
Linux环境编程与内核之进程

前言
在Linux内核源码分析进程一篇中,讲解了内核中进程的实现原理,本文从开发角度来审视进程。
进程环境
程序的开始
1 | // source |
在链接生成最后的可执行文件时,有大量的C库二进制文件参与进来,如crt1.o、crti.o等。可见最终的可执行文件,除了我们编写的这个简单的C代码以外,还有大量的C库文件参与了链接,并包含在最终的可执行文件中。这个“组装”的过程,是由链接器ld的链接脚本来决定的。在没有指定链接脚本的情况下,会使用ld的默认脚本,可以通过ld–verbose来查看,
1 | ❯ ld -verbose |
下面我们来追溯一下Linux可执行程序完整的启动过程。前面的链接脚本明确了入口为_start。在32位的x86平台中,_start位于sysdeps/i386/start.S中。
1 | .text |
上面列出的虽然是汇编代码,但是每一行都有清楚的注释,这段代码主要是为程序的运行创建好运行环境,其中需要注意的是,__libc_csu_fini和__libc_csu_init都被作为参数传给了__libc_start_main。从这两个函数的名字上可以推测它们是用来处理退出和初始化阶段的函数,那么.ctors section中的函数很可能就是由__libc_csu_init来调用的。我们先来关注__libc_csu_init是在何时被调用的,然后再分析其实现。上面的汇编代码将这两个函数作为参数传递给了__libc_start_main,然后又调用了generic_start_main函数。这个函数初始化了C库所需要的环境,如环境变量、函数栈、多线程环境等,最后调用main函数——进入普通应用程序的真正入口。而在此之前,以下代码先被执行:
1 | /* Register the destructor of the program, if any. */ |
init即为__libc_csu_init,上面的代码保证了__libc_csu_init在main之前被调用。.ctors的函数调用流程:__libc_csu_init->_init->__libc_global_ctors。
1 | void |
__CTOR_LIST__是一个函数指针数组,数组的大小为1。该数组使用gcc的扩展属性,使__CTOR_LIST__位于.ctors section中。因此,在上面的代码中,__libc_global_ctors将__CTOR_LIST__传递给了run_hooks,实际上就是将.ctors section的起始地址传递给了run_hooks。而__CTOR_LIST__位于.ctors的第一个位置,其本身并不是一个真正的.ctors属性函数,因此run_hooks的while(*++list)先执行自增操作,即跳过了__CTOR_LIST__。
可以通过 r2 反汇编查看二进制的可执行程序来验证:
1 | 080483e4 <before_main>: |
可以看到,函数before_main的地址为0x080483e4。然后使用objdump来查看.ctors section:
1 | objdump -s -j .ctors a.out |
可以看到,.ctors section的第一个元素即上文中的__CTOR_LIST__,第二个元素为before_main——由于x86是小端CPU,因此0xe4830408实际上表示的地址值为0x080483e4。
需要注意的是,在新版本的gcc中,.ctors属性的函数并不会位于.ctors section中,而是被gcc合并到了.init_array section中,.dtors section也被合并到了.fini_array section中。下面来看一下这种情况下的objdump输出:
1 | # 可以看到,在.ctors section中,没有任何有效的.ctors函数, |
关于 exit
在刚刚学习C语言的时候,我们就被告知分配内存以后,如果不使用free来释放内存,就会造成内存的泄漏。同样,打开文件以后,如果忘记close也会造成资源的泄漏。那么,在进程退出以后,这些资源是否真的泄漏了呢?
当进程正常退出时,会调用C库的exit;而当进程崩溃或被kill掉时,C库的exit则不会被调用,只会执行内核退出进程的操作。
首先,我们来分析C库的退出函数exit,代码如下:
1 | void |
C库的exit主要用来执行所有注册的退出函数,比如使用atexit或on_exit注册的函数。执行完注册的退出函数后,__run_exit_handlers会调用_exit,代码如下:
1 | void |
上面的代码很简单,当平台有exit_group时,就调用exit_group,否则就调用exit。从Linux内核2.5.35版本以后,为了支持线程,就有了exit_group。这个系统调用不仅仅是用于退出当前线程,还会让所有线程组的线程全部退出。下面来看看系统调用exit_group的实现:
1 | SYSCALL_DEFINE1(exit_group, int, error_code) |
下面来看看do_exit的实现:
1 | NORET_TYPE void do_exit(long code) |
从exit的源码可以得知,即使应用程序在应用层有内存泄漏或文件句柄泄漏也不必担心,当进程退出时,内核的exit_group调用将会默默地在后面做着清理工作,释放所有内存,关闭所有文件,以及其他资源——当然,前提条件是这些资源是该进程独享的。
关于 atexit
1 |
|
从上面的代码输出可以看出,我们顺序地注册callback1、callback2和callback3,当进程退出时,其调用顺序为callback3、callback2和callback1。
使用atexit注册的退出函数是在进程正常退出时,才会被调用。这里的正常退出是指,使用exit退出或使用main中最后的return语句退出。若是因为收到信号而导致程序退出,atexit注册的退出函数则不会被调用。下面我们通过一个测试程序来验证这一观点:
1 |
|
我们会发现atexit注册的退出函数并没有被调用,下面我们来看一下其在 glibc 中的源码:
1 | int |
上面的代码揭示了atexit是如何把函数注册到退出函数链表中的。那么,这些函数又是何时被调用的呢?回忆atexit的介绍,退出注册函数只有在程序正常退出或调用exit时才会被执行。程序正常退出时,系统就会调用exit。因此,问题的关键就在于exit函数了:
1 | void |
在这里,__run_exit_handlers会遍历__exit_funcs,一一调用注册的退出函数,在此就不再罗列其代码了。从atexit的实现机制上进行分析,我们可以得出atexit的实现是依赖于C库的代码的。当进程收到信号时,如果没有注册对应的信号处理函数,那么内核就会执行信号的默认动作,一般是直接终止进程。这时,进程的退出完全由内核来完成,自然不会调用到C库的exit函数,也就无法调用注册的退出函数了。
环境变量
Linux环境下,程序在启动的时候都会从shell环境下继承当前的环境变量,如PATH、HOME、TZ等。我们也可以通过C库的接口来增加、修改或删除当前进程的环境变量,putenv用于增加或修改当前的环境变量。string的格式为“名字=值”。如果当前环境变量没有该名称的环境变量,则增加这个新的环境变量;如果已经存在,则使用新值。看似功能很简单,但实际上使用这个接口时,却很容易犯错。请看下面的代码:
1 |
|
使用putenv添加环境变量时,参数直接被当作环境变量的一部分了。对于本例而言,set_env_string中的test_env数组直接被环境变量引用了。而test_env是一个局部变量,在执行set_env_string的时候,test_env已经不存在了,对应栈上的内存会在后面的函数调用中使用,并存入其他值。因此,在进入show_env_string的时候,就无法得到正确的值了。
笔者曾经修改过一个因为putenv引起的bug,当时也是费了很大一番力气才找到根本原因,所以颇为气愤当时的开发人员为什么在使用putenv的时候,不认真阅读该接口的说明。Martin Golding曾说过一句话“编程的时候,要总是想着那个维护你代码的人会是一个知道你住在哪儿的、有暴力倾向的精神病患者”。
如果非要用putenv来设置环境变量,就必须要保证参数是一个长期存在的内容。因此,只能选择全局变量、常量或动态内存等。为了避免犯错,我们应该尽量使用另外一个接口setenv,代码如下:
1 |
|
1 |
|
动态库
编译生成和使用动态库
1 | $ cat 4_5_2_dlib.c |
显示无法找到libdlib.so。原因在于-L只是在gcc编译的过程中指示库的位置,而在程序运行的时候,动态库的加载路径默认为/lib和/usr/lib。在Linux环境下,还可以通过/etc/ld.so.conf配置文件和环境变量LD_LIBRARY_PATH指示额外的动态库路径,或者使用patch_elf修改动态库路径。为简单起见,我们在这里将libdlib.so复制到/usr/lib目录下,再运行test_dlib试试:
1 | $ cp /home/fgao/works/my_git_codes/my_books/understanding_apue/sample_codes/chapter3/libdlib.so . |
上面的例子中,动态库是由系统自动加载的,所以需要将动态库放在指定的目录下。然而,C库还提供了dlopen等接口来支持手工加载动态库的功能,代码如下:
1 |
|
1 |
|
动态升级
动态库的一个重要优点就是,可执行程序并不包含动态库中的任何指令,而是在运行时加载动态库并完成调用。这就给我们提供了升级动态库的机会。只要保证接口不变,使用新版本的动态库替换原来的动态库,就完成了动态库的升级。
更新完库文件以后启动的可执行程序都会使用新的动态库。这样的更新方法只能够影响更新以后启动的程序,对于正在运行的程序则无法产生效果,因为程序在运行时,旧的动态库文件已经加载到内存中了。我们只能更新位于磁盘上的动态库的物理文件,而不能影响已经位于内存中的库了。
对于服务程序来说,重启会付出很大的代价并带来糟糕的用户体验。但可以使用前面介绍的手工加载动态库的方法。下面的伪代码将给出一个比较简单的解决方案。
1 | // (1) 使用一个结构体来管理动态库的接口: |
内存问题
内存泄漏
对于良好的代码风格,有一项很重要的要求是一个函数只专注于做一件事情。如果该函数像瑞士军刀一样能实现多个功能,那基本上可以断言这不是一个设计良好的函数。C库中的realloc函数就是一个典型的反面教材:
1 |
|
内存越界
通过良好的编程习惯基本上是可以避免内存越界问题的。防范的根本思想在于在对缓冲区(一般为数组)进行拷贝前,要保证复制的长度不要超过缓冲区的空间大小。比如在memcpy前,要检查目的地址是否有足够的空间。使用宏或sizeof可保证缓冲长度的一致性;
1 | // 当缓冲大小改变为32的时候,需要改动两处代码。一旦忘记修改memcpy处的拷贝长度,就会造成内存越界。 |
使用安全的库函数也可以保证复制的长度不超过缓冲区的空间,下面来介绍4种库函数。
1)使用strncat代替strcat,代码如下:
1 |
|
从src中最多追加n个字符到dest字符串的后面。需要注意的是,当src包含n个以上的字符时,dest的空间至少为strlen(dest)+n+1,因为该函数还会追加字符串结束符'\0'到dest后面。
2)使用strncpy代替strcpy,代码如下:
1 |
|
从src中最多复制n个字符到dest字符串中。与strncat相同的是,当src包含n个以上的字符时,dest的空间需要为n+1,因为该函数还会再复制一个字符串结束符'\0'。
3)使用snprintf代替sprintf,代码如下:
1 |
|
snprintf比前面两个函数strncat和strncpy更为友好,在往str中写数据时,最多会写入n字节,其中已包括字符串结束符’\0’。
4)使用fgets代替gets,代码如下:
1 |
|
危险的gets函数从来不检查缓冲区的大小,并且还是从标准输入中读取数据,这是极其危险的行为。再大的缓存空间也无法满足永无终止的标准输入,因此一定要使用fgets代替。fgets最多会复制size-1字节到缓存s中,并且会在最后一个字符后面追加'\0'。
由于历史原因,标准C库中还存在其他不安全的接口,不过后来C库中也发展了相应的安全接口。在日常的编程中,除非特殊情况,都要使用安全函数来替代非安全函数的调用。
内存检查
工欲善其事,必先利其器。valgrind作为一个免费且优秀的工具包,提供了很多有用的功能,其中最有名的就是对内存问题的检测和定位。
1 |
|
上面的代码中包含了六种常见的内存问题:
- 动态内存泄漏;
- 资源泄漏,代码中以文件描述符为例;
- 动态内存越界;
- 数组越界;
- 动态内存double free;
- 使用野指针。
下面来看看怎样执行valgrind来检测内存错误:
1 | $ valgrind --track-fds=yes --leak-check=full --undef-value-errors=yes ./mem_test |
这只是一个简单的示例程序,即使没有valgrind,我们也可以很轻易地发现问题。但是在真实的项目中,当代码量达到万行、十万行甚至百万行时,由于申请的内存可能不是在一个地方被使用,它不可避免地会被传来传去。这时,如果只是靠review代码来检查问题,可能很难找到根本原因,而使用valgrind则可以很容易地发现问题所在。
当然,valgrind也不是万能的。笔者就遇到过valgrind无法找到问题,最后是通过不断地检查代码才找到症结所在的情况。发现问题,再解决问题,毕竟是末流。最好的方法,就是从一开始就不引入问题,防微杜渐。这点可以通过良好的代码风格和设计来实现。写代码不是一件容易的事情,要用心,把代码当作自己的作品,真心地去写好它。这样,自然而然的就会把代码写好。
长跳转
setjmp与longjmp
1 |
|
1 |
|
在main函数中,使用setjmp将当前的栈环境保存到g_stack_env中,然后调用func1->func2,在func2中,使用longjmp来恢复保存的栈环境g_stack_env,从而完成“长跳转”。
长跳转机制
setjmp和longjmp分别用于保存和恢复栈的上下文,来实现长跳转。而栈的实现肯定是与平台相关的,因此setjmp和longjmp的实现也是与平台相关的。
1 | /* Calling environment, plus possibly a saved signal mask. */ |
x86平台的__jmp_buf的定义为:
1 |
|
x86平台的setjmp和longjmp的实现均位于glibc-2.17/sysdeps/i386/setjmp.S中。
1 | ENTRY (BP_SYM (__sigsetjmp)) |
上面的汇编代码,主要是将寄存器EBX、ESI、EDI、ESP、PC和EBP寄存器保存到jmp_buf中。回想前面__jmp_buf的定义,它在x86_32位平台上是大小为6的int型数组,正好用于保存这6个寄存器。
看完了__sigsetjmp的实现,自然就轮到longjmp了:
1 | ENTRY (__longjmp) |
setjmp保存寄存器的内容,longjmp自然是恢复寄存器的内容。上面的代码很简单,把寄存器PC、EBX、ESI、EDI、EBP和ESP的内容恢复后,将第二个参数val保存到EAX中,最后跳转到恢复的PC寄存器处——也就是setjmp的下一条指令的位置。
长跳转陷阱
longjmp的man手册给出了如下说明:
当满足以下条件时,局部变量的值是不能确定的:
- 它们是调用setjmp所在函数的局部变量。
- 其值在setjmp和longjmp之间有变化。
- 它们没有被声明为volatile变量。
1 |
|
除了上面这个缺陷以外,如果我们的思维再开阔些,还能发现由longjmp实现原理引发的其他缺陷。比如因为它不能处理局部变量的问题,因此在C++中局部变量的析构肯定也是有问题的。
1 |
|
进程概念
进程是操作系统的一个核心概念。每个进程都有自己唯一的标识:进程ID,也有自己的生命周期。
进程 ID
Linux下每个进程都会有一个非负整数表示的唯一进程ID,简称pid。Linux提供了getpid函数来获取进程的pid,同时还提供了getppid函数来获取父进程的pid,相关接口定义如下:
1 |
|
每个进程都有自己的父进程,父进程又会有自己的父进程,最终都会追溯到1号进程即init进程。这就决定了操作系统上所有的进程必然会组成树状结构,就像一个家族的家谱一样。可以通过pstree的命令来查看进程的家族树。
procfs文件系统会在/proc下为每个进程创建一个目录,名字是该进程的pid。目录下有很多文件,用于记录进程的运行情况和统计信息等,如下所示:
1 | ll /proc总用量 0 |
因为进程有创建,也有终止,所以/proc/下记录进程信息的目录(以及目录下的文件)也会发生变化。操作系统必须保证在任意时刻都不能出现两个进程有相同pid的情况。虽然进程ID是唯一的,但是进程ID可以重用。进程退出以后,其进程ID还可以再次分配给其他的进程使用。
Linux分配进程ID的算法不同于给进程分配文件描述符的最小可用算法,它采用了延迟重用的算法,即分配给新创建进程的ID尽量不与最近终止进程的ID重复,这样就可以防止将新创建的进程误判为使用相同进程ID的已经退出的进程。
那么如何实现延迟重用呢?内核采用的方法如下:
1)位图记录进程ID的分配情况(0为可用,1为已占用)。
2)将上次分配的进程ID记录到last_pid中,分配进程ID时,从last_pid+1开始找起,从位图中寻找可用的ID。
3)如果找到位图集合的最后一位仍不可用,则回滚到位图集合的起始位置,从头开始找。
既然是位图记录进程ID的分配情况,那么位图的大小就必须要考虑周全。位图的大小直接决定了系统允许同时存在的进程的最大个数,这个最大个数在系统中称为pid_max。上面的第3步提到,回绕到位图集合的起始位置,从头寻找可用的进程ID。事实上,严格说来,这种说法并不正确,回绕时并不是从0开始找起,而是从300开始找起。内核在kernel/pid.c文件中定义了RESERVED_PIDS,其值是300,300以下的pid会被系统占用,而不能分配给用户进程:
1 | define RESERVED_PIDS 300 |
Linux系统下可以通过procfs或sysctl命令来查看pid_max的值:
1 | manu@manu-rush:~$ cat /proc/sys/kernel/pid_max |
从上面的操作可以看出,Linux系统将系统进程数的硬上限设置为4194304(4M)。内核又是如何决定系统进程个数的硬上限的呢?对此,内核定义了如下的宏:
1 |
从上面代码中可以看出决定系统进程个数硬上限的逻辑为:
- 如果选择了CONFIG_BASE_SMALL编译选项,则为页面(PAGE_SIZE)的位数。
- 如果选择了CONFIG_BASE_FULL编译选项,那么:
- 对于32位系统,系统进程个数硬上限为32768(即32K)。
- 对于64位系统,系统进程个数硬上限为4194304(即4M)。
通过上面的讨论可以看出,在64位系统中,系统容许创建的进程的个数超过了400万,这个数字是相当庞大的,足够应用层使用。对于单线程的程序,进程ID比较好理解,就是唯一标识进程的数字。对于多线程的程序,每一个线程调用getpid函数,其返回值都是一样的,即进程的ID。
进程层次
每个进程都有父进程,父进程也有父进程,这就形成了一个以init进程为根的家族树。除此以外,进程还有其他层次关系:进程、进程组和会话。进程组和会话在进程之间形成了两级的层次:进程组是一组相关进程的集合,会话是一组相关进程组的集合。
这样说来,一个进程会有如下ID:
- PID:进程的唯一标识。对于多线程的进程而言,所有线程调用getpid函数会返回相同的值。
- PGID:进程组ID。每个进程都会有进程组ID,表示该进程所属的进程组。默认情况下新创建的进程会继承父进程的进程组ID。
- SID:会话ID。每个进程也都有会话ID。默认情况下,新创建的进程会继承父进程的会话ID。
可以调用如下指令来查看所有进程的层次关系:
1 | $ ps -ejH |
对于进程而言,可以通过如下函数调用来获取其进程组ID和会话ID。
1 |
|
前面提到过,新进程默认继承父进程的进程组ID和会话ID,如果都是默认情况的话,那么追根溯源可知,所有的进程应该有共同的进程组ID和会话ID。但是调用ps axjf可以看到,实际情况并非如此,系统中存在很多不同的会话,每个会话下也有不同的进程组。
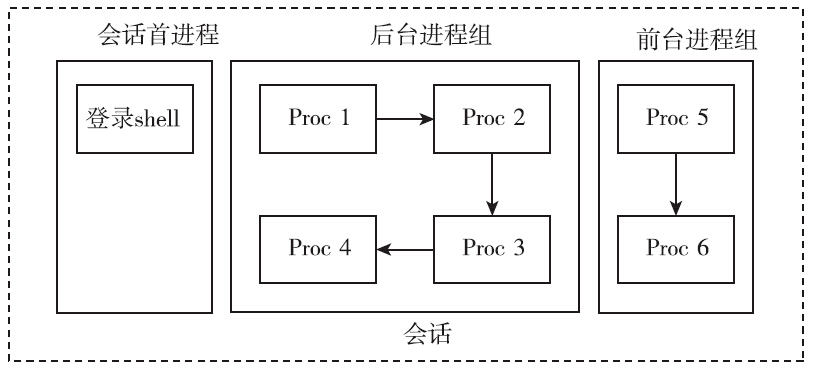
进程组和会话是为了支持shell作业控制而引入的概念。当有新的用户登录Linux时,登录进程会为这个用户创建一个会话。用户的登录shell就是会话的首进程。会话的首进程ID会作为整个会话的ID。会话是一个或多个进程组的集合,囊括了登录用户的所有活动。
在登录shell时,用户可能会使用管道,让多个进程互相配合完成一项工作,这一组进程属于同一个进程组。当用户通过SSH客户端工具连入Linux时,与上述登录的情景是类似的。
进程组
修改进程组ID的接口如下:
1 |
|
setpgid函数有很多限制:
- pid参数必须指定为调用setpgid函数的进程或其子进程,不能随意修改不相关进程的进程组ID,如果违反这条规则,则返回-1,并置errno为ESRCH。
- pid参数可以指定调用进程的子进程,但是子进程如果已经执行了exec函数,则不能修改子进程的进程组ID。如果违反这条规则,则返回-1,并置errno为EACCESS。
- 在进程组间移动,调用进程,pid指定的进程及目标进程组必须在同一个会话之内。如果违反这条规则,则返回-1,并置errno为EPERM。
- pid指定的进程,不能是会话首进程。如果违反这条规则,则返回-1,并置errno为EPERM。
有了创建进程组的接口,新创建的进程组就不必继承父进程的进程组ID了。最常见的创建进程组的场景就是在shell中执行管道命令,代码如下:
1 | cmd1 | cmd2 | cmd3 |
下面用一个最简单的命令来说明,其进程之间的关系如图:
1 | ps ax|grep nfsd |
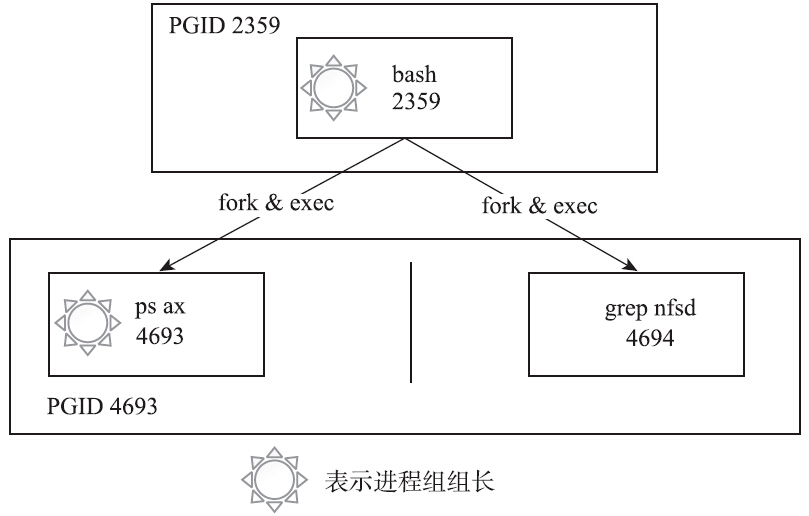
ps进程和grep进程都是bash创建的子进程,两者通过管道协同完成一项工作,它们隶属于同一个进程组,其中ps进程是进程组的组长。
引入了进程组的概念,可以更方便地管理这一组进程了。比如这项工作放弃了,不必向每个进程一一发送信号,可以直接将信号发送给进程组,进程组内的所有进程都会收到该信号。
前文曾提到过,子进程一旦执行exec,父进程就无法调用setpgid函数来设置子进程的进程组ID了,这条规则会影响shell的作业控制。出于保险的考虑,一般父进程在调用fork创建子进程后,会调用setpgid函数设置子进程的进程组ID,同时子进程也要调用setpgid函数来设置自身的进程组ID。这两次调用有一次是多余的,但是这样做能够保证无论是父进程先执行,还是子进程先执行,子进程一定已经进入了指定的进程组中。由于fork之后,父子进程的执行顺序是不确定的,因此如果不这样做,就会造成在一定的时间窗口内,无法确定子进程是否进入了相应的进程组。
可以通过跟踪bash进程的系统调用来证明这一点,下面的2258进程是bash,我们在该bash上执行sleep 200,在执行之前,在另一个终端用strace跟踪bash的系统调用,可以看到,父进程和子进程都执行了一遍setpgid函数,代码如下所示:
1 | manu@manu-hacks:~$ sudo strace -f -p 2258 |
用户在shell中可以同时执行多个命令。对于耗时很久的命令(如编译大型工程),用户不必傻傻等待命令运行完毕才执行下一个命令。用户在执行命令时,可以在命令的结尾添加“&”符号,表示将命令放入后台执行。这样该命令对应的进程组即为后台进程组。在任意时刻,可能同时存在多个后台进程组,但是不管什么时候都只能有一个前台进程组。只有在前台进程组中进程才能在控制终端读取输入。当用户在终端输入信号生成终端字符(如ctrl+c、ctrl+z、ctr+\等)时,对应的信号只会发送给前台进程组。
shell中可以存在多个进程组,无论是前台进程组还是后台进程组,它们或多或少存在一定的联系,为了更好地控制这些进程组(或者称为作业),系统引入了会话的概念。会话的意义在于将很多的工作囊括在一个终端,选取其中一个作为前台来直接接收终端的输入及信号,其他的工作则放在后台执行。
会话
会话是一个或多个进程组的集合,以用户登录系统为例:
系统提供setsid函数来创建会话,其接口定义如下:
1 |
|
如果这个函数的调用进程不是进程组组长,那么调用该函数会发生以下事情:
1)创建一个新会话,会话ID等于进程ID,调用进程成为会话的首进程。
2)创建一个进程组,进程组ID等于进程ID,调用进程成为进程组的组长。
3)该进程没有控制终端,如果调用setsid前,该进程有控制终端,这种联系就会断掉。
调用setsid函数的进程不能是进程组的组长,否则调用会失败,返回-1,并置errno为EPERM。这个限制是比较合理的。如果允许进程组组长迁移到新的会话,而进程组的其他成员仍然在老的会话中,那么,就会出现同一个进程组的进程分属不同的会话之中的情况,这就破坏了进程组和会话的严格的层次关系了。Linux提供了setsid命令,可以在新的会话中执行命令,通过该命令可以很容易地验证上面提到的三点:
1 | $ setsid sleep 100 |
从输出中可以看出,系统创建了新的会话4469,新的会话下又创建了新的进程组,会话ID和进程组ID都等于进程ID,而该进程已经不再拥有任何控制终端了(TTY对应的值为“?”表示进程没有控制终端)。常用的调用setsid函数的场景是login和shell。除此以外创建daemon进程也要调用setsid函数。
进程创建
fork
Linux系统下,进程可以调用fork函数来创建新的进程。调用进程为父进程,被创建的进程为子进程。
1 |
|
与普通函数不同,fork函数会返回两次。一般说来,创建两个完全相同的进程并没有太多的价值。大部分情况下,父子进程会执行不同的代码分支。fork函数的返回值就成了区分父子进程的关键。fork函数向子进程返回0,并将子进程的进程ID返给父进程。当然了,如果fork失败,该函数则返回-1,并设置errno。
常见的出错情景如表:

