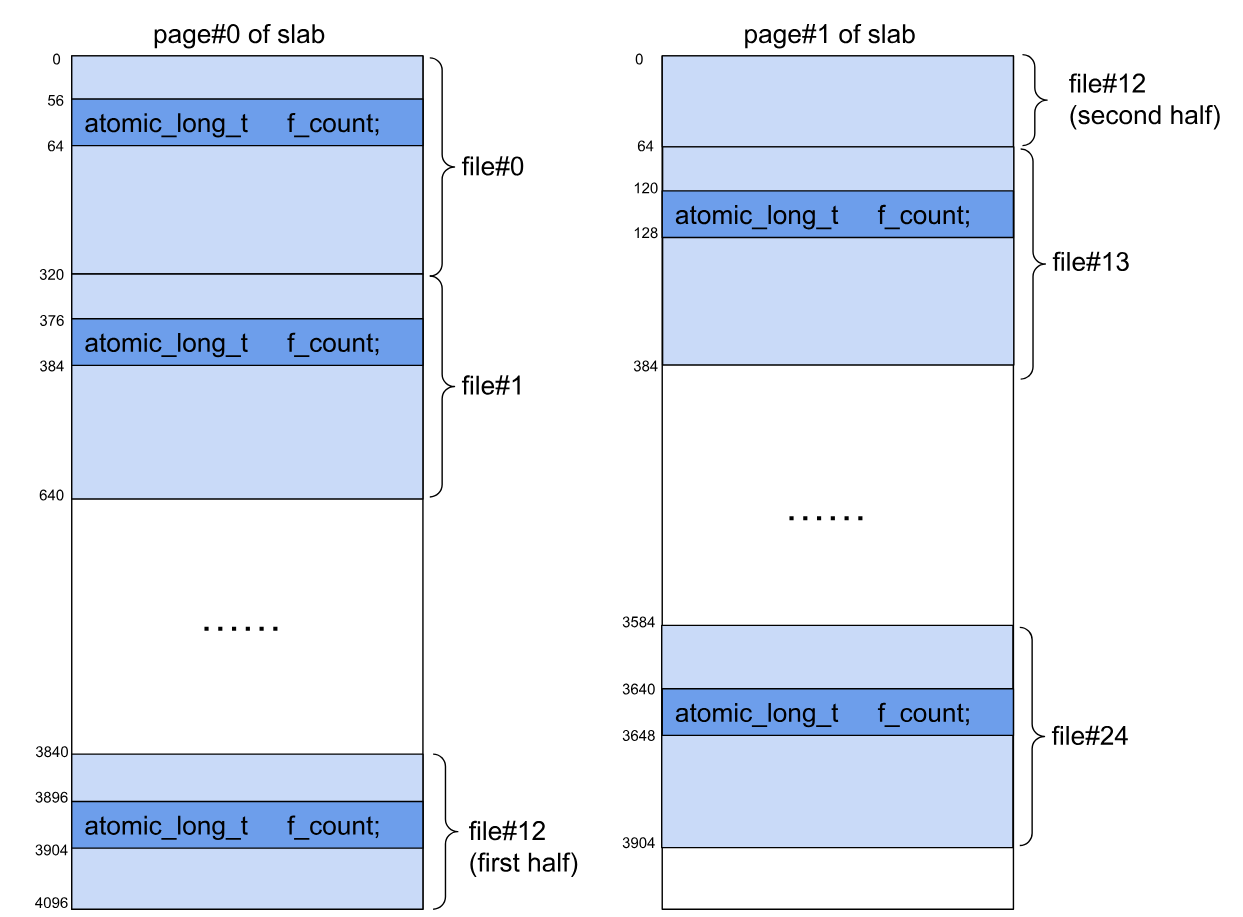
由于受害者file对象有25个可能的位置,为确保受害者file对象的f_count和受害者PTE恰好重合,需准备如下用户页表:
识别PTE对应的用户虚拟地址:现在我们能使受害者file对象的f_count与一个有效的PTE重合了,这个有效的PTE就是受害者PTE。如何找到受害者PTE对应的用户虚拟地址呢?可利用递增原语。
在利用递增原语之前,页表和相应的用户虚拟地址应该如下所示:可以看到,为了区分每个用户虚拟地址对应的物理页,作者将虚拟地址写在每个物理页的前8字节,作为标记。由于用户虚拟地址对应的所有物理页都是一次性分配的,因此它们的物理地址很可能是连续的。
如果我们利用递增原语将受害者PTE增加0x1000,就会改变与受害者PTE对应的物理页,如下所示:受害者PTE和另一个有效的PTE对应同一个物理页!现在可遍历所有虚拟页,检查前8字节是不是其虚拟地址,若不是,则该虚拟页就是受害者PTE对应的虚拟页。
堆喷占用页表
问题:现在找到了受害者PTE,且有递增原语。可将受害者PTE对应的物理地址设置为内核text/data的物理地址,但是mmap() 分配的内存对应的物理地址大于内核text/data的物理地址,而且递增原语有限,无法溢出受害者PTE。解决办法是使PTE指向某个用户页表,通过间接篡改用户页表,来篡改物理内存。
策略 1:现在已经让受害者PTE和另一有效PTE指向同一物理页,那么如果我们调用munmap()解除另一有效PTE的虚拟页映射,并触发物理页的释放,会发生什么?page UAF!再用用户页表占据释放页,就能控制用户页表。但问题是,很难堆喷用户页表来占据释放页。原因是,匿名 mmap() 分配的物理页来自内存区的MIGRATE_MOVABLE free_area,而用户页表是从内存区的MIGRATE_UNMOVABLE free_area分配,所以很难通过递增PTE使之指向另一用户页表。参考[10]解释了这一点。
策略 2:新策略能够捕获用户页表,步骤如下。本质是采用另一种方式来分配物理页,使该物理页和用户页表来自同一内存区域,这样如果受害者PTE指向该物理页,就能通过递增该PTE,使该PTE指向某个用户页表。
(1)对共享页和用户页表进行 heap shaping
目的:由于共享页和用户页表位于同一种内存,可将共享页嵌入到众多用户页表当中。
共享物理页:通常,内核空间和用户空间需要共享一些物理页,从两个空间都能访问到。有些组件可用于分配这些共享页,例如 dma-buf heaps, io_uring, GPUs 等。
分配共享物理页:作者选用 dma-buf 系统堆来分配共享页,因为可以从Android中不受信任的APP来访问/dev/dma_heap/system,并且 dma-buf 的实现相对简单。通过 open(/dev/dma_heap/system) 可获得一个 dma heap fd,然后用以下代码分配一个共享页:
1 | struct dma_heap_allocation_data data; |
由用户空间中的 dma_buf fd来表示一个共享页,可通过mmap() dma_buf fd 将共享页映射到用户空间。从 dma-buf 系统堆分配的共享页本质上是从页分配器分配的(实际上 dma-buf 子系统采用了页面池进行优化,对于本利用没有影响)。用于分配共享页的 gfp_flags 如下所示:
1 |
|
共享页分配vs页表分配:从LOW_ORDER_GFP可以看出,单个共享页是从内存的MIGRATE_UNMOVABLE free_area中分配的,和页表分配的出处一样。且单个共享页为order-1 (order-0 ?),和页表的order相同。结论是,单个共享页和页表都是从同一migrate free_cache中分配,且order相同。
通过以下步骤,就能获得下图中单个共享页和用户页表的布局:
1 | step1:分配3200个用户页表 |
(2)取消与受害者 PTE 对应的虚拟地址的映射,并将共享页映射到该虚拟地址
目标:由于共享页和页表位于同种内存,所以需要将受害者PTE从原先的物理页映射到共享物理页。
方法:可通过mmap() dma_buf fd 将共享页映射到用户空间,因此可先munmap() 受害者PTE对应的虚拟地址,然后将单个共享页映射到该虚拟地址。如下图所示:

(3)利用递增原语捕获用户页表
现在,我们利用递增原语对受害者PTE增加0x1000、0x2000、0x3000,有很大机率使受害者PTE对应到另一用户页表。如下图所示:

现在已经控制了一个用户页表。通过修改用户页表中的PTE,就能修改内核 text/data,即可提权:

CVE-2020-29661 - pid UAF | DirtyPTE
介绍:CVE-2020-29661属于pid UAF漏洞,已被Jann Horn[12]和Yong Wang[10]利用。Jann Horn在Debian上通过控制用户页表来修改只读文件(例如,setuid二进制文件)的页缓存,缺点是无法逃逸容器,且不能绕过Android上的SELinux防护。
作者采用Dirty Pagetable的方法重新利用了CVE-2020-29661,能在含有内核4.14的Google Pixel 4上提权。pid UAF 和 file UAF 都使用类似的增递增原语来操作 PTE。以下只介绍关键步骤。
脏页表方法利用CVE-2020-29661
与file UAF类似,在触发CVE-2020-29661并释放受害者slab中的所有其他pid对象后,用用户页表占用受害者slab。如下图所示,受害者pid对象位于用户页表中:
利用pid UAF构造递增原语
目标:利用递增原语篡改受害者PTE。
选取受害者pid对象的count成员与有效PTE重合,count位于pid对象的前4字节(8字节对齐):
1 | struct pid |
尽管 count 字段只有4字节,但是与PTE的低4字节重合。Jann horn[12] 之前基于 count 构造了递增原语,但是限制也是由于fd资源有限,可通过 fork() 在多个进程中执行递增原语,突破限制。
分配共享页
内核4.14中没有 dma-buf,可通过ION来分配共享页,ION更加方便,因为可通过设置ION的flag直接从页分配器分配共享页。分配代码如下:
1 |
|
共享页由用户空间中的dma_buf_fd 表示,可通过 mmap() dma_buf_fd 将共享页映射到用户空间。
Google Pixel 4提权
成功提权:
![]()
CVE-2019-2215 - Binder UAF
exploit
1 | /* |
Syzkaller For Android Kernel
please goto 《Syzkaller源码分析及利用》…….
- Title: Android安全-内核篇
- Author: 韩乔落
- Created at : 2024-10-22 15:21:46
- Updated at : 2025-12-24 15:42:49
- Link: https://jelasin.github.io/2024/10/22/Android安全-内核篇/
- License: This work is licensed under CC BY-NC-SA 4.0.