1 | ret = fork(); |
fork可能失败。检查返回值进行正确的出错处理,是一个非常重要的习惯。设想如果fork返回-1,而程序没有判断返回值,直接将-1当成子进程的进程号,那么后面的代码执行kill(child_pid,9)就相当于执行kill(-1,9)。这会发生什么?后果是惨重的,它将杀死除了init以外的所有进程,只要它有权限。
从内核2.6.32开始,在默认情况下,父进程将成为fork之后优先调度的对象。采取这种策略的原因是:fork之后,父进程在CPU中处于活跃的状态,并且其内存管理信息也被置于硬件内存管理单元的转译后备缓冲器(TLB),所以先调度父进程能提升性能。从2.6.24起,Linux采用完全公平调度(Completely Fair Scheduler,CFS)。用户创建的普通进程,都采用CFS调度策略。对于CFS调度策略,procfs提供了如下控制选项:
1 | /proc/sys/kernel/sched_child_runs_first |
该值默认是0,表示父进程优先获得调度。如果将该值改成1,那么子进程会优先获得调度。POSIX标准和Linux都没有保证会优先调度父进程。因此在应用中,决不能对父子进程的执行顺序做任何的假设。如果确实需要某一特定执行的顺序,那么需要使用进程间同步的手段。
从 Linux 内核版本 5.9 开始,
kernel.sched_child_runs_first参数被移除了。在移除该参数后,内核默认的行为是 父进程在fork()后优先运行,并且无法通过参数进行更改。
fork之后的子进程完全拷贝了父进程的地址空间,包括栈、堆、代码段等。通过下面的示例代码,我们一起来查看父子进程的内存关系:
1 |
|
这里刻意定义了三个变量,一个是位于数据段的全局变量,一个是位于栈上的局部变量,还有一个是通过malloc动态分配位于堆上的变量,三者的初始值都是1。然后调用fork创建子进程,子进程将三个变量的值都改成了0。按照fork的语义,子进程完全拷贝了父进程的数据段、栈和堆上的内存,如果父子进程对相应的数据进行修改,那么两个进程是并行不悖、互不影响的。因此,在上面示例代码中,尽管子进程将三个变量的值都改成了0,对父进程而言这三个值都没有变化,仍然是1,代码的输出也证实了这一点。
前文提到过,子进程和父进程执行一模一样的代码的情形比较少见。Linux提供了execve系统调用,构建在该系统调用之上,glibc提供了exec系列函数。这个系列函数会丢弃现存的程序代码段,并构建新的数据段、栈及堆。调用fork之后,子进程几乎总是通过调用exec系列函数,来执行新的程序。在这种背景下,fork时子进程完全拷贝父进程的数据段、栈和堆的做法是不明智的,因为接下来的exec系列函数会毫不留情地抛弃刚刚辛苦拷贝的内存。为了解决这个问题,Linux引入了写时拷贝(copy-on-write)的技术。
写时拷贝是指子进程的页表项指向与父进程相同的物理内存页,这样只拷贝父进程的页表项就可以了,当然要把这些页面标记成只读。如果父子进程都不修改内存的内容,大家便相安无事,共用一份物理内存页。但是一旦父子进程中有任何一方尝试修改,就会引发缺页异常(page fault)。此时,内核会尝试为该页面创建一个新的物理页面,并将内容真正地复制到新的物理页面中,让父子进程真正地各自拥有自己的物理内存页,然后将页表中相应的表项标记为可写。
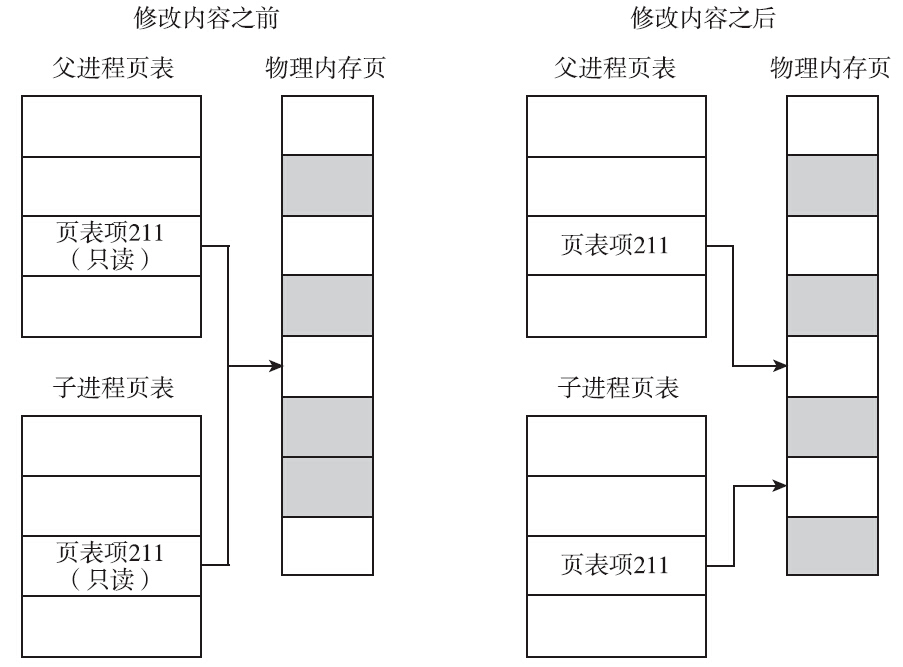
从上面的描述可以看出,对于没有修改的页面,内核并没有真正地复制物理内存页,仅仅是复制了父进程的页表。这种机制的引入提升了fork的性能,从而使内核可以快速地创建一个新的进程。
Linux的内存管理使用的是四级页表,如图4-6所示,看了四级页表的名字,也就不难推测图中那些函数的作用了。

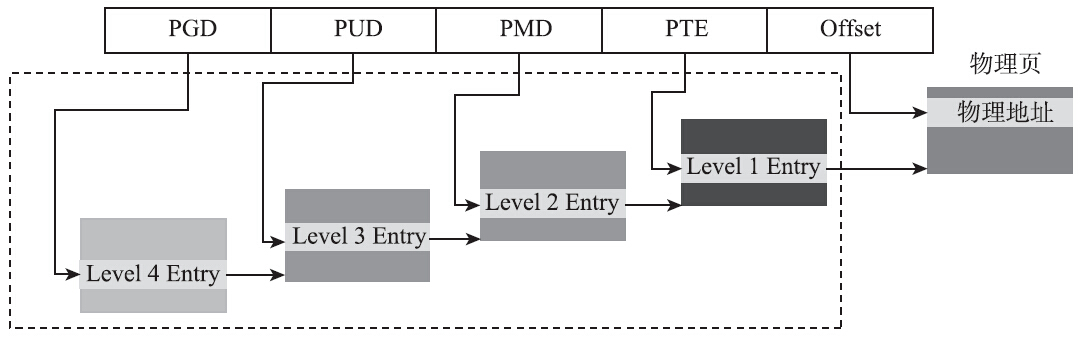
在最后的copy_one_pte函数中有如下代码:
1 | /*如果是写时拷贝,那么无论是初始页表,还是拷贝的页表,都设置了写保护 |
该代码将页表设置成写保护,父子进程中任意一个进程尝试修改写保护的页面时,都会引发缺页中断,内核会走向do_wp_page函数,该函数会负责创建副本,即真正的拷贝。写时拷贝技术极大地提升了fork的性能,在一定程度上让vfork成为了鸡肋。
执行fork函数,内核会复制父进程所有的文件描述符。对于父进程打开的所有文件,子进程也是可以操作的。那么父子进程同时操作同一个文件是并行不悖的,还是互相影响的呢?
下面通过对一个例子的讨论来说明这个问题。read函数并没有将偏移量作为参数传入,但是每次调用read函数或write函数时,却能够接着上次读写的位置继续读写。原因是内核已经将偏移量的信息记录在与文件描述符相关的数据结构里了。那么问题来了,父子进程是共用一个文件偏移量还是各有各的文件偏移量呢?
1 |
|
INFILE的内容是:
1 | 1 |
上面的程序中,父子进程都会去读INFILE,如果父子进程各维护各的文件偏移量,那么父子进程都会打印出1~6。事实如何呢?请看输出内容:
1 | $ ./fork_file |
如果父子进程各自维护自己的文件偏移量,那么一定是打印出两套1~6,但是事实并非如此。无论父进程还是子进程调用read函数导致文件偏移量后移都会被对方获知,这表明父子进程共用了一套文件偏移量。对于第二个输出,为什么父子进程都打印5呢?这是因为我的机器是多核的,父子进程同时执行,发现当前文件偏移量是4*2,然后各自去读了第8和第9字节,也就是“5\n”。写文件也是一样,如果fork之前打开了某文件,之后父子进程写入同一个文件描述符而又不采取任何同步的手段,那么就会因为共享文件偏移量而使输出相互混合,不可阅读。
文件描述符还有一个文件描述符标志(file descriptor flag)。目前只定义了一个标志位:FD_CLOSEXEC,这是close_on_exec标志位。细心阅读open函数手册也会发现,open函数也有一个类似的标志位,即O_CLOSEXEC,该标志位也是用于设置文件描述符标志的。那么这个标志位到底有什么作用呢?如果文件描述符中将这个标志位置位,那么调用exec时会自动关闭对应的文件。可是为什么需要这个标志位呢?主要是出于安全的考虑。对于fork之后子进程执行exec这种场景,如果子进程可以操作父进程打开的文件,就会带来严重的安全隐患。一般来讲,调用exec的子进程时,因为它会另起炉灶,因此父进程打开的文件描述符也应该一并关闭,但事实上内核并没有主动这样做。试想如下场景,Webserver首先以root权限启动,打开只有拥有root权限才能打开的端口和日志等文件,再降到普通用户,fork出一些worker进程,在进程中进行解析脚本、写日志、输出结果等操作。由于子进程完全可以操作父进程打开的文件,因此子进程中的脚本只要继续操作这些文件描述符,就能越权操作root用户才能操作的文件。
为了解决这个问题,Linux引入了close on exec机制。设置了FD_CLOSEXEC标志位的文件,在子进程调用exec家族函数时会将相应的文件关闭。
而设置该标志位的方法有两种:
- open时,带上O_CLOSEXEC标志位。
- open时如果未设置,那就在后面调用fcntl函数的F_SETFD操作来设置。
建议使用第一种方法。原因是第二种方法在某些时序条件下并不那么绝对的安全。
考虑以下的场景:Thread 1还没来得及将FD_CLOSEXEC置位,由于Thread 2已经执行过fork,这时候fork出来的子进程就不会关闭相应的文件。尽管Thread1后来调用了fcntl的F_SETFD操作,但是为时已晚,文件已经泄露了。
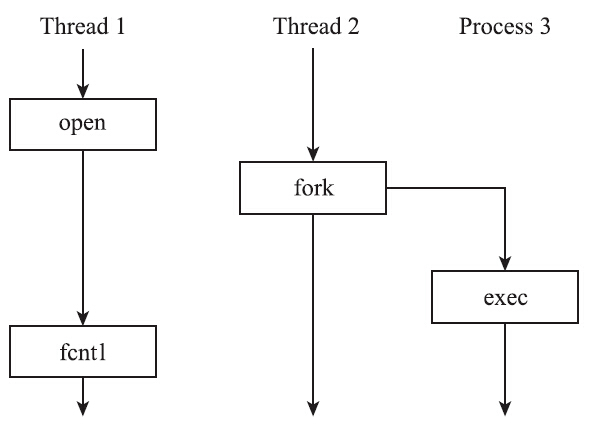
多线程程序执行了fork,仅仅是为了示意,实际中并不鼓励这种做法。正相反,这种做法是十分危险的。多线程程序不应该调用fork来创建子进程。
前面提到,执行fork时,子进程会获取父进程所有文件描述符的副本,但是测试结果表明,父子进程共享了文件的很多属性。这到底是怎么回事?让我们深入内核一探究竟。
在内核的进程描述符task_struct结构体中,与打开文件相关的变量如下所示:
1 | struct task_struct { |
CLONE_FILES标志位用来控制是否共享父进程的文件描述符。如果该标志位置位,则表示不必费劲复制一份父进程的文件描述符了,增加引用计数,直接共用一份就可以了。对于vfork函数和创建线程的pthread_create函数来说都是如此。但是fork函数却不同,调用fork函数时,该标志位为0,表示需要为子进程拷贝一份父进程的文件描述符。文件描述符的拷贝是通过内核的dup_fd函数来完成的。
1 | struct files_struct *dup_fd(struct files_struct *oldf, int *errorp) |
dup_fd函数首先会给子进程分配一个file_struct结构体,然后做一些赋值操作。这个结构体是进程描述符中与打开文件相关的数据结构,每一个打开的文件都会记录在该结构体中。其定义代码如下:
1 | struct files_struct { |
初看之下struct fdtable的内容与struct files_struct的内容有颇多重复之处,包括close_on_exec文件描述符位图、打开文件描述符位图及file指针数组等,但事实上并非如此。struct files_struct中的成员是相应数据结构的实例,而struct fdtable中的成员是相应的指针。
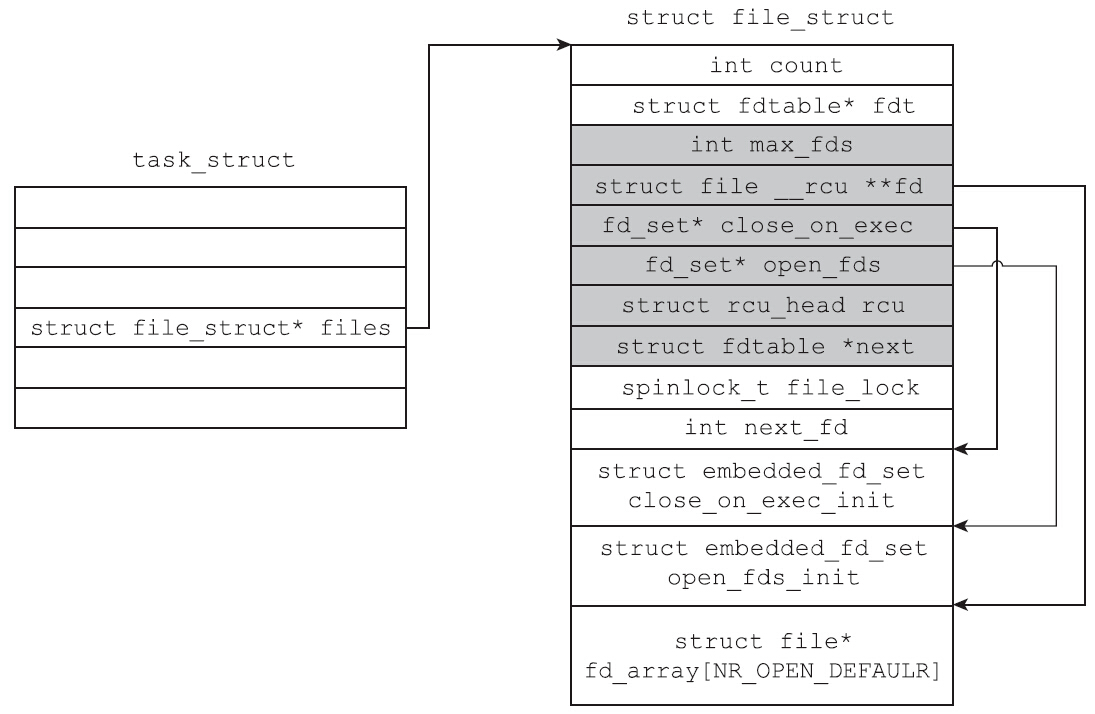
Linux系统假设大多数的进程打开的文件不会太多。于是Linux选择了一个long类型的位数(32位系统下为32位,64位系统下为64位)作为经验值。以64位系统为例,file_struct结构体自带了可以容纳64个struct file类型指针的数组fd_array,也自带了两个大小为64的位图,其中open_fds_init位图用于记录文件的打开情况,close_on_exec_init位图用于记录文件描述符的FD_CLOSEXCE标志位是否置位。只要进程打开的文件个数小于64,file_struct结构体自带的指针数组和两个位图就足以满足需要。因此在分配了file_struct结构体后,内核会初始化file_struct自带的fdtable,代码如下所示:
1 | atomic_set(&newf->count, 1); |
初始化之后,子进程的file_struct的情况如图所示。注意,此时file_struct结构体中的fdt指针并未指向file_struct自带的struct fdtable类型的fdtab变量。原因很简单,因为此时内核还没有检查父进程打开文件的个数,因此并不确定自带的结构体能否满足需要。
接下来,内核会检查父进程打开文件的个数。如果父进程打开的文件超过了64个,struct files_struct中自带的数组和位图就不能满足需要了。这种情况下内核会分配一个新的struct fdtable,代妈如下:
1 | spin_lock(&oldf->file_lock); |
alloc_fdtable所做的事情,不过是分配fdtable结构体本身,以及分配一个指针数组和两个位图。分配之前会根据父进程打开文件的数目,计算出一个合理的值nr,以确保分配的数组和位图能够满足需要。
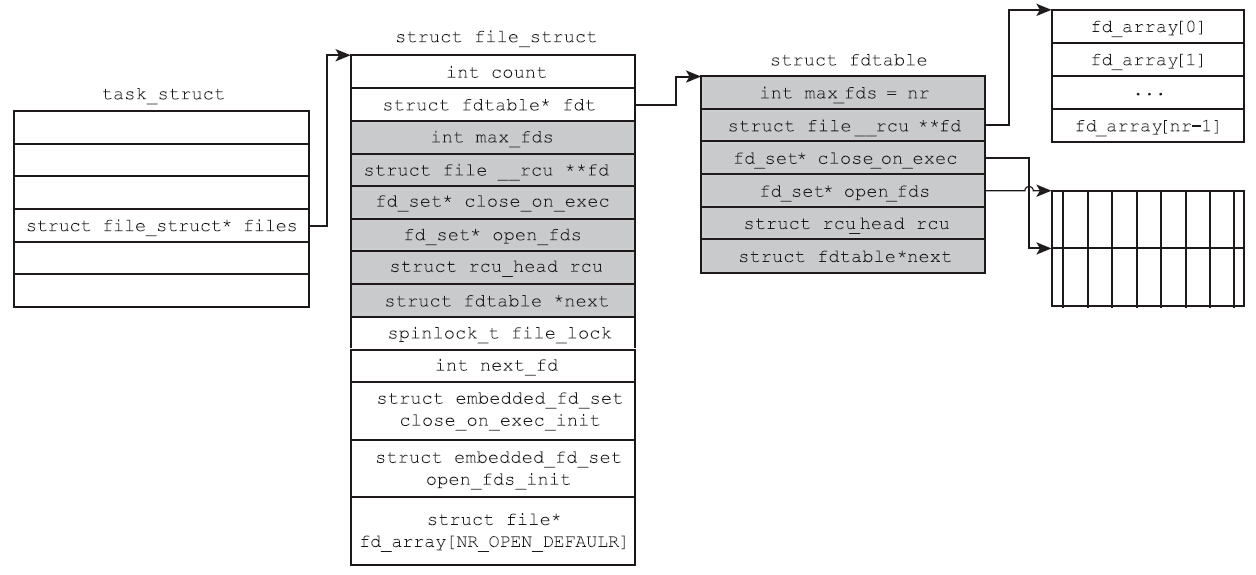
无论是使用file_struct结构体自带的fdtable,还是使用alloc_fdtable分配的fdtable,接下来要做的事情都一样,即将父进程的两个位图信息和打开文件的struct file类型指针拷贝到子进程的对应数据结构中,代码如下:
1 | old_fds = old_fdt->fd; /*父进程的struct file 指针数组*/ |
procfs的/proc/PID/status中的FDSize,记录了当前fdtable的大小:
2
FDSize: 128
当然了,FDSize记录的是目前fdtable能容纳的struct file指针,而不是已经打开的文件个数,已经打开的文件记录在/proc/PID/fd中。通过对上述流程的梳理,不难看出,父子进程之间拷贝的是struct file的指针,而不是struct file的实例,父子进程的struct file类型指针,都指向同一个struct file实例。fork之后,父子进程的文件描述符关系如图所示。
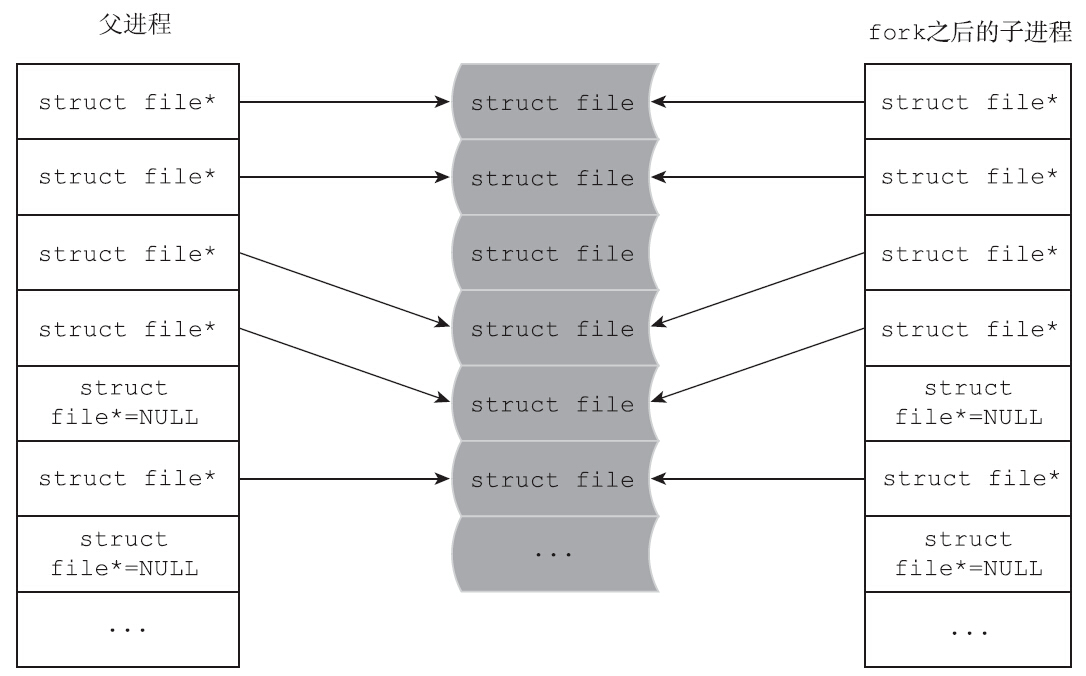
下面来看看struct file成员变量:
1 | struct file{ |
看到此处,就不难理解父子进程是如何共享文件偏移量的了,那是因为父子进程的指针都指向了同一个struct file结构体。
vfork
在早期的实现中,fork没有实现写时拷贝机制,而是直接对父进程的数据段、堆和栈进行完全拷贝,效率十分低下。很多程序在fork一个子进程后,会紧接着执行exec家族函数,这更是一种浪费。所以BSD引入了vfork。既然fork之后会执行exec函数,拷贝父进程的内存数据就变成了一种无意义的行为,所以引入的vfork压根就不会拷贝父进程的内存数据,而是直接共享。再后来Linux引入了写时拷贝的机制,其效率提高了很多,这样一来,vfork其实就可以退出历史舞台了。除了一些需要将性能优化到极致的场景,大部分情况下不需要再使用vfork函数了。
vfork会创建一个子进程,该子进程会共享父进程的内存数据,而且系统将保证子进程先于父进程获得调度。子进程也会共享父进程的地址空间,而父进程将被一直挂起,直到子进程退出或执行exec。注意,vfork之后,子进程如果返回,则不要调用return,而应该使用_exit函数。如果使用return,就会出现诡异的错误。请看下面的示例代码:
1 |
|
调用子进程,如果使用return返回,就意味着main函数返回了,因为栈是父子进程共享的,所以程序的函数栈发生了变化。main函数return之后,通常会调用exit系的函数,父进程收到子进程的exit之后,就会开始从vfork返回,但是这时整个main函数的栈都已经不复存在了,所以父进程压根无法执行。于是会返回一个诡异的栈地址,对于在某些内核版本中,进程会直接报栈错误然后退出,但是在某些内核版本中,有可能就会再次进出main,于是进入一个无限循环,直到vfork返回错误。笔者的Ubuntu版本就是后者。一般来说,vfork创建的子进程会执行exec,执行完exec后应该调用_exit返回。注意是_exit而不是exit。因为exit会导致父进程stdio缓冲区的冲刷和关闭。我们会在后面讲述exit和_exit的区别。
高版本内核修复了这个问题。
Daemon进程的创建
daemon进程又被称为守护进程,一般来说它有以下两个特点:
- 生命周期很长,一旦启动,正常情况下不会终止,一直运行到系统退出。但凡事无绝对:daemon进程其实也是可以停止的,如很多daemon提供了stop命令,执行stop命令就可以终止daemon,或者通过发送信号将其杀死,又或者因为daemon进程代码存在bug而异常退出。这些退出一般都是由手工操作或因异常引发的。
- 在后台执行,并且不与任何控制终端相关联。即使daemon进程是从终端命令行启动的,终端相关的信号如SIGINT、SIGQUIT和SIGTSTP,以及关闭终端,都不会影响到daemon进程的继续执行。
习惯上daemon进程的名字通常以d结尾,如sshd、rsyslogd等。但这仅仅是习惯,并非一定要如此。如何使一个进程变成daemon进程,或者说编写daemon进程,需要遵循哪些规则或步骤呢?一般来讲,创建一个daemon进程的步骤被概括地称为double-fork magic。细细说来,需要以下步骤:
(1)执行fork()函数,父进程退出,子进程继续执行这一步。
原因有二:
- 父进程有可能是进程组的组长(在命令行启动的情况下),从而不能够执行后面要执行的setsid函数,子进程继承了父进程的进程组ID,并且拥有自己的进程ID,一定不会是进程组的组长,所以子进程一定可以执行后面要执行的setsid函数。
- 如果daemon是从终端命令行启动的,那么父进程退出会被shell检测到,shell会显示shell提示符,让子进程在后台执行。
(2)子进程执行如下三个步骤,以摆脱与环境的关系。
修改进程的当前目录为根目录(/)。这样做是有原因的,因为daemon一直在运行,如果当前工作路径上包含有根文件系统以外的其他文件系统,那么这些文件系统将无法卸载。因此,常规是将当前工作目录切换成根目录,当然也可以是其他目录,只要确保该目录所在的文件系统不会被卸载即可。
1
chdir("/")
调用setsid函数。这个函数的目的是切断与控制终端的所有关系,并且创建一个新的会话。这一步比较关键,因为这一步确保了子进程不再归属于控制终端所关联的会话。因此无论终端是否发送SIGINT、SIGQUIT或SIGTSTP信号,也无论终端是否断开,都与要创建的daemon进程无关,不会影响到daemon进程的继续执行。
设置文件模式创建掩码为0。这一步的目的是让daemon进程创建文件的权限属性与shell脱离关系。因为默认情况下,进程的umask来源于父进程shell的umask。如果不执行umask(0),那么父进程shell的umask就会影响到daemon进程的umask。如果用户改变了shell的umask,那么也就相当于改变了daemon的umask,就会造成daemon进程每次执行的umask信息可能会不一致。
1
umask(0)
(3)再次执行fork,父进程退出,子进程继续。
执行完前面两步之后,可以说已经比较圆满了:新建会话,进程是会话的首进程,也是进程组的首进程。进程ID、进程组ID和会话ID,三者的值相同,进程和终端无关联。那么这里为何还要再执行一次fork函数呢?原因是,daemon进程有可能会打开一个终端设备,即daemon进程可能会根据需要,执行类似如下的代码:
1 | int fd = open("/dev/console", O_RDWR); |
这个打开的终端设备是否会成为daemon进程的控制终端,取决于两点:
- daemon进程是不是会话的首进程。
- 系统实现。(BSD风格的实现不会成为daemon进程的控制终端,但是POSIX标准说这由具体实现来决定)。
既然如此,为了确保万无一失,只有确保daemon进程不是会话的首进程,才能保证打开的终端设备不会自动成为控制终端。因此,不得不执行第二次fork,fork之后,父进程退出,子进程继续。这时,子进程不再是会话的首进程,也不是进程组的首进程了。
(4)关闭标准输入(stdin)、标准输出(stdout)和标准错误(stderr)。
因为文件描述符0、1和2指向的就是控制终端。daemon进程已经不再与任意控制终端相关联,因此这三者都没有意义。一般来讲,关闭了之后,会打开/dev/null,并执行dup2函数,将0、1和2重定向到/dev/null。这个重定向是有意义的,防止了后面的程序在文件描述符0、1和2上执行I/O库函数而导致报错。
至此,即完成了daemon进程的创建,进程可以开始自己真正的工作了。
上述步骤比较繁琐,对于C语言而言,glibc提供了daemon函数,从而帮我们将程序转化成daemon进程。
1 |
|
进程终止
在不考虑线程的情况下,进程的退出有以下5种方式。
正常退出有3种:
- 从main函数return返回
- 调用
exit - 调用
_exit
异常退出有两种:
- 调用abort
- 接收到信号,由信号终止
_exit
1 |
|
_exit 函数中status参数定义了进程的终止状态,父进程可以通过wait()来获取该状态值。需要注意的是返回值,虽然status是int型,但是仅有低8位可以被父进程所用。所以写_exit(-1)结束进程时,在终端执行“$?”会发现返回值是255。如果是shell相关的编程,shell可能需要获取进程的退出值,那么退出值最好不要大于128。如果退出值大于128,会给shell带来困扰。POSIX标准规定了退出状态及其含义如表4-2所示。
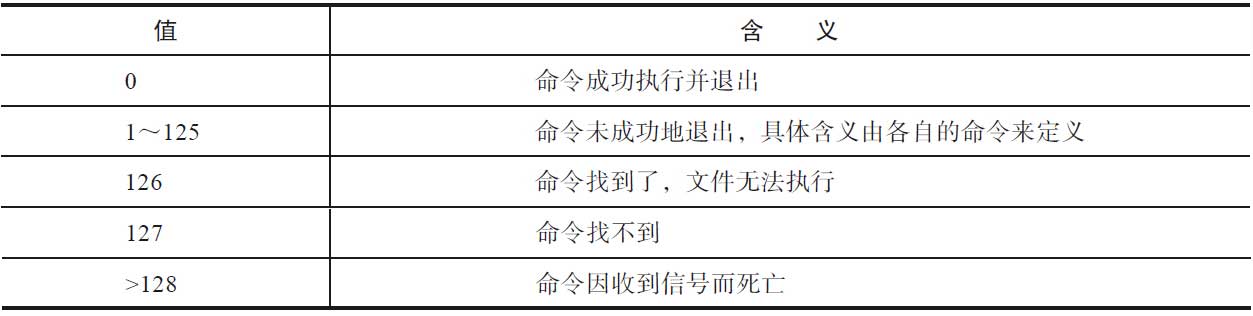
下面的命令被SIGINT信号(signo=2)中断,返回了130。如程序通过exit返回130,与其配合工作的shell就可能会误判为收到信号而退出。
1 | $ sleep 10000 |
用户调用_exit函数,本质上是调用exit_group系统调用。这点在前面已经详细介绍过,在此就不再赘述了。
exit
1 |
|
exit()函数的最后也会调用_exit()函数,但是exit在调用_exit之前,还做了其他工作:
1)执行用户通过调用atexit函数或on_exit定义的清理函数。
2)关闭所有打开的流(stream),所有缓冲的数据均被写入(flush),通过tmpfile创建的临时文件都会被删除。
3)调用_exit。
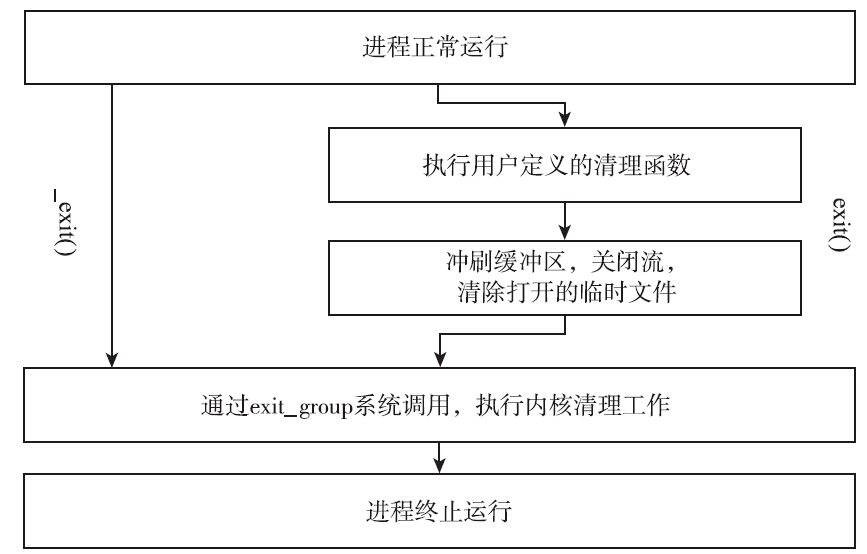
下面介绍exit函数和_exit函数的不同之处。
首先是exit函数会执行用户注册的清理函数。用户可以通过调用atexit()函数或on_exit()函数来定义清理函数。这些清理函数在调用return或调用exit时会被执行。执行顺序与函数注册的顺序相反。当进程收到致命信号而退出时,注册的清理函数不会被执行;当进程调用_exit退出时,注册的清理函数不会被执行;当执行到某个清理函数时,若收到致命信号或清理函数调用了_exit()函数,那么该清理函数不会返回,从而导致排在后面的需要执行的清理函数都会被丢弃。
其次是exit函数会冲刷(flush)标准I/O库的缓冲并关闭流。glibc提供的很多与I/O相关的函数都提供了缓冲区,用于缓存大块数据。缓冲有三种方式:无缓冲(_IONBF)、行缓冲(_IOLBF)和全缓冲(_IOFBF)。
- 无缓冲:就是没有缓冲区,每次调用stdio库函数都会立刻调用
read/write系统调用。 - 行缓冲:对于输出流,收到换行符之前,一律缓冲数据,除非缓冲区满了。对于输入流,每次读取一行数据。
- 全缓冲:就是缓冲区满之前,不会调用
read/write系统调用来进行读写操作。
对于后两种缓冲,可能会出现这种情况:进程退出时,缓冲区里面可能还有未冲刷的数据。如果不冲刷缓冲区,缓冲区的数据就会丢失。比如行缓冲迟迟没有等到换行符,又或者全缓冲没有等到缓冲区满。尤其是后者,很容易出现,因为glibc的缓冲区默认是8192字节。exit函数在关闭流之前,会冲刷缓冲区的数据,确保缓冲区里的数据不会丢失。
1 |
|
注意上面的示例代码,fprintf打印的字符串是没有换行符的,对于标准输出流stdout,采用的是行缓冲,收到换行符之前是不会有输出的。输出情况如下:
1 | manu@manu-hacks:exit$ ./test exit |
尽管缓冲区里的数据没有等到换行符,但是无论是调用return返回还是调用exit返回,缓冲区里的数据都会被冲刷,“Oops...forgot a newline!”都会被输出。因为exit()函数会负责此事。从测试代码的输出也可以看出,exit()函数首先执行的是用户注册的清理函数,然后才执行了缓冲区的冲刷。第三,存在临时文件,exit函数会负责将临时文件删除,这点在第3章中已经介绍过,此处就不再赘述了。exit函数的最后调用了_exit()函数,最终殊途同归,走向内核清理。
return
return是一种更常见的终止进程的方法。执行return(n)等同于执行exit(n),因为调用main()的运行时函数会将main的返回值当作exit的参数。
等待子进程
僵尸进程
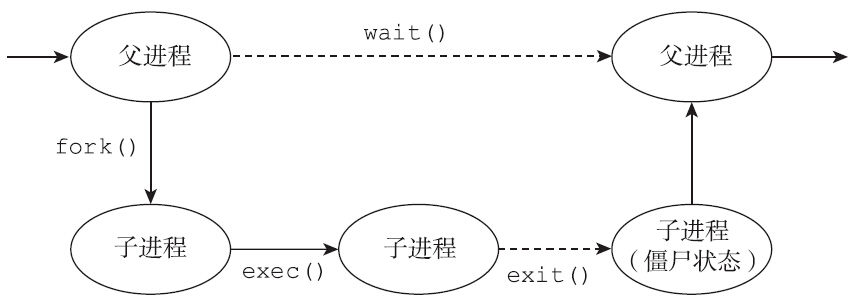
进程就像一个生命体,通过fork()函数,子进程呱呱坠地。有的子进程子承父业,继续执行与父进程一样的程序(相同的代码段,尽管可能是不同的程序分支),有的子进程则比较叛逆,通过exec离家出走,走向与父进程完全不同的道路。
令人悲伤的是,如同所有的生命体一样,进程也会消亡。进程退出时会进行内核清理,基本就是释放进程所有的资源,这些资源包括内存资源、文件资源、信号量资源、共享内存资源,或者引用计数减一,或者彻底释放。不过,进程的退出其实并没有将所有的资源完全释放,仍保留了少量的资源,比如进程的PID依然被占用着,不可被系统分配。此时的进程不可运行,事实上也没有地址空间让其运行,进程进入僵尸状态。
为什么进程退出之后不将所有的资源释放,从此灰飞烟灭,一了百了,反而非要保留少量资源,进入僵尸状态呢?看看僵尸进程依然占有的系统资源,我们就能获得答案。僵尸进程依然保留的资源有进程控制块task_struct、内核栈等。这些资源不释放是为了提供一些重要的信息,比如进程为何退出,是收到信号退出还是正常退出,进程退出码是多少,进程一共消耗了多少系统CPU时间,多少用户CPU时间,收到了多少信号,发生了多少次上下文切换,最大内存驻留集是多少,产生多少缺页中断?等等。这些信息,就像墓志铭,总结了进程的一生。如果没有这个僵尸状态,进程的这些信息也会随之流逝,系统也将再也没有机会获知该进程的相关信息了。因此进程退出后,会保留少量的资源,等待父进程前来收集这些信息。一旦父进程收集了这些信息之后(通过调用下面提到的wait/waitpid等函数),这些残存的资源完成了它的使命,就可以释放了,进程就脱离僵尸状态,彻底消失了。
从上面的讨论可以看出,制造一个僵尸进程是一件很容易的事情,只要父进程调用fork创建子进程,子进程退出后,父进程如果不调用wait或waitpid来获取子进程的退出信息,子进程就会沦为僵尸进程。示例代码如下:
1 |
|
上面的例子中父进程休眠300秒后才会调用wait来获取子进程的退出信息。而子进程退出之后会变成僵尸状态,苦苦等待父进程来获取退出信息。在这300秒左右的时间里,子进程就是一个僵尸进程。
如何查看一个进程是否处于僵尸状态呢?ps命令输出的进程状态Z,就表示进程处于僵尸状态,另外procfs提供的status信息中的State给出的值是Z(zombie),也表明进程处于僵尸状态。
1 | ps ax |
进程一旦进入僵尸状态,就进入了一种刀枪不入的状态,“杀人不眨眼”的kill-9也无能为力,因为谁也没有办法杀死一个已经死去的进程。
清除僵尸进程有以下两种方法:
- 父进程调用wait函数,为子进程“收尸”。
- 父进程退出,init进程会为子进程“收尸”。
一般而言,系统不希望大量进程长期处于僵尸状态,因为会浪费系统资源。除了少量的内存资源外,比较重要的是进程ID。僵尸进程并没有将自己的进程ID归还给系统,而是依然占有这个进程ID,因此系统不能将该ID分配给其他进程。
对于编程来说,如何防范僵尸进程的产生呢?答案是具体情况具体分析。如果我们不关心子进程的退出状态,就应该将父进程对SIGCHLD的处理函数设置为SIG_IGN,或者在调用sigaction函数时设置SA_NOCLDWAIT标志位。这两者都会明确告诉子进程,父进程很“绝情”,不会为子进程“收尸”。子进程退出的时候,内核会检查父进程的SIGCHLD信号处理结构体是否设置了SA_NOCLDWAIT标志位,或者是否将信号处理函数显式地设为SIG_IGN。如果是,则autoreap为true,子进程发现autoreap为true也就“死心”了,不会进入僵尸状态,而是调用release_task函数“自行了断”了。如果父进程关心子进程的退出信息,则应该在流程上妥善设计,能够及时地调用wait,使子进程处于僵尸状态的时间不会太久。对于创建了很多子进程的应用来说,知道子进程的返回值是有意义的。比如说父进程维护一个进程池,通过进程池里的子进程来提供服务。当子进程退出的时候,父进程需要了解子进程的返回值来确定子进程的“死因”,从而采取更有针对性的措施。
wait
1 | include <sys/wait.h> |
成功时,返回已退出子进程的进程ID;失败时,则返回-1并设置errno,常见的errno及说明见表:

注意父子进程是两个进程,子进程退出和父进程调用wait()函数来获取子进程的退出状态在时间上是独立的事件,因此会出现以下两种情况:
子进程先退出,父进程后调用wait()函数。
对于这种情况,子进程几乎已经销毁了自己所有的资源,只留下少量的信息,苦苦等待父进程来“收尸”。当父进程调用wait()函数的时候,苦守寒窑十八载的子进程终于等到了父进程来“收尸”,这种情况下,父进程获取到子进程的状态信息,wait函数立刻返回。
父进程先调用wait()函数,子进程后退出。
对于第二种情况,父进程先调用wait()函数,调用时并无子进程退出,该函数调用就会陷入阻塞状态,直到某个子进程退出。
wait()函数等待的是任意一个子进程,任何一个子进程退出,都可以让其返回。当多个子进程都处于僵尸状态,wait()函数获取到其中一个子进程的信息后立刻返回。由于wait()函数不会接受pid_t类型的入参,所以它无法明确地等待特定的子进程。
一个进程如何等待所有的子进程退出呢?wait()函数返回有三种可能性:
- 等到了子进程退出,获取其退出信息,返回子进程的进程ID。
- 等待过程中,收到了信号,信号打断了系统调用,并且注册信号处理函数时并没有设置SA_RESTART标志位,系统调用不会被重启,wait()函数返回-1,并且将errno设置为EINTR。
- 已经成功地等待了所有子进程,没有子进程的退出信息需要接收,在这种情况下,wait()函数返回-1,errno为ECHILD。
《Linux/Unix系统编程手册》给出下面的代码来等待所有子进程的退出:
2
3
4
continue;
if(errno !=ECHILD)
errExit("wait");这种方法并不完全,因为这里忽略了wait()函数被信号中断这种情况,如果wait()函数被信号中断,上面的代码并不能成功地等待所有子进程退出。若将上面的wait()函数封装一下,使其在信号中断后,自动重启wait就完备了。代码如下:
2
3
4
5
6
7
8
9
10
11
12
{
int retval;
while(((retval = wait(stat_loc)) == -1 && (errno == EINTR));
return retval;
}
while((childPid = r_wait(NULL)) != -1)
continue;
If(errno != ECHILD)
{
/*some error happened*/
}
如果父进程调用wait()函数时,已经有多个子进程退出且都处于僵尸状态,那么哪一个子进程会被先处理是不一定的(标准并未规定处理的顺序)。
通过上面的讨论,可以看出wait()函数存在一定的局限性:
- 不能等待特定的子进程。如果进程存在多个子进程,而它只想获取某个子进程的退出状态,并不关心其他子进程的退出状态,此时wait()只能一一等待,通过查看返回值来判断是否为关心的子进程。
- 如果不存在子进程退出,wait()只能阻塞。有些时候,仅仅是想尝试获取退出子进程的退出状态,如果不存在子进程退出就立刻返回,不需要阻塞等待,类似于trywait的概念。wait()函数没有提供trywait的接口。
- wait()函数只能发现子进程的终止事件,如果子进程因某信号而停止,或者停止的子进程收到SIGCONT信号又恢复执行,这些事件wait()函数是无法获知的。换言之,wait()能够探知子进程的死亡,却不能探知子进程的昏迷(暂停),也无法探知子进程从昏迷中苏醒(恢复执行)。由于上述三个缺点的存在,所以Linux又引入了waitpid()函数。
waitpid
1 |
|
先说说waitpid()与wait()函数相同的地方:
- 返回值的含义相同,都是终止子进程或因信号停止或因信号恢复而执行的子进程的进程ID。
- status的含义相同,都是用来记录子进程的相关事件,后面一节将会详细介绍。
接下来介绍waitpid()函数特有的功能。其第一个参数是pid_t类型,有了此值,不难看出waitpid函数肯定具备了精确打击的能力。waitpid函数可以明确指定要等待哪一个子进程的退出(以及停止和恢复执行)。事实上,扩展的功能不仅仅如此:
- pid>0:表示等待进程ID为pid的子进程,也就是上文提到的精确打击的对象。
- pid=0:表示等待与调用进程同一个进程组的任意子进程;因为子进程可以设置自己的进程组,所以某些子进程不一定和父进程归属于同一个进程组,这样的子进程,waitpid函数就毫不关心了。
- pid=-1:表示等待任意子进程,同wait类似。waitpid(-1,&status,0)与wait(&status)完全等价。
- pid<-1:等待所有子进程中,进程组ID与pid绝对值相等的所有子进程。
内核之中,wait函数和waitpid函数调用的都是wait4系统调用。下面是wait4系统调用的实现。函数的中间部分,根据pid的正负或是否为0和-1来定义wait_opts类型的变量wo,后面会根据wo来控制到底关心哪些进程的事件。
1 | SYSCALL_DEFINE4(wait4, pid_t, upid, int __user *, stat_addr, int options, struct rusage __user *, ru) |
可以看到,内核的do_wait函数会根据wait_opts类型的wo变量来控制到底在等待哪些子进程的状态。当前进程中的每一个线程(在内核层面,线程就是进程,每个线程都有独立的task_struct),都会遍历其子进程。在内核中,task_struct中的children成员变量是个链表头,该进程的所有子进程都会链入该链表,遍历起来比较方便。代码如下:
1 | static int do_wait_thread(struct wait_opts *wo, struct task_struct *tsk) |
但是我们并不一定关心所有的子进程。当wait()函数或waitpid()函数的第一个参数pid等于-1的时候,表示任意子进程我们都关心。但是如果是waitpid()函数的其他情况,则表示我们只关心其中的某些子进程或某个子进程。内核需要对所有的子进程进行过滤,找到关心的子进程。这个过滤的环节是在内核的eligible_pid函数中完成的。
1 | /* 当waitpid的第一个参数为-1时,wo->wo_type 赋值为PIDTYPE_MAX |
waitpid函数的第三个参数options是一个位掩码(bit mask),可以同时存在多个标志。当options没有设置任何标志位时,其行为与wait类似,即阻塞等待与pid匹配的子进程退出。options的标志位可以是如下标志位的组合:
- WUNTRACE:除了关心终止子进程的信息,也关心那些因信号而停止的子进程信息。
- WCONTINUED:除了关心终止子进程的信息,也关心那些因收到信号而恢复执行的子进程的状态信息。
- WNOHANG:指定的子进程并未发生状态变化,立刻返回,不会阻塞。这种情况下返回值是0。如果调用进程并没有与pid匹配的子进程,则返回-1,并设置errno为ECHILD,根据返回值和errno可以区分这两种情况。
传统的wait函数只关注子进程的终止,而waitpid函数则可以通过前两个标志位来检测子进程的停止和从停止中恢复这两个事件。讲到这里,需要解释一下什么是“使进程停止”,什么是“使进程继续”,以及为什么需要这些。设想如下的场景,正在某机器上编译一个大型项目,编译过程需要消耗很多CPU资源和磁盘I/O资源,并且耗时很久。如果我暂时需要用机器做其他事情,虽然可能只需要占用几分钟时间。但这会使这几分钟内的用户体验非常糟糕,那怎么办?当然,杀掉编译进程是一个选择,但是这个方案并不好。因为编译耗时很久,贸然杀死进程,你将不得不从头编译起。这时候,我们需要的仅仅是让编译大型工程的进程停下来,把CPU资源和I/O资源让给我,让我从容地做自己想做的事情,几分钟后,我用完了,让编译的进程继续工作就行了。
Linux提供了SIGSTOP(信号值19)和SIGCONT(信号值18)两个信号,来完成暂停和恢复的动作,可以通过执行kill-SIGSTOP或kill-19来暂停一个进程的执行,通过执行kill-SIGCONT或kill-18来让一个暂停的进程恢复执行。waitpid()函数可以通过WUNTRACE标志位关注停止的事件,如果有子进程收到信号处于暂停状态,waitpid就可以返回。同样的道理,通过WCONTINUED标志位可以关注恢复执行的事件,如果有子进程收到SIGCONT信号而恢复执行,waitpid就可以返回。但是上述两个事件和子进程的终止事件是并列的关系,waitpid成功返回的时候,可能是等到了子进程的终止事件,也可能是等到了暂停或恢复执行的事件。这需要通过status的值来区分。那么,现在应该分析status的值了。
等待状态值
无论是wait()函数还是waitpid()函数,都有一个status变量。这个变量是一个int型指针。可以传递NULL,表示不关心子进程的状态信息。如果不为空,则根据填充的status值,可以获取到子进程的很多信息,如图所示。
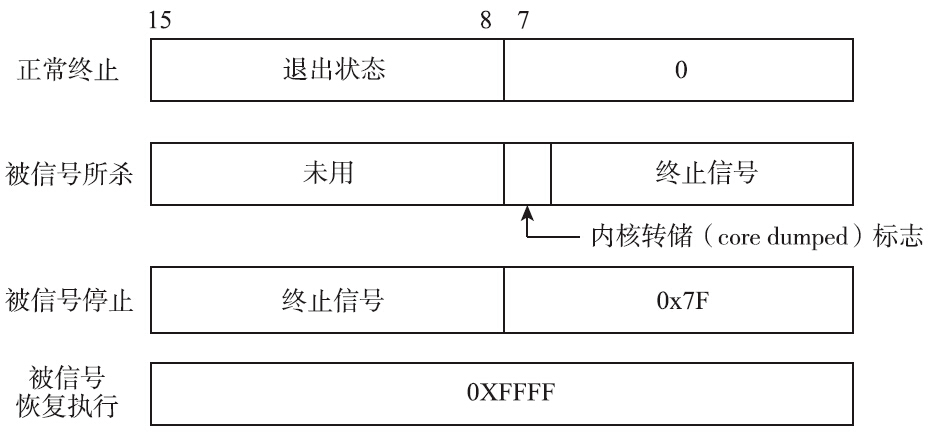
上图可知,直接根据status值可以获得进程的退出方式,但是为了保证可移植性,不应该直接解析status值来获取退出状态。因此系统提供了相应的宏(macro),用来解析返回值。下面分别介绍各种情况。
- 进程是正常退出的

所谓截取退出状态8~15位的值,也就是exit_group系统调用用户传入的int型的值。当然只有最低的8位:
1 |
- 进程收到信号,导致退出

- 进程收到信号,被停止

- 子进程恢复执行
有一个宏与这种情况相关。

为何没有返回使子进程恢复的信号值的宏?原因是只有SIGCONT信号能够使子进程从停止状态中恢复过来。如果子进程恢复执行,只可能是收到了SIGCONT信号,所以不需要宏来取信号的值。下面给出了判断子进程终止的示例代码。等待子进程暂停或恢复执行的情况,可以根据下面的示例代码自行实现。
1 | void print_wait_exit(int status) |
尽管waitpid函数对wait函数做了很多的扩展,但waitpid函数还是存在不足之处:waitpid固然通过WUNTRACE和WCONTINUED标志位,增加了对子进程停止事件和子进程恢复执行事件的支持,但是这种支持并不完美,这两种事件都和子进程的终止事件混在一起了。wait和waitpid函数都会调用wait4系统调用,无论用户传递的参数为何,总会添上WEXITED事件,如下所示:
1 | wo.wo_flags = options | WEXITED; |
如果用户不关心子进程的终止事件,只关心子进程的停止事件,能否使用waitpid()明确做到?答案是不行。当waitpid返回时,可能是因为子进程终止,也可能是因为子进程停止。这是waitpid和wait的致命缺陷。为了解决这个缺陷,wait家族的最重要成员,waitid()函数就要闪亮登场了。
waitid
前面提到过,waitpid函数是wait函数的超集,wait函数能干的事情,waitpid函数都能做到。但是waitpid函数的控制还是不太精确,无论用户是否关心相关子进程的终止事件,终止事件都可能会返回给用户。因此Linux提供了waitid系统调用。glibc封装了waitid系统调用从而实现了waitid函数。尽管目前普遍使用的是wait和waitpid两个函数,但是waitid函数的设计显然更加合理。
1 |
|
进程退出和等待的内核实现
Linux引入多线程之后,为了支持进程的所有线程能够整体退出,内核引入了exit_group系统调用。对于进程而言,无论是调用exit()函数、_exit()函数还是在main函数中return,最终都会调用exit_group系统调用。
对于单线程的进程,从do_exit_group直接调用do_exit就退出了。但是对于多线程的进程,如果某一个线程调用了exit_group系统调用,那么该线程在调用do_exit之前,会通过zap_other_threads函数,给每一个兄弟线程挂上一个SIGKILL信号。内核在尝试递送信号给兄弟进程时(通过get_signal_to_deliver函数),会在挂起信号中发现SIGKILL信号。内核会直接调用do_group_exit函数让该线程也退出(如图4-13所示)。这个过程在第3章中已经详细分析过了。
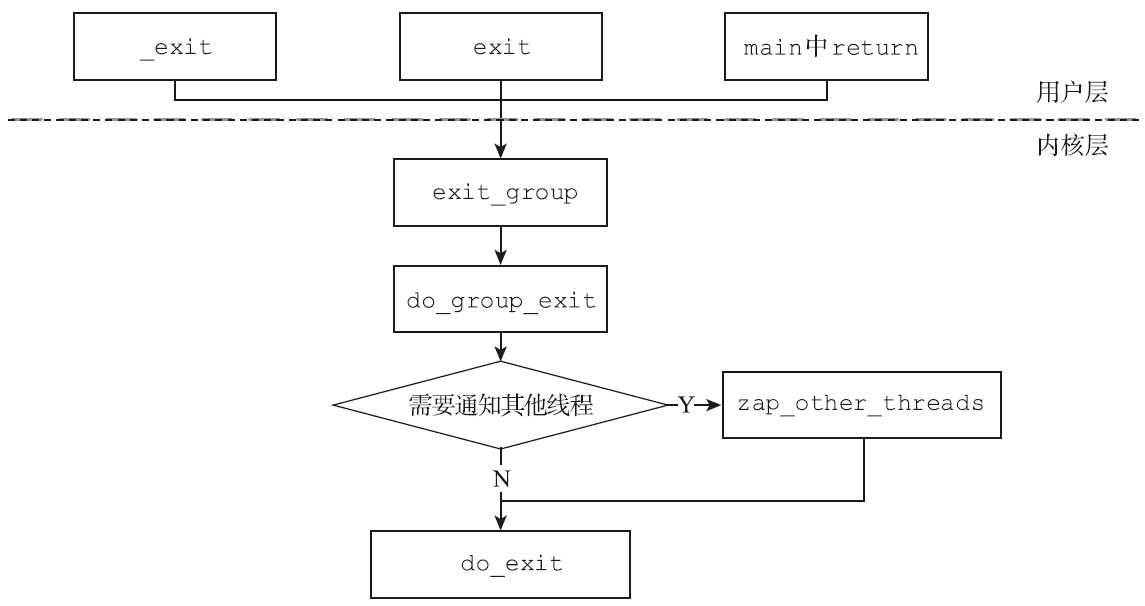
在do_exit函数中,进程会释放几乎所有的资源(文件、共享内存、信号量等)。该进程并不甘心,因为它还有两桩心愿未了:
- 作为父进程,它可能还有子进程,进程退出以后,将来谁为它的子进程“收尸”。
- 作为子进程,它需要通知它的父进程来为自己“收尸”。
这两件事情是由exit_notify来负责完成的,具体来说forget_original_parent函数和do_notify_parent函数各自负责一件事,如表所示。

forget_original_parent(),多么“悲伤”的函数名。顾名思义,该函数用来给自己的子进程安排新的父进程。给自己的子进程安排新的父进程,细分下来,是两件事情:
1)为子进程寻找新的父进程。
2)将子进程的父进程设置为第1)步中找到的新的父亲。
为子进程寻找父进程,是由find_new_reaper()函数完成的。如果退出的进程是多线程进程,则可以将子进程托付给自己的兄弟线程。如果没有这样的线程,就“托孤”给init进程。
为自己的子进程找到新的父亲之后,内核会遍历退出进程的所有子进程,将新的父亲设置为子进程的父亲。
1 | static void forget_original_parent(struct task_struct *father) |
这部分代码比较容易引起困扰的是下面这行,我们都知道,子进程“死”的时候,会向父进程发送信号SIGCHLD,Linux也提供了一种机制,允许父进程“死”的时候向子进程发送信号。
1 | if (t->pdeath_signal) |
读者可以通过man prctl,查看PR_SET_PDEATHSIG标志位部分。如果应用程序通过prctl函数设置了父进程“死”时要向子进程发送信号,就会执行到这部分内核代码,以通知其子进程。
接下来是第二桩未了的心愿:想办法通知父进程为自己“收尸”。对于单线程的程序来说完成这桩心愿比较简单,但是多线程的情况就复杂些。只有线程组的主线程才有资格通知父进程,线程组的其他线程终止的时候,不需要通知父进程,也没必要保留最后的资源并陷入僵尸态,直接调用release_task函数释放所有资源就好。为什么要这样设计?细细想来,这么做是合理的。父进程创建子进程时,只有子进程的主线程是父进程亲自创建出来的,是父进程的亲生儿子,父进程也只关心它,至于子进程调用pthread_create产生的其他线程,父进程压根就不关心。
由于父进程只认子进程的主线程,所以在线程组中,主线程一定要挺住。在用户层面,可以调用pthread_exit让主线程先“死”,但是在内核态中,主线程的task_struct一定要挺住,哪怕变成僵尸,也不能释放资源。生命在于“折腾”,如果主线程率先退出了,而其他线程还在正常工作,内核又将如何处理?
1 | else if (thread_group_leader(tsk)) { |
上面的代码给出了答案,如果退出的进程是线程组的主线程,但是线程组中还有其他线程尚未终止(thread_group_empty函数返回false),那么autoreaper就等于false,也就不会调用do_notify_parent向父进程发送信号了。因为子进程的线程组中有其他线程还活着,因此子进程的主线程退出时不能通知父进程,错过了调用do_notify_parent的机会,那么父进程如何才能知晓子进程已经退出了呢?答案会在最后一个线程退出时揭晓。此答案就藏在内核的release_task函数中:
1 | leader = p->group_leader; |
当线程组的最后一个线程退出时,如果发现:
- 该线程不是线程组的主线程。
- 线程组的主线程已经退出,且处于僵尸状态。
- 自己是最后一个线程。
同时满足这三个条件的时候,该子进程就需要冒充线程组的组长,即以子进程的主线程的身份来通知父进程。
上面讨论了一种比较少见又比较折腾的场景,正常的多线程编程应该不会如此安排。对于多线程的进程,一般情况下会等所有其他线程退出后,主线程才退出。这时,主线程会在exit_notify函数中发现自己是组长,线程组里所有成员均已退出,然后它调用do_notify_parent函数来通知父进程。无论怎样,子进程都走到了do_notify_parent函数这一步。该函数是完成父子进程之间互动的主要函数。
1 | bool do_notify_parent(struct task_struct *tsk, int sig) |
父子进程之间的互动有两种方式:
子进程向父进程发送信号SIGCHLD。
父进程可能并不知道子进程是何时退出的,如果调用wait函数等待子进程退出,又会导致父进程陷入阻塞,无法执行其他任务。那有没有一种办法,让子进程退出的时候,异步通知到父进程呢?答案是肯定的。当子进程退出时,会向父进程发送SIGCHLD信号。父进程收到该信号,默认行为是置之不理。在这种情况下,子进程就会陷入僵尸状态,而这又会浪费系统资源,该状态会维持到父进程退出,子进程被init进程接管,init进程会等待僵尸进程,使僵尸进程释放资源。如果父进程不太关心子进程的退出事件,听之任之可不是好办法,可以采取以下办法:
父进程调用signal函数或sigaction函数,将SIGCHLD信号的处理函数设置为SIG_IGN。
父进程调用sigaction函数,设置标志位时置上SA_NOCLDWAIT位(如果不关心子进程的暂停和恢复执行,则置上SA_NOCLDSTOP位)。
从内核代码来看,如果父进程的SIGCHLD的信号处理函数为SIG_IGN或sa_flags中被置上了SA_NOCLDWAIT位,子进程运行到此处时就知道了,父进程并不关心自己的退出信息,do_notify_parent函数就会返回true。在外层的exit_notify函数发现返回值是true,就会调用release_task函数,释放残余的资源,自行了断,子进程也就不会进入僵尸状态了。如果父进程关心子进程的退出,情况就不同了。父进程除了调用wait函数之外,还有了另外的选择,即注册SIGCHLD信号处理函数,在信号处理函数中处理子进程的退出事件。
为SIGCHLD写信号处理函数并不简单,原因是SIGCHLD是传统的不可靠信号。信号处理函数执行期间,会将引发调用的信号暂时阻塞(除非显式地指定了SA_NODEFER标志位),在这期间收到的SIGCHLD之类的传统信号,都不会排队。因此,如果在处理SIGCHLD信号时,有多个子进程退出,产生了多个SIGCHLD信号,但父进程只能收到一个。如果在信号处理函数中,只调用一次wait或waitpid,则会造成某些僵尸进程成为漏网之鱼。
正确的写法是,信号处理函数内,带着NOHANG标志位循环调用waitpid。如果返回值大于0,则表示不断等待子进程退出,返回0则表示,当前没有僵尸子进程,返回-1则表示出错,最大的可能就是errno等于ECHLD,表示所有子进程都已退出。
1 | while(waitpid(-1,&status,WNOHANG) > 0) |
信号处理函数中的waitpid可能会失败,从而改变全局的errno的值,当主程序检查errno时,就有可能发生冲突,所以进入信号处理函数前要现保存errno到本地变量,信号处理函数退出前,再恢复errno。
子进程唤醒父进程
上一种方法可以称之为信号通知。另一种情况是父进程调用wait主动等待。如果父进程调用wait陷入阻塞,那么子进程退出时,又该如何及时唤醒父进程呢?前面提到了,子进程会调用__wake_up_parent函数,来及时唤醒父进程。事实上,前提条件是父进程确实在等待子进程的退出。如果父进程并没有调用wait系列函数等待子进程的退出,那么,等待队列为空,子进程的__wake_up_parent对父进程并无任何影响。
1 | void __wake_up_parent(struct task_struct *p, struct task_struct *parent) |
父进程的进程描述符的signal结构体中有wait_childexit变量,这个变量是等待队列头。父进程调用wait系列函数时,会创建一个wait_opts结构体,并把该结构体挂入等待队列中。
1 | static long do_wait(struct wait_opts *wo) |
父进程先把自己设置成TASK_INTERRUPTIBLE状态,然后开始寻找满足等待条件的子进程。如果找到了,则将自己重置成TASK_RUNNING状态,欢乐返回;如果没找到,就要根据WNOHANG标志位来决定等不等待子进程。如果没有WNOHANG标志位,那么,父进程就会让出CPU资源,等待别人将它唤醒。回到另一头,子进程退出的时候,会调用__wake_up_parent,唤醒父进程,父进程醒来以后,回到repeat,再次扫描。这样做,子进程的退出就能及时通知到父进程,从而使父进程的wait系列函数可以及时返回。
exec 族
整个exec家族有6个函数,这些函数都是构建在execve系统调用之上的。该系统调用的作用是,将新程序加载到进程的地址空间,丢弃旧有的程序,进程的栈、数据段、堆栈等会被新程序替换。
execve
1 |
|
一般来说,execve()函数总是紧随fork函数之后。父进程调用fork之后,子进程执行execve函数,抛弃父进程的程序段,和父进程分道扬镳,从此天各一方,各走各路。但是也可以不执行fork,单独调用execve函数:
1 |
|
我们可以看到,代码段最后的Never get here没有被打印出来,这是因为execve函数的返回是特殊的。如果失败,则会返回-1,但是如果成功,则永不返回,这是可以理解的。execve做的就是斩断过去,奔向新生活的事情,如果成功,自然不可能再返回来,再次执行老程序的代码。所以无须检查execve的返回值,只要返回,就必然是-1。可以从errno判断出出错的原因。出错的可能性非常多,手册提供了19种不同的errno,罗列了22种失败的情景。很难记住,好在大部分都不常见,常见的情况有以下几种:
- EACCESS:这个是我们最容易想到的,就是第一个参数filename,不是个普通文件,或者该文件没有赋予可执行的权限,或者目录结构中某一级目录不可搜索,或者文件所在的文件系统是以MS_NOEXEC标志挂载的。
- ENOENT:文件不存在。
- ETXTBSY:存在其他进程尝试修改filename所指代的文件。
- ENOEXEC:这个错误其实是比较高端的一种错误了,文件存在,也可以执行,但是无法执行,比如说,Windows下的可执行程序,拿到Linux下,调用execve来执行,文件的格式不对,就会返回这种错误。
上面提到的ENOEXEC错误码,其实已经触及了execve函数的核心,即哪些文件是可以执行的,execve系统调用又是如何执行的呢?这些会在execve系统调用的内核系统调用中详细介绍。
从内核的角度来说,提供execve系统调用就足够了,但是从应用层编程的角度来讲,execve函数就并不那么好使了:
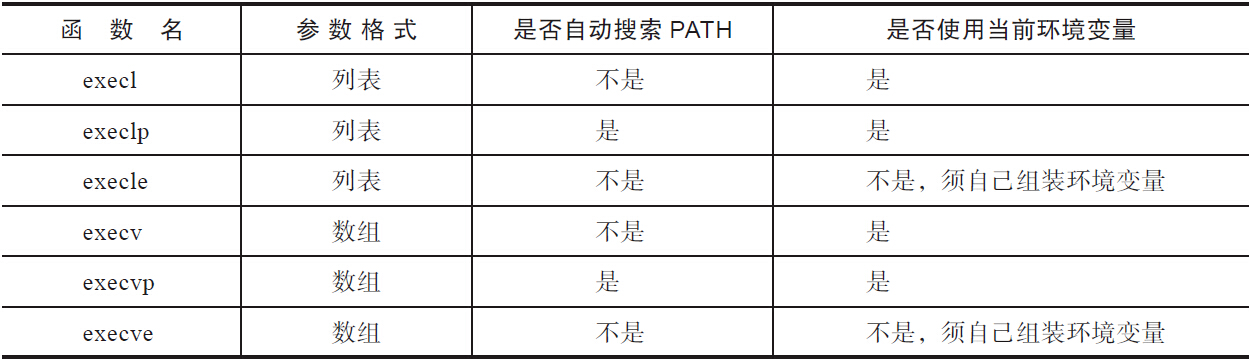
- 第一个参数必须是绝对路径或是相对于当前工作目录的相对路径。习惯在shell下工作的用户会觉得不太方便,因为日常工作都是写ls和mkdir之类命令的,没有人会写/bin/ls或/bin/mkdir。shell提供了环境变量PATH,即可执行程序的查找路径,对于位于查找路径里的可执行程序,我们不必写出完整的路径,很方便,而execve函数享受不到这个福利,因此使用不便。
- execve函数的第三个参数是环境变量指针数组,用户使用execve编程时不得不自己负责环境变量,书写大量的“key=value”,但大部分情况下并不需要定制环境变量,只需要使用当前的环境变量即可。正是为了提供相应的便利,所以用户层提供了6个函数,当然,这些函数本质上都是调用execve系统调用,只是使用的方法略有不同,代码如下:
1 |
|
上述6个函数分成上下两个半区。分类的依据是参数采用列表(l,表示list)还是数组(v,表示vector)。上半区采用列表,它们会罗列所有的参数,下半区采用数组。在每个半区之中,带p的表示可以使用环境变量PATH,带e的表示必须要自己维护环境变量,而不使用当前环境变量。
execve 系统调用的内核实现
前面提到的ENOEXEC错误表示内核不知道如何执行对应的可执行文件。Linux支持很多种可执行文件的格式,有渐渐退出历史舞台的a.out格式,有比较通用的ELF格式的文件,还有shell脚本文件、python脚本、java文件、php文件等。对于这些形形色色的可执行文件,内核该如何正确地执行呢?直接将Windows平台上的可执行文件拷贝到Linux下,Linux为什么不能执行(假设没有wine这个执行Windows程序的工具)?这是本节需要解决问题。要解决上述问题,首先还是需要深入内核。
execve是平台相关的系统调用,刨去我们不太关心的平台差异,内核都会走到do_execve_common函数这一步。
1 | static int do_execve_common(const char *filename, |
其中,linux_binprm是重要的结构体,它与稍后提到的linux_binfmt联手,支持了Linux下多种可执行文件的格式。首先,内核会将程序运行需要的参数argv和环境变量搜集到linux_binprm结构体中,比较关键的一步是:
1 | retval = prepare_binprm(bprm); |
在prepare_binprm函数中读取可执行文件的头128个字节,存放在linux_binprm结构体的buf[BINPRM_BUF_SIZE]中。我们知道日常写shell脚本、python脚本的时候,总是会在第一行写下如下语句:
1 |
|
开头的#!被称为shebang,又被称为sha-bang、hashbang等,指的就是脚本中开始的字符。在类Unix操作系统中,运行这种程序,需要相应的解释器。使用哪种解释器,取决于shebang后面的路径。#!后面跟随的一般是解释器的绝对路径,或者是相对于当前工作目录的相对路径。格式如下所示:
1 | #!interpreter [optional-arg] |
解释器是绝对路径或是相对于当前工作目录的相对路径,这就给脚本的可移植性带来了挑战。以python的解释器为例,python可能位于/usr/bin/python,也可能位于/usr/local/bin/python,甚至有的还位于/home/username/bin/python。这样编写的脚本在新的环境里面运行时,用户就不得不修改脚本了,当大量的脚本移植到新环境中运行时,修改量是巨大的。为了解决这个问题,系统又引入了如下格式:
1 |
|
如果执行方式是./python_script的方式,就会优先查找/home/manu/bin/python,/usr/local/bin/python次之……如下所示:
1 | execve("/home/manu/bin/python", ["python", "./hello.py"], [/* 25 vars */]) = -1 ENOENT (No such file or directory) |
上面提到的是脚本文件,除此以外,还有其他格式的文件。Linux平台上最主要的可执行文件格式是ELF格式,当然还有出现较早,逐渐退出历史舞台的的a.out格式,这些文件的特点是最初的128字节中都包含了可执行文件的属性的重要信息。
1 | manu@manu-hacks:~$ file hello |
prepare_binprm函数将文件开始的128字节存入linux_binprm,是为了让后面的程序根据文件开头的magic number选择正确的处理方式。做完准备工作后,开始执行,核心代码位于search_binary_handler()函数中。内核之中存在一个全局链表,名叫formats,挂到此链表的数据结构为struct linux_binfmt:
1 | struct linux_binfmt { |
操作系统启动的时候,每个编译进内核的可执行文件的“代理人”都会调用register_binfmt函数来注册,把自己挂到formats链表中。每个成员代表一种可执行文件的代理人,前面提到过,会将可执行文件的头128字节存放到linux_binprm的buf中,同时会将运行时的参数和环境变量也存放到linux_binprm的相关结构中。formats链表中的成员依次前来认领,如果是自己代表的可执行文件的格式,后面执行的事情,就委托给了该“代理人”。如果遍历了链表,所有的linux_binfmt都表示不认识该可执行文件,那又当如何呢?这种情况要根据头部的信息,查看是否有为该格式设计的,作为可动态安装的模块实现的“代理人”存在。如果有的话,就把该模块安装进来,挂入全局的formats链表之中,然后让formats链表中的所有成员再试一次。上述逻辑位于search_binary_handler函数之中:
1 | int search_binary_handler(struct linux_binprm *bprm,struct pt_regs *regs) |
我们可以通过下面的方式来查看自己机器的编译选项,从而得知支持的可执行文件的类型:
1 | grep BINFMT /boot/config-3.13.0-43-generic |
在内核代码树中fs目录下,Makefile记录了支持的格式,在fs目录下,每一种支持的格式xx都有一个binfmt_xx.c文件。binfmt_aout.c是对应a.out类型的可执行文件,这种文件格式是早期Unix系统使用的可执行文件的格式,由AT&T设计,今天已经退出了历史舞台。binfmt_elf.c对应的是ELF格式的可执行文件。ELF最早由Unix系统实验室(Unix SYSTEM Laboratories USL)开发,目的是取代传统的a.out格式。1994年6月ELF格式出现在Linux系统上,目前,ELF格式已经成为Linux下最主要的可执行文件格式。
binfmt_script对应的是script格式的可执行文件,这种格式的可执行文件一般以“#!”开头,查找相应的解释器来执行脚本。比如python脚本、shell脚本和perl脚本等。早期的内核之中,曾经为Java格式提供了专门的binfmt结构,后来取消了,原因是Java并不特殊,不值得为其提供专门的binfmt结构。如果专门为Java提供了,其他语言就会有意见了,没有做到一视同仁。但是需要支持的可执行文件的格式越来越多,大家都可能有自己的解释器,内核支持也不可能无限地增加binfmt结构,这时候,binfmt_misc就出现了。binfmt把这个功能开放给了用户层,用户可以引入自己的可执行文件格式,只要你能定义好magic number,识别出文件是不是自己的这种格式,另外自己定义好解释器就可以了。binfmt_misc这个机制非常好,提供了支持额外可执行格式的可扩展方法。举例来讲,如果想在Linux下执行Windows的exe文件,Wine软件可以在Linux下执行Windows的exe文件。
注册某种可执行文件到binfmt_misc的格式时,echo的内容如下所示:
1 | :Name:Type:Offset:String:Mask:Interpreter:Flags |
例如我们可以将Windows exe文件注册到binfmt_misc,直接使用如下方法即可执行exe文件:
1 | echo ':Wine:M::MZ::/usr/bin/wine:' > /proc/sys/fs/binfmt_misc/register |
我们echo语句的含义是:Windows可执行文件的前两个字节是magic number,值为MZ,由解释程序/usr/bin/wine执行这个可执行文件。
关于ELF文件的加载执行,博客中很多其他文章有所介绍。
exec与信号
exec系列函数,会将现有进程的所有文本段抛弃,直接奔向新生活。调用exec之前,进程可能执行过signal或sigaction,为某些信号注册了新的信号处理函数。一旦决裂,这些新的信号处理函数就无处可寻了。所以内核会为那些曾经改变信号处理函数的信号负责,将它们的处理函数重新设置为SIG_DFL。这里有一个特例,就是将处理函数设置为忽略(SIG_IGN)的SIGCHLD信号。调用exec之后,SIGCHLD的信号处理函数是保持为SIG_IGN还是重置成SIG_DFL,SUSv3语焉不详,这点要取决于操作系统。对于Linux系统而言,采用的是前者:保持为SIG_IGN。
执行exec之后进程继承的属性
执行exec的进程,其个性虽然叛逆,与过去做了决裂,但是也继承了过去的一些属性。exec运行之后,与进程相关的ID都保持不变。如果进程在执行exec之前,设置了告警(如调用了alarm函数),那么在告警时间到时,它仍然会产生一个信号。在执行exec后,挂起信号依然保留。创建文件时,掩码umask和执行exec之前一样。
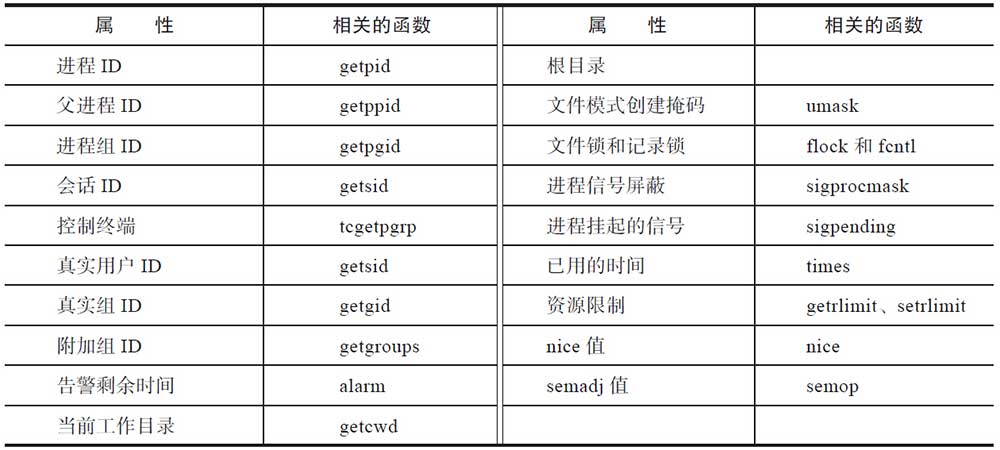
通过fork创建的子进程继承的属性和执行exec之后进程保持的属性,两相比较,差异不小。对于fork而言:
- 告警剩余时间:不仅仅是告警剩余时间,还有其他定时器(
setitimer、timer_create等),fork创建的子进程都不继承。 - 进程挂起信号:子进程会将挂起信号初始化为空。
- 信号量调整值semadj:子进程不继承父进程的该值,详情请见进程间通信的相关章节。
- 记录锁(fcntl):子进程不继承父进程的记录锁。比较有意思的地方是文件锁flock子进程是继承的。
- 已用的时间times:子进程将该值初始化成0。
system
前面提到了fork函数、exec系列函数、wait系列函数。库将这些接口糅合在一起,提供了一个system函数。程序可以通过调用system函数,来执行任意的shell命令。相信很多程序员都用过system函数,因为它起到了一个粘合剂的作用,可以让C程序很方便地调用其他语言编写的程序。同时,相信有很多程序员被system函数折磨过,当出现错误时,如何根据system函数的返回值,定位失败的原因是个比较头疼的问题。下面我们来细细展开。
函数接口
1 |
|
这里将需要执行的命令作为command参数,传给system函数,该函数就帮你执行该命令。这样看来system最大的好处就在于使用方便。不需要自己来调用fork、exec和waitpid,也不需要自己处理错误,处理信号,方便省心。
但是system函数的缺点也是很明显的。首先是效率,使用system运行命令时,一般要创建两个进程,一个是shell进程,另外一个或多个是用于shell所执行的命令。如果对效率要求比较高,最好是自己直接调用fork和exec来执行既定的程序。从进程的角度来看,调用system的函数,首先会创建一个子进程shell,然后shell会创建子进程来执行command。
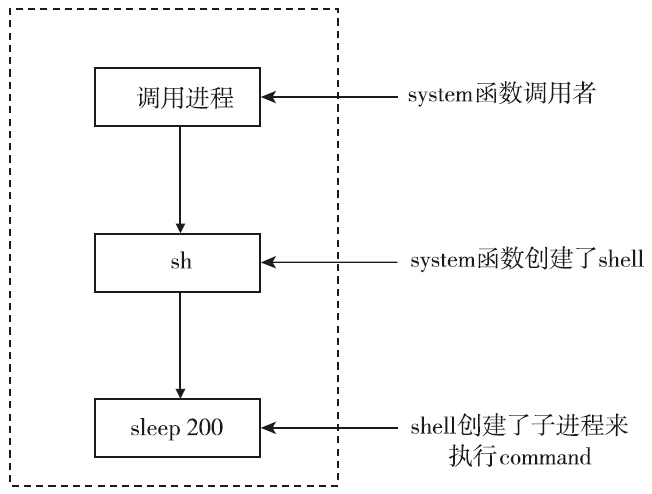
调用system函数后,命令是否运行成功是我们最关心的事情。但是system的返回值比较复杂,下面通过一个简化的不完备(没有处理信号)的system实现来讲述system函数的返回值,代码如下:
1 |
|
- 当command为NULL时,返回0或1正常情况下,不会这样用system。但是command为NULL是有用的,用户可以通过调用
system(NULL)来探测shell是否可用。如果shell存在并且可用,则返回1,如果系统里面压根就没有shell,这种情况下,shell就是不可用的,返回0。那么何种情况下shell不可用呢?比如system函数运行在非Unix系统上,再比如程序调用system之前,执行过了chroot,这些情况下shell都可能无法使用。
1 | glibc-2.17/sysdeps/posix/system.c |
- 创建进程(fork)失败,或者获取子进程终止状态(waitpid)失败,则返回-1创建进程失败的情况比较少见,比较容易想到的也就是创建了太多的进程,超出了系统的限制。但是等待子进程终止状态失败,是比较容易造出来的。前面讲过,子进程退出的时候,如果SIGCHLD的信号处理函数是SIG_IGN或用户设置了SA_NOCLDWAIT标志位,那么子进程就不进入僵尸状态等待父进程wait了,直接自行了断,灰飞烟灭。但是system函数的内部实现会调用waitpid来获取子进程的退出状态。这就是父子之前没有协调好造成的错误。这种情况下,system返回-1,errno为ECHLD。
1 | signal(SIGCHLD,SIG_IGN);/*返回-1的根源在于此处*/ |
- 如果子进程不能执行shell,那么system返回值会与
_exit(127)终止时一样
1 | // 这里如果执行execl失败,就会执行到_exit(127),否则不会执行到_exit(127)。 |
如果所有的系统调用都执行成功,system函数就会返回执行command的子shell的终止状态。因为shell的终止状态是其执行最后一条命令的退出状态。这种情况下就和获取子进程的退出状态一样了。前文详细提到过,可以根据下面的接口来判断:
1
2
3
4
5WIFEXITED(status)
WEXITSTATUS(status)
WIFSIGNALED(status)
WTERMSIG(status)
WCOREDUMP(status)
综上所述,在command不等于NULL的情况下,正确判断system返回值的方法如下:
1 | if((status = system(command) ) == -1) |
system与信号
前面介绍了system函数的用法,并且引入了一个system函数的简单不完备的实现。之所以说是不完备的,是因为没有考虑信号。正确地处理信号,将会给system的实现带来复杂度。首先要考虑SIGCHLD。如果调用system函数的进程还存在其他子进程,并且对SIGCHLD信号的处理函数也执行了wait()。那么这种情况下,由system()创建的子进程退出并产生SIGCHLD信号时,主程序的信号处理函数就可能先被执行,导致system函数内部的waitpid无法等待子进程的退出,这就产生了竞争。这种竞争带来的危害是双方面的:
- 程序会误认为自己调用fork创建的子进程退出了。
- system函数内部的waitpid返回失败,无法获取内部子进程的终止状态。
鉴于上述原因,system运行期间必须要暂时阻塞SIGCHLD信号。其他需要考虑的信号还有由终端的中断操作(一般是ctrl+c)和退出操作(一般是ctrl+\)产生的SIGINT信号和SIGQUIT信号。调用system函数会创建shell子进程,然后由shell子进程再创建子进程来执行command。那么这三个进程又是如何应对的呢?SUSv3标准规定:
- 调用system函数的进程,需要忽略SIGINT和SIGQUIT信号。
- system函数内部创建的进程,要恢复对SIGINT和SIGQUIT的默认处理。
进程控制
这部分内容在Linux 内核分析之进程中有较为详细的描述。
进程状态
就像人不可能一刻不停地工作一样,进程也无法始终占有CPU运行。原因有三:
- 进程可能需要等待某种外部条件的满足,在条件满足之前,进程是无法继续执行的。这种情况下,该进程继续占有CPU就是对CPU资源的浪费。
- Linux是多用户多任务的操作系统,可能同时存在多个可以运行的进程,进程个数可能远远多于CPU的个数。一个进程始终占有CPU对其他进程来说是不公平的,进程调度器会在合适的时机,选择合适的进程使用CPU资源。
- Linux进程支持软实时,实时进程的优先级高于普通进程,实时进程之间也有优先级的差别。软实时进程进入可运行状态的时候,可能会发生抢占,抢占当前运行的进程。
Linux下,进程的状态有以下7种:
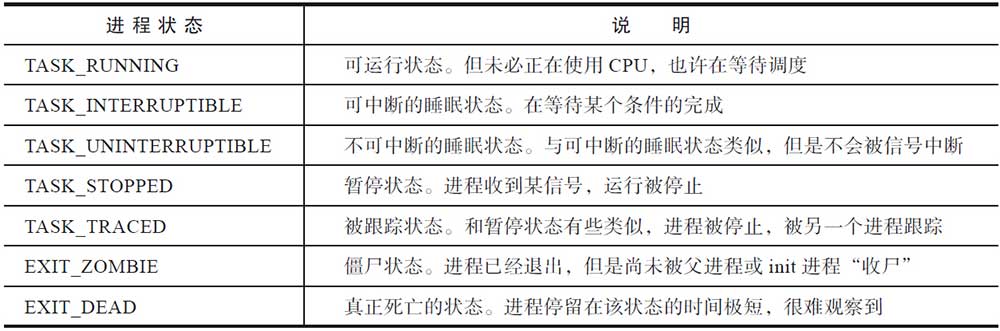
可运行状态
首先是可运行状态。该状态的名称为TASK_RUNNING,严格来说这个名字是不准确的,因为该状态的确切含义是可运行状态,并非一定是在占有CPU运行,将该状态称为TASK_RUNABLE会更准确。有人说Linux进程有8种状态,这种说法也是对的。因为TASK_RUNNIING可以根据是否在CPU上运行,进一步细分成RUNNING和READY两种状态(如图5-1所示)。处于READY状态的进程表示,它们随时可以投入运行,只不过由于CPU资源有限,调度器暂时并未选中它运行。
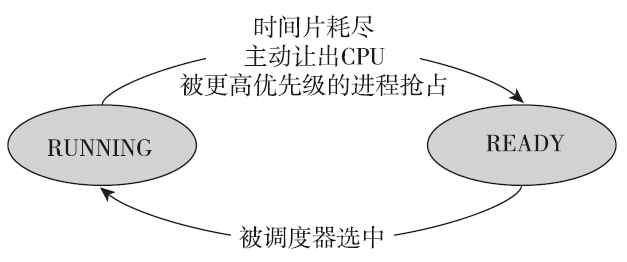
处于可运行状态的进程是进程调度的对象。如果进程并不处于可运行状态,进程调度器就不会选择它投入运行。在Linux中,每一个CPU都有自己的运行队列,事实上还不止一个,根据进程所属调度类别的不同,可运行状态的进程也会位于不同的队列上:如果是实时进程(属于实时调度类),则根据优先级的情况,落在相应的优先级的队列上;如果是普通进程(属于完全公平调度类),则根据虚拟运行时间的大小,落在红黑树的相应位置上。这样进程调度器就可以根据一定的算法从运行队列上挑选合适的进程来使用CPU资源。
处于RUNNING状态的进程,可能正在执行用户态(user-mode)代码,也可能正在执行内核态(kernel-mode)代码,内核提供了进一步的区分和统计。Linux提供的time命令可以统计进程在用户态和内核态消耗的CPU时间:
1 | manu@manu-rush:~$ time sleep 2 |
time命令统计了三种时间:实际时间、用户CPU时间和系统CPU时间。实际时间即进程从开始到终止,一共执行了多久。user一行统计的是进程执行用户态代码消耗的CPU时间;sys一行统计的是进程在内核态运行所消耗的CPU时间。
如何区分用户态CPU时间和内核态CPU时间呢?我们举例来说明。如果进程在执行加减乘除或浮点数计算或排序等操作时,尽管这些操作正在消耗CPU资源,但是和内核并没有太多的关系,CPU大部分时间都在执行用户态的指令。这种场景下,我们称CPU时间消耗在用户态。如果进程频繁地执行创建进程、销毁进程、分配内存、操作文件等操作,那么进程不得不频繁地陷入内核执行系统调用,这些时间都累加在进程的内核态CPU时间。对于这三种时间,最容易产生的误解的是real time=user time+sys time。这种想法是错误的。在单核系统上,real time总是不小于user time与sys time的总和。但是在多核系统上,user time与sys time的总和可以大于real time。利用这三个时间,我们可以计算出程序的CPU使用率:
1 | cpu_usage = ((user time) + (sys time))/(real time) |
在多核处理器情况下,cpu_usage如果大于1,则表示该进程是计算密集型(CPU bound)的进程,且cpu_usage的值越大,表示越充分地利用了多处理器的并行运行优势;如果cpu_usage的值小于1,则表示进程为I/O密集型(I/O bound)的进程,多核并行的优势并不明显。time命令的问题在于要等进程运行完毕后,才能获取到进程的统计信息,正所谓盖棺定论。有些时候,我们需要了解正在运行的进程:它运行了多久,内核态CPU时间和用户态CPU时间分别是多少?procfs在/proc/PID/stat中提供了相关的信息:
1 | manu@manu-rush:~$ cat /proc/8283/stat |
数组中的每个字段都有自己独特的含义。如果从0开始计数,那么字段13对应的是进程消耗的用户态CPU时间,字段14记录的是进程消耗的内核态CPU时间。两者的单位是时钟嘀嗒(clock tick)。一个时钟嘀嗒是多久?可以通过如下命令来获取:
1 | grep CONFIG_HZ /boot/config-`uname -r` |
当配置内核的时候,有100Hz、250Hz、300Hz和1000Hz这4个选项。如果配置的频率为250Hz,那么1秒钟就有250个时钟嘀嗒,即每过4ms,增加一个时钟嘀嗒(内核的jiffies++)。pidstat可以通过-p参数指定观察的进程,从而可以获取到该进程的CPU使用情况,包括用户态CPU时间和内核态CPU时间。
1 | manu@manu-rush:~$ ps -p 8283 -o etime,cmd,pid |
可中断睡眠状态和不可中断睡眠状态
进程并不总是处于可运行的状态。有些进程需要和慢速设备打交道。比如进程和磁盘进行交互,相关的系统调用消耗的时间是非常长的(可能在毫秒数量级甚至会更久),进程需要等待这些操作完成才可以执行接下来的指令。有些进程需要等待某种特定条件(比如进程等待子进程退出、等待socket连接、尝试获得锁、等待信号量等)得到满足后方可以执行,而等待的时间往往是不可预估的。在这种情况下,进程依然占用CPU就不合适了,对CPU资源而言,这是一种极大的浪费。因此内核会将该进程的状态改变成其他状态,将其从CPU的运行队列中移除,同时调度器选择其他的进程来使用CPU资源。
Linux存在两种睡眠的状态:可中断的睡眠状态(TASK_INTERRUPTIBLE)和不可中断的睡眠状态(TASK_UNINTERRUPTIBLE)。这两种睡眠状态是很类似的。两者的区别就在于能否响应收到的信号。处于可中断的睡眠状态的进程,返回到可运行的状态有以下两种可能性:
- 等待的事件发生了,继续运行的条件满足了。
- 收到未被屏蔽的信号。
当处于可中断睡眠状态的进程收到信号时,会返回EINTR给用户空间。程序员需要检测返回值,并做出正确的处理。
但是对于不可中断的睡眠状态,只有一种可能性能使其返回到可运行的状态,即等待的事件发生了,继续运行的条件满足了。
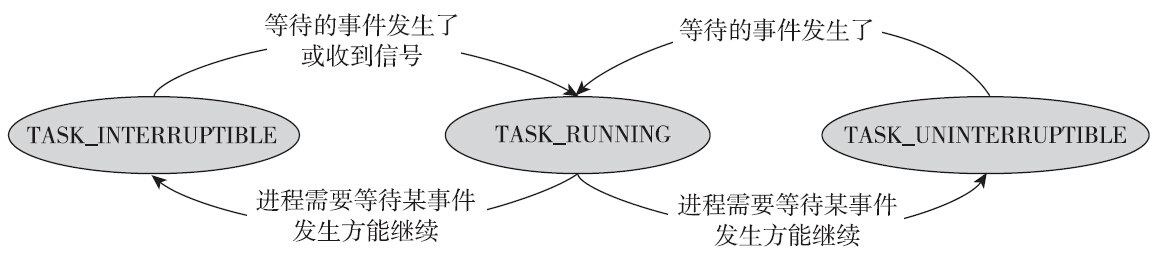
TASK_UNINTERRUPTIBLE状态存在的意义在于,内核中某些处理流程是不应该被打断的,如果响应异步信号,程序的执行流程中就会插入一段用于处理异步信号的流程,原有的流程就被中断了。因此当进程在对某些硬件进行某些操作时(比如进程调用read系统调用对某个文件进行读操作,read系统调用最终执行对应设备驱动的代码,并与对应的物理设备交互),需要使用TASK_UNINTERRUPTIBLE状态把进程保护起来,以避免进程与设备的交互过程被打断,致使设备陷入不可控的状态。
TASK_UNINTERRUPTIBLE是一种很危险的状态,因为进程进入该状态后,刀枪不入,任何信号都无法打断它。我们无法通过信号杀死一个处于不可中断的休眠状态的进程,SIGKILL信号也不行。
正常情况下,进程处于TASK_UNINTERRUPTIBLE状态的时间会非常短暂,进程不应该长时间处于不可中断的睡眠状态,但是这种情况确实可能会发生(内核代码流程中可能有bug,或者用户内核模块中的相关机制不合理都会导致某些进程长时间处于D状态)。举例来讲,当通过NFS访问远程目录时,异地文件系统的异常可能会使进程进入该状态。如果远端的文件系统始终异常,使进程的I/O请求得不到满足,该进程会一直处于TASK_UNINTERRUPTIBLE状态,无法杀死,除了重启Linux机器之外,无药可救。
内核提供了hung task检测机制,它会启动一个名为khungtaskd的内核线程来检测处于TASK_UNINTERRUPTIBLE状态的进程是否已经失控。khungtaskd定期被唤醒(默认是120秒),它会遍历所有处于TASK_UNINTERRUPTIBLE状态的进程进行检查,如果某进程超过120秒未获得调度,那么内核就会打印出警告信息和该进程的堆栈信息。120秒这个时间是可以定制的,内核提供了控制选项:
1 | root@manu-rush:~ |
关于khungtaskd的更多细节,可以阅读内核kernel/hung_task.c代码。无论进程处于可中断的睡眠状态,还是不可中断的睡眠状态,我们都可能会希望了解进程停在什么位置或在等待什么资源。procfs的wchan提供了这方面的信息,wchan是wait channel的含义。ps命令也可以通过wchan获得该信息:
1 | manu@manu-rush:~$ echo $$ |
另外一种方法是查看进程的stack信息,方法如下所示:
1 | manu@manu-rush:~$ sudo cat /proc/3828/stack |
通过procfs的wchan和stack,不难看出,当前的bash正在等待子进程的退出。
睡眠进程和等待队列
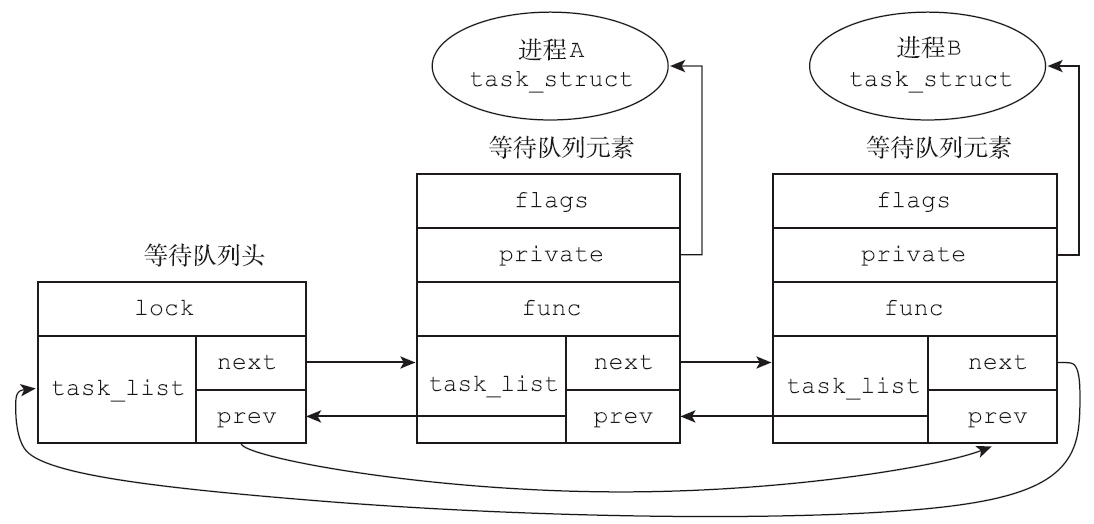
进程无论是处于可中断的睡眠状态还是不可中断的睡眠状态,有一个数据结构是绕不开的:等待队列(wait queue)。进程但凡需要休眠,必然是等待某种资源或等待某个事件,内核必须想办法将进程和它等待的资源(或事件)关联起来,当等待的资源可用或等待的事件已发生时,可以及时地唤醒相关的进程。
内核采用的方法是等待队列。等待队列作为Linux内核中的基础数据结构和进程调度紧密地结合在一起。当进程需要等待特定事件时,就将其放置在合适的等待队列上,因此等待队列对应的是一组进入休眠状态的进程,当等待的事件发生时(或者说等待的条件满足时),这组进程会被唤醒,这类事件通常包括:中断(比如DISK I/O完成)、进程同步、休眠时间到时等。内核使用双向链表来实现等待队列,每个等待队列都可以用等待队列头来标识,等待队列头的定义如下:
1 | struct __wait_queue_head { |
进程需要休眠的时候,需要定义一个等待队列元素,将该元素挂入合适的等待队列,等待队列元素的定义如下:
1 | typedef struct __wait_queue wait_queue_t; |
等待队列上的每个等待队列元素,都对应于一个处于睡眠状态的进程。
内核如何使用等待队列完成睡眠,以及条件满足之后如何唤醒对应的进程呢?首先要定义和初始化等待队列头部。等待队列头部相当于一杆大旗,没有这杆大旗,将来的等待队列元素将成为“孤魂野鬼”,无处安放。内核提供了init_waitqueue_head和DECLARE_WAIT_QUEUE_HEAD两个宏,用来初始化等待队列头部。其次,当进程需要睡眠时,需要定义等待队列元素。内核提供了init_waitqueue_entry函数和init_waitqueue_func_entry函数来完成等待队列元素的初始化:
1 | static inline void init_waitqueue_entry(wait_queue_t *q, struct task_struct *p) |
除此以外,内核还提供了宏DECLARE_WAITQUEUE,也可用来初始化等待队列元素:
1 |
从等待队列元素的初始化函数或初始化宏不难看出,等待队列元素的private成员变量指向了进程的进程描述符task_struct,因此就有了等待队列元素,就可以将进程挂入对应的等待队列了。第三步是将等待队列元素(即睡眠进程)放入合适的等待队列中。内核同时提供了add_wait_queue和add_wait_queue_exclusive两个函数来把等待队列元素添加到等待队列头部指向的双向链表,代码如下:
1 | void add_wait_queue(wait_queue_head_t *q, wait_queue_t *wait) |
这两个函数的区别在于:
- 一个等待队列元素设置了WQ_FLAG_EXCLUSIVE标志位,而另一个则没有。
- 一个等待队列元素放到了等待队列的尾部,而另一个则放到了等待队列的头部。
同样是添加到等待队列,为何同时提供了两个函数,WQ_FLAG_EXCLUSIVE标志位到底有什么作用?不妨来思考如下问题:如果存在多个进程在等待同一个条件满足或同一个事件发生(即等待队列上有多个等待队列元素),那么当条件满足时,应该把所有进程一并唤醒还是只唤醒某一个或某几个进程?
答案是具体情况具体分析。有时候需要唤醒等待队列上的所有进程,但又有些时候唤醒操作需要具有排他性(EXCLUSIVE)。比如多个进程等待临界区资源,当锁的持有者释放锁时,如果内核将所有等待在该锁上的进程一起唤醒,那么最终也只能有一个进程竞争到锁资源,而大多数的竞争者,不过是从休眠中醒来,然后继续休眠,这会浪费CPU资源,如果等待队列中的进程数目很大,还会严重影响性能。这就是所谓的惊群效应(thundering herd problem)。
因此内核提供了WQ_FLAG_EXCLUSEVE标志位来实现互斥等待,add_wait_queue_exclusive函数会将带有该标志位的等待队列元素添加到等待队列的尾部。当内核唤醒等待队列上的进程时,等待队列元素中的WQ_FLAG_EXCLUSEVE标志位会影响唤醒行为,比如wake_up宏,它唤醒第一个带有WQ_FLAG_EXCLUSEVE标志位的进程后就会停止。
1 | wait_event(wq, condition) |
第一个参数指向的是等待队列头部,表示进程会睡眠在该等队列上。进程醒来时,condition需要得到满足,否则继续阻塞。其中wait_event和wait_event_interruptible的区别在于,睡眠过程中,前者的进程状态是不可中断的睡眠状态,不能被信号中断,而后者是可中断的睡眠状态,可以被信号中断。名字中带有_timeout的宏意味着阻塞等待的超时时间,以jiffy为单位,当超时时间到达时,无论condition是否满足,均返回。我们不妨以wait_event宏为例,欣赏一下内核是如何使用等待队列,等待某个条件的满足的:
1 |
|
prepare_to_wait函数负责将等待队列元素添加到对应的等待队列,同时将进程的状态设置成TASK_UNINTERRUPTIBLE,完成prepare_to_wait的工作后,会检查条件是否满足条件,如果条件不满足,则调用schedule()函数,主动让出CPU使用权,等待被唤醒。有睡眠就要有唤醒,有wait_event系列的宏,与之对应的,就要有wake_up系列的宏,它们必须成对出现。这一组宏有:
1 | wake_up(x) |
这些宏和前面wait_event系列宏的配对使用情况如图所示。
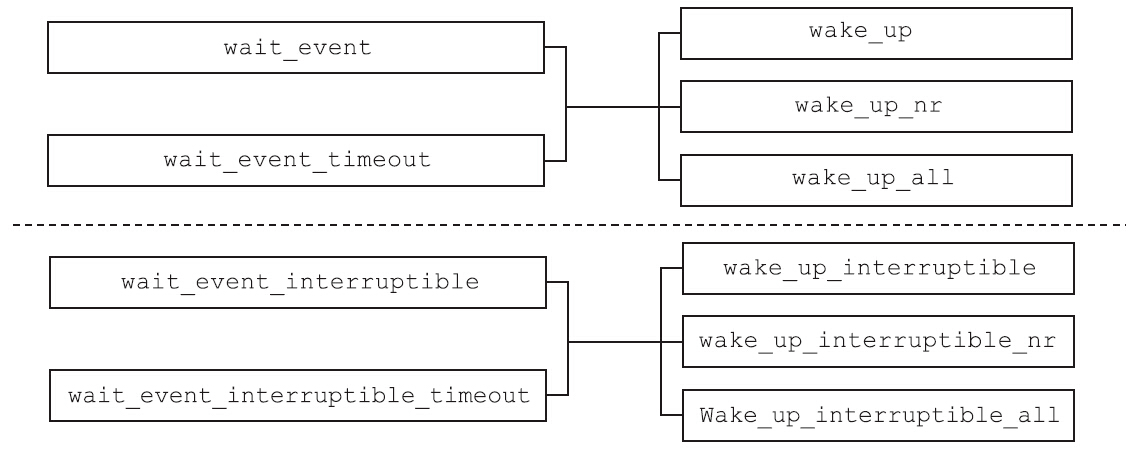
其中该系列宏中,名字里带_interruptible的宏只能唤醒处于TASK_INTERRUPTIBLE状态的进程,而名字中不带_interruptible的宏,既可以唤醒TASK_INTERRUPTIBLE状态的进程,也可以唤醒TASK_UNINTERRUPTIBLE状态的进程。wake_up系列函数中为什么有些函数后面有_nr和_all这样的后缀?其实不难猜到这些后缀的含义:不带后缀的表示最多只能唤醒一个带有WQ_FLAG_EXCLUSIVE标志位的进程,带_nr的表示可以唤醒nr个带有WQ_FLAG_EXCLUSIVE标志位的进程,而带_all后缀的则表示唤醒等待队列上的所有进程。这些wake_up系列的宏,其实现部分最终都是通过__wake_up函数的简单封装来实现的,如图所示。
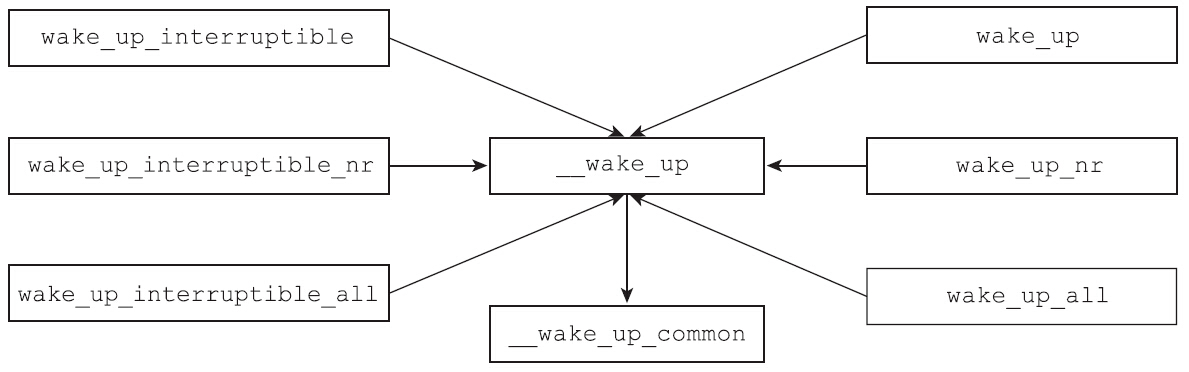
下面来分析下__wake_up函数,看看内核是如何唤醒睡眠在等待队列上的进程的,代码如下:
1 | void __wake_up(wait_queue_head_t *q, unsigned int mode, int nr_exclusive, void *key) |
注意,遍历等待队列上的所有等待队列元素时,对于每一个需要唤醒的进程,执行的是等待队列元素中定义的func,最多唤醒nr_exclusive个带有WQ_FLAG_EXCLUSIVE的等待队列元素。在初始化等待队列元素的时候,需要注册回调函数func。当内核唤醒该进程时,就会执行等待队列元素中的回调函数。等待队列元素最常用的回调函数是default_wake_function,就像它的名字一样,是默认的唤醒回调函数。无论是DECLARE_WAITQUEUE还是init_waitqueue_entry,都将等待队列元素的func指向default_wake_function。而default_wake_function仅仅是大名鼎鼎的try_to_wake_up函数的简单封装,代码如下:
1 | int default_wake_function(wait_queue_t *curr, unsigned mode, int wake_flags, |
try_to_wake_up是进程调度里非常重要的一个函数,它负责将睡眠的进程唤醒,并将醒来的进程放置到CPU的运行队列中,然后并设置进程的状态为TASK_RUNNING。在本章的后面会对该函数进行详细的分析。
TASK_KILLABLE状态
很多文章在介绍TASK_UNINTERRUPTIBLE状态时,都喜欢通过下面的例子来创建一个处于TASK_UNINTERRUPTIBLE状态的进程:
1 |
|
很多文章认为,调用vfork函数创建子进程时,子进程在调用exec函数或退出之前,父进程始终处于TASK_UNINTERRUPTIBLE的状态。其实这种说法是错误的。因为很明显,父进程可以轻易地被信号杀死,这证明父进程并不是处于TASK_UNINTERRUPTIBLE的状态。
1 | root@manu-hacks:~ |
为什么进程的状态显示的是D+,按照ps命令的说法应该是处于不可中断的睡眠状态,可为什么仍然会被信号杀死呢?这好像和前面的讲述并不一致。
事实上,ps命令输出的D状态不能简单地理解成UNINTERRUPTIBLE状态。内核自2.6.25版本起引入了一种新的状态即TASK_KILLABLE状态。可中断的睡眠状态太容易被信号打断,与之对应,不可中断的睡眠状态完全不可以被信号打断,又容易失控,两者都失之极端。而内核新引入的TASK_KILLABLE状态则介于两者之间,是一种调和状态。该状态行为上类似于TASK_UNINTERRUPTIBLE状态,但是进程收到致命信号(即杀死一个进程的信号)时,进程会被唤醒。上面的例子中vfork创建子进程之后,ps显示父进程处于D的状态,却依然可以被杀死的原因就是进程并不是处于不可中断的睡眠状态,而是处于TASK_KILLABLE状态。而这种状态,是可以响应致命信号的。有了该状态,wait_event系列宏也增加了killable的变体,即wait_event_killable宏。该宏会将进程置为TASK_KILLABLE状态,同时睡眠在等待队列上。致命信号SIGKILL可以将其唤醒。
TASK_STOPPED状态和TASK_TRACED状态
TASK_STOPPED状态是一种比较特殊的状态。SIGSTOP、SIGTSTP、SIGTTIN和SIGTTOU等信号会将进程暂时停止,停止后进程就会进入到该状态。上述4种信号中的SIGSTOP具有和SIGKILL类似的属性,即不能忽略,不能安装新的信号处理函数,不能屏蔽等。当处于TASK_STOPPED状态的进程收到SIGCONT信号后,可以恢复进程的执行

TASK_TRACED是被跟踪的状态,进程会停下来等待跟踪它的进程对它进行进一步的操作。如何才能制造出处于TASK_TRACED状态的进程呢?最简单的例子是用gdb调试程序,当进程在断点处停下来时,此时进程处于该状态。下面用一个最简单的hello程序来验证gdb停下的程序的确处于TASK_TRACED的状态。在一个终端,gdb将程序停下,停在断点处:
TASK_TRACED和TASK_STOPPED状态的类似之处是都处于暂停状态,不同之处是TASK_TRACED不会被SIGCONT信号唤醒。只有调试进程通过ptrace系统调用,下达PTRACE_CONT、PTRACE_DETACH等指令,或者调试进程退出,被调试的进程才能恢复TASK_RUNNING的状态。
EXIT_ZOMBIE状态和EXIT_DEAD状态
EXIT_ZOMBIE和EXIT_DEAD是两种退出状态,严格说来,它们并不是运行状态。当进程处于这两种状态中的任何一种时,它其实已经死去了。内核会将这两种状态记录在进程描述符的exit_state中,不过不想细分的话,可以笼统地说进程处于TASK_DEAD状态。
两种状态的区别在于,如果父进程没有将SIGCHLD信号的处理函数重设为SIG_IGN,或者没有为SIGCHLD设置SA_NOCLDWAIT标志位,那么子进程退出后,会进入僵尸状态等待父进程或init进程来收尸,否则直接进入EXIT_DEAD。如果不停留在僵尸状态,进程的退出是非常快的,因此很难观察到一个进程是否处于EXIT_DEAD状态。
在proc文件系统中,在/proc/PID/status中,记录了PID对应进程的状态信息。其中State项记录了该进程的瞬时状态。因为进程状态是不断迁移变化的,所以读出来的结果是瞬时的值。
1 | manu@manu-rush:~$ cat /proc/1/status |
procfs中,进程的状态有几种可能的值呢?一起去查看内核的源码。在fs/proc/array.c中,定义了所有可能的值,定义如下:
1 | static const char * const task_state_array[] = { |
这几种状态都会从procfs中出现吗?并非如此。
1 | static inline const char *get_task_state(struct task_struct *tsk) |
只有在TASK_REPORT宏出现的状态加上两个退出状态时,才能出现在procfs中:
1 |
从TASK_REPORT宏中可以看出,并没有TASK_DEAD、TASK_WAKEKILL和TASK_WAKING,也就是说在procfs中,无法观察到下面这三个值,它们从不出现:
1 | "x (dead)", /* 64 */ |
在vfork那个例子中,在procfs中查询进程状态时,父进程处于D(disk sleep)状态,而并没有出现K(wakekill),原因就在于此。那么是时候记住,会在procfs中出现的进程状态了:
1 | "R (running)", |
进程调度
进程调度器是对处于可运行(TASK_RUNNING)状态的进程进行调度,如果进程并非TASK_RUNNING的状态,那么该进程和进程调度是没有关系的。
Linux是多任务的操作系统,所谓多任务是指系统能够同时并发地执行多个进程,哪怕是单处理器系统。在单处理器系统上支持多任务,会给用户多个进程同时跑的幻觉,事实上多个进程仅仅是轮流使用CPU资源。只有在多处理器系统中,多个进程才能真正地做到同时、并行地执行。多任务系统可以根据是否支持抢占分成两类:非抢占式多任务和抢占式多任务。在非抢占式多任务的系统中,下一个任务被调度的前提是当前进程主动让出CPU的使用权,因此非抢占式多任务又称为合作型多任务。而抢占式多任务由操作系统来决定进程调度,在某些时间点上,操作系统可以将正在运行的进程调度出去,选择其他进程来执行。毫无疑问,Linux属于抢占式多任务系统。事实上,大多数的现代操作系统都是抢占式的多任务系统。
此外,不同的进程之间,其行为模式可能存在着巨大的差异。进程的行为模式可以粗略地分成两类:CPU消耗型(CPU bound)和I/O消耗型(I/O bound)。所谓CPU消耗型是指进程因为没有太多的I/O需求,始终处于可运行的状态,始终在执行指令。而I/O消耗型是指进程会有大量I/O请求(比如等待键盘键入、读写块设备上的文件、等待网络I/O等),它处于可执行状态的时间不多,而是将更多的时间耗费在等待上。当然这种划分方法并非绝对的,可能有些进程某段时间表现出CPU消耗型的特征,另一段时间又表现出I/O消耗型的特征。
还有另外一种进程分类的方法,如下。
- 交互型进程:这种类型的进程有很多的人机交互,进程会不断地陷入休眠状态,等待键盘和鼠标的输入。但是这种进程对系统的响应时间要求非常高,用户输入之后,进程必须被及时唤醒,否则用户就会觉得系统反应迟钝。比较典型的例子是文本编辑程序和图形处理程序等。
- 批处理型进程:这类进程和交互型的进程相反,它不需要和用户交互,通常在后台执行。这样的进程不需要及时的响应。比较典型的例子是编译、大规模科学计算等,一般来说,这种进程总是“被侮辱的和被损害的”。
- 实时进程:这类进程优先级比较高,不应该被普通进程和优先级比它低的进程阻塞。一般需要比较短的响应时间。
计一个优秀的进程调度器绝不是一件容易的事情,它还有很多事情需要考虑,很多目标需要达成:
- 公平:每一个进程都可以获得调度的机会,不能出现“饿死”的现象。
- 良好的调度延迟:尽量确保进程在一定的时间范围内,总能够获得调度的机会。
- 差异化:允许重要的进程获得更多的执行时间。
- 支持软实时进程:软实时进程,比普通进程具有更高的优先级。
- 负载均衡:多个CPU之间的负载要均衡,不能出现一些CPU很忙,而另一些CPU很闲的情况。·高吞吐量:单位时间内完成的进程个数尽可能多。
- 简单高效:调度算法要高效。不应该在调度上花费太长的时间。
- 低耗电量:在系统并不繁忙的情况下,降低系统的耗电量。
在对称多处理器(SMP)的系统上,存在着多个处理器,那么所有处于可运行状态的进程是应该位于一个队列上,还是每个处理器都要有自己的队列?这大概是进程调度首先要解决的问题。目前Linux采用的是每个CPU都要有自己的运行队列,即per cpu run queue。每个CPU去自己的运行队列中选择进程,这样就降低了竞争。这种方案还有另外一个好处:缓存重利用。某个进程位于这个CPU的运行队列上,经过多次调度之后,内核趋于选择相同的CPU执行该进程。这种情况下上次运行的变量很可能仍然在CPU的缓存中,这样就提升了效率。
Linux选择了每一个CPU都有自己的运行队列这种解决方案。这种选择也带来了一种风险:CPU之间负载不均衡,可能出现一些CPU闲着而另外一些CPU忙不过来的情况。为了解决这个问题,load_balance就闪亮登场了。load_balance的任务就是在一定的时机下,通过将任务从一个CPU的运行队列迁移到另一个CPU的运行队列,来保持CPU之间的负载均衡。进程调度具体要做哪些事情呢?概括地说,进程调度的职责是挑选下一个执行的进程,如果下一个被调度到的进程和调度前运行的进程不是同一个,则执行上下文切换,将新选择的进程投入运行。下面根据调度的入口点函数schedule()来看下进程调度做了哪些事情,代码如下:
1 | asmlinkage void __sched schedule(void) |
Linux是可抢占式内核(Preemptive Kernel),从内核2.6版本开始,Linux不仅支持用户态抢占,也开始支持内核态抢占。可抢占式内核的优势在于可以保证系统的响应时间。当高优先级的任务一旦就绪,总能及时得到CPU的控制权。但是很明显,内核抢占不能随意发生,某些情况下是不允许发生内核抢占的。因此为了更好地支持内核抢占,内核为每一个进程的thread_info引入了preempt_count计数器,数值为0时表示可以抢占,当该计数器的值不为0时,表示禁止抢占。
并不是所有的时机都允许发生内核抢占。以自旋锁为例,在内核可抢占的系统中,自旋锁持有期间不允许发生内核抢占,否则可能会导致其他CPU长期不能获得锁而死等。因此在spin_lock函数中(通过__raw_spin_lock),会调用preempt_disable宏,而该宏会将进程preempt_count计数器的值加1,表示不允许抢占。同样的道理,解锁的时候,会将preempt_count的值减1(通过preempt_enable宏)。
1 | static inline void __raw_spin_lock(raw_spinlock_t *lock) |
preempt_count的Bit 28是一个很重要的标志位,即PREEMPT_ACTIVE。该标志位用来标记是否正在进行内核抢占。很明显,设置了该标志位之后,preempt_count就不再为0了,因此也就不允许再次发生内核抢占,从而使得正在执行抢占工作的代码不会再次被抢占。内核的preempt_schedule函数是内核抢占时呼叫调度器的入口,它会调用__schedule函数发起调度。在调用__schedule函数之前,会设置进程的PREEMPT_ACTIVE标志位,表示这是从抢占过程中进入__schedule函数的。
1 | asmlinkage void __sched notrace preempt_schedule(void) |
在__schedule函数中,内核会检查进程的PREEMPT_ACTIVE标志位,如果发现了该标志位置位,就不会调用deactivate_task函数将其从运行队列中移除。PREEMPT_ACTIVE标志位有一个非常重要的作用,即防止不处于TASK_RUNNING状态的进程被抢占过程错误地从运行队列中移除。这句话非常地绕,我们结合__schedule函数的对应代码来分析该标志位的作用。
1 | if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) { |
如果进程设置了PREEMPT_ACTIVE标志位,上述代码最外层的条件就不会得到满足。这么做的用意是:如果进程是被抢占而进入了schedule函数,那么即使它不处于TASK_RUNNING状态,也不能把它从运行队列中移除。为什么这么做?从运行队列中移除不处于TASK_RUNNING状态的进程是schedule函数份内之事,为什么设置了PREEMPT_ACTIVE标志位就不能移除呢?原因是进程从TASK_RUNNING变成其他状态,是一个过程,在这个过程中可能发生抢占。试想如下场景:一个进程刚把自己设置成TASK_INTERRUPTIBLE,它就被抢占了。因为这时候它还没来得及调用schedule()主动交出CPU控制权,仍然在CPU上执行,这就是非TASK_RUNNING状态的进程也会被抢占的场景。对于这种场景,抢占流程不应擅自将其从运行队列中移除,因为它的切换过程并未完成。下面的代码在wait_event系列宏中不断出现,我们以它为例分析上面提到的问题:
1 | for (;;) { |
执行完prepare_to_wait语句,本来是要检查条件是否满足的,如果这时候被抢占,假如没有PREEMPT_ACTIVE标志位,那么抢占过程中调用的__schedule函数就会将进程从运行队列中移除。如果本来condition条件满足了,那就错过了唤醒的机会,也许就会永远休眠了。正确的做法是,继续保留在运行队列中,后面还有机会被调度到继续运行,恢复运行后继续判断条件是否满足。上面讨论了抢占的情况,如果进程不处于TASK_RUNNING的状态,并且PREEMPT_ACTIVE并没有置位,那么就有可能会调用deactivate_task函数将其从运行队列中移除。这里说可能是因为,该进程可能存在尚未处理的信号,如果是这种情况它并不会被移除出运行队列,相反会被再次设置成TASK_RUNNING的状态,获得再次被调度到的机会。
__schdule函数的基本流程如图所示。流程图中带有背景色的部分都是调度框架里的hook点。内核的进程调度是模块化的,实现一个新的调度算法,只需要实现一组框架需要的钩子函数即可,内核将会在合适的时机调用这些函数。不妨以deactivate_task为例,来看下调度框架与具体调度算法中的函数之间的关系。deactivate_task函数的职责可以顾名思义,即进程不再处于TASK_RUNNING的状态,需要将其从对应的运行队列中移除。因此其实现为:
1 | static void deactivate_task(struct rq *rq, struct task_struct *p, int flags) |
内核会调用进程所属调度类的dequeue_task函数,至于调度类的dequeue_task函数具体做了哪些事情,完全由具体的调度类来决定。
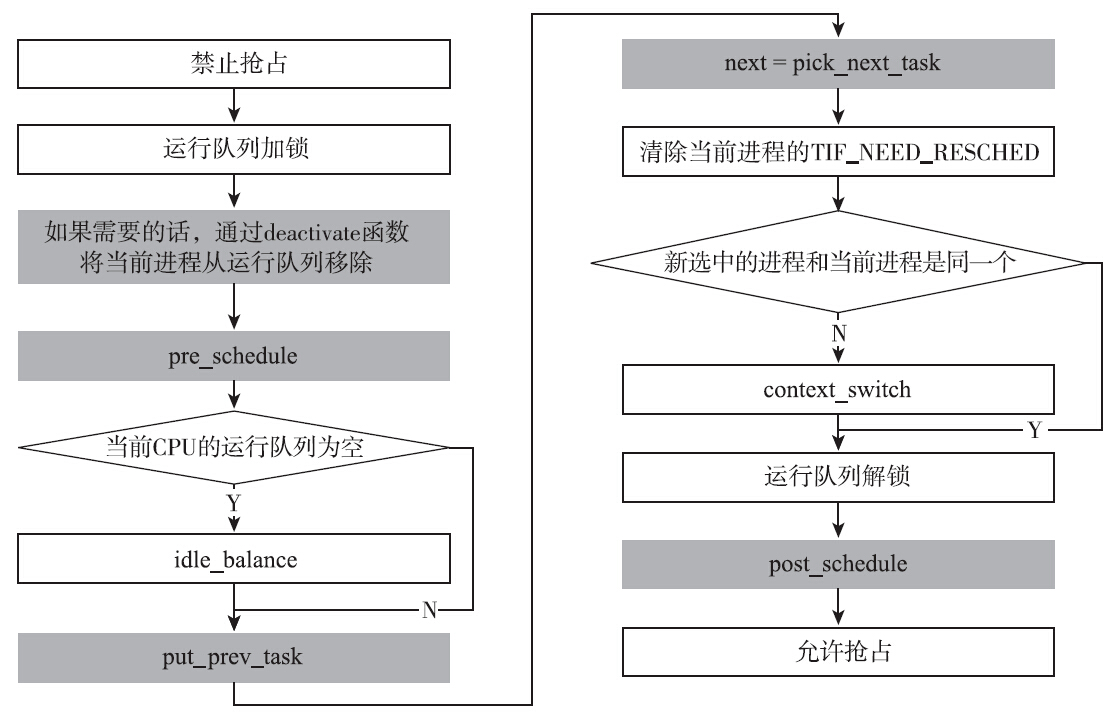
调用schedule函数时,当前进程可能仍然处于可运行的状态(主动让出CPU或被其他进程抢占),因此选择下一个占用CPU的进程之前,需要调用put_prev_task函数。该函数的目的是,当前进程被调度出去之前,留给具体调度算法一个时机来更新内部的状态。和deactivate_task函数一样,根据当前进程所属的调度类,调用具体的put_prev_task函数。
Linux内核实现了如下4种调度类:
- stop_sched_class:停止类
- rt_sched_class:实时类
- fair_sched_class:完全公平调度类
- idle_sched_class:空闲类
这4种调度类是按照优先级顺序排列的,停止类(stop_sched_class)具有最高的调度优先级,与之对应的,空闲类(idle_sched_class)具有最低的调度优先级。进程调度器挑选下一个执行的进程时,会首先从停止类中挑选进程,如果停止类中没有挑选到可运行的进程,再从实时类中挑选进程,依此类推。
pick_next_task函数负责挑选下一个运行的进程,从其实现逻辑中可以看出,系统是按照优先级顺序从调度类中挑选进程的。
1 | static inline struct task_struct * |
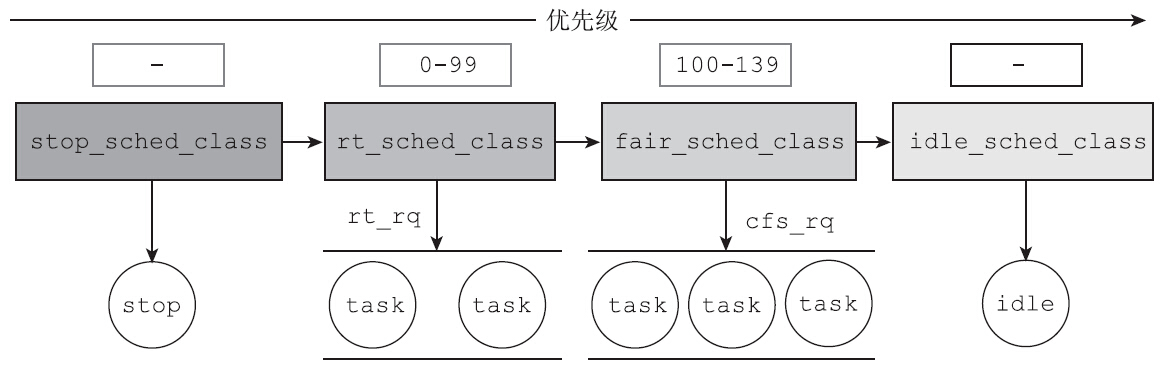
优先级最高的停止类进程,主要用于多个CPU之间的负载均衡和CPU的热插拔,它所做的事情就是停止正在运行的CPU,以进行任务的迁移或插拔CPU。优先级最低的空闲类,负责将CPU置于停机状态,直到有中断将其唤醒。idle_sched_class类的空闲任务只有在没有其他任务的时候才能被执行。每一个CPU只有一个停止任务和一个空闲任务。从上面的职责描述也可以看出,这两种调度类属于诸神之战,和应用层的关系并不大。应用层无法将进程设置成停止类进程或空闲类进程。和应用层关系比较密切的两种调度类是实时类和完全公平调度类,尤其是完全公平调度类。
进程优先级
事实上,除非将Linux用在特定的领域,否则在大部分时间里所有可运行的进程都属于完全公平调度类。从内核代码pick_next_task函数(该函数负责挑选下一个进程放到CPU上执行)中所做的优化可见一斑。Linux是多任务系统,在存在多个可运行进程的情况下,系统不能放任当前进程始终占着CPU。每个进程运行多长时间,是任何一个调度算法都不能回避的问题。传统的调度算法面临着一种困境,那就是时间片到底多大才合适?如果时间片太大,进程执行前需要等待的时间就会变长,当CPU运行队列上可运行进程的个数比较多的时候尤为明显,用户可能会感觉到明显的延迟。如果时间片太短,进程调度的频率就会增加,考虑到上下文切换也需要花费时间,可以想见,大量的时间都浪费到了进程调度上。
完全公平调度,使用了一种动态时间片的算法。它给每个进程分配了使用CPU的时间比例。进程调度设计上,有一个很重要的指标是调度延迟,即保证每一个可运行的进程都至少运行一次的时间间隔。比如调度延迟是20毫秒,如果运行队列上只有2个同等优先级的进程,那么可以允许每个进程执行10毫秒,如果运行队列上是4个同等优先级的进程,那么,每个进程可以运行5毫秒。如果可运行的进程比较少,采用这种算法则没有问题。可是如果运行队列上有200个同等优先级的进程怎么办?每个进程运行0.1毫秒?这可不是个好主意。因为时间片太小,进程调度过于频繁,上下文切换的开销就不能忽视了。为了应对这种情况,完全公平调度提供了另一种控制方法:调度最小粒度。调度最小粒度指的是任一进程所运行的时间长度的基准值。任何一个进程,只要分配到了CPU资源,都至少会执行调度最小粒度的时间,除非进程在执行过程中执行了阻塞型的系统调用或主动让出CPU资源(通过sched_yield调用)。在Linux操作系统中,调度延迟被称为sysctl_sched_latency,记录在/proc/sys/kernel/sched_latency_ns中,而调度最小粒度被称为sysctl_sched_min_granularity,记录在/proc/sys/kernel/sched_min_granularity_ns中,两者的单位都是纳秒。
1 | cat /proc/sys/kernel/sched_latency_ns |
调度延迟和调度最小粒度综合起来看是比较有意思的,它反映了在调度延迟内允许的最大活动进程数目。这个值被称为sched_nr_latency。如果运行队列上可运行状态的进程太多,超出了该值,调度最小粒度和调度延迟两个目标则不可能被同时实现。内核并没有提供参数来指定sched_nr_latency,它的值完全是由调度延迟和调度最小粒度来决定的。计算公式如下:
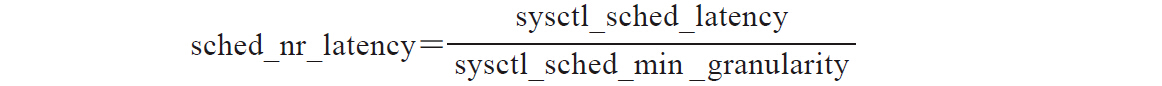
因此调度延迟是一个尽力而为的目标。当可运行的进程个数小于sched_nr_latency的时候,调度周期总是等于调度延迟(sysctl_sched_latency)。但是如果可运行的进程个数超过了sched_nr_latency,系统就会放弃调度延迟的承诺,转而保证调度最小粒度。在这种情况下调度周期等于最小粒度乘以可运行进程的个数,代码如下所示:
1 | static u64 __sched_period(unsigned long nr_running) |
上述函数并不难理解:
- 若运行队列中进程个数小于或等于sched_nr_latency,那么调度周期等于调度延迟。
- 若运行队列中进程个数大于sched_nr_latency,那么调度周期则等于可运行进程个数与调度最小粒度的乘积。
有了调度周期,我们就可以计算,分配给进程的运行时间了:
分配给进程的运行时间=调度周期*1/运行队列上进程个数
到目前为止,所有的讨论都是基于运行队列上所有的进程都有相同的优先级这个假设。但真实情况并非如此,有些任务优先级比较高,理应获得更多的运行时间。考虑到这种情况,完全公平调度又引入了优先级的概念。完全公平调度通过引入调度权重来实现优先级,进程之间按照权重的比例,分配CPU时间。引入权重后,调度周期内分配给进程的运行时间的计算公式如下:
分配给进程的运行时间=调度周期*进程权重/运行队列所有进程权重之和
Linux下每一个进程都有一个nice值,该值的取值范围是[-20,19],其中nice值越高,表示优先级越低。默认的优先级是0。
1 | static const int prio_to_weight[40] = { |
这个数组基本是通过如下公式来获得的:
1 | weight = 1024 / (1.25 ^ nice_value) |
其中普通进程的nice值等于0,其权重为基准的1024。nice值为0的进程权重被称为NICE_0_LOAD。当nice值为1时,权重等于1024/1.25,约等于820,当nice值为2时,权重等于1024/(1.25^2)。
Linux提供了如下函数来获取和修改进程的nice值:
1 |
|
两个系统调用的头两个参数都是which和who,这两个参数用于标识需要读取和修改优先级的进程。who参数如何解释,取决于which参数的值,具体如下:
- PRIO_PROCESS:操作进程ID为who的进程,如果who为0,那么使用调用者的进程ID。
- PRIO_PGRP:操作进程组ID为who的进程组的所有成员。如果who等于0,那么使用调用者的进程组ID。
- PRIO_USER:操作所有真实用户ID为who的进程。如果who等于0,使用调用者的真实用户ID。
getpriority函数返回which和who指定进程的nice值。如果存在多个进程符合指定的标准,那么返回优先级最高的那个nice值(即nice值最小的那个)。因为进程优先级的范围为[-20,19],所以成功的时候,返回值也可能是-1。因此,不能用返回值是不是-1来判断调用是成功还是失败。正确的方法是,调用前将errno设置成0,然后调用getpriority函数。如果返回值是-1,并且errno不是0,才能确定调用失败。否则,调用成功。
1 | errno = 0; |
setpriority函数的返回值并不存在getpriority函数的困境。其成功时返回0,失败时返回-1,并置errno。常见的errno见表

对于其中的EACCESS错误码,这里仔细说明一下。在早期版本的Linux中非特权进程不能提升优先级,只能降低优先级。但在现在的Linux中,非特权进程也能适当地提升进程的优先级了。Linux提供了RLIMIT_NICE资源限制。如果一个进程的RLIMIT_NICE限制为25,那么其nice值可以提升到20-25=-5。详情可以查看getrlimit函数的手册。调整进程的优先级会有什么影响?完全公平调度算法里,优先级比较高(nice值比较低)的进程会获得更多的CPU时间。比如,有两个进程位于CPU的运行队列上,一个nice值是0(权重是1024),另外一个nice值是5(权重是335),按照前面的权重可以推算出,nice值为0的进程获得CPU的时间应该是nice值为5的3倍。可以通过一个简单的测试来验证这个结论:
1 |
|
上面的程序设置了进程的CPU亲和力,父子进程都将运行在CPU 0上,不过,子进程首先调用setpriority函数将自己的nice值设置成了5,而父进程的nice值是默认值0。父子进程都是CPU bound型的程序,始终处于可运行状态。
1 | manu@manu-rush:~$ ps -C nice_test -o pid,ppid,cmd,etime,nice,pri,psr |
通过NI这一列可以看出,父进程的nice值是0,而子进程的nice值是5。父进程占用的CPU时间应该是子进程的三倍左右。通过/proc/PID/sched可以查看这些调度的信息,其中se_sum_exec_runtime的含义是累计运行的物理时间。
1 | se.sum_exec_runtime : 1584276.837760 父进程 |
那么我们比较一下:1024÷335≈3.05671584276.837760÷518296.243156≈3.0567从执行时间上可以看出,执行时间几乎完美地符合权重比。原因就是决定每个进程运行时间片的时候,是根据权重来计算的。有意思的是,如果CPU运行队列上的两个进程的nice值分别是10和15,那么两者占用的CPU时间的比例依然约等于3:1。原因是绝对的nice值并不影响调度决策,而是运行队列上进程间的优先级相对值,影响了CPU时间的分配。
完全公平调度
时间片和虚拟运行时间
在进程优先级都相等的情况下,时间记账是一个非常好的方法,但是优先级的存在,给时间记账带来了一定的麻烦。有些进程优先级比较高,理应获得更多的CPU时间,这种情况下如何进行时间记账?Linux引入了虚拟运行时间来解决这个记账的问题。假设CPU运行队列上有两个进程需要调度,nice值分别为0和5,两者的权重比是3:1,调度周期为20毫秒。那么按照公式,第一个进程应该运行15毫秒,接着第二个进程运行5毫秒。尽管两个进程在调度周期内的实际运行时间不同,但是我们希望第一个进程的15毫秒和第二个进程的5毫秒,时间记账是相等的。即:第一个进程15毫秒的记账值=第二个进程的5毫秒的记账值这样两个进程就能根据时间记账值的大小交替执行了。这种时间加权记账的思想就是完全公平调度的核心了。
Linux内核定义了调度实体结构体,代码如下:
1 | struct sched_entity { |
上述结构中,sum_exec_runtime维护的是真实时间记账信息。而vruntime维护的则是加权过的时间记账,即虚拟运行时间。如何根据真实的时间计算出虚拟的运行时间,作为加权过的时间记账?公式如下。

在该公式中,NICE_0_LOAD的值是nice值为0的进程的权重,即1024。前面的例子中,nice值为0的进程运行了15毫秒,因为其权重为1024,故其虚拟运行时间也为15毫秒;nice值为5的进程运行时间为5毫秒,因为其权重为335,所以记账时其虚拟运行时间为:
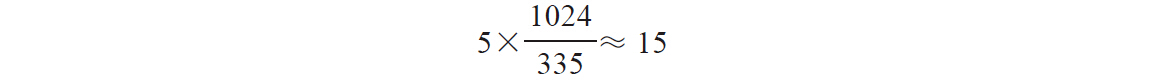
内核的sched_slice函数负责计算进程在本轮调度周期应分得的真实运行时间,其实现代码如下:
1 | static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se) |
在这个函数中,calc_delta_mine函数就是用来计算分配这个调度实体的时间片长度:
1 | //分配给进程的运行时间=调度周期 * 进程权重 / 所有进程权重之和 |
在下一节中可以看到,内核会周期性地检查进程是不是已经耗完了自己的时间片,检查的方法就是判断进程本轮运行时间是否已经超过了sched_slice计算出来的时间片。如果超过,则表示运行时间足够久了,应该发生一次抢占。更新进程虚拟运行时间的逻辑位于内核的__update_curr函数,该函数里更新了当前进程的真实运行时间和虚拟运行时间,同时也更新了CFS运行队列的最小虚拟运行时间。
1 | static inline void |
运行队列上存在多个进程,随着时间的流逝,每个进程的虚拟时间各不相同,内核会将所有进程中虚拟运行时间的最小值记录到运行队列的最小虚拟运行时间(vruntime)中。当然运行队列的最小虚拟运行时间是奔流向前的,只会单调增大,绝不会减小。为什么要维护这个值?CFS算法可确保队列上的所有进程步调一致地轮流运行,虚拟运行时间不断增大,大部分进程的虚拟运行时间相差也不会太远。但是记录下队列虚拟运行时间的最小值仍然是有意义的。比如新加入一个进程,应该给它的虚拟运行时间赋初始值,初始值应是多少?再比如进程陷入了漫长的休眠,醒来时已经沧海桑田,相对其他进程,它的虚拟运行时间已经大幅落后。内核应该将该进程的虚拟运行时间调整成何值?又比如内核不得不将某个进程从一个CPU的运行队列拉到另一个CPU的运行队列中,该进程的虚拟运行时间该如何调整?此时,维护运行队列的最小虚拟运行时间的意义就彰显出来了。运行队列的最小虚拟运行时间给了我们一个基准,根据这个基准值可以知道,该CPU运行队列上的大部分进程的虚拟运行时间就在该值附近,且大于该值。在后面分析新创建的进程和唤醒休眠进程时,会分析内核如何调整这些进程的虚拟运行时间。
进程有了虚拟运行时间,完全公平调度器挑选下一个运行程序时就变得非常简单了,只需要挑选具有最小虚拟运行时间(vruntime)的进程投入运行即可。这就是完全公平调度算法的核心所在。内核为了加速挑选具有最小虚拟运行时间的进程,使用了红黑树数据结构。运行队列上的所有调度实体都是红黑树的节点。红黑树是平衡二叉树的一种,调度实体的虚拟运行时间是红黑树的键值。虚拟运行时间最小的调度实体,位于红黑树的最左端。因此挑选下一个运行程序,就简化成了从红黑树上取出最左端的节点。
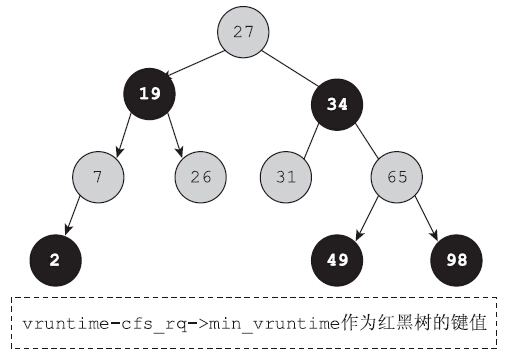
维护进程的虚拟运行时间就成了调度算法的关键。问题是何时会更新进程的虚拟运行时间呢?可以查看内核代码中所有调用update_curr的函数。内核会周期性地更新进程的虚拟运行时间,也会在某些合适的时间点调用update_curr更新。我们暂时强忍好奇,继续探索。在探索的过程中,会多次遇到调用update_curr的函数。
周期性调度任务
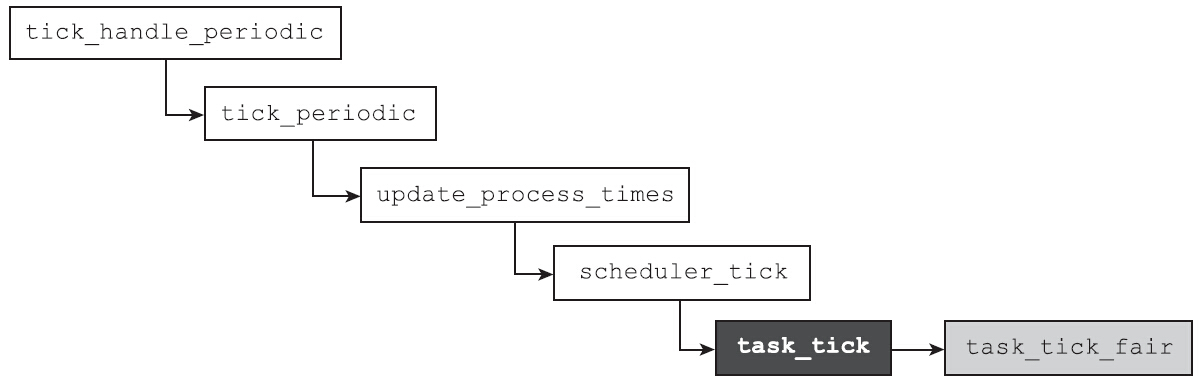
周期性调度任务是调度框架中很重要的一个部分。因为Linux是抢占式多任务,系统需要周期性地检查,当前运行的进程是不是已经耗尽了它的时间片,是不是应该发起一次抢占了。这就是周期性调度任务的职责。当时钟发生中断时,首先调用的是tick_handle_peroid函数。该函数会调用scheduler_tick函数,而scheduler_tick函数是进程调度框架中的重要函数,负责处理进程调度相关的周期性任务。
在scheduler_tick函数中一个非常重要的调用是:
1 | curr->sched_class->task_tick(rq, curr, 0); |
在Linux的实现中调度器采用了模块化的实现,任何一个调度类,都要实现task_tick这个函数。那这个task_tick函数要完成哪些使命呢?主要的工作是更新当前运行进程调度相关的统计信息,以及判断是否需要发生调度。对于完全公平的调度而言,task_tick函数为:
1 | .task_tick = task_tick_fair, |
在我们探索的第一站就遇到了更新updat_curr的地方。时钟中断触发了周期性的调度任务,其中一项重要的任务就是通过updat_curr函数更新调度的统计信息。它随着时钟中断处理函数周期性地执行,更新进程的虚拟运行时间、真实运行时间和运行队列的最小虚拟运行时间等。内核需要知道在什么时候调用schedule函数,而不能仅仅依靠用户程序显式地调用schedule函数。如果将schedule函数的发起完全委托给用户程序,那么用户程序可能会无止尽地执行下去,而导致其他进程饿死。内核提供了一个need_resched标志位来表明是否需要重新执行一次调度。很明显,伴随着时钟中断发生的周期性调度任务是一个非常好的时机来判断当前进程是否应该被抢占(另一个时机是进程从睡眠状态醒来时,try_to_wake_up函数也会判断是否需要设置need_resched标志位来抢占当前的进程)。当运行队列上处于可运行状态的进程不止一个时,内核会调用check_preempt_tick函数来检查是否应该发生抢占。该函数确保了当前进程使用完自己的时间片后,可以及时地让出CPU,代码如下:
1 | static void |
在check_preempt_tick中可以看出,进程有自己的完美运行时间,即本轮调度周期应得的时间片。如果本轮执行时间已经超出了时间片,就会执行resched_task函数,在该函数中会通过set_tsk_need_resched函数来设置need_resched标志位,告诉内核请尽快调用schedule函数。如果进程的本轮运行时间小于调度最小粒度,那么不允许发生抢占。resched_task函数仅仅是设置标志位,并没有真正地执行进程切换。进程调度发生的时机之一是发生在中断返回时,check_preempt_tick函数是scheduler_tick函数的一部分,而scheduler_tick函数是中断处理程序的一部分。执行完中断处理,会检查need_resched标志位是否置位,如果置位,那就自然会调用schedule函数来执行切换。
新进程的加入
首先分析一下sched_fork的内核代码:
1 | void sched_fork(struct task_struct *p) |
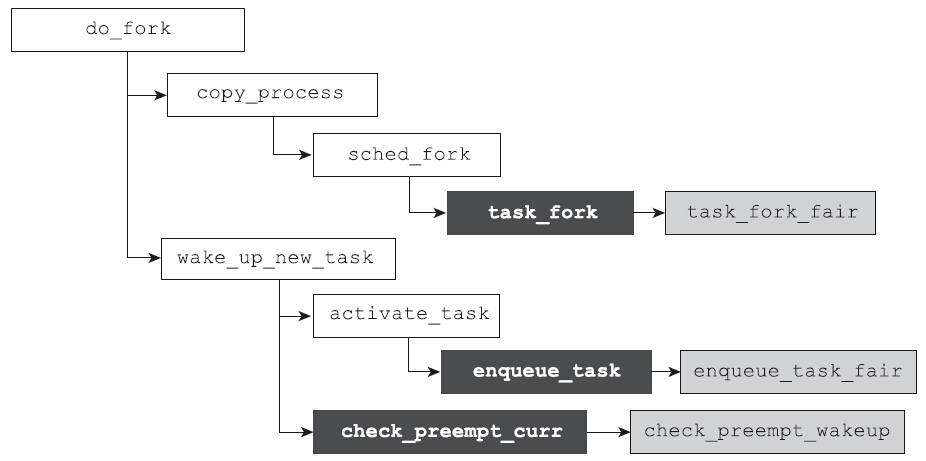
sched_fork函数的主要工作是初始化进程的与调度相关的变量,确定进程所属的调度类及优先级设置。根据进程所属的调度类,执行与调度类相关的函数。调度类需要实现task_fork这个hook函数。该函数用于处理与新创建的进程相关的初始化事宜。对于完全公平调度类,该函数的实现为:
1 | .task_fork = task_fork_fair, |
新创建进程的虚拟运行时间初始值
1 | if (curr) |
从上面的函数中可以看出,新创建子进程的虚拟运行时间首先被初始化成父进程的虚拟运行时间,接下来会调用了place_entity函数,而place_entity函数会调整新创建进程的虚拟运行时间。“place_entity”,直白的翻译就是放置调度实体的意思,即把调度实体放置到合适的位置。如何才能决定调度实体的位置呢?毫无疑问,只能通过调整调度实体的虚拟运行时间来实现。place_entity函数用来处理两种比较特殊的情况:
- 调整新创建进程的虚拟运行时间。
- 调整从休眠中唤醒进程的虚拟运行时间。
这两种情况根据该函数的第三个参数initial来区分。initial等于1则表示调整新创建进程的虚拟运行时间。下面来看看place_entity函数是如何调整新创建进程的虚拟运行时间的,代码如下:
1 | static void |
完全公平调度类的运行队列cfs_rq中维护有成员变量min_vruntime,该变量存放的是此运行队列中的最小虚拟运行时间。就像前面所说的,它提供了一个基准值,通过它我们无须遍历队列上所有进程的虚拟运行时间,就可以得知该运行队列的整体情况了。大多数进程的虚拟值在该值附近,且略大于该值。内核提供了很多调度的特性,记录在/sys/kernel/debug/sched_features中,如下所示:
1 | cat /sys/kernel/debug/sched_features |
其中START_DEBIT特性是用来给新创建的进程略加惩罚的。如果没有START_DEBIT选项,子进程的虚拟运行时间为:
1 | max(父进程的虚拟运行时间,CFS运行队列的最小运行时间) |
这个值通常比较小,这就意味着子进程很快就能获得调度的机会,因此也就给了恶意进程可乘之机。因为恶意进程可以通过不停地fork来获得更多的CPU时间。如果设置了START_DEBIT选项,会通过增大子进程的虚拟运行时间来惩罚新创建的进程,使新创建的进程晚一点才能获得被调度的机会。那么虚拟运行时间增大多少呢?看看下面的语句:
1 | vruntime += sched_vslice(cfs_rq, se); |
前面介绍过sched_slice函数是用来计算进程的时间片的,那么sched_vslice函数又是何意呢?
1 | static u64 sched_vslice(struct cfs_rq *cfs_rq, struct sched_entity *se) |
sched_vslice函数是根据时间片的值,来计算对应的虚拟时间片的值。即根据进程的优先级来调整。调整的算法前面已经提到过了。打开了START_DEBIT特性,子进程的虚拟运行时间就会被初始化成:
1 | max(父进程的虚拟运行时间,CFS运行队列的最小运行时间+进程虚拟时间片) |
父子进程谁先执行
task_fork_fair函数中有以下代码:
1 | if (sysctl_sched_child_runs_first && curr && entity_before(curr, se)) { |
如果要设置子进程优先获得调度,则会通过entity_before函数来比较父子进程的vruntime,如果父进程的vruntime小,则需要和子进程互换vruntime以确保子进程优先获得调度。
继续分析task_fork_fair函数。在该函数中有一条语句非常奇怪,该语句代码如下:
1 | se->vruntime -= cfs_rq->min_vruntime; |
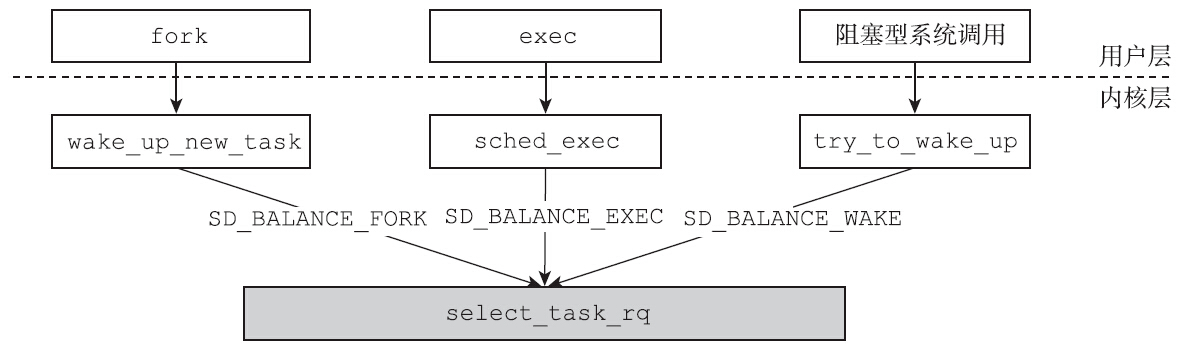
为何要减掉运行队列的最小虚拟运行时间?继续向下看就可以恍然大悟了。因为在do_fork的末尾会调用wake_up_new_task函数。事实上在对称多处理器结构上,新创建的进程和父进程不一定在同一个CPU上运行。进程刚刚创建好,尚未运行,这是多个CPU之间负载均衡的一个良机。Linux也是这么做的,在wake_up_new_task函数中会首先调用如下语句,选择一个合适的CPU:
1 | set_task_cpu(p, select_task_rq(p, SD_BALANCE_FORK, 0)); |
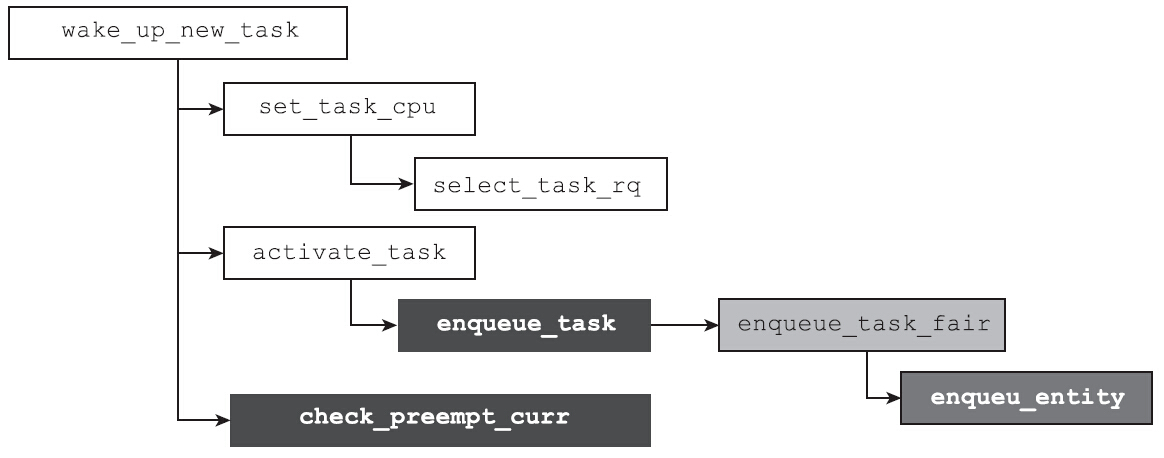
很不幸的是,不同的CPU之间负载并不完全相同,有的CPU更忙一些,而且每个CPU都有自己的运行队列cfs_rq,不同的CPU运行队列的最小虚拟运行时间min_vruntime并不相同。如果新创建的进程从一个CPU的运行队列迁移到另外一个CPU的运行队列,就可能会产生问题。比如新创建的进程从min_vruntime小的CPU A跳到min_vruntime非常大的CPU B,它就会占便宜,因为它的虚拟运行时间会在相当长的时间范围内都是最小的,从而产生调度的不公平。解决的方法非常简单:
迁移前:进程的虚拟运行时间–= 迁移前所在CPU运行队列的最小虚拟运行时间
迁移后:进程的虚拟运行时间 += 迁移后所在CPU 运行队列的最小虚拟运行时间
enqueue_task也是调度类的hook函数,每一个调度类都要实现该函数,对于完全公平的调度而言:
1 | .enqueue_task = enqueue_task_fair, |
事实上该解决方案不仅仅只是用于新创建的进程这一个场景。Linux支持CPU之间的负载均衡,可以将进程从一个CPU迁移到另外一个CPU,为了防止不公平的产生,也采用了上述的解决方案。
1 | static void |
睡眠进程醒来
如何对待睡眠进程也是调度器需要解决的问题。因为交互型的进程会不断陷入休眠状态中,并等待用户的输入。虽然这类进程对CPU的整体消耗并不大,但是要求响应必须及时,否则用户会感觉到系统卡顿,用户体验就会很糟糕。
对CFS之前的O(1)调度器来说,交互型进程堪称其阿喀琉斯之踵。该调度算法的交互进程识别启发式算法异常复杂,该启发式算法融入了睡眠时间作为考量的标准,但是对于一些特殊的情况,经常判断不准,而且经常是改完一种情况又发现另一种特殊情况。CFS调度算法并没有刻意地区分交互型进程和批处理型进程,依然漂亮地满足了交互型进程需要及时响应的需求。CFS算法是如何做到的呢,对于从休眠中醒来的进程,CFS进行了哪些处理呢?
当进程被内核唤醒时,内核通常会执行try_to_wake_up函数。概括地讲,try_to_wake_up函数的职责是:
- 把从休眠中醒来的进程放到合适的运行队列。
- 将进程的状态设置为
TASK_RUN-NING。 - 判断醒来的进程是否应该抢占当前正在运行的进程,如果是,则设置
need_resched标志位。
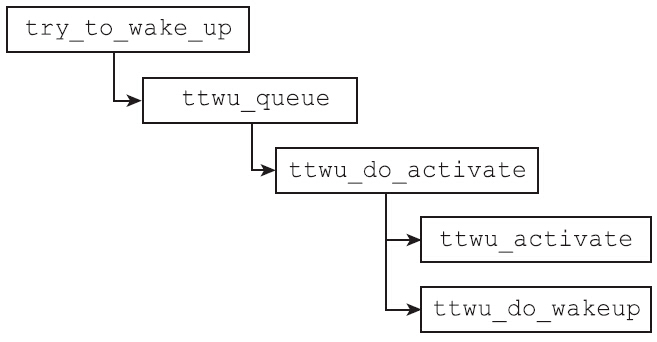
前面提到的try_to_wake_up负责的三件事,分别由以下函数负责完成。

1 | static void ttwu_activate(struct rq *rq, struct task_struct *p, int en_flags) |

activate_task函数和deactivate_task函数一样,都是调度框架内的重要函数,并且两者是一对,就好像wake_up和wait_event是一对一样。当进程调用wait_event时,进程从可运行状态变成睡眠状态,因此需要通过deactivate_task函数将进程从运行队列中移除,与此对应的,当内核调用wake_up函数把进程从休眠状态唤醒时,内核需要通过activate_task函数将进程放入运行队列中。
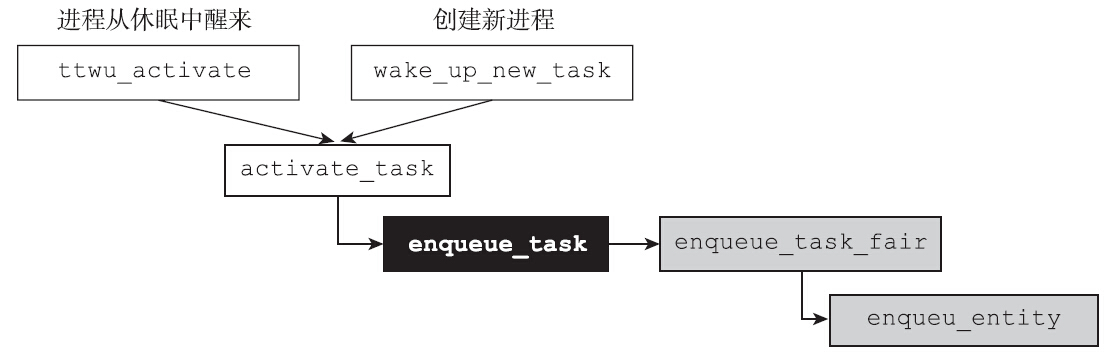
其中enqueue_task函数是调度类的hook函数,每个调度类都需要实现该函数。其含义顾名思义,即将进程放入运行队列。对于完全公平调度类而言,该函数指针指向的是enqueue_task_fair。
enqueue_task_fair很大部分的工作是更新调度相关的统计,其中有一支代码路径非常有意思。这条路径之所以很重要,是因为它决定了休眠进程醒来后的虚拟运行时间。
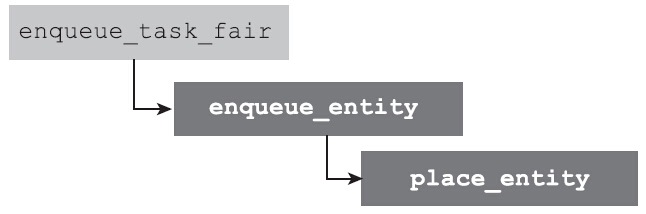
休眠进程的虚拟运行时间会保持不变吗?答案是否定的。很多进程可能会长时间地休眠,在这个过程中,如果虚拟运行时间vruntime保持不变,一旦该进程醒来,它的vruntime就会比运行队列上的其他进程小很多,因为会长时间保持调度的优势。这显然是不合理的。对于这种情况,完全公平调度的做法是,以运行队列的min_vruntime为基础,给予一定的补偿。补偿多少?这就又要去看看我们的老朋友place_entity函数了。在创建新进程时,曾经走到过该函数,那时该函数负责决定新进程的虚拟运行时间。下面来看看对于被唤醒的休眠进程,该函数是如何决定进程的虚拟运行时间的:
1 | static void |
当initial等于0时,表示正在处理从休眠中醒来的进程。如果没有设置GENTLE_FAIR_SLEEPERS特性,那么在队列最小虚拟运行时间的基础上,补偿1个调度延迟,如果设置了GENTLE_FAIR_SLEEPERS,那么补偿减半,即补偿半个调度延迟。默认情况下,GENTLE_FAIR_SLEEPER的特性是打开的。但休眠进程醒来后的虚拟运行时间并非只是简单粗暴地设置成队列的最小运行时间减掉补偿值。影响因素还有进程原本的虚拟运行时间,如下所示:
1 | vruntime = max_vruntime(se->vruntime, vruntime); |
如果休眠进程的睡眠时间非常短,很有可能进程原本的虚拟运行时间要大于上述计算得到的值,此时,休眠进程的虚拟运行时间不变,即为睡眠前的值。如果休眠进程的睡眠时间特别久,醒来时已经沧海桑田,那么就将虚拟运行时间设置为所在运行队列的最小虚拟运行时间减去补偿量。从上面的代码可以看出,从长时间休眠中醒来的进程,因为其虚拟运行时间较小(比队列的最小虚拟运行时间还小),所以会获得优先的调度,从而使交互型进程得到及时的响应。
这种对休眠进程进行奖励的做法,在进程调度设计领域存在一定的争议。内核进程调度领域的大牛Con Kolivas就坚持认为,调度器只需要向前看,而不应该考虑一个进程的过去。在早期的CFS调度算法(版本2.6.23)中,CFS会负责记录进程的sleep time,2.6.24版本之后的内核,就不再考虑进程过去的睡眠时间了。但是CFS做得并不彻底,在place_entity函数中,对休眠进程进行了补偿。在CFS早期的版本中,sleeper fairness的特性会导致在一些情况下出现严重的调度延迟。在Jens Axboe的测试中,甚至会出现10秒的延迟,也有客户报告在编译内核时,音频视频会有严重的停顿。上面代码中的GENTLE_FAIR_SLEEPER特性就是作者Ingo给出的Patch,这个特性解决了10秒的延迟和其他鼠标滞后、视频停顿等交互性的问题。
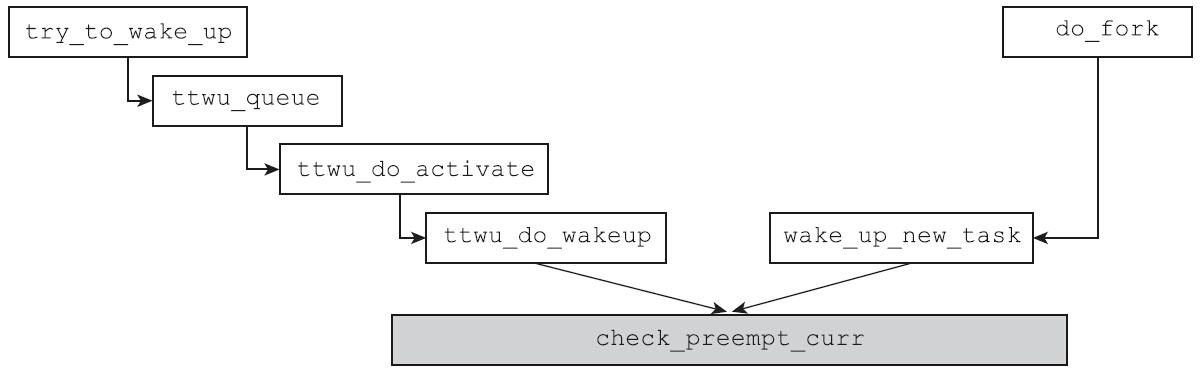
唤醒抢占
无论是try_to_wake_up唤醒睡眠的进程还是wake_up_new_task唤醒新创建的进程,内核都会使用check_preempt_curr函数来检查新唤醒的进程或新创建进程是否可以抢占当前运行的进程
1 | static void check_preempt_curr(struct rq *rq, struct task_struct *p, int flags) |
判断能否发生抢占的逻辑异常简单,也是符合正常人思维的:
- 如果候选进程和正在运行的进程属于同一个调度类,那么调度类内部提供方法解决。
- 如果候选进程和正在运行的进程属于不同的调度类,候选进程所属调度类的优先级高于正在运行进程的调度类的优先级,则可以抢占,否则不可以。
注意新唤醒的进程不一定是普通进程,也可能是实时进程。如果唤醒的进程是实时进程而当前运行的进程为普通进程,则会设置need_resched标志位,因为实时进程总是会抢占CFS调度域的普通进程。每一种调度类都应该实现自己的check_preempt_curr函数来判断是否需要发生抢占,对于完全公平调度类,check_preempt_curr的实现为check_preempt_wakeup函数。
如果被唤醒的进程的睡眠时间非常久(上百毫秒、几百毫秒、几秒甚至更久),前面的place_entity函数会将睡眠进程的虚拟运行时间设置为队列的最小虚拟运行时间减掉补偿的半个调度周期,这会使睡眠进程的虚拟运行时间非常的小,醒来时几乎总是会抢占当前的进程,这种行为也是期待的行为,因为它可以保证交互型进程的响应时间。但是也有很多进程的睡眠时间非常短暂(比如只有几毫秒甚至更短),醒来之后通过place_entity函数计算得出的虚拟运行时间值仍然是自己本来的虚拟运行时间值。如果仅仅比较醒来的进程和当前运行进程的虚拟运行时间来决定是否抢占,那么很可能会使得抢占过于频繁。因此Linux引入了唤醒抢占粒度sched_wakeup_granularity_ns,可以通过如下方法来查看系统的唤醒抢占粒度sched_wakeup_granularity_ns的值:
1 | cat /proc/sys/kernel/sched_wakeup_granularity_ns |
引入该最小粒度后,唤醒进程抢占当前进程的条件是:只有当唤醒进程的vruntime小,并且两者的差值vdiff大于sched_wakeup_granularity_ns时,才能抢占。具体的算法实现如下:
1 | static int |
如果系统的唤醒抢占太过频繁,大量的上下文切换会影响系统的整体性能。这种情况下可以通过调整sched_wakeup_granularity_ns的值来解决,sched_wakeup_granularity_ns的值越大,发生唤醒抢占就越不容易。注意sched_wakeup_granularity_ns的值不要超过调度周期sched_latency_ns的一半,否则的话,就相当于禁止唤醒抢占了。
普通进程的组调度
完全公平调度算法会尽力在进程之间保证公平。如果有50个优先级相同的进程,CFS会努力让每个进程获得的CPU时间为2%,以确保公平。
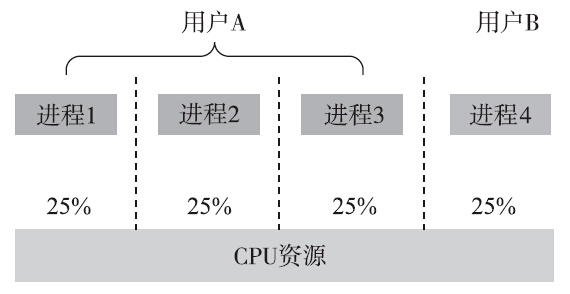
考虑上图情景,表面看每个进程都被进程调度器公平对待了,即4个进程每个都获得了25%的CPU时间。但是其中的用户B并没有得到公平的对待。我们将情况考虑得再极端一点:系统上存在50个进程,其中49个都属于用户A,而用户B只有1个进程。那么对于用户B而言,它只能使用2%的CPU资源,这显然是不公平的。

比较合理的做法是,首先确保组间的公平,然后才是组内进程之间的公平。
Linux内核实现了cgroups(control groups的缩写)功能,该功能用来限制、记录和隔离一个进程组群所使用的物理资源(如CPU、内存、磁盘IO、网络等)。为了管理不同的资源,cgroups提供了一系列子系统,本节将要介绍的cpu和后面CPU亲和力一节介绍的cpuset都属于cgroups的子系统。cpu子系统只用于限制进程的CPU使用率。
实时进程
对于普通进程来说,完全公平调度已经能够提供足够好的性能和响应体验了。但是某些进程对实时性的要求更高。严格说来实时系统可以分成两类:硬实时进程和软实时进程。硬实时进程对响应时间的要求非常严格,必须保证在一定的时间内完成,超过时间限制就会失败,而且后果非常严重。这类应用典型的例子有军用武器系统、航空航天系统、交通导航系统、医疗设备等。硬实时的关键特征是任务必须在可保证的时间范围内得到处理。当然这并不意味所要求的时间范围特别短,而是系统必须保证绝不会超过某一时间范围,无论当时系统的负载如何。主流内核的Linux并不支持硬实时进程,当然有些修改版本提供了该特性。软实时进程是硬实时的一种弱化形式。尽管软实时进程仍然需要快速响应和要在规定的时间内完成,但是超过了时间的范围也不会有什么灾难性的后果。比较典型的例子是视频处理应用,如果超过了操作时限,则会影响用户体验,但是少量的丢帧还是可以忍受的。
实时调度策略和优先级
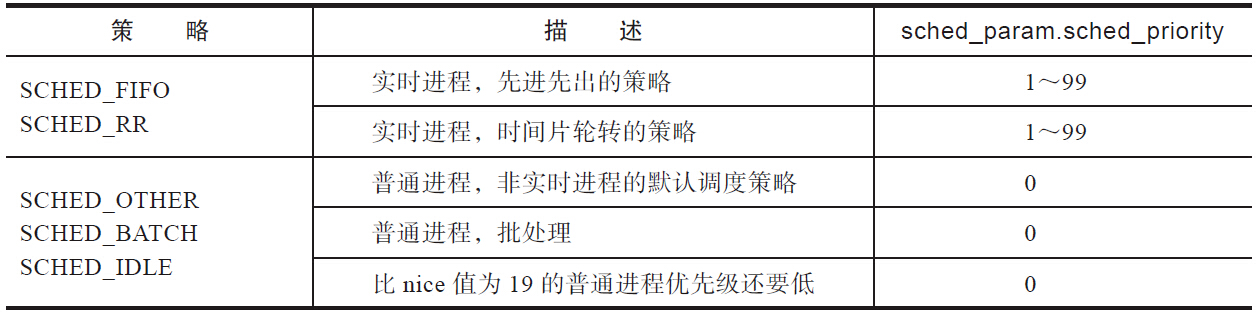
Linux提供了两种实时调度的策略:先进先出(SCHED_FIFO)策略和时间片轮转(SCHED_RR)策略。无论进程使用哪种实时策略,其优先级都会高于前面介绍的采用完全公平调度的普通进程。实时进程也有一个优先级的范围。SUSv3要求至少要为实时策略实现32个离散的优先级。Linux中为实时进程提供了99个实时优先级。从内核层面看,从0到99范围内的优先级属于实时调度范围,从100到139共40个等级属于前面讨论过的完全公平调度的优先级。其中创建普通进程的时候,其优先级的值为完全公平调度中的中间值120。从整体来看,优先级的值越低,其优先级就越高。事实上每个CPU都有实时运行队列。根据99种离散的优先级可知,共有99个队列。具有相同优先级的实时进程都保存在一个队列之中。这使得在实时调度类中选择下一个运行的进程也就比较简单了,按照优先级从高到低的顺序,选择存在可运行进程的最高优先级队列中的第一个进程即可。事实上内核中还维护有位图来表征哪个优先级的运行队列有可运行的进程,相关结构体定义如下:
1 | struct rt_prio_array { |
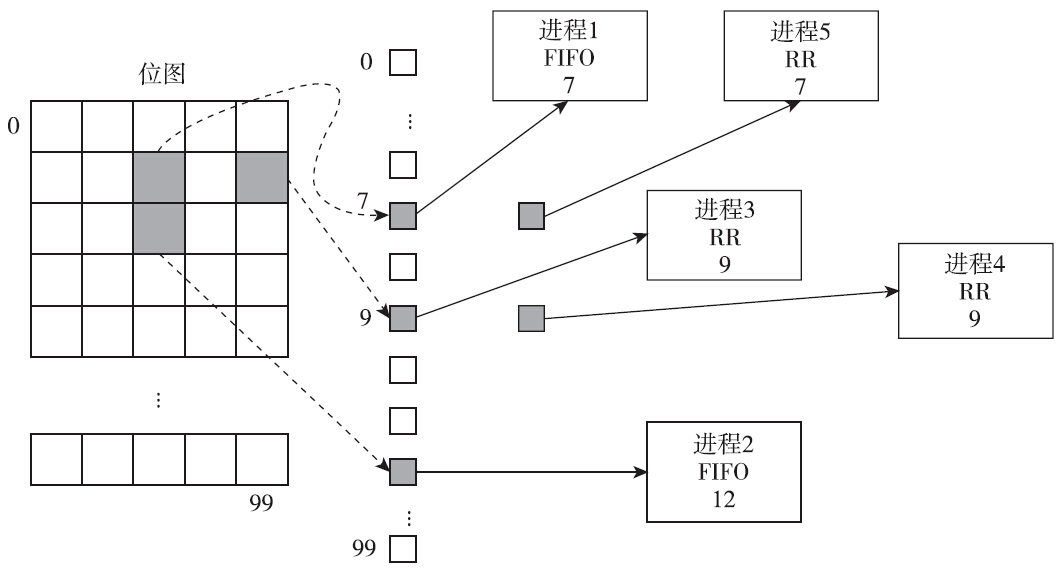
对于实时进程而言,内核态的优先级和用户进程通过sched_setscheduler或sched_setparam系统调用设置的优先级并不相同:对于内核态而言,优先级的值越小,优先级就越高,而用户进程通过系统调用设置的优先级正好相反,优先级的值越大,优先级越高。
两者的换算关系是:内核态优先级=MAX_RT_PRIO-1-用户态优先级
其中MAX_RT_PRIO的值为100。
SCHED_FIFO策略
SCHED_FIFO策略是一种比较简单的策略,即先进先出,它没有时间片的概念,只要没有更高优先级的进程就绪,使用该调度策略的进程就会一直执行。一旦一个调度策略为SCHED_FIFO的进程获得了CPU控制权,它就会始终占有CPU资源直到下面的某种情况发生:
- 自动放弃CPU资源,如执行了一个阻塞型的系统调用或调用了sched_yield系统调用,进程不再处于可执行状态。
- 进程终止了。
- 被一个优先级更高的进程抢占。
如果FIFO类型的进程通过sched_yield系统调用主动让出了CPU,那么内核会将该进程放到对应队列的尾部;如果进程被更高优先级的进程抢占,那么该进程在队列中的位置不变,一旦高优先级的进程停止执行,被抢占的FIFO类型的进程会继续执行。
SCHED_RR策略
在时间片轮转的策略中,具有相同优先级的进程轮流执行,进程每次使用CPU的时间为一个固定长度的时间片。使用SCHED_RR策略的实施进程一旦被调度器选中,就会一直占有CPU资源,直到下面的某种情况发生:
- 时间片耗尽。
- 进程自动放弃CPU:或者执行了阻塞式的系统调用,或者主动执行sched_yield函数让出CPU资源。
- 进程终止了。
- 被更高优先级的进程抢占。
前两种情况下,SCHED_RR策略的进程会被放到其优先级运行队列的队尾。最后一种情况下,被抢占的SCHED_RR策略的实施进程仍然位于其运行队列的头部,在更高优先级的进程运行结束后,被抢占的进程会继续执行,直到其时间片的剩余部分耗光为止。在时间片轮转策略中,时间片的长度是一个关键的参数。POSIX定义了接口来查询SCHED_RR策略的时间片长度:
1 |
|
默认情况下,SCHED_RR类型进程的时间片总是100毫秒。如果内核版本不低于3.9,时间片的大小可以通过调整/proc/sys/kernel/sched_rr_timeslice_ms的值来调整。伴随着时钟中断处理程序,scheduler_tick函数会根据当前进程的调度类执行对应的task_tick函数,如下所示:
1 | curr->sched_class->task_tick(rq, curr, 0); |
从上面的代码不难看出,采用SCHED_RR调度策略的实时进程,时间片大小为时钟滴答的整数倍。如果系统CONFIG_HZ为250,那么每4毫秒一个时钟滴答,即时间片大小总是4毫秒的整数倍。
SCHED_OTHER策略
SCHED_OTHER策略不属于实时调度的范畴。SCHED_OTHER和下面要讨论的SCHED_BATCH、SCHED_IDLE策略同属于完全公平调度的范畴。事实上,我们遇到的大多数进程都是属于SCHED_OTHER的调度策略。前面讨论的是nice值在-20~19范围内的进程,都是属于SCHED_OTHER的调度策略。在这种调度策略下,不同的nice值,意味着不同的时间片权重。优先级越高的普通进程,将获得越多的CPU时间。
SCHED_BATCH策略
尽管可以通过POSIX实时调度的API设置进程的策略为SCHED_BATCH,但是SCHED_BATCH策略并不属于实时调度的策略。SCHED_BATCH策略是在Linux 2.6.16的内核中加入的。最初引入这个策略的目的是告知内核,指定这个策略的进程并非交互型的进程,不需要根据休眠时间更改优先级。这个策略主要用于早期的O(1)调度器,对于完全公平的调度,SCHED_BATCH策略和SCHED_OTHER策略几乎一样。
SCHED_IDLE策略
SCHED_IDLE策略也隶属于完全公平调度的范畴。采取SCHED_IDLE调度策略的进程拥有非常低的优先级,比nice值为19的进程的优先级还要低(nice值是19的进程,其权重是15,采用SCHED_IDLE调度策略的进程其权重是3)。一般来说,该策略用于运行优先级非常低的进程,通常在系统中没有其他任务需要使用CPU时这些任务才会运行。
完全公平调度类中负责检查是否应该唤醒抢占的check_preempt_wakeup函数中有如下的语句:
1 | if (unlikely(curr->policy == SCHED_IDLE) && |
这段代码表明,在CFS调度域内,如果醒来的候选进程采用的不是SCHED_IDLE策略,而当前运行的进程采用的调度策略是SCHED_IDLE,那么抢占总是会发生。
实时调度相关API
Linux下可以通过sched_setscheduler函数来修改进程的调度策略及优先级,其接口定义如下:
1 |
|
该接口用于修改pid对应进程的调度策略和优先级。当pid等于0时,修改函数调用进程的调度策略和优先级。策略和优先级的有效值如表
sched_setscheduler函数调用成功时返回0,失败时返回-1,并设置errno。设置进程调度策略和优先级的方法如下面的代码所示。下面的代码将进程的调度策略设置成了SCHED_RR,并且其优先级为99,即实时进程中的最低优先级。
1 | struct sched_param sp = { .sched_priority = 99 }; |
通过fork创建的子进程会保持父进程的调度策略和优先级。有些时候,不希望子进程继承父进程的调度策略和优先级,尤其是父进程是实时进程或nice值是负值的时候。Linux自2.6.32版本开始,提供了SCHED_RESET_ON_FORK选项,一旦设置了该选项,子进程就不会继承父进程的调度策略或nice值了。可通过如下代码设置该标志位:
1 | ret = sched_setscheduler(0, SCHED_RR |SCHED_RESET_ON_FORK, &sp); |
- 如果调用进程的调度策略是SCHED_FIFO或SCHED_RR,那么将fork创建出来的子进程调度策略重设成SCHED_OTHER。
- 如果调用进程的nice值是负值,那么将fork创建出来的进程的nice值重新设置成0。
如何查看进程的调度策略及调度参数?可使用如下语句:
1 | int sched_getscheduler(pid_t pid); |
除了ps命令外,util-linux包中提供了chrt工具,可以查看和修改进程的调度策略和优先级。
查看进程的调度策略和优先级的方法如下:
1 | manu@manu-rush:~$ chrt -p 7125 |
修改进程的调度策略和优先级的方法如下:
1 | /*7135进程最初是普通进程,调度策略为SCHED_OTHER*/ |
限制实时进程运行时间
实时进程的优先级高于普通进程,如果实时进程处于可执行的状态,那么普通进程无法获得CPU资源。如果使用实时调度策略的进程出现了bug,始终处于可运行的状态,系统将不会调度其他普通进程。这种情况是非常危险的,系统很可能会失去控制,而用户甚至超级用户也无能为力。为了防止出现这种情况,系统做了改进,纵然始终存在可以运行的实时进程,仍然允许普通进程获得一定的CPU时间。系统提供了控制选项来控制单位时间内最多分配多少CPU时间给实时进程。在Linux中,这两个控制参数为:
1 | sysctl -n kernel.sched_rt_period_us |
这两个参数的含义是在以sched_rt_period_us为一个周期的时间内,所有实时进程运行的时间总和不超过sched_rt_runtime_us。这两个配置项的默认值为1秒和0.95秒,表示每秒钟为一个周期,所有实时进程运行的总时间不超过0.95秒,剩下的0.05秒留给普通进程。有了这个机制,哪怕始终有实时进程处于TASK_RUNNING状态,普通进程也能获得运行的机会。如果在一个周期的时间内,实时进程对CPU的需求不足0.95秒,那么剩余的时间都会分配给普通的进程。而如果实时进程对CPU的需求大于0.95秒,它也只能够运行0.95秒,剩下的0.05秒留给其他普通进程。但是如果0.05秒内并没有任何普通进程处于可运行状态,实时进程能否运行超过0.95秒吗?答案还是不能,内核宁可让CPU闲着,也不给实时进程使用。
但是前面讨论的场景都是单CPU的场景,如果存在N个CPU,那么所有CPU上的所有实时进程占有CPU的上限应该为N*sched_rt_runtime_us/sched_rt_period_us。有的CPU上实时进程对CPU的需求超过sched_rt_runtime_us,而有的CPU上实时进程对CPU的需求不足sched_rt_runtime_us,因此内核允许CPU之间互相拆借。若实时进程在CPU上占用的时间超过了sched_rt_runtime_us,则该实时进程会尝试去其他CPU上借时间,将其他CPU剩余的时间借过来。这样做的好处是避免了进程在CPU之间迁移导致的上下文切换、缓存失效等开销。这部分逻辑出现在kernel/sched_rt.c中的sched_rt_runtime_exceeded函数,该函数会通过balance_runtime函数向其他CPU借用时间
事实上,实时进程也支持组调度,可以控制一组实时进程(task_group)占用的CPU时间,将CPU占用的管理分配得更加细致。
CPU的亲和力
在对称多处理器(SMP)环境中,一个进程被重新调度时,不一定是在上次执行的CPU上运行。同一个进程在不同CPU之间迁移会带来性能的损失,损失的主要原因在于缓存。在进程迁移到新的处理器上后写入新数据到内存时,原有处理器的缓存就过期了。当进程在不同处理器之间迁移时,会带来两方面的性能损失:
- 进程不能访问老的缓存数据;
- 原处理器中缓存中的数据必须标记为无效。
如何查看进程当前运行在哪个CPU上?可以通过ps命令的PSR字段来查看进程当前执行或上一次执行时所在的CPU编号。因为进程调度并不保证进程总是固定在某个CPU上,所以多次查看进程的PSR,其值可能会发生变化。
1 | root@manu-rush:~ |
有时候需要把进程绑定到某个或某几个CPU上运行。这就需要设置进程的CPU硬亲和力了。Linux提供了非标准的系统调用来获取和修改进程的硬亲和力:即sched_setaffinity函数和sched_getaffinity函数。sched_setaffinity函数用来设置pid指定进程的CPU亲和力,如果pid的值为0,那么该函数用来修改调用进程的CPU亲和力。函数接口定义如下:
1 |
|
调用sched_getaffinity之前,需要先调用CPU_ZERO将set清空。函数调用成功时,会将结果记录在set中,但是不要直接操作set来判断哪些CPU在集合中,而是应该用CPU_ISSET来判断。内核如何保证进程只会在某些CPU上执行?内核中的进程对应的进程描述符中有个cpumask_t类型的成员变量cpus_allowed,该成员变量会记住进程允许的CPU。内核在调度的时候会通过select_task_rq来选择CPU,只会选择出允许的CPU。
1 | static inline |
有个很有意思的话题是内核调用select_task_rq的时机:当新的进程创建出来时,当进程调用exec时,当进程从睡眠中醒来时,都是调用select_task_rq的好时机。可以通过这些时机来实现各个CPU之间的负载均衡。
除了编程接口可以获取和修改进程的亲和力以外,Linux的util-linux包中还提供了tasket工具以命令行的方式做同样的事情。它查询进程的CPU亲和力的方法如下:
1 | manu@manu-rush:~$ taskset -p 1 |
标准库
在 Linux 和类 Unix 系统中,pid_t 是一个用于表示进程 ID 的数据类型。它通常是一个有符号整数类型,用于标识系统中的进程。以下是关于 pid_t 类型以及相关函数 getpid() 和 getppid() 的详细信息:
相关数据结构
pid_t 类型
pid_t是一个数据类型,用于表示进程 ID。它通常定义在头文件<sys/types.h>中。一般为int类型。- 进程 ID 是一个唯一的整数,用于标识系统中的每个进程。
获取 ID
在 Linux 系统编程中,getpid、getppid、getpgid 和 getsid 等函数用于获取与进程相关的标识符。这些函数对于进程管理和控制非常重要。下面是对这些函数的详细介绍:
getpid
功能
获取调用进程的进程 ID。
原型
1 |
|
返回值
- 返回调用进程的进程 ID。
使用示例
1 |
|
getppid
功能
获取调用进程的父进程 ID。
原型
1 |
|
返回值
- 返回调用进程的父进程 ID。
使用示例
1 |
|
getpgid
功能
获取指定进程的进程组 ID。
原型
1 |
|
参数
pid:要查询的进程的进程 ID。如果pid为 0,则返回调用进程的进程组 ID。
返回值
- 成功时返回指定进程的进程组 ID。
- 失败时返回 -1,并设置
errno来指示错误类型。
使用示例
1 |
|
getsid
功能
获取指定进程的会话 ID。
原型
1 |
|
参数
pid:要查询的进程的进程 ID。如果pid为 0,则返回调用进程的会话 ID。
返回值
- 成功时返回指定进程的会话 ID。
- 失败时返回 -1,并设置
errno来指示错误类型。
使用示例
1 |
|
注意事项
- 权限:调用这些函数通常不需要特殊权限,但如果查询其他进程的信息,可能会受到权限限制。
- 错误处理:对于
getpgid和getsid,如果返回 -1,请检查errno以了解具体的错误原因。 - 概念理解:
- **进程 ID (PID)**:每个进程在系统中都有唯一的标识符。
- **父进程 ID (PPID)**:一个进程的父进程的 ID。
- **进程组 ID (PGID)**:进程组用于信号分发,多个进程可以属于同一个进程组。
- **会话 ID (SID)**:一个会话可以包含多个进程组,通常与控制终端相关联。
进程创建
在 Linux 和其他类 Unix 操作系统中,fork 和 vfork 是用于创建新进程的系统调用。它们在进程管理和多任务处理方面发挥着重要作用。以下是对这两个函数的详细解析:
fork 函数
fork 是用于创建一个新进程的系统调用。新进程被称为子进程,它是调用 fork 的进程(父进程)的副本。
函数原型
1 |
|
返回值
- 在父进程中,
fork返回子进程的进程 ID。 - 在子进程中,
fork返回 0。 - 如果发生错误,
fork返回 -1,并设置errno。
特点
- 子进程是父进程的一个几乎完全的副本,包括文件描述符、环境变量、用户 ID 等。
- 子进程有自己独立的地址空间,父子进程之间的内存是分开的。
fork使用写时复制(Copy-On-Write)技术来优化内存使用。
使用示例
1 |
|
vfork 函数
vfork 是 fork 的一个变种,用于创建一个新进程。它与 fork 的主要区别在于性能和行为。
函数原型
1 |
|
返回值
- 在父进程中,
vfork返回子进程的进程 ID。 - 在子进程中,
vfork返回 0。 - 如果发生错误,
vfork返回 -1,并设置errno。
特点
vfork创建的子进程与父进程共享相同的地址空间,直到子进程调用exec或_exit。- 因为共享地址空间,子进程在
exec或_exit之前不应该修改父进程的数据。 vfork比fork更高效,因为它不需要复制父进程的地址空间。
使用注意
vfork主要用于在子进程立即调用exec时提高性能。- 不建议在
vfork创建的子进程中进行复杂的操作,因为父进程会被阻塞,直到子进程调用exec或_exit。
使用示例
1 |
|
总结
- **
fork**:用于创建子进程,父子进程拥有独立的地址空间,适用于大多数场景。 - **
vfork**:用于创建子进程,子进程与父进程共享地址空间,适用于子进程立即调用exec的场景,以提高性能。
选择使用 fork 还是 vfork,主要取决于应用程序的具体需求和对性能的考虑。一般情况下,fork 是更安全和通用的选择,而 vfork 适用于特定的优化场景。
进程等待
在 Linux 中,进程同步是指协调多个进程的执行顺序,以确保它们能够正确地共享系统资源。对于父子进程之间的同步,wait、waitpid 和 waitid 是常用的系统调用,用于等待子进程的状态变化。以下是对这些函数的详细讲解:
wait 函数
功能:
wait用于使父进程阻塞,直到其任一子进程结束。在子进程终止时,wait收集该子进程的终止状态。原型:
1
2
3
4
pid_t wait(int *status);参数:
status: 一个指向整数的指针,用于存储子进程的退出状态。如果不关心退出状态,可以传递NULL。
返回值:
- 成功时返回终止子进程的 PID。
- 失败时返回
-1,并设置errno以指示错误类型。
使用场景: 适用于简单的父子进程同步需求,父进程不关心哪个子进程终止,只需等待任一子进程结束。
waitpid 函数
功能:
waitpid提供了更细粒度的控制,允许父进程等待特定子进程的状态变化。原型:
1
2
3
4
pid_t waitpid(pid_t pid, int *status, int options);参数:
pid: 指定要等待的子进程的 PID。可以是以下值:> 0: 等待进程 ID 等于pid的子进程。-1: 等待任一子进程,相当于wait。0: 等待与调用进程在同一进程组中的任一子进程。< -1: 等待进程组 ID 等于|pid|的任一子进程。
status: 用于存储子进程的退出状态。options: 可以是以下选项的组合:WNOHANG: 如果没有子进程退出,则立即返回,而不是阻塞。WUNTRACED: 返回已停止的子进程的状态。WCONTINUED: 返回已恢复执行的子进程的状态。
返回值:
- 成功时返回终止或状态变化的子进程的 PID。
- 如果使用
WNOHANG且没有子进程退出,返回0。 - 失败时返回
-1,并设置errno。
使用场景: 适用于需要等待特定子进程或实现非阻塞等待的场景。
waitid 函数
功能:
waitid提供了更灵活的接口,用于等待子进程的状态变化,并获取更详细的状态信息。原型:
1
2
3
4
int waitid(idtype_t idtype, id_t id, siginfo_t *infop, int options);参数:
idtype: 指定id的类型,可以是P_PID(进程 ID)、P_PGID(进程组 ID)或P_ALL(任一子进程)。id: 根据idtype指定的等待对象。infop: 指向siginfo_t结构的指针,用于存储子进程的详细状态信息。options: 控制等待行为的选项,如WNOHANG、WEXITED(等待已终止的子进程)等。
返回值:
- 成功时返回
0。 - 失败时返回
-1,并设置errno。
- 成功时返回
使用场景: 适用于需要获取子进程详细状态信息的复杂同步需求。
进程替换
在 Linux 和类 Unix 系统中,exec 家族的函数用于替换当前进程的映像,即用一个新的程序替换当前正在运行的程序。exec 家族的函数不会创建新的进程,而是在当前进程中执行新的程序代码。这个特性使得 exec 在实现进程控制和程序执行时非常有用,尤其是在使用 fork 创建子进程后用 exec 执行新程序。
exec 家族
exec 家族有多种变体,主要区别在于参数的传递方式和环境变量的处理方式。以下是主要的 exec 函数:
execl: 用于指定可执行文件路径及一系列可变参数,参数列表必须以NULL结尾。1
int execl(const char *path, const char *arg, ..., NULL);
execlp: 类似于execl,但会在PATH环境变量指定的目录中查找可执行文件。1
int execlp(const char *file, const char *arg, ..., NULL);
execle: 类似于execl,但允许显式传递环境变量列表。1
int execle(const char *path, const char *arg, ..., NULL, char *const envp[]);
execv: 使用参数数组传递参数。1
int execv(const char *path, char *const argv[]);
execvp: 类似于execv,但会在PATH环境变量指定的目录中查找可执行文件。1
int execvp(const char *file, char *const argv[]);
execve: 最底层的exec函数,允许传递参数数组和环境变量数组。1
int execve(const char *filename, char *const argv[], char *const envp[]);
使用说明
返回值:
exec函数族中的函数通常不返回。如果返回,则表示执行失败,此时返回值为-1,并设置errno以指示错误原因。错误处理: 常见错误包括文件不存在(
ENOENT)、没有执行权限(EACCES)等。环境变量: 使用
execle和execve可以指定新的环境变量数组;其他变体会继承当前进程的环境变量。
示例代码
以下是使用 execvp 的示例代码,它在子进程中替换为执行 ls 命令:
1 |
|
注意事项
进程替换:
exec函数会用新程序替换当前进程的代码段、数据段和堆栈段,但保留进程 ID 和一些资源(如打开的文件描述符,除非设置了FD_CLOEXEC标志)。与
fork配合: 常见用法是fork创建子进程,然后在子进程中调用exec执行新程序。环境变量传递: 如果需要传递特定的环境变量给新程序,使用
execle或execve。
通过理解和使用 exec 家族的函数,可以在 Linux 环境中灵活地控制和执行程序。
守护进程
daemon() 是一个在 Linux 系统中用于将进程转化为守护进程(daemon)的函数。守护进程是在后台运行的进程,通常用于执行系统服务或后台任务。
函数原型
1 | int daemon(int nochdir, int noclose); |
参数说明
nochdir:- 如果为
0,则将当前工作目录更改为根目录/。 - 如果为非零值,则不更改当前工作目录。
- 如果为
noclose:- 如果为
0,则将标准输入、标准输出和标准错误重定向到/dev/null。 - 如果为非零值,则不关闭标准输入、输出和错误。
- 如果为
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno以指示错误原因。
功能详解
创建子进程: 使用
fork()函数创建一个子进程,然后使父进程退出。这样做的目的是让子进程在后台运行。创建新的会话: 使用
setsid()创建一个新的会话,并使当前进程成为会话的领导者。这将导致进程脱离控制终端,从而变成一个真正的守护进程。更改工作目录: 如果
nochdir为0,则将当前工作目录更改为根目录。这是为了避免守护进程在运行期间阻止挂载的文件系统被卸载。重定向标准流: 如果
noclose为0,则关闭标准输入、输出和错误,并将它们重定向到/dev/null。这避免了守护进程在后台运行时意外地与终端交互。
使用示例
以下是一个简单的示例,展示如何使用 daemon() 函数:
1 |
|
注意事项
- 权限: 确保守护进程有足够的权限执行所需的任务。
- 资源管理: 守护进程需要妥善管理系统资源,例如内存、文件描述符等,以避免资源泄漏。
- 信号处理: 考虑为守护进程设置适当的信号处理程序,以便能够优雅地处理终止信号和其他重要信号。
- 日志记录: 由于守护进程通常不与用户直接交互,建议使用日志文件记录其活动和错误信息。
进程退出
在 Linux 和其他类 Unix 操作系统中,进程可以通过多种方式退出,包括使用 exit、_exit、atexit 和 return。每种方式在细节和用途上有所不同。以下是对这些方法的详细解析:
exit 函数
exit 函数用于正常终止进程,并执行清理操作。
函数原型
1 |
|
参数
- **
status**:退出状态码,通常0表示成功,非零值表示错误或异常。
特点
- 调用
exit会执行所有注册的atexit函数。 - 刷新所有打开文件的缓冲区。
- 释放进程的所有资源。
- 通知父进程子进程已终止。
使用示例
1 |
|
_exit 函数
_exit 函数用于立即终止进程,不执行任何清理操作。
函数原型
1 |
|
参数
- **
status**:退出状态码。
特点
- 不会执行
atexit注册的函数。 - 不刷新文件缓冲区。
- 立即终止进程。
- 常用于子进程在
fork后立即退出的场景。
使用示例
1 |
|
atexit 函数
atexit 函数用于注册一个在 exit 调用时执行的函数。
函数原型
1 |
|
参数
- **
func**:指向无参数、无返回值函数的指针。
返回值
- 成功时返回
0。 - 失败时返回非零值。
特点
- 可以注册多个函数,调用顺序与注册顺序相反(后注册的先调用)。
- 常用于释放资源或执行其他清理操作。
使用示例
1 |
|
return 语句
return 语句用于从函数返回,并在 main 函数中用于终止程序。
特点
- 在
main函数中,return等效于调用exit。 - 返回值作为程序的退出状态码。
- 执行
atexit注册的函数和其他清理操作。
使用示例
1 |
|
总结
- **
exit**:正常退出程序,执行清理操作,刷新缓冲区,适用于大多数场景。 - **
_exit**:立即退出程序,不执行清理操作,适用于子进程需要快速退出的场景。 - **
atexit**:注册退出时执行的函数,用于资源释放和清理。 - **
return**:在main函数中用于退出程序,等效于exit。
选择使用哪种退出方式,取决于具体的程序需求和对资源清理的考虑。一般情况下,exit 和 return 是最常用的退出方式,而 _exit 则用于特定的性能优化场景。
进程调度
在 Linux 系统中,进程调度是操作系统内核的重要功能之一,它负责管理 CPU 资源的分配。Linux 提供了一些 API 来与进程调度器进行交互,这些 API 允许程序员设置或查询进程的调度策略和优先级。
以下是一些与进程调度相关的常用 API:
sched_setscheduler
功能
设置进程的调度策略和优先级。
原型
1 |
|
参数
pid:要设置的进程 ID。如果为 0,则表示当前进程。policy:调度策略,可以是以下之一:SCHED_OTHER:默认的时间共享调度策略。SCHED_FIFO:实时调度策略,先进先出。SCHED_RR:实时调度策略,时间片轮转。SCHED_BATCH:适用于批处理作业。SCHED_IDLE:适用于非常低优先级的作业。
param:指向包含优先级信息的sched_param结构体的指针。
返回值
- 成功时返回 0。
- 失败时返回 -1,并设置
errno。
sched_getscheduler
功能
获取进程的调度策略。
原型
1 |
|
参数
pid:要查询的进程 ID。如果为 0,则表示当前进程。
返回值
- 成功时返回调度策略。
- 失败时返回 -1,并设置
errno。
sched_setparam
功能
设置进程的调度优先级。
原型
1 |
|
参数
pid:要设置的进程 ID。如果为 0,则表示当前进程。param:指向包含优先级信息的sched_param结构体的指针。
返回值
- 成功时返回 0。
- 失败时返回 -1,并设置
errno。
sched_getparam
功能
获取进程的调度优先级。
原型
1 |
|
参数
pid:要查询的进程 ID。如果为 0,则表示当前进程。param:指向sched_param结构体的指针,用于存储优先级信息。
返回值
- 成功时返回 0。
- 失败时返回 -1,并设置
errno。
sched_yield
功能
让出处理器,以便其他进程可以运行。
原型
1 |
|
返回值
- 成功时返回 0。
- 失败时返回 -1,并设置
errno。
sched_get_priority_max / sched_get_priority_min
功能
获取指定调度策略的最大和最小优先级。
原型
1 |
|
参数
policy:调度策略。
返回值
- 成功时返回最大或最小优先级。
- 失败时返回 -1,并设置
errno。
注意事项
- 实时调度策略(如
SCHED_FIFO和SCHED_RR)通常需要超级用户权限。 - 使用这些 API 时需要理解调度策略的影响,特别是在实时系统中。
- 调度优先级的范围因策略而异,可以使用
sched_get_priority_max和sched_get_priority_min来获取合法的优先级范围。
CPU 亲和力
在 Linux 中,CPU 亲和力(CPU Affinity)是指将特定进程或线程绑定到特定的 CPU 核心上运行。这样可以提高缓存命中率,减少上下文切换带来的开销,从而在某些情况下提高性能。Linux 提供了一些 API 来设置和获取进程或线程的 CPU 亲和力。
以下是与 CPU 亲和力相关的常用 API:
sched_setaffinity
功能
设置进程的 CPU 亲和力,即指定进程可以在哪些 CPU 上运行。
原型
1 |
|
参数
pid:要设置的进程 ID。如果为 0,则表示当前进程。cpusetsize:cpu_set_t数据结构的大小,通常使用sizeof(cpu_set_t)。mask:指向cpu_set_t结构的指针,该结构指定了允许进程运行的 CPU 集合。
返回值
- 成功时返回 0。
- 失败时返回 -1,并设置
errno。
使用示例
1 |
|
sched_getaffinity
功能
获取进程的 CPU 亲和力,即查询进程可以在哪些 CPU 上运行。
原型
1 |
|
参数
pid:要查询的进程 ID。如果为 0,则表示当前进程。cpusetsize:cpu_set_t数据结构的大小,通常使用sizeof(cpu_set_t)。mask:指向cpu_set_t结构的指针,用于存储允许进程运行的 CPU 集合。
返回值
- 成功时返回 0。
- 失败时返回 -1,并设置
errno.
使用示例
1 |
|
注意事项
cpu_set_t是一个位掩码,用于表示 CPU 的集合。可以使用CPU_ZERO、CPU_SET、CPU_CLR和CPU_ISSET等宏来操作这个集合。- 设置 CPU 亲和力需要有足够的权限,通常需要超级用户权限。
- 在多核处理器系统中,合理设置 CPU 亲和力可以提高应用程序性能,但也可能导致负载不均衡,因此需要谨慎使用。
在 Linux 中,cpu_set_t 和相关的宏(如 CPU_ZERO、CPU_SET、CPU_CLR 和 CPU_ISSET)用于管理和操作 CPU 集合。这些工具允许程序员指定进程或线程在哪些 CPU 上运行。以下是对这些工具的详细介绍:
cpu_set_t
cpu_set_t 是一个数据结构,用于表示 CPU 集合。它实际上是一个位掩码,每一位表示一个 CPU。这个结构通常是一个数组,能够表示系统中所有可能的 CPU。
宏函数
CPU_ZERO
功能:
初始化 cpu_set_t 结构,将其所有位清零。这意味着在初始化后,集合中没有任何 CPU。
用法:
1 | void CPU_ZERO(cpu_set_t *set); |
示例:
1 | cpu_set_t mask; |
CPU_SET
功能:
将指定的 CPU 添加到 cpu_set_t 结构中。即,将对应位设置为 1。
用法:
1 | void CPU_SET(int cpu, cpu_set_t *set); |
参数:
cpu: 要添加的 CPU 的编号。set: 指向cpu_set_t结构的指针。
示例:
1 | CPU_SET(0, &mask); // 将 CPU 0 添加到集合中 |
CPU_CLR
功能:
从 cpu_set_t 结构中移除指定的 CPU。即,将对应位清零。
用法:
1 | void CPU_CLR(int cpu, cpu_set_t *set); |
参数:
cpu: 要移除的 CPU 的编号。set: 指向cpu_set_t结构的指针。
示例:
1 | CPU_CLR(0, &mask); // 从集合中移除 CPU 0 |
CPU_ISSET
功能:
检查指定的 CPU 是否在 cpu_set_t 结构中。即,检查对应位是否为 1。
用法:
1 | int CPU_ISSET(int cpu, const cpu_set_t *set); |
参数:
cpu: 要检查的 CPU 的编号。set: 指向cpu_set_t结构的指针。
返回值:
- 如果 CPU 在集合中,返回非零值。
- 如果 CPU 不在集合中,返回 0。
示例:
1 | if (CPU_ISSET(0, &mask)) { |
使用示例
以下是一个完整的示例,展示了如何使用这些宏来操作 CPU 集合:
1 |
|
注意事项
cpu_set_t的大小通常足够大,可以表示系统中所有可能的 CPU,但在某些非常大的系统中,可能需要调整。- 这些 API 和宏是线程安全的,可以在多线程环境中使用。
- 在使用这些宏时,确保对
cpu_set_t结构进行适当的初始化和操作,以避免未定义行为。
长跳转
jmp_buf 是一个类型定义,用于保存由 setjmp 函数记录的执行环境信息,以便后续可以通过 longjmp 恢复该环境。它是一个数组类型,具体的实现细节依赖于具体的编译器和平台,因为它需要保存足够的信息来恢复程序的执行状态。
jmp_buf 的特点
- 平台依赖:
jmp_buf的具体大小和内容是平台依赖的。通常,它会包含一些寄存器状态和栈指针,以便能够恢复程序的执行环境。 - 不可直接访问:程序员通常无法直接访问或修改
jmp_buf的内容,只能通过setjmp和longjmp使用它。 - 使用限制:由于
jmp_buf保存的是执行环境,使用时需要确保在setjmp和longjmp之间的代码不会破坏该环境。例如,不能通过longjmp跳转到已经退出的函数。
使用示例
在使用 setjmp 和 longjmp 时,通常会如下定义和使用 jmp_buf:
1 |
|
在这个示例中:
jmp_buf env用于保存setjmp的执行环境。setjmp(env)保存当前的栈状态。longjmp(env, 1)恢复到setjmp的状态,并使setjmp返回 1。
注意事项
- 不可跨函数使用:不能通过
longjmp跳转到已经返回的函数,因为这会导致未定义行为。 - 适用于非局部跳转:
jmp_buf主要用于实现非局部跳转,通常在错误处理或异常处理的场景中使用。 - 线程安全性:在多线程环境中使用时需要注意,因为
jmp_buf只保存调用线程的上下文。
总的来说,jmp_buf 是一个底层的、平台相关的结构,用于实现非局部跳转。使用时需要小心管理资源和控制流,以避免出现不可预测的行为。
setjmp 和 longjmp 是 C 语言标准库中提供的用于非局部跳转的函数。这两个函数允许程序在代码执行过程中跳转到先前保存的状态,通常用于错误处理和异常处理。它们在某些情况下可以替代异常处理机制,但使用时需要小心,因为它们会绕过常规的栈帧展开过程。
setjmp 函数
setjmp 用于保存当前的执行环境(即程序的栈上下文),以便后续可以使用 longjmp 恢复到这个状态。
函数原型
1 |
|
参数
- **
env**:用于保存环境信息的缓冲区,类型为jmp_buf。
返回值
- 如果直接调用
setjmp,则返回值为 0。 - 如果通过
longjmp恢复到setjmp,则返回值为longjmp提供的非零值。
使用示例
1 |
|
longjmp 函数
longjmp 用于跳转到之前通过 setjmp 保存的执行环境。
函数原型
1 |
|
参数
- **
env**:由setjmp保存的环境信息。 - **
val**:跳转后setjmp的返回值。如果val为 0,则返回 1。
特点
longjmp会跳过栈帧的展开过程,因此不会执行自动对象的析构函数或清理代码。- 使用
longjmp可以恢复到setjmp保存的状态,但需要小心管理资源,以避免资源泄漏或未定义行为。
使用注意
资源管理:由于
longjmp跳过了栈帧的展开,可能导致资源未被正确释放。因此,避免在使用setjmp和longjmp的代码中使用需要自动清理的资源(如动态分配的内存、打开的文件等)。返回值处理:
longjmp的返回值不能为 0,因此如果val为 0,setjmp会返回 1。代码可读性:使用
setjmp和longjmp可能会导致代码难以理解,建议仅在必要时使用,并添加适当的注释。线程安全:
setjmp和longjmp在多线程环境中可能不安全,因为它们只保存调用线程的上下文。
总结
- **
setjmp**:用于保存当前执行环境,以便后续通过longjmp恢复。 - **
longjmp**:用于跳转到之前保存的执行环境,常用于错误处理。
setjmp 和 longjmp 提供了一种灵活但危险的控制流机制,适合某些特定场景的错误处理。
环境变量
在 Linux 环境编程中,与环境变量相关的函数主要包括以下几个:
getenv
- 功能:获取环境变量的值。
- 原型:
1
2
3
char *getenv(const char *name); - 参数:
name是要获取的环境变量的名称。 - 返回值:返回指向环境变量值的指针,如果环境变量不存在,则返回
NULL。
putenv
- 功能:添加或修改环境变量。
- 原型:
1
2
3
int putenv(char *string); - 参数:
string是一个格式为NAME=VALUE的字符串。 - 返回值:成功时返回 0,失败时返回非零值。
- 注意:该函数直接使用传入的字符串,因此传入的字符串必须是可修改的。
setenv
- 功能:设置环境变量。
- 原型:
1
2
3
int setenv(const char *name, const char *value, int overwrite); - 参数:
name:环境变量的名称。value:环境变量的值。overwrite:如果为非零值,则覆盖已有的环境变量。
- 返回值:成功时返回 0,失败时返回 -1。
unsetenv
- 功能:删除环境变量。
- 原型:
1
2
3
int unsetenv(const char *name); - 参数:
name是要删除的环境变量的名称。 - 返回值:成功时返回 0,失败时返回 -1。
clearenv
- 功能:清除所有环境变量。
- 原型:
1
2
3
int clearenv(void); - 返回值:成功时返回 0,失败时返回 -1。
使用示例
以下是一个简单的示例,演示如何使用这些函数:
1 |
|
注意事项
- 环境变量的名称通常是大小写敏感的。
putenv和setenv的区别在于putenv直接使用传入的字符串,而setenv会复制字符串。- 在多线程程序中,修改环境变量时需要注意线程安全问题,因为环境变量是进程级别的共享资源。
- Title: Linux环境编程与内核之进程
- Author: 韩乔落
- Created at : 2024-02-01 11:01:40
- Updated at : 2025-03-19 18:10:54
- Link: https://jelasin.github.io/2024/02/01/Linux环境编程与内核之进程/
- License: This work is licensed under CC BY-NC-SA 4.0.